Parquetは、カラム型データフォーマットであり、クエリがデータセット内のカラムのサブセットのみにアクセスする必要がある分析ワークロードに特に有益です。このため、多くのデータパイプライン戦略において好まれるオプションとなっています。
Amazon S3 Parquet Export Integrationを使用すると、Treasure Dataのジョブ結果からParquetファイルを生成し、Amazon S3に直接アップロードできます。
- Treasure Dataの基本的な知識
TD リージョンと同じリージョンにある AWS S3 バケットを使用している場合、TD がバケットにアクセスする IP アドレスはプライベートで動的に変化します。アクセスを制限したい場合は、静的 IP アドレスではなく VPC の ID を指定してください。例えば、US リージョンの場合は vpc-df7066ba 経由でアクセスを設定し、Tokyo リージョンの場合は vpc-e630c182 経由、EU01 リージョンの場合は vpc-f54e6a9e 経由でアクセスを設定してください。
TD Console にログインする URL から TD Console のリージョンを確認し、URL 内のリージョンのデータコネクターを参照してください。
詳細については、API ドキュメントを参照してください。
セキュリティポリシーで IP ホワイトリストが必要な場合は、接続を成功させるために Treasure Data の IP アドレスを許可リストに追加する必要があります。
リージョンごとに整理された静的 IP アドレスの完全なリストは、次のリンクにあります: https://api-docs.treasuredata.com/en/overview/ip-addresses-integrations-result-workers/
