このデータコネクタを使用すると、Databricksから Treasure Data にデータをインポートできます。
- Treasure Data の基本的な知識とTreasure Data アカウントへのアクセス権
- Databricks の基本的な知識とDatabricks アカウントへのアクセス権
- Databricks サーバーへのアクセス権
- Databricks サーバーが休止モードの場合、起動に数分かかることがあり、コネクタがタイムアウトする可能性があります。
- Databricks の Web サイトにログインします。
- SQL タブに移動し、SQL Warehouses を選択します。
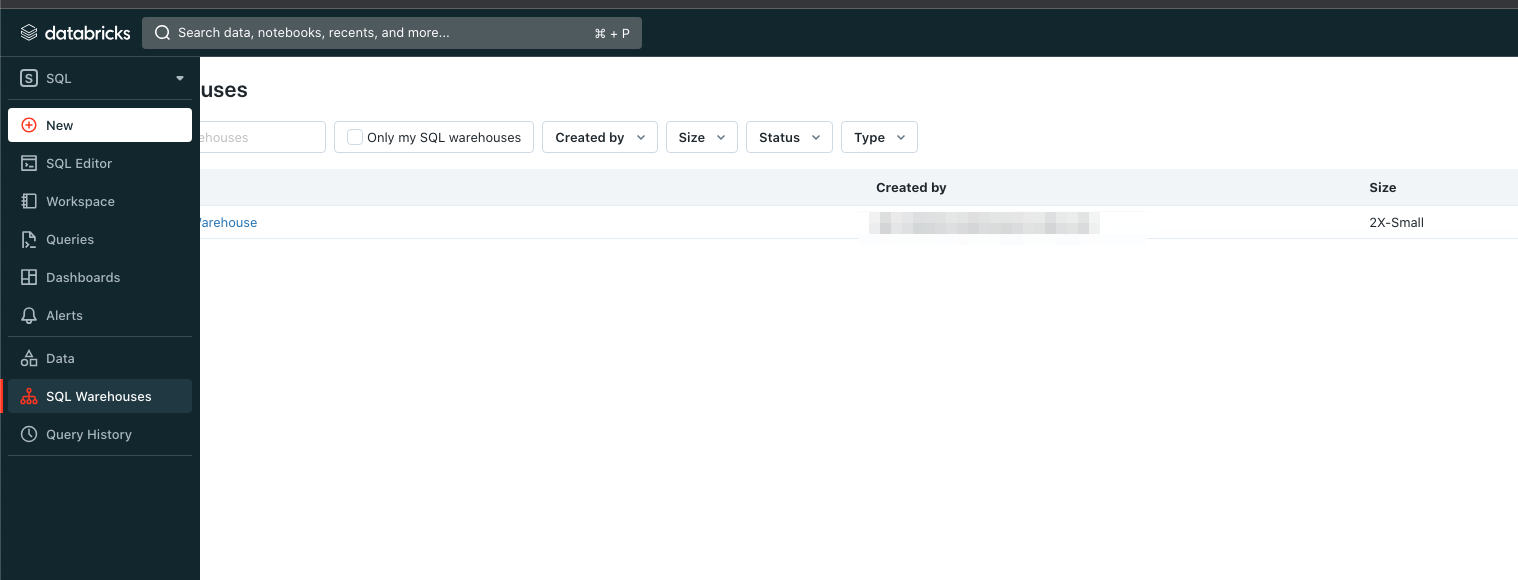 3. SQL Warehouse のインスタンスを選択します。
3. SQL Warehouse のインスタンスを選択します。
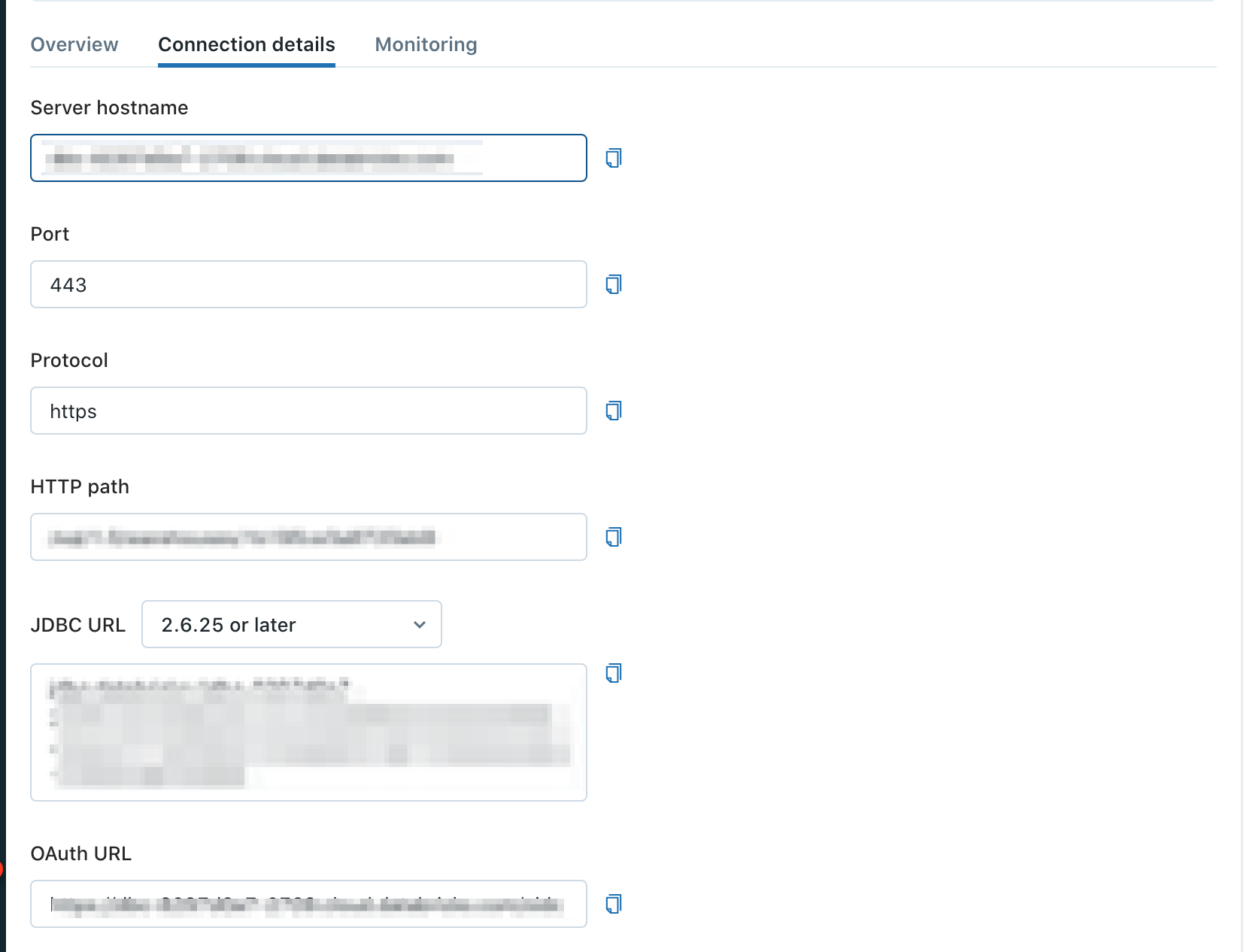
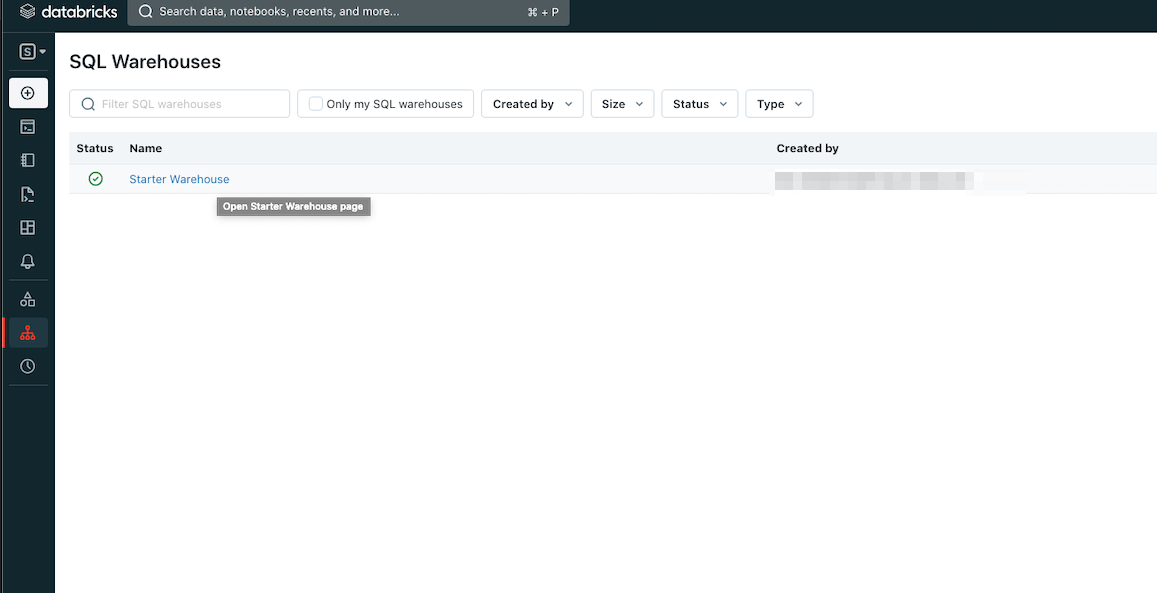 4. Connection details タブを選択します。 5. SQL Warehouse のServer hostname とHTTP path をメモします。
4. Connection details タブを選択します。 5. SQL Warehouse のServer hostname とHTTP path をメモします。
最初のステップは、認証情報のセットを使用して新しい認証を作成することです。
- Integrations Hub > Catalog を選択します。
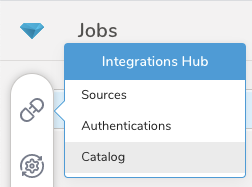
- カタログで databricks を検索します。
- アイコンの上にマウスを移動し、Create Authentication を選択します。
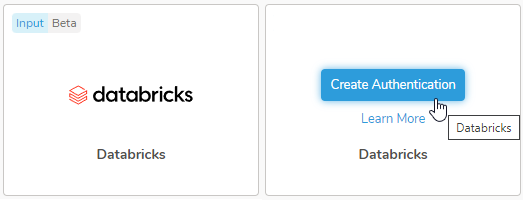
- Credentials タブが選択されていることを確認し、統合の認証情報を入力します。
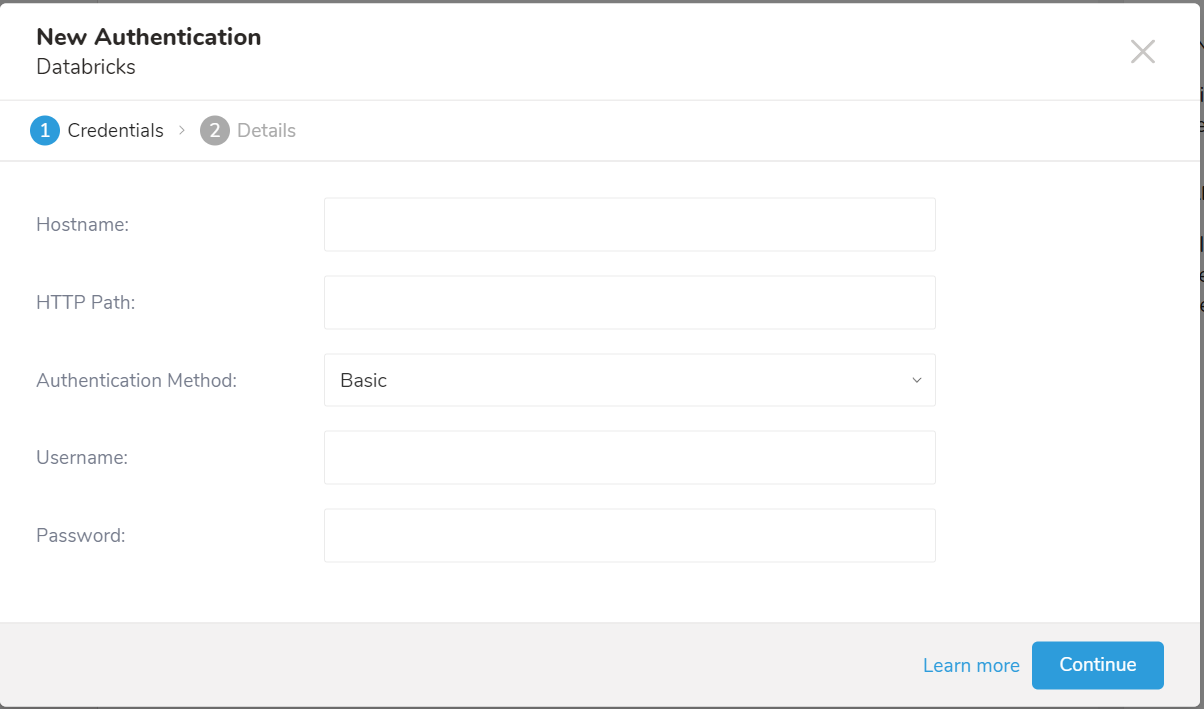
| パラメータ | 説明 |
|---|---|
| Hostname | Databricks インスタンスのホスト名です。 |
| HTTP Path | Databricks インスタンスのHTTP パスです。 |
| Authentication Method | 認証方法です。Basic または Personal Access Token を選択できます。 |
| Username | ログインに使用するユーザー名です。Authentication Method が Basic の場合にのみ有効です。 |
| Password | ログインに使用するパスワードです。Authentication Method が Basic の場合にのみ有効です。 |
| Token | Databricks パーソナルアクセストークンです。Authentication Method が Personal Access Token の場合にのみ有効です。 |
- Continue を選択します。
- 認証の名前を入力し、Done を選択します。
- TD Console を開きます。
- Integrations Hub > Authentications に移動します。
- 新しい認証を見つけて、New Source を選択します。
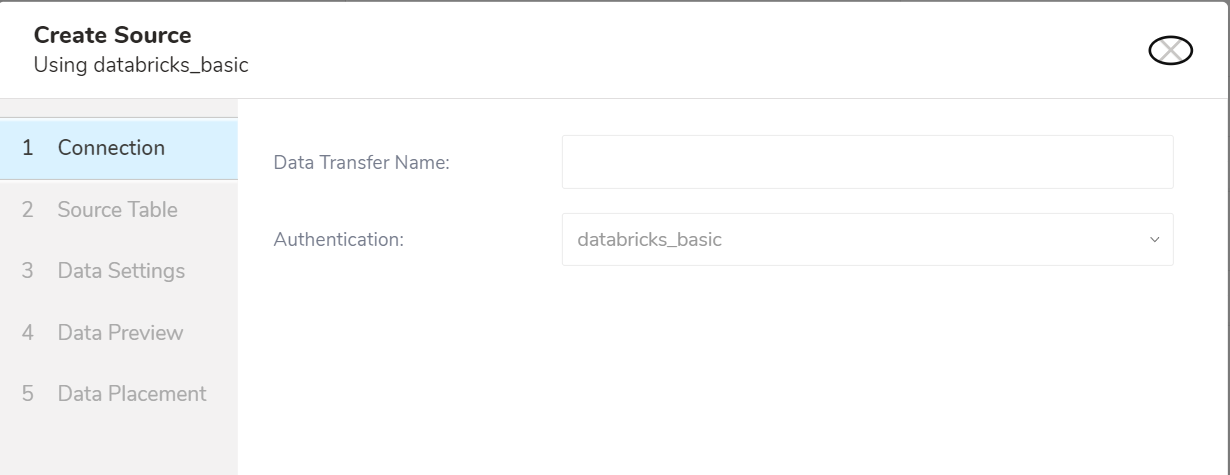
