Repro Import Integrationの詳細はこちらをご覧ください。
新しいRepro Export Integrationコネクタを使用して、簡単な設定のためにカスタマイズされたパラメータでReproのAmazon S3バケットにファイルをエクスポートできます。
- TD Toolbeltを含むTreasure Dataの基本知識
- リージョンIDを持つS3バケット
データ接続を作成する際は、統合にアクセスするための認証情報を提供する必要があります。Treasure Dataでは、まず認証を設定してから、ソース情報を指定します。
- TD Consoleを開きます。
- Integrations Hub > Catalogに移動します。
- Reproを検索して選択します。
- 次のダイアログが開きます:
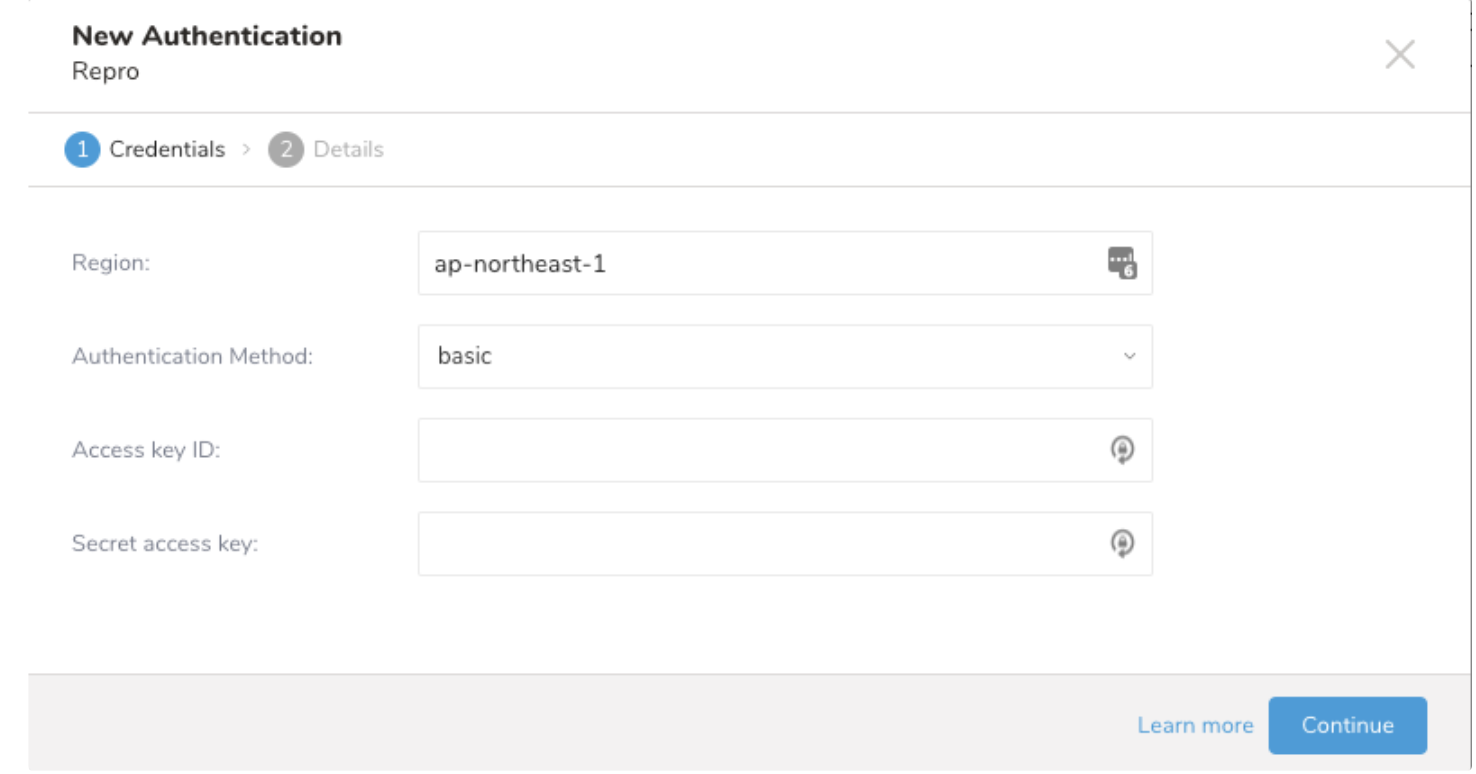
- 接続の名前を入力し、Doneをクリックします。
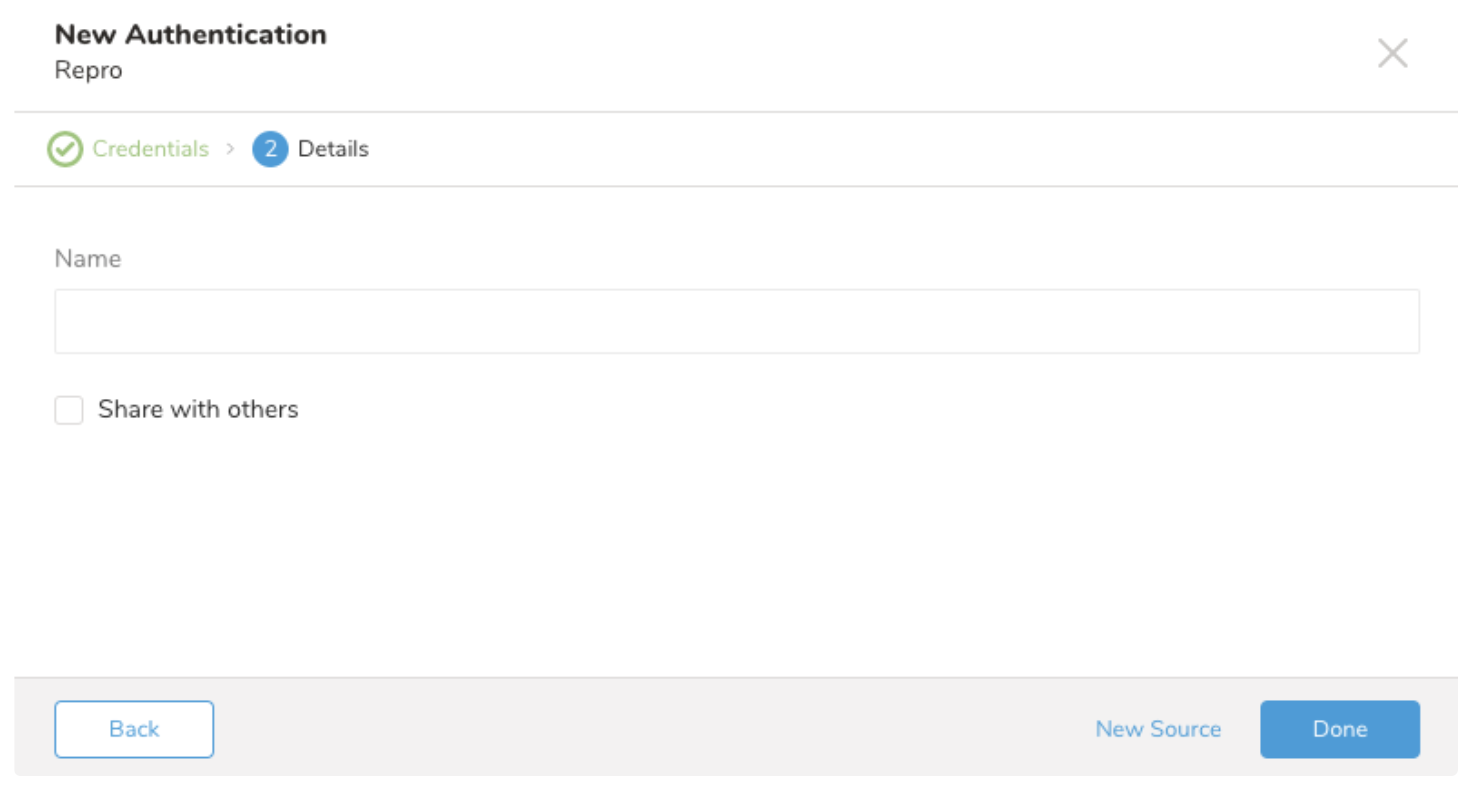
このステップでは、クエリを作成または再利用します。クエリ内でデータ接続を設定します。クエリ内でカラムマッピングを定義する必要がある場合があります。
- TD consoleを開きます。
- Data Workbench > Queriesに移動します。
- データのエクスポートに使用する予定のクエリを選択します。
