Amazon S3向けインポートデータコネクタにより、S3バケットに保存されているJSON、TSV、CSVファイルからデータをインポートすることができます。Amazon S3 Import Integration v2とv1の主な違いとメリットは、assume_role認証のサポートが追加されたことです。
以下の表の情報を確認して、v2とv1の認証の違いを理解してください。v1の詳細については、Amazon S3 Import Integration v1を参照してください。
| 認証方式 | Amazon S3 v2 | Amazon S3 v1 |
|---|---|---|
| basic | x | x |
| anonymous | x | |
| session | x | x |
| assume_role | x |
- Treasure Dataの基本的な知識
TD リージョンと同じリージョンにある AWS S3 バケットを使用している場合、TD がバケットにアクセスする IP アドレスはプライベートで動的に変化します。アクセスを制限したい場合は、静的 IP アドレスではなく VPC の ID を指定してください。例えば、US リージョンの場合は vpc-df7066ba 経由でアクセスを設定し、Tokyo リージョンの場合は vpc-e630c182 経由、EU01 リージョンの場合は vpc-f54e6a9e 経由でアクセスを設定してください。
TD Console にログインする URL から TD Console のリージョンを確認し、URL 内のリージョンのデータコネクターを参照してください。
詳細については、API ドキュメントを参照してください。
セキュリティポリシーで IP ホワイトリストが必要な場合は、接続を成功させるために Treasure Data の IP アドレスを許可リストに追加する必要があります。
リージョンごとに整理された静的 IP アドレスの完全なリストは、次のリンクにあります: https://api-docs.treasuredata.com/en/overview/ip-addresses-integrations-result-workers/
非常に大きなファイルをインポートする場合、このインテグレーションが提供する並列インポートサポートを利用できます。これを行うには、大きなファイルを小さなファイルに分割し、小さなファイルをバッチで同時にアップロードします。ただし、非常に小さなファイルを大量にインポートしようとすると、パフォーマンスに悪影響を及ぼすことに注意してください。したがって、Treasure Dataでは、50MB未満のファイルサイズで並列入力を実行しないことを推奨しています。 使用できる並列インポートスレッドのデフォルトの最大数は16です。
TD Consoleを使用してデータコネクタを作成できます。
- TD Consoleを開きます。
- Integrations Hub > Catalogに移動します。
- S3 v2を検索し、Amazon S3 (v2)を選択します。
- Create Authenticationを選択します。
新しいAuthenticationダイアログが開きます。選択した認証方式によって、ダイアログは次のいずれかの画面のように表示される場合があります:
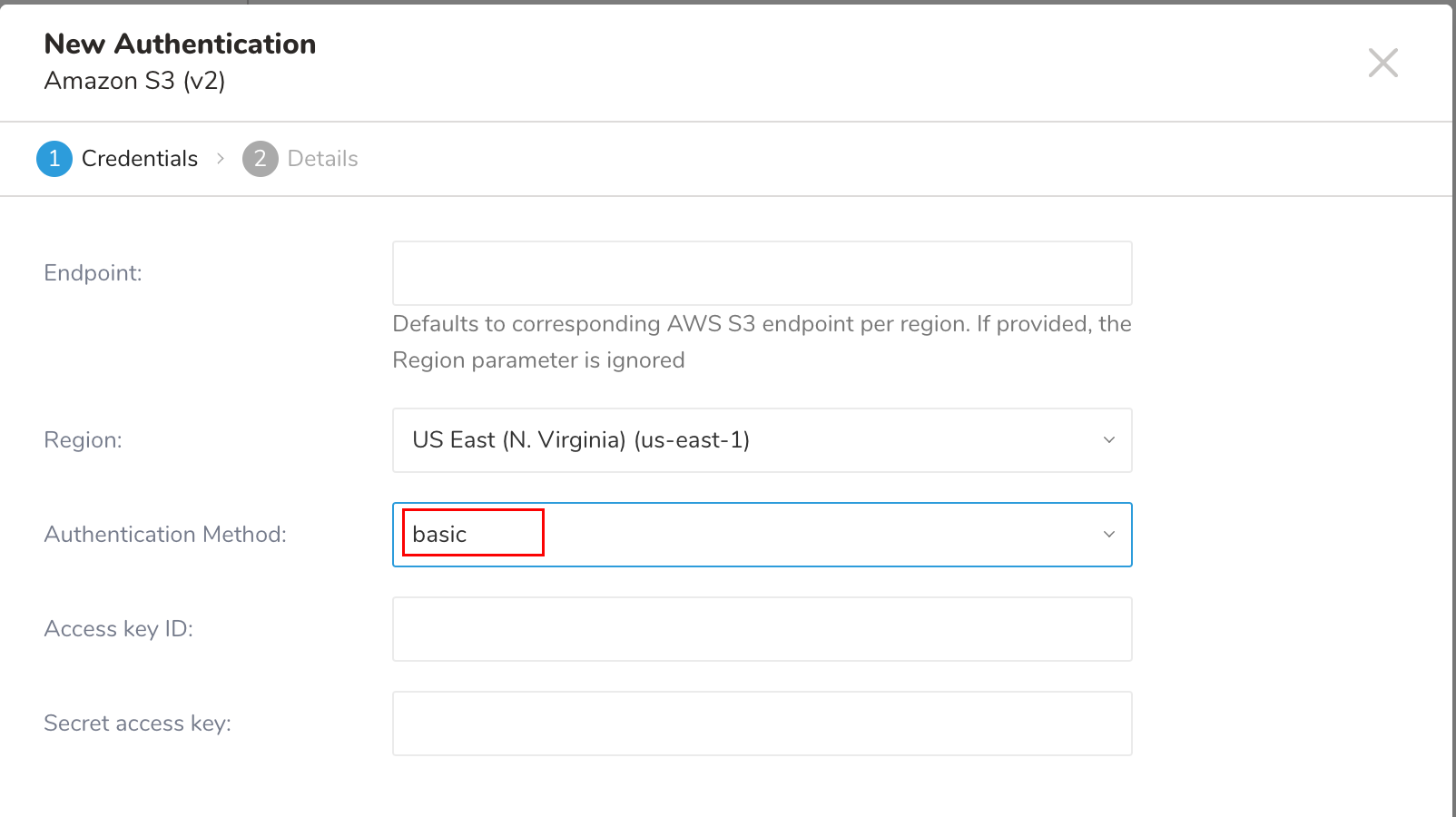
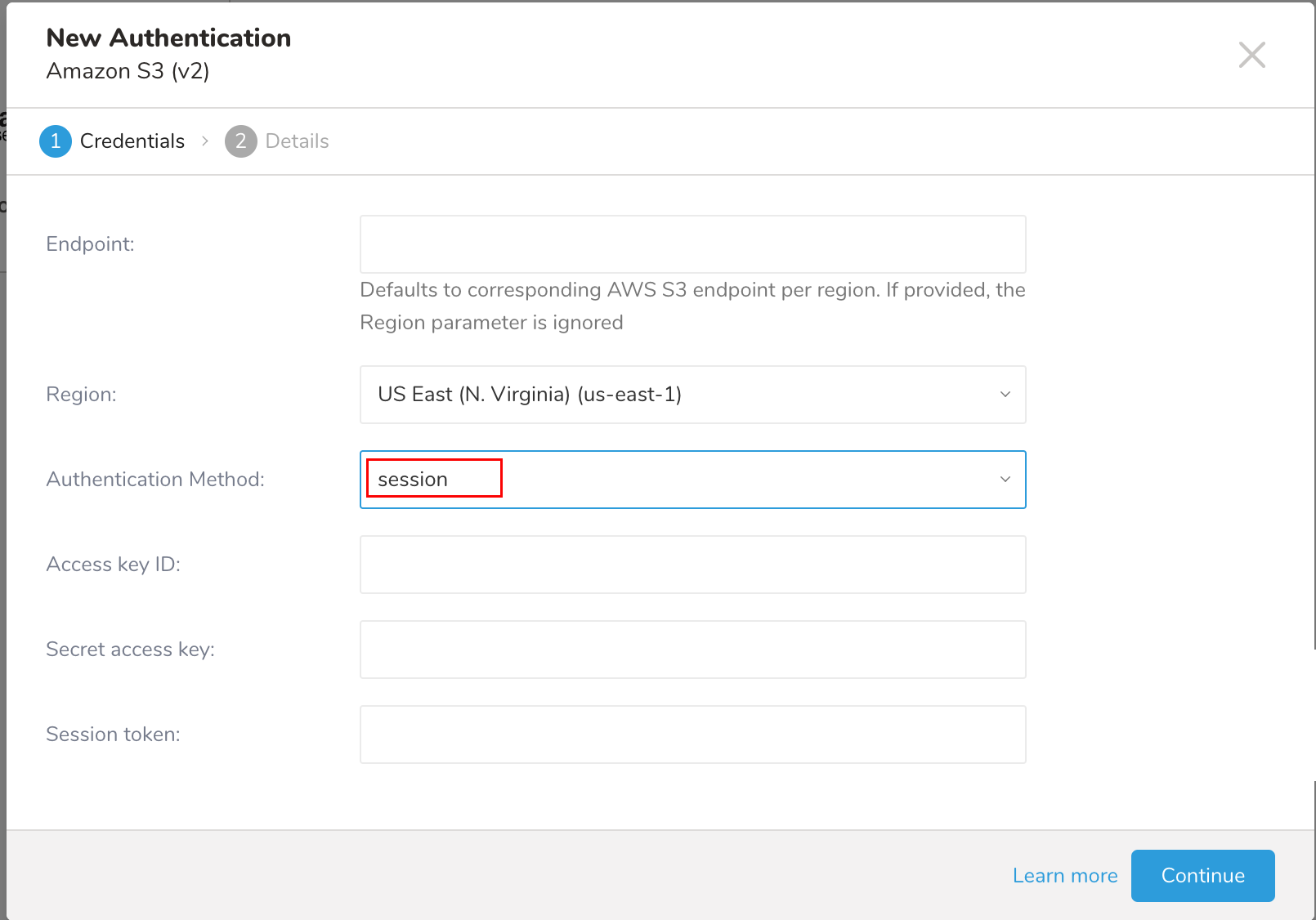
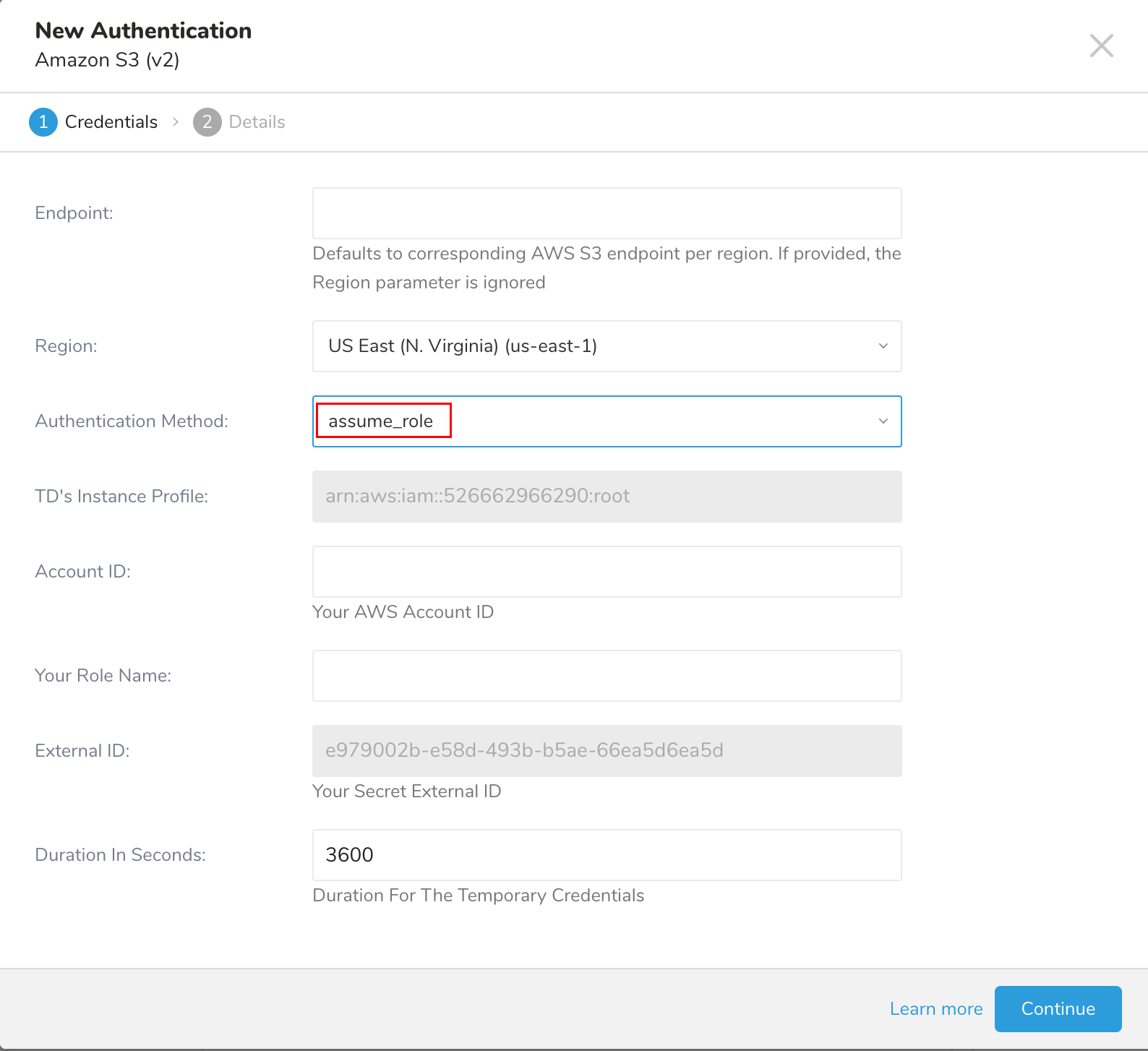
- 認証フィールドを設定し、Continueを選択します。
以下の表は、Amazon S3 Import Integration v2の認証設定パラメータについて説明しています。
| パラメータ | 説明 |
|---|---|
Endpoint | S3サービスエンドポイントの上書き。リージョンとエンドポイント情報は、AWS service endpointsドキュメントから確認できます。(例:s3.ap-northeast-1.amazonaws.com) 指定すると、リージョン設定が上書きされます。 |
| Region | AWSリージョン |
| Authentication Method |
|
| Access Key ID | AWS S3が発行 |
| Secret Access Key | AWS S3が発行 |