- Data Transfer Name フィールドにソース名を入力します。
- Next を選択します。
| パラメータ | 説明 |
|---|---|
| Data Transfer Name | データ転送ソースの名前です。 |
| Authentication | 使用する認証の名前です。 |
Source Table タブが選択された状態で Create Source ページが表示されます。
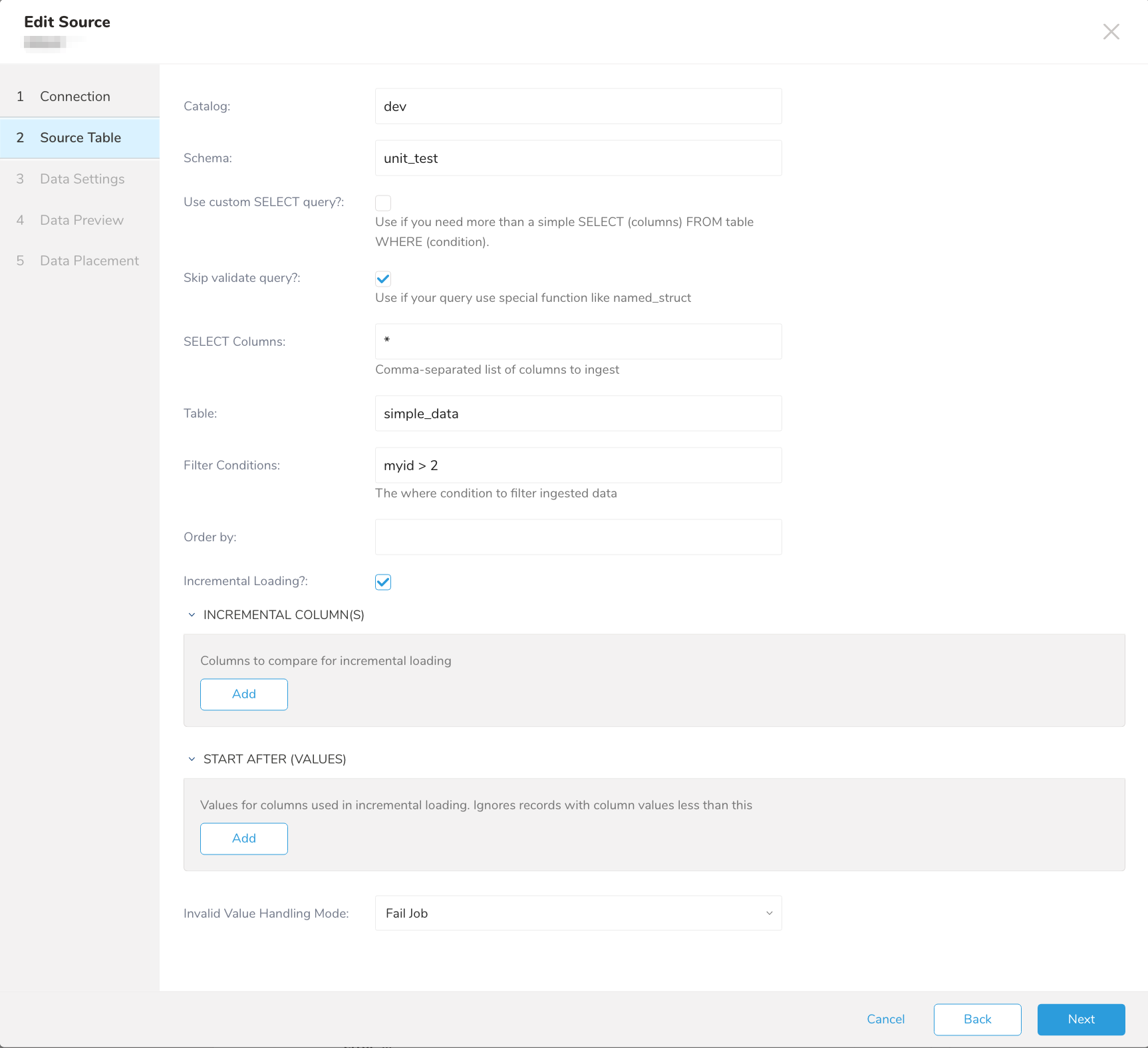
| パラメータ | 説明 |
|---|---|
| Catalog | データセットカタログです。 |
| Schema | データセットスキーマです。 |
| Use custom SELECT query? | カスタムクエリを構築する場合はチェックボックスを選択し、クエリを作成する場合はフィールドに入力します。 |
| Skip validate query? | クエリの構文検証をスキップします |
| Select Columns | データセットから選択する列を定義します。screen-shotUse custom SELECT queryscreen-shot が選択されていない場合にのみ必要です。 |
| Table | 選択するテーブルです。screen-shotUse custom SELECT queryscreen-shot が選択されていない場合にのみ必要です。 |
| Filter Conditions | テーブルから取得するデータに追加の特定性が必要な場合は、WHERE 句の一部として指定できます。 |
| Order by | 特定のフィールドでレコードを並べ替える必要がある場合に指定します。増分列は order by 条件に含める必要があります。 |
| Query | SQL クエリを含むフィールドです。screen-shotUse custom SELECT queryscreen-shot が選択されている場合にのみ必要です。 |
| Incremental Loading | 増分読み込みを有効にする場合はチェックボックスを選択します |
| Incremental Columns | 増分列を定義します。これらの列は order by フィルタに含める必要があります。 |
| Start after value | 増分読み込みに使用される列の値です。 |
| Invalid Value Handling Mode | 無効な値の処理方法を指定します。次のいずれかを選択できます。 - Fail Job - Ignore Invalid Value - Ignore Row |
Next を選択します。
- シンプルなクエリ:
query: SELECT * FROM simple_data WHERE cut = 'Very Good' ORDER BY `c_custkey`- 増分とlast_records を使用したクエリ
incremental\_columns の値は、パラメータの位置に従い、列と同じ名前にする必要があります。
query: SELECT * FROM simple_data WHERE myid > :myid AND count > :count ORDER BY `myid`
incremental: true
incremental_columns: ['myid', 'count']
last_record: ['4', '5']クエリには、last\_record に値が入力されたWHERE 条件が必要です。
Order by は必須ではありませんが、より正確な結果を得るために指定する必要があります。
