Amazon Simple Storage Service (Amazon S3)は、スケーラビリティ、データの可用性、セキュリティ、パフォーマンスを提供するオブジェクトストレージサービスです。Amazon S3は、ビジネス、組織、コンプライアンス要件に対応するデータ編成とアクセス制御の構成機能を提供します。
このTD export integrationを使用すると、Treasure Dataからジョブ結果を直接Amazon S3に書き込むことができます。
- データの保存: バケットに無制限のデータを保存できます。
次の表の情報を確認して、v1では利用できないがv2で利用可能な機能を理解してください。
| Feature | Amazon S3 v2 | Amazon S3 v1 |
|---|---|---|
| AWS Key Management Serviceに保存されているCustomer Master Key (CMK)を使用したServer-side Encryption | X | |
| 出力データ形式のQuote Policyのサポート | X | |
| Assume Role認証方法のサポート | X |
- IAM Userの以下のAWS権限:
- s3:PutObject、s3:AbortMultipartUpload権限
- sse-kms設定を選択する場合のkms:Decrypt、kms:GenerateDataKey権限
- (オプション) Treasure Dataの基本的な知識(TD Toolbeltを含む)
- S3へのエクスポートのデフォルトのクエリ結果制限は100GBです。パートサイズ設定を最大5000 (MB)まで構成できます。ファイル制限は約5TBになります。
- デフォルトのエクスポート形式はCSV RFC 4180です。
- TSVおよびJSONL形式での出力もサポートされています。
- TLS v.1.2サポート
セキュリティポリシーで IP ホワイトリストが必要な場合は、接続を成功させるために Treasure Data の IP アドレスを許可リストに追加する必要があります。
リージョンごとに整理された静的 IP アドレスの完全なリストは、次のリンクにあります: https://api-docs.treasuredata.com/en/overview/ip-addresses-integrations-result-workers/
AWS S3 Server-Side Encryptionを使用してアップロードデータを暗号化できます。暗号化キーを準備する必要はありません。データは、256ビットAdvanced Encryption Standard (AES-256)でサーバー側で暗号化されます。
