Microsoft Azure Blob Storage Export Integrationの詳細はこちらをご覧ください。
Microsoft Azure Blob Storage用のオープンデータコネクタは、Azure Blob Storageコンテナに保存されている*.tsvおよび*.csvファイルの内容をインポートできます。
コネクタUIの制限事項。コネクタUIでの編集には多くの制限があります。編集にはCLIの使用を推奨します。
階層型名前空間が有効になっている場合、増分フローは正常に動作しません。
- Treasure Dataの基本知識
- Microsoft Azure Platformアカウント
Microsoft Azure Blob Storage用のDataConnectorは、Connector UIから送信できます。

まず、以下のパラメータを設定してコネクタを登録する必要があります。
- Storage Account name:Microsoft Azure Blob Storageアカウントの名前。
- Primary access key: Microsoft Azure Blob Storageアカウントへのアクセスに使用するアクセスキー。
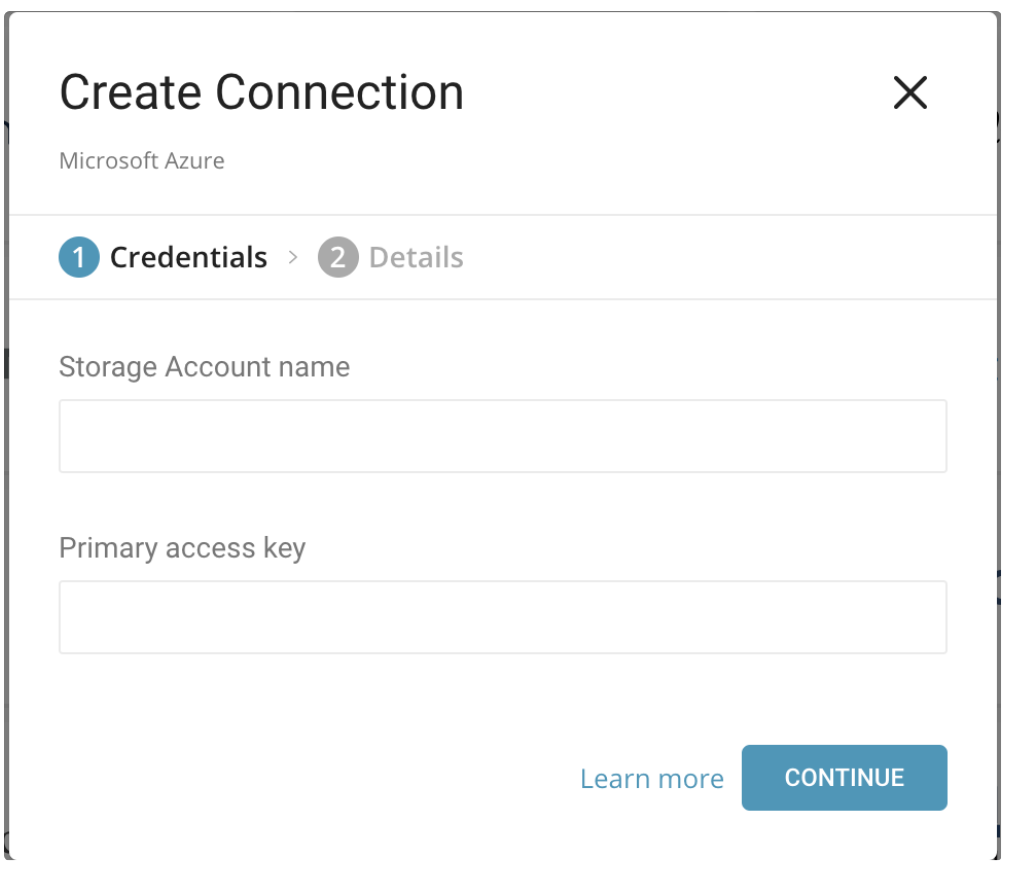
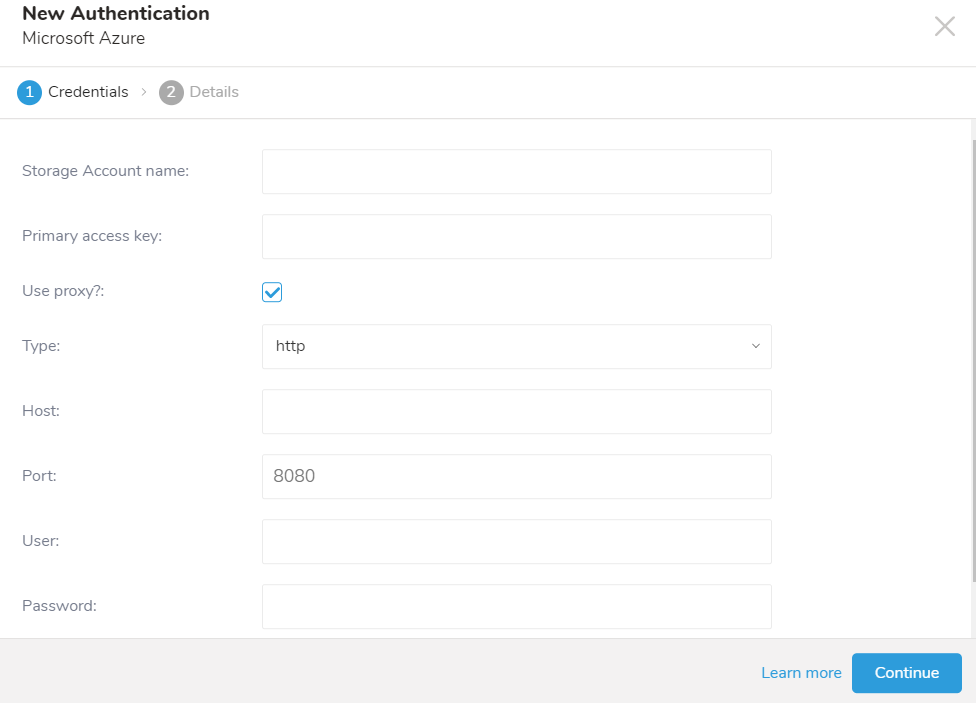
プロキシ設定が有効な場合
次に、My Connectionsページで「New Transfer」を作成します。アドホックDataConnectorジョブまたはスケジュールDataConnectorジョブを準備できます。以下の手順を実行してください。

取り込みたい情報を登録します。
- Container: Azureクラウドストレージのコンテナ名(例: your_cont)
- Path Prefix: ターゲットキーのプレフィックス。(例: logs/data_)
- Path Regex: ファイルパスにマッチする正規表現。ファイルパスがこのパターンにマッチしない場合、そのファイルはスキップされます。(例: .csv$ # この場合、パスがこのパターンにマッチしない場合、ファイルはスキップされます)
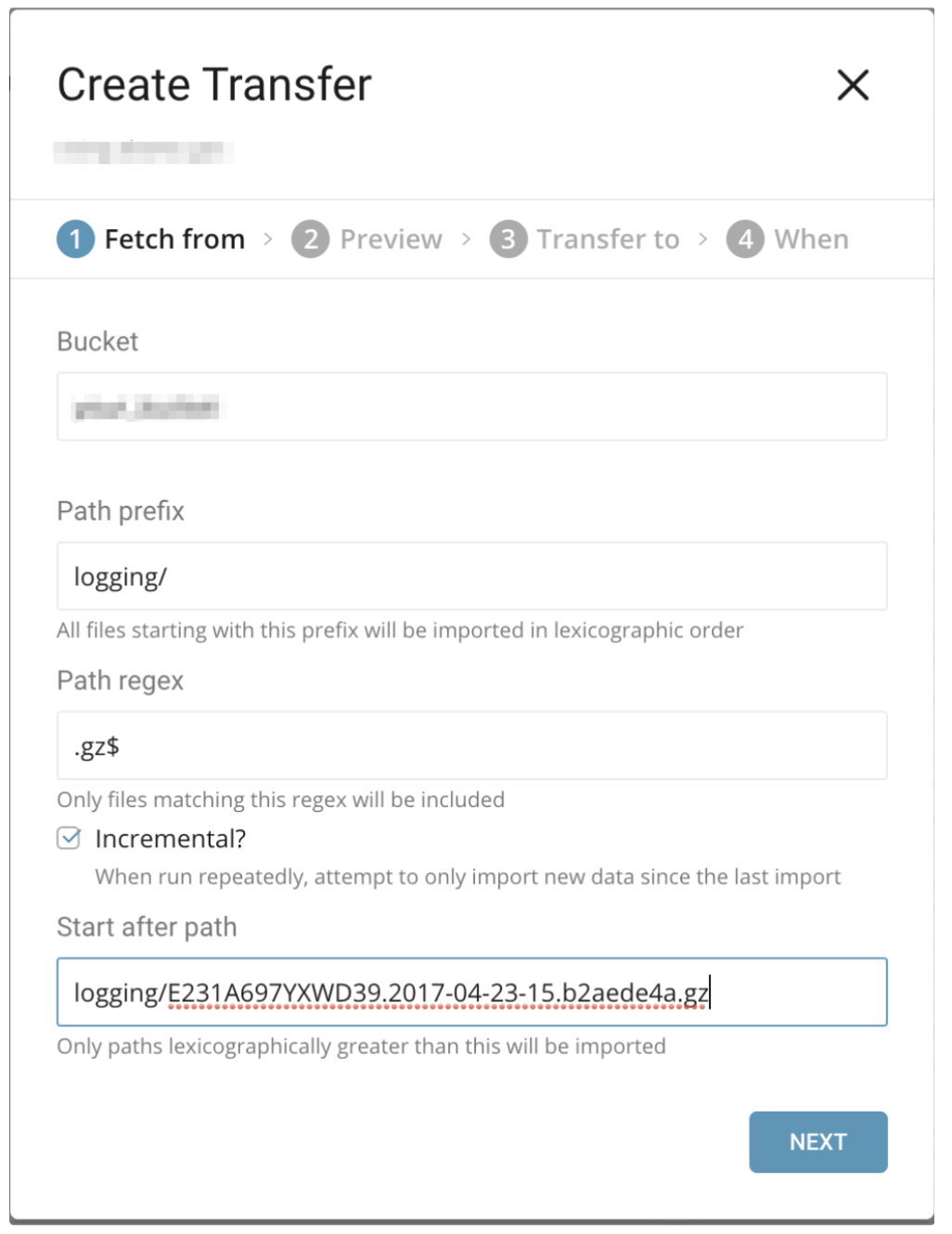
Amazon CloudFrontは、静的および動的なWebコンテンツの配信を高速化するWebサービスです。CloudFrontを設定して、CloudFrontが受信するすべてのユーザーリクエストに関する詳細情報を含むログファイルを作成できます。ロギングを有効にすると、次のようなCloudFrontログファイルを保存できます。
[your_bucket] - [logging] - [E231A697YXWD39.2017-04-23-15.a103fd5a.gz]
[your_bucket] - [logging] - [E231A697YXWD39.2017-04-23-15.b2aede4a.gz]