- 最大512 MBの行グループサイズのみをサポートします。
- ファイルのアップロードにマルチパートアップロードが使用されるため、何らかの理由でS3コンテナにアップロードパーツが残る場合があります。不完全なマルチパートアップロードのクリーンアップポリシーを有効にすることをお勧めします。詳細については、S3 Lifecycle Management Update – Support for Multipart Uploads and Delete Markersを参照してください。
クエリを実行する前に、データ接続を作成して設定する必要があります。データ接続の一部として、統合にアクセスするための認証を提供します。
| 認証方法 | Amazon S3 Parquet |
|---|---|
| basic | x |
| session | x |
| assume_role | x |
最初のステップは、認証情報のセットを使用して新しい認証を作成することです。
- Integrations Hubを選択します。
- Catalogを選択します。
- Catalogで統合を検索し、アイコンにマウスカーソルを合わせてCreate Authenticationを選択します。

- Credentialsタブが選択されていることを確認し、統合の認証情報を入力します。 認証フィールド
| Parameter | Description |
|---|---|
| Endpoint | S3サービスエンドポイントのオーバーライド。リージョンとエンドポイント情報は、AWS service endpointsで確認できます(例:s3.ap-northeast-1.amazonaws.com)。指定すると、リージョン設定が上書きされます。 |
| Region | AWSリージョン |
| Authentication Method | |
| basic |
|
| session (推奨) |