バケットに保存されているすべてのオブジェクトにサーバー側の暗号化が必要な場合は、Server-Side Encryptionバケットポリシーを使用してください。サーバー側の暗号化が有効になっている場合、SSEオプションをオンにする必要はありません。ただし、暗号化情報なしのHTTPリクエストを拒否するバケットポリシーがある場合、ジョブ結果が失敗する可能性があります。
Amazon S3-managed encryption keys (SSE-S3)を使用してアップロードデータを暗号化できます。
Amazon S3でサーバー側の暗号化にAWS KMSを有効にする場合:
- KMS Key IDを入力しない場合、デフォルトのKMSキーを使用(または作成)します。
- KMS Key IDを入力する場合は、対称CMK(非対称CMKではない)を選択する必要があります。
- AWS KMS CMKは、バケットと同じリージョンにある必要があります。
Treasure Dataでは、クエリを実行する前にデータ接続を作成して構成する必要があります。データ接続の一部として、統合にアクセスするための認証を提供します。
- TD Consoleを開きます。
- Integrations Hub > Catalogに移動します。
- S3 v2を検索し、Amazon S3 (v2)を選択します。
- Create Authenticationを選択します。
新しいAuthenticationダイアログが開きます。選択した認証方法に応じて、ダイアログは次の画面のいずれかのように表示される場合があります:
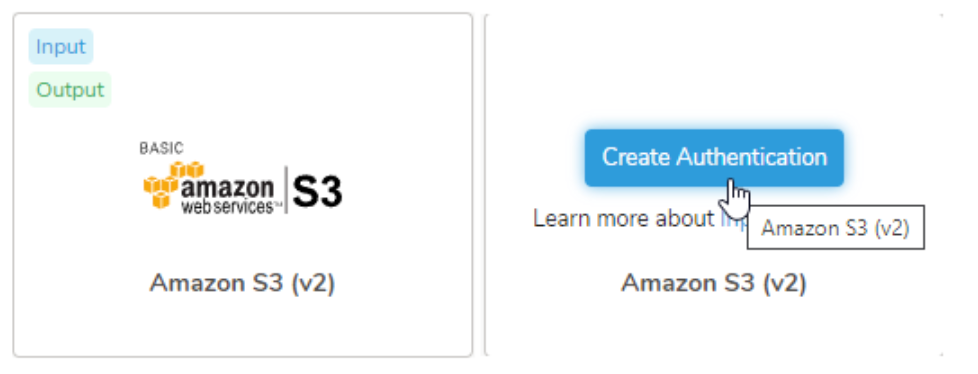
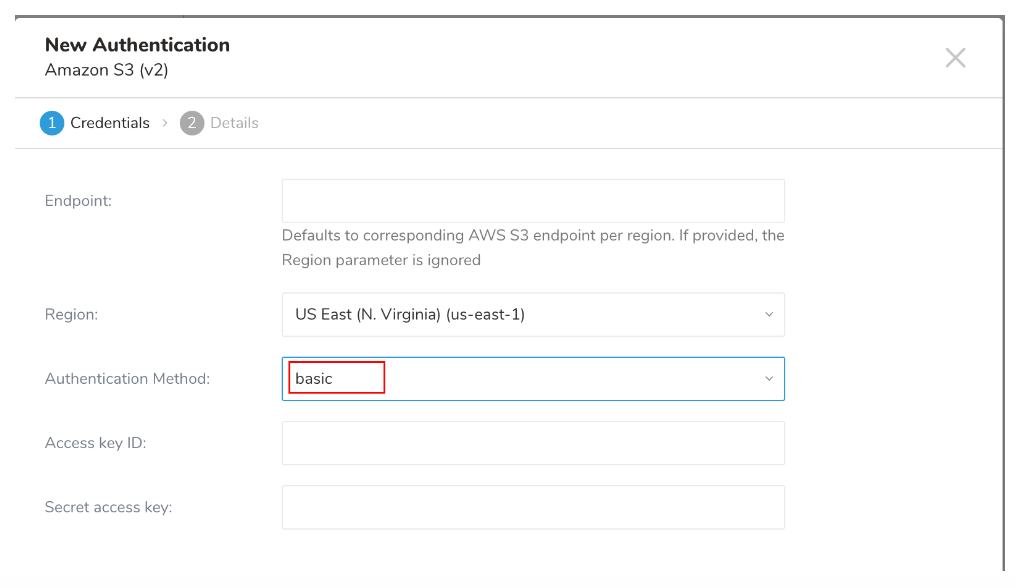
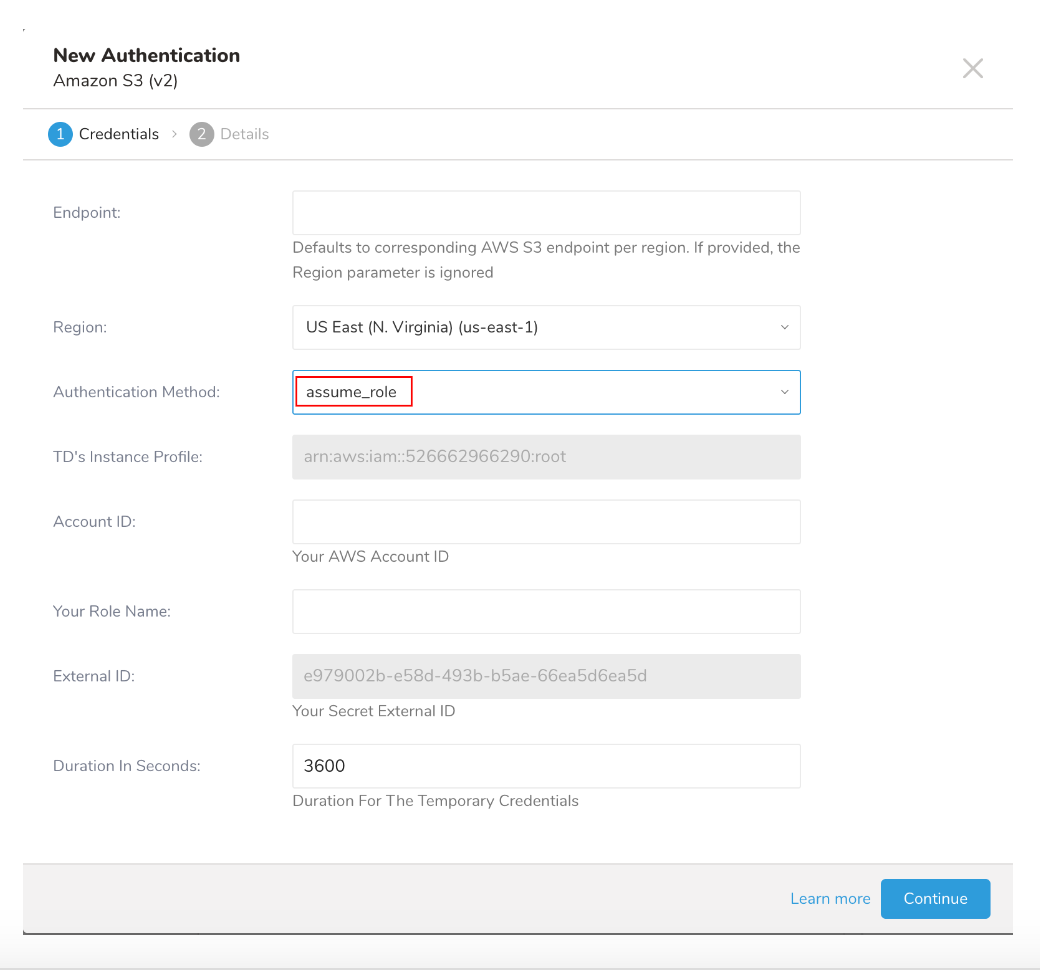
- 認証フィールドを構成し、Continueを選択します。
| Parameter | Description | |
|---|---|---|
| Endpoint | S3サービスエンドポイントのオーバーライド。リージョンとエンドポイント情報はAWS service endpointsドキュメントから確認できます。(例: s3.ap-northeast-1.amazonaws.com) 指定された場合、リージョン設定を上書きします。 | |
| Region | AWSリージョン | |
| Authentication Method | basic |
|
