Repro Export Integrationの詳細はこちらをご覧ください。
Repro Import Integrationを使用して、カスタマイズされたパラメータでAmazon S3バケットからファイルを取り込み、簡単に設定できます。
- TD Toolbeltを含むTreasure Dataの基礎知識。
- Reproアプリケーション ID、アクセスキー ID、およびシークレットアクセスキー。
- ファイル名パターンを入力し、Incremental?を選択した場合、データは読み込まれません。Reproは古いフォルダにデータを配置せず、毎回新しいフォルダを作成するため、データが読み込まれません。
データ接続を作成する際は、統合にアクセスするための認証を提供する必要があります。Treasure Dataで認証を設定してから、ソース情報を指定します。
- TD Consoleを開きます。
- Integrations Hub > Catalogに移動します。
- Reproを検索して選択します。

次のダイアログが開きます:
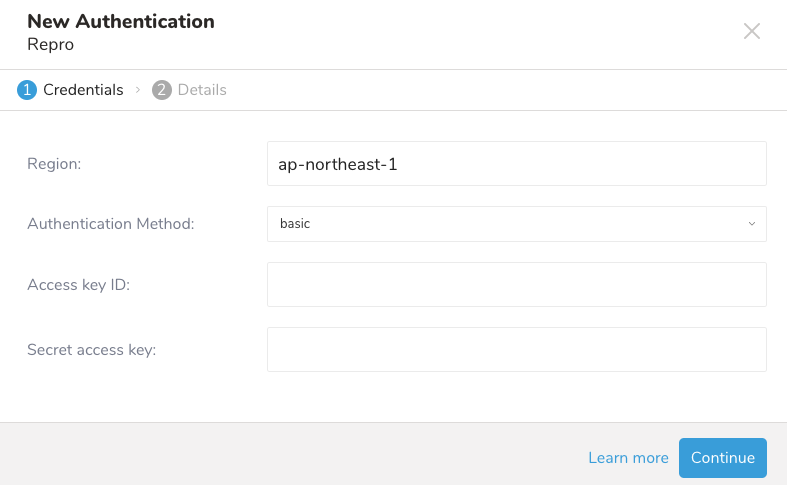 4. 必要な情報を入力します:
4. 必要な情報を入力します:
- Region: Reproアプリケーションのリージョン(例: ap-northeast-1、us-east-1など)
- Authentication Method: basicを選択します。
- Access key ID: Reproから取得したキーを入力します。