|
| assume_role |
|
| 匿名 | サポートされていません |
| アクセスキーID | AWS S3から発行 |
| シークレットアクセスキー | AWS S3から発行 |
| セッショントークン | 一時的なAWSセッショントークン |
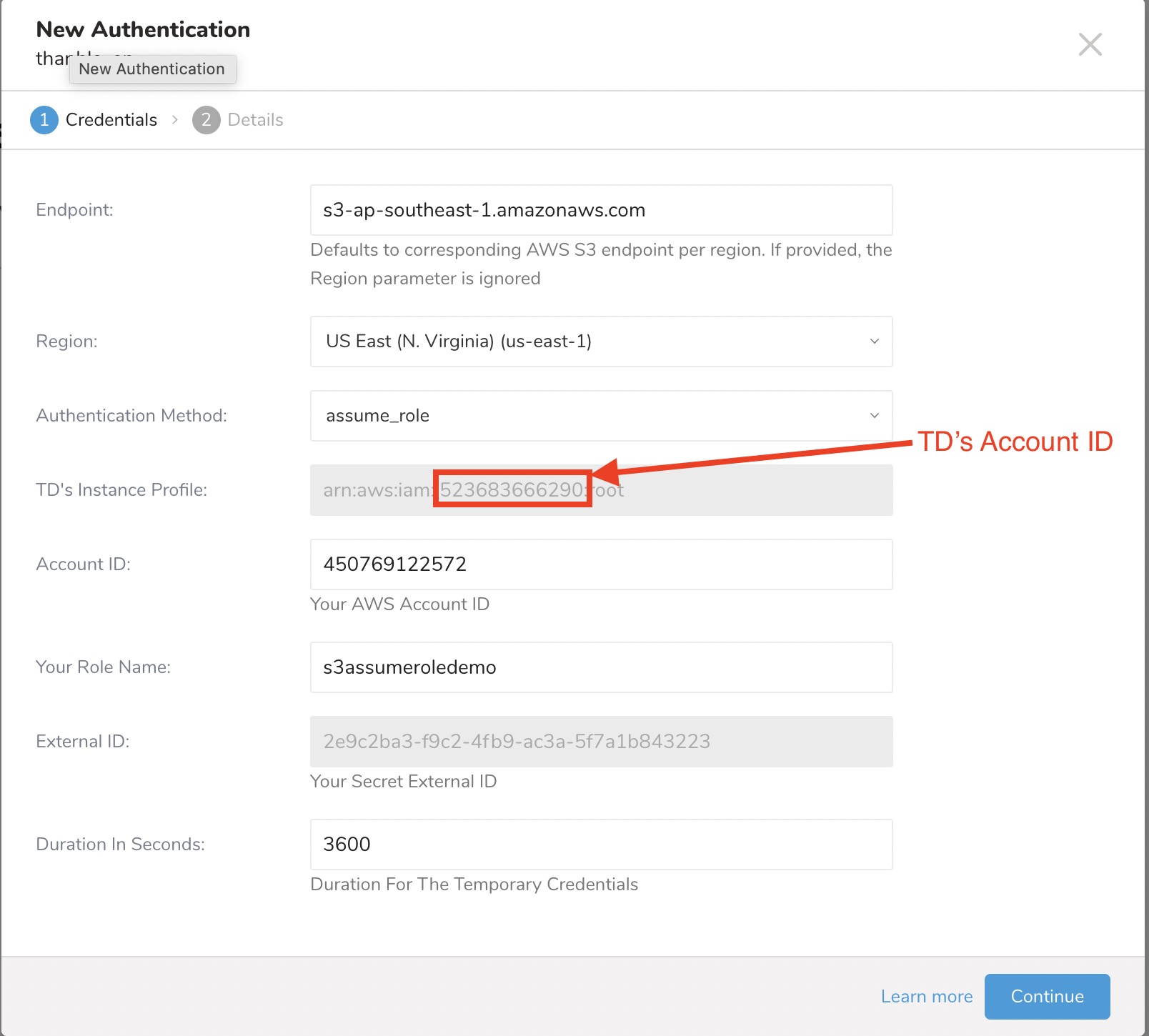
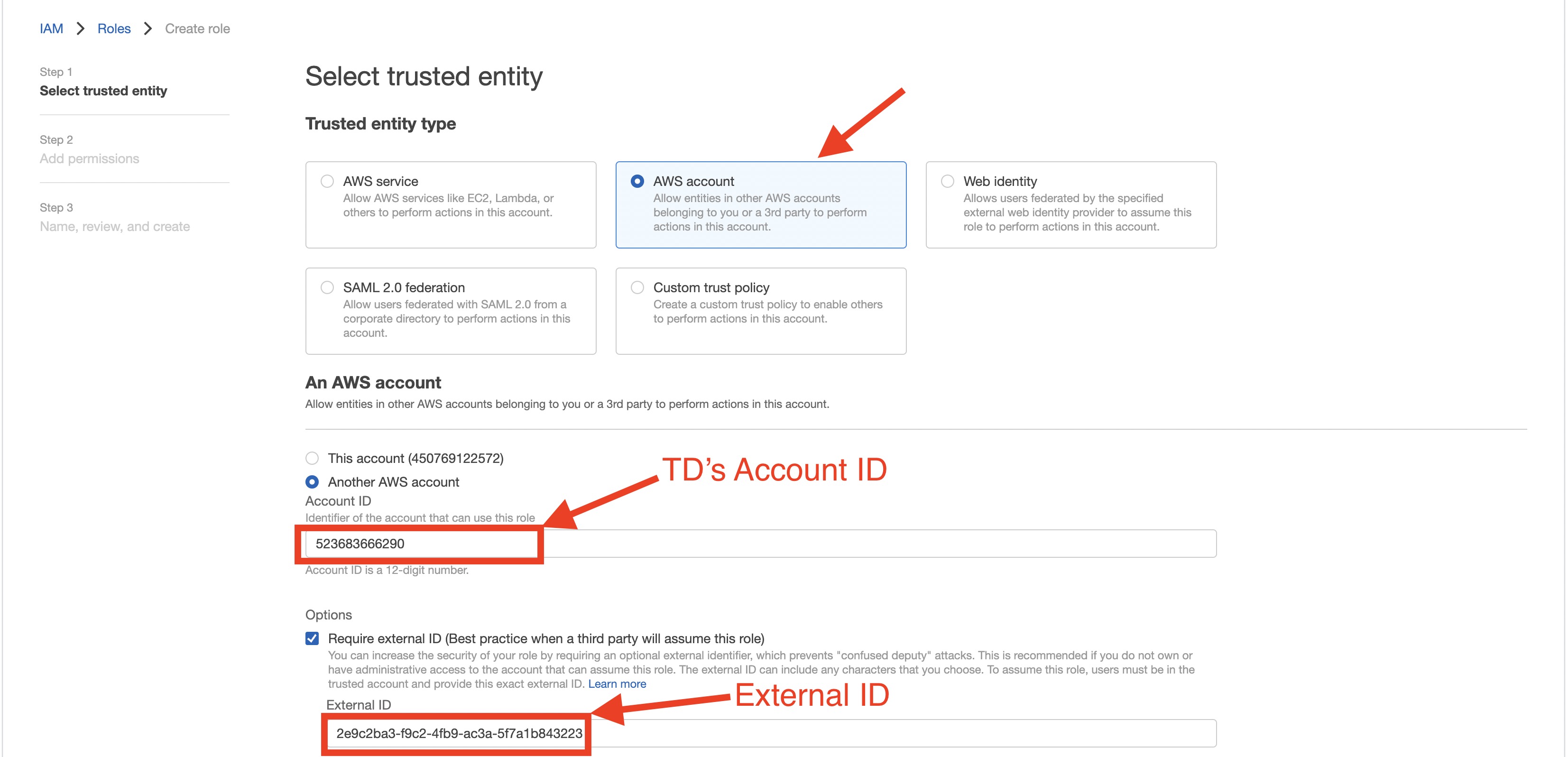
| TDのインスタンスプロファイル | この値はTDコンソールによって提供されます。この値の数値部分が、IAMロールを作成する際に使用するアカウントIDを構成します。 |
| アカウントID | AWSアカウントID |
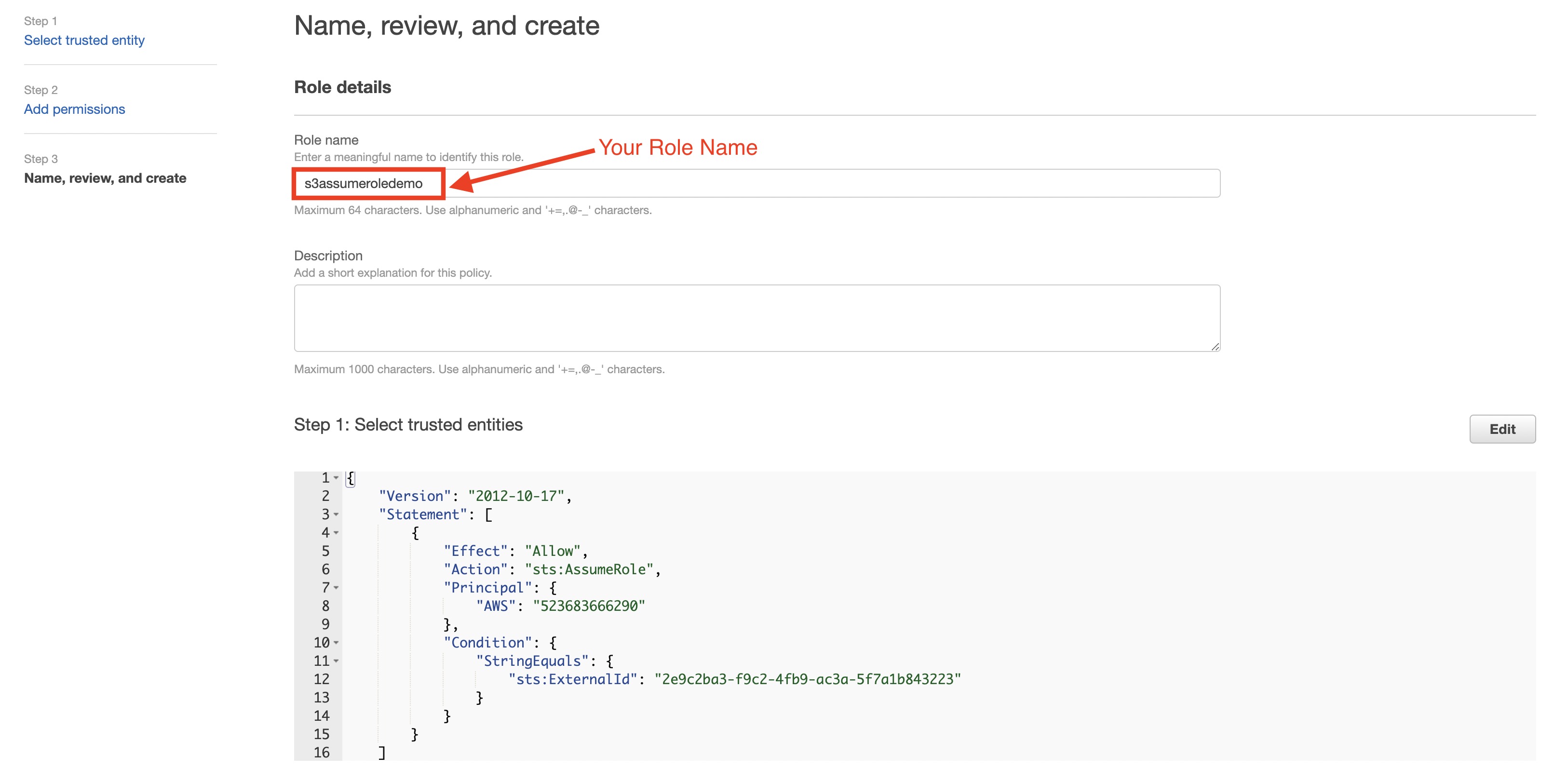
| ロール名 | AWSロール名 |
| 外部ID | シークレット外部ID |
| 有効期間 | 一時的な認証情報の有効期間 |
- 続行を選択します。
- 認証の名前を入力し、完了を選択します。
- assume_role認証方式で新しい認証を作成します。
- TDのインスタンスプロファイルフィールドの値の数値部分をメモします。
- AWS IAMロールを作成します。
- Data Workbench > Queriesに移動します。
- 新しいクエリを選択します。
- クエリを実行して結果セットを検証します。
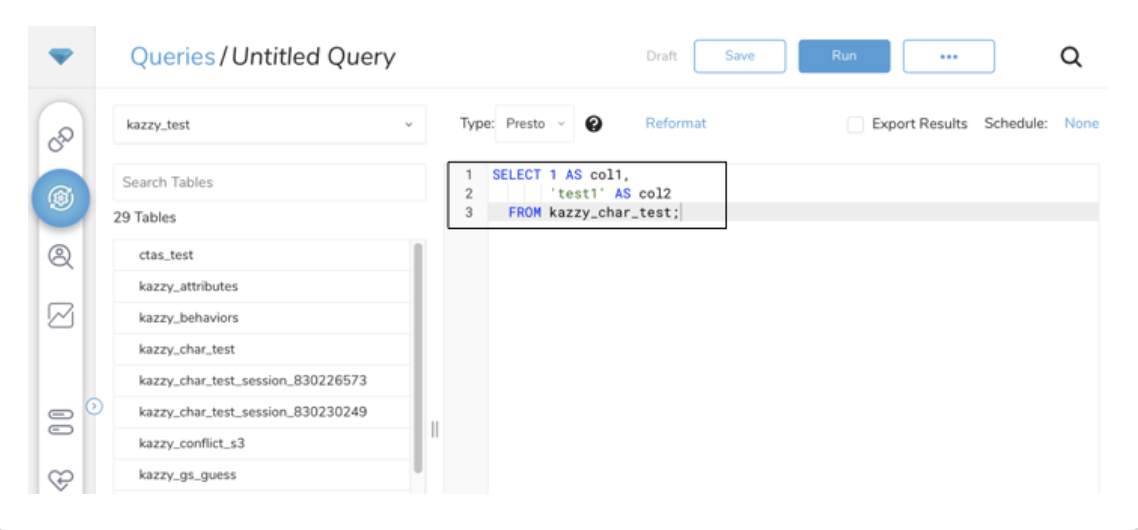
- 結果をエクスポートを選択します。
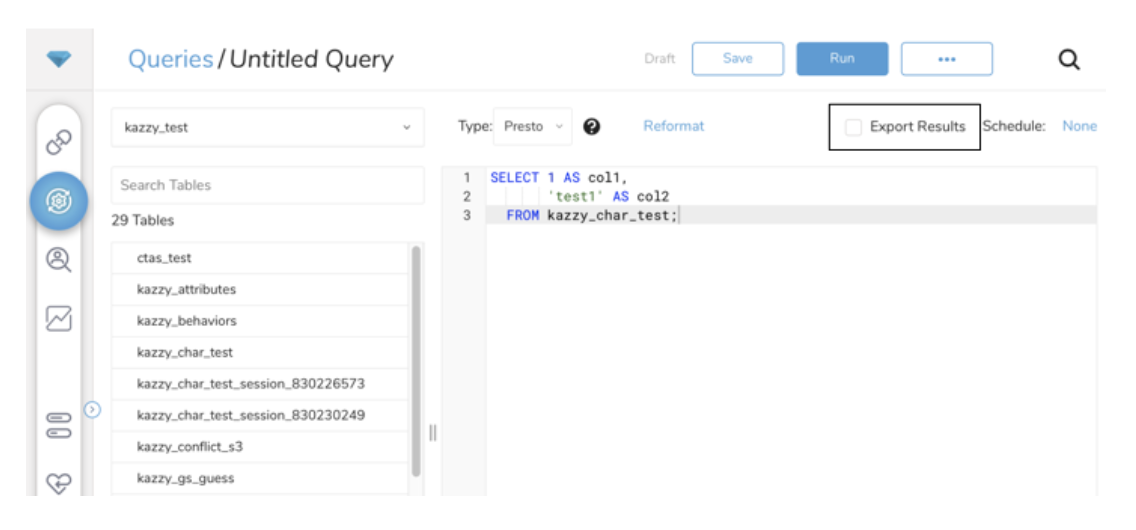
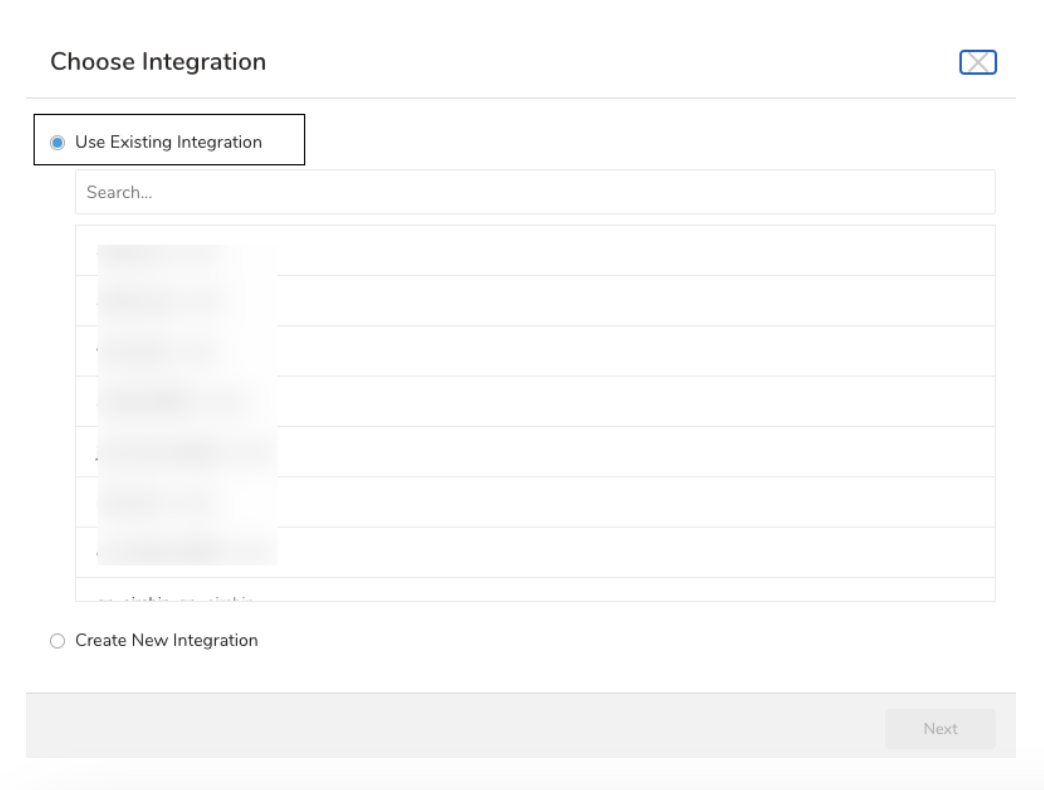
- 認証を指定し、エクスポートの設定を開始します。 既存の認証を選択するか、出力に使用する外部サービス用の新しい認証を作成できます。次のいずれかを選択します:
既存のIntegrationを使用する
新しいIntegrationを作成する
 **
**
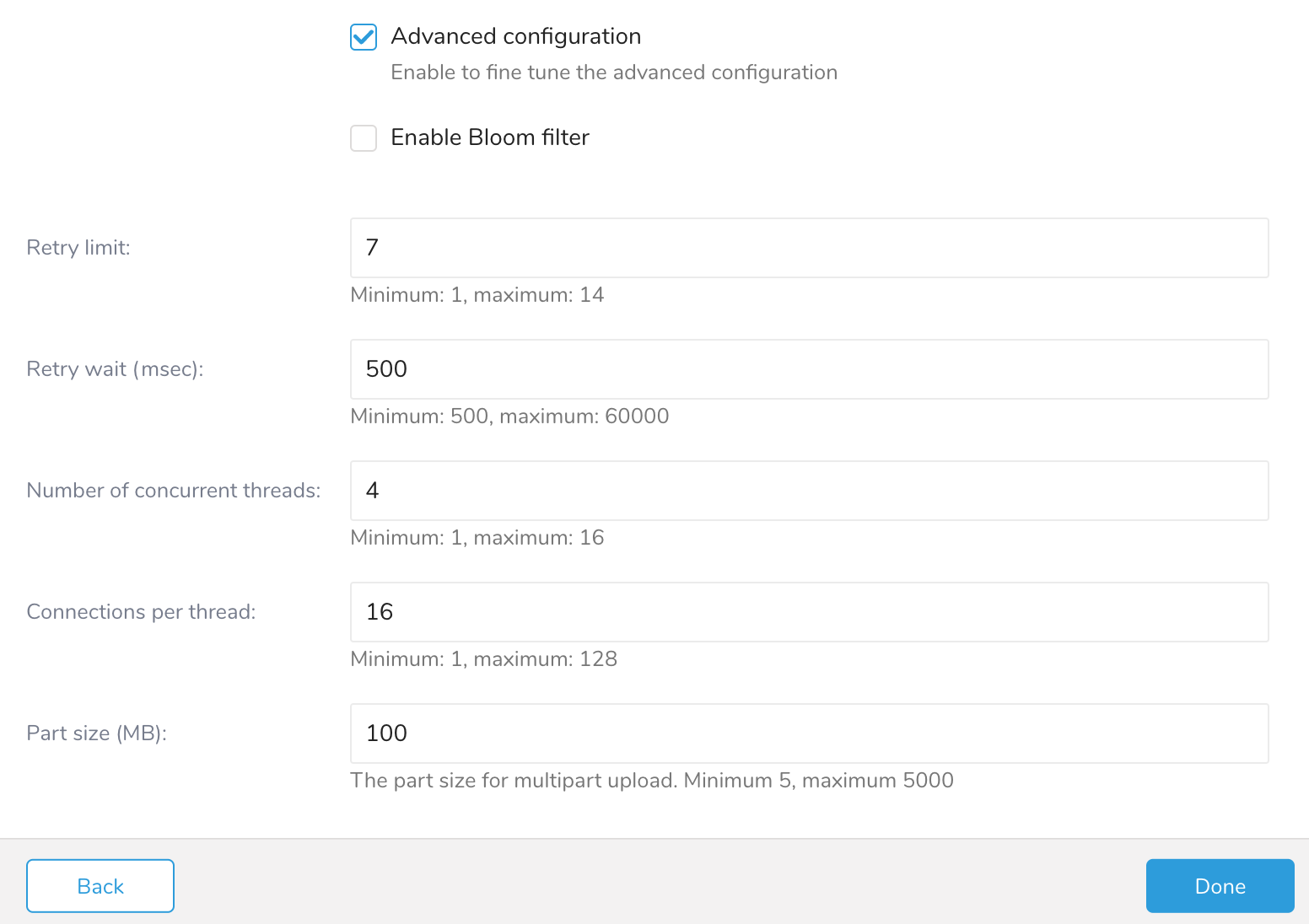
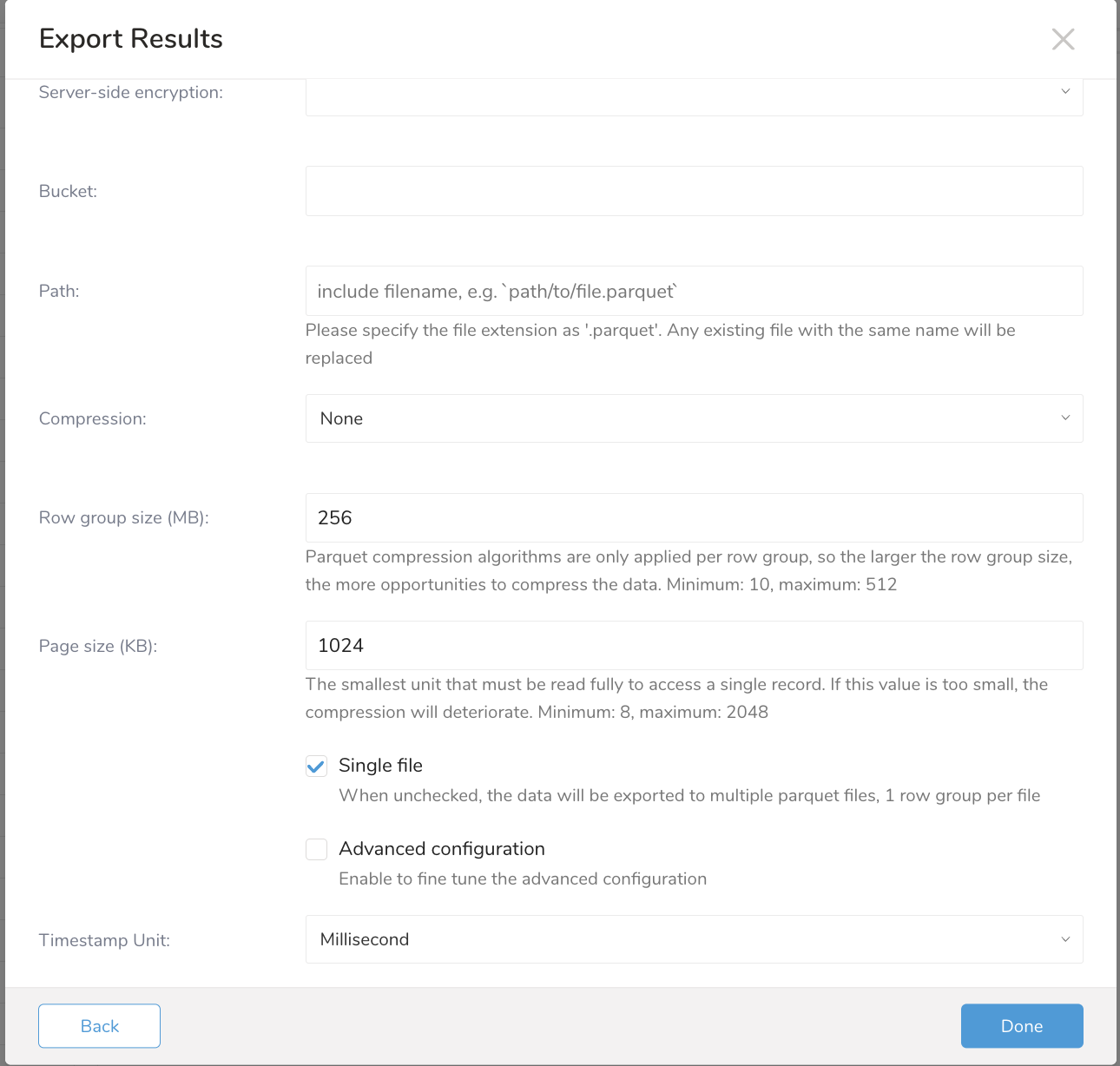
| フィールド | 説明 |
|---|---|
| Server-side encryption | サポートされる値:
|
| Server-side Encryption Algorithm | サポートされる値: - AES256 |
| KMS Key ID | 対称AWS KMS Key ID。KMS Key IDの入力がない場合、デフォルトのKMS Keyを作成/使用します。 |
| Bucket | S3バケット名を指定してください (例: your_bucket_name)。 |
| Compression | S3バケット名を指定してください (例: your_bucket_name)。 |
| Path | s3ファイル名(オブジェクトキー)を指定し、拡張子を含めてください (例: test.parquet)。 |
| Compression | エクスポートされるファイルの圧縮形式。サポートされる値: - None - Gzip - Snappy |
| Row group size | Parquetファイルのグループサイズを指定してください |
| Page size | Parquetファイルのページサイズを指定してください |
| Timestamp Unit | Parquetファイルのタイムスタンプ形式を指定してください。サポートされる時間単位:
|
| Single file | Row Groupのサイズで複数のファイルに分割する場合はチェックを外してください |