| session (推奨) |
| |
| assume_role |
| |
| anonymous | サポートされていません | |
| Access Key ID | AWS S3発行 | |
| Secret Access Key | AWS S3発行 | |
| Secret token | ||
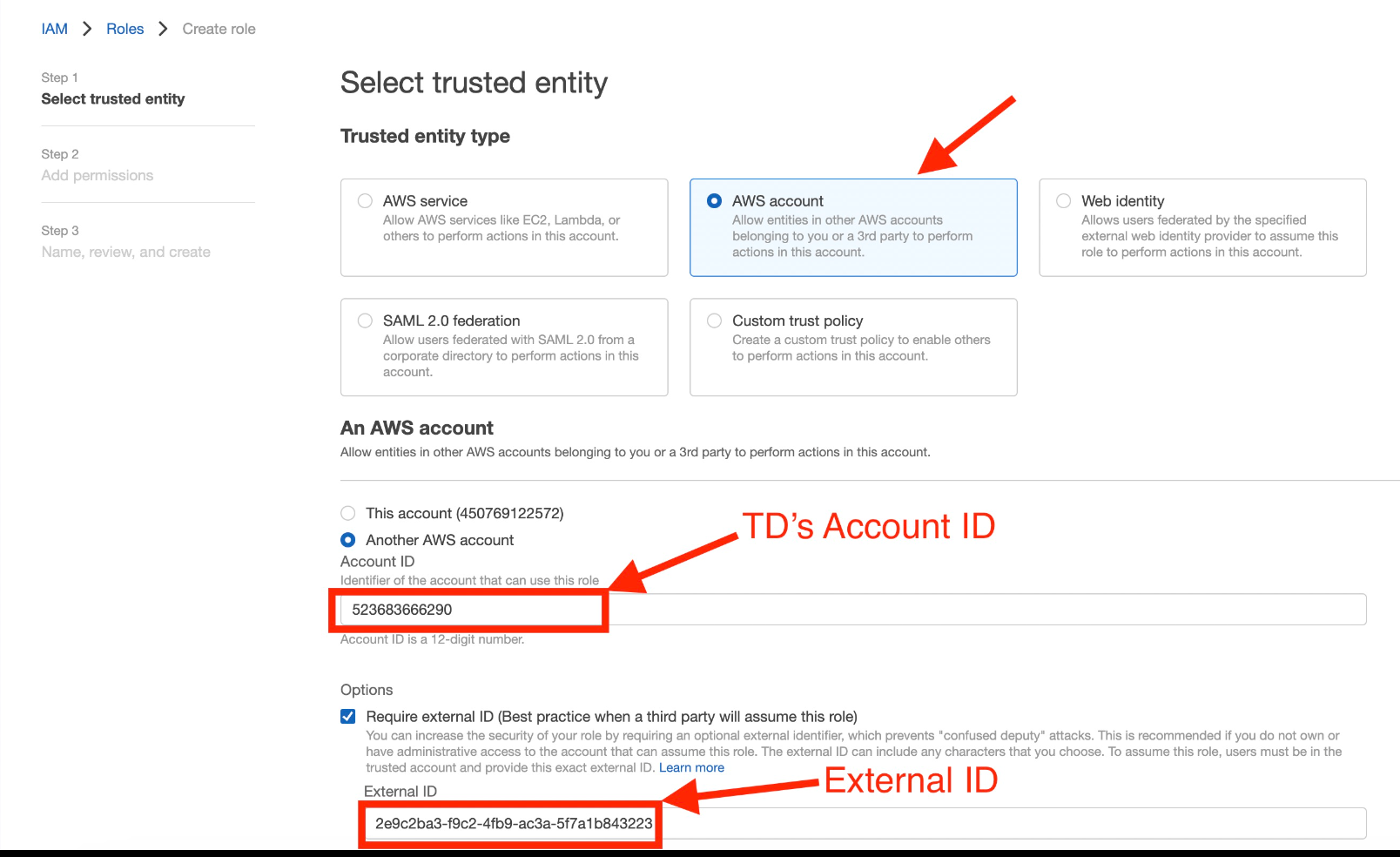
| TD's Instance Profile | この値はTD Consoleによって提供されます。値の数値部分は、IAMロールを作成するときに使用するAccount IDを構成します。 | |
| Account ID | あなたのAWS Account ID | |
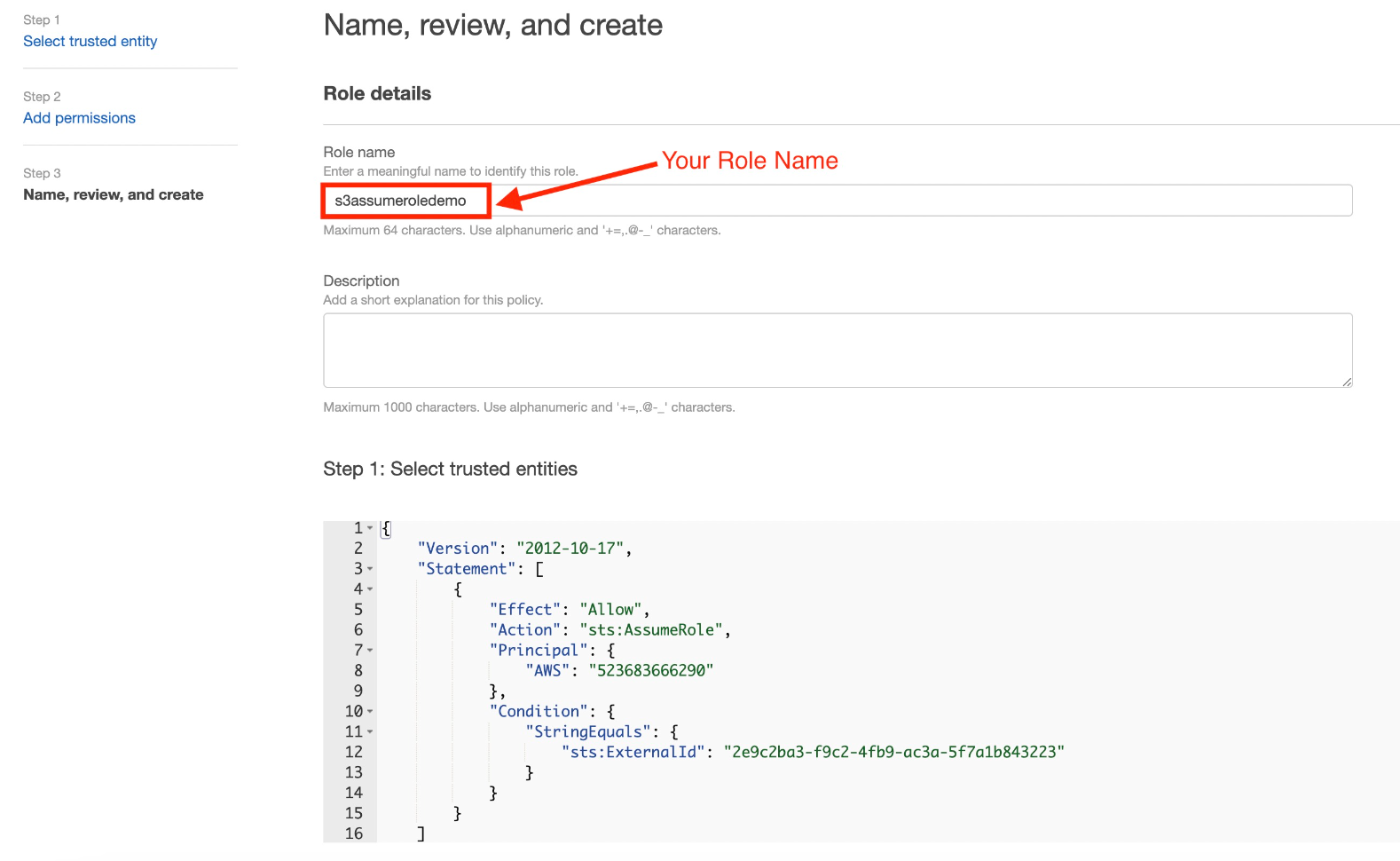
| Your Role Name | あなたのAWS Role Name | |
| External ID | あなたのSecret External ID | |
| Duration In Seconds | 一時的な認証情報の期間 |
- 新しいAWS S3接続に名前を付け、Doneを選択します。
- assume_role認証方法で新しい認証を作成します。
- TD's Instance Profileフィールドの値の数値部分をメモします。
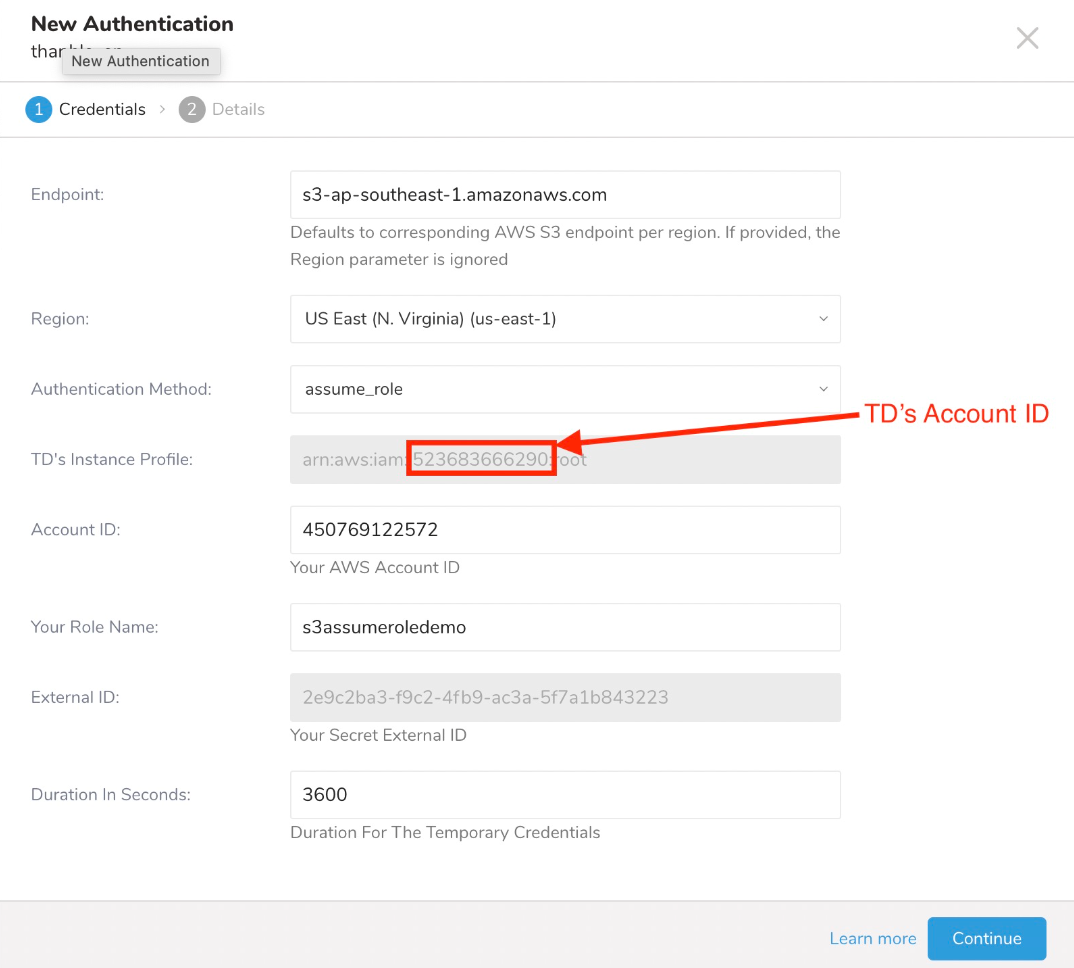
- AWS IAMロールを作成します。
- Export Resultsを選択します。
- 既存の認証を選択するか、出力に使用する外部サービスの新しい認証を作成できます。次のいずれかを選択します:
Use Existing Integration
Create a New Integration
(オプション) Amazon S3へのエクスポート情報を指定します。
| Field | Description |
|---|---|
| Is user directory Root? | 選択した場合、ユーザーディレクトリはルートディレクトリとして扱われます。(例: '/home/treasure-data'を'/'として) |
| Path prefix: | ファイルが保存されるファイルパス |
| Rename file after upload finish | 選択した場合、SFTP result outputは、すべてのデータが転送された後、リモートSFTPサーバー上のファイル名を".xxx.tmp"から".xxx"に変更します。一部のMAツールは、特定の名前のファイルがSFTPサーバーに存在する場合にデータのインポートを試みます。temp nameオプションはそのような場合に便利です。 |
