Amazon S3のimportデータコネクタを使用すると、AWS S3バケットに保存されているJSON、TSV、およびCSVファイルからデータをインポートできます。
- Integration v1 vs v2: Amazon S3 Import Integration v2とv1の主な違いと利点は、assume_role認証のサポートが追加されていることです。v2とv1の違いと潜在的な利点を理解するには、次の表を参照してください。
| Authentication Method | Amazon S3 v2 | Amazon S3 v1 |
|---|---|---|
| basic | x | x |
| anonymous | x | |
| session | x | x |
| assume_role | x |
- Amazon S3 - Filename Metadata Enhancedは、v1の機能に以下の追加機能を提供します
- 入力ファイル名を新しいカラムとして取り込むオプション。ファイル名のみ(ファイルパスではない)が各レコードに追加されます。
Treasure Dataの基本的な知識が必要です。
TD リージョンと同じリージョンにある AWS S3 バケットを使用している場合、TD がバケットにアクセスする IP アドレスはプライベートで動的に変化します。アクセスを制限したい場合は、静的 IP アドレスではなく VPC の ID を指定してください。例えば、US リージョンの場合は vpc-df7066ba 経由でアクセスを設定し、Tokyo リージョンの場合は vpc-e630c182 経由、EU01 リージョンの場合は vpc-f54e6a9e 経由でアクセスを設定してください。
TD Console にログインする URL から TD Console のリージョンを確認し、URL 内のリージョンのデータコネクターを参照してください。
詳細については、API ドキュメントを参照してください。
セキュリティポリシーで IP ホワイトリストが必要な場合は、接続を成功させるために Treasure Data の IP アドレスを許可リストに追加する必要があります。
リージョンごとに整理された静的 IP アドレスの完全なリストは、次のリンクにあります: https://api-docs.treasuredata.com/en/overview/ip-addresses-integrations-result-workers/
TD Consoleを使用してデータコネクタを作成できます。
データ接続を構成する際、Integrationにアクセスするための認証を提供します。Treasure Dataでは、認証を構成してからソース情報を指定します。
- Integrations Hub > Catalogに移動し、AWS S3を検索します。
- Create Authenticationを選択します
- Amazon S3 Import V1の場合:
- Amazon S3 - Filename Enhance Metadataの場合
- Amazon S3 Import V1の場合:
- New Authenticationダイアログが開きます。認証情報を使用して認証するには、Access key IDとSecret access keyが必要です。
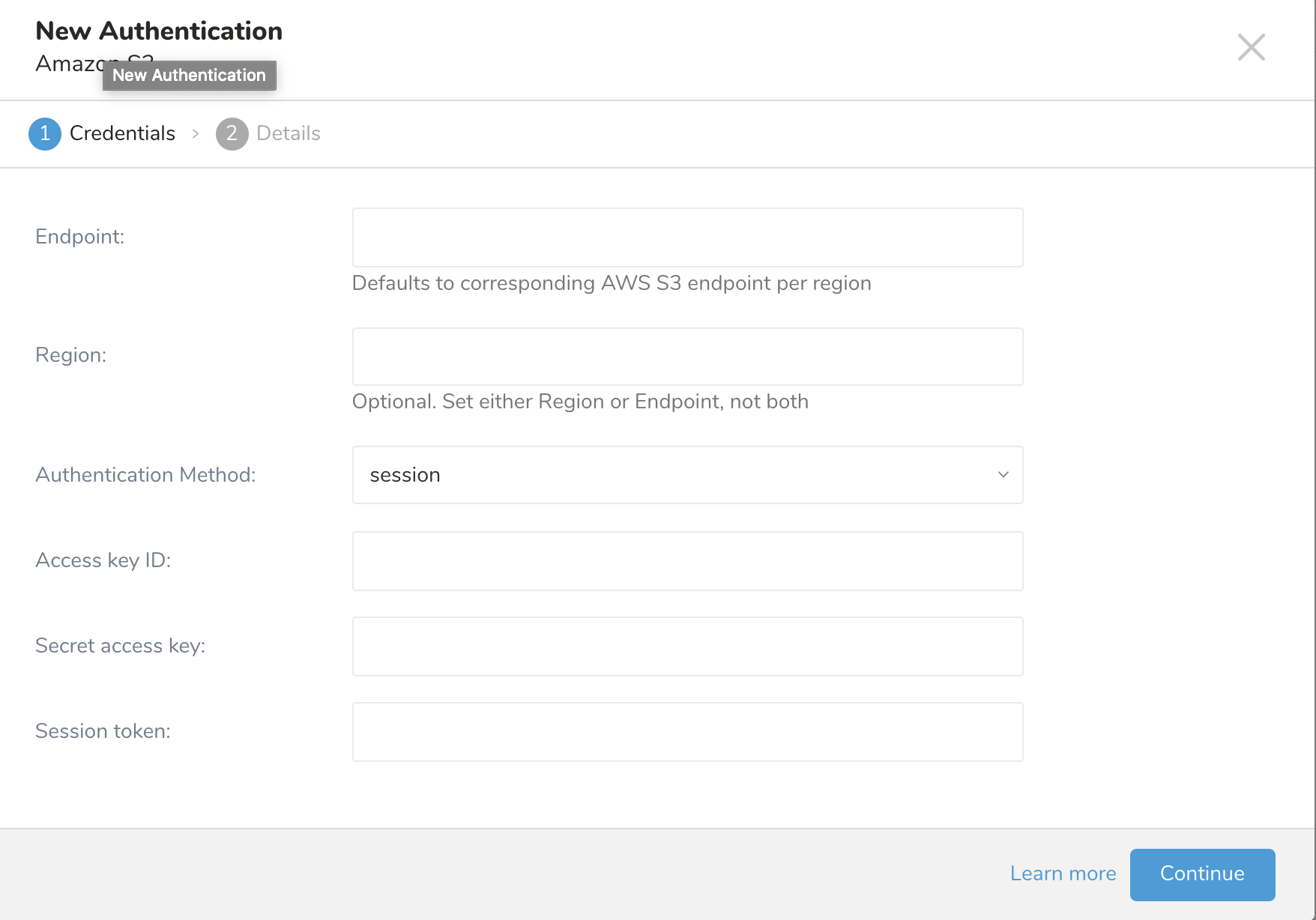
- 以下のパラメータを設定します。Continueを選択します。新しいAWS S3接続に名前を付けます。Doneを選択します。
| Parameter | Description |
|---|---|
| Endpoint |
|
| Authentication Method | |
| basic |
|
| anonymous |
|
| session (推奨) |
|
| Access Key ID | AWS S3が発行 |
| Secret Access Key | AWS S3が発行 |
認証された接続を作成すると、自動的にAuthenticationsに移動します。
- 作成した接続を検索します。
- New Sourceを選択します。
- Data Transfer フィールドにSourceの名前を入力します。
- Next をクリックします。
- Sourceダイアログが開きます。以下のパラメータを編集します。
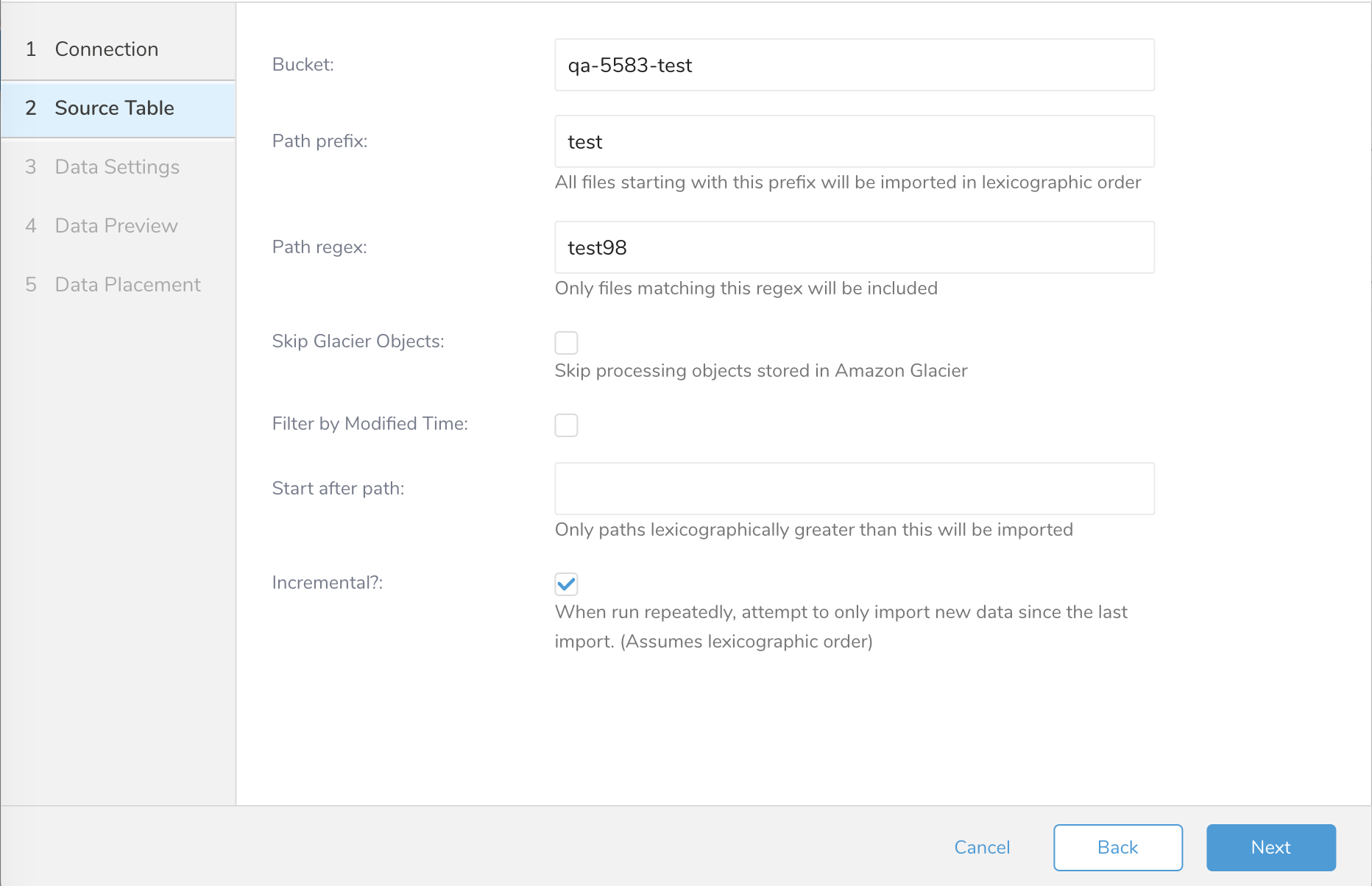
| パラメータ | 説明 |
|---|---|
| Bucket |
|
| Path Prefix |
|
| Path Regex |
|
| Skip Glacier Objects |
|
| Filter by Modified Time |
|
| チェックされていない場合(デフォルト): |
|
| チェックされている場合: |
|
例
Amazon CloudFrontは、静的および動的なWebコンテンツの配信を高速化するWebサービスです。CloudFrontが受信するすべてのユーザーリクエストに関する詳細情報を含むログファイルを作成するようにCloudFrontを設定できます。ロギングを有効にすると、以下のようにCloudFrontログファイルを保存できます:
[your_bucket] - [logging] - [E231A697YXWD39.2017-04-23-15.a103fd5a.gz]
[your_bucket] - [logging] - [E231A697YXWD39.2017-04-23-15.b2aede4a.gz]
