Riak CS用のData Connectorは、Riak CSバケットに保存されている*.tsvおよび*.csvファイルの内容のインポートを可能にします。
- Treasure Dataの基本知識
Riak CSの接続を設定するには:
- Treasure Data consoleで、Integration Hub > Catalog**に移動します。
- Catalog画面の右端にある検索アイコンをクリックし、Riakと入力します。
- RiakCS connectorの上にカーソルを置き、Create Authenticationを選択します。

- 以下のパラメータを設定します:
- Endpoint
- Authentication Method
- Access key ID
- Secret access key
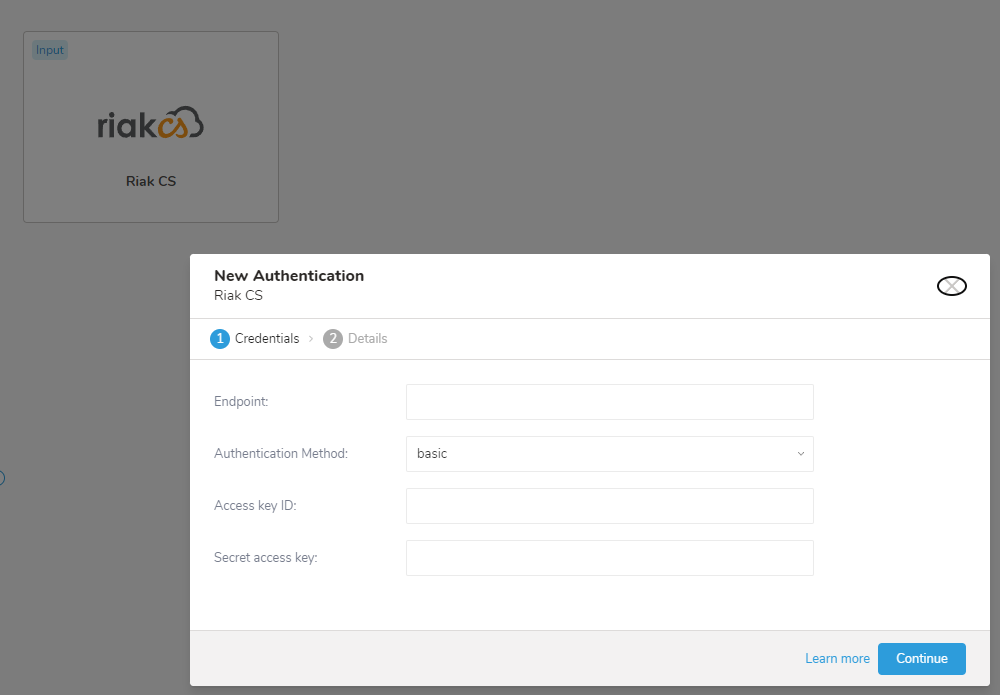
- 必要な接続の詳細を入力した後、Continueを選択します。
- 接続に名前を付けて、後で接続の詳細を変更する必要がある場合に見つけられるようにします。
- この接続を組織内の他のユーザーと共有したい場合は、Share with othersチェックボックスをチェックします。このボックスがチェックされていない場合、この接続は自分だけに表示されます。
- Create Connectionを選択して接続を完了します。
作成した接続が、指定した名前で接続のリストに表示されます。
You can see a preview of your data before running the import by selecting Generate Preview. Data preview is optional and you can safely skip to the next page of the dialog if you choose to.
- Select Next. The Data Preview page opens.
- If you want to preview your data, select Generate Preview.
- Verify the data.
For data placement, select the target database and table where you want your data placed and indicate how often the import should run.
Select Next. Under Storage, you will create a new or select an existing database and create a new or select an existing table for where you want to place the imported data.
Select a Database > Select an existing or Create New Database.
Optionally, type a database name.
Select a Table> Select an existing or Create New Table.
Optionally, type a table name.
Choose the method for importing the data.
- Append (default)-Data import results are appended to the table. If the table does not exist, it will be created.
- Always Replace-Replaces the entire content of an existing table with the result output of the query. If the table does not exist, a new table is created.
- Replace on New Data-Only replace the entire content of an existing table with the result output when there is new data.