screen-shotmyidscreen-shot が4より大きく、screen-shotcountscreen-shot が5より大きい実際のクエリは、次のようになります。
SELECT * FROM simple_data WHERE myid > 4 AND count > 5 ORDER BY `myid`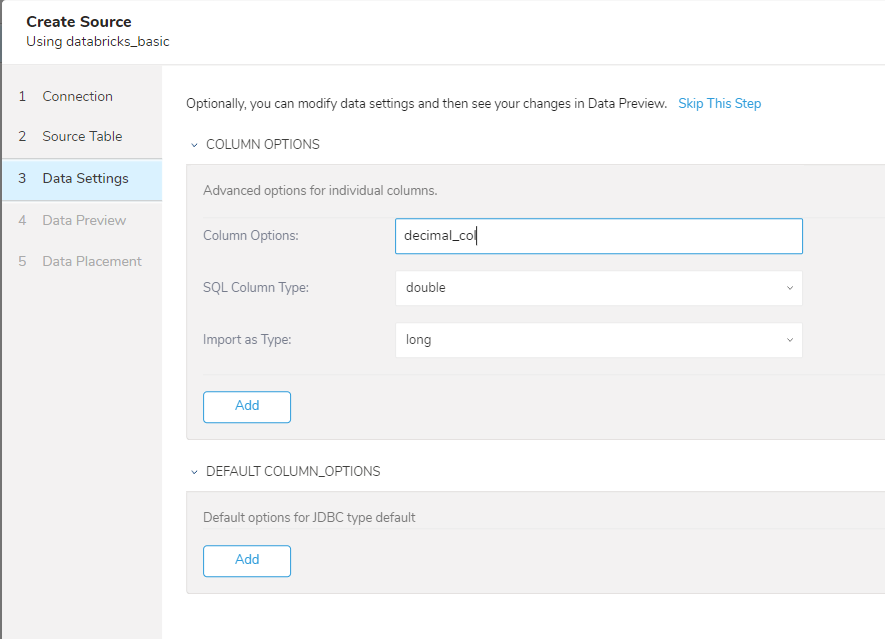
| パラメータ | 説明 |
|---|---|
| COLUMN OPTIONS | 特定のカラムのデータ型を定義します。 |
| DEFAULT COLUMN_OPTIONS | 特定のデータ型の変換データ型を定義します。例: longを常にstringに変換する |
Next を選択します。
データプレビューはオプションであり、次のダイアログページに進む場合は Next をクリックしても問題ありません。
- インポートを実行する前にデータのプレビューを表示するには、Generate Preview を選択します。
データプレビューに表示されるデータは、ソースから概算されたものです。これはインポートされる実際のデータではありません。
- データが期待通りに表示されていることを確認します。
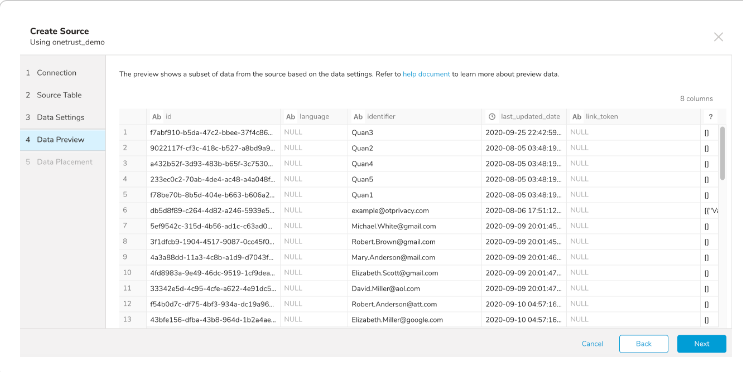 3. Next を選択します。
3. Next を選択します。
データの配置について、データを配置したいターゲット database と table を選択し、インポートを実行する頻度を指定します。
Next を選択します。Storage の下で、インポートされたデータを配置する新しい database を作成するか、既存の database を選択し、新しい table を作成するか、既存の table を選択します。
Database を選択 > Select an existing または Create New Database を選択します。
オプションで、database 名を入力します。
Table を選択 > Select an existing または Create New Table を選択します。
オプションで、table 名を入力します。
データをインポートする方法を選択します。
- Append (デフォルト) - データインポートの結果は table に追加されます。 table が存在しない場合は作成されます。
- Always Replace - 既存の table の全体の内容をクエリの結果出力で置き換えます。table が存在しない場合は、新しい table が作成されます。
- Replace on New Data - 新しいデータがある場合のみ、既存の table の全体の内容をクエリの結果出力で置き換えます。
Timestamp-based Partition Key 列を選択します。 デフォルトキーとは異なるパーティションキーシードを設定したい場合は、long または timestamp 列をパーティショニング時刻として指定できます。デフォルトの時刻列として、add_time フィルターで upload_time を使用します。
データストレージの Timezone を選択します。
Schedule の下で、このクエリを実行するタイミングと頻度を選択できます。
- Off を選択します。
- Scheduling Timezone を選択します。
- Create & Run Now を選択します。
- On を選択します。
- Schedule を選択します。UI では、@hourly、@daily、@monthly、またはカスタム cron の 4 つのオプションが提供されます。
