Amazon Elastic MapReduce (EMR)でApache Spark Driver for Treasure Data(td-sparkとも呼ばれます)を使用できます。最適なパフォーマンスを得るためにAmazon EC2のus-eastリージョンの使用をお勧めしますが、他のSpark環境でもtd-sparkを使用できます。
td-sparkの概要については、TD Spark FAQsを参照してください。
- ScalaとPython (PySpark)のSparkからTreasure Dataにアクセスします。
- Treasure DataテーブルをSparkにDataFrameとして取り込みます(TDクエリは発行されず、TD保存データとSparkクラスター間の最短のレイテンシパスを提供します)。
- Presto、Hive、またはSparkSQLクエリを発行し、結果をSpark DataFrameとして返します。
このドライバは、Spark 2.4.4以降での使用が推奨されます
最速のデータアクセスと最低のデータ転送コストのために、AWSのus-eastリージョンでSparkクラスターをセットアップすることをお勧めします。他のAWSリージョンまたは処理環境を使用すると、データ転送コストが非常に高くなる可能性があります。
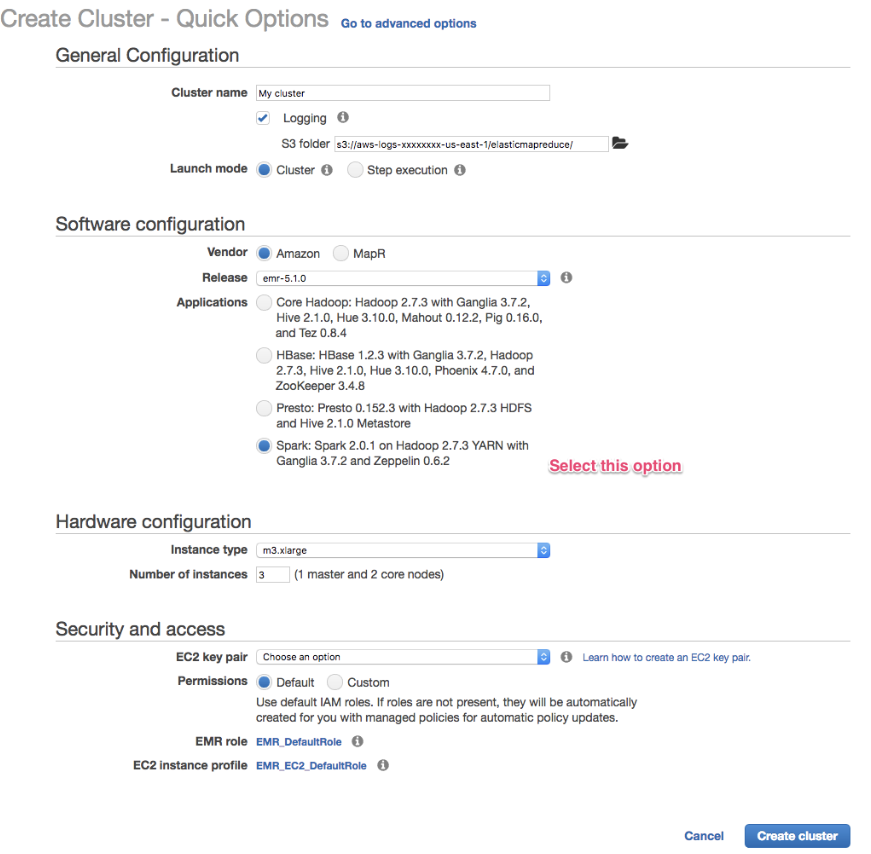
Sparkサポート付きのEMRクラスターを作成します。
S3からのデータ転送パフォーマンスを最大化するために、us-eastリージョンが推奨されます。
