AWS LinuxへのTD Agentのインストールについて詳しく学んでください。
既存のAmazon Redshift clusterにjobの結果を書き込むことができます。Exportに関するAmazon Redshiftのサンプルworkflowについては、Treasure Boxesを参照してください。
- TD Toolbeltを含むTreasure Dataの基本的な知識
- 実行中のAmazon Redshift clusterのセットアップ - シングルノードまたはマルチノードcluster
- queryを実行するTreasure Data tableに対する少なくとも'Query only'権限
- Redshiftに結果をエクスポートする際、Redshiftは宛先tableがすでに存在する場合、カラムタイプの変換を試みます。変換中にカラムがNULLになり、Redshift上のカラムがNOT NULLフィールドの場合、すべてのレコードが拒否されます。これは、Redshiftへの結果エクスポートのjobが成功した場合でも発生する可能性がありますが、Redshiftにはデータが取り込まれません。
- このconnectorは、timestamp/dateタイプのデータをサポートしていません。このタイプのデータをstringカラムまたはUnix timestampに変換する必要があります。
Result Output to Redshiftは、いくつかのregionにデータをエクスポートできます。以下はサポートされているregionです:
- us-east-1 (US Standard)
- us-west-2 (Oregon)
- eu-west-1 (Ireland)
- ap-northeast-1 (Tokyo)
- us-west-1 (N. California)
- ap-southeast-1 (Singapore)
- ap-southeast-2 (Sydney)
- sa-east-1 (São Paulo)
以下のregionはサポートされていません:
- us-east-2 (Ohio)
- ap-south-1 (Mumbai)
- ap-northeast-2 (Seoul)
- ca-central-1 (Central)
- eu-central-1 (Frankfurt)
- eu-west-2 (London)
サポートしたい他のregionがある場合は、Treasure Data supportに連絡してください。
フロントエンドアプリケーションは、Treasure Agent (td-agent)を介してTreasure Dataに収集されるデータをストリーミングします。Treasure Dataは定期的にデータ上でjobを実行し、jobの結果をRedshift clusterに書き込みます。
