Amazon S3のインポートデータコネクタにより、S3バケットに保存されているParquetファイルからデータをインポートできます。
| 認証方法 | Amazon S3 parquet |
|---|---|
| basic | x |
| session | x |
| assume_role | x |
前提条件
- Treasure Dataに関する基本的な知識。
TD リージョンと同じリージョンにある AWS S3 バケットを使用している場合、TD がバケットにアクセスする IP アドレスはプライベートで動的に変化します。アクセスを制限したい場合は、静的 IP アドレスではなく VPC の ID を指定してください。例えば、US リージョンの場合は vpc-df7066ba 経由でアクセスを設定し、Tokyo リージョンの場合は vpc-e630c182 経由、EU01 リージョンの場合は vpc-f54e6a9e 経由でアクセスを設定してください。
TD Console にログインする URL から TD Console のリージョンを確認し、URL 内のリージョンのデータコネクターを参照してください。
詳細については、API ドキュメントを参照してください。
セキュリティポリシーで IP ホワイトリストが必要な場合は、接続を成功させるために Treasure Data の IP アドレスを許可リストに追加する必要があります。
リージョンごとに整理された静的 IP アドレスの完全なリストは、次のリンクにあります: https://api-docs.treasuredata.com/en/overview/ip-addresses-integrations-result-workers/
Treasure Dataでは、最適なパフォーマンスを得るために、個々のparquetファイルのサイズを100 MB以下に制限することを推奨しています。ただし、これは厳密な要件ではなく、ニーズに合わせてパーティションサイズを調整できます。
TD Consoleを使用してデータコネクタを作成できます。
- TD Consoleを開きます。
- Integrations Hub > Catalogに移動します。
- S3 parquetを検索し、Amazon S3 parquetを選択します。
- Create Authenticationを選択します。
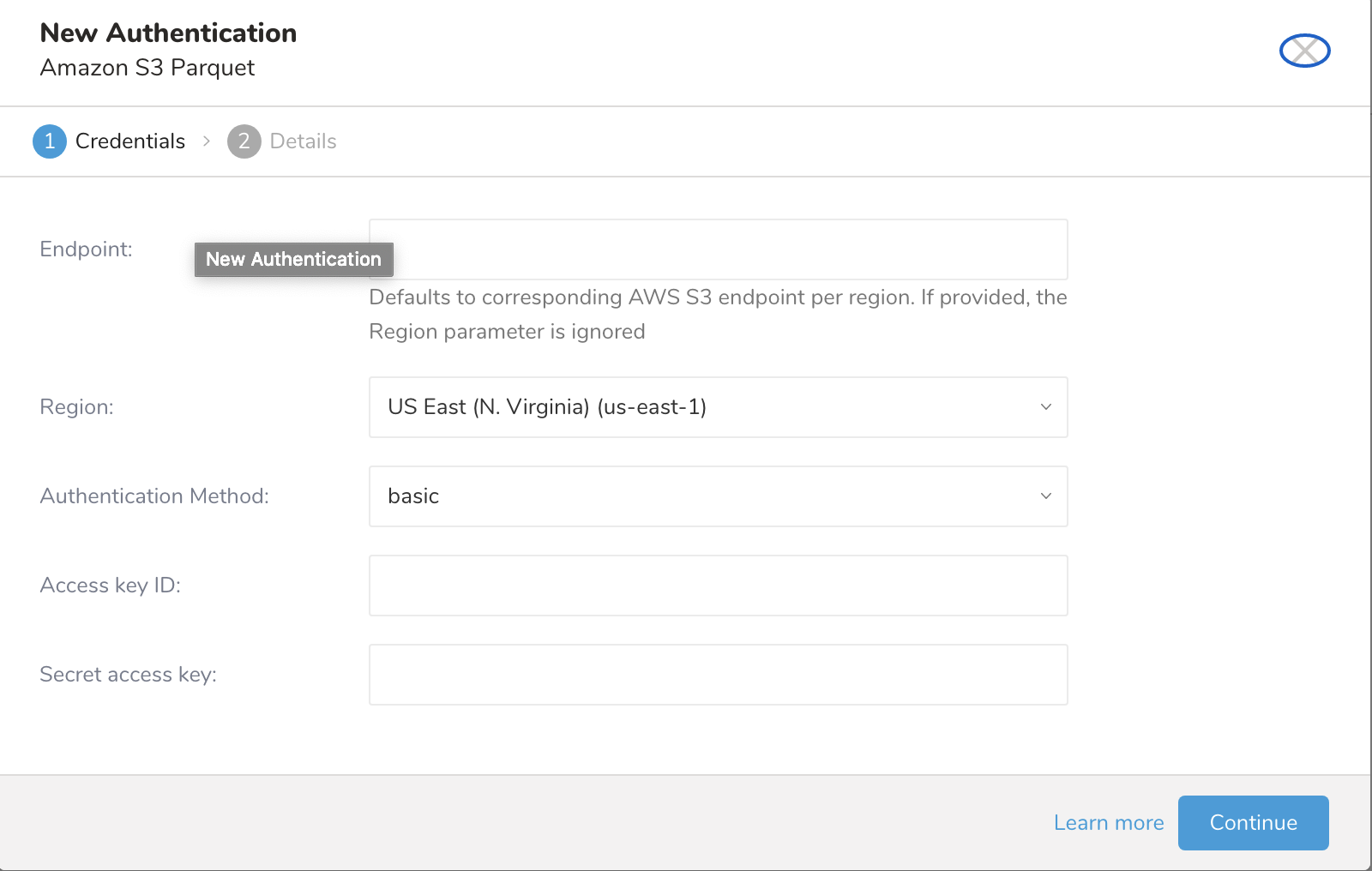
New Authenticationダイアログが開きます。選択した認証方法によって、ダイアログは次のような画面になります:
basic
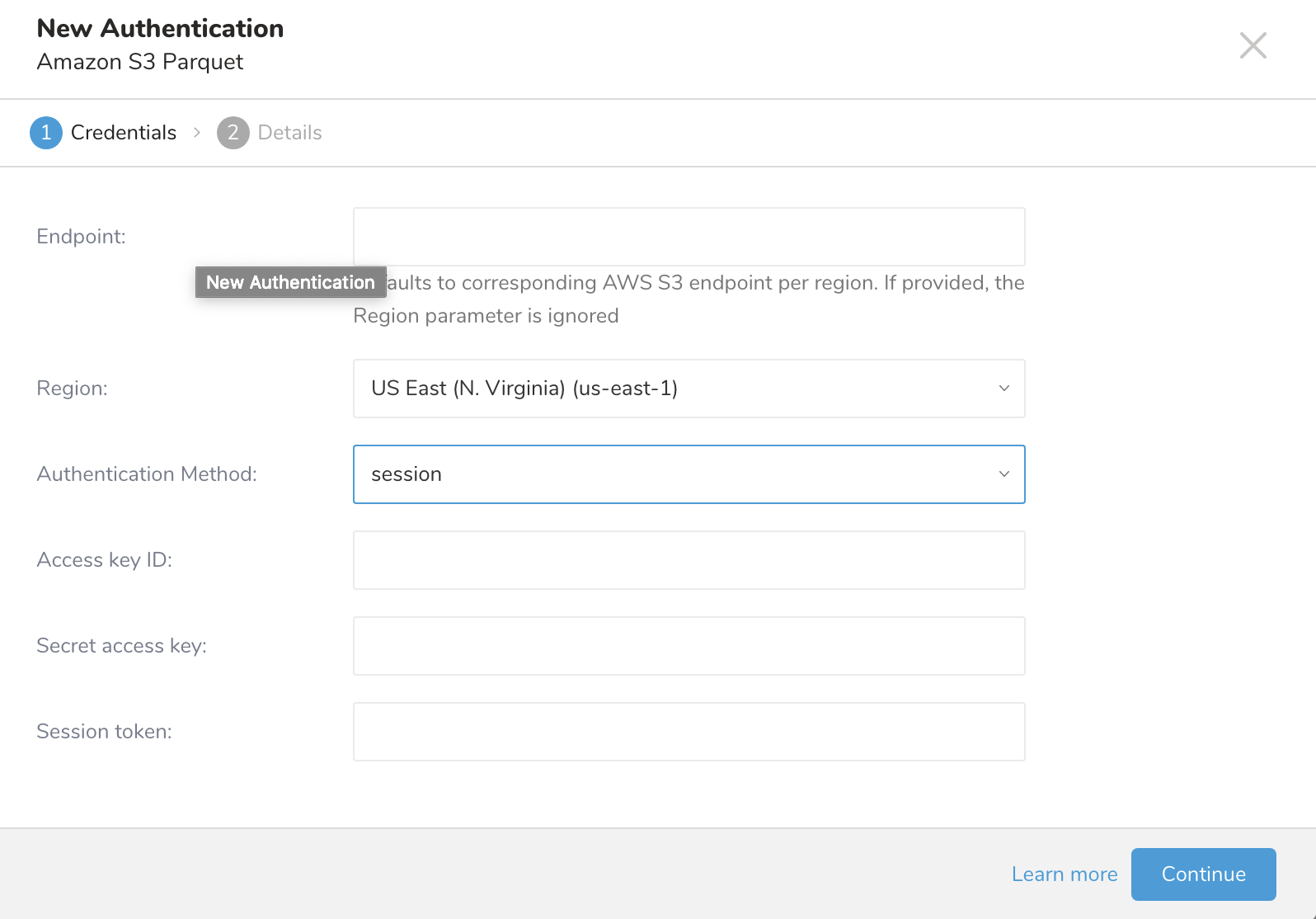
session
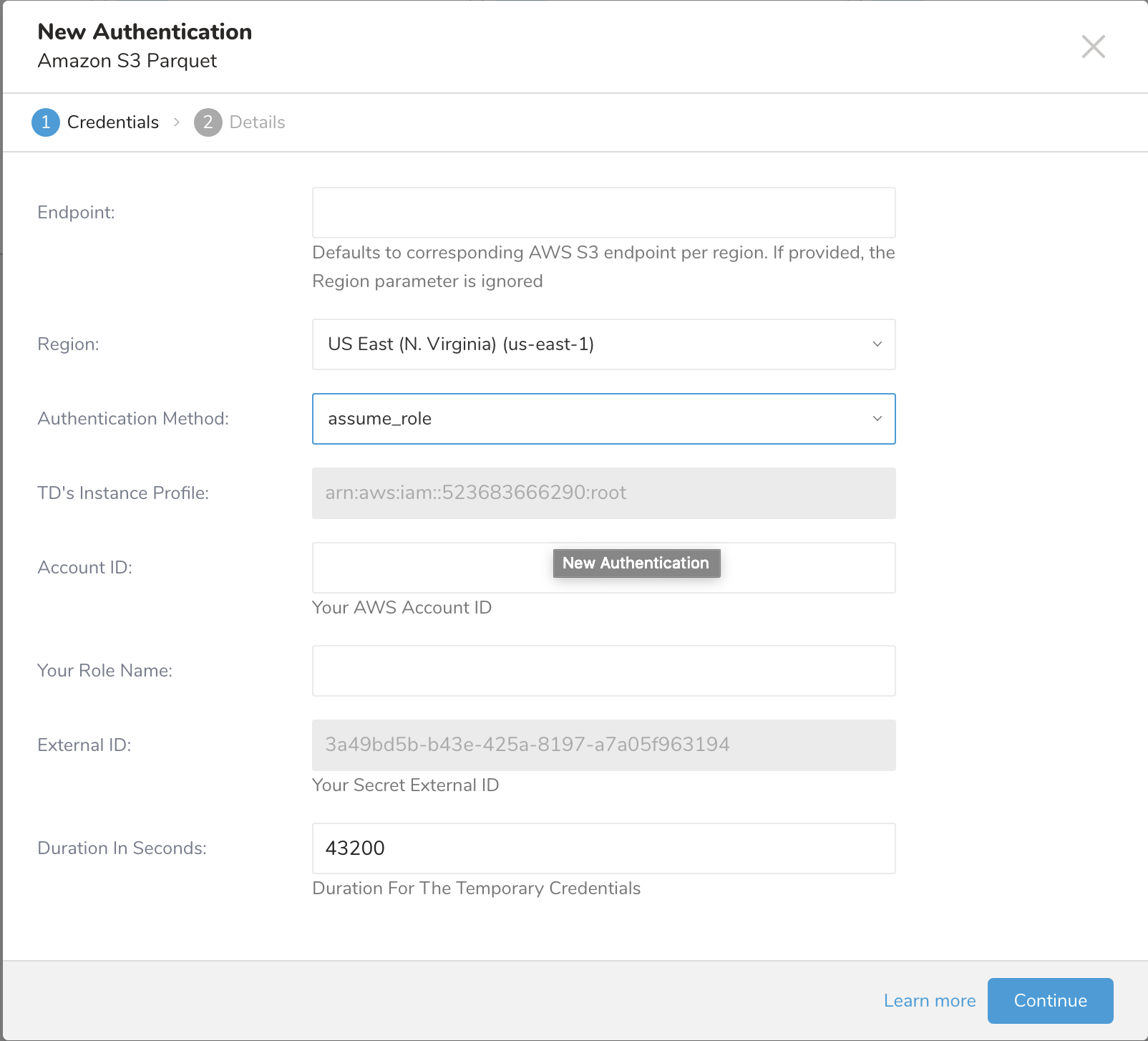
assume_role
- 認証フィールドを設定し、Continueを選択します。
| Parameter | Description |
|---|---|
| Endpoint | S3サービスエンドポイントのオーバーライド。リージョンとエンドポイント情報はAWS service endpointsで確認できます。(例: s3.ap-northeast-1.amazonaws.com) 指定すると、リージョン設定を上書きします。 |
| リージョン | AWSリージョン |
| 認証方式 | |
| basic |
|
| session (推奨) |
|
| assume_role |
|
| anonymous | サポートされていません |
| アクセスキーID | AWS S3が発行 |
| シークレットアクセスキー | AWS S3が発行 |
| セッショントークン | お客様の一時的なAWSセッショントークン |
| TDのインスタンスプロファイル | この値はTDコンソールによって提供されます。値の数値部分は、IAMロールを作成する際に使用するアカウントIDを構成します。 |
| Account ID | AWS Account ID |
| Your Role Name | AWS Role 名 |
| External ID | シークレット External ID |
| Duration | 一時的な認証情報の有効期間 |
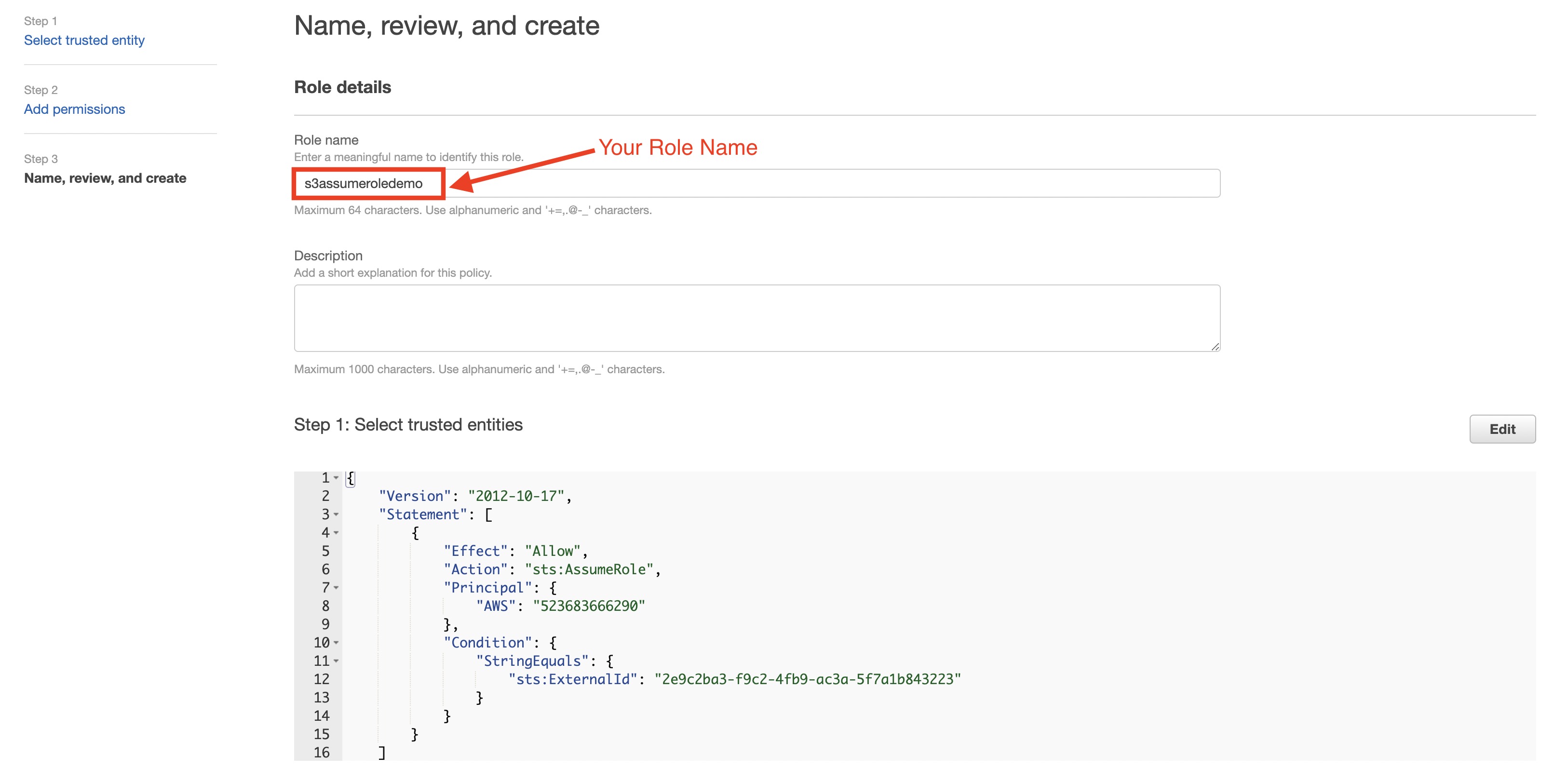
- 新しい AWS S3 接続に名前を付け、Done を選択します。
- assume_role 認証方式で新しい認証を作成します。
- TD's Instance Profile フィールドの値の数値部分をメモしておきます。
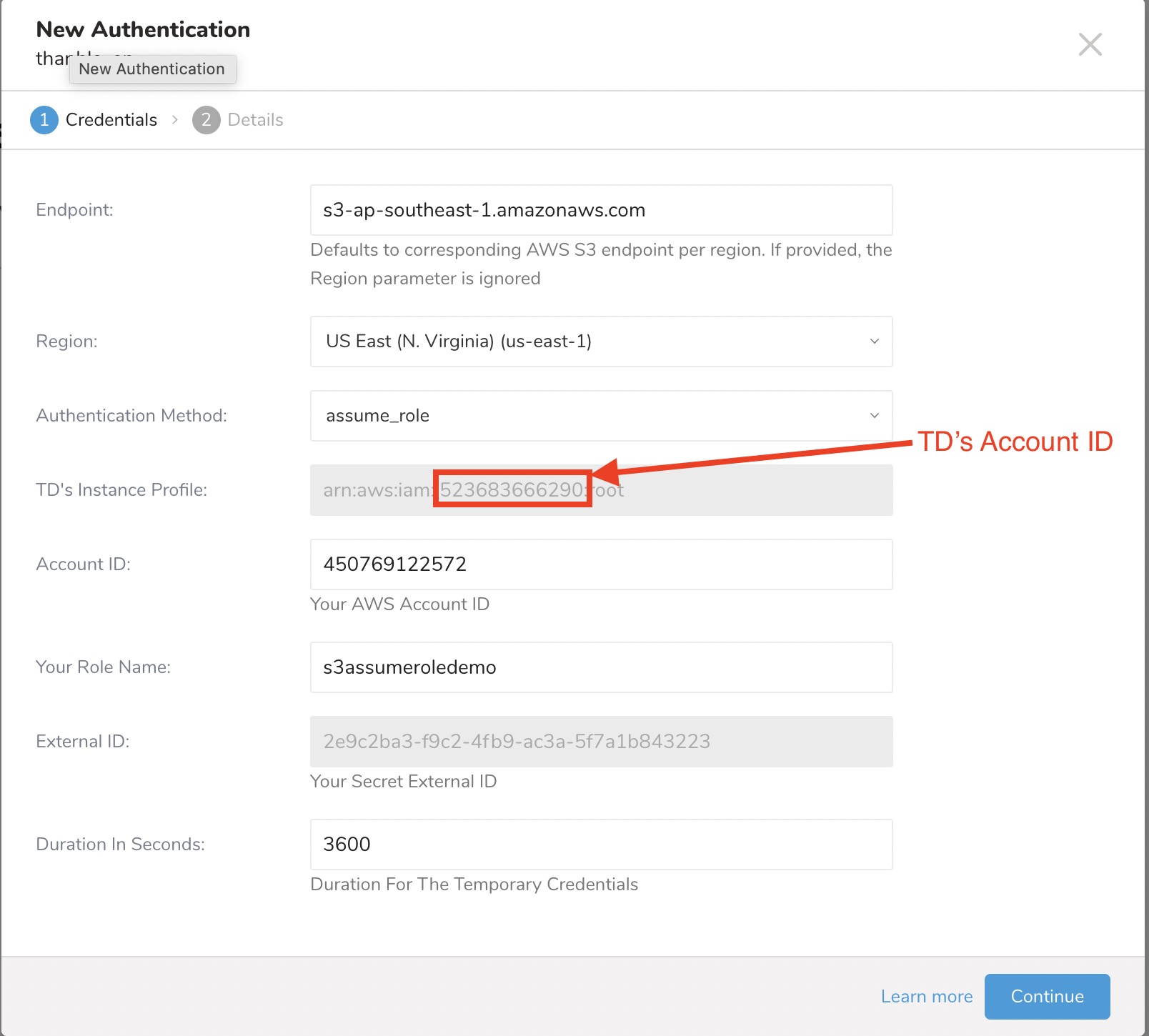
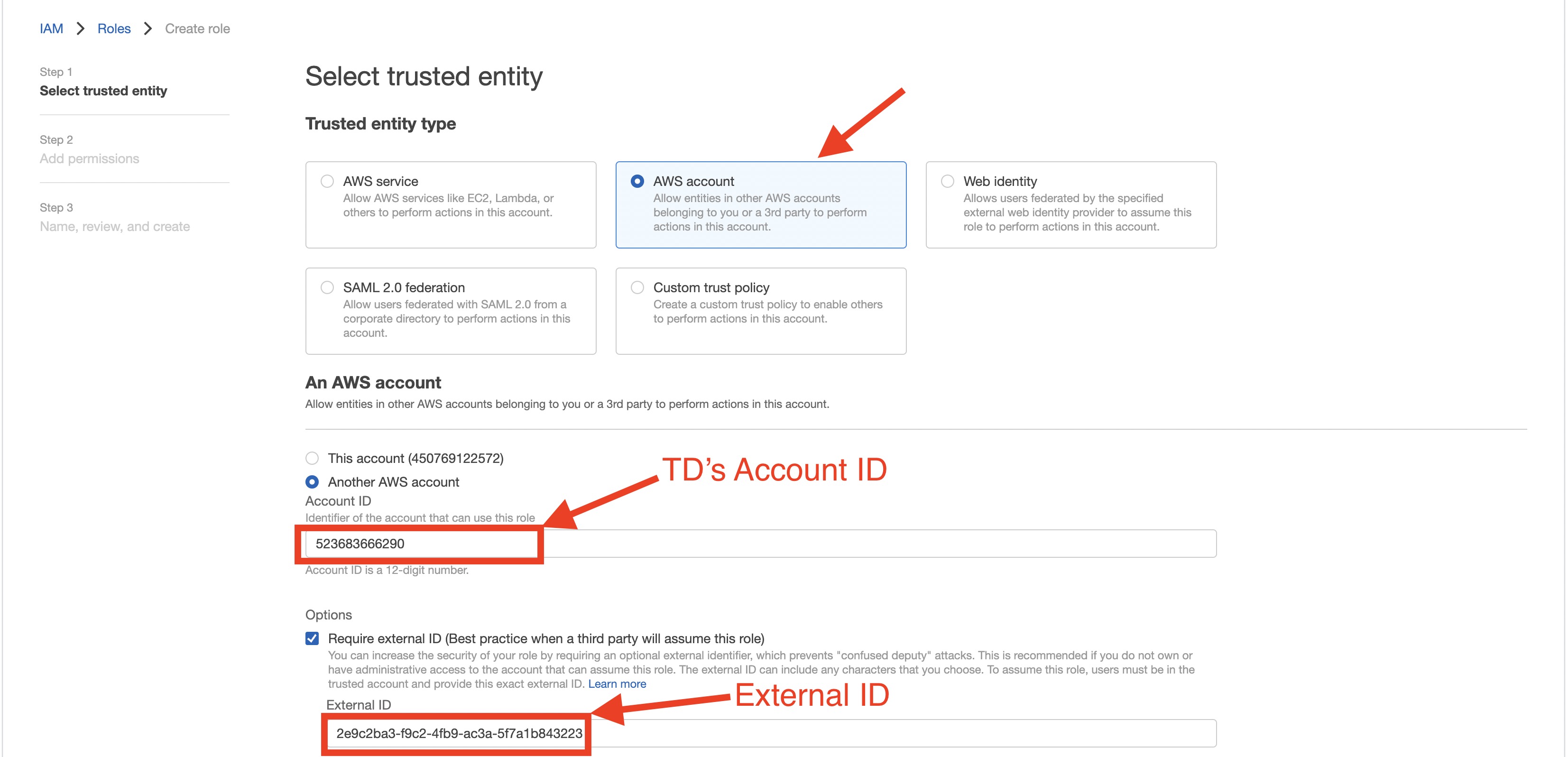
- AWS IAM role を作成します。
認証済み接続を作成すると、認証画面が表示されます。
- 作成した接続を検索します。
- New Source を選択します。
- Data Transfer フィールドで Source の名前を入力します。
- Next をクリックします。