新しいEMRのマスターノードアドレスを確認します。
テーブルデータをSpark DataFrameとして読み取ります
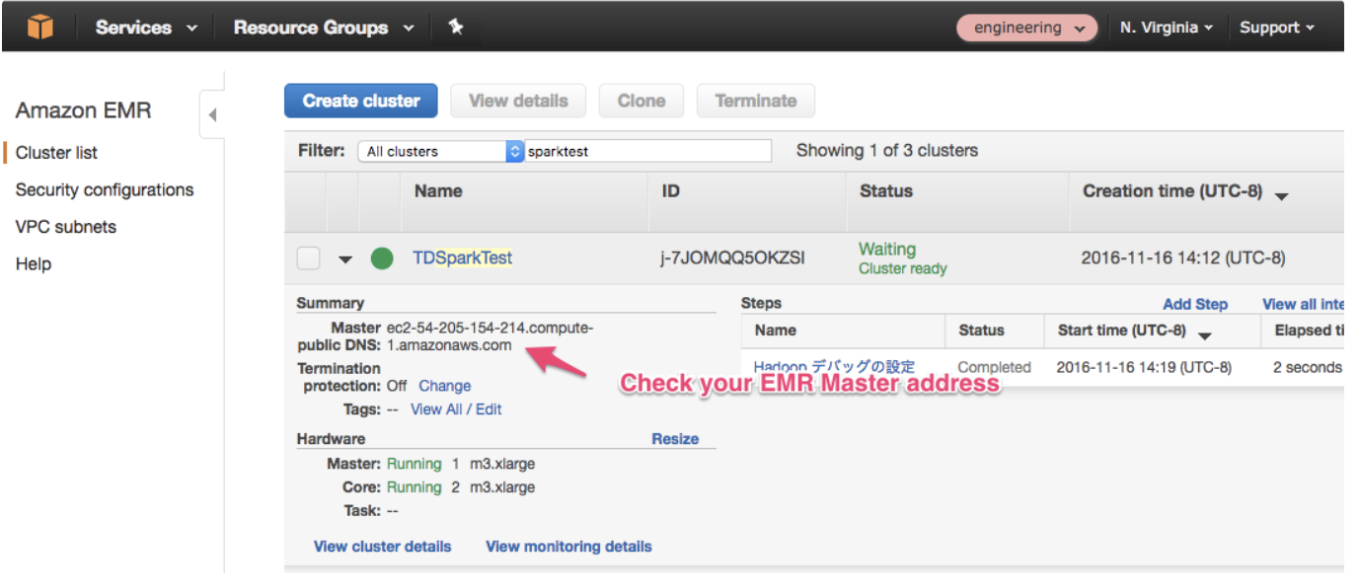
デフォルトのセキュリティグループ(ElasticMapReduce-master)でEMRを作成した場合は、環境からのインバウンドアクセスを許可する必要があります。Amazon EMR-Managed Security Groupsを参照してください。
Connect to EMR Master node with SSH
# SOCKS5プロキシポート8157を使用して、EMR Sparkジョブ履歴ページ(ポート18080)、Zeppelinノートブック(ポート8890)などにアクセスできるようにします。
$ ssh -i (your AWS key pair file. .pem) -D8157 hadoop@ec2-xxx-xxx-xxx-xxx.compute-1.amazonaws.com
__| __|_ )
_| ( / Amazon Linux AMI
___|\___|___|
https://aws.amazon.com/amazon-linux-ami/2016.09-release-notes/
4 package(s) needed for security, out of 6 available
Run "sudo yum update" to apply all updates.