| Enable Bloom filter | ParquetファイルのBloom filterを有効にする |
| リトライ制限 | 最大リトライ回数 |
| リトライ待機時間 | 各リトライ時の待機時間(ミリ秒) |
| 同時実行スレッド数 | S3へのアップロードを行うS3スレッドの同時実行数 |
| スレッドあたりの接続数 | S3への各スレッドが開くHTTP接続数 |
| パートサイズ | S3のマルチパートアップロードのパートサイズ |
アクティベーションを作成して、セグメントデータやステージをエクスポートできます。
Audience Studio で activation を作成することで、segment データをターゲットプラットフォームに送信することもできます。
- Audience Studio に移動します。
- parent segment を選択します。
- ターゲット segment を開き、右クリックして、Create Activation を選択します。
- Details パネルで、Activation 名を入力し、前述の Configuration Parameters のセクションに従って activation を設定します。
- Output Mapping パネルで activation 出力をカスタマイズします。

- Attribute Columns
- Export All Columns を選択すると、変更を加えずにすべての列をエクスポートできます。
- + Add Columns を選択して、エクスポート用の特定の列を追加します。Output Column Name には、Source 列名と同じ名前があらかじめ入力されます。Output Column Name を更新できます。+ Add Columns を選択し続けて、activation 出力用の新しい列を追加します。
- String Builder