| Format | エクスポートされるファイルの形式: - csv (comma separated) - tsv (tab separated) - jsonl |
| Compression | エクスポートされるファイルの圧縮形式: - None - GZ - bzip2 |
| Header line? | 最初の行として列名を含むヘッダー行 |
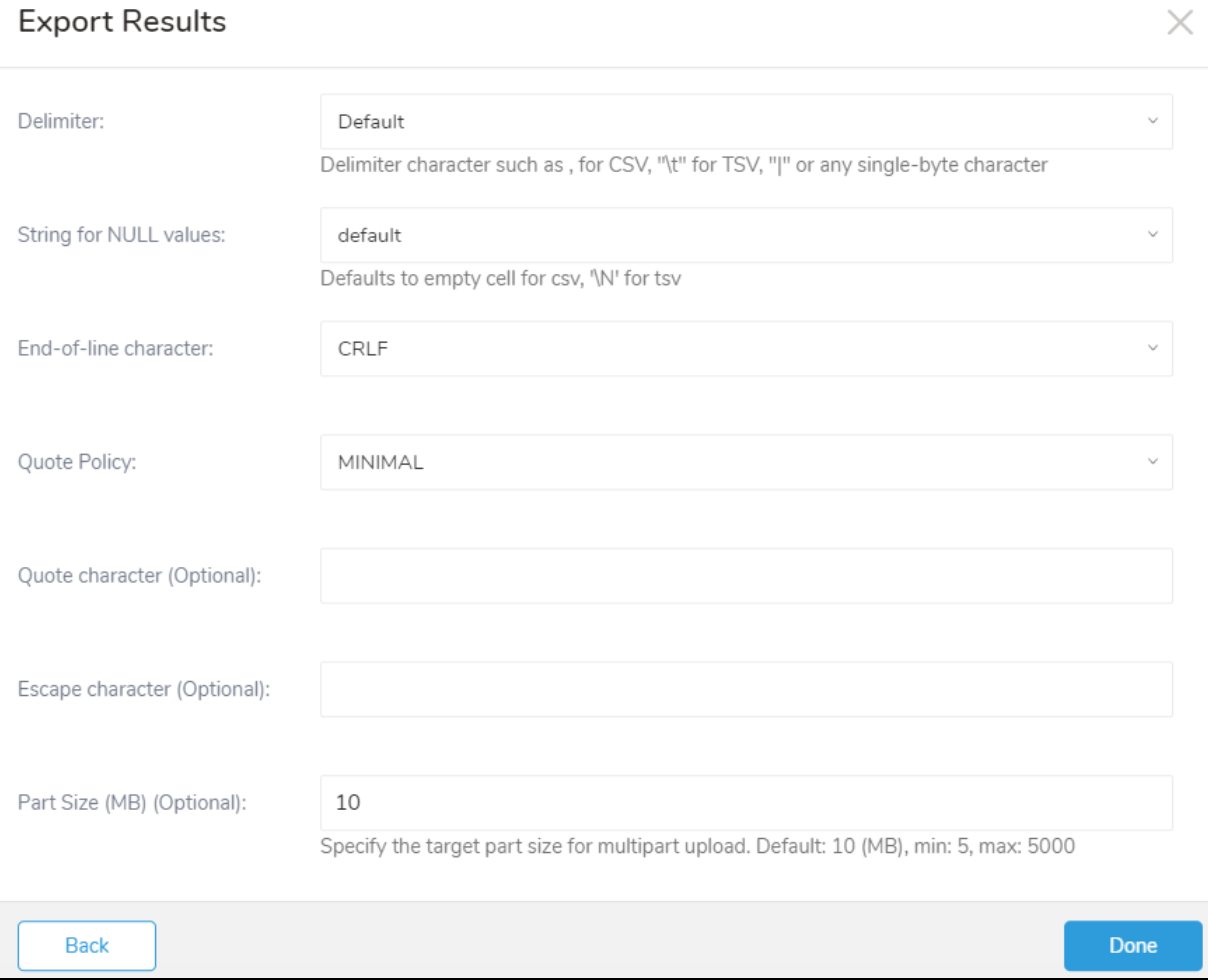
| Delimiter | 区切り文字: - Default - , - Tab - |
| Quote policy | 引用符のポリシー: - ALL - MINIMAL: 区切り文字、引用符、または行終端文字のいずれかを含むフィールドにのみ引用符文字を追加します。 - NONE |
| Null string | クエリ結果のnull値の表示方法: - Default - empty string - \N - NULL - null |
| End-of-line character | EOL (end-of-line)文字: - CRLF - LF - CR |
| Temp filesize threshold | ローカル一時ファイルの最大ファイルサイズ(バイト単位)。一時ファイルがしきい値に達すると、ファイルはリモートファイルにフラッシュされます。channel is brokenエラーが発生した場合は、このオプションの値を減らしてエラーを解決してください。 |
- 追加のExport Resultsの詳細を定義し、コンテンツで統合パラメータを確認します。 例えば、Export Results画面が異なる場合や、記入する追加の詳細がない場合があります。
- Doneを選択します。
- クエリを実行します
- データが指定した宛先に移動したことを検証します。
| Parameter | Data Type | Required? | Supported in V1? | Description |
|---|---|---|---|---|
| Server-side Encryption | String | yes、sse-s3のみ | サポート値: - sse-s3: Server-side Encryption Mode - sse-kms: 新しいSSE Mode | |
| Server-side Encryption Algorithm | String | yes | サポート値: - AES256 | |