EEEEEEEEEEEEEEEEEEEE MMMMMMMM MMMMMMMM RRRRRRRRRRRRRRR
E::::::::::::::::::E M:::::::M M:::::::M R::::::::::::::R
EE:::::EEEEEEEEE:::E M::::::::M M::::::::M R:::::RRRRRR:::::R
E::::E EEEEE M:::::::::M M:::::::::M RR::::R R::::R
E::::E M::::::M:::M M:::M::::::M R:::R R::::R
E:::::EEEEEEEEEE M:::::M M:::M M:::M M:::::M R:::RRRRRR:::::R
E::::::::::::::E M:::::M M:::M:::M M:::::M R:::::::::::RR
E:::::EEEEEEEEEE M:::::M M:::::M M:::::M R:::RRRRRR::::R
E::::E M:::::M M:::M M:::::M R:::R R::::R
E::::E EEEEE M:::::M MMM M:::::M R:::R R::::R
EE:::::EEEEEEEE::::E M:::::M M:::::M R:::R R::::R
E::::::::::::::::::E M:::::M M:::::M RR::::R R::::R
EEEEEEEEEEEEEEEEEEEE MMMMMMM MMMMMMM RRRRRRR RRRRRRtd-spark jarファイルをダウンロードします:
[hadoop@ip-x-x-x-x]$ wget https://s3.amazonaws.com/td-spark/td-spark-assembly_2.11-0.4.0.jarマスターノードにtd.confファイルを作成します:
# ここにTD APIキーを記述します
spark.td.apikey (your TD API key)
spark.td.site (your site name: us, jp, ap02, eu01, etc.)
# (推奨) より高速なパフォーマンスのためにKryoSerializerを使用
spark.serializer org.apache.spark.serializer.KryoSerializer[hadoop@ip-x-x-x-x]$ spark-shell --master yarn --jars td-spark-assembly-latest.jar --properties-file td.conf
