カラム形式のデータフォーマットであるParquetは、クエリがデータセット内の一部のカラムのみにアクセスする必要がある分析ワークロードに特に有益であり、多くのデータパイプライン戦略で好まれる選択肢となっています。
このTDエクスポート連携により、Treasure Dataのジョブ結果からParquetファイルを生成し、Azure Data Lake Storageに直接アップロードすることができます。
- Treasure Dataの基本的な知識
- Azure Data Lake Storageの基本的な知識
- Hierarchical Namespaceを有効にして構成されたAzure Data Lake Storageアカウント
- Azure Data Lake Access KeysまたはShared Access Signatureが設定されていること。詳細については、Obtain Azure Data Lake Credentialsを参照してください
- Export Integrationは、アカウントレベルまたはコンテナレベルのShared Access Signatureのみをサポートしています。フォルダレベルまたはディレクトリレベルのShared Access Signatureはサポートしていません
TD Consoleでは、クエリを実行する前にデータ接続を作成して構成する必要があります。データ接続の一部として、以下の手順に従って統合にアクセスするための認証を提供します。
- TD Consoleを開きます
- Integrations Hub > Catalogに移動します
- 統合を検索し、Azure Data Lakeを選択します
- Create Authenticationを選択し、統合の認証情報を入力します
認証フィールド
| Parameter | Description |
|---|---|
| Authentication Mode | 2つのサポートされている認証モードのいずれかを選択します: - Access Key - Shared Access Signatures |