| KMS Key ID | String | no | 対称AWS KMS Key ID。KMS Key IDの入力がない場合、デフォルトのKMS Keyを作成/使用します。 | |
| Bucket | String | yes | yes | S3バケット名を指定します(例: your_bucket_name)。 |
| Path | String | yes | yes | s3ファイル名(オブジェクトキー)を指定し、拡張子を含めます(例: test.csv)。 |
| Format | String | yes | エクスポートされるファイルの形式: csv、tsv、jsonl | |
| Compression | String | yes | エクスポートされるファイルの圧縮形式*(例: None or gz)* | |
| Header | Boolean | yes | エクスポートされるファイルにヘッダーを含めます。 | |
| Delimiter | String | yes | 区切り文字を指定するために使用*(例: (comma))* | |
| String for NULL values | String | yes | null値に挿入するプレースホルダー*(例: Empty String)* | |
| End-of-line character | String | yes | EOL(End-Of-Line)表現を指定*(例: CRLF、LF)* | |
| Quote Policy | String | no | 引用符で囲むフィールドタイプを決定するために使用します。サポート値: - ALL すべてのフィールドを引用符で囲みます - MINIMAL 区切り文字、引用符、または行終端文字のいずれかを含むフィールドのみを引用符で囲みます。 - NONE フィールドを引用符で囲みません。区切り文字がフィールド内に出現する場合は、エスケープ文字でエスケープします。 デフォルト値: MINIMAL | |
| Quote character (オプション) | Char | yes | エクスポートされるファイルで引用符に使用される文字(例: ")。区切り文字、引用符、または行終端文字のいずれかを含むフィールドのみを引用符で囲みます。入力が1文字を超える場合、デフォルト値が使用されます。 | |
| Escape character(オプション) | Char | yes | エクスポートされるファイルで使用されるエスケープ文字。入力が1文字を超える場合、デフォルト値が使用されます。 | |