- Secret access key: Reproから取得したシークレットアクセスキーを入力します。
- Continueを選択します。
- 接続の名前を入力します。
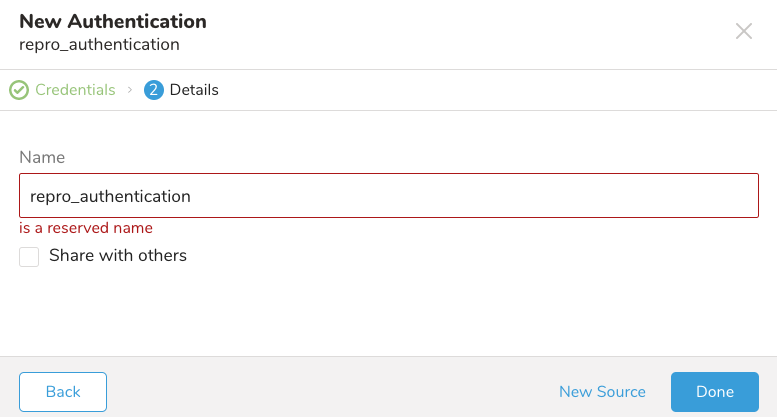 7. Doneを選択します。
7. Doneを選択します。
認証済み接続を作成すると、自動的にAuthenticationsに移動します。
- 作成した接続を検索します。
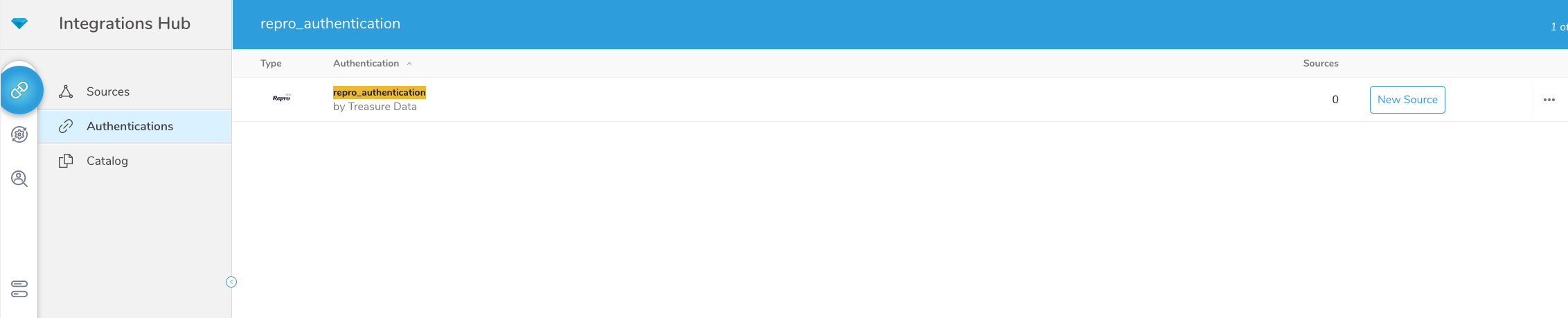 2. New Sourceを選択します。
2. New Sourceを選択します。
- Data TransferフィールドにSourceの名前を入力します**。**
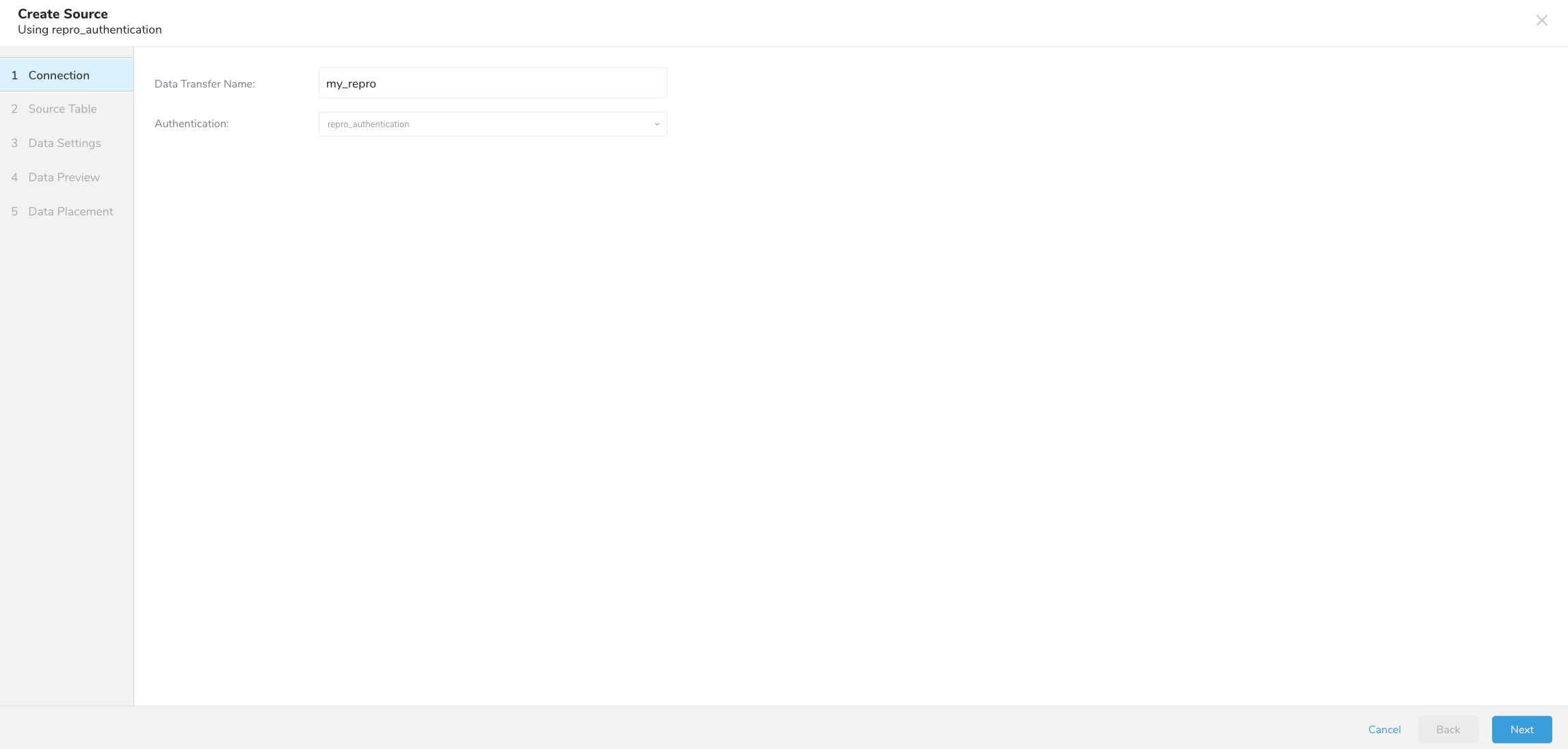 2. Nextを選択します。
2. Nextを選択します。
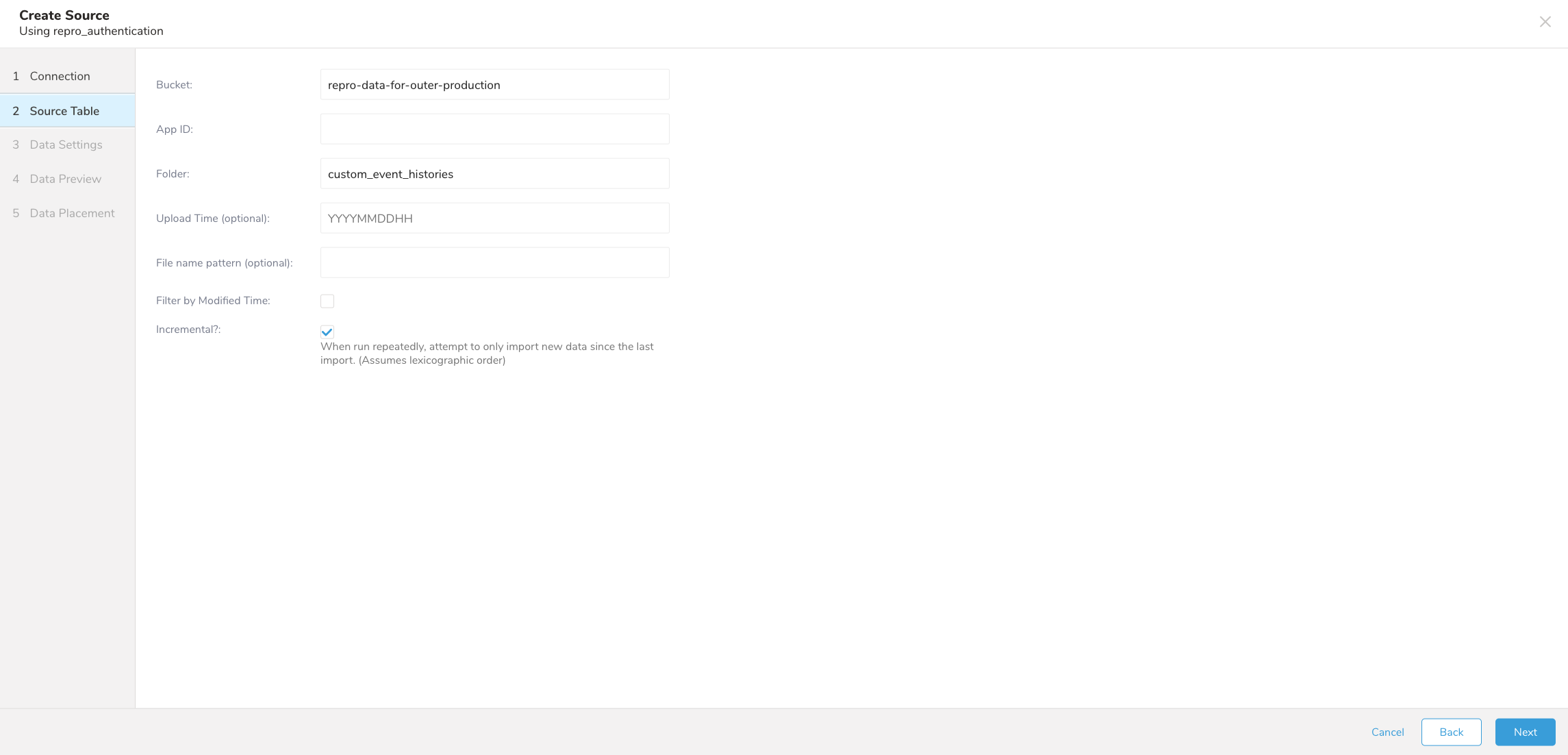
- ソーステーブルで次のパラメータを編集します。
| パラメータ | 説明 |
|---|---|
| Bucket | Reproアプリケーションが配置されているバケット。例: repro-data-for-outer-production |
| App ID | ReproアプリケーションID。 |
| Upload Time | データを取り込む特定の時間(YYYYMMDDHH形式)。 |