| Account Name | 階層型名前空間が有効になっているAzureストレージアカウント名 |
| Account Key | 選択した認証モードに対応するAccount KeyまたはSAS Token。Azureプラットフォームから取得します。詳細については、Obtain Azure Data Lake Credentialsを参照してください |
| SAS Token | |
| Proxy Type | Azure Data Lake Storageへの統合がHTTPプロキシ経由の場合はHTTPを選択します |
| Proxy Host | Proxy TypeがHTTPの場合のProxy Host値 |
| Proxy Port | Proxy TypeがHTTPの場合のProxy Port値 |
| Proxy Username | Proxy TypeがHTTPの場合のプロキシユーザー名 |
| Proxy Password | Proxy TypeがHTTPの場合のプロキシパスワード |
| On Premises | このパラメータはエクスポート統合には適用されないため、無視してください |
- Continueを選択します
- 認証の名前を入力し、Doneを選択します
Audience Studioでアクティベーションを作成することで、ターゲットプラットフォームにセグメントデータを送信することもできます。
- Audience Studioに移動します
- 親セグメントを選択します
- ターゲットセグメントを開き、右クリックして、Create Activationを選択します
- Detailsパネルで、アクティベーション名を入力し、前のセクションのConfiguration Parametersに従ってアクティベーションを構成します
- Output Mappingパネルでアクティベーション出力をカスタマイズします

- Attribute Columns
- すべてのカラムを変更なしでエクスポートするには、Export All Columnsを選択します