- クエリエディタの上部にあるExport Resultsをクリックします。Choose Integrationダイアログが開きます。結果をエクスポートするために使用する接続を選択する際には、既存の接続を使用するか、新しい接続を作成するかの2つのオプションがあります。
- 検索ボックスに接続名を入力してフィルタリングします。
- 接続を選択します。
- フィールドの値を入力して新しい接続を作成します。
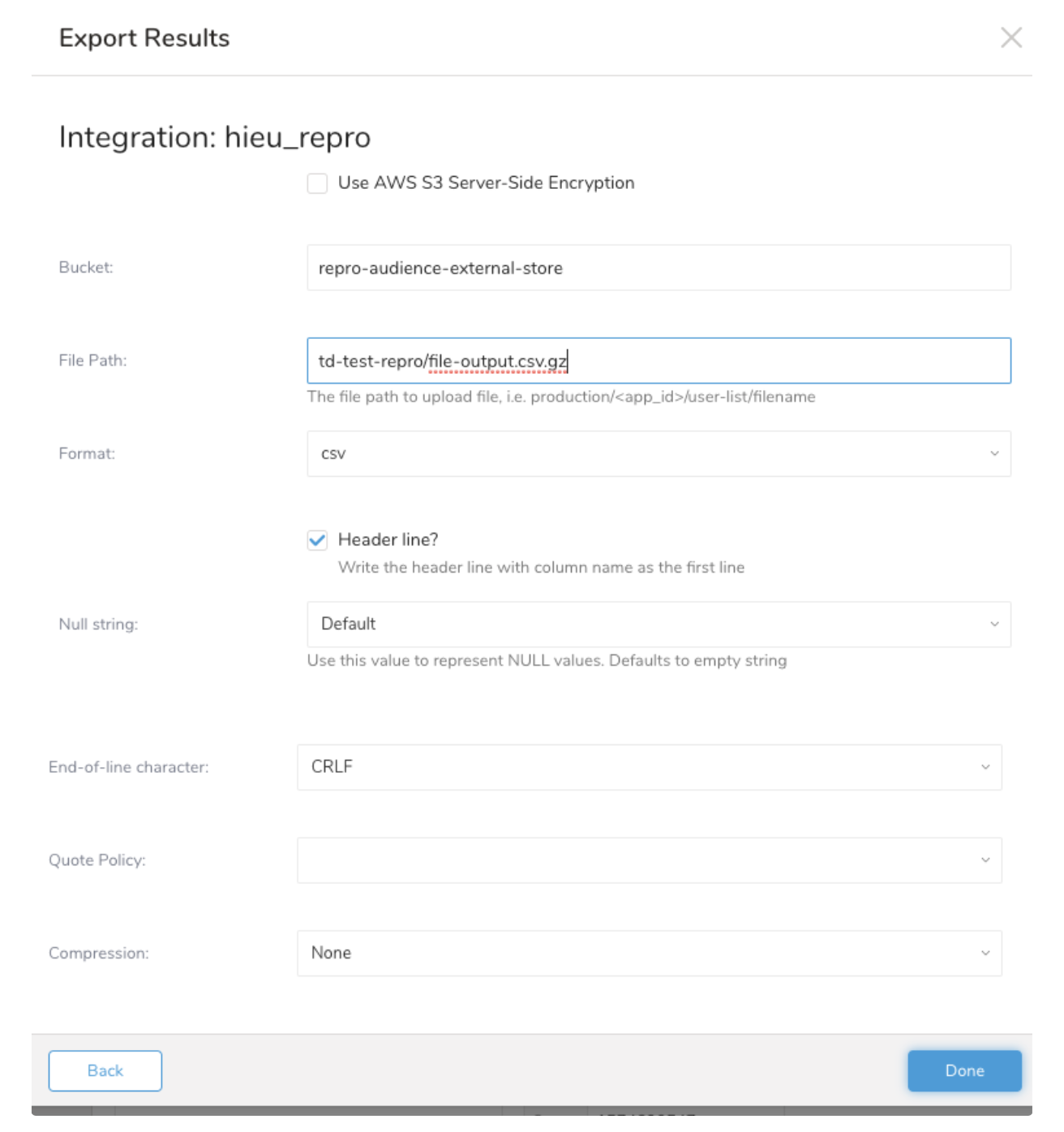
- 新しい接続に必要な認証情報を入力します。次のパラメータを設定します。
| パラメータ | 説明 |
|---|---|
| Use AWS S3 Server-Side Encryption (オプション) | S3サーバーサイド暗号化を使用する |
| Server-Side Encryption algorithm: (オプション) | 暗号化に使用されるアルゴリズム |
| Bucket (必須) | s3のバケット名 |
| File Path (必須) | ファイル名と拡張子を含むファイルのフルパス、例: production/<app_id>/user-list/filename.csv.gz |
| Format (必須) | ファイルをcsvにエクスポートする、ファイルパスに拡張子が必須 |
| Header line (必須) | エクスポートファイルの最初の行にカラム名を含める |