[your_bucket] - [logging] - [E231A697YXWD39.2017-04-23-16.594fa8e6.gz]
[your_bucket] - [logging] - [E231A697YXWD39.2017-04-23-16.d12f42f9.gz]この場合、Source Tableの設定は以下のようになります:
- Bucket:your_bucket
- Path Prefix:logging/
- Path Regex:.gz$(必須ではありません)
- Start after path:logging/E231A697YXWD39.2017-04-23-15.b2aede4a.gz(2017-04-23-16からログファイルをインポートしたいと仮定した場合)
- Incremental:true(このジョブをスケジュールする場合)
BZip2 decoderプラグインはデフォルトでサポートされています。Zip Decoder Function
- Next を選択します。 Data Settingsページが開きます。
- 必要に応じてデータ設定を編集するか、このページをスキップします。
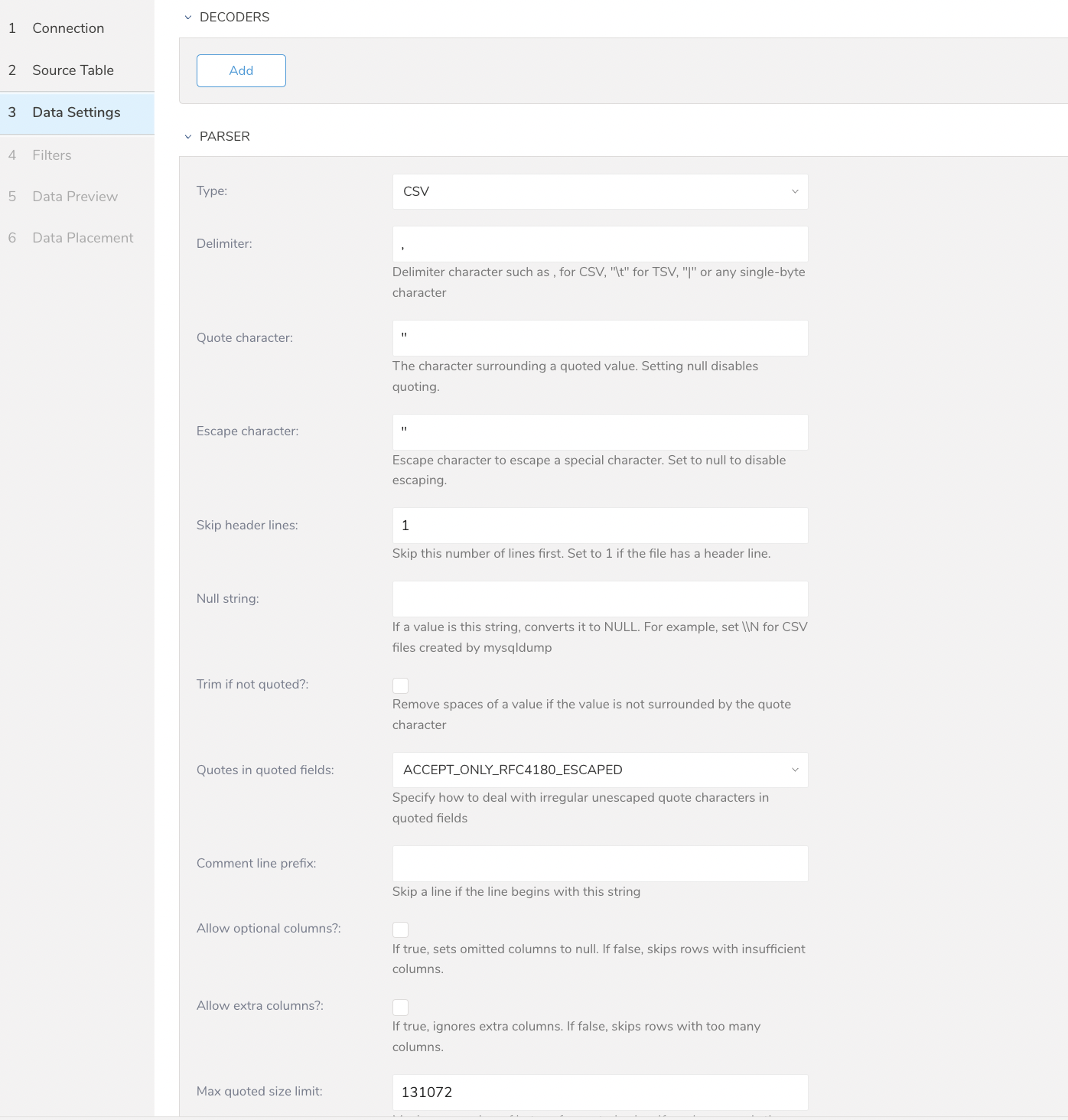
| パラメータ | 説明 |
|---|---|
| Total file count limit | 読み込むファイルの最大数を指定できます |
| Minimum task size | このサイズまでのファイルが1つのタスクにグループ化されます。デフォルト値は268435456(バイト)です。 |
Filters は、S3、FTP、または SFTP コネクターの Create Source または Edit Source インポート設定で使用できます。
Import Integration Filters を使用すると、インポート用のデータ設定の編集を完了した後、インポートされたデータを変更できます。
import integration filters を適用するには:
- Data Settings で Next を選択します。Filters ダイアログが開きます。
- 追加したいフィルターオプションを選択します。
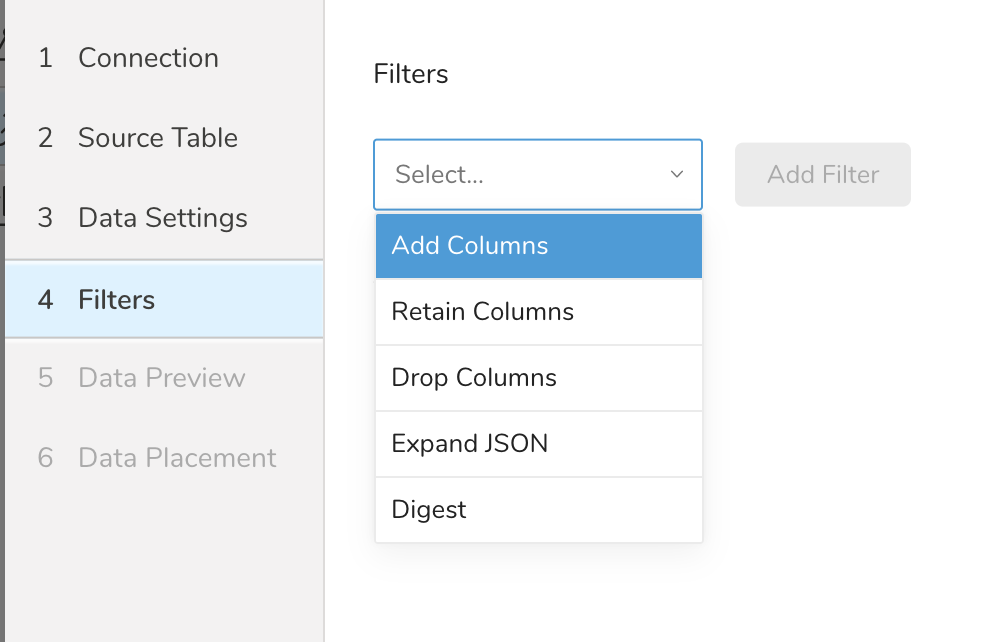
- Add Filter を選択します。そのフィルターのパラメーターダイアログが開きます。
- パラメーターを編集します。各フィルタータイプの情報については、次のいずれかを参照してください:
- Retaining Columns Filter
- Adding Columns Filter
- Dropping Columns Filter
- Expanding JSON Filter
- Digesting Filter
- オプションで、同じタイプの別のフィルターを追加するには、特定の列フィルターダイアログ内で Add を選択します。
- オプションで、別のタイプの別のフィルターを追加するには、リストからフィルターオプションを選択して、同じ手順を繰り返します。
- 追加したいフィルターを追加した後、Next を選択します。Data Preview ダイアログが開きます。
インポートを実行する前に、Generate Preview を選択してデータのプレビューを表示できます。Data preview はオプションであり、選択した場合はダイアログの次のページに安全にスキップできます。
- Next を選択します。Data Preview ページが開きます。
- データをプレビューする場合は、Generate Preview を選択します。
- データを確認します。
データの配置について、データを配置したいターゲット database と table を選択し、インポートを実行する頻度を指定します。
Next を選択します。Storage の下で、インポートされたデータを配置する新しい database を作成するか、既存の database を選択し、新しい table を作成するか、既存の table を選択します。
Database を選択 > Select an existing または Create New Database を選択します。
オプションで、database 名を入力します。
Table を選択 > Select an existing または Create New Table を選択します。
オプションで、table 名を入力します。
データをインポートする方法を選択します。
- Append (デフォルト) - データインポートの結果は table に追加されます。 table が存在しない場合は作成されます。
- Always Replace - 既存の table の全体の内容をクエリの結果出力で置き換えます。table が存在しない場合は、新しい table が作成されます。
- Replace on New Data - 新しいデータがある場合のみ、既存の table の全体の内容をクエリの結果出力で置き換えます。
Timestamp-based Partition Key 列を選択します。 デフォルトキーとは異なるパーティションキーシードを設定したい場合は、long または timestamp 列をパーティショニング時刻として指定できます。デフォルトの時刻列として、add_time フィルターで upload_time を使用します。
データストレージの Timezone を選択します。