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 2.1.0
/_/
scala> import com.treasuredata.spark._
scala> val td = spark.td
scala> val d = td.table("sample_datasets.www_access").df
scala> d.show
+----+---------------+--------------------+--------------------+----+--------------------+----+------+----------+
|user| host| path| referer|code| agent|size|method| time|
+----+---------------+--------------------+--------------------+----+--------------------+----+------+----------+
|null|136.162.131.221| /category/health| /category/cameras| 200|Mozilla/5.0 (Wind...| 77| GET|1412373596|
|null| 172.33.129.134| /category/toys| /item/office/4216| 200|Mozilla/5.0 (comp...| 115| GET|1412373585|
|null| 220.192.77.135| /category/software| -| 200|Mozilla/5.0 (comp...| 116| GET|1412373574|
+----+---------------+--------------------+--------------------+----+--------------------+----+------+----------+
only showing top 3 rows- EMRクラスターへのSSHトンネルを作成します。
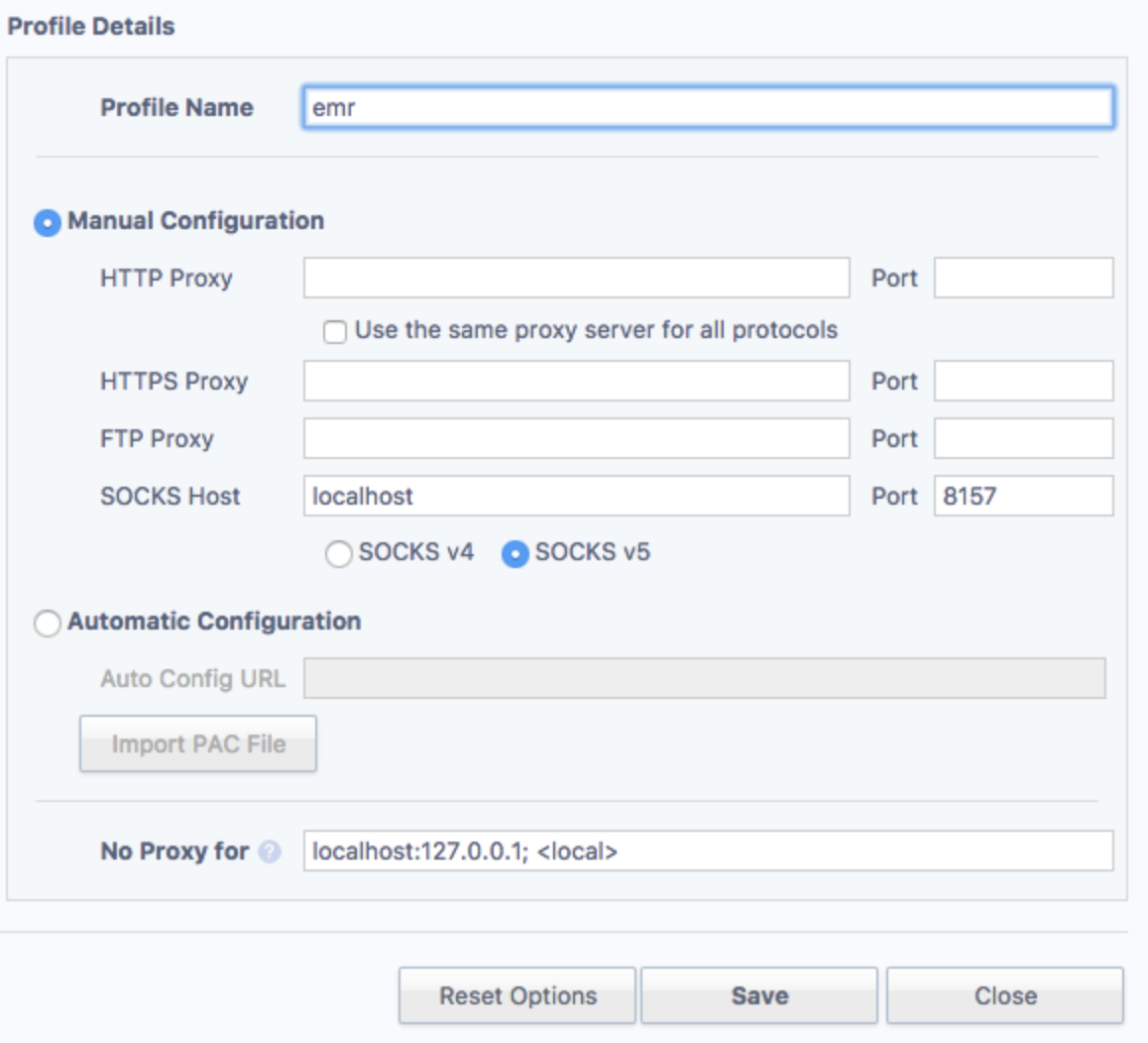
$ ssh -i (your AWS key pair file. .pem) -D8157 hadoop@ec2-xxx-xxx-xxx-xxx.compute-1.amazonaws.com(Chromeユーザー向け) Proxy Switchy Sharp Chrome Extensionをインストールします。EMRマスターにアクセスする際にEMRのproxy-switchをオンにします 2. http://(your EMR master node public address):8890/を開きます 3. td-sparkを設定するためにInterpretersページを開きます。
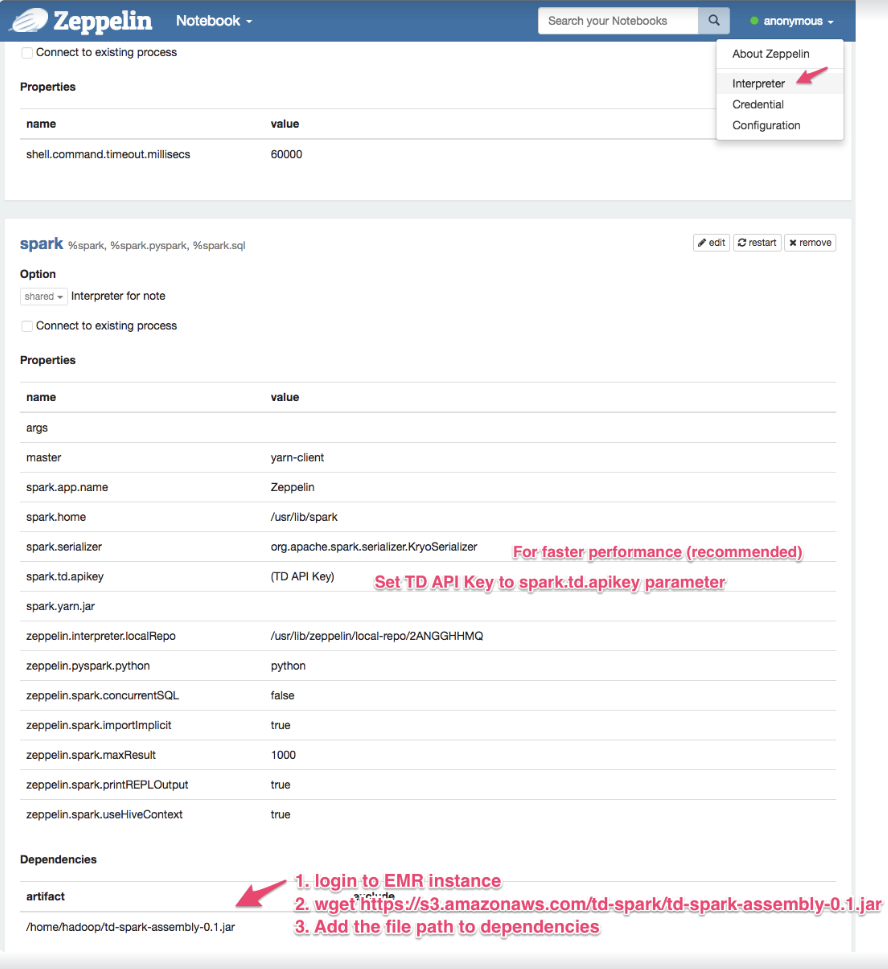 4. プロファイルの詳細を編集し、Saveを選択します。
4. プロファイルの詳細を編集し、Saveを選択します。
テーブルデータをSpark DataFrameとして読み取ることができます。
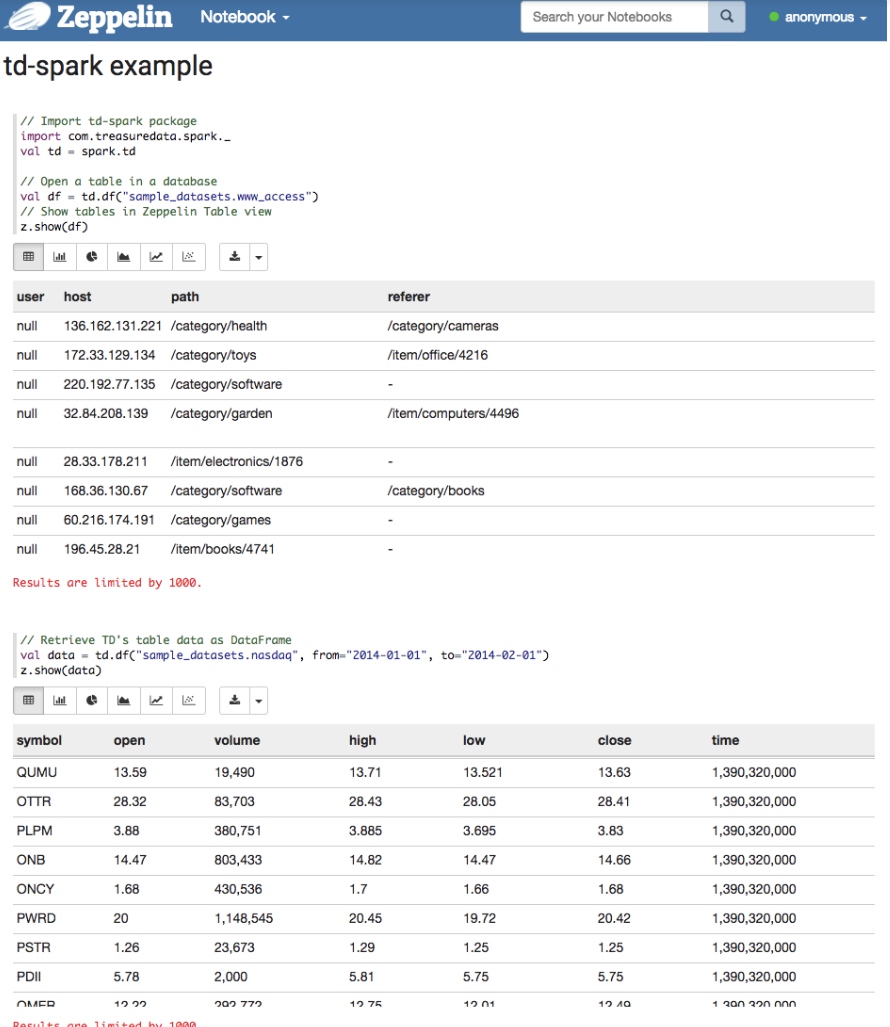
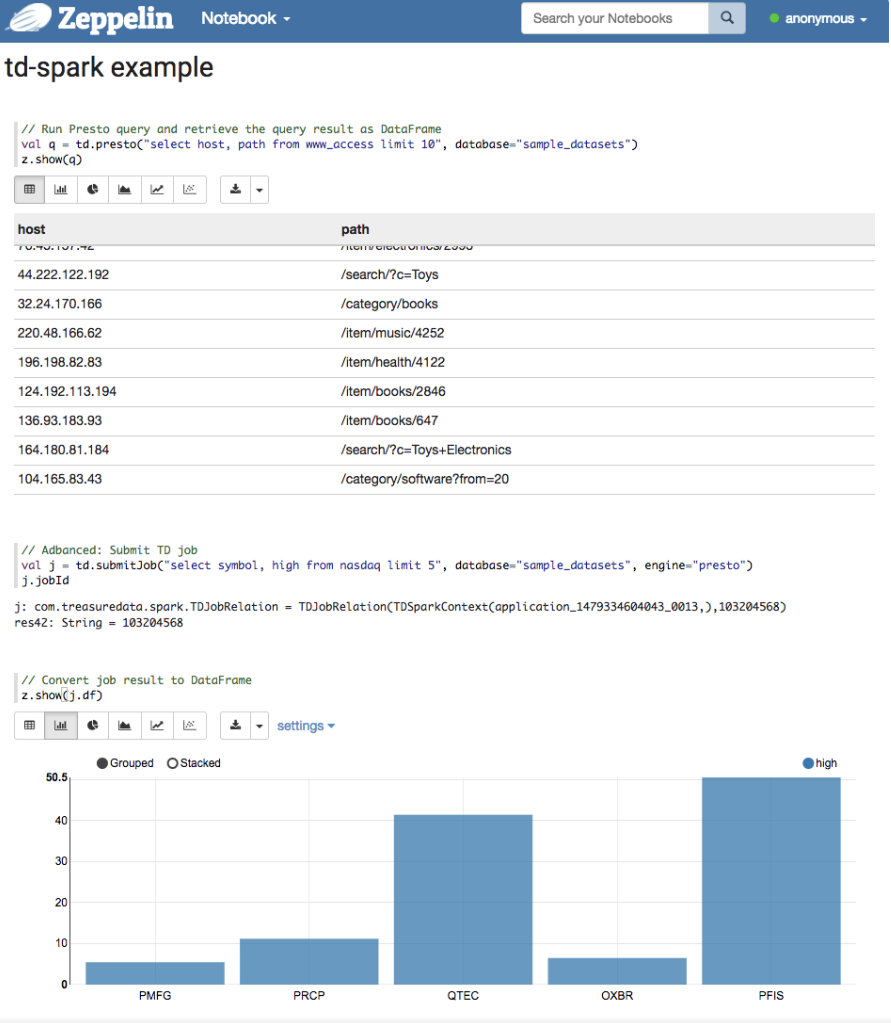
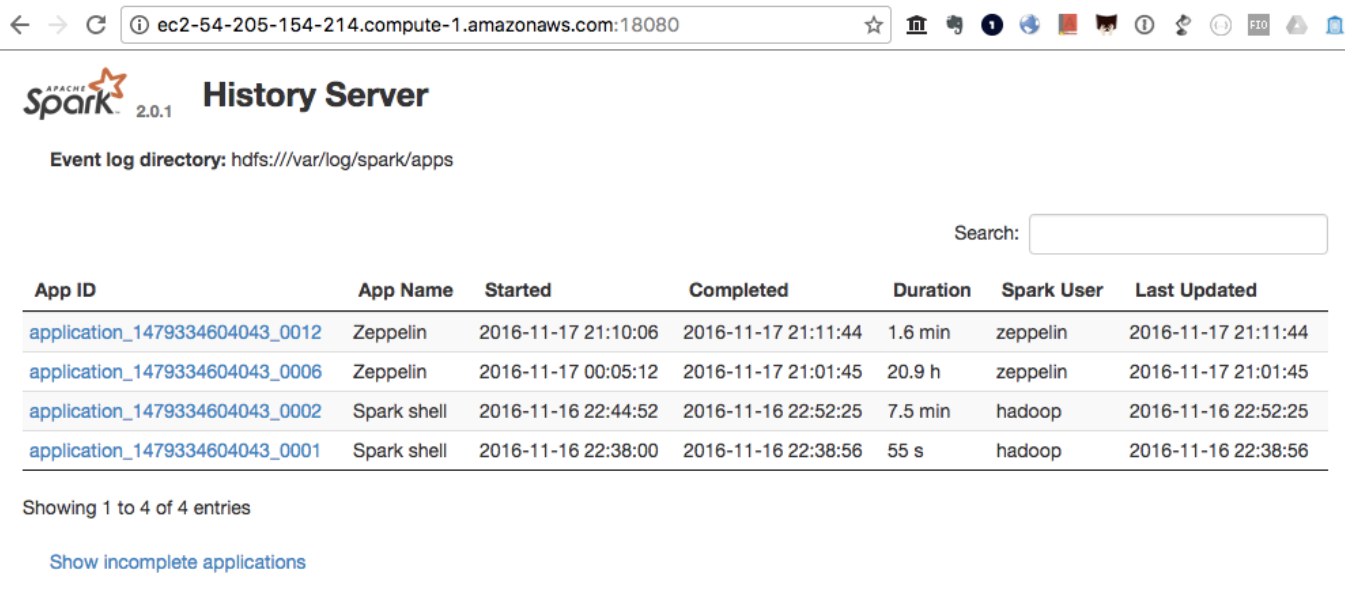
EMRマスターノードのパブリックアドレスを使用して、History Serverでイベント履歴を確認できます。
http://(your EMR master node public address):18080/
$ ./bin/pyspark --driver-class-path ~/work/git/td-spark/td-spark/target/td-spark-assembly-0.1-SNAPSHOT.jar --properties-file ../td-dev.conf
>>> df = spark.read.format("com.treasuredata.spark").load("sample_datasets.www_access")
>>> df.show(10)
2016-07-19 16:34:15-0700 info [TDRelation] Fetching www_access within time range:[-9223372036854775808,9223372036854775807) - (TDRelation.scala:82)