- Delay Transfer を選択して、実行時間の遅延を追加することもできます。
- Scheduling Timezone を選択します。
- Create & Run Now を選択します。
転送が実行された後、Data Workbench > Databases で転送の結果を確認できます。
Workflowの screen-shottd_load>:screen-shot オペレーターを使用して、Databricksからデータをインポートできます。既にSOURCEを作成している場合は実行できます。SOURCEを作成したくない場合は、screen-shot.ymlscreen-shot ファイルを使用してインポートできます。
- TD Consoleを開きます。
- Integrations Hub > Sourcesに移動します。
- 対象のSourceを特定します。
- Sourceの右端にあるmore icon (...)を選択し、Copy Unique IDを選択します。
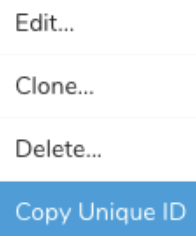
Unique IDは次のようになります: screen-shotdatabricks_import_1234••••••screen-shot
- screen-shottd_load>:screen-shot オペレーターを使用してWorkflowタスクを定義します。
+load:
td_load>: databricks_import_1234••••••
database: ${td.dest_db}
table: ${td.dest_table}- Workflowを実行します。
- 対象の screen-shot.ymlscreen-shot ファイルを特定します。
screen-shot.ymlscreen-shot ファイルを作成する必要がある場合は、Amazon S3 Import Integration Using CLIを参照してください。
- screen-shottd_load>:screen-shot オペレーターを使用してWorkflowタスクを定義します。
+load:
td_load>: config/daily_load.yml
database: ${td.dest_db}
table: ${td.dest_table}- Workflowを実行します。
| 名前 | 説明 | 値 | デフォルト値 | 必須 |
|---|---|---|---|---|
| type | databricks | databricks | True | |
| auth_method | 認証方法です。 | basic または access_token | basic | |
host_name | Databricksインスタンスのホスト名です。 | True | ||
http_path | DatabricksインスタンスのHTTPパスです。 | True | ||
| user_name | ログイン用のユーザー名です。 | True(auth_methodがbasicの場合) | ||
| password | ログイン用のパスワードです。 | True(auth_methodがbasicの場合) | ||
| access_token | データ取得に使用するaccess_tokenです。 | True(auth_methodがaccess_tokenの場合) | ||
| catalog | データセットのカタログです。 | True | ||
| schema | データセットのスキーマです。 | True | ||
