Amazon Redshift Export Integrationの詳細についてはこちらをご覧ください。
Amazon Redshiftに接続してTreasure Dataにデータをインポートできます。
- Redshiftインスタンスが作成されていること
- Treasure Data TD Toolbeltがインストールされていること
- Amazon Redshiftの基本的な知識
- Treasure Dataの基本的な知識(TD Toolbeltを含む)
データ接続を構成する際、統合にアクセスするための認証情報を提供します。Treasure Dataでは、認証を構成してからソース情報を指定します。
TD Consoleを開きます。
Integrations Hub > Catalogに移動します。
Catalog画面の右端にある検索アイコンをクリックし、Amazon Redshiftと入力します。
Amazon Redshiftコネクタにカーソルを合わせ、Create Authenticationを選択します。

必要な認証情報を指定します。 Host: ソースデータベースのホスト情報(IPアドレスなど) Port: ソースインスタンスの接続ポート。PostgreSQLのデフォルトは5432です。 User: ソースデータベースに接続するためのユーザー名 Password: ソースデータベースに接続するためのパスワード Use SSL: SSLを使用して接続する場合はこのボックスをチェックします JDBC Connection options: ソースデータベースで必要な特別なJDBC接続(オプション) Region: Redshiftインスタンスがホストされているリージョン Socket connection timeout: ソケット接続のタイムアウト(秒単位)(デフォルトは300) Network timeout: ネットワークソケット操作のタイムアウト(秒単位)。0はタイムアウトなしを意味します。 Rows per batch: 一度に取得する行数
必要な接続詳細を入力した後、Continueを選択します。
接続に名前を付けて、後で接続の詳細を変更する必要がある場合に見つけられるようにします。
オプションで、この接続を組織内の他のユーザーと共有する場合は、Share with othersを選択します。
Doneを選択します。
接続が成功すると、認証のリストに接続が表示されます。
認証された接続を作成すると、自動的にAuthenticationsに移動します。
作成した接続を検索します。