| Secret token | 一時認証情報用のセッショントークン |
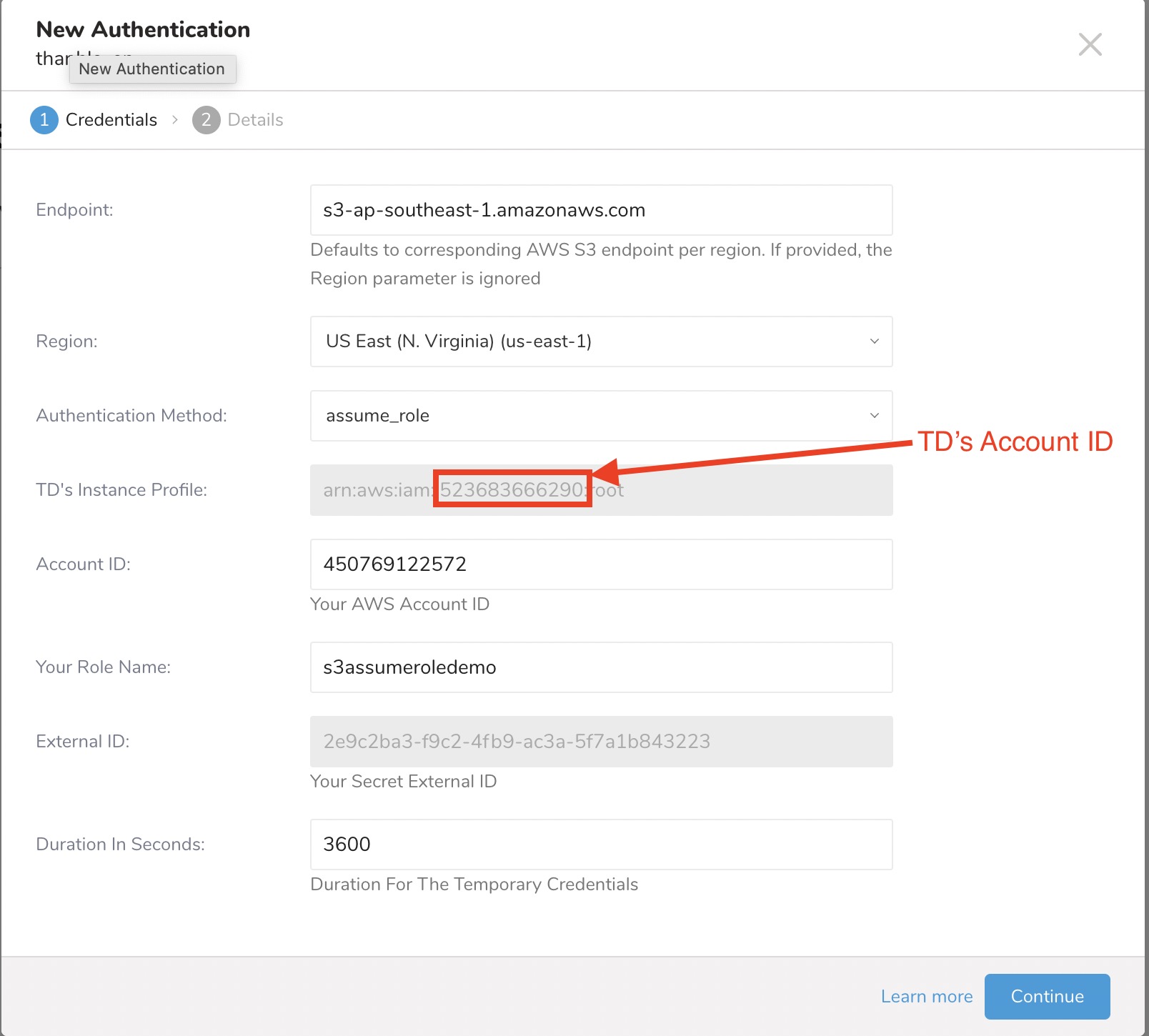
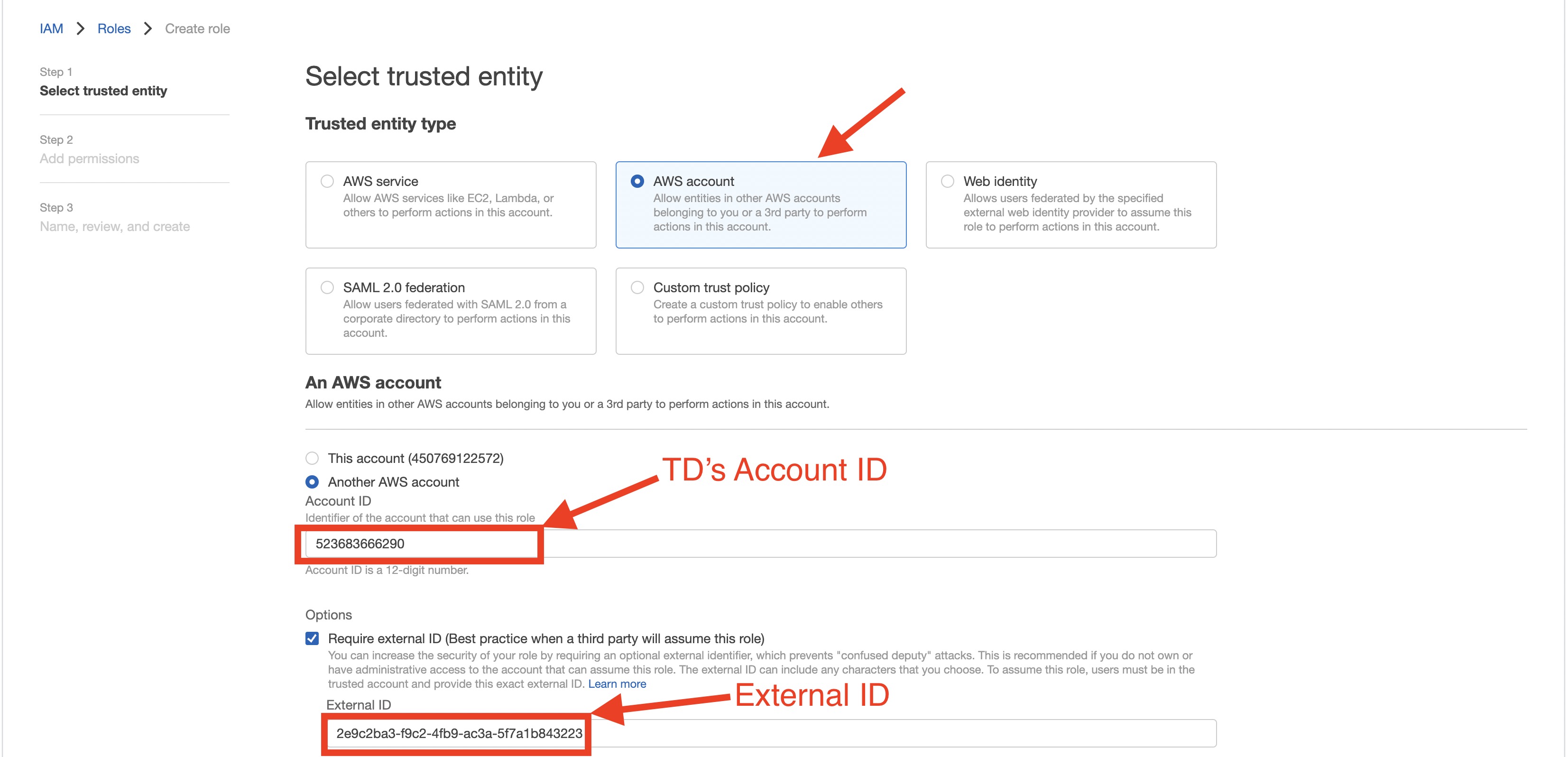
| TD's Instance Profile | この値はTD Consoleから提供されます。この値の数値部分が、IAMロールを作成する際に使用するAccount IDになります。 |
| Account ID | あなたのAWSアカウントID |
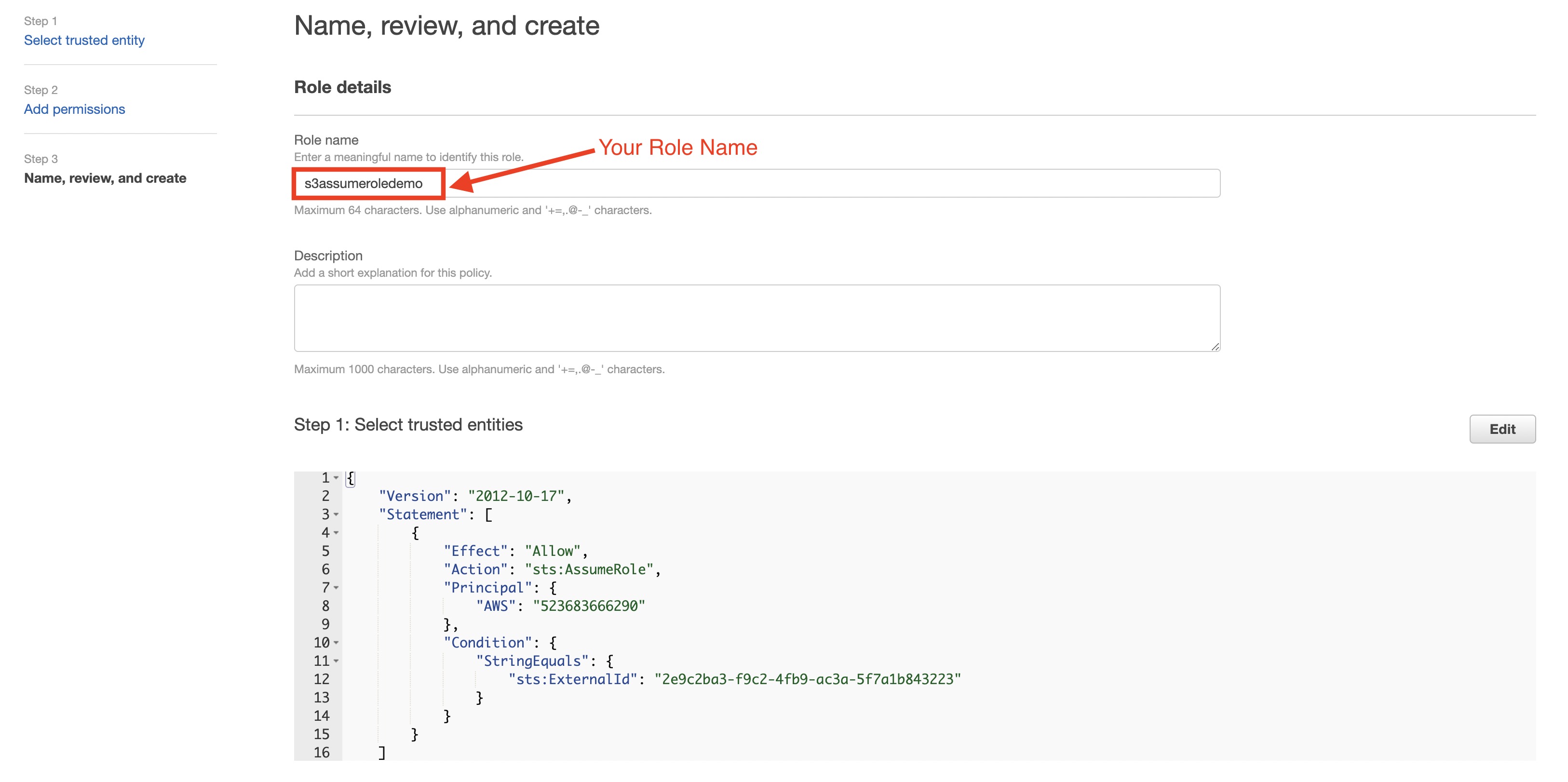
| Your Role Name | あなたのAWSロール名 |
| External ID | あなたのシークレット外部ID |
| Duration In Seconds | 一時認証情報の有効期間 |
- 新しいAWS S3接続に名前を付け、Doneを選択します。
- assume_role認証方式で新しい認証を作成します。
- TD's Instance Profileフィールドの値の数値部分をメモしておきます。
- AWS IAMロールを作成します。
認証済み接続を作成すると、自動的にAuthenticationsページに移動します。
- 作成した接続を検索します。
- New Sourceを選択します。
- Data TransferフィールドにSourceの名前を入力します**。**
- Nextをクリックします。
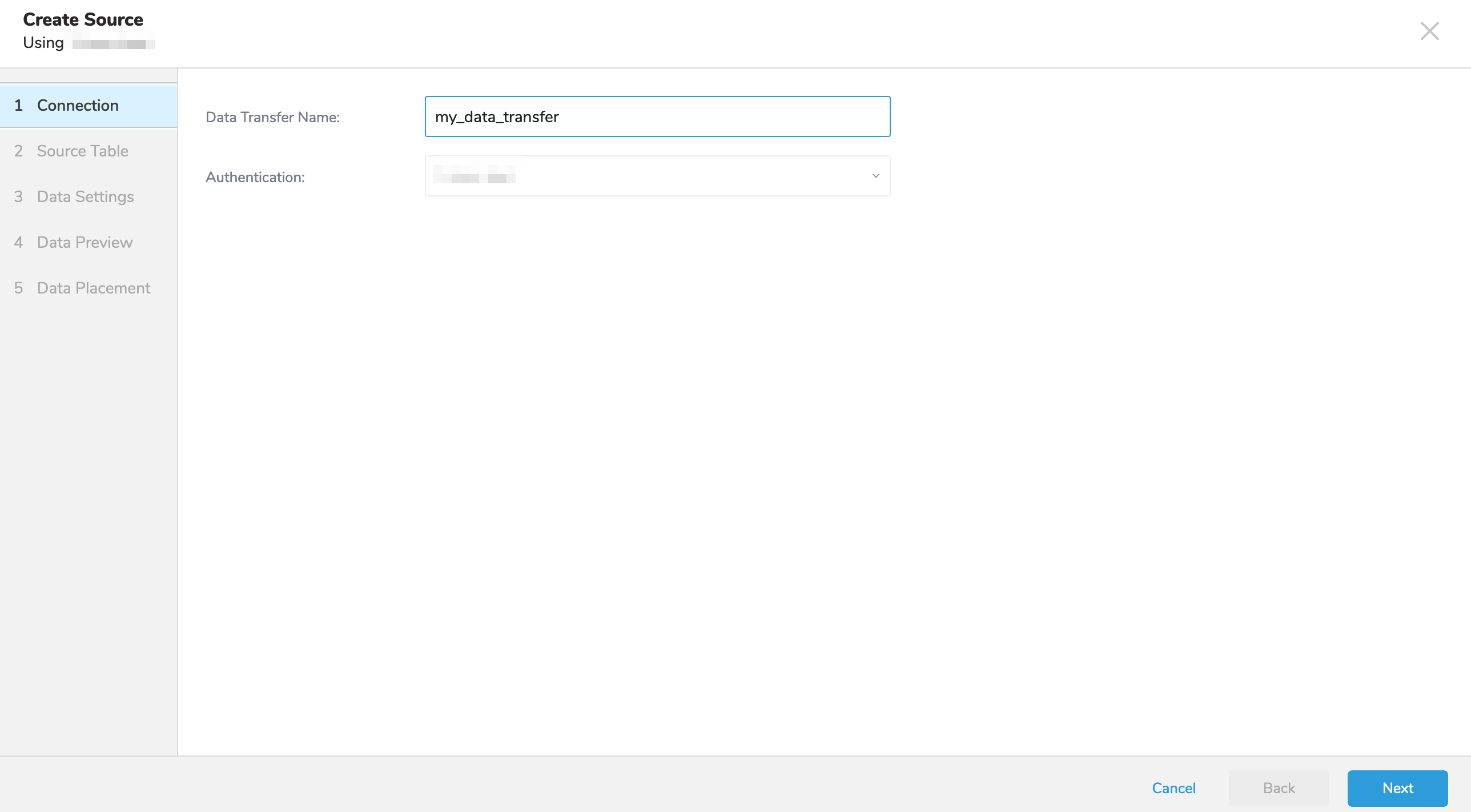
Sourceダイアログが開きます。
- 以下のパラメータを編集します。
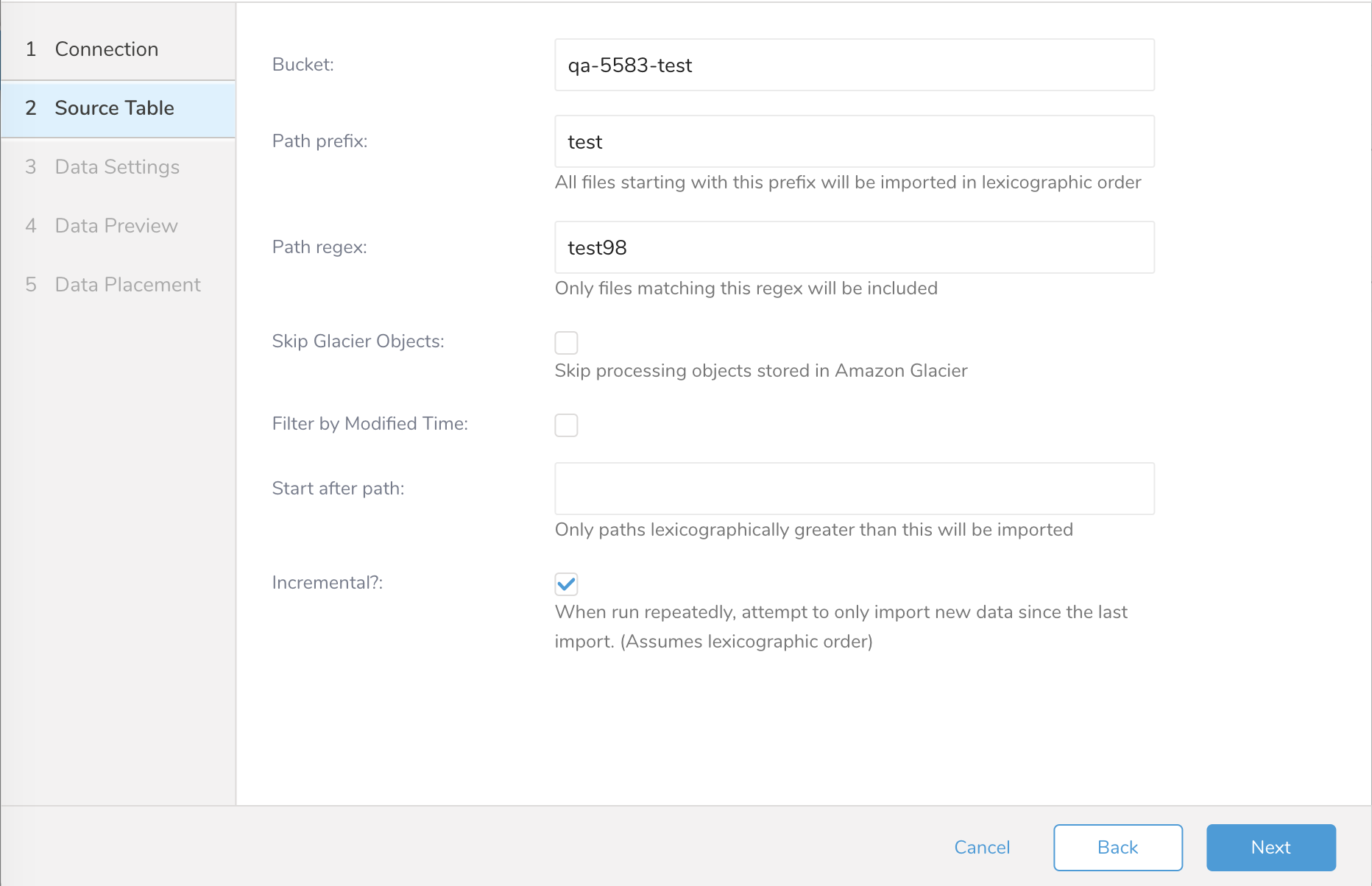
| パラメータ | 説明 |
|---|---|
| Bucket |
|
| Path Prefix |
|
| Path Regex |
|
| Skip Glacier Objects |
|
| Filter by Modified Time |
|
| 未チェック(デフォルト): |
|
| チェック済み: |
|
ディレクトリ(トップレベルディレクトリ「/」など)内のすべてのファイルをスキャンする必要がある場合があります。このような場合は、CLIを使用してインポートを実行する必要があります。
例
Amazon CloudFrontは、静的および動的Webコンテンツの配信を高速化するWebサービスです。CloudFrontを設定して、CloudFrontが受信するすべてのユーザーリクエストに関する詳細情報を含むログファイルを作成できます。ロギングを有効にすると、CloudFrontを次のようにログファイルを保存するように設定できます:
[your_bucket] - [logging] - [E231A697YXWD39.2017-04-23-15.a103fd5a.gz][your_bucket] - [logging] - [E231A697YXWD39.2017-04-23-15.b2aede4a.gz][your_bucket] - [logging] - [E231A697YXWD39.2017-04-23-16.594fa8e6.gz][your_bucket] - [logging] - [E231A697YXWD39.2017-04-23-16.d12f42f9.gz]この場合、Source Tableの設定は次のようになります:
- Bucket: your_bucket
- Path Prefix: logging/
- Path Regex: .gz$ (必須ではありません)
- Start after path: logging/E231A697YXWD39.2017-04-23-15.b2aede4a.gz (2017-04-23-16からログファイルをインポートする場合)
- Incremental: true (このジョブをスケジュール設定する場合)
BZip2デコーダープラグインはデフォルトでサポートされています。File Decoder Functionを参照してください。
Nextを選択します。
Data Settingsページが開きます。
必要に応じて、データ設定を編集するか、このダイアログのページをスキップします。
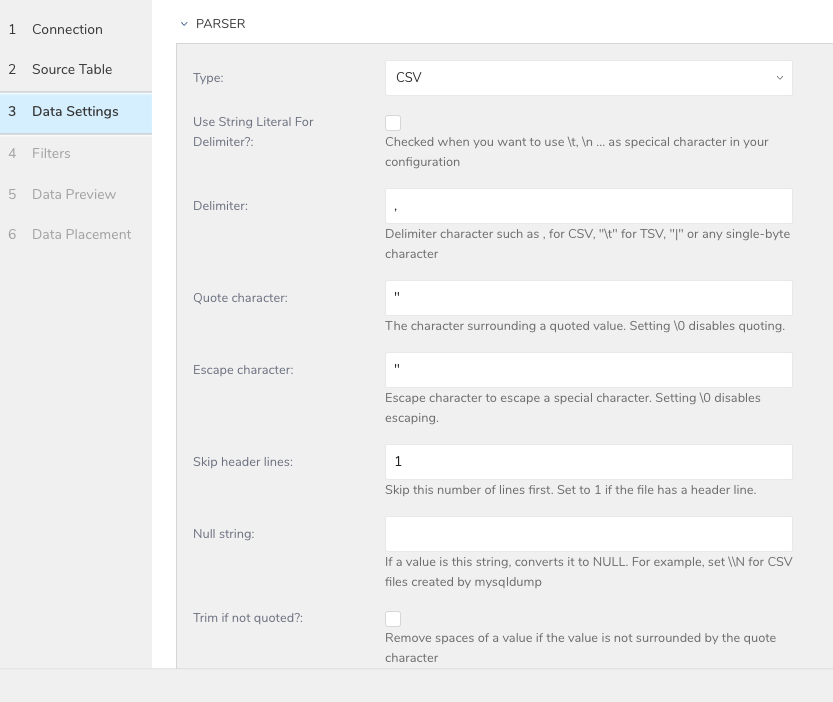