Source ダイアログが開きます。
- 以下のパラメータを編集します。
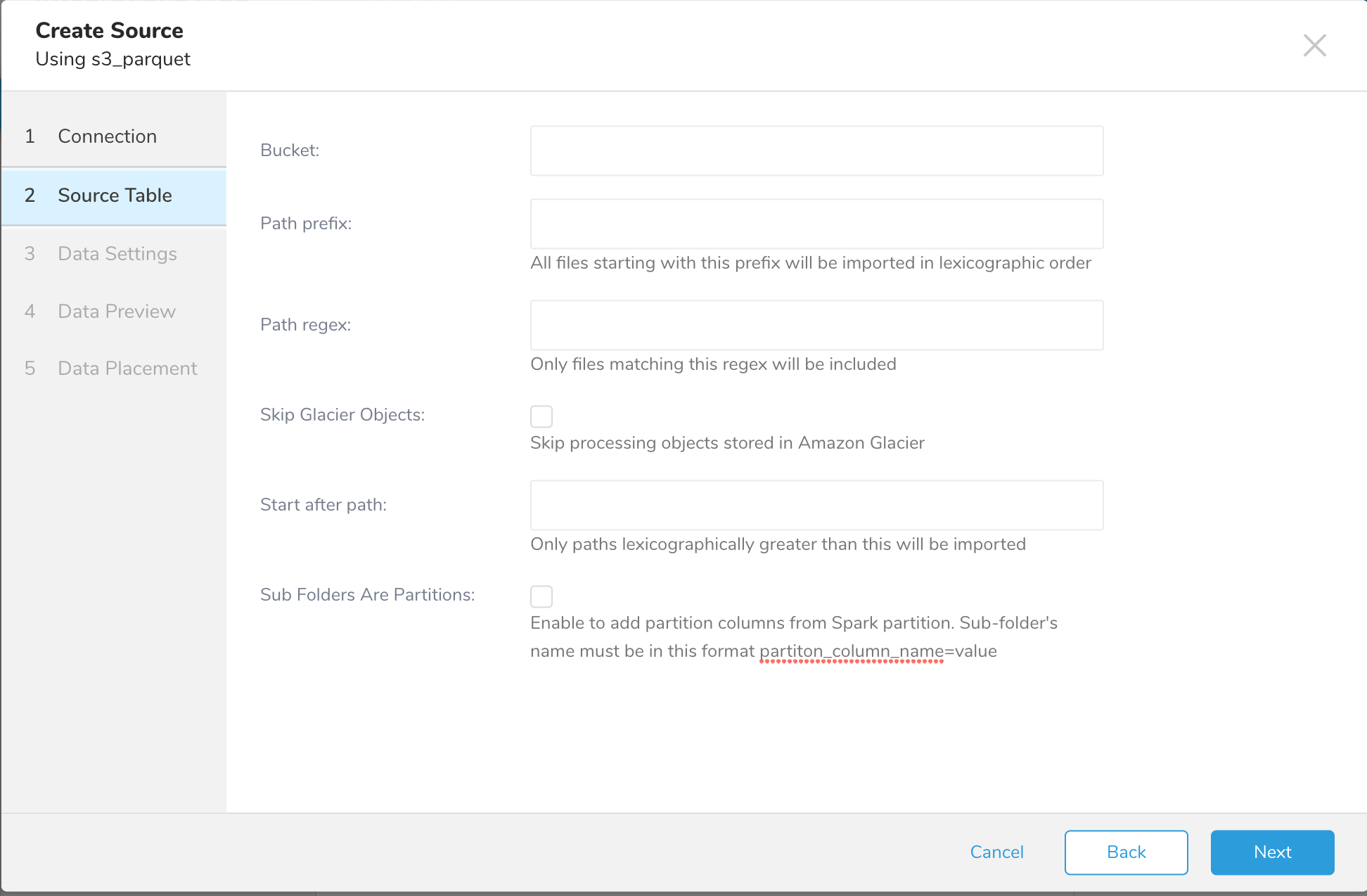
| Parameters | Description |
|---|---|
| Bucket | S3バケット名(例:your_bucket_name) |
| Path Prefix | ターゲットキーのプレフィックス(例:logs/data_) |
| Path Regex | ファイルパスに一致させる正規表現。ファイルパスが指定されたパターンに一致しない場合、そのファイルはスキップされます。例えば、.csvファイルのみに一致させたい場合、パターン .csv$ を入力すると、.csvで終わらないファイル名はすべてスキップされます。正規表現を参照してください。 |
| Skip Glacier Objects | Amazon Glacierストレージクラスに保存されているオブジェクトの処理をスキップします。オブジェクトがGlacierストレージクラスに保存されているにもかかわらず、このオプションがチェックされていない場合、例外がスローされます。 |
| Start after path | 辞書順でこれより長いパスのみがインポートされます。 |
| Sub Folders Are Partitions | Sparkパーティションからパーティション列を追加します。サブフォルダー名は次の形式である必要があります:partiton_column_name=value |
ディレクトリ内のすべてのファイルをスキャンする必要がある場合(トップレベルディレクトリ「/」からなど)があります。このような場合は、CLIを使用してインポートを行う必要があります。
例
EMRを設定して、次のようにファイル内のデータを含むparquetファイルを作成できます:
[your_bucket] - [YM=202010] - [E231A697YXWD39.2020-10-29-15.a103fd5a.parquet]
[your_bucket] - [YM=202010] - [E231A697YXWD39.2020-10-30-15.b2aede4a.parquet]
[your_bucket] - [YM=202010] - [E231A697YXWD39.2020-10-31-01.594fa8e6.parquet]この場合、ソーステーブルの設定は次のようになります:
- Bucket: your_bucket
- Path Prefix: YM=202010a/