2016-07-19 16:34:16-0700 info [TDRelation] Retrieved 19 PlazmaAPI entries - (TDRelation.scala:85)
+----+---------------+--------------------+--------------------+----+--------------------+----+------+----------+
|user| host| path| referer|code| agent|size|method| time|
+----+---------------+--------------------+--------------------+----+--------------------+----+------+----------+
|null| 148.165.90.106|/category/electro...| /category/music| 200|Mozilla/4.0 (comp...| 66| GET|1412333993|
|null| 144.105.77.66|/item/electronics...| /category/computers| 200|Mozilla/5.0 (iPad...| 135| GET|1412333977|
|null| 108.54.178.116|/category/electro...| /category/software| 200|Mozilla/5.0 (Wind...| 69| GET|1412333961|
|null|104.129.105.202|/item/electronics...| /item/games/394| 200|Mozilla/5.0 (comp...| 83| GET|1412333945|
|null| 208.48.26.63| /item/software/706|/search/?c=Softwa...| 200|Mozilla/5.0 (comp...| 76| GET|1412333930|
|null| 108.78.209.95|/item/giftcards/4879| /item/toys/197| 200|Mozilla/5.0 (Wind...| 137| GET|1412333914|
|null| 108.198.97.206|/item/computers/4785| -| 200|Mozilla/5.0 (Wind...| 69| GET|1412333898|
|null| 172.195.185.46| /category/games| /category/games| 200|Mozilla/5.0 (Maci...| 41| GET|1412333882|
|null| 88.24.72.177|/item/giftcards/4410| -| 200|Mozilla/4.0 (comp...| 72| GET|1412333866|
|null| 24.129.141.79|/category/electro...|/category/networking| 200|Mozilla/5.0 (comp...| 73| GET|1412333850|
+----+---------------+--------------------+--------------------+----+--------------------+----+------+----------+
only showing top 10 rows
## Prestoジョブの送信
>>> df = spark.read.format("com.treasuredata.spark").options(sql="select 1").load("sample_datasets")
2016-07-19 16:56:56-0700 info [TDSparkContext]
Submitted job 515990:
select 1 - (TDSparkContext.scala:70)
>>> df.show(10)
+-----+
|_col0|
+-----+
| 1|
+-----+
## ジョブ結果の読み取り
>>> df = sqlContext.read.format("com.treasuredata.spark").load("job_id:515990")# DataFrameを一時テーブルとして登録
scala> td.df("hb_tiny.rankings").createOrReplaceTempView("rankings")
scala> val q1 = spark.sql("select page_url, page_rank from rankings where page_rank > 100")