Filters は、S3、FTP、または SFTP コネクターの Create Source または Edit Source インポート設定で使用できます。
Import Integration Filters を使用すると、インポート用のデータ設定の編集を完了した後、インポートされたデータを変更できます。
import integration filters を適用するには:
- Data Settings で Next を選択します。Filters ダイアログが開きます。
- 追加したいフィルターオプションを選択します。
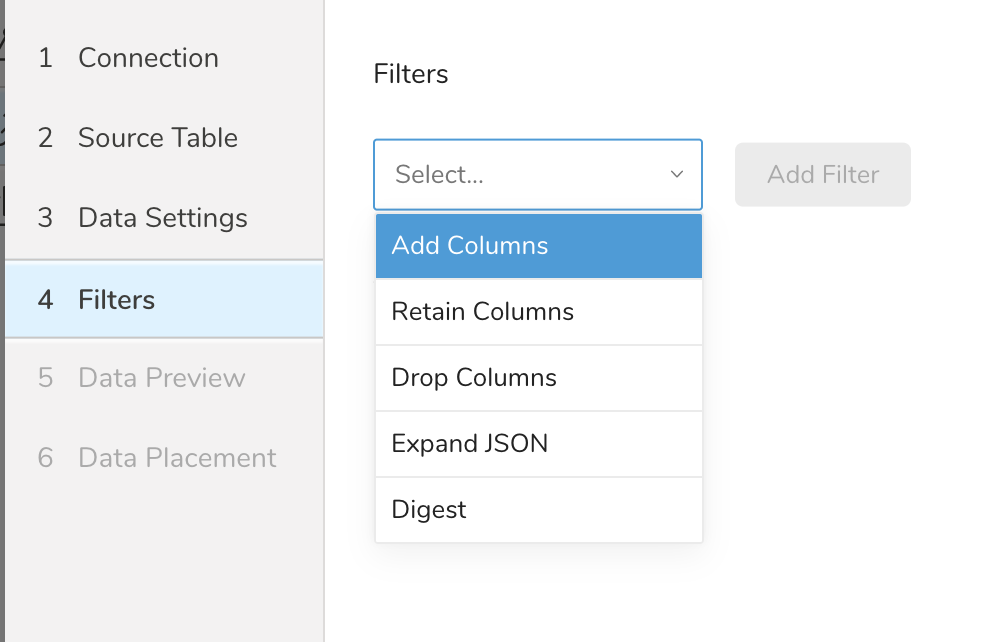
- Add Filter を選択します。そのフィルターのパラメーターダイアログが開きます。
- パラメーターを編集します。各フィルタータイプの情報については、次のいずれかを参照してください:
- Retaining Columns Filter
- Adding Columns Filter
- Dropping Columns Filter
- Expanding JSON Filter
- Digesting Filter
- オプションで、同じタイプの別のフィルターを追加するには、特定の列フィルターダイアログ内で Add を選択します。
- オプションで、別のタイプの別のフィルターを追加するには、リストからフィルターオプションを選択して、同じ手順を繰り返します。
- 追加したいフィルターを追加した後、Next を選択します。Data Preview ダイアログが開きます。
インポートを実行する前に、Generate Preview を選択してデータのプレビューを表示できます。Data preview はオプションであり、選択した場合はダイアログの次のページに安全にスキップできます。
- Next を選択します。Data Preview ページが開きます。
- データをプレビューする場合は、Generate Preview を選択します。
- データを確認します。
データの配置について、データを配置したいターゲット database と table を選択し、インポートを実行する頻度を指定します。
Next を選択します。Storage の下で、インポートされたデータを配置する新しい database を作成するか、既存の database を選択し、新しい table を作成するか、既存の table を選択します。
Database を選択 > Select an existing または Create New Database を選択します。
オプションで、database 名を入力します。
Table を選択 > Select an existing または Create New Table を選択します。
オプションで、table 名を入力します。
データをインポートする方法を選択します。
- Append (デフォルト) - データインポートの結果は table に追加されます。 table が存在しない場合は作成されます。
- Always Replace - 既存の table の全体の内容をクエリの結果出力で置き換えます。table が存在しない場合は、新しい table が作成されます。
- Replace on New Data - 新しいデータがある場合のみ、既存の table の全体の内容をクエリの結果出力で置き換えます。
Timestamp-based Partition Key 列を選択します。 デフォルトキーとは異なるパーティションキーシードを設定したい場合は、long または timestamp 列をパーティショニング時刻として指定できます。デフォルトの時刻列として、add_time フィルターで upload_time を使用します。
データストレージの Timezone を選択します。
Schedule の下で、このクエリを実行するタイミングと頻度を選択できます。
- Off を選択します。
- Scheduling Timezone を選択します。
- Create & Run Now を選択します。
- On を選択します。
- Schedule を選択します。UI では、@hourly、@daily、@monthly、またはカスタム cron の 4 つのオプションが提供されます。
- Delay Transfer を選択して、実行時間の遅延を追加することもできます。