| Null String (オプション) | ファイル内のnullを置き換える値 |
| End-of-line character (オプション) | ファイル内で行末として記されるマーカー文字 |
| Quote Policy (必須) | ファイルの引用符ポリシー |
| Compression (必須) | - ファイルをgzで圧縮する、ファイルパスに拡張子が必須 - PGP Encryption - ファイルはアップロード前に公開鍵を使用して暗号化される |
| Public Key | - ファイルがアップロードされる前に暗号化するために使用される公開鍵 |
| Key Identifier | - ファイルを保護するために使用される暗号化サブキーのKey IDを指定します。マスターキーは暗号化プロセスから除外されます。 |
| Amor | - ASCII armorを使用するかどうか |
| Compression Type | - ファイルの圧縮に使用される圧縮アルゴリズムを定義します。ファイルはSFTPサーバーにアップロードするために暗号化前に圧縮されます。 - 注意: ファイルを暗号化してアップロードする前に圧縮してください。復号化すると、ファイルは.gzや.bz2などの圧縮形式に戻ります。 |
サンプル設定は次のとおりです:
Treasure Dataから、Repro用の接続にエクスポート結果を設定して次のクエリを実行します:
コード例
SELECT
an_email_column AS EMAIL,
another_phone_column AS PHONE
FROM
your_table;Scheduled Jobs と Result Export を使用して、指定したターゲット宛先に出力結果を定期的に書き込むことができます。
Treasure Data のスケジューラー機能は、高可用性を実現するために定期的なクエリ実行をサポートしています。
2 つの仕様が競合するスケジュール仕様を提供する場合、より頻繁に実行するよう要求する仕様が優先され、もう一方のスケジュール仕様は無視されます。
例えば、cron スケジュールが '0 0 1 * 1' の場合、「月の日」の仕様と「週の曜日」が矛盾します。前者の仕様は毎月 1 日の午前 0 時 (00:00) に実行することを要求し、後者の仕様は毎週月曜日の午前 0 時 (00:00) に実行することを要求するためです。後者の仕様が優先されます。
Data Workbench > Queries に移動します
新しいクエリを作成するか、既存のクエリを選択します。
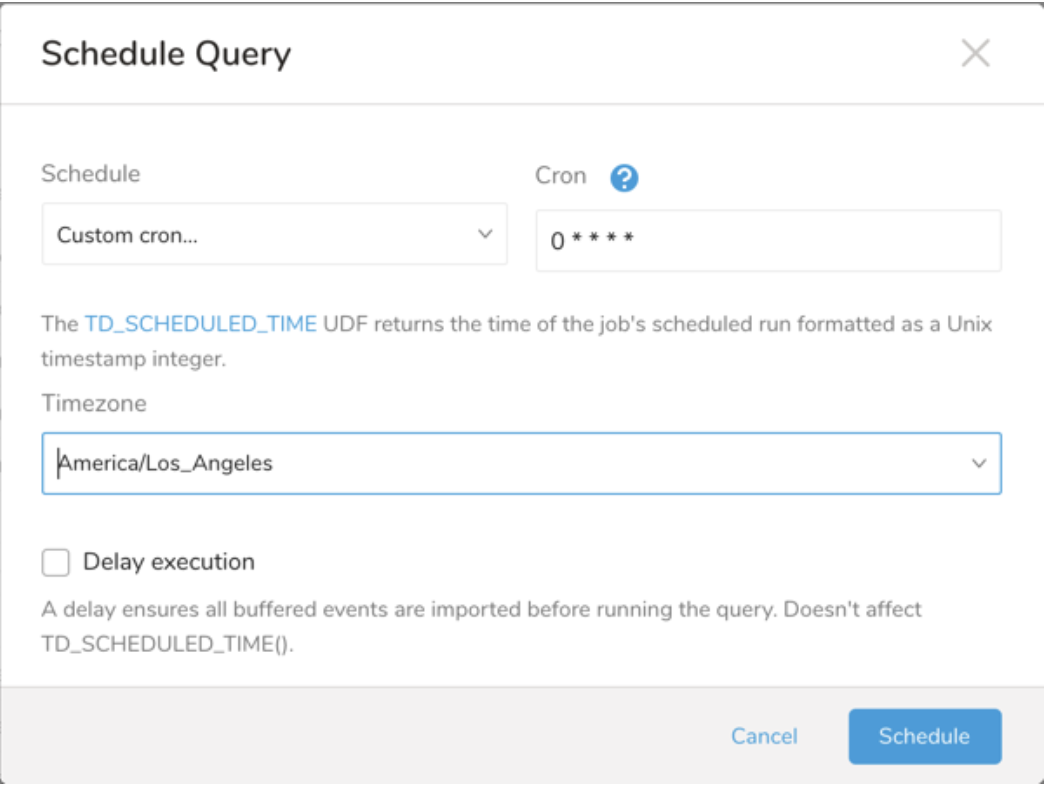
Schedule の横にある None を選択します。

ドロップダウンで、次のスケジュールオプションのいずれかを選択します:
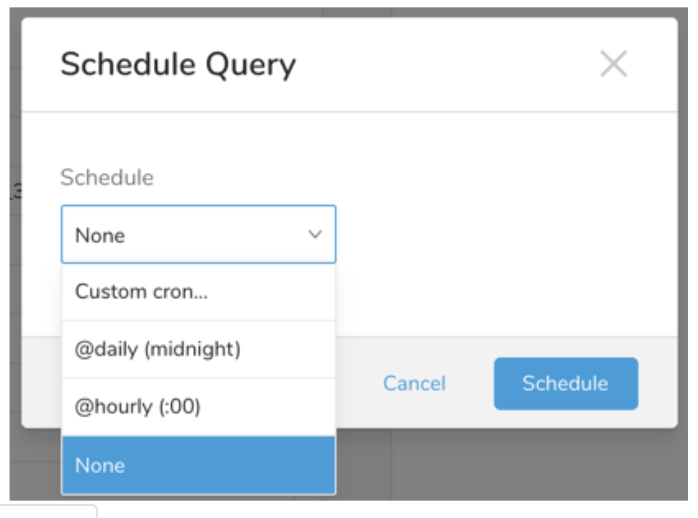
ドロップダウン値 説明 Custom cron... Custom cron... の詳細を参照してください。 @daily (midnight) 指定されたタイムゾーンで 1 日 1 回午前 0 時 (00:00 am) に実行します。 @hourly (:00) 毎時 00 分に実行します。 None スケジュールなし。
| Cron 値 | 説明 |
|---|---|
0 * * * * | 1 時間に 1 回実行します。 |
0 0 * * * | 1 日 1 回午前 0 時に実行します。 |
0 0 1 * * | 毎月 1 日の午前 0 時に 1 回実行します。 |
| "" | スケジュールされた実行時刻のないジョブを作成します。 |
* * * * *
- - - - -
| | | | |
| | | | +----- day of week (0 - 6) (Sunday=0)
| | | +---------- month (1 - 12)
| | +--------------- day of month (1 - 31)
| +-------------------- hour (0 - 23)
+------------------------- min (0 - 59)次の名前付きエントリを使用できます:
- Day of Week: sun, mon, tue, wed, thu, fri, sat.
