Amazon Simple Storage Service (Amazon S3)は、スケーラビリティ、データの可用性、セキュリティ、パフォーマンスを提供するオブジェクトストレージサービスです。データレイク、ウェブサイト、モバイルアプリケーション、バックアップと復元、アーカイブ、エンタープライズアプリケーション、IoTデバイス、ビッグデータ分析などのために、あらゆる量のデータを保存および保護するために使用できます。Amazon S3は、ビジネス、組織、コンプライアンス要件に対応するデータ編成とアクセス制御の構成機能を提供します。
このTD export integrationを使用すると、Treasure Dataからジョブ結果を直接Amazon S3に書き込むことができます。
- データの保存: バケットに無制限のデータを保存できます。
- Treasure Dataの基本的な知識(TD Toolbeltを含む)
- AWS用:
s3:PutObjectおよびs3:AbortMultipartUpload権限を持つIAM User。この接続に使用するIAM Userには他の権限を設定しないことをお勧めします。
- S3へのエクスポートのクエリ結果の制限は100GBです。クエリ結果が制限を超える場合、ログに次のメッセージが表示されます:
The number of chunks for multipart upload is exceeded.クエリでデータを分割してみてください。 - デフォルトのエクスポート形式はCSV RFC 4180です。
- TSV形式での出力もサポートされています。
セキュリティポリシーで IP ホワイトリストが必要な場合は、接続を成功させるために Treasure Data の IP アドレスを許可リストに追加する必要があります。
リージョンごとに整理された静的 IP アドレスの完全なリストは、次のリンクにあります: https://api-docs.treasuredata.com/en/overview/ip-addresses-integrations-result-workers/
AWS S3 Server-Side Encryptionを使用してアップロードデータを暗号化できます。このために暗号化キーを準備する必要はありません。データは、256ビットAdvanced Encryption Standard (AES-256)を使用してサーバー側で暗号化されます。
バケットに保存されているすべてのオブジェクトにサーバー側の暗号化が必要な場合は、Server-Side Encryptionバケットポリシーを使用してください。サーバー側の暗号化が有効になっている場合、use_sseオプションをオンにする必要はありません。ただし、暗号化情報なしのHTTPリクエストを拒否するバケットポリシーが設定されている場合、ジョブ結果が失敗する可能性があります。