- Scheduling Timezone を選択します。
- Create & Run Now を選択します。
転送が実行された後、Data Workbench > Databases で転送の結果を確認できます。
ジョブログを確認してください。警告とエラーは、インポートの成功に関する情報を提供します。例えば、インポートエラーに関連する source ファイル名を特定できます。
特定のジョブの詳細を確認するには、そのジョブを選択して詳細を表示します。ジョブのタイプに応じて、次のいずれか、またはすべてを確認できます: 結果、クエリ、出力ログ、エンジンログ、詳細、および宛先。
- TD Console を開きます。
- Jobs に移動します。ページの右上に記載されているジョブの数を確認できます。
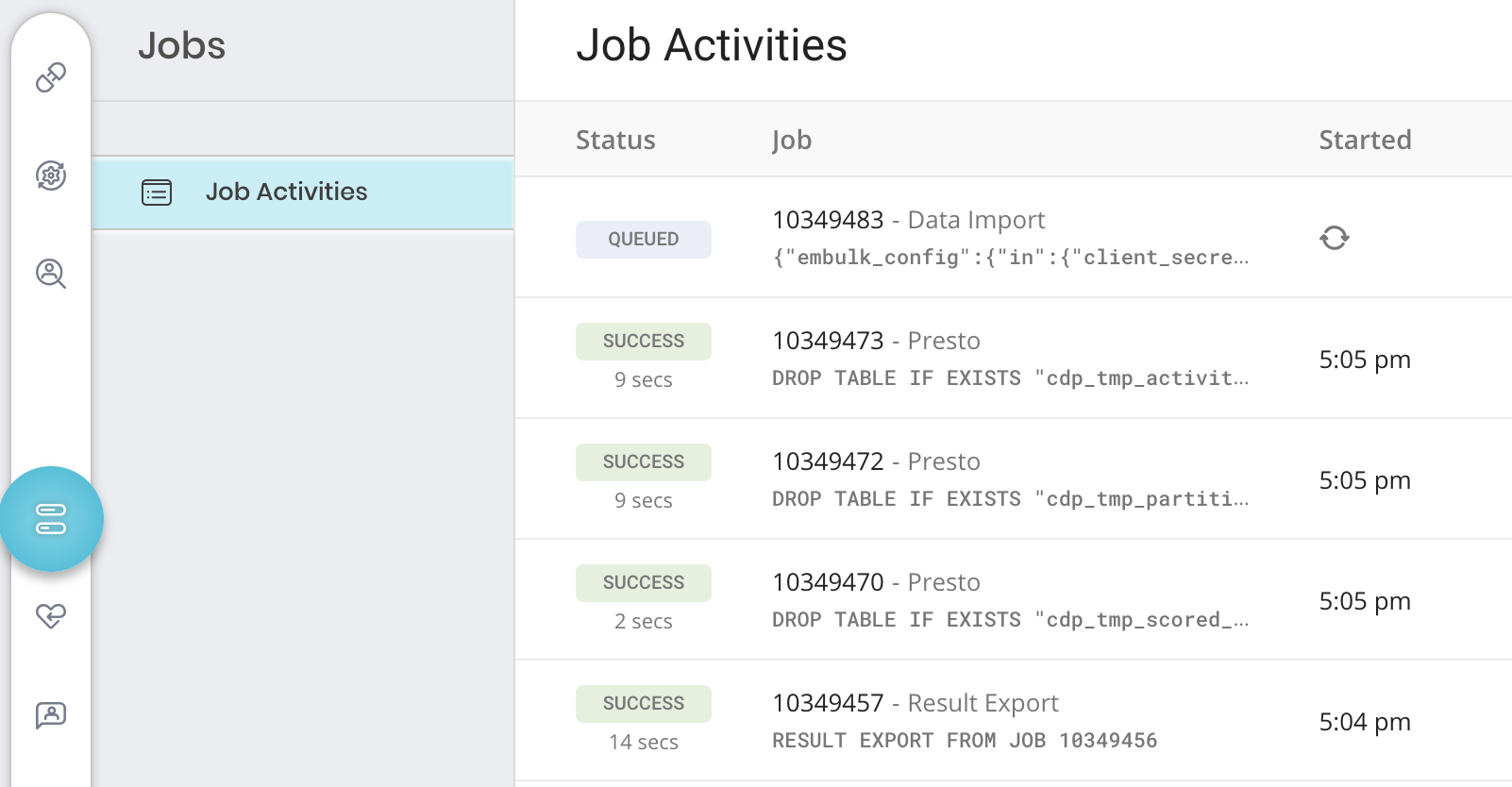 3. オプションで、フィルターを使用してジョブのリストを絞り込み、ジョブ所有者、日付、database 名などでフィルタリングして、関心のあるものを見つけます。 4. ジョブを選択して開き、結果、クエリ定義、ログ、その他の詳細を表示します。
3. オプションで、フィルターを使用してジョブのリストを絞り込み、ジョブ所有者、日付、database 名などでフィルタリングして、関心のあるものを見つけます。 4. ジョブを選択して開き、結果、クエリ定義、ログ、その他の詳細を表示します。
 5. 各タブには、ジョブに関する異なる情報が表示されます。
5. 各タブには、ジョブに関する異なる情報が表示されます。
| タブ名 | 説明 |
|---|---|
| Results |
|
| Query |
|
| Output および Engine Logs |
|
| Details | 詳細情報を表示します:
|
| Destination | ここでは、エクスポート integration 設定の詳細を表示できます(インポート integration には適用されません): - integration - タイプ - 設定 |
Amazon S3 Import Integration v2のv1に対する主な違いと利点は、assume_role認証のサポートが追加されたことです。認証方法としてassume_roleを使用する場合、認証を明示的に宣言することはできません。認証を再利用したWorkflow設定については、既存の認証の再利用を参照してください。
Workflowは、一意のIDでジョブを開始できます。詳細については、td_loadを参照してください。
オプションで、TD Toolbeltを使用して接続の設定、ジョブの作成、ジョブ実行のスケジュール設定を行うことができます。
コネクタを設定する前に、最新のTD Toolbeltをインストールしてください。
CLIとYAMLファイルを使用して増分ロードを計画している場合は、TDコンソールで既存のソースコネクタを使用する必要があります。増分ロード機能は、コンソールで処理された最後のレコードに関する情報を保持するためです。
以下の例に示すように、AWSアクセスキーを使用してseed.ymlファイルを設定します。バケット名とソースファイル名も指定する必要があります。オプションで、複数のファイルに一致させるためにpath_prefixを指定できます。以下の例では、path_prefix: path/to/sample_fileは以下に一致します
path/to/sample_201501.csv.gzpath/to/sample_201502.csv.gzpath/to/sample_201505.csv.gzなど
path_prefixを先頭の'/'付きで使用すると、意図しない結果になる可能性があります。例えば、「path_prefix: /path/to/sample_file」とすると、プラグインはs3://sample_bucket//path/to/sample_fileでファイルを探すことになり、これはS3上では意図したパスs3://sample_bucket/path/to/sample_fileとは異なります。
in:
type: s3_v2
access_key_id: XXXXXXXXXX
secret_access_key: YYYYYYYYYY
bucket: sample_bucket