Schedule の下で、このクエリを実行するタイミングと頻度を選択できます。
- Off を選択します。
- Scheduling Timezone を選択します。
- Create & Run Now を選択します。
- On を選択します。
- Schedule を選択します。UI では、@hourly、@daily、@monthly、またはカスタム cron の 4 つのオプションが提供されます。
- Delay Transfer を選択して、実行時間の遅延を追加することもできます。
- Scheduling Timezone を選択します。
- Create & Run Now を選択します。
転送が実行された後、Data Workbench > Databases で転送の結果を確認できます。
ジョブログを確認してください。警告とエラーは、インポートの成功に関する情報を提供します。例えば、インポートエラーに関連する source ファイル名を特定できます。
特定のジョブの詳細を確認するには、そのジョブを選択して詳細を表示します。ジョブのタイプに応じて、次のいずれか、またはすべてを確認できます: 結果、クエリ、出力ログ、エンジンログ、詳細、および宛先。
- TD Console を開きます。
- Jobs に移動します。ページの右上に記載されているジョブの数を確認できます。
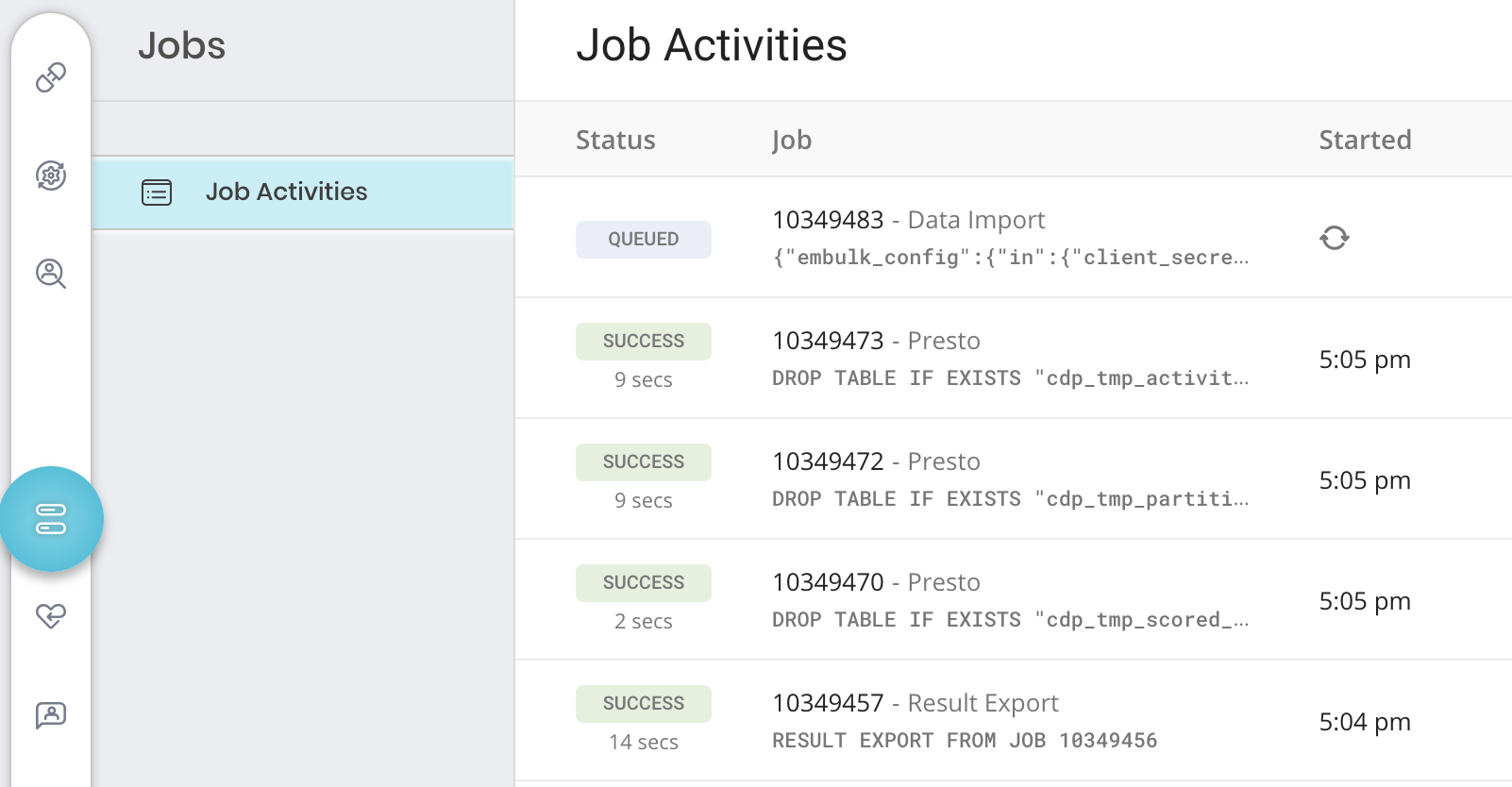 3. オプションで、フィルターを使用してジョブのリストを絞り込み、ジョブ所有者、日付、database 名などでフィルタリングして、関心のあるものを見つけます。 4. ジョブを選択して開き、結果、クエリ定義、ログ、その他の詳細を表示します。
3. オプションで、フィルターを使用してジョブのリストを絞り込み、ジョブ所有者、日付、database 名などでフィルタリングして、関心のあるものを見つけます。 4. ジョブを選択して開き、結果、クエリ定義、ログ、その他の詳細を表示します。
 5. 各タブには、ジョブに関する異なる情報が表示されます。
5. 各タブには、ジョブに関する異なる情報が表示されます。
| タブ名 | 説明 |
|---|---|
| Results |
|
| Query |
|
| Output および Engine Logs |
|
| Details | 詳細情報を表示します:
|
| Destination | ここでは、エクスポート integration 設定の詳細を表示できます(インポート integration には適用されません): - integration - タイプ - 設定 |
ジョブログを確認してください。警告とエラーは、インポートの成功に関する情報を提供します。たとえば、インポートエラーに関連するソースファイル名を特定することができます。
特定のジョブの詳細を確認するには、そのジョブを選択して詳細を表示できます。ジョブの種類に応じて、結果、クエリ、出力ログ、エンジンログ、詳細、送信先のいずれか、またはすべてを確認できます。
- TD Consoleを開きます。
- Jobsに移動します。
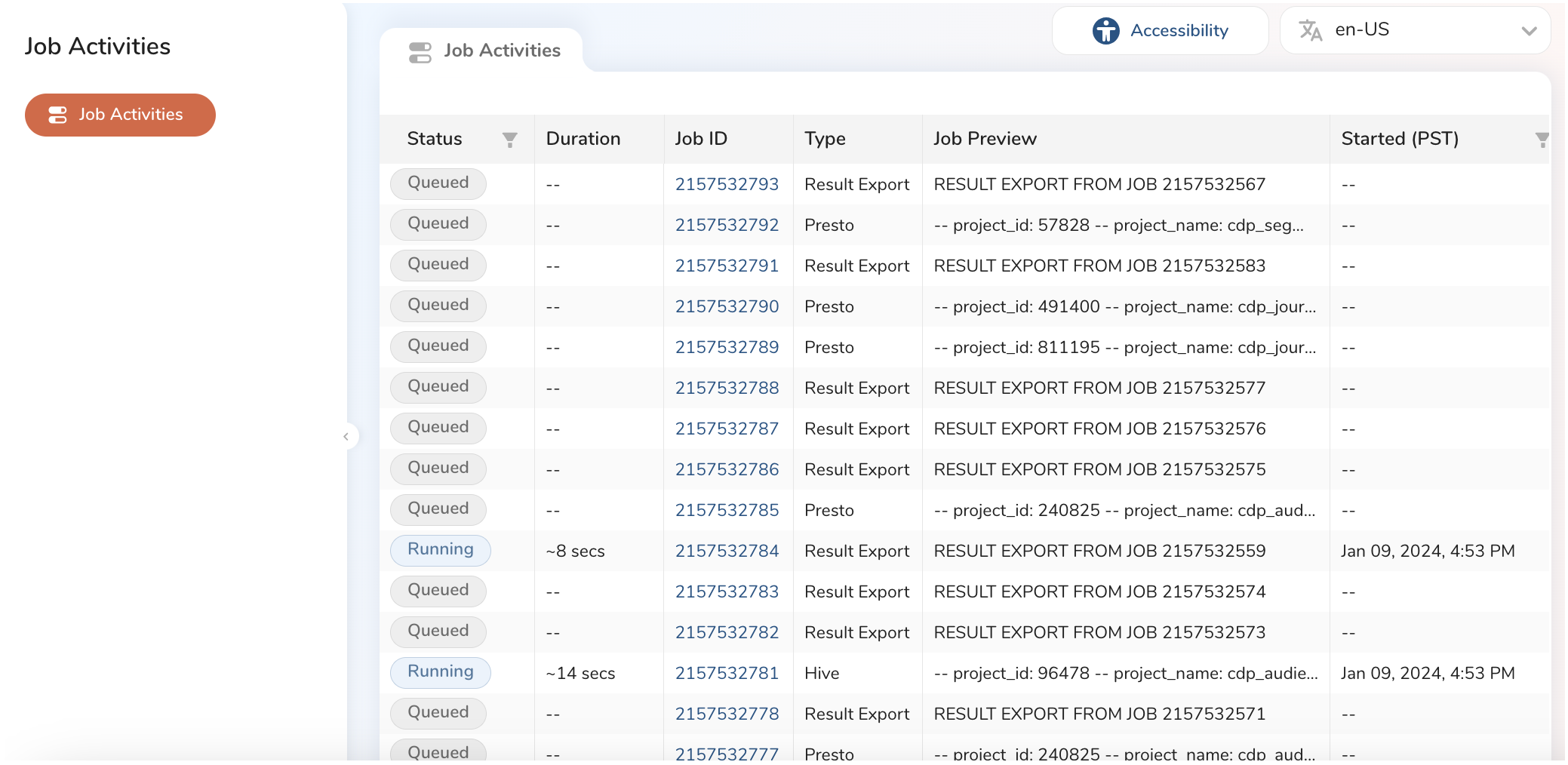 3. オプションで、フィルターを使用してジョブのリストを絞り込み、興味のあるものを見つけます。ジョブの所有者、日付、データベース名でのフィルタリングが含まれます 4. ジョブを選択して開き、結果、クエリ定義、ログ、その他の詳細を表示します。 5. 各タブには、ジョブに関する異なる情報が表示されます。
3. オプションで、フィルターを使用してジョブのリストを絞り込み、興味のあるものを見つけます。ジョブの所有者、日付、データベース名でのフィルタリングが含まれます 4. ジョブを選択して開き、結果、クエリ定義、ログ、その他の詳細を表示します。 5. 各タブには、ジョブに関する異なる情報が表示されます。
| 説明 | |
|---|---|
| Results | - ジョブからインポートされたデータを表示します。 - ここから、結果をクリップボードにコピーしたり、CSVファイルとしてダウンロードしたりできます。 |
| Query | - ジョブのクエリ構文を表示します - クエリエディタを起動します - クエリをコピーして、新しいクエリやワークフローの作成に使用します - クエリを改良して効率を向上させます |
| Output Logs | - ログ情報は、実行時間、クエリ結果数、エラーコードについて確認できます - ログ情報はクリップボードにコピーできます |
| Engine Logs | - ログ情報は、実行時間、クエリ結果数、エラーコードについて確認できます - ログ情報はクリップボードにコピーできます |
| Job Details | 詳細情報を表示します: - クエリ名 - タイプ - ジョブID - ステータス - 期間 - スケジュールされた時間と実際の時間 - 結果のカウントとサイズ - ランナー - クエリされたデータベース - 優先度 |
コネクタジョブが取り込んでいるS3ファイルの数を確認してください。10,000ファイルを超える場合、パフォーマンスが低下します。この問題を軽減するには、次のことができます:
- path_prefixオプションを絞り込み、S3ファイルの数を減らします。
- min_task_sizeオプションに268,435,456(256MB)を設定します。