- エクスポート用の特定のカラムを追加するには、+ Add Columnsを選択します。Output Column Nameには、同じSourceカラム名が事前入力されます。Output Column Nameを更新できます。アクティベーション出力用の新しいカラムを追加するには、+ Add Columnsを選択し続けます
- String Builder
- エクスポート用の文字列を作成するには、+ Add stringを選択します。以下の値から選択します:
- String: 任意の値を選択し、テキストを使用してカスタム値を作成します
- Timestamp: エクスポートの日時
- Segment Id: セグメントID番号
- Segment Name: セグメント名
- Audience Id: 親セグメント番号
- エクスポート用の文字列を作成するには、+ Add stringを選択します。以下の値から選択します:
- Scheduleを設定します

- スケジュールを定義する値を選択し、オプションでメール通知を含めます
- Createを選択します
TD Consoleは、複数の方法でデータをエクスポートすることをサポートしています。Data Workbenchからデータをエクスポートするには、以下の手順を実行します。
- Data Workbench > Queriesに移動します
- New Queryを選択し、クエリを定義します
- Export Resultsを選択して、データエクスポートを構成します

- 既存の認証を選択するか、上記のセクションに従って新しい認証を作成します
- エクスポートパラメータを構成し、Doneを選択します
- オプションで、指定したターゲット宛先に定期的にデータをエクスポートするスケジュールを構成できます。詳細については、Scheduling Jobs on TD Consoleを参照してください
構成フィールド
| Field | Description |
|---|---|
| Container name | 既存のAzureストレージコンテナの名前 |