[your_bucket] - [logging] - [E231A697YXWD39.2017-04-23-16.594fa8e6.gz]
[your_bucket] - [logging] - [E231A697YXWD39.2017-04-23-16.d12f42f9.gz]この場合、「Fetch from」の設定は以下のようになります。
- Container: your_container
- Path Prefix: logging/
- Path Regex: .gz$(必須ではありません)
設定したデータのプレビューを表示できます。プレビューが表示されない場合、またはプレビューの表示に問題がある場合は、サポートにお問い合わせください。
プレビューコマンドは、指定されたバケットから1つのファイルをダウンロードし、そのファイルから結果を表示します。これにより、プレビューとissueコマンドの結果に違いが生じる可能性があります。
特定のカラム名を設定したい場合は、Advanced Settingsを選択してください。
Advanced Settingsでは、推測されたプロパティを編集できます。必要に応じて以下のセクションを編集してください。
Default timezone: 値自体にタイムゾーンが含まれていない場合、タイムスタンプカラムのタイムゾーンを変更します。
Columns:
Name: カラム名を変更します。カラム名に使用できる文字は、小文字のアルファベット、数字、「_」(アンダースコア)のみです。
Type: 値を指定されたタイプとして解析し、そのタイプをTreasure Dataスキーマの一部として保存します。
- boolean
- long
- timestamp: Treasure DataではString型としてインポートされます(例: 2017-04-01 00:00:00.000)
- double
- string
- json
Total file count limit: 読み込むファイルの最大数。(オプション)
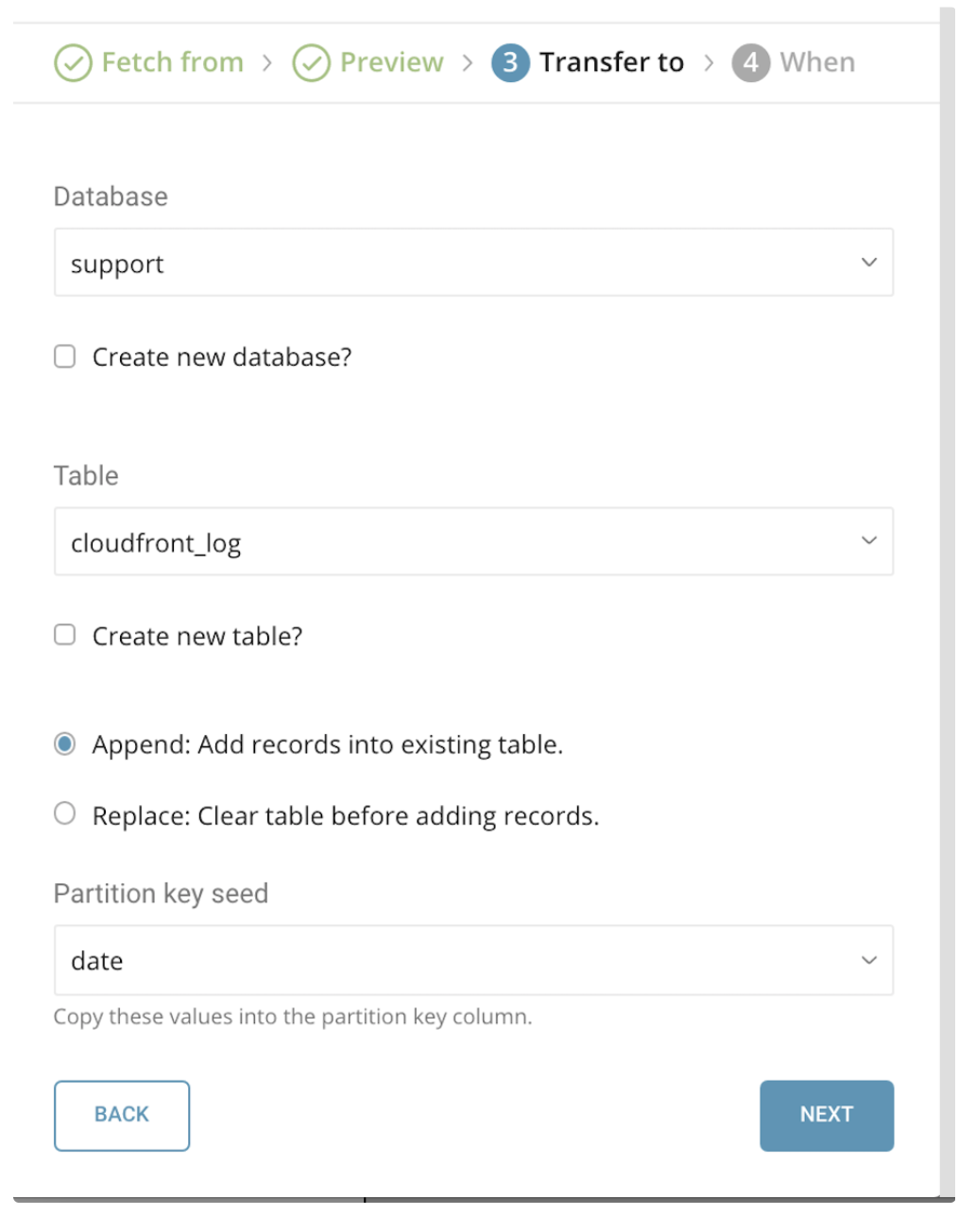
このフェーズでは、インポート先のターゲットdatabaseとtableを選択します。Create new databaseまたはCreate new tableのチェックボックスを使用して、新しいdatabaseまたはtableを作成できます。
- Mode: Append – 既存のtableにレコードを追加できます。
- Mode: Replace – tableの既存データを、インポートされるデータで置き換えます。
- Partition key Seed: パーティショニング時間カラムとして使用したいlongまたはtimestampカラムを選択します。時間カラムを指定しない場合、転送のアップロード時間がadd_timeフィルタの追加と併せて使用されます。
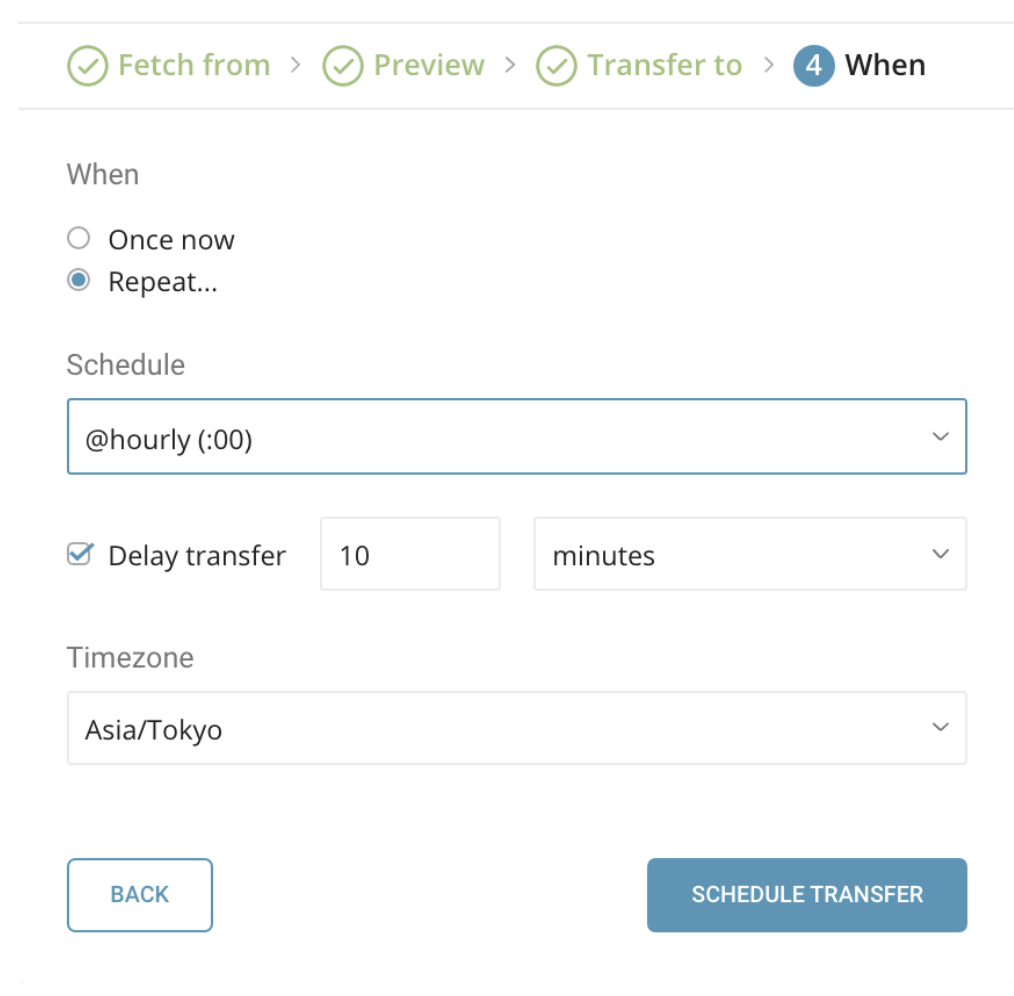