S3インポート統合用のサンプルワークフローファイルがあります。ymlファイルを使用してインポート設定を定義し、td\_load>: workflowオペレータを使用して実行できます。TD consoleのSourceファンクションだけでは使用できない変数定義が、ymlファイルベースの実行では可能です。
サンプルコードはhttps://github.com/treasure-data/treasure-boxes/tree/master/td_load/s3から参照できます。
timezone: UTC
schedule:
daily>: 02:00:00
sla:
time: 08:00
+notice:
mail>: {data: Treasure Workflow Notification}
subject: This workflow is taking long time to finish
to: [me@example.com]
_export:
td:
dest_db: dest_db_ganesh
dest_table: dest_table_ganesh
+prepare_table:
td_ddl>:
create_databases: ["${td.dest_db}"]
create_tables: ["${td.dest_table}"]
database: ${td.dest_db}
+load:
td_load>: config/daily_load.yml
database: ${td.dest_db}
table: ${td.dest_table}オプションとして、TD Toolbeltを使用して接続を設定し、ジョブを作成し、実行をスケジュールすることができます。
コネクタをセットアップする前に、'td'コマンドをインストールします。最新のTD Toolbeltをインストールしてください。
次の例に示すように、AWSアクセスキーとシークレットアクセスキーを使用してseed.ymlを準備します。バケット名とソースファイル名(または複数ファイルのプレフィックス)も指定する必要があります。
in:
type: s3
access_key_id: XXXXXXXXXX
secret_access_key: YYYYYYYYYY
bucket: sample_bucket
# path to the *.json or *.csv or *.tsv file on your s3 bucket
path_prefix: path/to/sample_file
path_match_pattern: \.csv$ # a file will be skipped if its path doesn't match with this pattern
## some examples of regexp:
#path_match_pattern: /archive/ # match files in .../archive/... directory
#path_match_pattern: /data1/|/data2/ # match files in .../data1/... or .../data2/... directory
#path_match_pattern: .csv$|.csv.gz$ # match files whose suffix is .csv or .csv.gz
out:
mode: appendData Connector for Amazon S3は、指定されたプレフィックスに一致するすべてのファイルをインポートします。(例:path_prefix: path/to/sample_ –> path/to/sample_201501.csv.gz、path/to/sample_201502.csv.gz、…、path/to/sample_201505.csv.gz)。
先頭に'/'を付けたpath_prefixを使用すると、意図しない結果につながる可能性があります。たとえば、「path_prefix: /path/to/sample_file」は、プラグインがs3://sample_bucket//path/to/sample_fileでファイルを探すことになり、意図したs3://sample_bucket/path/to/sample_fileのパスとは異なります。
connector:guessを使用します。このコマンドは自動的にソースファイルを読み込み、ファイル形式とそのフィールド/カラムを評価(ロジックを使用して推測)します。
$ td connector:guess seed.yml -o load.ymlload.ymlを開くと、ファイル形式、エンコーディング、カラム名、および型を含む評価されたファイル形式定義が表示されます。
in:
type: s3
access_key_id: XXXXXXXXXX
secret_access_key: YYYYYYYYYY
bucket: sample_bucket
path_prefix: path/to/sample_file
parser:
charset: UTF-8
newline: CRLF
type: csv
delimiter: ','
quote: '"'
escape: ''
skip_header_lines: 1
columns:
- name: id
type: long
- name: company
type: string
- name: customer
type: string
- name: created_at
type: timestamp
format: '%Y-%m-%d %H:%M:%S'
out:
mode: append次に、td connector:previewコマンドを使用してデータのプレビューを確認できます。