- Path Regex: * (必須ではありません)
- Start after path: YM=202010/E231A697YXWD39.2020-10-29-15.a103fd5a.parquet
Nextを選択します。
Data Settingsページが開きます。
オプションで、データ設定を編集するか、このダイアログページをスキップします。
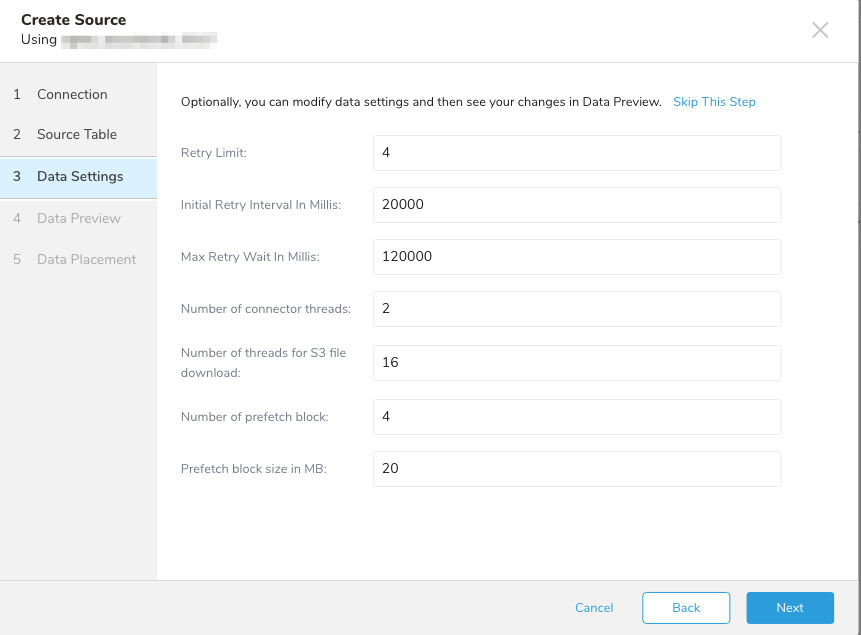
| Parameters | Description |
|---|---|
| Retry Limit | 最大リトライ回数 |
| Initial Retry Interval in Millis | 初期リトライ間隔(ミリ秒単位) |
| Max Retry Wait in Millis | 最大リトライ間隔。初回リトライ後、待機間隔はこの最大値に達するまで2倍になります。 |
| Number of connector threads | 並列処理可能なファイルハンドルの数 |
| Number of threads for S3 file downloads | ファイルのブロックをダウンロードするために使用できる接続数 |
| Number of prefetch block | 使用するプリフェッチブロックの数 |
| Prefetch block size in MB | プリフェッチブロックサイズ(MB単位で指定) |
Filters は、S3、FTP、または SFTP コネクターの Create Source または Edit Source インポート設定で使用できます。
Import Integration Filters を使用すると、インポート用のデータ設定の編集を完了した後、インポートされたデータを変更できます。
import integration filters を適用するには:
- Data Settings で Next を選択します。Filters ダイアログが開きます。
- 追加したいフィルターオプションを選択します。
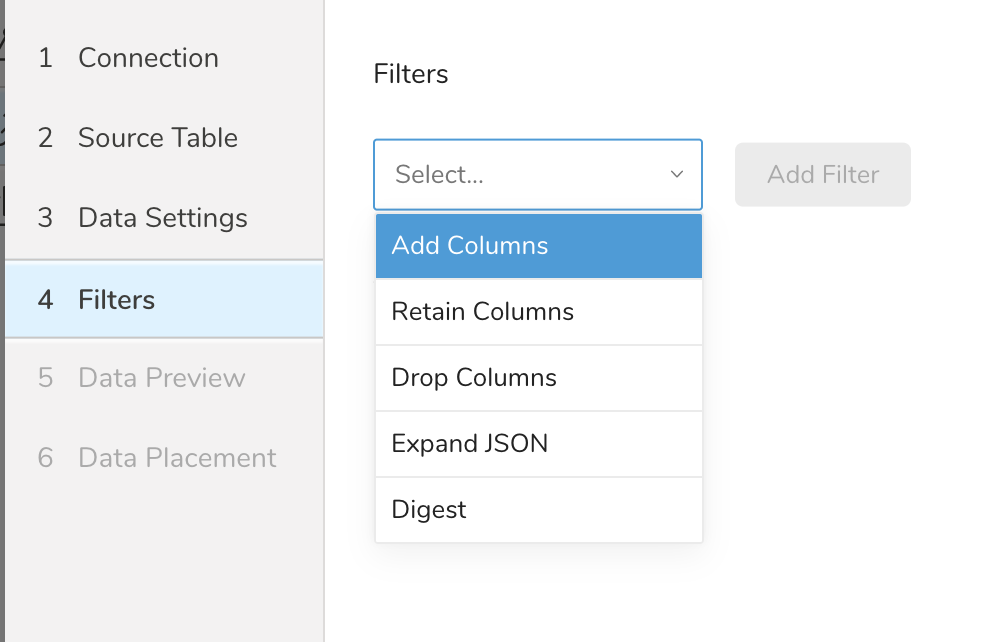
- Add Filter を選択します。そのフィルターのパラメーターダイアログが開きます。
- パラメーターを編集します。各フィルタータイプの情報については、次のいずれかを参照してください:
- Retaining Columns Filter
- Adding Columns Filter
- Dropping Columns Filter
