DataRobotインテグレーションを使用して、インタラクティブにデータを取得します。Treasure Dataは、DataRobotで行われるデータモデリングのデータソースとして機能します。
DataRobotは、データサイエンスを民主化し、AIの構築、デプロイ、および大規模な保守のエンドツーエンドプロセスを自動化します。最新のオープンソースアルゴリズムによって強化され、クラウド、オンプレミス、または完全に管理されたAIサービスとして利用可能なDataRobotを使用すると、AIを活用してより良いビジネス成果を実現できます。
DataRobotのData Connections設定でTD-Hive JDBCドライバーまたはTrino JDBCドライバー設定を構成し、Add new data connectionを選択します。Hiveを使用する場合は、Treasure Dataを選択してください。Trinoを使用する場合は、Trinoを選択してください。
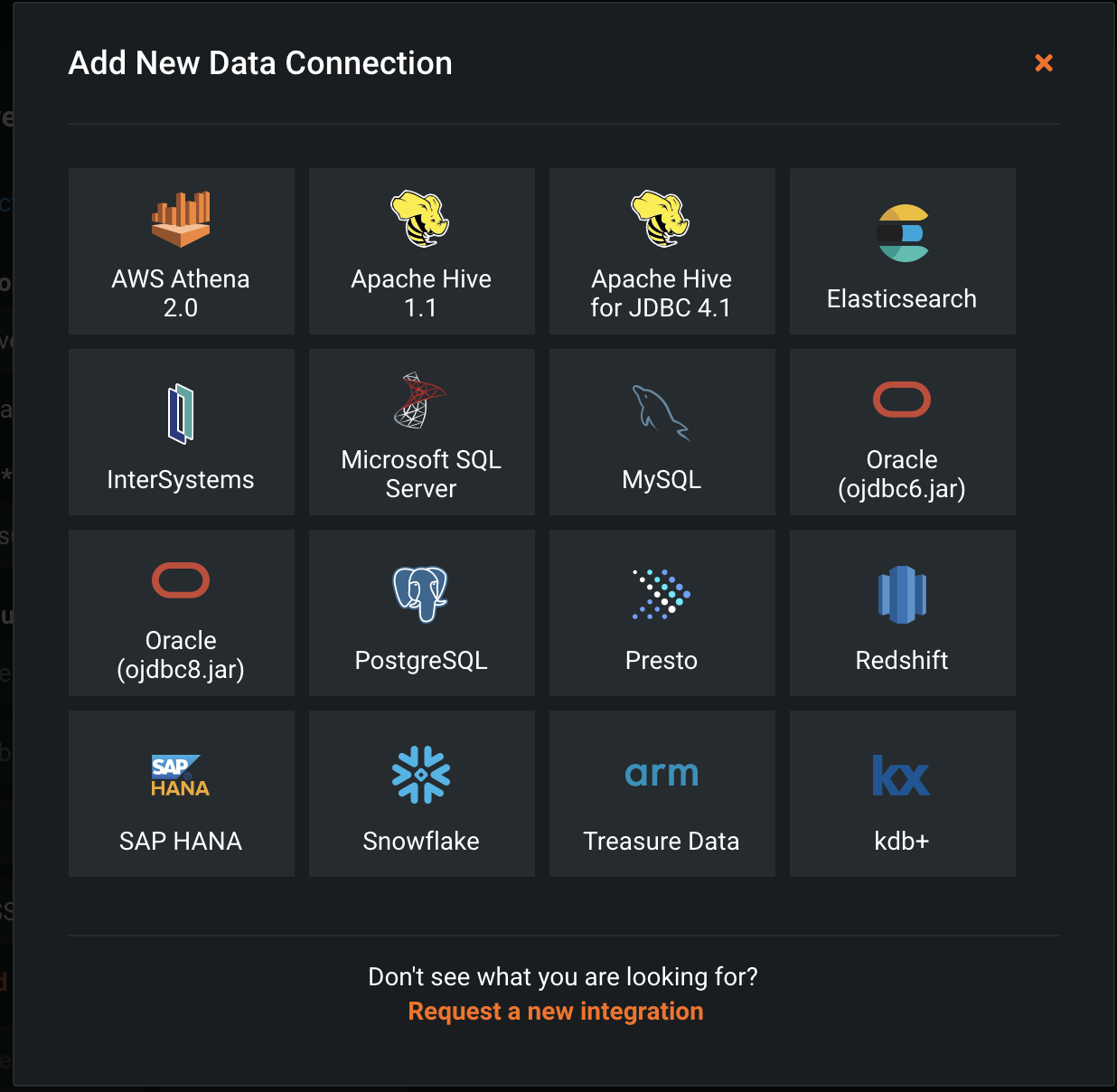
**URL(Advanced)**を選択します。
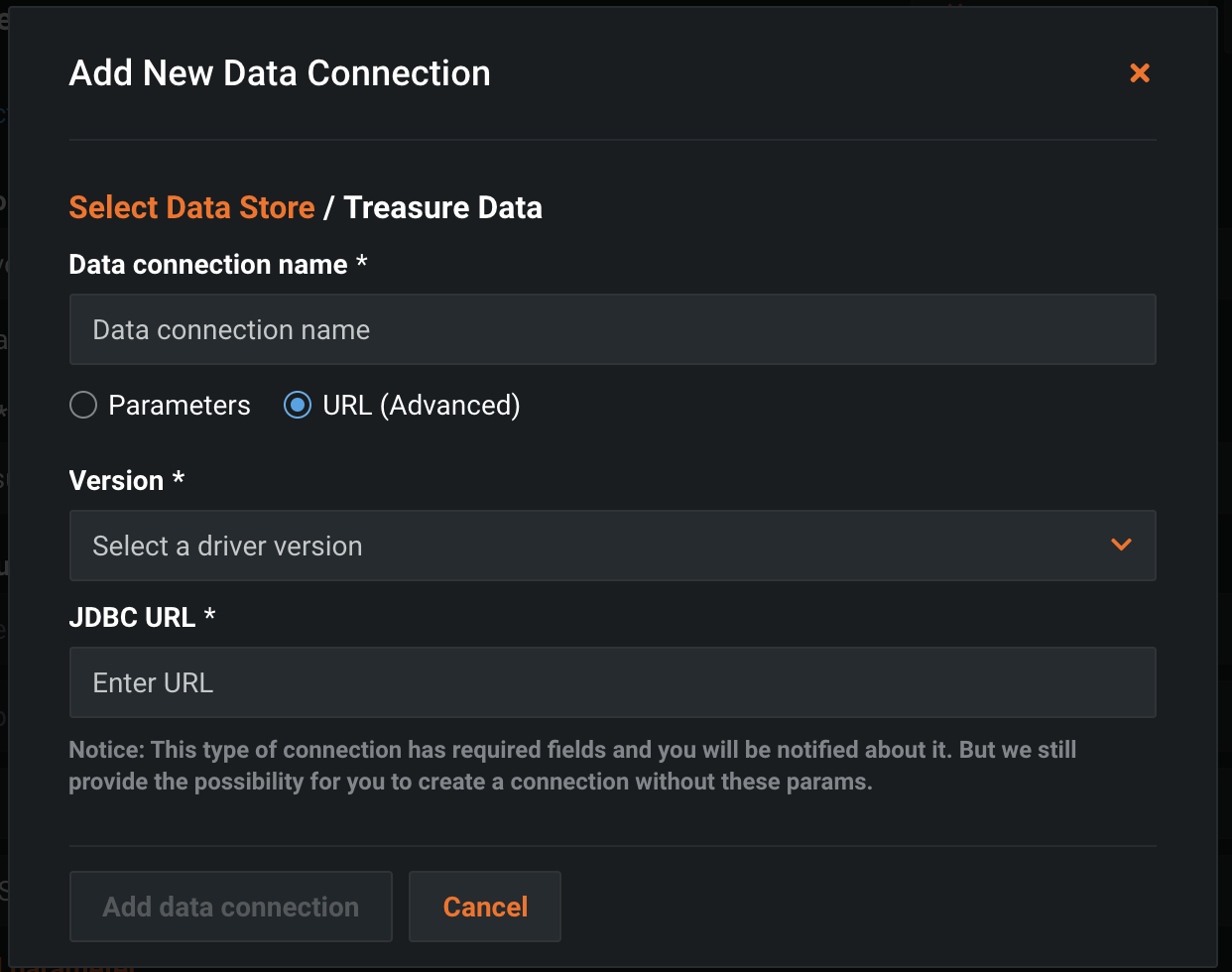
Data connection nameとJDBC URLを入力します。Treasure Dataの場合、接続URLはデータベース名です。Treasure Dataのデータベース名に合わせて接続URLを変更する必要があります。以下は、USリージョンのエンドポイントに接続する例です。