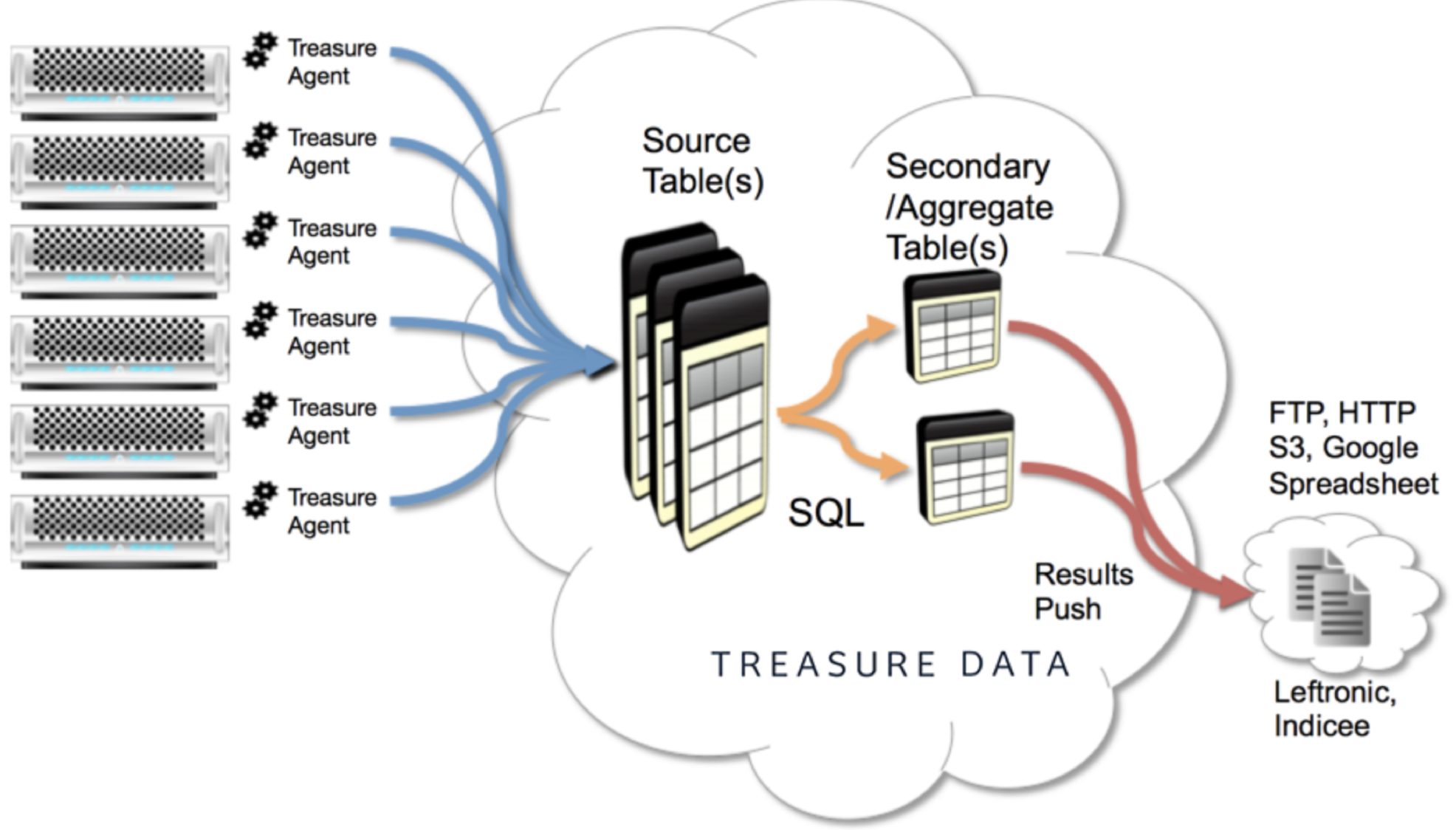
この画像は、Redshiftの使用に精通しているデータアナリストが、データのアップロード方法ではなく、queryと視覚化に集中できるようにする、かなり一般的なアーキテクチャを示しています。
セキュリティポリシーで IP ホワイトリストが必要な場合は、接続を成功させるために Treasure Data の IP アドレスを許可リストに追加する必要があります。
リージョンごとに整理された静的 IP アドレスの完全なリストは、次のリンクにあります: https://api-docs.treasuredata.com/en/overview/ip-addresses-integrations-result-workers/
Amazon Redshiftは、シングルノードモードまたはマルチノード/clusterモードで設定できます。マルチノード構成は、利用可能なノード上でのquery実行の並列化により、より多くのquery計算能力を提供します。
Treasure Dataでは、queryを実行する前にデータconnectionを作成して設定する必要があります。データconnectionの一部として、integrationにアクセスするためのauthenticationを提供します。
TD Consoleを開きます。
Integrations Hub > Catalogに移動します。
Catalog画面の右端にある検索アイコンをクリックし、Amazon Redshiftと入力します。
Amazon Redshift connectorにカーソルを合わせ、Create Authenticationを選択します。

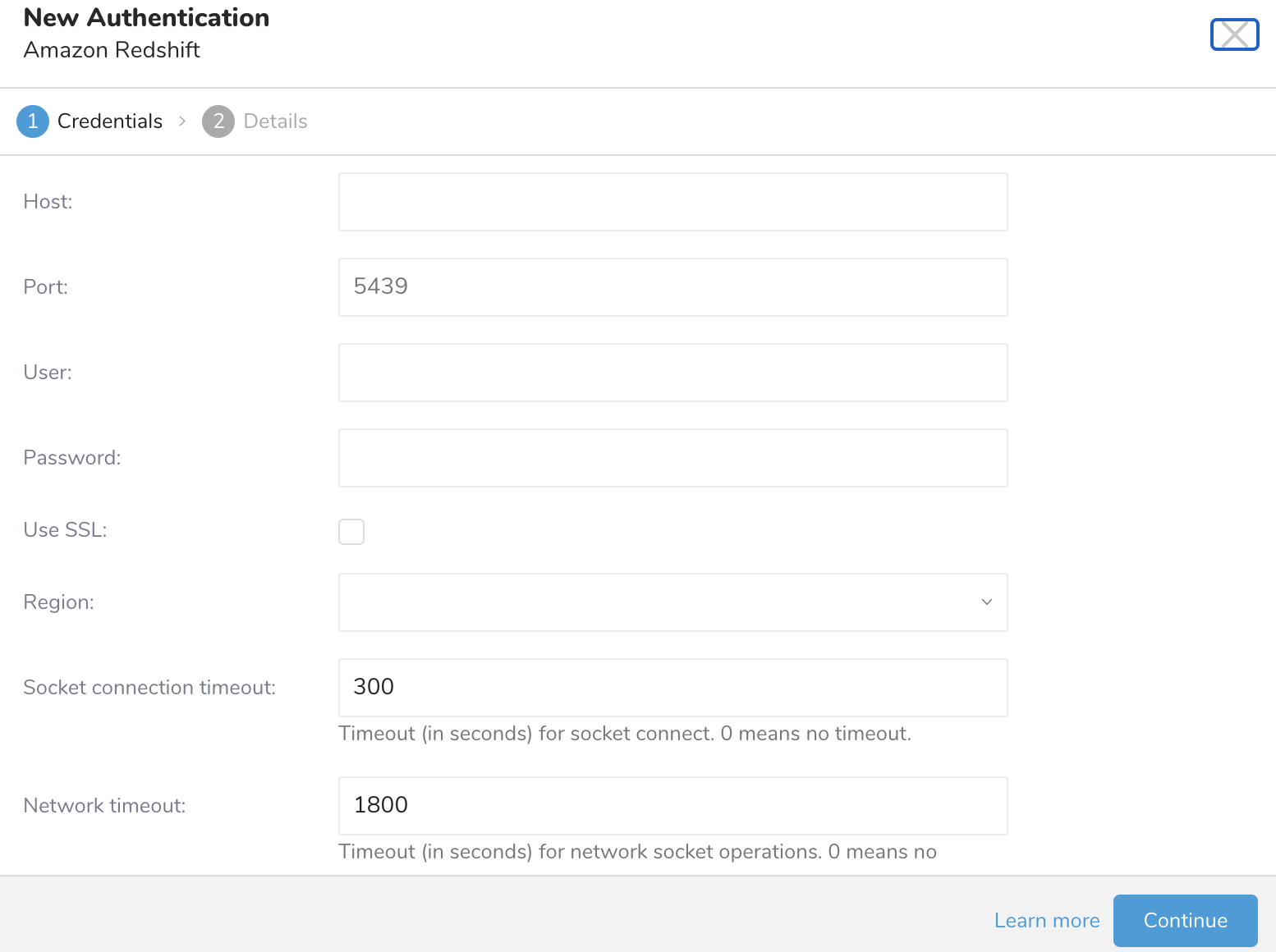
認証するcredentialsを入力します。
| Parameter | Value |
|---|---|
| Host | source databaseのhost情報(IPアドレスなど)。Redshift設定ページから取得できます。通常、形式は次のとおりです:name.<instance_id>.region.redshift.amazonaws.com。nameはclusterに提供されたもの、instance idはcluster作成時にAmazon Redshiftによって自動生成されます、regionは選択したAmazon availability zoneです。hostnameの代わりにIPアドレスを使用している場合は、regionオプションを明示的に設定する必要があります。 |