- Expanding JSON Filter
- Digesting Filter
- オプションで、同じタイプの別のフィルターを追加するには、特定の列フィルターダイアログ内で Add を選択します。
- オプションで、別のタイプの別のフィルターを追加するには、リストからフィルターオプションを選択して、同じ手順を繰り返します。
- 追加したいフィルターを追加した後、Next を選択します。Data Preview ダイアログが開きます。
インポートを実行する前に、Generate Preview を選択してデータのプレビューを表示できます。Data preview はオプションであり、選択した場合はダイアログの次のページに安全にスキップできます。
- Next を選択します。Data Preview ページが開きます。
- データをプレビューする場合は、Generate Preview を選択します。
- データを確認します。
データの配置について、データを配置したいターゲット database と table を選択し、インポートを実行する頻度を指定します。
Next を選択します。Storage の下で、インポートされたデータを配置する新しい database を作成するか、既存の database を選択し、新しい table を作成するか、既存の table を選択します。
Database を選択 > Select an existing または Create New Database を選択します。
オプションで、database 名を入力します。
Table を選択 > Select an existing または Create New Table を選択します。
オプションで、table 名を入力します。
データをインポートする方法を選択します。
- Append (デフォルト) - データインポートの結果は table に追加されます。 table が存在しない場合は作成されます。
- Always Replace - 既存の table の全体の内容をクエリの結果出力で置き換えます。table が存在しない場合は、新しい table が作成されます。
- Replace on New Data - 新しいデータがある場合のみ、既存の table の全体の内容をクエリの結果出力で置き換えます。
Timestamp-based Partition Key 列を選択します。 デフォルトキーとは異なるパーティションキーシードを設定したい場合は、long または timestamp 列をパーティショニング時刻として指定できます。デフォルトの時刻列として、add_time フィルターで upload_time を使用します。