- Month: jan, feb, mar, apr, may, jun, jul, aug, sep, oct, nov, dec.
各フィールド間には単一のスペースが必要です。各フィールドの値は、次のもので構成できます:
| フィールド値 | 例 | 例の説明 |
|---|---|---|
| 各フィールドに対して上記で表示された制限内の単一の値。 | ||
フィールドに基づく制限がないことを示すワイルドカード '*'。 | '0 0 1 * *' | 毎月 1 日の午前 0 時 (00:00) に実行するようにスケジュールを設定します。 |
範囲 '2-5' フィールドの許可される値の範囲を示します。 | '0 0 1-10 * *' | 毎月 1 日から 10 日までの午前 0 時 (00:00) に実行するようにスケジュールを設定します。 |
カンマ区切りの値のリスト '2,3,4,5' フィールドの許可される値のリストを示します。 | 0 0 1,11,21 * *' | 毎月 1 日、11 日、21 日の午前 0 時 (00:00) に実行するようにスケジュールを設定します。 |
周期性インジケータ '*/5' フィールドの有効な値の範囲に基づいて、 スケジュールが実行を許可される頻度を表現します。 | '30 */2 1 * *' | 毎月 1 日、00:30 から 2 時間ごとに実行するようにスケジュールを設定します。 '0 0 */5 * *' は、毎月 5 日から 5 日ごとに午前 0 時 (00:00) に実行するようにスケジュールを設定します。 |
'*' ワイルドカードを除く上記の いずれかのカンマ区切りリストもサポートされています '2,*/5,8-10' | '0 0 5,*/10,25 * *' | 毎月 5 日、10 日、20 日、25 日の午前 0 時 (00:00) に実行するようにスケジュールを設定します。 |
- (オプション) Delay execution を有効にすることで、クエリの開始時刻を遅延させることができます。
クエリに名前を付けて保存して実行するか、単にクエリを実行します。クエリが正常に完了すると、クエリ結果は指定された宛先に自動的にエクスポートされます。
設定エラーにより継続的に失敗するスケジュールジョブは、複数回通知された後、システム側で無効化される場合があります。
(オプション) Delay execution を有効にすることで、クエリの開始時刻を遅延させることができます。
Treasure Workflow内で、このデータコネクタを使用してデータをエクスポートするように指定できます。
timezone: UTC
_export:
td:
database: sample_datasets
+td-result-into-target:
td>: queries/sample.sql
result_connection: your_connections_name
result_settings:
type: repro
bucket: bucket_name
region: ap-northeast-2
use_sse: true
sse_algorithm: AES256
auth_method: basic
session_token: session_token
path: /td-export-repro/file_output.csv
access_key_id: access_id
secret_access_key: secret_key
formatter: {type: csv, delimiter: "\t", newline: CRLF, newline_in_field: LF, charset: UTF-8,
quote_policy: MINIMAL, quote: '"', escape: \, null_string: \N, default_timezone: UTC}
encoders: {type: gzip}ワークフローでデータコネクタを使用してデータをエクスポートする方法の詳細については、こちらをクリックしてください。
- Embulk-encoder-Encryptionドキュメント: Embulk Encoder Encryption PGP