このフェーズでは、ジョブのアドホックまたはスケジュール設定を行うことができます。
When
Once now: 転送を1回だけ実行します。
Repeat…
- Schedule: 次の3つのオプションを受け付けます:
@hourly、@daily、@monthly、およびカスタムcron。 - Delay Transfer: 実行時間に遅延を追加します。
- Schedule: 次の3つのオプションを受け付けます:
Data Storage Timezone: データが保存されるタイムゾーン。データはこのタイムゾーンでも表示されます。「Asia/Tokyo」などの拡張タイムゾーン形式をサポートしています。
頻度を選択した後、Start Transferを選択して転送を開始します。エラーがなければ、Treasure Dataへの転送が完了し、データが利用可能になります。転送が実行されると、ジョブが起動されます。JobsセクションまたはMy Input Transfersセクションを使用して、データ転送の進行状況を監視できます。
ジョブログを確認してください。警告とエラーは、インポートの成功に関する情報を提供します。たとえば、インポートエラーに関連するソースファイル名を特定することができます。
コマンドラインインターフェイスからMicrosoft Azure Blob Storageデータコネクタを使用することもできます。以下の手順は、CLIを使用してデータをインポートする方法を示しています。
最新のTreasure Data Toolbeltをインストールしてください。
$ td --version
0.11.10まず、以下の例のように、アカウント情報を含む seed.yml を準備します(Azure ストレージアカウントについてを確認してください)。また、コンテナ名とターゲットファイル名(または複数ファイルのプレフィックス)も指定する必要があります。
in:
type: azure_blob_storage
account_name: myaccount
account_key: myaccount_key
container: my-container
path_prefix: logs/csv-
out:
mode: appendData Connector for Microsoft Azure Blob Storage は、指定されたプレフィックスに一致するすべてのファイルをインポートします。(例: path_prefix: path/to/sample_ –> path/to/sample_201501.csv.gz, path/to/sample_201502.csv.gz, …, path/to/sample_201505.csv.gz)
利用可能な out モードの詳細については、以下の付録を参照してください。
次に、connector:guess を使用します。このコマンドは、ソースファイルを自動的に読み取り、ファイル形式を評価(ロジックを使用して推測)します。