td query \
--result 's3://accesskey:secretkey@/bucketname/path/to/file.csv?use_sse=true&sse_algorithm=AES256' \
-w -d testdb \
"SELECT code, COUNT(1) AS cnt FROM www_access GROUP BY code"デフォルトのエクスポート形式はCSV RFC 4180です。TSV形式での出力もサポートされています。
ファイル形式をカスタマイズするオプション...
CSVとTSVの両方の形式について、次の表に示すオプションを使用して、宛先に書き込まれるファイルの最終形式をカスタマイズできます:
| Name | Description | Restrictions | CSV default | TSV default | JSONL |
|---|---|---|---|---|---|
| format | ファイル形式を指定するメイン設定 | csv | csv (TSV形式を選択するには'tsv'を使用) | JSONL形式を選択するにはJSONLを使用 | |
| delimiter | 区切り文字を指定するために使用 | , (comma) | \t (tab) | Parameter ignored | |
| quote | 引用符文字を指定するために使用 | TSV形式では使用不可 | " (double quote) | (no character) | Parameter ignored |
| escape | 他の特殊文字をエスケープするために使用される文字を指定 | TSV形式では使用不可 | " (double quote) | (no character) | Parameter ignored |
| null | 'null'値の表示方法を指定するために使用 | (empty string) | \N (backslash capital n) | Parameter ignored | |
| newline | EOL (End-Of-Line)表現を指定するために使用 | (CRLF) | (CRLF) | ||
| header | 列ヘッダーを抑制するために使用可能 | 列ヘッダーが出力されます。抑制するには'false'を使用 | 列ヘッダーが出力されます。抑制するには'false'を使用 | Parameter ignored |