$ td connector:preview load.yml
+-------+---------+----------+---------------------+
| id | company | customer | created_at |
+-------+---------+----------+---------------------+
| 11200 | AA Inc. | David | 2015-03-31 06:12:37 |
| 20313 | BB Imc. | Tom | 2015-04-01 01:00:07 |
| 32132 | CC Inc. | Fernando | 2015-04-01 10:33:41 |
| 40133 | DD Inc. | Cesar | 2015-04-02 05:12:32 |
| 93133 | EE Inc. | Jake | 2015-04-02 14:11:13 |
+-------+---------+----------+---------------------+guessコマンドは、ソースデータのサンプル行を使用してカラム定義を評価するため、ソースデータファイルに3行以上、2カラム以上が必要です。
カラム名またはカラムタイプが予期しないものとして検出された場合は、load.ymlを直接修正して再度プレビューしてください。
現在、Data Connectorは「boolean」、「long」、「double」、「string」、および「timestamp」タイプの解析をサポートしています。
ロードジョブを送信します。データのサイズによっては数時間かかる場合があります。データを保存するTreasure Dataのデータベースとテーブルを指定します。
Treasure Dataのストレージは時間でパーティション化されているため(データパーティショニングを参照)、--time-columnオプションを指定することをお勧めします。このオプションが指定されていない場合、Data Connectorは最初のlongまたはtimestampカラムをパーティショニング時間として選択します。--time-columnで指定されるカラムのタイプは、longとtimestampタイプのいずれかである必要があります。
データに時間カラムがない場合は、add_timeフィルターオプションを使用して時間カラムを追加できます。詳細については、add_time filter pluginを参照してください。
$ td connector:issue load.yml --database td_sample_db --table td_sample_table --time-column created_atconnector:issueコマンドは、すでにdatabase(td_sample_db)とtable(td_sample_table)を作成していることを前提としています。データベースまたはテーブルがTDに存在しない場合、このコマンドは成功しないため、データベースとテーブルを手動で作成するか、td connector:issueコマンドで--auto-create-tableオプションを使用してデータベースとテーブルを自動作成してください。
$ td connector:issue load.yml --database td_sample_db --table td_sample_table --time-column created_at --auto-create-tableData Connectorはサーバー側でレコードをソートしません。時間ベースのパーティショニングを効果的に使用するには、事前にファイル内のレコードをソートしてください。
timeというフィールドがある場合は、--time-columnオプションを指定する必要はありません。
$ td connector:issue load.yml --database td_sample_db --table td_sample_tableデータ配置の場合は、データを配置するターゲットのデータベースとテーブルを選択し、インポートを実行する頻度を指定します。
Nextを選択します。Storageの下で、新しいデータベースを作成するか既存のデータベースを選択し、インポートしたデータを配置する新しいテーブルを作成するか既存のテーブルを選択します。
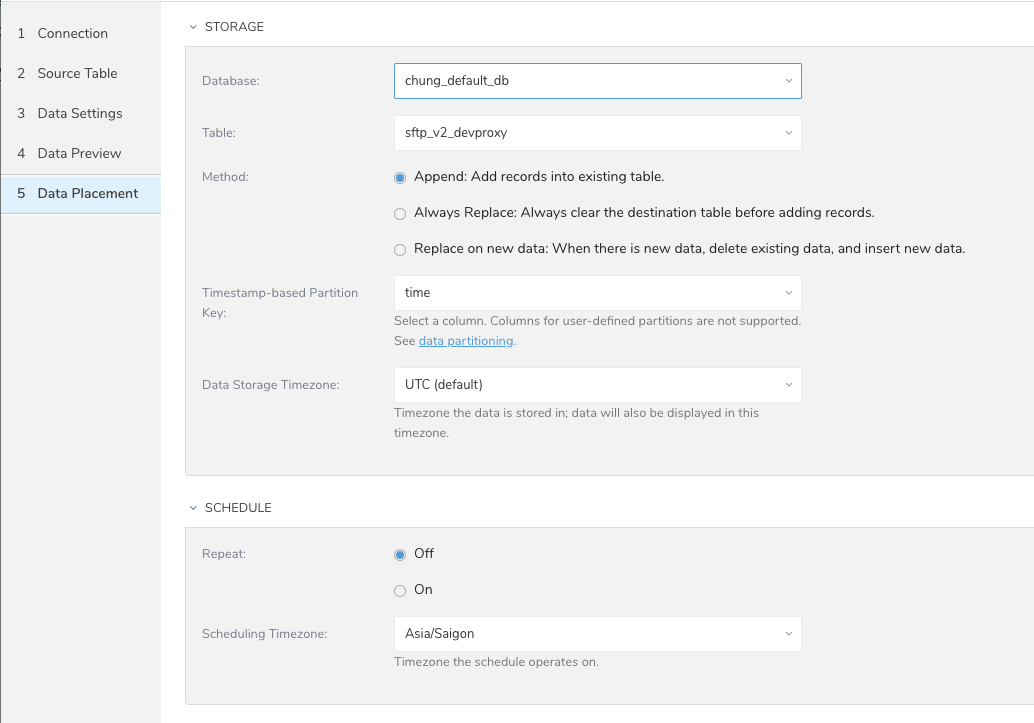
Databaseを選択 > Select an existingまたはCreate New Databaseを選択します。
オプションで、データベース名を入力します。
Tableを選択 > Select an existingまたはCreate New Tableを選択します。
オプションで、テーブル名を入力します。
データをインポートする方法を選択します。
- Append(デフォルト)- データインポートの結果はテーブルに追加されます。 テーブルが存在しない場合は、作成されます。
- Always Replace - 既存のテーブルの全コンテンツをクエリの結果出力で置き換えます。テーブルが存在しない場合は、新しいテーブルが作成されます。
- Replace on New Data - 新しいデータがある場合のみ、既存のテーブルの全コンテンツをクエリの結果出力で置き換えます。