$ td connector:guess seed.yml -o load.ymlload.yml を開くと、ファイル形式、エンコーディング、カラム名、型を含む推測されたファイル形式定義が表示されます。
in:
type: azure_blob_storage
account_name: myaccount
account_key: myaccount_key
container: my-container
path_prefix: logs/csv-
decoders:
- {type: gzip}
parser:
charset: UTF-8
newline: CRLF
type: csv
delimiter: ','
quote: '"'
header_line: true
columns:
- {name: id, type: long}
- {name: account, type: long}
- {name: time, type: timestamp, format: '%Y-%m-%d %H:%M:%S'}
- {name: purchase, type: timestamp, format: '%Y%m%d'}
- {name: comment, type: string}
out:
mode: append次に、preview コマンドを使用して、システムがファイルをどのように解析するかをプレビューできます。
$ td connector:preview load.yml
+-------+---------+----------+---------------------+
| id | company | customer | created_at |
+-------+---------+----------+---------------------+
| 11200 | AA Inc. | David | 2015-03-31 06:12:37 |
| 20313 | BB Imc. | Tom | 2015-04-01 01:00:07 |
| 32132 | CC Inc. | Fernando | 2015-04-01 10:33:41 |
| 40133 | DD Inc. | Cesar | 2015-04-02 05:12:32 |
| 93133 | EE Inc. | Jake | 2015-04-02 14:11:13 |
+-------+---------+----------+---------------------+| guess コマンドは、ソースデータからサンプル行を使用してカラム定義を推測するため、ソースデータファイルに3行以上と2カラム以上が必要です。 |
システムがカラム名またはカラム型を予期せず検出した場合は、load.yml を直接修正して、再度プレビューしてください。
現在、Data Connector は "boolean"、"long"、"double"、"string"、および "timestamp" 型の解析をサポートしています。
データロードジョブを実行する前に、ローカルデータベースとテーブルを作成する必要があります。以下の手順に従ってください。