| File path | Azureストレージ内のエクスポート場所。ファイル名とparquet拡張子を含みます。例: "folder/file.parquet" |
| Overwrite existing file? | チェックボックスがオンの場合、既存のファイルが上書きされます |
| Parquet compression | サポートされているparquet圧縮: - Uncompressed - Gzip - Snappy |
| Row group size (MB) | Parquet圧縮アルゴリズムは行グループごとにのみ適用されるため、行グループサイズが大きいほど、データを圧縮する機会が増えます。実際のデータスキーマに基づいてデータエクスポートを微調整するには、このフィールドを使用します。最小: 10 MB、最大: 1024 MB、デフォルト: 128 MB |
| Page size (KB) | 単一のレコードにアクセスするために完全に読み取る必要がある最小単位。この値が小さすぎると、圧縮が劣化します。実際のデータスキーマに基づいてデータエクスポートを微調整するには、このフィールドを使用します。最小: 8 KB、最大: 2048 KB、デフォルト: 1024 KB |
| Single file? | 有効にすると、単一のファイルが作成されます。それ以外の場合は、行グループサイズに基づいて複数のファイルが生成されます(圧縮が有効になっている場合、出力ファイルサイズは異なることに注意してください) |
| Advanced configuration | このオプションを有効にして、以下の詳細設定を調整します |
| Timestamp Unit | タイムスタンプ単位をミリ秒またはマイクロ秒で構成します。デフォルト: ミリ秒 |
| Enable Bloom filter | Bloomフィルターは、セットメンバーシップを近似する空間効率の高い構造で、明確な「いいえ」または「はいの可能性がある」という回答を提供します。このオプションを有効にして、生成されたparquetファイルにBloomフィルターを含めることができます |
| Retry limit | 最大リトライ回数。最小: 1、最大: 10、デフォルト: 5 |