Timestamp-based Partition Key カラムを選択します。 デフォルトキーとは異なるパーティションキーシードを設定する場合は、long または timestamp カラムをパーティショニング時刻として指定できます。デフォルトの時刻カラムとしては、add_time フィルタを使用した upload_time が使用されます。
データストレージの Timezone を選択します。
Schedule で、このクエリを実行する時期と頻度を選択できます。
- 一度だけ実行:
- Off を選択します。
- Scheduling Timezone を選択します。
- Create & Run Now を選択します。
クエリを繰り返し実行:
- On を選択します。
- Schedule を選択します。UI では @hourly、@daily、@monthly、またはカスタム cron の4つのオプションが提供されます。
- Delay Transfer を選択して、実行時刻の遅延を追加することもできます。
- Scheduling Timezone を選択します。
- Create & Run Now を選択します。
転送が実行された後、転送の結果は Data Workbench > Databases で確認できます。
増分ファイルインポートのために、定期的なデータコネクタ実行をスケジュールできます。高可用性を確保するために、スケジューラは慎重に設定されています。
スケジュールされたインポートでは、指定されたプレフィックスに一致するすべてのファイルと、以下のいずれかのフィールドを条件としてインポートできます:
- use_modified_time が無効の場合、次の実行のために最後のパスが保存されます。2回目以降の実行では、コネクタはアルファベット順で最後のパス以降のファイルのみをインポートします。
- それ以外の場合、ジョブが実行された時刻が次の実行のために保存されます。2回目以降の実行では、コネクタはその実行時刻以降にアルファベット順で変更されたファイルのみをインポートします。
td connector:create コマンドを使用して新しいスケジュールを作成できます。
$ td connector:create daily_import "10 0 * * *" \
td_sample_db td_sample_table load.ymlTreasure Data のストレージは時刻でパーティション化されているため、--time-column オプションを指定することも推奨されます(データパーティショニングも参照してください)。
$ td connector:create daily_import "10 0 * * *" \
td_sample_db td_sample_table load.yml \
--time-column created_atcron パラメータは、@hourly、@daily、@monthly の3つの特別なオプションも受け入れます。
デフォルトでは、スケジュールは UTC タイムゾーンで設定されます。-t または --timezone オプションを使用して、タイムゾーンでスケジュールを設定できます。--timezone オプションは、'Asia/Tokyo'、'America/Los_Angeles' などの拡張タイムゾーン形式のみをサポートします。PST、CST などのタイムゾーン略語は*サポートされておらず*、予期しないスケジュールにつながる可能性があります。
td connector:list コマンドを実行すると、現在スケジュールされているエントリのリストを確認できます。
$ td connector:list
+--------------+--------------+----------+-------+--------------+-----------------+------------------------------------------+
| Name | Cron | Timezone | Delay | Database | Table | Config |
+--------------+--------------+----------+-------+--------------+-----------------+------------------------------------------+
| daily_import | 10 0 * * * | UTC | 0 | td_sample_db | td_sample_table | {"in"=>{"type"=>"s3", "access_key_id"... |
+--------------+--------------+----------+-------+--------------+-----------------+------------------------------------------+td connector:show は、スケジュールエントリの実行設定を表示します。
各項目の説明:
| <access_key_id> | TD AWS サービスへのアクセスを許可します |
| --- | --- | | <secret_access_key> | TD AWS サービスへのアクセスを許可します | | endpoint | ネットワークと相互に通信するコンピュータ 例: s3.amazonaws.com | | bucket | データベース内のコンテナオブジェクト 例: https://my-bucket.s3.us-west-2.amazonaws.com | | <path_prefix> | ターゲットキーのプレフィックスを指定 例: logging/ path/to/sample_201501.csv.gz、path/to/sample_201502.csv.gz、…、path/to/sample_201505.csv.gz |