データストレージの Timezone を選択します。
Schedule の下で、このクエリを実行するタイミングと頻度を選択できます。
- Off を選択します。
- Scheduling Timezone を選択します。
- Create & Run Now を選択します。
- On を選択します。
- Schedule を選択します。UI では、@hourly、@daily、@monthly、またはカスタム cron の 4 つのオプションが提供されます。
- Delay Transfer を選択して、実行時間の遅延を追加することもできます。
- Scheduling Timezone を選択します。
- Create & Run Now を選択します。
転送が実行された後、Data Workbench > Databases で転送の結果を確認できます。
ジョブログを確認してください。警告とエラーは、インポートの成功に関する情報を提供します。例えば、インポートエラーに関連する source ファイル名を特定できます。
特定のジョブの詳細を確認するには、そのジョブを選択して詳細を表示します。ジョブのタイプに応じて、次のいずれか、またはすべてを確認できます: 結果、クエリ、出力ログ、エンジンログ、詳細、および宛先。
- TD Console を開きます。
- Jobs に移動します。ページの右上に記載されているジョブの数を確認できます。
 3. オプションで、フィルターを使用してジョブのリストを絞り込み、ジョブ所有者、日付、database 名などでフィルタリングして、関心のあるものを見つけます。 4. ジョブを選択して開き、結果、クエリ定義、ログ、その他の詳細を表示します。
3. オプションで、フィルターを使用してジョブのリストを絞り込み、ジョブ所有者、日付、database 名などでフィルタリングして、関心のあるものを見つけます。 4. ジョブを選択して開き、結果、クエリ定義、ログ、その他の詳細を表示します。
 5. 各タブには、ジョブに関する異なる情報が表示されます。
5. 各タブには、ジョブに関する異なる情報が表示されます。
| タブ名 | 説明 |
|---|---|
| Results |
|
| Query |
|
| Output および Engine Logs |
|
| Details | 詳細情報を表示します:
|