次の例は、カスタマイズが要求されていない場合のCSV形式のデフォルトサンプル出力を示しています:
code,cnt
"200",4981
"302",
"404",17
"500",2format=tsv、delimiter="、null=NULLオプションが指定された場合:
td query \
--result 's3://accesskey:secretkey@/bucket_name/path/to/file.tsv?format=tsv&delimiter=%22&null=empty' \
-w -d testdb \
"SELECT code, COUNT(1) AS cnt FROM www_access GROUP BY code"access keyとsecret keyはURLエンコードする必要があります。 出力は次のように変更されます:
"code" "cnt"
"200" 4981
"302" NULL
"404" 17
"500" 2Treasure Dataでは、クエリを実行する前にデータ接続を作成して構成する必要があります。データ接続の一部として、統合にアクセスするための認証を提供します。
- TD Consoleを開きます。
- Integrations Hub > Catalogに移動します。
- AWS S3を検索します。
- Create Authenticationを選択します。
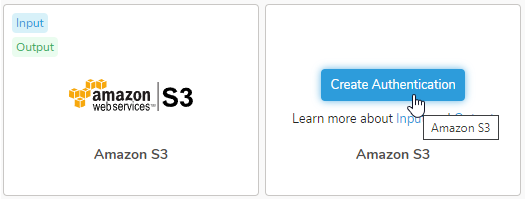
- New Authenticationダイアログが開きます。認証情報を使用して認証するには、client IDとaccess keysが必要です。
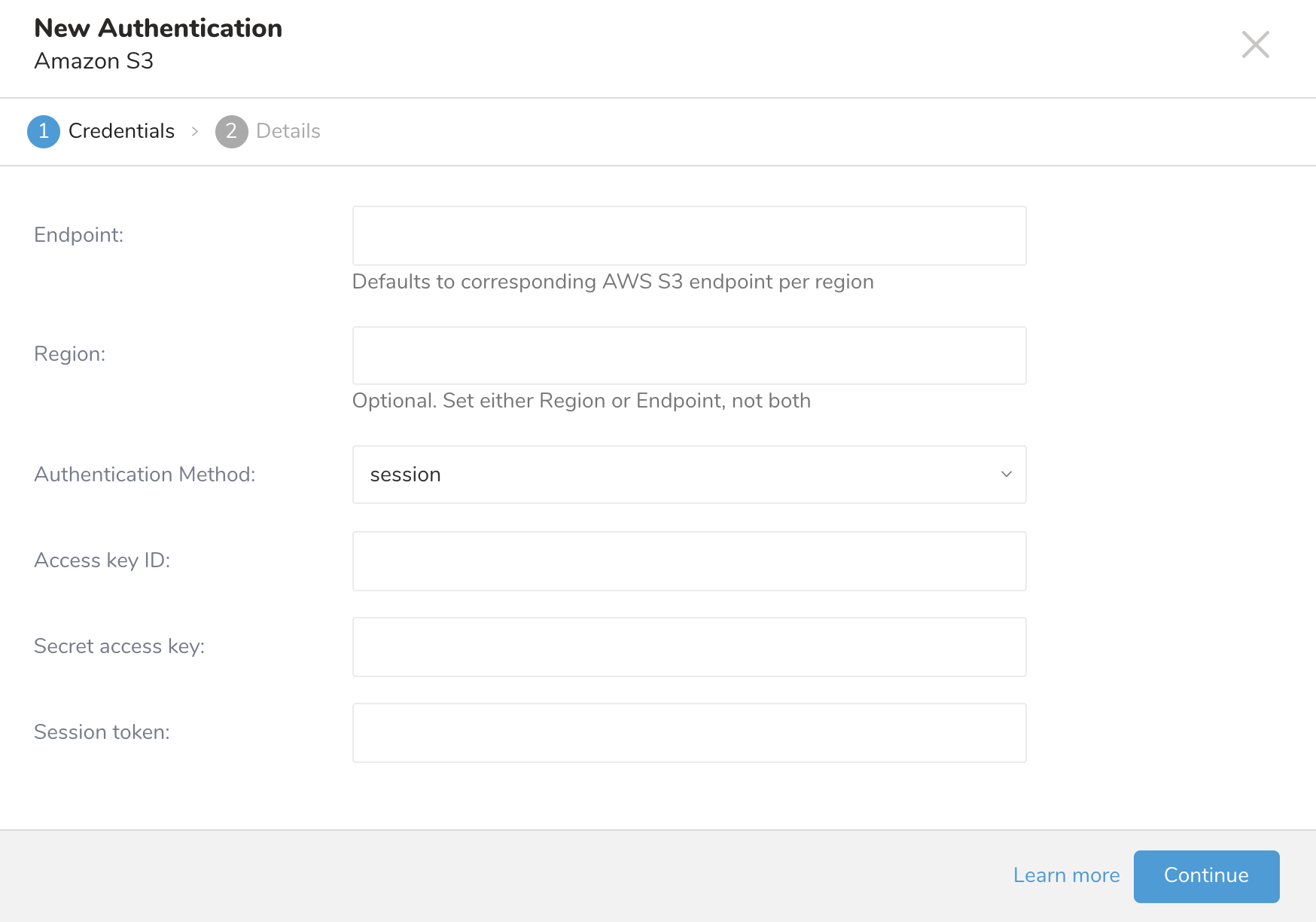
- 次のパラメータを設定します。
| Parameter | Description |
|---|---|
| Endpoint |
|
| Authentication Method | |
| basic |
|
| anonymous |
|
| session (推奨) |
|
| Access Key ID | AWS S3発行 |
| Secret Access Key | AWS S3発行 |
- Continueを選択します。
- 新しいAWS S3接続に名前を付けます。
- Doneを選択します。
- Creating a Destination Integrationの手順を完了します。
- Data Workbench > Queriesに移動します。
- データをエクスポートするクエリを選択します。
- クエリを実行して結果セットを検証します。