- + Add string を選択して、エクスポート用の文字列を作成します。次の値から選択します:
- String: 任意の値を選択します。テキストを使用してカスタム値を作成します。
- Timestamp: エクスポートの日時。
- Segment Id: segment ID 番号。
- Segment Name: segment 名。
- Audience Id: parent segment 番号。
- + Add string を選択して、エクスポート用の文字列を作成します。次の値から選択します:
- Schedule を設定します。

- スケジュールを定義する値を選択し、オプションでメール通知を含めます。
- Create を選択します。
batch journey の activation を作成する必要がある場合は、Creating a Batch Journey Activation を参照してください。
Scheduled Jobs と Result Export を使用して、指定したターゲット宛先に出力結果を定期的に書き込むことができます。
Treasure Data のスケジューラー機能は、高可用性を実現するために定期的なクエリ実行をサポートしています。
2 つの仕様が競合するスケジュール仕様を提供する場合、より頻繁に実行するよう要求する仕様が優先され、もう一方のスケジュール仕様は無視されます。
例えば、cron スケジュールが '0 0 1 * 1' の場合、「月の日」の仕様と「週の曜日」が矛盾します。前者の仕様は毎月 1 日の午前 0 時 (00:00) に実行することを要求し、後者の仕様は毎週月曜日の午前 0 時 (00:00) に実行することを要求するためです。後者の仕様が優先されます。
Data Workbench > Queries に移動します
新しいクエリを作成するか、既存のクエリを選択します。