$ td database:create td_sample_db
$ td table:create td_sample_db td_sample_table最後に、ロードジョブを送信します。データのサイズによっては、数時間かかる場合があります。データが格納される Treasure Data データベースとテーブルを指定してください。
Treasure Data のストレージは時間によってパーティション化されているため(データパーティショニングを参照)、--time-column オプションを指定することをお勧めします。オプションが指定されていない場合、Data Connector は最初の long または timestamp カラムをパーティショニング時間として選択します。--time-column で指定されるカラムの型は、long および timestamp 型のいずれかである必要があります。
データに時間カラムがない場合は、add_time フィルターオプションを使用して時間カラムを追加できます。詳細については、add_time フィルタープラグインを参照してください。
$ td connector:issue load.yml --database td_sample_db --table td_sample_table \
--time-column created_atconnector:issue コマンドは、database(td_sample_db) と table(td_sample_table) が既に作成されていることを前提としています。データベースまたはテーブルが TD に存在しない場合、connector:issue コマンドは失敗するため、手動でデータベースとテーブルを作成するか、td connector:issue コマンドで --auto-create-table オプションを使用してデータベースとテーブルを自動作成してください。
$ td connector:issue load.yml --database td_sample_db --table td_sample_table --time-column created_at --auto-create-table| 現在、Data Connector はサーバー側でレコードをソートしません。時間ベースのパーティショニングを効果的に使用するには、事前にファイル内のレコードをソートしてください。 |
time というフィールドがある場合は、--time-column オプションを指定する必要はありません。
$ td connector:issue load.yml --database td_sample_db --table td_sample_table増分的な Microsoft Azure Blob Storage ファイルインポートのために、定期的な Data Connector の実行をスケジュールできます。高可用性を確保するために、スケジューラーを慎重に設定しています。この機能を使用することで、ローカルデータセンターに cron デーモンが不要になります。