- Export Resultsを選択します。
- 既存の統合認証を選択します。
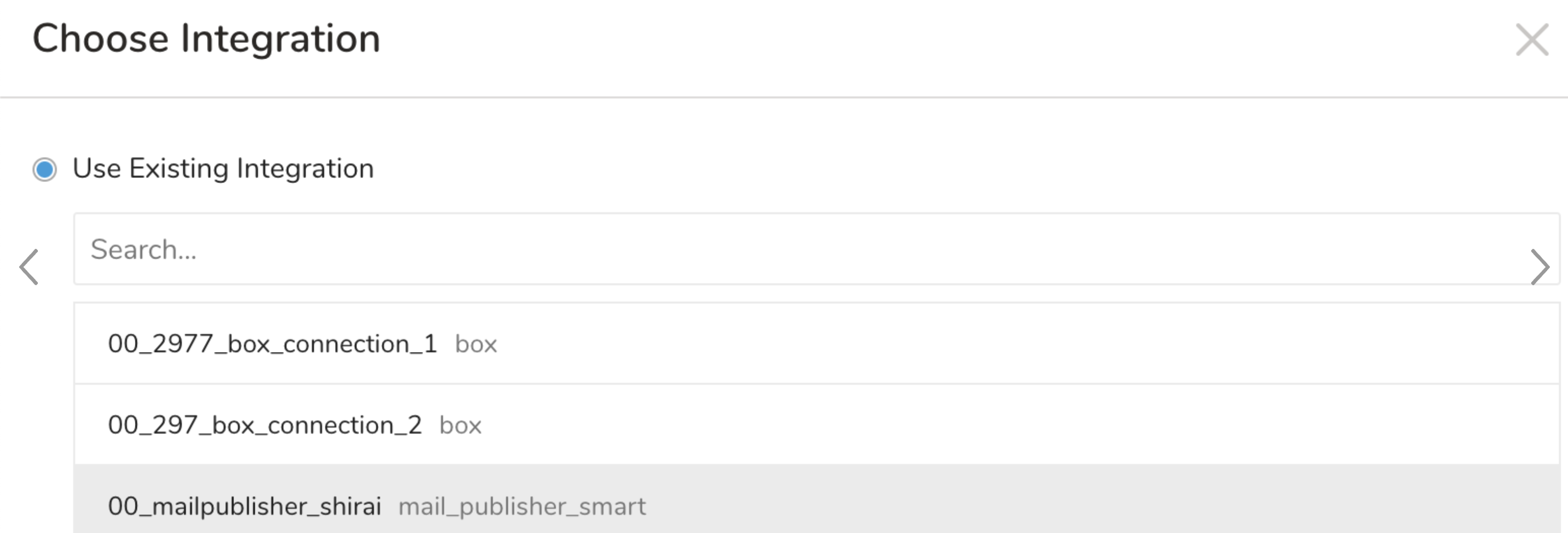
- 追加のExport Resultsの詳細を定義します。エクスポート統合コンテンツで統合パラメータを確認します。 例えば、Export Results画面が異なる場合や、記入する追加の詳細がない場合があります。
- Doneを選択します。
- クエリを実行します。
- データが指定した宛先に移動したことを検証します。
- Export Resultsを選択します。
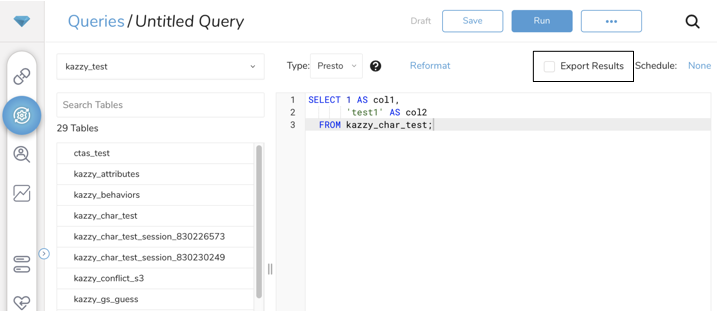
- 既存の認証を選択するか、出力に使用する外部サービスの新しい認証を作成できます。次のいずれかを選択します: Use Existing Integration
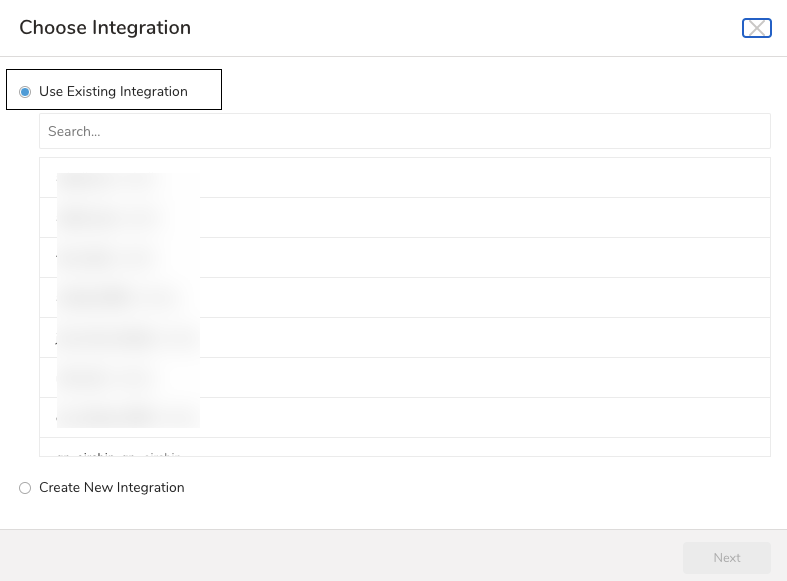 Create a New Integration
Create a New Integration 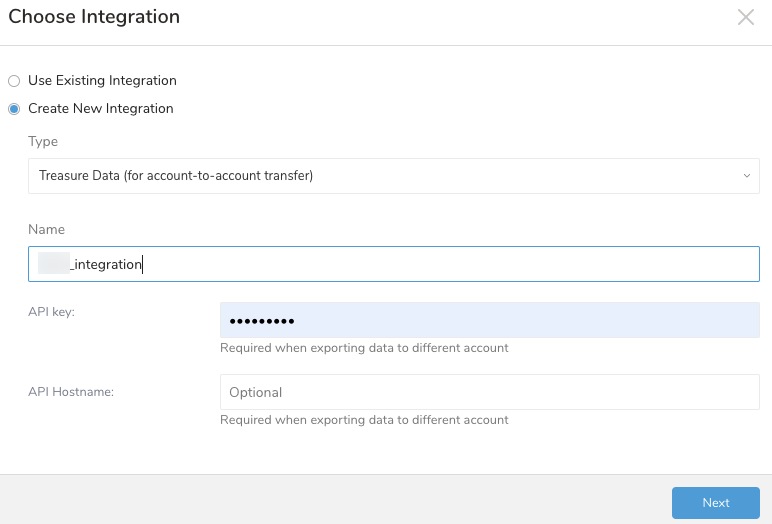
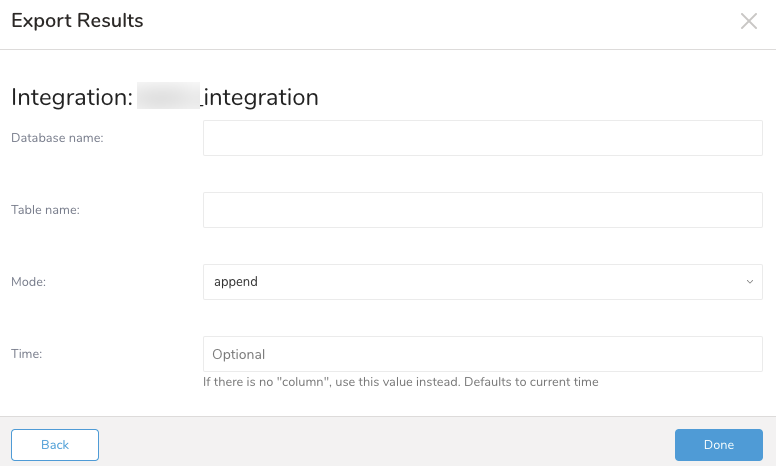
(オプション) Amazon S3へのエクスポート情報を指定する 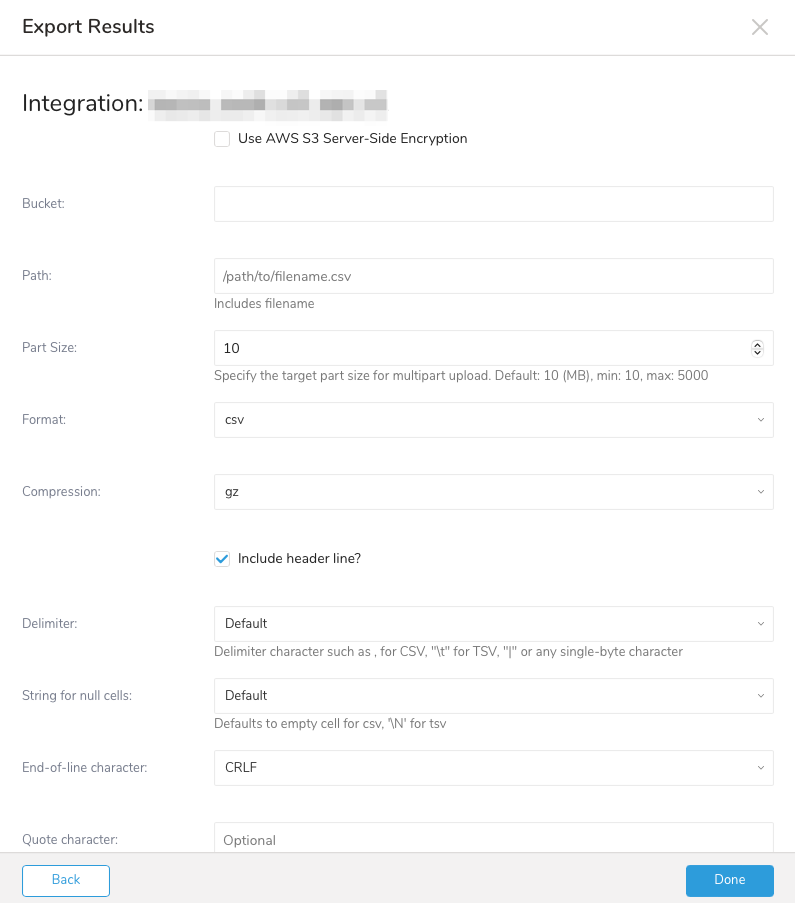
| Field | Description |
|---|---|
| Use AWS S3 Server-Side Encryption | 選択した場合、Server-Side Encryption algorithmとしてAES256を選択してください |
| Bucket | S3バケット名を指定します |
| Path | エクスポートされるファイルにファイル名を含むパスを指定します |
| Part Size | マルチパートアップロードのターゲットパートサイズを指定します デフォルト: 10 (MB)、最小: 10、最大: 5000 |
| Format | エクスポートされるファイルの形式 - csv - tsv - jsonl |
| Compression | エクスポートされるファイルの圧縮形式: - None - gz |
| Include header line? | 選択した場合、最初の行として列名を含むヘッダー行が含まれます。 |
| Delimiter | 区切り文字: - Default - , - Tab - | |
| String for null cells | クエリ結果のnull値の表示方法: - Default - empty string - \N - NULL - null |