Schedule の横にある None を選択します。

ドロップダウンで、次のスケジュールオプションのいずれかを選択します:
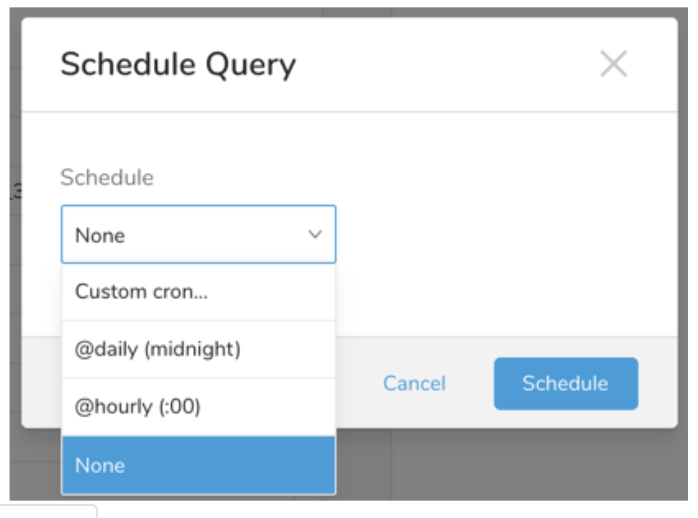
ドロップダウン値 説明 Custom cron... Custom cron... の詳細を参照してください。 @daily (midnight) 指定されたタイムゾーンで 1 日 1 回午前 0 時 (00:00 am) に実行します。 @hourly (:00) 毎時 00 分に実行します。 None スケジュールなし。
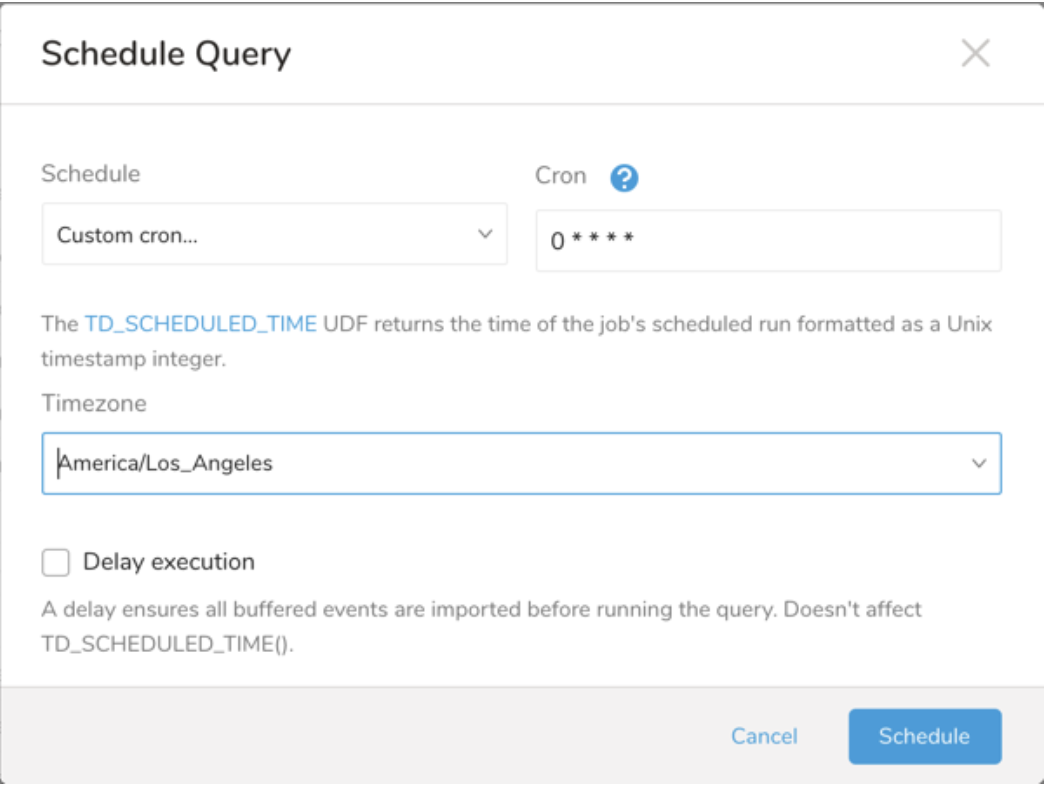
| Cron 値 | 説明 |
|---|---|
0 * * * * | 1 時間に 1 回実行します。 |
0 0 * * * | 1 日 1 回午前 0 時に実行します。 |
0 0 1 * * | 毎月 1 日の午前 0 時に 1 回実行します。 |
| "" | スケジュールされた実行時刻のないジョブを作成します。 |
* * * * *
- - - - -
| | | | |
| | | | +----- day of week (0 - 6) (Sunday=0)
| | | +---------- month (1 - 12)
| | +--------------- day of month (1 - 31)
| +-------------------- hour (0 - 23)
+------------------------- min (0 - 59)次の名前付きエントリを使用できます:
- Day of Week: sun, mon, tue, wed, thu, fri, sat.
- Month: jan, feb, mar, apr, may, jun, jul, aug, sep, oct, nov, dec.