Select the Timestamp-based Partition Key column. If you want to set a different partition key seed than the default key, you can specify the long or timestamp column as the partitioning time. As a default time column, it uses upload_time with the add_time filter.
Select the Timezone for your data storage.
Under Schedule, you can choose when and how often you want to run this query.
- Select Off.
- Select Scheduling Timezone.
- Select Create & Run Now.
- Select On.
- Select the Schedule. The UI provides these four options: @hourly, @daily and @monthly or custom cron.
- You can also select Delay Transfer and add a delay of execution time.
- Select Scheduling Timezone.
- Select Create & Run Now.
After your transfer has run, you can see the results of your transfer in Data Workbench > Databases.
最新のTreasure Data Toolbeltをインストールします。
$ td --version
0.11.10以下のようにseed.ymlを準備し、AWSアクセスキーとシークレットアクセスキーを設定します。バケット名とターゲットファイル名(または複数ファイルのプレフィックス)も指定する必要があります。
in:
type: riak_cs
access_key_id: XXXXXXXXXX
secret_access_key: YYYYYYYYYY
bucket: sample_bucket
path_prefix: path/to/sample_file # path the the *.csv or *.tsv file on your Riak CS bucket
endpoint: host
out:
mode: appendRiak CS用のData Connectorは、指定されたプレフィックスと一致するすべてのファイルをインポートします。(例: path_prefix: path/to/sample_ –> path/to/sample_201501.csv.gz, path/to/sample_201502.csv.gz, …, path/to/sample_201505.csv.gz)
利用可能なoutモードの詳細については、Appendixを参照してください。
connector:guessを使用します。このコマンドは自動的にターゲットファイルを読み取り、ファイル形式をインテリジェントに推測します。
$ td connector:guess seed.yml -o load.ymlload.ymlを開くと、ファイル形式、エンコーディング、列名、および型を含む推測されたファイル形式定義が表示されます。
in:
type: riak_cs
access_key_id: XXXXXXXXXX
secret_access_key: YYYYYYYYYY
bucket: sample_bucket
path_prefix: path/to/sample_file
endpoint: host
parser:
charset: UTF-8
newline: CRLF
type: csv
delimiter: ','
quote: '"'
escape: ''
skip_header_lines: 1
columns:
- name: id
type: long
- name: company
type: string
- name: customer
type: string
- name: created_at
type: timestamp
format: '%Y-%m-%d %H:%M:%S'
out:
mode: append次に、previewコマンドを使用して、システムがファイルをどのように解析するかをプレビューできます。
$ td connector:preview load.yml
+-------+---------+----------+---------------------+
| id | company | customer | created_at |
+-------+---------+----------+---------------------+
| 11200 | AA Inc. | David | 2015-03-31 06:12:37 |
| 20313 | BB Imc. |Tom | 2015-04-01 01:00:07 |
| 32132 | CC Inc. | Fernando | 2015-04-01 10:33:41 |
| 40133 | DD Inc. | Cesar | 2015-04-02 05:12:32 |
| 93133 | EE Inc. | Jake | 2015-04-02 14:11:13 |
+-------+---------+----------+---------------------+guessコマンドは、ソースデータファイルに3行以上、2列以上が必要です。ソースデータのサンプル行を使用して列定義を推測するためです。 | システムが列名または列タイプを予期せず検出した場合は、load.ymlを直接変更して再度プレビューしてください。
Data Connectorは、"boolean"、"long"、"double"、"string"、および"timestamp"タイプの解析をサポートしています。
また、ロードジョブを実行する前に、ローカルデータベースとテーブルを作成しておく必要があります。 これを行うには、以下のコマンドを実行します。
$ td database:create td_sample_db
$ td table:create td_sample_db td_sample_tableロードジョブを送信します。データのサイズによっては数時間かかる場合があります。ユーザーは、データが保存されているデータベースとテーブルを指定する必要があります。
Treasure Dataのストレージは時間でパーティション化されているため(data partitioningも参照)、--time-columnオプションを指定することをお勧めします。オプションが指定されていない場合、Data Connectorは最初のlongまたはtimestamp列をパーティション化時刻として選択します。--time-columnで指定された列のタイプは、longまたはtimestampタイプのいずれかである必要があります。
データに時刻列がない場合は、add_timeフィルターオプションを使用して追加できます。詳細については、add_time filter pluginを参照してください。
$ td connector:issue load.yml --database td_sample_db --table td_sample_table --time-column created_at上記のコマンドは、すでに*database(td_sample_db)とtable(td_sample_table)*を作成していることを前提としています。データベースまたはテーブルがTDに存在しない場合、このコマンドは成功しないため、データベースとテーブルを手動で作成するか、td connector:issueコマンドで--auto-create-tableオプションを使用してデータベースとテーブルを自動作成します:
$ td connector:issue load.yml --database td_sample_db --table td_sample_table --time-column created_at --auto-create-table現在、Data Connectorはサーバー側でレコードをソートしません。時間ベースのパーティショニングを効果的に使用するには、事前にファイル内のレコードをソートしてください。
timeというフィールドがある場合は、--time-columnオプションを指定する必要はありません。
$ td connector:issue load.yml --database td_sample_db --table td_sample_tableseed.ymlのoutセクションでファイルインポートモードを指定できます。
in:
...