| End-of-line character | EOL (end-of-line)文字: - CRLF - LF - CR |
| Quote character | エクスポートされるファイルで引用符に使用される文字。区切り文字、引用符、または行終端文字のいずれかを含むフィールドのみを引用符で囲みます。 |
| Escape character | エクスポートされるファイルで使用されるエスケープ文字 |
次の転送パラメータを定義します: 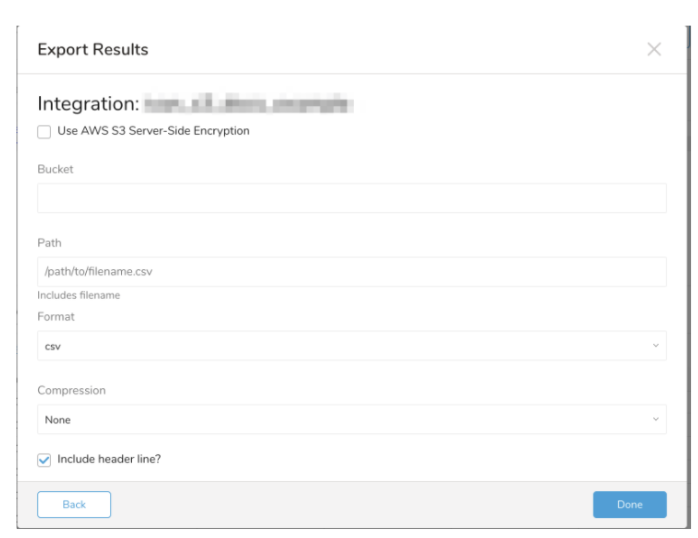
Use AWS S3 Server-Side Encryptionボックスがチェックされている場合:- Server-Side Encryption algorithm.(例: AES256)
Bucket: S3バケット名を指定します(例: your_bucket_name)。
Path: ターゲットキーのプレフィックスを指定します(例: logs/data_)。
Format: エクスポートされるファイルの形式(例: csv (comma separated or tab separated))。
Compression: エクスポートされるファイルの圧縮形式*(例: None or gz)*。
Delimiter: 区切り文字を指定するために使用*(例、(comma))*。
String for null cells: null値に挿入するプレースホルダー*(例: Empty String)*。
End-of-line character: EOL(End-Of-Line)表現を指定*(例: CRLF)*。
Quote Character (オプション): エクスポートされるファイルで引用符に使用される文字(例: ")。区切り文字、引用符、または行終端文字のいずれかを含むフィールドのみを引用符で囲みます。
Escape character (オプション): エクスポートされるファイルで使用されるエスケープ文字。
例えば:
SELECT code, COUNT(1) AS cnt FROM www_access GROUP BY code- 転送の詳細を入力する際に指定したAmazon S3バケットで結果を確認します。
Audience Studio で activation を作成することで、segment データをターゲットプラットフォームに送信することもできます。
- Audience Studio に移動します。
- parent segment を選択します。
- ターゲット segment を開き、右クリックして、Create Activation を選択します。
