ジョブ結果を直接Databricksに書き込むことができます。例えば、複数のソースからTreasure Dataにデータを統合し、クエリを実行してデータを整理した後、コネクタを適用するジョブを使用してDatabricksにデータをエクスポートすることができます。
インポート連携については、Databricksインポート連携を参照してください。
- TD Toolbeltを含むTreasure Dataの基本知識
- Databricksの基本知識とDatabricksアカウントへのアクセス
- Databricksサーバーへのアクセス
- Databricksサーバーが休止モードの場合、起動に数分かかる可能性があり、コネクタがタイムアウトする原因となることがあります。
- Databricksは複数のステートメントにまたがるトランザクションをサポートしていません。そのため、replaceモードとtruncateモードは部分的に失敗する可能性があり、ロールバックできません。例えば、truncateまたはreplaceモードで、削除またはcreate replace操作は成功したが、一時テーブルからターゲットテーブルへのデータ挿入が失敗した場合、コネクタは以前のデータにロールバックできません。
Treasure Data Consoleを使用して接続を設定できます。
- Databricksのウェブサイトにログインします。
- SQLタブに移動し、SQL Warehousesを選択します。
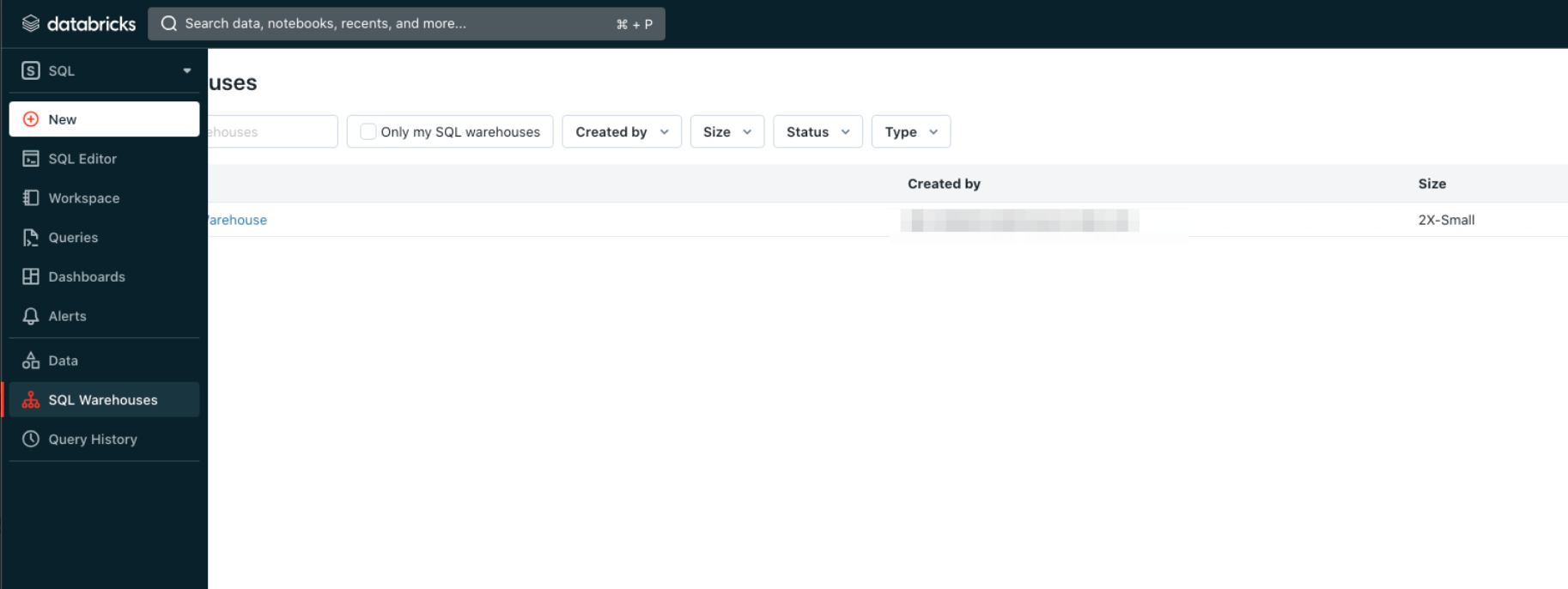
- SQL Warehouseのインスタンスを選択します。
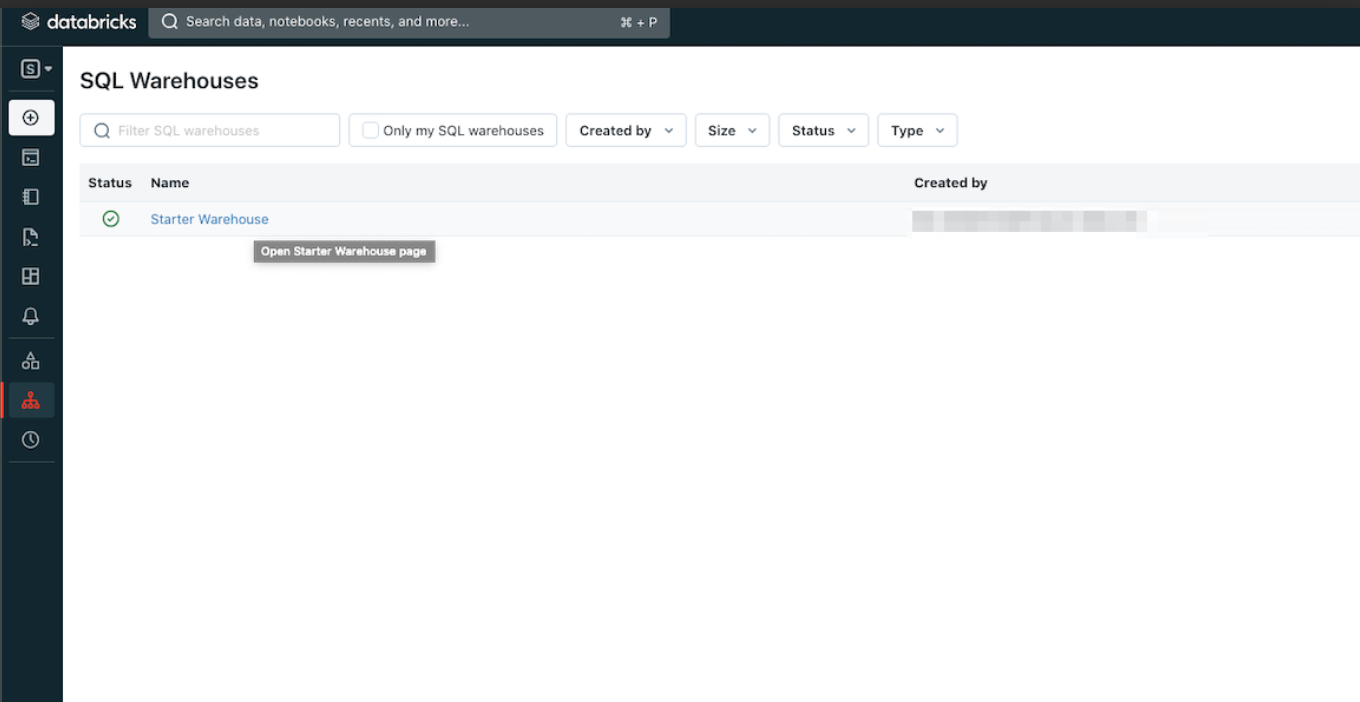
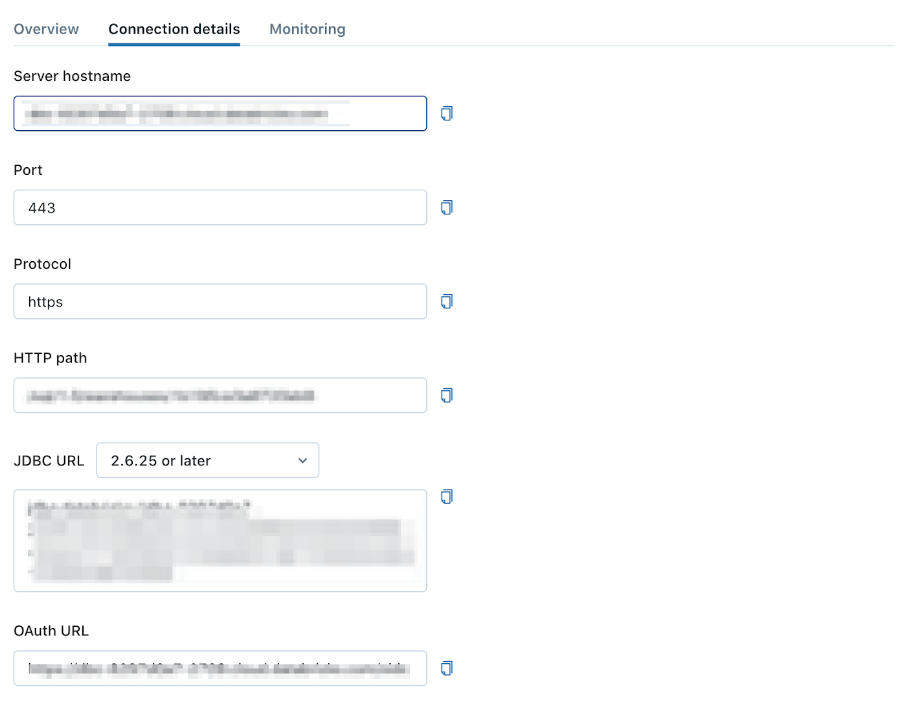
- Connection detailsタブを選択します。
- SQL WarehouseのServer hostnameとHTTP pathを記録します。
Treasure Data Connectionsに移動します。
- Integrations Hub > Catalogを選択します。
- カタログでDatabricksを検索します。
- アイコンにマウスを合わせて、Create Authenticationを選択します。
- Credentialsタブが選択されていることを確認し、連携の認証情報を入力します。
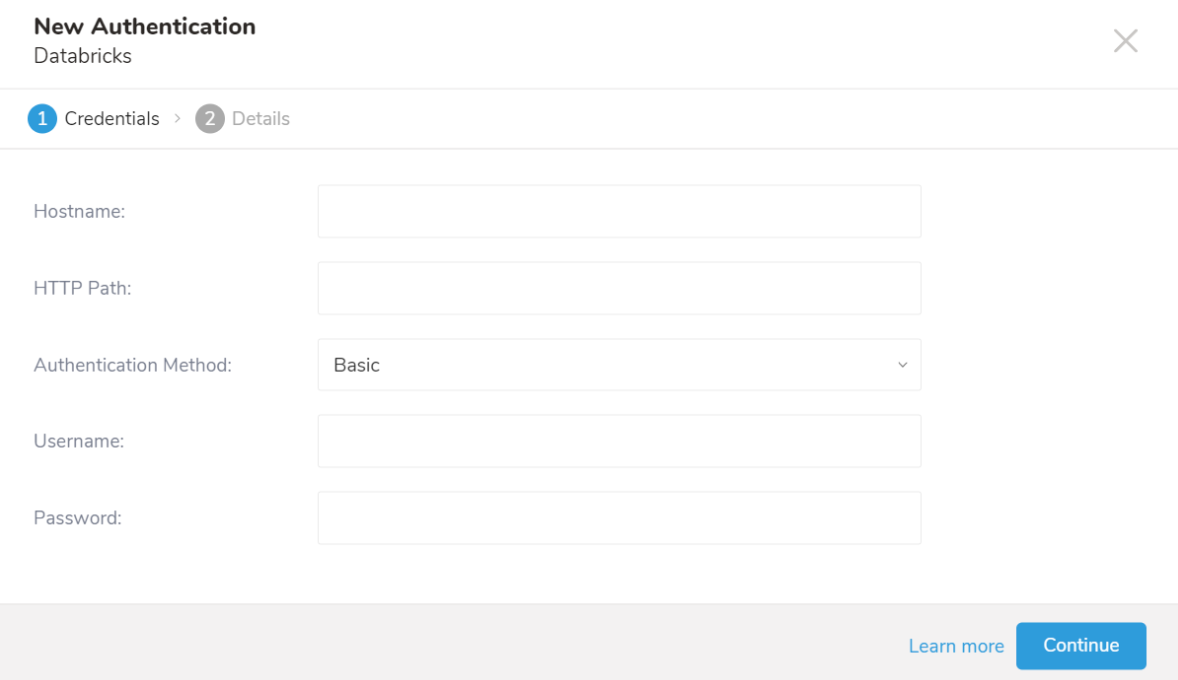
| パラメータ | 説明 |
|---|---|
| Hostname | Databricksインスタンスのホスト名です。 |
| HTTP Path | Databricksインスタンスの HTTPパスです。 |