out:
mode: appendこれはデフォルトモードです。インポートされたレコードはターゲットテーブルに追加されます。
in:
...
out:
mode: replaceターゲットテーブルがすでに存在する場合、既存のテーブルの行はインポートされたレコードで置き換えられます。
インクリメンタルRiak CSファイルインポートのために、定期的なData Connector実行をスケジュールできます。高可用性を確保するため、スケジューラーは慎重に管理されています。この機能を使用することで、ローカルデータセンターでcronデーモンを実行する必要がなくなります。
スケジュールされたインポートの場合、Riak CS用のData Connectorは、最初に指定されたプレフィックスと一致するすべてのファイルをインポート(例: path_prefix: path/to/sample_ –> path/to/sample_201501.csv.gz, path/to/sample_201502.csv.gz, …, path/to/sample_201505.csv.gz)し、次回の実行のために最後のパス(path/to/sample_201505.csv.gz)を記憶します。
2回目以降の実行では、アルファベット順(辞書順)で最後のパスの後に来るファイルのみをインポートします。(path/to/sample_201506.csv.gz, …)
新しいスケジュールは、td connector:createコマンドを使用して作成できます。以下が必要です: スケジュールの名前、cronスタイルのスケジュール、データが保存されるデータベースとテーブル、およびデータコネクタ設定ファイル。
$ td connector:create \
daily_import \
"10 0 * * *" \
td_sample_db \
td_sample_table \
load.ymlTDストレージは時間でパーティション化されているため(data partitioningも参照)、--time-columnオプションを指定することをお勧めします。
$ td connector:create \
daily_import \
"10 0 * * *" \
td_sample_db \
td_sample_table \
load.yml \
--time-column created_atcronパラメータは、3つの特別なオプションも受け入れます: @hourly、@daily、@monthly。 | デフォルトでは、スケジュールはUTCタイムゾーンで設定されます。-tまたは--timezoneオプションを使用して、タイムゾーンでスケジュールを設定できます。--timezoneオプションは、'Asia/Tokyo'、'America/Los_Angeles'などの拡張タイムゾーン形式のみをサポートします。PST、CSTなどのタイムゾーンの略語は*サポートされておらず*、予期しないスケジュールにつながる可能性があります。
コマンドtd connector:listを実行することで、現在スケジュールされているエントリのリストを確認できます。
$ td connector:listtd connector:showは、スケジュールエントリの実行設定を表示します。
td connector:show daily_importtd connector:historyは、スケジュールエントリの実行履歴を表示します。個々の実行の結果を調査するには、td job jobidを使用します。
td connector:history daily_importtd connector:deleteは、スケジュールを削除します。
$ td connector:delete daily_importseed.ymlのoutセクションでファイルインポートモードを指定できます。
これはデフォルトモードで、レコードはターゲットテーブルに追加されます。
in:
...
out:
mode: appendこのモードは、ターゲットテーブルのデータを置き換えます。ターゲットテーブルに対して行われた手動のスキーマ変更は、このモードでもそのまま残ります。
in:
...
out:
mode: replace