スケジュールされたインポートでは、Data Connector for Microsoft Azure Blob Storage は、指定されたプレフィックスに一致するすべてのファイル(例: path_prefix: path/to/sample_ –> path/to/sample_201501.csv.gz, path/to/sample_201502.csv.gz, …, path/to/sample_201505.csv.gz)を最初にインポートし、次の実行のために最後のパス(path/to/sample_201505.csv.gz)を記憶します。
2回目以降の実行では、コネクターはアルファベット順(辞書順)で最後のパスの後に来るファイルのみをインポートします(path/to/sample_201506.csv.gz, …)。
新しいスケジュールは、td connector:create コマンドを使用して作成できます。以下が必要です: スケジュールの名前、cron スタイルのスケジュール、データが格納されるデータベースとテーブル、および Data Connector 設定ファイル。
$ td connector:create \
daily_import \
"10 0 * * *" \
td_sample_db \
td_sample_table \
load.ymlTreasure Data のストレージは時間によってパーティション化されているため(データパーティショニングを参照)、--time-column オプションを指定することをお勧めします。
$ td connector:create \ daily_import \
"10 0 * * *" \
td_sample_db \
td_sample_table \
load.yml \
--time-column created_atcronパラメータは、@hourly、@daily、@monthlyの3つの特別なオプションも受け付けます。 |
| --- |
td connector:listコマンドを実行することで、現在スケジュールされているエントリの一覧を確認できます。
$ td connector:list
+--------------+------------+----------+-------+--------------+-----------------+-------------------------------------------+
| Name | Cron | Timezone | Delay | Database | Table | Config |
+--------------+------------+----------+-------+--------------+-----------------+-------------------------------------------+