| Authentication Method | 認証方法です。BasicまたはPersonal Access Tokenを指定できます。 |
| Username | ログインに使用するユーザー名です。Authentication MethodがBasicの場合にのみ有効です。 |
| Password | ログインに使用するパスワードです。Authentication MethodがBasicの場合にのみ有効です。 |
| Token | Databricksのpersonal access tokenです。Authentication MethodがPersonal Access Tokenの場合にのみ有効です。 |
- Continueを選択します。
- 認証の名前を入力し、Doneを選択します。
データ接続を設定するクエリを作成または再利用します。
Treasure Data consoleに移動します。Query Editorに移動します。データのエクスポートに使用する予定のクエリにアクセスします。
場合によっては、クエリで列マッピングを定義する必要があります。
例:
SELECT c_id, c_double, c_long, c_string, c_boolean, c_timestamp, c_json FROM (VALUES (1, 100, 10, 'T4', true, '2018-01-01','{ "name":"John"}'),(2, 100, 99, 'P@#4', false, '2018-01-01', '{ "name":"John"}'),(3, 100.1234, 22, 'C!%^&*', false, '2018-01-01','{ "name":"John"}')) tbl1 (c_id, c_double, c_long, c_string, c_boolean, c_timestamp, c_json)クエリエディタの上部にあるOutput Resultsを選択します。
- 検索ボックスに接続名を入力してフィルタリングし、接続を選択します。
- Databricks接続を選択すると、ConfigurationまたはExport Resultsダイアログペインが表示されます。
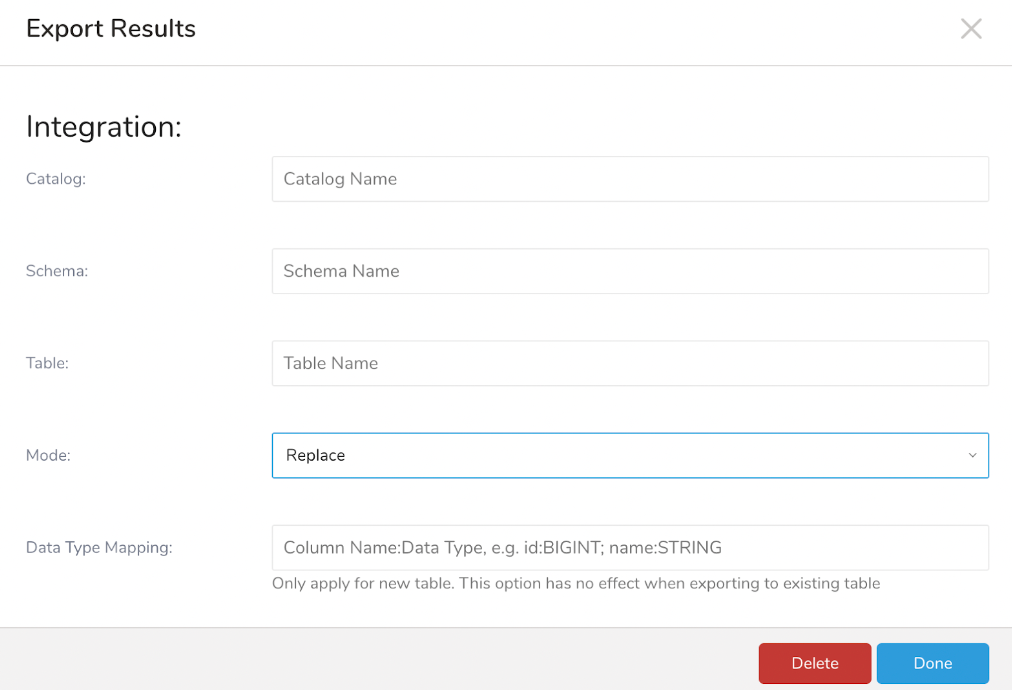
パラメータを指定します。パラメータは以下の通りです:
Catalog (必須): データセットカタログです。
Schema (必須): データセットスキーマです。
Table (必須): 結果がエクスポートされるテーブルです。存在しない場合は、新しいテーブルが作成されます。
Mode (必須): Databricksテーブルに結果を反映する3つのモードがあります: Append、Overwrite、Replace。
- Append: TD結果がターゲットテーブルに追加されます