# path to the *.json or *.csv or *.tsv file on your s3 bucket
path_prefix: path/to/sample_file
path_match_pattern: \.csv$ # a file will be skipped if its path doesn't match with this pattern
## some examples of regexp:
#path_match_pattern: /archive/ # match files in .../archive/... directory
#path_match_pattern: /data1/|/data2/ # match files in .../data1/... or .../data2/... directory
#path_match_pattern: .csv$|.csv.gz$ # match files whose suffix is .csv or .csv.gz
out:
mode: append既存の認証を再利用する場合は、td_authentication_id設定キーの値に認証IDを設定します。これは、assume-role認証方法に必要です。既存の認証の再利用を参照してください。
connector:guessは、ソースファイルを自動的に読み取り、ファイル形式とフィールドおよび列を評価します。
td connector:guess seed.yml -o load.ymlload.ymlファイルを確認すると、ファイル形式、エンコーディング、カラム名、型を含む「推測された」ファイル形式定義が表示されます。
in:
type: s3_v2
access_key_id: XXXXXXXXXX
secret_access_key: YYYYYYYYYY
bucket: sample_bucket
path_prefix: path/to/sample_file
parser:
charset: UTF-8
newline: CRLF
type: csv
delimiter: ','
quote: '"'
escape: ''
skip_header_lines: 1
columns:
- name: id
type: long
- name: company
type: string
- name: customer
type: string
- name: created_at
type: timestamp
format: '%Y-%m-%d %H:%M:%S'
out:
mode: appendtd connector:previewコマンドを使用してデータのプレビューを表示できます。
td connector:preview load.ymlconnector:guessコマンドはソースデータから3行以上、2カラム以上のデータを必要とします。これは、コマンドがソースデータのサンプル行を使用してカラム定義を評価するためです。
システムがカラム名またはカラムタイプを予期せず検出した場合は、load.ymlを直接変更して再度プレビューしてください。
現在、Data Connectorは"boolean"、"long"、"double"、"string"、"timestamp"タイプの解析をサポートしています。
Load Jobを送信します。データのサイズによっては数時間かかる場合があります。データを保存するTreasure Dataのデータベースとテーブルを指定します。
Treasure Dataのストレージは時刻でパーティション化されているため、--time-columnオプションを指定することが推奨されます(data partitioningを参照)。このオプションが指定されていない場合、Data Connectorは最初のlongまたはtimestampカラムをパーティション化時刻として選択します。--time-columnで指定するカラムの型は、longまたはtimestampのいずれかでなければなりません。
データに時刻カラムがない場合は、add_timeフィルタオプションを使用して時刻カラムを追加できます。詳細については、add_time filter pluginを参照してください。
td connector:issue load.yml \
--database td_sample_db --table td_sample_table \