| daily_import | 10 0 * * * | UTC | 0 | td_sample_db | td_sample_table | {"in"=>{"type"=>"azure_blob_storage", ... |
+--------------+------------+----------+-------+--------------+-----------------+-------------------------------------------+td connector:showは、スケジュールエントリの実行設定を表示します。
% td connector:show daily_import
Name : daily_import
Cron : 10 0 * * *
Timezone : UTC
Delay : 0
Database : td_sample_db
Table : td_sample_tabletd connector:historyは、スケジュールエントリの実行履歴を表示します。各実行の結果を調査するには、td job jobidを使用します。
% td connector:history daily_import
+--------+---------+---------+--------------+-----------------+----------+---------------------------+----------+
| JobID | Status | Records | Database | Table | Priority | Started | Duration |
+--------+---------+---------+--------------+-----------------+----------+---------------------------+----------+
| 578066 | success | 10000 | td_sample_db | td_sample_table | 0 | 2015-04-18 00:10:05 +0000 | 160 |
| 577968 | success | 10000 | td_sample_db | td_sample_table | 0 | 2015-04-17 00:10:07 +0000 | 161 |
| 577914 | success | 10000 | td_sample_db | td_sample_table | 0 | 2015-04-16 00:10:03 +0000 | 152 |
| 577872 | success | 10000 | td_sample_db | td_sample_table | 0 | 2015-04-15 00:10:04 +0000 | 163 |
| 577810 | success | 10000 | td_sample_db | td_sample_table | 0 | 2015-04-14 00:10:04 +0000 | 164 |