% td connector:show daily_import
Name : daily_import
Cron : 10 0 * * *
Timezone : UTC
Delay : 0
Database : td_sample_db
Table : td_sample_table
Config
---
in:
type: s3
access_key_id: access_key_id
secret_access_key: secret_access_key
endpoint: endpoint
bucket: bucket
path_prefix: path_prefix
parser:
charset: UTF-8
...td connector:history は、スケジュールエントリの実行履歴を表示します。個々の実行結果を調査するには、td job jobid を使用します。
% td connector:history daily_import
+--------+---------+---------+--------------+-----------------+----------+---------------------------+----------+
| JobID | Status | Records | Database | Table | Priority | Started | Duration |
+--------+---------+---------+--------------+-----------------+----------+---------------------------+----------+
| 578066 | success | 10000 | td_sample_db | td_sample_table | 0 | 2015-04-18 00:10:05 +0000 | 160 |
| 577968 | success | 10000 | td_sample_db | td_sample_table | 0 | 2015-04-17 00:10:07 +0000 | 161 |
| 577914 | success | 10000 | td_sample_db | td_sample_table | 0 | 2015-04-16 00:10:03 +0000 | 152 |
| 577872 | success | 10000 | td_sample_db | td_sample_table | 0 | 2015-04-15 00:10:04 +0000 | 163 |
| 577810 | success | 10000 | td_sample_db | td_sample_table | 0 | 2015-04-14 00:10:04 +0000 | 164 |
| 577766 | success | 10000 | td_sample_db | td_sample_table | 0 | 2015-04-13 00:10:04 +0000 | 155 |
| 577710 | success | 10000 | td_sample_db | td_sample_table | 0 | 2015-04-12 00:10:05 +0000 | 156 |
| 577610 | success | 10000 | td_sample_db | td_sample_table | 0 | 2015-04-11 00:10:04 +0000 | 157 |
+--------+---------+---------+--------------+-----------------+----------+---------------------------+----------+
8 rows in settd connector:delete は、スケジュールを削除します。
$ td connector:delete daily_importYML設定ファイルで指定され、connector:guess および connector:issue コマンドで使用されるIAM認証情報には、アクセスする必要があるAWS S3リソースに対する権限が許可されている必要があります。IAMユーザーがこれらの権限を持っていない場合は、事前定義されたポリシー定義の1つでユーザーを設定するか、JSON形式で新しいポリシー定義を作成してください。
以下の例は、Policy Definition reference形式に基づいており、your-bucketに対する読み取り専用(GetObjectおよびListBucketアクションを通じて)権限をIAMユーザーに付与します。
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"s3:GetObject",
"s3:ListBucket"
],
"Resource": [
"arn:aws:s3:::your-bucket",
"arn:aws:s3:::your-bucket/*"
]
}
]
}your-bucketを実際のバケット名に置き換えてください。
特定の場合、access_key_idとsecret_access_keyによるIAM基本認証はリスクが高すぎる可能性があります(ただし、ジョブが実行されるとき、またはセッションが作成された後、secret_access_keyは明確に表示されることはありません)。