--time-column created_at以下の例では、connector:issueコマンドは、すでにdatabase(td_sample_db)とtable(td_sample_table)を作成していることを前提としています。データベースまたはテーブルがTDに存在しない場合、このコマンドは失敗します。データベースとテーブルを手動で作成するか、td connector:issueコマンドで--auto-create-tableオプションを使用してデータベースとテーブルを自動作成してください:
td connector:issue load.yml \
--database td_sample_db --table td_sample_table \
--time-column created_at --auto-create-tableデータコネクタはサーバーサイドでレコードをソートしません。時間ベースのパーティショニングを効果的に使用するには、事前にファイル内のレコードをソートしておいてください。
timeという名前のフィールドがある場合は、--time-columnオプションを指定する必要はありません。
td connector:issue load.yml --database td_sample_db --table td_sample_tableload.ymlファイルのoutセクションでファイルインポートモードを指定できます。
out:セクションは、データがTreasure Dataテーブルにどのようにインポートされるかを制御します。
たとえば、Treasure Dataの既存のテーブルにデータを追加するか、データを置き換えるかを選択できます。
| モード | 説明 | 例 |
|---|---|---|
| Append | レコードがターゲットテーブルに追加されます。 | in: ...out: mode: append |
| Always Replace | ターゲットテーブルのデータを置き換えます。ターゲットテーブルに加えられた手動のスキーマ変更はそのまま保持されます。 | in: ...out: mode: replace |
| Replace on new data | インポートする新しいデータがある場合にのみ、ターゲットテーブルのデータを置き換えます。 | in: ...out: mode: replace_on_new_data |
増分ファイルインポートのために、データコネクタの定期実行をスケジュールできます。高可用性を確保するために、スケジューラーを慎重に設定しています。
スケジュールされたインポートでは、指定されたprefixに一致するすべてのファイルを、以下のいずれかのフィールドの条件でインポートできます:
- use_modified_timeが無効の場合、最後のパスが次の実行のために保存されます。2回目以降の実行では、コネクタはアルファベット順で最後のパスの後にあるファイルのみをインポートします。
- それ以外の場合、ジョブが実行された時刻が次の実行のために保存されます。2回目以降の実行では、コネクタはその実行時刻以降にアルファベット順で変更されたファイルのみをインポートします。
td connector:createコマンドを使用して新しいスケジュールを作成できます。
td connector:create daily_import "10 0 * * *" \
td_sample_db td_sample_table load.ymlTreasure Dataのストレージは時間でパーティション化されているため、--time-columnオプションを指定することをお勧めします(data partitioningも参照してください)。
td connector:create daily_import "10 0 * * *" \
td_sample_db td_sample_table load.yml \
--time-column created_atcronパラメータは、@hourly、@daily、@monthlyの3つの特別なオプションも受け入れます。
デフォルトでは、スケジュールはUTCタイムゾーンで設定されます。-tまたは--timezoneオプションを使用して、タイムゾーンでスケジュールを設定できます。--timezoneオプションは、'Asia/Tokyo'、'America/Los_Angeles'などの拡張タイムゾーン形式のみをサポートします。PST、CSTなどのタイムゾーンの略語はサポートされておらず、予期しないスケジュールにつながる可能性があります。