| 577766 | success | 10000 | td_sample_db | td_sample_table | 0 | 2015-04-13 00:10:04 +0000 | 155 |
| 577710 | success | 10000 | td_sample_db | td_sample_table | 0 | 2015-04-12 00:10:05 +0000 | 156 |
| 577610 | success | 10000 | td_sample_db | td_sample_table | 0 | 2015-04-11 00:10:04 +0000 | 157 |
+--------+---------+---------+--------------+-----------------+----------+---------------------------+----------+
8 rows in settd connector:deleteは、スケジュールを削除します。
$ td connector:delete daily_importseed.ymlのoutセクションでファイルインポートモードを指定できます。
これはデフォルトのモードで、レコードはターゲットテーブルに追加されます。
in:
...
out:
mode: appendこのモードは、ターゲットテーブルのデータを置き換えます。このモードでは、ターゲットテーブルに対して手動で行ったスキーマ変更はそのまま保持されることに注意してください。
in:
...
out:
mode: replacein:
type: azure_blob_storage
account_name: myaccount
account_key: myaccount_key
container: my-container
path_prefix: logs/csv-
proxy:
type: http
host: 201.202.203.10
port: 8080
user: test
password: testin: type: azure_blob_storage account_name: myaccount account_key: myaccount_key container: my-container path_prefix: logs/csv- incremental: true use_modified_time: false last_path: logs/csv-123.csvin: type: azure_blob_storage account_name: myaccount account_key: myaccount_key container: my-container path_prefix: logs/csv- incremental: true use_modified_time: true last_modified_time: 2025-04-09T00:00:00.000Z