| Destination | ここでは、エクスポート integration 設定の詳細を表示できます(インポート integration には適用されません): - integration - タイプ - 設定 |
Parquetファイル形式は、ディスクストレージの効率を最適化するために設計された、プリミティブ型と呼ばれる最小限のデータ型を使用します。一方、論理型は、プリミティブ型がどのように解釈されるべきかを指定することで、型を拡張するために使用されます。インポートされると、これらの型はTDでサポートされているデータ型に変換されます。
| Parquet data type | Type mapping when import to TD |
|---|---|
| Primitive types | |
| boolean | boolean |
| boolean | boolean |
| int32 | long |
| int64 | double |
| int96 | string |
| float, double | double |
| byte_array, fixed_len_byte_array | string |
| Logical types | |
| byte type, short type, integer type, long type | long |
| float type, double type | double |
| decimal | string |
| array type | string |
| map, struct | json |
| string type, binary type | string |
オプションとして、TD Toolbeltを使用して接続の設定、ジョブの作成、およびジョブ実行のスケジュール設定を行うことができます。統合をセットアップする前に、最新バージョンのTD Toolbeltがインストールされていることを確認してください。
以下の例に示すように、AWSアクセスキーを使用してseed.ymlファイルを設定します。また、バケット名とソースファイル名を指定する必要があります。オプションで、複数のファイルにマッチさせるためにpath_prefixを指定できます。以下の例では、path_prefix: path/to/sample_fileは次のファイルにマッチします
path/to/sample_201501.parquetpath/to/sample_201502.parquetpath/to/sample_201505.parquetetc.