| use_custom_query | カスタムクエリを構築するか、フィールドに入力してカスタムクエリを作成できます。 | true/false | true | |
| select | データセットから選択するカラムを定義します。これはscreen-shotUse custom SELECT queryscreen-shotがfalseの場合のみ必須です。 | * | True(use_custom_queryがfalseの場合) | |
| table | 選択するテーブルです。これはscreen-shotUse custom SELECT queryscreen-shot がfalseの場合のみ必須です。 | True(use_custom_queryがfalseの場合) | ||
| where | テーブルから取得するデータの詳細な条件が必要な場合は、WHERE句の一部として指定できます。 | |||
| order_by | 特定のフィールドでレコードを並べ替える必要がある場合は指定します。増分カラムはorder by条件に含める必要があります。 | |||
| query | 独自のクエリを構築します。 | True(use_custom_queryがtrueの場合) | ||
| incremental | 増分読み込みを有効にします。 | true/false | false | |
incremental_columns | 特定のカラムのデータ型を定義します。 | |||
| last_record | 増分読み込みの最後のレコード値を定義します。 | |||
default_column_options | 特定のデータ型の変換データ型を定義します。 |
サンプルWorkflowコードについては、Treasure Boxesを参照してください。
コネクタを設定する前に、最新のTD Toolbeltをインストールしてください。
in:
type: databricks
auth_method: BASIC
host_name: "dbc-8297d0a7-2709.cloud.databricks.com"
http_path: "/sql/1.0/warehouses/1b195ce3a8720eb9"
username: ***
password: ***
access_token: ***
catalog: hive_metastore
schema: default
select: "*"
table: diamonds
incremental_columns: [ price, x, y, z ]
order_by: "`price`, `x`, `y`, `z`"
incremental: true
last_record: ['4']
default_column_options: {"double": {"type": "string"}}
out:
mode: append| 名前 | 説明 | 値 | デフォルト値 | 必須 |
|---|---|---|---|---|
| type | databricks | databricks | True | |
| auth_method | 認証方法です。 | basic/access_token | basic | |
host_name | Databricksインスタンスのホスト名です。 | True | ||
http_path | DatabricksインスタンスのHTTPパスです。 | True | ||
| user_name | ログインするためのユーザー名です。 | True(auth_methodがbasicの場合) | ||
| password | ログインするためのパスワードです。 | True(auth_methodがbasicの場合) | ||