| Port | sourceインスタンス上の接続port。PostgreSQLのデフォルトは5432です。Redshift serverにアクセスするためのport番号。":"はオプションで、デフォルトでは5439と想定されます。マルチノードcluster設定では異なる場合があります。実際の値は、Redshift clusterの詳細ページから取得できます。 |
| User | source databaseに接続するためのUsername。Amazon RedshiftインスタンスのCredentials。これらのcredentialsは、Redshift clusterを最初に作成するときに指定され、S3 public/private access keysとは異なります。 |
| Password | source databaseに接続するためのpassword。 |
| Use SSL | SSLを使用して接続する場合は、このボックスにチェックを入れます |
| JDBC Connection options | source databaseに必要な特別なJDBC接続(オプション)。 |
| Region | Redshiftインスタンスがホストされているaws region。Redshiftインスタンスが配置されているregionを指定します。hostnameにregion名が含まれていない場合、このオプションが必要です。redshift://user:password@host/database/table?region=us-east-1 |
| Socket connection timeout | socket接続のタイムアウト(秒単位)(デフォルトは300)。 |
| Network timeout | network socketオペレーションのタイムアウト(秒単位)。0はタイムアウトなしを意味します。 |
| Rows per batch | 一度に取得する行数。 |
| Options | JDBC driverに与えたいOptions。Installing Redshift JDBC Driverを参照してください。例えば、これらのパラメータと値のフィールドを使用して、LogLevelやLogPathなどのさまざまなURLオプションを定義できます。jdbc:redshift://company.us-west1.redshift.amazonaws.com:9000/Default;LogLevel=3;LogPath =C: emp Redshiftへのresult outputは、オプションのURLパラメータとして指定できるさまざまなオプションをサポートしています。これらのオプションは互いに互換性があり、組み合わせることができます。該当する場合、デフォルトの動作が示されます。