- Overwrite: ターゲットテーブルが消去され、TD結果がターゲットテーブルの先頭から追加されます
- Replace: ターゲットテーブルが再作成され、TD結果がターゲットテーブルの先頭から追加されます
Data type mapping: 次のセクションで説明します。
ターゲットテーブルが存在しない場合の、TD結果の型からターゲットテーブルへの1対1のデフォルトマッピングのテーブルは次の通りです:
| TD results | Databricks |
|---|---|
| string | STRING |
| double | DOUBLE |
| long | BIGINT |
| timestamp | TIMESTAMP |
| boolean | BOOLEAN |
| json | STRING |
デフォルトとは異なる型を設定したい場合があります。Data Type Mappingを使用すると、特定の列に特定の型(例: STRING)を明示的に設定できます。Data Type Mappingは、ターゲットテーブルの列にのみ型を適用します。
Data Mappingを使用する場合、以下が当てはまります:
- ターゲットテーブルが存在しない場合、エクスポートジョブは新しいターゲットテーブルを作成します。
データ型マッピングパラメータの構文は、col_name_1: STRING; col_name2: BIGINTです。列名とDatabricksデータ型を指定する必要があります。
TD Databricks ExportはBINARY、INTERVAL、STRUCTURE、ARRAY、MAPデータ型をサポートしていません。
例えば、クエリの場合:
SELECT c_id, c_double, c_long, c_string, c_boolean, c_timestamp, c_json FROM (VALUES (1, 100, 10, 'T4', true, '2018-01-01','{ "name":"John"}'),(2, 100, 99, 'P@#4', false, '2018-01-01', '{ "name":"John"}'),(3, 100.1234, 22, 'C!%^&*', false, '2018-01-01','{ "name":"John"}')) tbl1 (c_id, c_double, c_long, c_string, c_boolean, c_timestamp, c_json)
オプション: 出力のためのスケジュールジョブの使用Scheduled JobsとResult Outputを使用して、特定のターゲット先に出力結果を定期的に書き込むことができます。
Audience Studio で activation を作成することで、segment データをターゲットプラットフォームに送信することもできます。