| Part Size (MB) (オプション) | Integer | no | マルチパートアップロードのパートサイズ。デフォルト10、最小5、最大5000 | |
| JSON Columns | String | no | JSONとして送信する文字列列のカンマ区切りリスト |
SELECT * FROM www_accessAudience Studio で activation を作成することで、segment データをターゲットプラットフォームに送信することもできます。
- Audience Studio に移動します。
- parent segment を選択します。
- ターゲット segment を開き、右クリックして、Create Activation を選択します。
- Details パネルで、Activation 名を入力し、前述の Configuration Parameters のセクションに従って activation を設定します。
- Output Mapping パネルで activation 出力をカスタマイズします。

- Attribute Columns
- Export All Columns を選択すると、変更を加えずにすべての列をエクスポートできます。
- + Add Columns を選択して、エクスポート用の特定の列を追加します。Output Column Name には、Source 列名と同じ名前があらかじめ入力されます。Output Column Name を更新できます。+ Add Columns を選択し続けて、activation 出力用の新しい列を追加します。
- String Builder
- + Add string を選択して、エクスポート用の文字列を作成します。次の値から選択します:
- String: 任意の値を選択します。テキストを使用してカスタム値を作成します。
- Timestamp: エクスポートの日時。
- Segment Id: segment ID 番号。
- Segment Name: segment 名。
- Audience Id: parent segment 番号。
- + Add string を選択して、エクスポート用の文字列を作成します。次の値から選択します:
- Schedule を設定します。

- スケジュールを定義する値を選択し、オプションでメール通知を含めます。
- Create を選択します。
batch journey の activation を作成する必要がある場合は、Creating a Batch Journey Activation を参照してください。