SSL Option sslオプションは、Redshiftに接続する際にSSLを使用するかどうかを決定します。ssl=true Treasure DataからRedshift接続にSSLを使用します。redshift://user:password@host/database/table?ssl=true ssl=false(デフォルト)Treasure DataからRedshiftにSSLを使用しません。redshift://user:password@host/database/table?ssl=false |
必要な接続の詳細を入力した後、Continueを選択します。
後でconnectionの詳細を変更する必要がある場合に見つけられるように、connectionに名前を付けます。
オプションで、組織内の他のユーザーとこのconnectionを共有したい場合は、Share with othersを選択します。
Doneを選択します。
- Creating a Destination Integrationの指示を完了します。
- Data Workbench > Queriesに移動します。
- データをエクスポートするqueryを選択します。
- queryを実行して、結果セットを検証します。
- Export Resultsを選択します。
- 既存のintegration authenticationを選択します。

- 追加のExport Resultsの詳細を定義します。export integrationコンテンツで、integrationパラメータを確認します。 例えば、Export Results画面は異なる場合があり、入力する追加の詳細がない場合もあります:
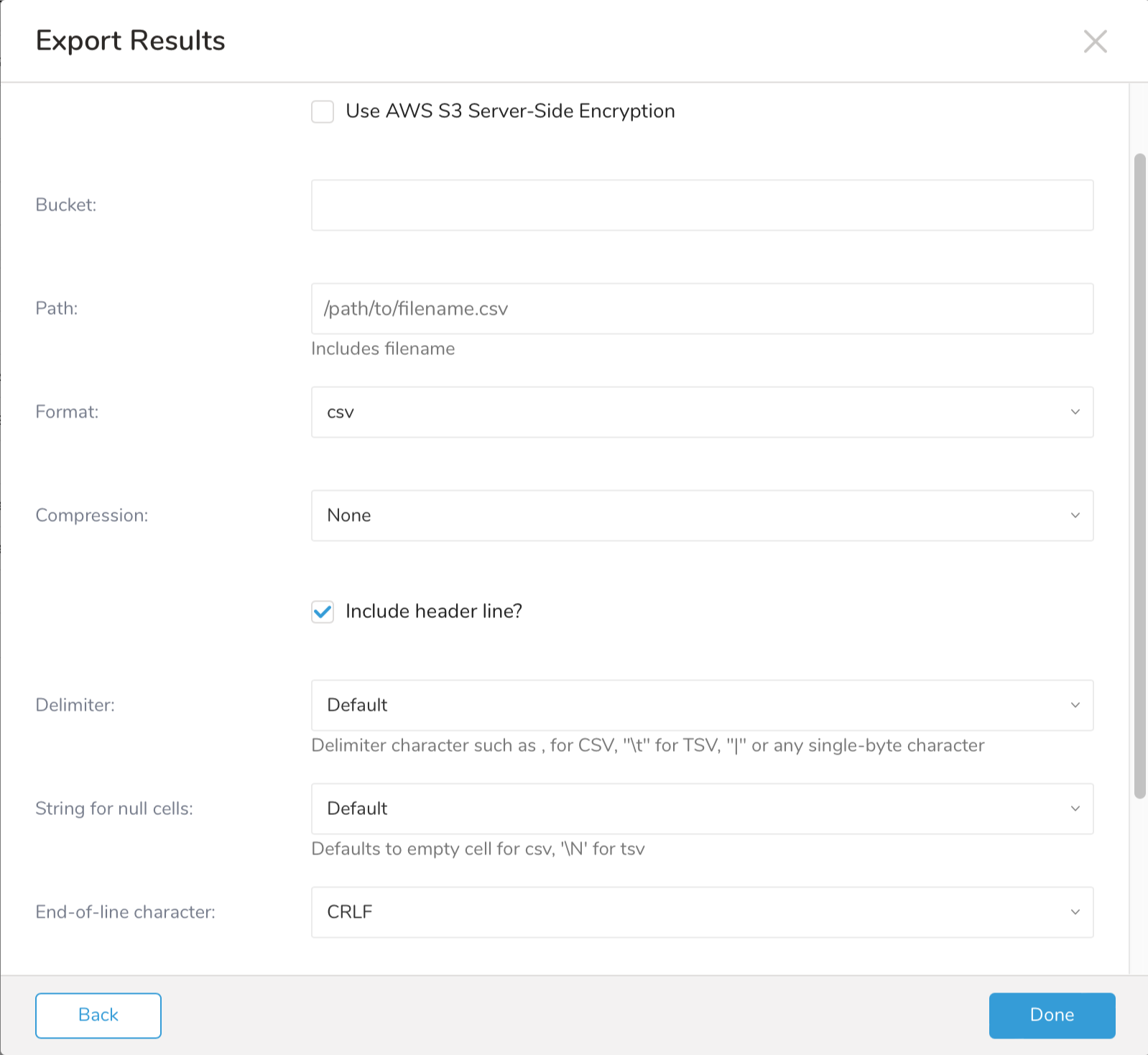
- Doneを選択します。
- queryを実行します。
- データが指定した宛先に移動したことを検証します。
| Parameter | Values | Description |
|---|---|---|
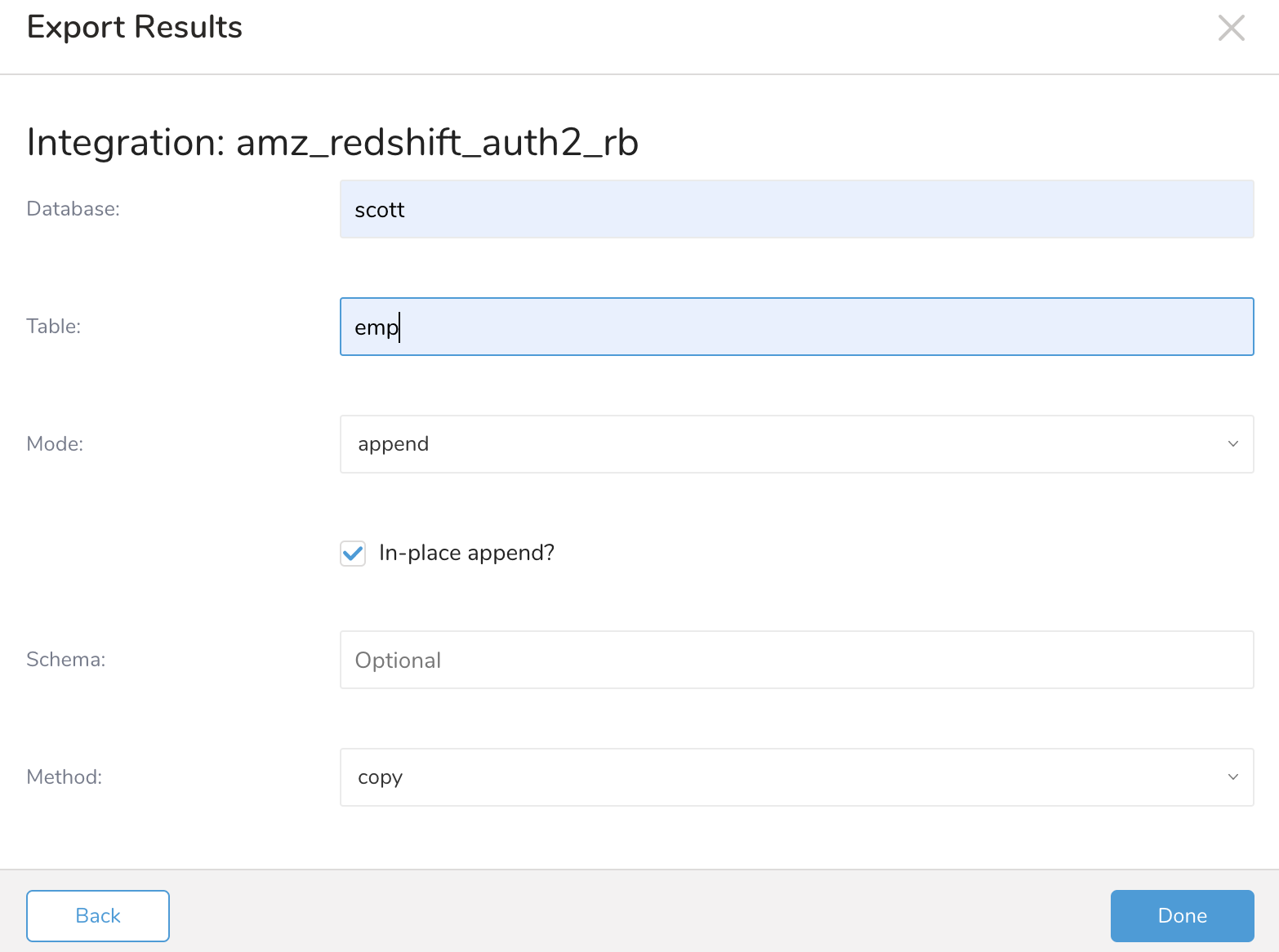
| Database | データをエクスポートするdatabaseの名前。Redshift clusterの作成時に指定されたdatabaseの名前。Redshift clusterの詳細ページから取得できます。 | |
| Table | データをエクスポートするdatabase内のtableの名前。database内のtableの名前。query出力が実行されるときに存在しない場合があります。tableが存在しない場合、指定された名前のtableが作成されます。 | |
| Mode | databaseデータを変更するさまざまな方法を制御します。
| |