q1: org.apache.spark.sql.DataFrame = [page_url: string, page_rank: bigint]
scala> q1.show
2016-07-20 11:27:11-0700 info [TDRelation] Fetching rankings within time range:[-9223372036854775808,9223372036854775807) - (TDRelation.scala:82)
2016-07-20 11:27:12-0700 info [TDRelation] Retrieved 2 PlazmaAPI entries - (TDRelation.scala:85)
+--------------------+---------+
| page_url|page_rank|
+--------------------+---------+
|xjhmjsuqolfklbvxn...| 251|
|seozvzwkcfgnfuzfd...| 165|
|fdgvmwbrjlmvuoquy...| 132|
|gqghyyardomubrfsv...| 108|
|qtqntqkvqioouwfuj...| 278|
|wrwgqnhxviqnaacnc...| 135|
| cxdmunpixtrqnvglnt| 146|
| ixgiosdefdnhrzqomnf| 126|
|xybwfjcuhauxiopfi...| 112|
|ecfuzdmqkvqktydvi...| 237|
|dagtwwybivyiuxmkh...| 177|
|emucailxlqlqazqru...| 134|
|nzaxnvjaqxapdjnzb...| 119|
| ffygkvsklpmup| 332|
|hnapejzsgqrzxdswz...| 171|
|rvbyrwhzgfqvzqkus...| 148|
|knwlhzmcyolhaccqr...| 104|
|nbizrgdziebsaecse...| 665|
|jakofwkgdcxmaaqph...| 187|
|kvhuvcjzcudugtidf...| 120|
+--------------------+---------+
only showing top 20 rows