Scheduled Jobs と Result Export を使用して、指定したターゲット宛先に出力結果を定期的に書き込むことができます。
Treasure Data のスケジューラー機能は、高可用性を実現するために定期的なクエリ実行をサポートしています。
2 つの仕様が競合するスケジュール仕様を提供する場合、より頻繁に実行するよう要求する仕様が優先され、もう一方のスケジュール仕様は無視されます。
例えば、cron スケジュールが '0 0 1 * 1' の場合、「月の日」の仕様と「週の曜日」が矛盾します。前者の仕様は毎月 1 日の午前 0 時 (00:00) に実行することを要求し、後者の仕様は毎週月曜日の午前 0 時 (00:00) に実行することを要求するためです。後者の仕様が優先されます。
Data Workbench > Queries に移動します
新しいクエリを作成するか、既存のクエリを選択します。
Schedule の横にある None を選択します。

ドロップダウンで、次のスケジュールオプションのいずれかを選択します:
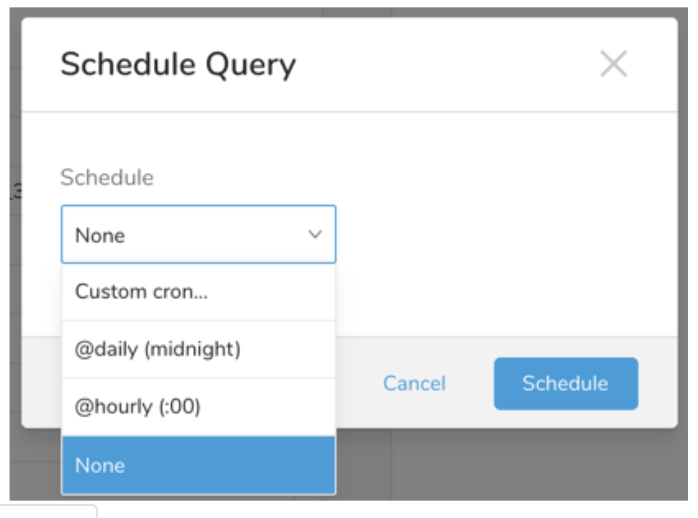
ドロップダウン値 説明 Custom cron... Custom cron... の詳細を参照してください。 @daily (midnight) 指定されたタイムゾーンで 1 日 1 回午前 0 時 (00:00 am) に実行します。 @hourly (:00) 毎時 00 分に実行します。 None スケジュールなし。
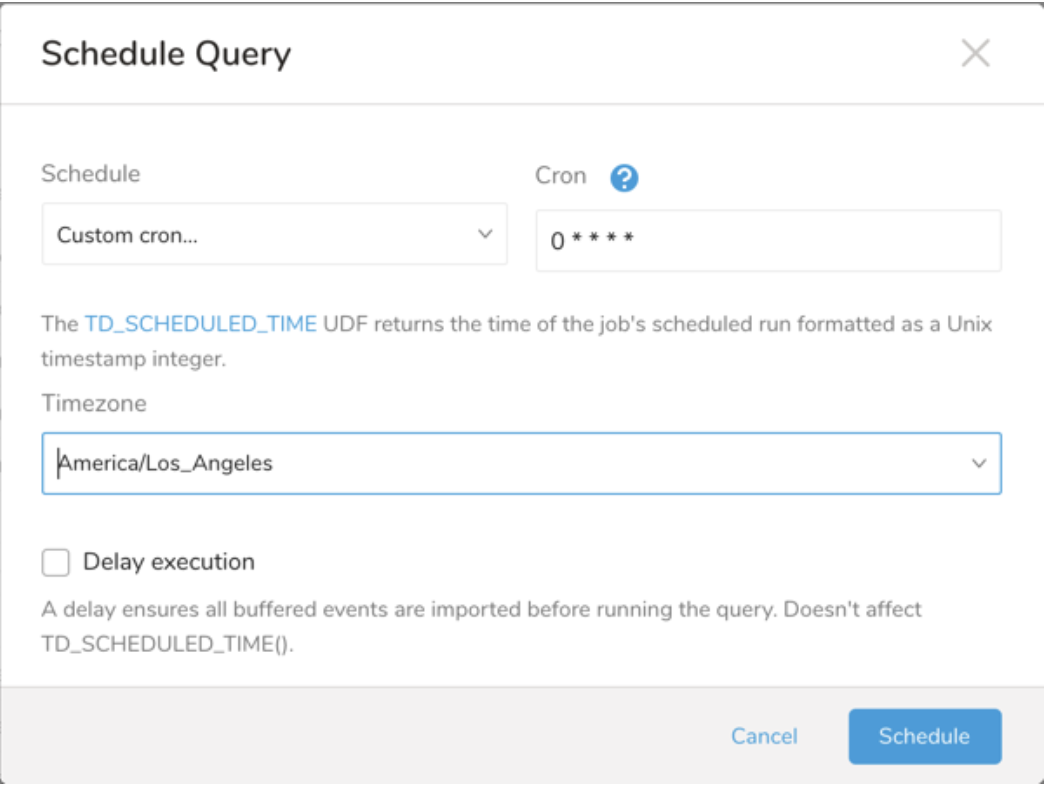
| Cron 値 | 説明 |
|---|---|
0 * * * * | 1 時間に 1 回実行します。 |
0 0 * * * | 1 日 1 回午前 0 時に実行します。 |
0 0 1 * * | 毎月 1 日の午前 0 時に 1 回実行します。 |
| "" | スケジュールされた実行時刻のないジョブを作成します。 |
* * * * *
- - - - -
| | | | |
| | | | +----- day of week (0 - 6) (Sunday=0)
| | | +---------- month (1 - 12)
| | +--------------- day of month (1 - 31)
| +-------------------- hour (0 - 23)
+------------------------- min (0 - 59)次の名前付きエントリを使用できます:
- Day of Week: sun, mon, tue, wed, thu, fri, sat.