S3 data connectorは、AWS Secure Token Service (STS)が提供するTemporary Security Credentialsを使用できます。AWS STSを使用すると、任意のIAMユーザーが自身のaccess_key_idとsecret_access_keyを使用して、有効期限が関連付けられた一時的なnew_access_key_id、new_secret_access_key、およびsession_tokenキーのセットを作成でき、その有効期限が過ぎると認証情報は無効になります。 Temporary Security Credentialsには以下のタイプがあります。
- Session Token 有効期限が関連付けられた最もシンプルなSecurity Credentialsです。一時的な認証情報は、それらを生成するために使用された元のIAM認証情報が持っていたすべてのリソースへのアクセスを提供します。これらの認証情報は、有効期限が切れておらず、元のIAM認証情報の権限が変更されていない限り有効です。
- Federation Token 上記のSession Tokenに権限制御の追加レイヤーを追加します。Federation Tokenを生成する際、IAMユーザーはPermission Policy定義を指定する必要があります。スコープを使用して、IAMユーザーがアクセス可能なリソースのうち、Federation Tokenの所有者がアクセスすべきリソースをさらに絞り込むことができます。任意のPermission Policy定義を使用できますが、権限のスコープは、トークンを生成するために使用されたIAMユーザーが持っていた権限のすべてまたは一部のサブセットに限定されます。Session Tokenと同様に、Federation Token認証情報は、有効期限が切れておらず、元のIAM認証情報に関連付けられた権限が変更されていない限り有効です。
AWS STS Temporary Security Credentialsは、AWS CLIまたは選択した言語のAWS SDKを使用して生成できます。
$ aws sts get-session-token --duration-seconds 900
{
"Credentials": {
"SecretAccessKey": "YYYYYYYYYY",
"SessionToken": "ZZZZZZZZZZ",
"Expiration": "2015-12-23T05:11:14Z",
"AccessKeyId": "XXXXXXXXXX"
}
}$ aws sts get-federation-token --name temp_creds --duration-seconds 900 --policy '{"Statement": [{"Effect": "Allow", "Action": ["s3:GetObject", "s3:ListBucket"], "Resource": "arn:aws:s3:::bucketname"}]}'
{
"FederatedUser": {
"FederatedUserId": "523683666290:temp_creds",
"Arn": "arn:aws:sts::523683666290:federated-user/temp_creds"
},
"Credentials": {
"SecretAccessKey": "YYYYYYYYYY",
"SessionToken": "ZZZZZZZZZZ",
"Expiration": "2015-12-23T06:06:17Z",
"AccessKeyId": "XXXXXXXXXX"
},
"PackedPolicySize": 16
}ここで: * temp_cred は Federated トークン/ユーザーの名前です * bucketname はアクセスを許可するバケットの名前です。詳細については ARN仕様 を参照してください * s3:GetObject と s3:ListBucket は AWS S3 バケットの基本的な読み取り操作です。
AWS STS 認証情報は取り消すことができません。有効期限が切れるまで、または認証情報の生成に使用した元の IAM ユーザーの権限を削除するまで有効です。
Temporary Security Credentials が生成されたら、seed.yml ファイルに SecretAccessKey、AccessKeyId、および SessionToken を次のようにコピーします。
in:
type: s3
auth_method: session
access_key_id: XXXXXXXXXX
secret_access_key: YYYYYYYYYY
session_token: ZZZZZZZZZZ
bucket: sample_bucket
path_prefix: path/to/sample_fileそして、通常通り Data Connector for S3 を実行します。
STS 認証情報は指定された時間が経過すると期限切れになるため、認証情報の有効期限が切れると、その認証情報を使用するデータコネクタジョブは最終的に失敗し始める可能性があります。 現在、STS 認証情報の有効期限切れが報告された場合、データコネクタジョブは最大回数(5回)まで再試行し、最終的に「error」ステータスで完了します。