- Details パネルで、Activation 名を入力し、前述の Configuration Parameters のセクションに従って activation を設定します。
- Output Mapping パネルで activation 出力をカスタマイズします。

- Attribute Columns
- Export All Columns を選択すると、変更を加えずにすべての列をエクスポートできます。
- + Add Columns を選択して、エクスポート用の特定の列を追加します。Output Column Name には、Source 列名と同じ名前があらかじめ入力されます。Output Column Name を更新できます。+ Add Columns を選択し続けて、activation 出力用の新しい列を追加します。
- String Builder
- + Add string を選択して、エクスポート用の文字列を作成します。次の値から選択します:
- String: 任意の値を選択します。テキストを使用してカスタム値を作成します。
- Timestamp: エクスポートの日時。
- Segment Id: segment ID 番号。
- Segment Name: segment 名。
- Audience Id: parent segment 番号。
- + Add string を選択して、エクスポート用の文字列を作成します。次の値から選択します:
- Schedule を設定します。

- スケジュールを定義する値を選択し、オプションでメール通知を含めます。
- Create を選択します。
batch journey の activation を作成する必要がある場合は、Creating a Batch Journey Activation を参照してください。
Scheduled JobsとResult Exportを使用して、指定したターゲット宛先に出力結果を定期的に書き込むことができます。
Treasure Dataのスケジューラー機能は、高可用性を実現するための定期的なクエリ実行をサポートします。
2つの仕様が競合するスケジュール仕様を提供する場合、より頻繁に実行することを要求する仕様が従われ、もう一方のスケジュール仕様は無視されます。
例えば、cronスケジュールが'0 0 1 * 1'の場合、「月の日」仕様と「曜日」は不一致です。前者の仕様では毎月1日の深夜(00:00)に実行することが要求され、後者の仕様では毎週月曜日の深夜(00:00)に実行することが要求されるためです。後者の仕様が従われます。