| access_token | データ取得のためのaccess_tokenです。 | True(auth_methodがaccess_tokenの場合) | ||
| catalog | データセットのカタログです。 | True | ||
| schema | これはデータセットのスキーマです。 | True | ||
| use_custom_query | カスタムクエリを作成するか、フィールドを入力してクエリを作成します。 | true/false | true | |
| skip_validate_query | クエリの検証をスキップします。クエリの検証をスキップすると、プレビューモードは常にダミーデータで実行されます。 | true/false | false | |
| select | データセットから選択する列を定義します。カスタムSELECTクエリを使用がfalseの場合にのみ必須です。 | * | use_custom_queryがfalseの場合はTrue | |
| table | 選択するテーブルです。カスタムSELECTクエリを使用がfalseの場合にのみ必須です。 | use_custom_queryがfalseの場合はTrue | ||
| where | テーブルから取得するデータに追加の特定性が必要な場合は、WHERE句の一部として指定できます。 | |||
| order_by | 特定のフィールドでレコードを並べ替える必要がある場合に指定します。incrementalカラムはorder by条件に含める必要があります。 | |||
| query | 独自のクエリを作成します。 | use_custom_queryがtrueの場合はTrue | ||
| incremental | インクリメンタルローディングを有効にします。 | true/false | false | |
incremental_columns | 特定の列のデータ型を定義します。 | |||
| last_record | インクリメンタルローディングの最終レコード値を定義します。 | |||
default_column_options | 特定のデータ型の変換データ型を定義します。 |
connector:guessコマンドは、ソースファイルを自動的に読み取り、ロジックを使用してファイル形式、フィールド、列を推測します。
$ td connector:guess seed.yml -o load.ymlload.ymlを開いて、ファイル形式、エンコーディング、列名、型などの定義を確認できます。
- 例
in:
type: databricks
auth_method: BASIC
host_name: "dbc-8297d0a7-2709.cloud.databricks.com"
http_path: "/sql/1.0/warehouses/1b195ce3a8720eb9"
username: ***
password: ***
access_token: ***
catalog: hive_metastore
schema: default
select: "*"
table: diamonds
incremental_columns: [ price, x, y, z ]
order_by: "`price`, `x`, `y`, `z`"
query: SELECT * FROM simple_data WHERE myid > :myid
incremental: true
last_record: ['4']
default_column_options: {"double": {"type": "string"}}