| Retry Wait (second) | リトライを実行する前に待機する時間。最小: 1秒、最大: 300秒、デフォルト: 3秒 |
| Number of concurrent threads | Azure Storageサービスへの同時リクエストの数。最小: 1、最大: 8、デフォルト: 4 |
| Part size (MB) | Azure Storageは、小さなチャンク(リクエストバッファサイズ)でのファイルアップロードをサポートしています。最小: 1 MB、最大: 100 MB、デフォルト: 8 MB |
CLI(Toolbelt)を使用して、Parquetファイル形式でAzure Data Lakeへのクエリ結果のエクスポートをトリガーできます。td queryコマンドの--resultオプションとして、Azure Data Lake Storageへのエクスポート情報を指定する必要があります。td queryコマンドについては、この記事を参照してください。
オプションの形式はJSONであり、一般的な構造は以下の通りです。
{"type": "azure_datalake", "authentication_mode": "account_key", "account_name": "demo_account_name", "proxy_type": "none", "container_name": "demo_container_name", "file_path": "joetest/test-3.parquet", "overwrite_file": "true", "compression": "uncompressed", "row_group_size": "128", "page_size": 1024, "single_file": "false", "advanced_configuration": "false"}使用例
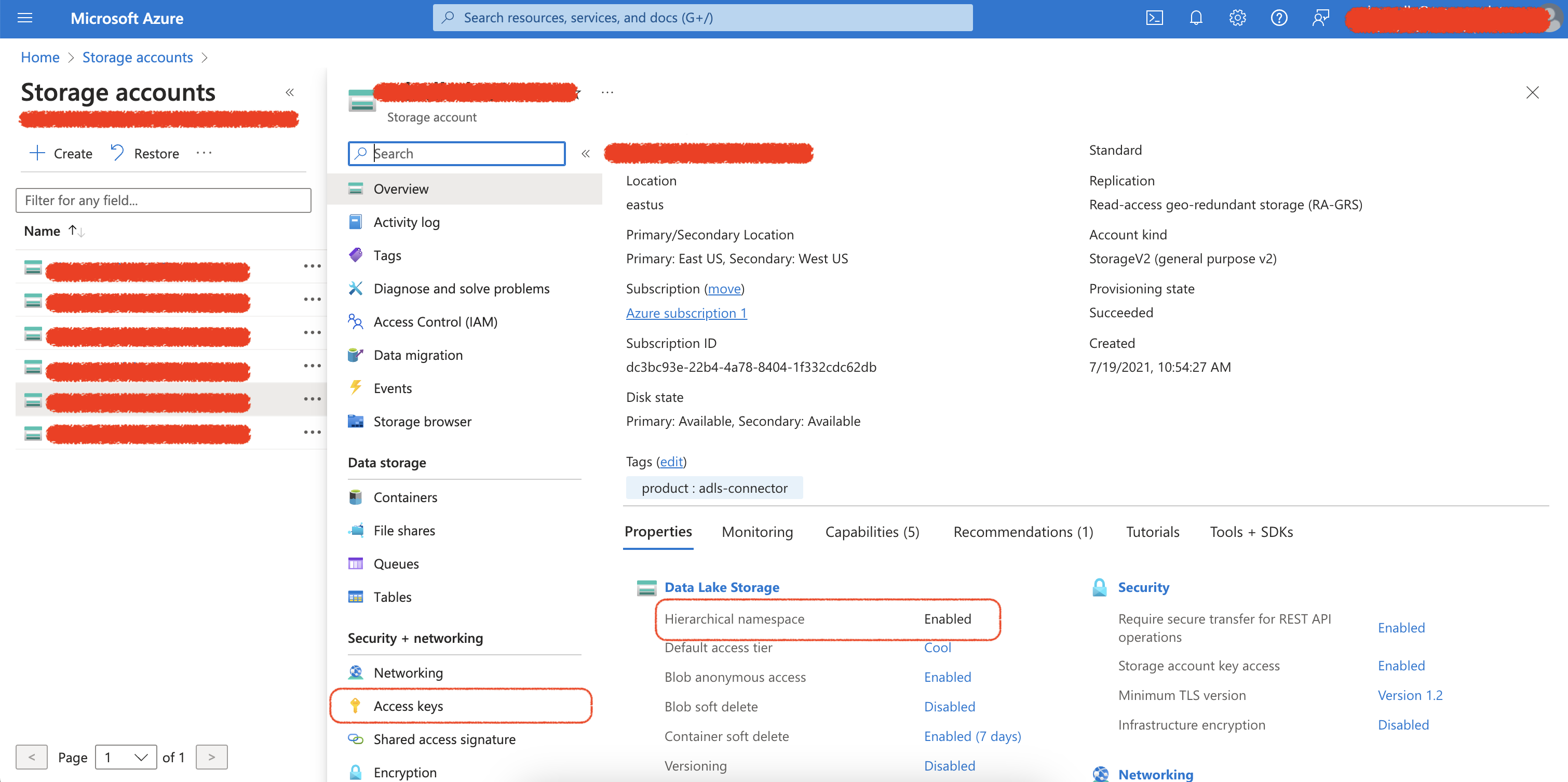