Scheduled Jobs と Result Export を使用して、指定したターゲット宛先に出力結果を定期的に書き込むことができます。
Treasure Data のスケジューラー機能は、高可用性を実現するために定期的なクエリ実行をサポートしています。
2 つの仕様が競合するスケジュール仕様を提供する場合、より頻繁に実行するよう要求する仕様が優先され、もう一方のスケジュール仕様は無視されます。
例えば、cron スケジュールが '0 0 1 * 1' の場合、「月の日」の仕様と「週の曜日」が矛盾します。前者の仕様は毎月 1 日の午前 0 時 (00:00) に実行することを要求し、後者の仕様は毎週月曜日の午前 0 時 (00:00) に実行することを要求するためです。後者の仕様が優先されます。
Data Workbench > Queries に移動します
新しいクエリを作成するか、既存のクエリを選択します。
Schedule の横にある None を選択します。

ドロップダウンで、次のスケジュールオプションのいずれかを選択します:
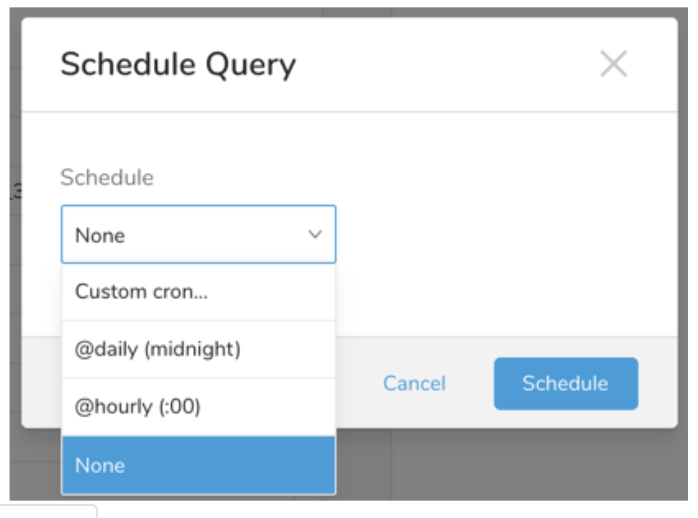
ドロップダウン値 説明 Custom cron... Custom cron... の詳細を参照してください。 @daily (midnight) 指定されたタイムゾーンで 1 日 1 回午前 0 時 (00:00 am) に実行します。 @hourly (:00) 毎時 00 分に実行します。 None スケジュールなし。
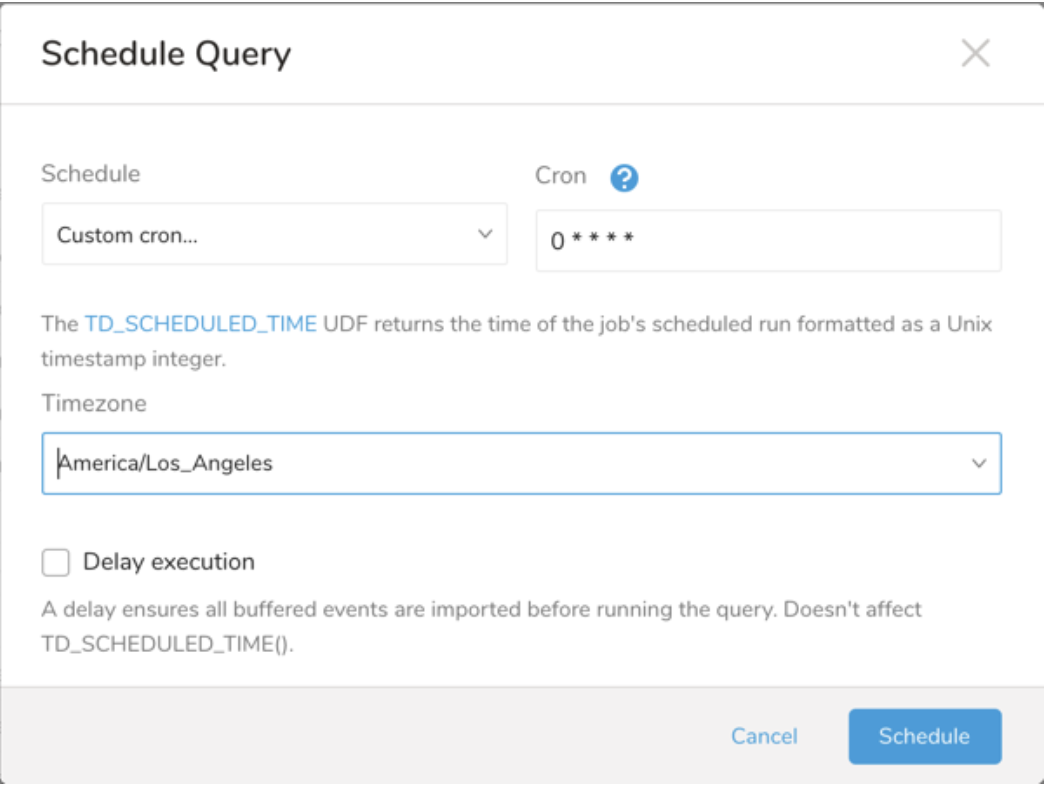
| Cron 値 | 説明 |
|---|---|
0 * * * * | 1 時間に 1 回実行します。 |
0 0 * * * | 1 日 1 回午前 0 時に実行します。 |
0 0 1 * * | 毎月 1 日の午前 0 時に 1 回実行します。 |
| "" | スケジュールされた実行時刻のないジョブを作成します。 |
* * * * *
- - - - -
| | | | |
| | | | +----- day of week (0 - 6) (Sunday=0)
| | | +---------- month (1 - 12)
| | +--------------- day of month (1 - 31)
| +-------------------- hour (0 - 23)
+------------------------- min (0 - 59)次の名前付きエントリを使用できます:
- Day of Week: sun, mon, tue, wed, thu, fri, sat.