| In-place append | select clear | コピーするのではなく、既存のデータを変更するために選択します。これにより、大幅なパフォーマンス向上が得られます。mode=appendの場合、inplaceマイナーオプションでアクションのatomicityを制御できます。trueの場合、temporary tableは使用されず、operationはatomicであることが保証されません。オプションがfalseの場合、temporary tableが使用されます。デフォルト値はtrueです。 |
| Schema | ターゲットtableが配置されているschemaを制御します。指定されていない場合、デフォルトのschemaが使用されます。デフォルトのschemaは、ユーザーの"search_path"設定に依存しますが、通常は"public"です。 | |
| Method | copy bulk copy | copy(デフォルト)このオプションを使用すると、COPY Redshift SQLコマンドを使用して、異なるフローでデータをエクスポートできます。**bulk_copy**このオプションはcopyコマンドを使用しますが、異なるフローを使用します。Treasure DataからSSLを使用してRedshift接続をインスタンス化できます。例:redshift://user:password@host/database/table?method=bulk_copy。 |
| Serial Copy | select clear | serial_copyオプションは、並列にファイルをアップロードするときに発生する可能性のあるデッドロックを回避するために、すべてのファイルを1つずつ順番にアップロードするかどうかを決定します。serial_copy=true serial_copy=false(デフォルト) |
select * from an_redshift_data limit 800000000Audience Studio で activation を作成することで、segment データをターゲットプラットフォームに送信することもできます。
- Audience Studio に移動します。
- parent segment を選択します。
- ターゲット segment を開き、右クリックして、Create Activation を選択します。
- Details パネルで、Activation 名を入力し、前述の Configuration Parameters のセクションに従って activation を設定します。
- Output Mapping パネルで activation 出力をカスタマイズします。

- Attribute Columns