各フィールド間には単一のスペースが必要です。各フィールドの値は、次のもので構成できます:
| フィールド値 | 例 | 例の説明 |
|---|---|---|
| 各フィールドに対して上記で表示された制限内の単一の値。 | ||
フィールドに基づく制限がないことを示すワイルドカード '*'。 | '0 0 1 * *' | 毎月 1 日の午前 0 時 (00:00) に実行するようにスケジュールを設定します。 |
範囲 '2-5' フィールドの許可される値の範囲を示します。 | '0 0 1-10 * *' | 毎月 1 日から 10 日までの午前 0 時 (00:00) に実行するようにスケジュールを設定します。 |
カンマ区切りの値のリスト '2,3,4,5' フィールドの許可される値のリストを示します。 | 0 0 1,11,21 * *' | 毎月 1 日、11 日、21 日の午前 0 時 (00:00) に実行するようにスケジュールを設定します。 |
周期性インジケータ '*/5' フィールドの有効な値の範囲に基づいて、 スケジュールが実行を許可される頻度を表現します。 | '30 */2 1 * *' | 毎月 1 日、00:30 から 2 時間ごとに実行するようにスケジュールを設定します。 '0 0 */5 * *' は、毎月 5 日から 5 日ごとに午前 0 時 (00:00) に実行するようにスケジュールを設定します。 |
'*' ワイルドカードを除く上記の いずれかのカンマ区切りリストもサポートされています '2,*/5,8-10' | '0 0 5,*/10,25 * *' | 毎月 5 日、10 日、20 日、25 日の午前 0 時 (00:00) に実行するようにスケジュールを設定します。 |
- (オプション) Delay execution を有効にすることで、クエリの開始時刻を遅延させることができます。
Treasure Workflow内で、この連携を使用してデータをエクスポートするように指定できます。
_export:
td:
database: td.database
+a_s3_parquet_export_task:
td>: export_test.sql
database: ${td.database}
result_connection: s3_parquet_conn
result_settings:
type:単一のクエリ結果をS3バケットに出力するには、td queryコマンドに*--result*オプションを追加します。ジョブが完了すると、結果がS3バケットに書き込まれます。td queryコマンドについては、こちらの記事を参照してください。
以下のように、--resultパラメータを使用してS3へのエクスポートの詳細設定を指定できます:
{
"type": "s3_parquet",
"endpoint": "",
"region": "us-east-1",
"auth_method": "",
"session_token": "",
"account_id": "",
"role_name": "",
"duration_in_seconds": 3600,
"access_key_id": "xxxxx",
"secret_access_key": "xxxxx",
"sse_type": "sse-s3",
"sse_algorithm": "AES256",
"kms_key_id": "arn:aws:kms:us-east-1:xxx:key/xxx",
"bucket": "bucket",
"path": "file.parquet",
"row_group_size": 256,
"page_size": 1024,
"timestamp_unit": "milliseconds",
"enable_bloom_filter": false,
"enable_single_file": true,
"compression": "gzip",
"part_size": 100,
"part_size": 100,
"retry_limit": 7,
"retry_wait_millis": 500,
"number_of_concurrent_threads": 4,
"connections_per_thread": 128,
}| 名前 | 説明 | 値 | デフォルト値 | 必須 |
|---|---|---|---|---|
| type | エクスポート先サービスの名前を記述します。 | s3_parquet | N/A | Yes |
| endpoint | S3 サービスエンドポイントのオーバーライド。AWS サービスエンドポイントでリージョンとエンドポイント情報を確認できます。(例: s3.ap-northeast-1.amazonaws.com) | S3 サービスエンドポイントのオーバーライド | N/A | No |
| region | AWS リージョン | AWS リージョン | us-east-1 | No |
| auth_method | S3 の認証方式 | basic session assume_role | basic | Yes |
| access_key_id | アクセスキー ID | キー ID | N/A | auth_method として basic または session を使用する場合 |
| secret_access_key | シークレットアクセスキー | シークレットアクセスキー | N/A | auth_method として basic または session を使用する場合 |
| session_token | セッショントークン | セッショントークン | N/A | auth_method として session を使用する場合 |
| account_id | アカウント ID | アカウント ID | N/A | auth_method として assume_role を使用する場合 |
| role_name | ロール名 | ロール名 | N/A | auth_method として assume_role を使用する場合 |
| external_id | 外部 ID | 外部 ID | N/A | auth_method として assume_role を使用する場合 |
| duration_in_seconds | 接続の持続時間 | 秒単位の持続時間 | 3600 | No |
| bucket | S3 バケット値 | S3 バケット値 | N/A | Yes |
| path | ファイル形式を含む S3 パス (例: "/path/file.parquet") | パスファイル | N/A | Yes |
| row_group_size | Parquet 行グループサイズ | Parquet 行グループサイズ | 256 | No |
| page_size | Parquet ページサイズ | Parquet ページサイズ | 1024 | No |
| timestamp_unit | Parquet タイムスタンプ形式 | - milliseconds - microseconds | milliseconds | No |
| enable_bloom_filter | Parquet ファイルのブルームフィルタを有効化 | - true - false | false | No |
| enable_single_file | 単一ファイルへのエクスポート、または各ファイルに1つの row_group_file を含む複数ファイルへのエクスポートを有効化 | - true - false | true | Y |
| compression | エクスポートされたファイルの圧縮形式 | - None - Gzip - Snappy | None | No |
| retry_limit | 最大リトライ回数 | リトライ制限 | 7 | No |
| retry_wait_millis | 各リトライ時の待機時間(ミリ秒) | リトライ待機時間(ミリ秒) | 500 | No |
| number_of_concurrent_threads | S3 へのアップロードのための同時スレッド数 | 同時 S3 スレッド数 | 4 | No |
| connection_per_thread | S3 への各スレッドごとの HTTP 接続数 | スレッドごとの HTTP 接続数 | 16 | No |
| part_size | S3 のマルチパートアップロードのパートサイズ | パートサイズ | 100 | No |
$ td query \
--result '{"type":"s3_parquet","auth_method":"basic","access_key_id":"access_key_id","secret_access_key":"secret_access_key","bucket":"bucket","path":"/path/file.parquet"}' \
-d sample_datasets "select * from www_access" -T presto