td connector:listコマンドを実行すると、現在スケジュールされているエントリのリストを確認できます。
td connector:listtd connector:show daily_importNametd connector:historyはスケジュールエントリの実行履歴を表示します。各実行の結果を調査するには、td job jobidを使用してください。
td connector:historytd connector:deleteはスケジュールを削除します。
td connector:delete daily_importconnector:guessおよびconnector:issueコマンドで使用されるYML設定ファイルに指定されたIAM認証情報は、アクセスする必要があるAWS S3リソースに対する権限を持っている必要があります。IAMユーザーがこれらの権限を持っていない場合は、事前定義されたポリシー定義のいずれかでユーザーを設定するか、JSON形式で新しいポリシー定義を作成してください。
以下の例は、Policy Definition reference形式に基づいています。これは、IAMユーザーに「your-bucket」への読み取り専用権限(GetObjectおよびListBucketアクション経由)を与えます。
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"s3:GetObject",
"s3:ListBucket"
],
"Resource": [
"arn:aws:s3:::your-bucket",
"arn:aws:s3:::your-bucket/*"
]
}
]
}「your-bucket」を実際のS3バケット名に置き換えてください。
特定の場合において、access_key_idとsecret_access_keyによるIAM基本認証はリスクが高すぎる可能性があります(ジョブの実行時やセッションの作成後にsecret_access_keyが明示的に表示されることはありませんが)。
S3データコネクタは、AWS Secure Token Service (STS)を使用してTemporary Security Credentialsを提供できます。AWS STSを使用すると、任意のIAMユーザーが自身のaccess_key_idとsecret_access_keyを使用して、特定の有効期限を持つ以下の一時キーを作成できます:
- new_access_key_id
- new_secret_access_key
- session_token keys
以下はTemporary Security Credentialsのタイプです:
有効期限が指定された最もシンプルなSecurity Credentialsです。temporary credentialsは、それを生成したIAMユーザーと同じアクセス権を持ちます。これらのcredentialsは、有効期限が切れておらず、元のIAMユーザーの権限が変更されていない限り有効です。
これは上記のSession Tokenに対して追加の権限制御レイヤーを追加します。Federation Tokenを生成する際、IAMユーザーはPermission Policy定義を指定する必要があります。このスコープを使用して、Federation Tokenの所有者がアクセスできるリソースを制限できます(トークンを付与するIAMユーザーのアクセス権より少なくすることができます)。任意のPermission Policy定義を使用できますが、権限のスコープはトークンを生成したIAMユーザーの権限と同じか、そのサブセットに制限されます。Session Tokenと同様に、Federation Token credentialsは有効期限が切れておらず、元のIAM credentialsに関連付けられた権限が変更されていない限り有効です。
AWS STS Temporary Security Credentialsは、AWS CLIまたは任意の言語のAWS SDKを使用して生成できます。
aws sts get-session-token --duration-seconds 900この例では、