- Export All Columns を選択すると、変更を加えずにすべての列をエクスポートできます。
- + Add Columns を選択して、エクスポート用の特定の列を追加します。Output Column Name には、Source 列名と同じ名前があらかじめ入力されます。Output Column Name を更新できます。+ Add Columns を選択し続けて、activation 出力用の新しい列を追加します。
- String Builder
- + Add string を選択して、エクスポート用の文字列を作成します。次の値から選択します:
- String: 任意の値を選択します。テキストを使用してカスタム値を作成します。
- Timestamp: エクスポートの日時。
- Segment Id: segment ID 番号。
- Segment Name: segment 名。
- Audience Id: parent segment 番号。
- + Add string を選択して、エクスポート用の文字列を作成します。次の値から選択します:
- Schedule を設定します。

- スケジュールを定義する値を選択し、オプションでメール通知を含めます。
- Create を選択します。
batch journey の activation を作成する必要がある場合は、Creating a Batch Journey Activation を参照してください。
TD Toolbeltを使用して、Amazon Redshiftにエクスポートしたいデータを返すqueryを実行する場合:
td query -w -d testdb \
--result 'redshift://username:password@host.redshift.amazonaws.com/database/table?mode=replace' \
"SELECT code, COUNT(1) FROM www_access GROUP BY code"td sched:create hourly_count_example "0 * * * *" -d testdb \
--result 'redshift://username:password@host.redshift.amazonaws.com/database/table?mode=replace' \
"SELECT COUNT(*) FROM www_access"Result Output to Redshiftは、宛先tableがすでに存在する場合、カラムタイプの変換を試みます。変換が失敗すると、カラムがNULLになり、Redshift上のカラムがNOT NULLフィールドの場合、すべてのレコードが拒否されます。