out:
mode: appendデータをプレビューするには、td connector:previewコマンドを使用します。
$ td connector:preview load.yml
+-------+---------+----------+---------------------+
| id | company | customer | created_at |
+-------+---------+----------+---------------------+
| 11200 | AA Inc. | David | 2015-03-31 06:12:37 |
| 20313 | BB Imc. | Tom | 2015-04-01 01:00:07 |
| 32132 | CC Inc. | Fernando | 2015-04-01 10:33:41 |
| 40133 | DD Inc. | Cesar | 2015-04-02 05:12:32 |
| 93133 | EE Inc. | Jake | 2015-04-02 14:11:13 |
+-------+---------+----------+---------------------+guessコマンドは、ソースデータファイル内に3行以上、2列以上が必要です。これは、コマンドがソースデータのサンプル行を使用して列定義を評価するためです。
列名または列型が予期せず検出された場合は、load.ymlファイルを変更して再度プレビューしてください。
ジョブの実行には、データのサイズに応じて数時間かかる場合があります。データを保存するTreasure Dataのデータベースとテーブルを必ず指定してください。
Treasure Dataのストレージは時間によってパーティション分割されているため(データパーティショニングを参照)、--time-columnオプションを指定することをお勧めします。このオプションが指定されていない場合、データコネクタは最初のlongまたはtimestamp列をパーティショニング時間として選択します。--time-columnで指定する列の型は、longまたはtimestampのいずれかである必要があります。
データに時間列がない場合は、add_timeフィルタオプションを使用して時間列を追加できます。詳細については、add_timeフィルタプラグインを参照してください。
$ td connector:issue load.yml --database td_sample_db --table td_sample_table \
--time-column created_atこのconnector:issueのコマンド例では、すでにdatabase(td_sample_db)とtable(td_sample_table)を作成していることを前提としています。TDにデータベースまたはテーブルが存在しない場合、このコマンドは失敗します。データベースとテーブルを手動で作成するか、td connector:issueコマンドで--auto-create-tableオプションを使用してデータベースとテーブルを自動作成してください。
$ td connector:issue load.yml --database td_sample_db --table td_sample_table
--time-column created_at --auto-create-tableデータコネクタは、サーバー側でレコードをソートしません。時間ベースのパーティショニングを効果的に使用するには、事前にファイル内のレコードをソートしてください。