- Month: jan, feb, mar, apr, may, jun, jul, aug, sep, oct, nov, dec.
各フィールド間には単一のスペースが必要です。各フィールドの値は、次のもので構成できます:
| フィールド値 | 例 | 例の説明 |
|---|---|---|
| 各フィールドに対して上記で表示された制限内の単一の値。 | ||
フィールドに基づく制限がないことを示すワイルドカード '*'。 | '0 0 1 * *' | 毎月 1 日の午前 0 時 (00:00) に実行するようにスケジュールを設定します。 |
範囲 '2-5' フィールドの許可される値の範囲を示します。 | '0 0 1-10 * *' | 毎月 1 日から 10 日までの午前 0 時 (00:00) に実行するようにスケジュールを設定します。 |
カンマ区切りの値のリスト '2,3,4,5' フィールドの許可される値のリストを示します。 | 0 0 1,11,21 * *' | 毎月 1 日、11 日、21 日の午前 0 時 (00:00) に実行するようにスケジュールを設定します。 |
周期性インジケータ '*/5' フィールドの有効な値の範囲に基づいて、 スケジュールが実行を許可される頻度を表現します。 | '30 */2 1 * *' | 毎月 1 日、00:30 から 2 時間ごとに実行するようにスケジュールを設定します。 '0 0 */5 * *' は、毎月 5 日から 5 日ごとに午前 0 時 (00:00) に実行するようにスケジュールを設定します。 |
'*' ワイルドカードを除く上記の いずれかのカンマ区切りリストもサポートされています '2,*/5,8-10' | '0 0 5,*/10,25 * *' | 毎月 5 日、10 日、20 日、25 日の午前 0 時 (00:00) に実行するようにスケジュールを設定します。 |
- (オプション) Delay execution を有効にすることで、クエリの開始時刻を遅延させることができます。
クエリに名前を付けて保存して実行するか、単にクエリを実行します。クエリが正常に完了すると、クエリ結果は指定された宛先に自動的にエクスポートされます。
設定エラーにより継続的に失敗するスケジュールジョブは、複数回通知された後、システム側で無効化される場合があります。
(オプション) Delay execution を有効にすることで、クエリの開始時刻を遅延させることができます。
Treasure Workflow内で、このデータコネクタを使用してデータをエクスポートすることを指定できます。
- About Using Workflows to Export Data with TD Toolbelt - workflowでデータコネクタを使用してデータをエクスポートする方法の詳細について
- Treasure Boxes - workflowの例を確認する
- About Workflow Secrets Management - workflowで認証情報をマスクするためにシークレットを構成する方法の詳細について
詳細はUsing Workflows to Export Data with the TD Toolbeltをご覧ください。
timezone: UTC _export: td: database: sample_datasets +td-result-into-s3: td>: queries/sample.sql result_connection: your_connections_name result_settings: bucket: your_bucket path: /path/file_${moment(session_time).format("YYYYMMDD")}.csv.gz compression: 'gz' header: true newline: \r\n "null": "hoge"TD Consoleが利用できない場合、またはニーズに合わない場合は、CLIを使用してクエリを発行し、結果を出力できます。CLIを使用してクエリ出力結果をフォーマットします。
access keyとsecret keyはURLエンコードする必要があります。
単一のクエリの結果をS3バケットに出力するには、td queryコマンドに--resultオプションを追加します。ジョブが完了すると、結果がデータベースに書き込まれます。
オンデマンドジョブの場合は、td queryコマンドに--resultオプションを追加するだけです。ジョブが完了すると、結果は指定された名前とパスでS3バケットに書き込まれます。access keyとsecret keyはURLエンコードする必要があります。
td query \
--result 's3://accesskey:secretkey@/bucketname/path/to/file.csv.gz?compression=gz' \
-w -d testdb \
"SELECT code, COUNT(1) AS cnt FROM www_access GROUP BY code"セキュリティ上の理由から、AWS IAMを使用してストレージの書き込みとアクセス権限を管理することをお勧めします。
結果を圧縮するために、—result URLで圧縮オプション(現時点ではgzのみ許可)を指定できます。圧縮パラメータがない場合、非圧縮データが生成されます。access keyとsecret keyはURLエンコードする必要があります。
td query \ --result 's3://accesskey:secretkey@/bucketname/path/to/file.csv' \
-w -d testdb \ "SELECT code, COUNT(1) AS cnt FROM www_access GROUP BY code"