- Month: jan, feb, mar, apr, may, jun, jul, aug, sep, oct, nov, dec.
各フィールド間には単一のスペースが必要です。各フィールドの値は、次のもので構成できます:
| フィールド値 | 例 | 例の説明 |
|---|---|---|
| 各フィールドに対して上記で表示された制限内の単一の値。 | ||
フィールドに基づく制限がないことを示すワイルドカード '*'。 | '0 0 1 * *' | 毎月 1 日の午前 0 時 (00:00) に実行するようにスケジュールを設定します。 |
範囲 '2-5' フィールドの許可される値の範囲を示します。 | '0 0 1-10 * *' | 毎月 1 日から 10 日までの午前 0 時 (00:00) に実行するようにスケジュールを設定します。 |
カンマ区切りの値のリスト '2,3,4,5' フィールドの許可される値のリストを示します。 | 0 0 1,11,21 * *' | 毎月 1 日、11 日、21 日の午前 0 時 (00:00) に実行するようにスケジュールを設定します。 |
周期性インジケータ '*/5' フィールドの有効な値の範囲に基づいて、 スケジュールが実行を許可される頻度を表現します。 | '30 */2 1 * *' | 毎月 1 日、00:30 から 2 時間ごとに実行するようにスケジュールを設定します。 '0 0 */5 * *' は、毎月 5 日から 5 日ごとに午前 0 時 (00:00) に実行するようにスケジュールを設定します。 |
'*' ワイルドカードを除く上記の いずれかのカンマ区切りリストもサポートされています '2,*/5,8-10' | '0 0 5,*/10,25 * *' | 毎月 5 日、10 日、20 日、25 日の午前 0 時 (00:00) に実行するようにスケジュールを設定します。 |
- (オプション) Delay execution を有効にすることで、クエリの開始時刻を遅延させることができます。
クエリに名前を付けて保存して実行するか、単にクエリを実行します。クエリが正常に完了すると、クエリ結果は指定された宛先に自動的にエクスポートされます。
設定エラーにより継続的に失敗するスケジュールジョブは、複数回通知された後、システム側で無効化される場合があります。
(オプション) Delay execution を有効にすることで、クエリの開始時刻を遅延させることができます。
Treasure Workflow内で、このデータコネクタを使用してデータをエクスポートすることを指定できます。
詳細はExporting Data with Parametersをご覧ください。
| Name | Type | Required | Description | |
|---|---|---|---|---|
| bucket | String | Yes | ||
| path | String | Yes | ||
| sse_type | String | sse-s3, sse-kms | ||
sse_algorithm | String | AES256 | ||
kms_key_id | String | |||
| format | String | csv, tsv, jsonl | ||
| compression | String | none, gz | ||
| header | Boolean | デフォルトtrue | ||
| delimiter | String | default , \t | ||
| null_value | String | default, empty, \N, NULL, null | ||
| newline | String | CR, LF, CRLF | ||
| quote_policy | String | ALL, MINIMAL, NONE | ||
| escape | Char | |||
| quote | Char | |||
| part_size | Integer | |||
| json_columns | String |
_export:
td:
database: td.database
+s3v2_test_export_task:
td>: export_s3v2_test.sql
database: ${td.database}
result_connection: s3v2_conn
result_settings:
bucket: my-bucket
path: /path/to/target.csv
sse_type: sse-s3
format: csv
compression: gz
header: false
delimiter: default
null_value: empty
newline: LF
quote_policy: MINIMAL
escape: '"'
quote: '"'
part_size: 20
json_columns: col_map,col_array,col_json_string単一のクエリの結果をS3バケットに出力するには、td queryコマンドに"--result option"を追加します。ジョブが完了すると、結果がS3バケットに書き込まれます。
"--result parameter"を使用してS3をエクスポートするための詳細設定を指定できます。
Assume Roleを使用した認証の作成は、コンソールUIを通じてのみサポートされています。Authentication IDを取得するには、Reuse the existing Authenticationの手順に従い、CLIで再利用してください
td query \
--result '{"type":"s3_v2","auth_method":"basic","region":"us-east-2","access_key_id": "************","secret_access_key":"***************","bucket":"bucket_name","path":"path/to/file.csv","format":"csv","compression":"none","header":true,"delimiter":"default","null_value":"default","newline":"CRLF","quote_policy":"NONE","part_size":10}' \
-w -d testdb \
"SELECT 1 as col" -T prestotd query \
--result '{"type":"s3_v2","td_authentication_id": 77348,"bucket":"bucket_name","path":"path/to/file.csv","format":"csv","compression":"none","header":true,"delimiter":"default","null_value":"default","newline":"CRLF","quote_policy":"NONE","part_size":10}' \
-w -d testdb \
"SELECT 1 as col" -T presto