timeというフィールドがある場合は、--time-columnオプションを指定する必要はありません。
$ td connector:issue load.yml --database td_sample_db --table td_sample_tableload.ymlファイルのoutセクションでファイルのインポートモードを指定できます。*out:*セクションは、データがTreasure Dataテーブルにインポートされる方法を制御します。たとえば、データを追加したり、Treasure Dataの既存のテーブル内のデータを置き換えたりすることができます。
| モード | 説明 | 例 |
|---|---|---|
| Append | レコードはターゲットテーブルに追加されます。 | in: ... out: mode: append |
| Always Replace | ターゲットテーブルのデータを置き換えます。ターゲットテーブルに対して行われた手動のスキーマ変更はそのまま保持されます。 | in: ... out: mode: replace |
| Replace on new data | インポートする新しいデータがある場合にのみ、ターゲットテーブルのデータを置き換えます。 | in: ... out: mode: replace_on_new_data |
インクリメンタルファイルインポートのために、定期的なデータコネクタの実行をスケジュールできます。高可用性を確保するために、スケジューラを慎重に設定してください。
スケジュールされたインポートの場合、指定されたプレフィックスに一致し、条件に応じて次のいずれかのフィールドを持つすべてのファイルをインポートできます。
- use_modified_timeが無効になっている場合、次の実行のために最後のパスが保存されます。2回目以降の実行では、コネクタはアルファベット順で最後のパスの後に来るファイルのみをインポートします。
- それ以外の場合、ジョブが実行された時刻が次の実行のために保存されます。2回目以降の実行では、コネクタはアルファベット順でその実行時刻以降に変更されたファイルのみをインポートします。
タイムゾーンを指定せずに指定されたすべての日付および日付/時刻形式は、常にデフォルトのUTCとして扱われます。
新しいスケジュールは、td connector:createコマンドを使用して作成できます。
$ td connector:create daily_import "10 0 * * *" \
td_sample_db td_sample_table load.ymlTreasure Dataのストレージは時間によってパーティション分割されているため(データパーティショニングも参照)、--time-columnオプションを指定することをお勧めします。
$ td connector:create daily_import "10 0 * * *" \
td_sample_db td_sample_table load.yml \
--time-column created_atcronパラメータは、@hourly、@daily、@monthlyの3つの特別なオプションも受け付けます。
デフォルトでは、スケジュールはUTCタイムゾーンで設定されます。-tまたは*--timezoneオプションを使用して、タイムゾーンでスケジュールを設定できます。--timezoneオプションは、'Asia/Tokyo'、'America/Los_Angeles'などの拡張タイムゾーン形式のみをサポートしています。PSTやCSTなどのタイムゾーンの略語はサポートされておらず*、予期しないスケジュールになる可能性があります。