td query --result '{"type":"azure_datalake","authentication_mode":"account_key","account_name": "account name", "account_key": "account key", "proxy_type": "none", "container_name": "container", "file_path": "joe/test.parquet", "overwrite_file": "false", "compression": "uncompressed", "row_group_size": 128, "page_size": 1024, "single_file": true, "advanced_configuration": false}' -d sample_datasets "select * from sample_table" -T prestoMicrosoft Azure Portalにログインし、Storage accountsを選択します

ストレージアカウントを選択し、階層型名前空間オプションが有効になっていることを確認します。
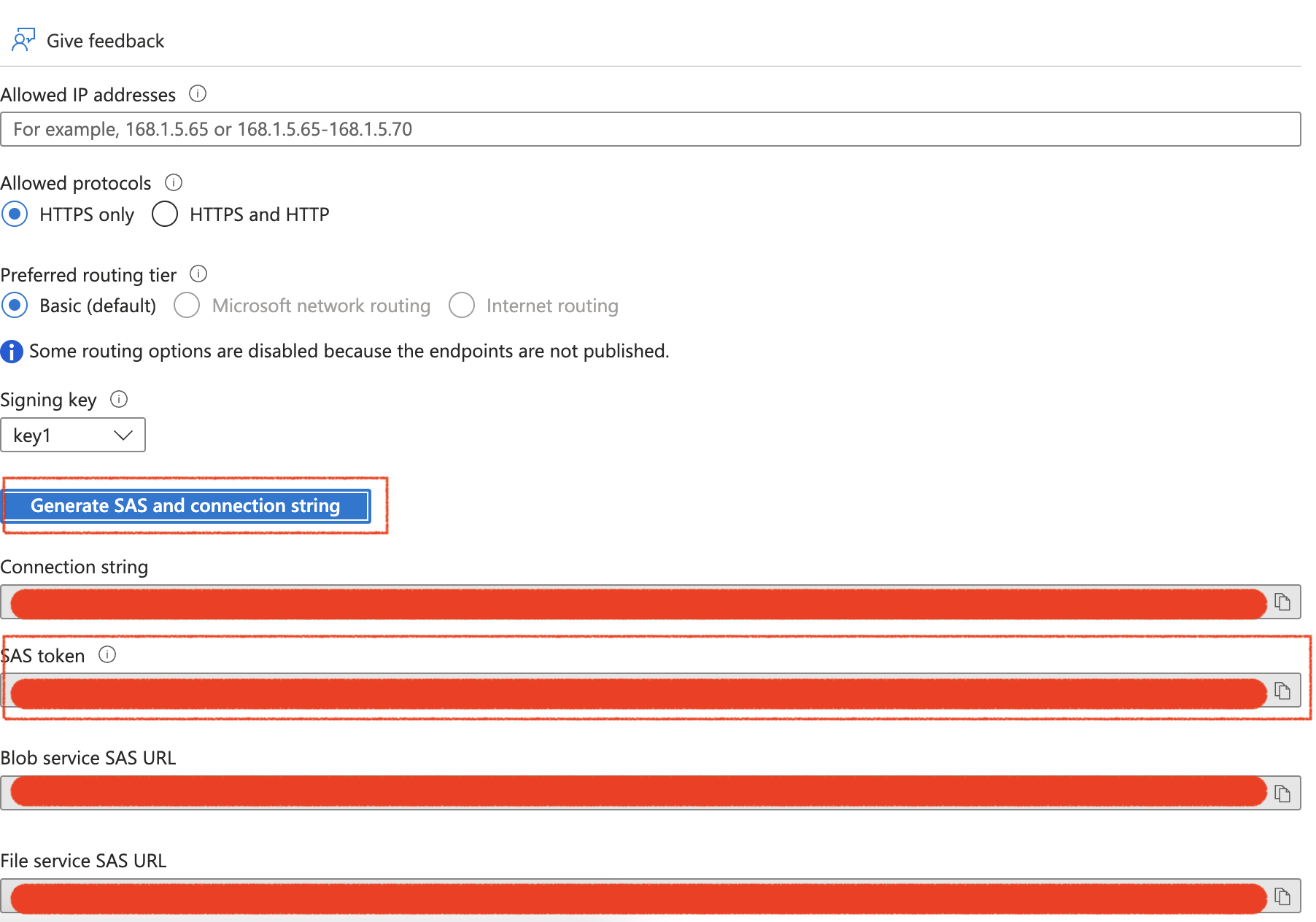
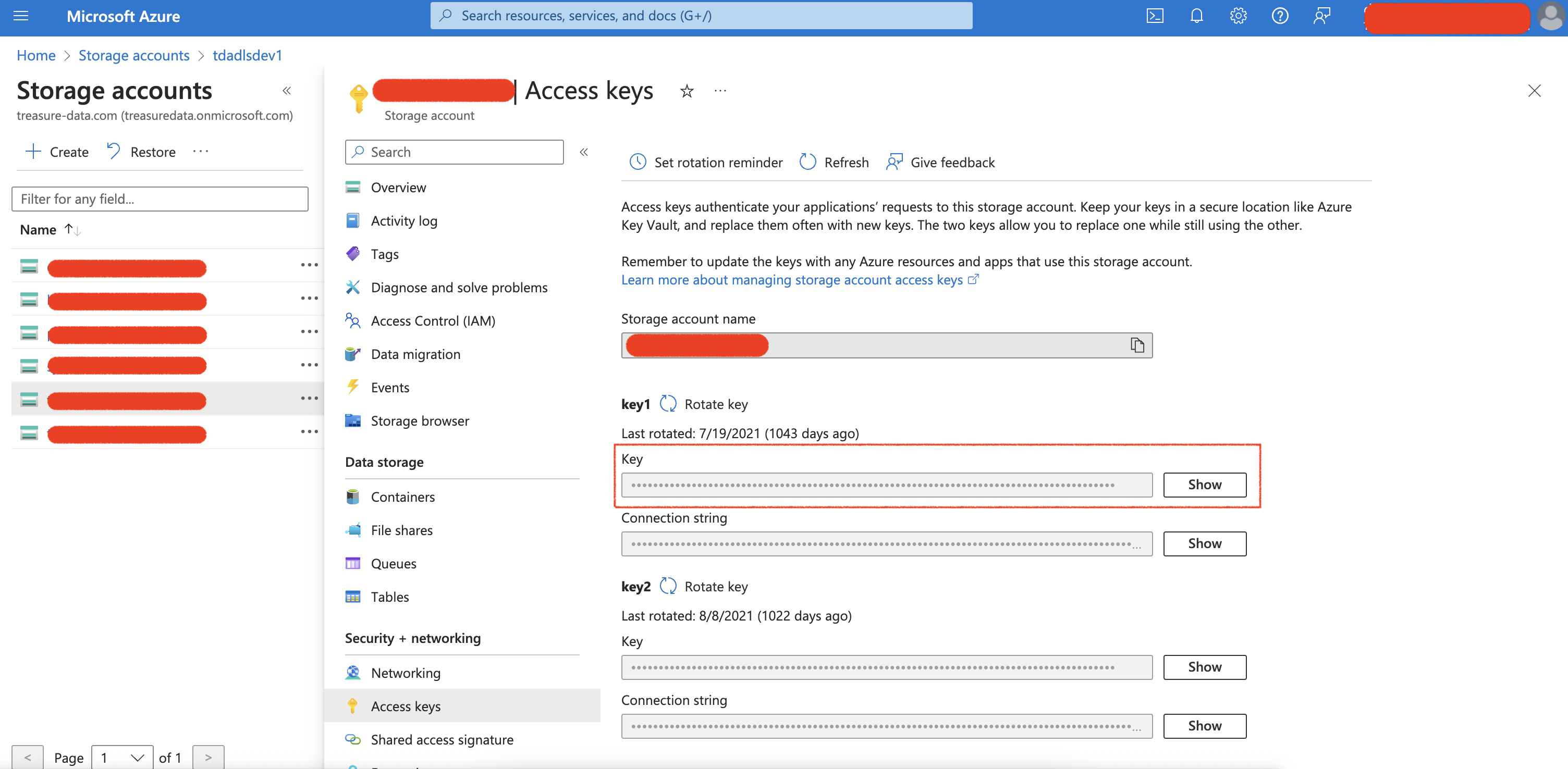
統合にAccess Keyを使用するには:
- Security + networkingメニューからAccess keysを選択します
- Showボタンを選択し、アクセスキーをコピーします
統合にShared Access Signatureを使用するには:
- Security + networkingメニューからShared access signatureを選択します
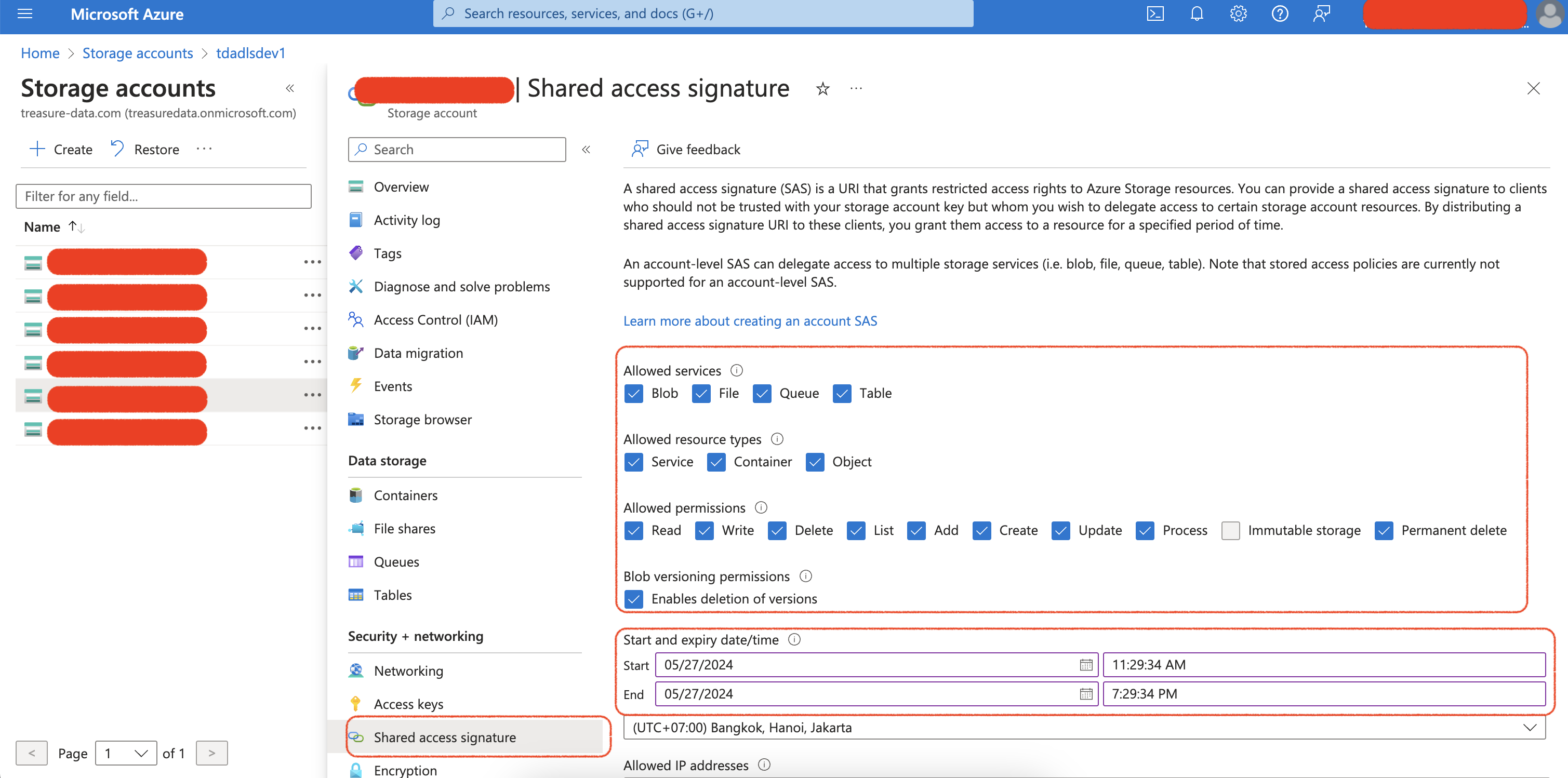
- Shared Access Signatureの権限と有効期限を構成します
- Generate SAS and connection stringボタンを選択し、SASトークンをコピーします