temp_credsはFederated tokenまたはユーザーのtemp credentialsの名前です。bucketnameはアクセスが許可されるS3バケットの名前です。(詳細についてはARN specificationを参照してください)s3:GetObjectとs3:ListBucketはAWS S3バケットの基本的な読み取り操作です。
aws sts get-federation-token --name temp_creds --duration-seconds 900 \
--policy '{"Statement": [{"Effect": "Allow", "Action": ["s3:GetObject", "s3:ListBucket"], "Resource": "arn:aws:s3:::bucketname"}]}'AWS STS credentialsは取り消すことができません。有効期限が切れるか、credentialsを生成するために使用した元のIAMユーザーの権限を削除または取り消すまで有効です。
Temporary Security Credentialsが生成されたら、seed.ymlファイルにSecretAccessKey、AccessKeyId、SessionTokenを含め、通常通りS3用のData Connectorを実行します。
in:
type: s3_v2
auth_method: session
access_key_id: XXXXXXXXXX
secret_access_key: YYYYYYYYYY
session_token: ZZZZZZZZZZ
bucket: sample_bucket
path_prefix: path/to/sample_fileSTS credentialsは指定された時間後に有効期限が切れるため、credentialを使用するdata connector jobは最終的に失敗し始める可能性があります。現在、STS credentialsの有効期限が切れたと報告された場合、data connector jobは最大回数(5回)までリトライし、最終的に「error」のstatusで完了します。
インポートを確認するには、Validating Your Data Connector Jobsの手順を参照してください。
この機能により、TD console UIで定義された既存のauthenticationを再利用できます。
TD Consoleを使用したAWS S3からのインポートの手順に従ってauthenticationを作成します。
Integrations Hub > Authentications画面に移動します
保存されたAuthenticationをクリックします。
Authentication IDはブラウザのURLに表示される番号です
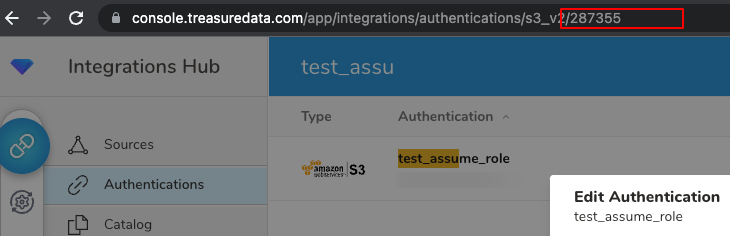
上記のAuthentication IDをconfig キーtd_authentication_idとして使用し、TD WorkflowまたはCLI(Toolbelt)の設定を作成します。
Authenticationを再利用した設定の例
+import_from_s3_assume_role_with_existing_connection:
td_load>: cfg_load.yml
database: test_db
table: test_tbl
## cfg_load.yml
in:
type: s3_v2
bucket: sample_bucket
path_prefix: path/to/sample_file
td_authentication_id: 287355
parser:
charset: UTF-8
newline: CRLF
type: csv
delimiter: ","
quote: "\""
escape: "\""
trim_if_not_quoted: false
skip_header_lines: 1
allow_extra_columns: false
allow_optional_columns: false
columns:
- name: col_1
type: string
- name: col_2
type: string
Seed設定の例(seed.yml)
in:
type: s3_v2
td_authentication_id: 287355
bucket: sample_bucket
path_prefix: path/to/sample_file