New Sourceを選択します。

Data Transfer フィールドにSourceの名前を入力します。
Nextをクリックします。
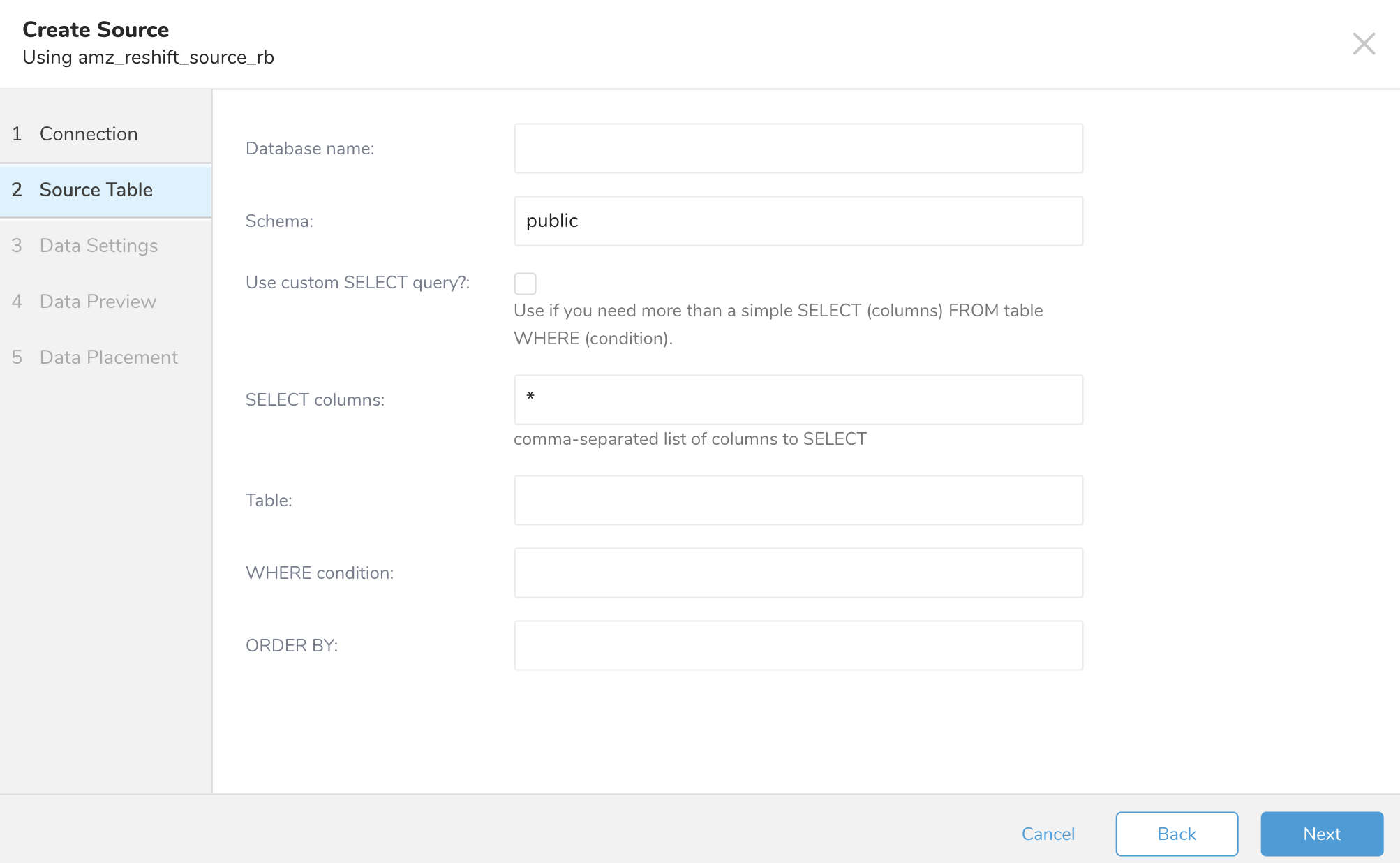
データをインポートするデータベースとテーブルの詳細を指定します。 Database name: データを転送するデータベースの名前(例:
your_database_name) Use custom SELECT query?: 単純なSELECT (columns) FROM table WHERE (condition)以上のものが必要な場合に使用します。 Schema: データを転送するスキーマ SELECT columns: 特定の列からのみデータを取得したい場合は、ここにリストします。それ以外の場合は、すべての列が転送されます。 Table: データをインポートするテーブル WHERE condition: テーブルから取得するデータにさらに詳細を指定する必要がある場合は、WHERE句の一部としてここで指定できます。 ORDER BY: 特定のフィールドでレコードを並べ替える必要がある場合に指定します。
Nextを選択します。 Data Settingsページが開きます。
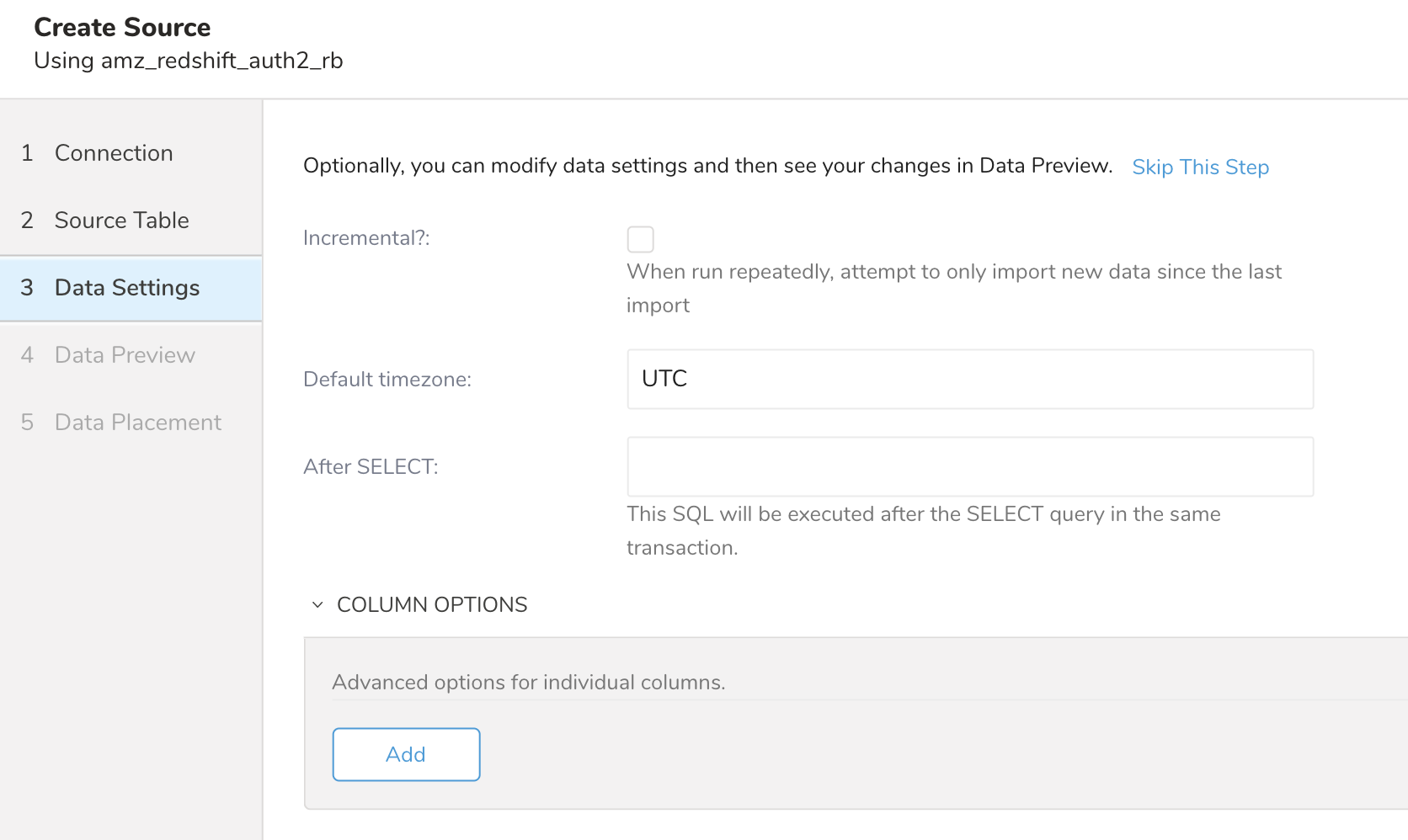
オプションで、データ設定を編集するか、ダイアログのこのページをスキップします。 Incremental: この転送を繰り返し実行する場合は、チェックボックスを使用して、前回のインポート実行以降のデータのみをインポートします。 Default timezone: インポート時に使用されるタイムゾーン。デフォルトはUTCです。 After SELECT: このSQLは、同じトランザクション内でSELECTクエリの後に実行されます。 Column Options: インポート前に列のタイプを変更する場合は、このオプションを選択します。
Nextを選択します。
インポートを実行する前に、Generate Preview を選択してデータのプレビューを表示できます。Data preview はオプションであり、選択した場合はダイアログの次のページに安全にスキップできます。
- Next を選択します。Data Preview ページが開きます。
- データをプレビューする場合は、Generate Preview を選択します。
- データを確認します。