| Filename pattern | 正規表現を使用してファイルパスをマッチさせます。ファイルパスが指定されたパターンと一致しない場合、そのファイルはスキップされます。例えば、パターン .csv$ # を指定すると、パスがパターンと一致しないファイルはスキップされます。正規表現の詳細をご覧ください。 |
| Filter by Modified Time | 更新時刻をデータ読み込みの主要な基準として使用する場合に選択します。 |
| Insert these parameters so that the first executions skip files that were modified before that specified timestamp. For example, 2019-06-03T10:30:19.806Z. | これらのパラメータを挿入すると、最初の実行で指定されたタイムスタンプより前に変更されたファイルがスキップされます。例: 2019-06-03T10:30:19.806Z |
| Incremental by Modified Time (Filter by Modified Timeを選択した場合に利用可能) | 前回の取り込み以降の新しいデータのみを取り込む場合に選択します。 |
| Incremental? (Filter by Modified Timeを選択した場合に利用可能) | 前回の取り込み以降の新しいデータのみを取り込む場合に選択します。 |
- Nextを選択します。 Data Settingsページが開きます。
- 必要に応じてデータ設定を編集するか、このページをスキップします。
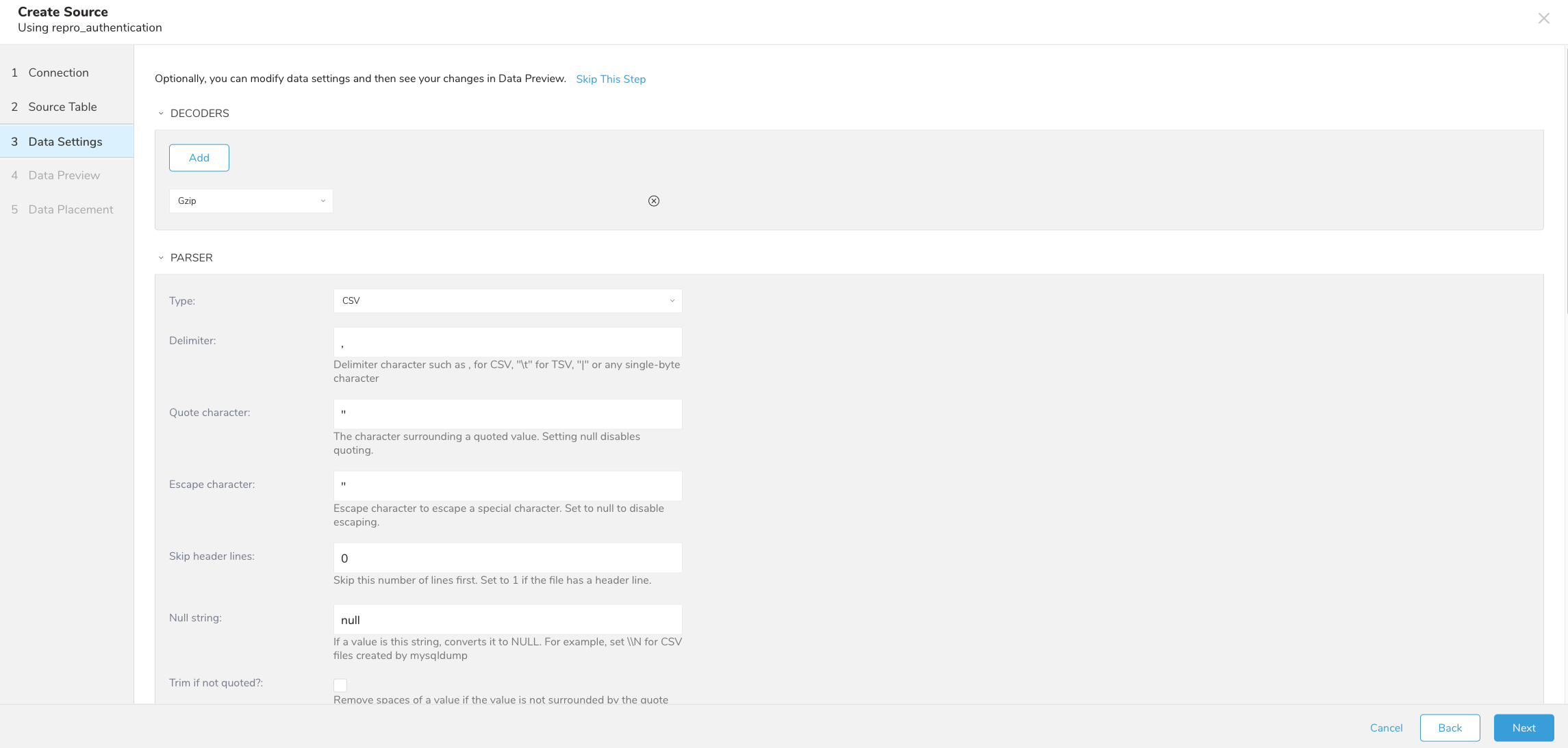
インポートを実行する前に、Generate Preview を選択してデータのプレビューを表示できます。Data preview はオプションであり、選択した場合はダイアログの次のページに安全にスキップできます。
- Next を選択します。Data Preview ページが開きます。
- データをプレビューする場合は、Generate Preview を選択します。
- データを確認します。
データの配置について、データを配置したいターゲット database と table を選択し、インポートを実行する頻度を指定します。
Next を選択します。Storage の下で、インポートされたデータを配置する新しい database を作成するか、既存の database を選択し、新しい table を作成するか、既存の table を選択します。
Database を選択 > Select an existing または Create New Database を選択します。
オプションで、database 名を入力します。
Table を選択 > Select an existing または Create New Table を選択します。
オプションで、table 名を入力します。
データをインポートする方法を選択します。
- Append (デフォルト) - データインポートの結果は table に追加されます。 table が存在しない場合は作成されます。
- Always Replace - 既存の table の全体の内容をクエリの結果出力で置き換えます。table が存在しない場合は、新しい table が作成されます。
- Replace on New Data - 新しいデータがある場合のみ、既存の table の全体の内容をクエリの結果出力で置き換えます。
Timestamp-based Partition Key 列を選択します。 デフォルトキーとは異なるパーティションキーシードを設定したい場合は、long または timestamp 列をパーティショニング時刻として指定できます。デフォルトの時刻列として、add_time フィルターで upload_time を使用します。
データストレージの Timezone を選択します。
Schedule の下で、このクエリを実行するタイミングと頻度を選択できます。
- Off を選択します。
- Scheduling Timezone を選択します。
- Create & Run Now を選択します。
- On を選択します。
- Schedule を選択します。UI では、@hourly、@daily、@monthly、またはカスタム cron の 4 つのオプションが提供されます。
- Delay Transfer を選択して、実行時間の遅延を追加することもできます。
- Scheduling Timezone を選択します。
- Create & Run Now を選択します。
転送が実行された後、Data Workbench > Databases で転送の結果を確認できます。