- Trino:
jdbc:trino://api-presto.treasuredata.com:443/td/(database name)?SSL=true - Hive:
jdbc:td://api.treasuredata.com/(database_name);useSSL=true;type=hive
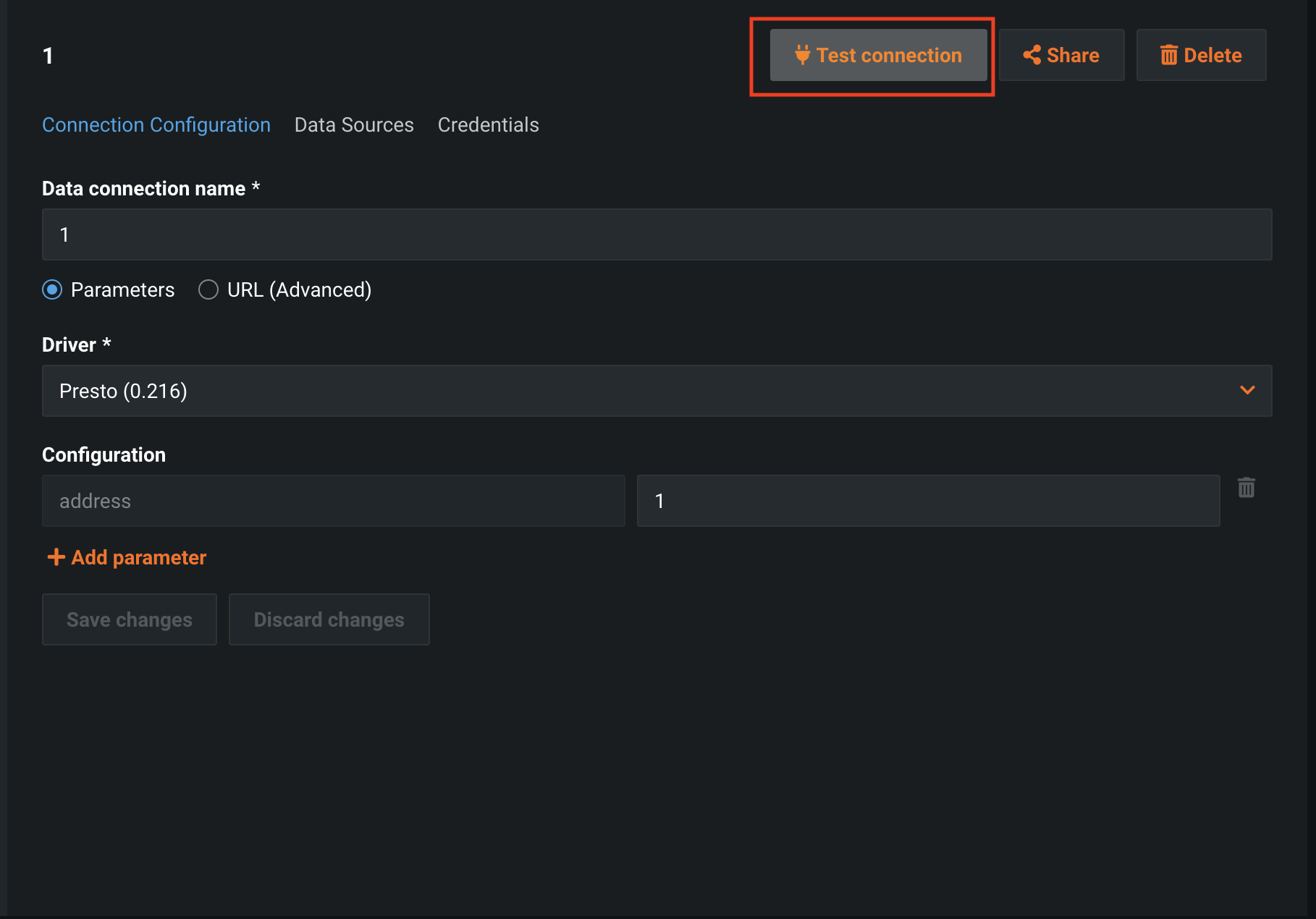
データ接続を作成した後、Test connectionを選択して接続をテストします。
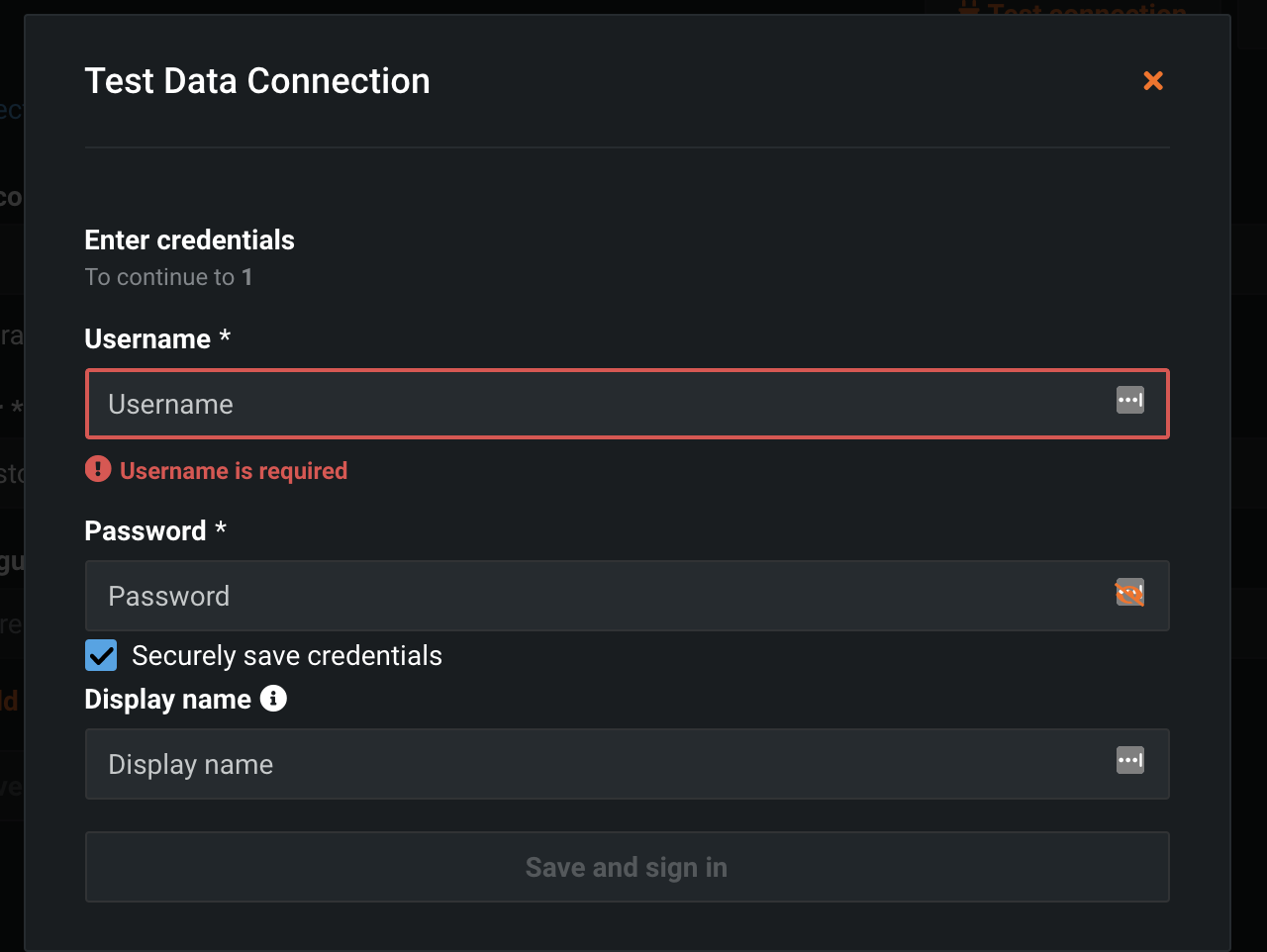
認証情報には、以下の情報を入力します。
- Trino: UsernameにTreasure DataのMaster API keyを入力し、Passwordにダミー文字列を入力します。
- Hive: Treasure Dataのログインメールアドレスとログインパスワードを入力します。
これで、DataRobotをTreasure Dataと組み合わせてbatch prediction modeを構築する準備が整いました。
DataRobotによる予測結果をTreasure Dataにエクスポートしたい場合は、DataRobot Pythonクライアントとcustom script機能を備えたTreasure Workflowを使用できます。
このインテグレーションの使用に興味がある場合は、サポートにお問い合わせください。