データの配置について、データを配置したいターゲット database と table を選択し、インポートを実行する頻度を指定します。
Next を選択します。Storage の下で、インポートされたデータを配置する新しい database を作成するか、既存の database を選択し、新しい table を作成するか、既存の table を選択します。
Database を選択 > Select an existing または Create New Database を選択します。
オプションで、database 名を入力します。
Table を選択 > Select an existing または Create New Table を選択します。
オプションで、table 名を入力します。
データをインポートする方法を選択します。
- Append (デフォルト) - データインポートの結果は table に追加されます。 table が存在しない場合は作成されます。
- Always Replace - 既存の table の全体の内容をクエリの結果出力で置き換えます。table が存在しない場合は、新しい table が作成されます。
- Replace on New Data - 新しいデータがある場合のみ、既存の table の全体の内容をクエリの結果出力で置き換えます。
Timestamp-based Partition Key 列を選択します。 デフォルトキーとは異なるパーティションキーシードを設定したい場合は、long または timestamp 列をパーティショニング時刻として指定できます。デフォルトの時刻列として、add_time フィルターで upload_time を使用します。
データストレージの Timezone を選択します。
Schedule の下で、このクエリを実行するタイミングと頻度を選択できます。
- Off を選択します。
- Scheduling Timezone を選択します。
- Create & Run Now を選択します。
- On を選択します。
- Schedule を選択します。UI では、@hourly、@daily、@monthly、またはカスタム cron の 4 つのオプションが提供されます。
- Delay Transfer を選択して、実行時間の遅延を追加することもできます。
- Scheduling Timezone を選択します。
- Create & Run Now を選択します。
転送が実行された後、Data Workbench > Databases で転送の結果を確認できます。