先頭に'/'を付けたpath_prefixを使用すると、意図しない結果になる可能性があります。例:「path_prefix: /path/to/sample_file」とすると、プラグインはs3://sample_bucket//path/to/sample_fileのファイルを探すことになり、これはS3上でs3://sample_bucket/path/to/sample_fileという意図したパスとは異なります。
in:
type: s3_parquet
access_key_id: XXXXXXXXXX
secret_access_key: YYYYYYYYYY
bucket: sample_bucket
# s3バケット上の*.parquetファイルへのパス
path_prefix: path/to/sample_file
path_match_pattern: \.parquet$ # このパターンにマッチしないファイルはスキップされます
## 正規表現の例:
#path_match_pattern: /archive/ # .../archive/...ディレクトリ内のファイルにマッチ
#path_match_pattern: /data1/|/data2/ # .../data1/...または.../data2/...ディレクトリ内のファイルにマッチ
out:
mode: append既存の認証を再利用する場合は、td_authentication_id コンフィグキーの値にAuthentication IDを設定します。これはassume-role認証方式に必要です。既存の認証の再利用を参照してください。
in:
type: s3_qarquet
td_authentication: xxxx
bucket: sample_bucket
path_prefix: path/to/sample_file
out:
mode: appendconnector:guess は自動的にソースファイルを読み取り、ファイル形式、フィールド、カラムを評価します。
td connector:guess seed.yml -o load.ymlload.yml ファイルを確認すると、ファイル形式、エンコーディング、カラム名、型を含む「推測された」ファイル形式定義を確認できます。
in:
type: s3_parquet
access_key_id: XXXXXXXXXX
secret_access_key: YYYYYYYYYY
bucket: sample_bucket
path_prefix: path/to/sample_file
out:
mode: appendロードジョブを送信します。データのサイズによっては数時間かかる場合があります。データを保存する Treasure Data のデータベースとテーブルを指定します。
Treasure Data のストレージは時間によってパーティション分割されているため、--time-column オプションを指定することを推奨します(データパーティショニング を参照)。このオプションが指定されていない場合、データコネクタは最初の long または timestamp カラムをパーティショニング時間として選択します。--time-column で指定するカラムの型は、long または timestamp のいずれかである必要があります。
データに時間カラムがない場合は、add_time フィルタオプションを使用して時間カラムを追加できます。詳細については、add_time フィルタ機能 を参照してください。
td connector:issue load.yml --database td_sample_db --table td_sample_table \
--time-column created_at以下の例では、connector:issue コマンドは、database(td_sample_db) と table(td_sample_table) がすでに作成されていることを前提としています。Treasure Data にデータベースまたはテーブルが存在しない場合、このコマンドは失敗します。データベースとテーブルを手動で作成するか、td connector:issue コマンドで --auto-create-table オプションを使用してデータベースとテーブルを自動作成してください:
td connector:issue load.yml --database td_sample_db --table td_sample_table --time-column created_at --auto-create-tableデータコネクタはサーバー側でレコードをソートしません。時間ベースのパーティショニングを効果的に使用するには、事前にファイル内のレコードをソートしてください。
time というフィールドがある場合は、--time-column オプションを指定する必要はありません。
$ td connector:issue load.yml --database td_sample_db --table td_sample_tableYML 設定ファイルで指定された IAM 認証情報は、connector:guess および connector:issue コマンドで使用され、アクセスする必要のある AWS S3 リソースに対する権限が必要です。IAM ユーザーがこれらの権限を持っていない場合は、定義済みのポリシー定義のいずれかでユーザーを設定するか、JSON 形式で新しいポリシー定義を作成してください。
以下の例は、ポリシー定義リファレンス形式 に基づいています。これにより、IAM ユーザーに「your-bucket」に対する 読み取り専用 権限(GetObject および ListBucket アクションを通じて)が付与されます。
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"s3:GetObject",
"s3:ListBucket"
],
"Resource": [
"arn:aws:s3:::your-bucket",
"arn:aws:s3:::your-bucket/*"
]
}
]
}"your-bucket" を実際のS3バケット名に置き換えてください。
特定のケースでは、access_key_idとsecret_access_keyを通じたIAM基本認証はリスクが高すぎる可能性があります(ジョブの実行時やセッション作成後にsecret_access_keyが明確に表示されることはありませんが)。
S3データコネクタは、AWS Secure Token Service (STS) を使用して一時的なセキュリティ認証情報を提供できます。AWS STSを使用すると、任意のIAMユーザーが自身のaccess_key_idとsecret_access_keyを使用して、特定の有効期限を持つこれらの一時キーを作成できます:
- new_access_key_id
- new_secret_access_key
- session_tokenキー
以下は一時的なセキュリティ認証情報のタイプです:
指定された有効期限を持つ最もシンプルなセキュリティ認証情報です。一時的な認証情報は、それらを生成したIAMユーザーと同じアクセス権を持ちます。これらの認証情報は、有効期限が切れておらず、元のIAMユーザーの権限が変更されていない限り有効です。
これは上記のSession Tokenに対して追加の権限制御レイヤーを追加します。Federation Tokenを生成する際、IAMユーザーはPermission Policy定義を指定する必要があります。スコープは、Federation Tokenの保有者がアクセスできるリソースを制限するために使用できます(権限を付与するIAMユーザーのアクセス権より少ない場合があります)。任意のPermission Policy定義を使用できますが、権限のスコープは、トークンを生成したIAMの権限と同じか、そのサブセットに制限されます。Session Tokenと同様に、Federation Token認証情報は、有効期限が切れておらず、元のIAM認証情報に関連する権限が変更されていない限り有効です。
AWS STS一時的なセキュリティ認証情報は、AWS CLIまたはお好みの言語のAWS SDKを使用して生成できます。
$ aws sts get-session-token --duration-seconds 900この例では、
temp_credsはFederated tokenまたはユーザーの一時認証情報の名前です。bucketnameはアクセスが許可されているS3バケットの名前です(詳細についてはARN仕様を参照してください)。s3:GetObjectとs3:ListBucketはAWS S3バケットの基本的な読み取り操作です。
$ aws sts get-federation-token --name temp_creds --duration-seconds 900 \
--policy '{"Statement": [{"Effect": "Allow", "Action": ["s3:GetObject", "s3:ListBucket"], "Resource": "arn:aws:s3:::bucketname"}]}'AWS STS認証情報は取り消すことができません。有効期限が切れるまで、または認証情報の生成に使用された元のIAMユーザーの権限を削除または取り消すまで、有効なままです。
一時的なセキュリティ認証情報が生成されたら、seed.yml ファイルに SecretAccessKey、AccessKeyId、および SessionToken を含めて、通常どおりData Connector for S3を実行します。
in:
type: s3_parquet
auth_method: session
access_key_id: XXXXXXXXXX
secret_access_key: YYYYYYYYYY
session_token: ZZZZZZZZZZ
bucket: sample_bucket
path_prefix: path/to/sample_fileSTS認証情報は指定された時間が経過すると有効期限が切れるため、その認証情報を使用するデータコネクタジョブは最終的に失敗し始める可能性があります。現在、STS認証情報の有効期限が切れたと報告された場合、データコネクタジョブは最大回数(5回)まで再試行し、最終的に「error」のステータスで完了します。
インポートを確認するには、データコネクタジョブの検証の手順を参照してください。
- 定期的な実行については、TD Toolbeltを使用したスケジューリングを参照してください
- 作成したSourceをワークフローからトリガーするには、IntegrationでTD Workflowを使用するを参照してください
コネクタジョブが取り込んでいるS3ファイルの数を確認してください。10,000ファイルを超える場合、パフォーマンスが低下します。この問題を軽減するには、次の方法があります:
- path_prefixオプションを絞り込んで、S3ファイルの数を減らす
- min_task_sizeオプションを268,435,456(256MB)に設定する
1ファイルあたり1つのrow_groupではなく、多くのrow_groupsを持つファイルを提供する
1か所に多数のファイルがある場合は、パラメータPath PrefixとPath Regexを使用して複数のジョブに分割してください。 各ジョブは20〜40ファイルにする必要があります。
例:
path_prefix: folder/sub_folderpath_match_pattern: folder/sub_folder/regrex