- Audience Studio に移動します。
- parent segment を選択します。
- ターゲット segment を開き、右クリックして、Create Activation を選択します。
- Details パネルで、Activation 名を入力し、前述の Configuration Parameters のセクションに従って activation を設定します。
- Output Mapping パネルで activation 出力をカスタマイズします。

- Attribute Columns
- Export All Columns を選択すると、変更を加えずにすべての列をエクスポートできます。
- + Add Columns を選択して、エクスポート用の特定の列を追加します。Output Column Name には、Source 列名と同じ名前があらかじめ入力されます。Output Column Name を更新できます。+ Add Columns を選択し続けて、activation 出力用の新しい列を追加します。
- String Builder
- + Add string を選択して、エクスポート用の文字列を作成します。次の値から選択します:
- String: 任意の値を選択します。テキストを使用してカスタム値を作成します。
- Timestamp: エクスポートの日時。
- Segment Id: segment ID 番号。
- Segment Name: segment 名。
- Audience Id: parent segment 番号。
- + Add string を選択して、エクスポート用の文字列を作成します。次の値から選択します:
- Schedule を設定します。

- スケジュールを定義する値を選択し、オプションでメール通知を含めます。
- Create を選択します。
batch journey の activation を作成する必要がある場合は、Creating a Batch Journey Activation を参照してください。
Treasure Workflow内で、このデータコネクタを使用してデータを出力するように指定できます。
timezone: UTC
_export:
td:
database: sample_datasets
+td-result-into-databricks:
td>: queries/sample.sql
result_connection: your_connection_name
result_settings:
catalog: CATALOG
schema: default
table: TARGET_TABLE
mode: insert
column_options:
col1: {type: 'DATE'}TD Toolbeltをインストールします。
td queryコマンドの-r / --resultオプションを使用してDatabricks結果出力先を追加します:
td query -d mydb \
-w 'SELECT id, name FROM source_table' \
--type presto \
-r '{"type": "databricks", "host_name": "hostname", "http_path": "httpPath", "auth_method": "BASIC", "username": "username", "password": "password", catalog: "catalog", "schema": "default", "table": "target_table", "mode": "replace", "column_options": {"col1": {"type": "DATE"}}}'catalogやschemaなどの一部のパラメータは自明であり、TD Consoleで使用されるパラメータと同じです(「パラメータを指定して接続を設定する」セクションを参照)。ただし、一部のパラメータはキーまたは値が異なります:
mode (必須): modeの値はModeパラメータの生の値です:
- insert: TD結果がターゲットテーブルに追加されます
- truncate_insert: ターゲットテーブルが消去され、TD結果がターゲットテーブルの先頭から追加されます
- replace: ターゲットテーブルが再作成され、TD結果がターゲットテーブルの先頭から追加されます
column_options: データ型マッピングです。
td sched:createコマンドの-r / --resultオプションを使用してDatabricks結果出力先を追加します:
td sched:create every_6_mins "*/6 * * * *" \
-d mydb \
-w 'SELECT id, name FROM source_table' \
--type presto \
-r '{"type": "databricks", "host_name": "hostname", "http_path": "httpPath", "auth_method": "BASIC", "username": "username", "password": "password", catalog: "catalog", "schema": "default", "table": "target_table", "mode": "replace", "column_options": {"col1": {"type": "DATE"}}}'