Microsoft Azure Blob Storage Import Integrationの詳細はこちら。
この記事では、ジョブの実行結果をMicrosoft Azure Blob Storageに直接書き込む方法について説明します。
Microsoft Azure Blob Storageへのエクスポートのサンプルワークフローについては、Treasure Boxesをご覧ください。
- TD Toolbeltを含むTreasure Dataの基本知識
- Microsoft Azure Platformアカウント
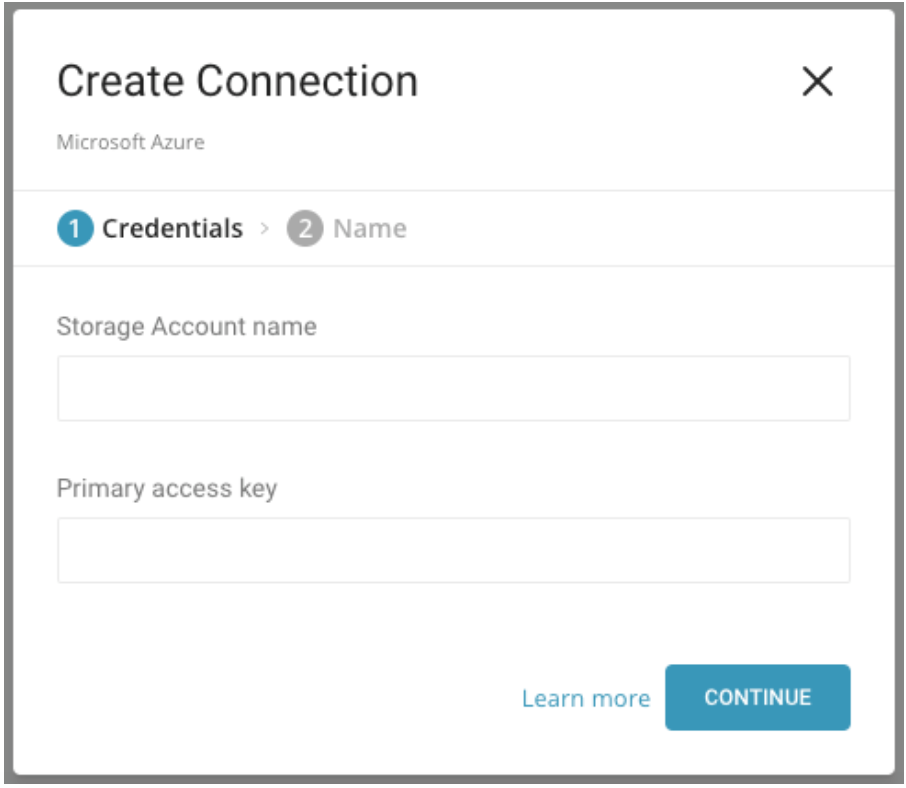
まず、Azure Storage Accountを作成する必要があります。作成方法に関するドキュメントは以下をご覧ください。
Azure Portalで、ストレージアカウントに移動し、「すべての設定」を選択してから「アクセスキー」を選択して、アカウントアクセスキーを取得します。
Azure PortalからAzure Blob Storageのコンテナを作成します。
また、コンテナ、Blob、およびメタデータの名前付けと参照のルールを確認してください。
TD Consoleのクエリエディタページにアクセスして、クエリをコンパイルします。
同じウィンドウで、「Result Export」セクションの「Add」ボタンを選択し、ドロップダウンメニューから「Microsoft Azure Blob Storage」を選択します。Account Name、Account Key、Container、Pathを含むすべての認証情報を編集します。
- Data Workbench > Queriesに移動します。
- 既存のクエリを選択するか、新しいクエリを作成します。
- クエリエディタで、Export Resultsチェックボックスをオンにします。
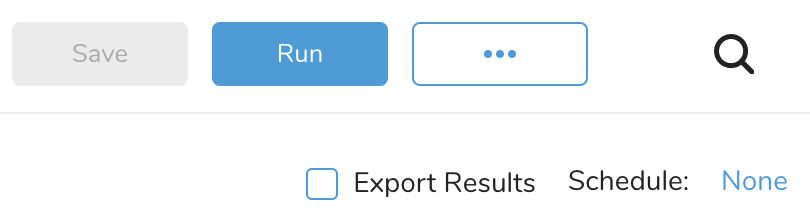
- Microsoft Azure接続を選択します。
- Export Resultsダイアログペインが開きます。以下のパラメータを編集します。
| パラメータ | 説明 | |
|---|---|---|
| Container (container) | Azure Blobコンテナ名 | |
| Path prefix (path_prefix) | ファイルが保存されるパス | |
| Blob Type (blob_type) | UNSPECIFIEDまたはBLOCK_BLOB。結果が非常に大きい場合はBLOCK_BLOBを指定してください | |
| Format (format) | 出力ファイル形式(csvまたはtsv) | |
| Compression (Encoders) | 出力ファイルを圧縮します。サポートされている圧縮形式:GzipまたはBzip2(gz / bz2) | |
| public_key | 暗号化に使用する公開鍵 | String |
| key_identifier | ファイルを保護するために使用される暗号化サブキーのKey IDを指定します。マスターキーは暗号化プロセスから除外されます。(string、必須) | String |
| amor | 暗号化された出力にASCII armorを使用(boolean) | Boolean |
| compression_type | 圧縮タイプは、暗号化する前にデータを圧縮するかどうかを決定します。サポートされる値 - gzip --> 例:ファイル拡張子は.csv.gz.gpgになります - bzip2 --> 例:ファイル拡張子は.csv.bz2.gpgになります - none --> 例:ファイル拡張子は.csv.gpgになります - zip_builtin --> 例:ファイル拡張子は.csv.zip.gpgになります - zlip_builtin --> 例:ファイル拡張子は.csv.z.gpgになります - bzip2_builtin --> 例:ファイル拡張子は.csv.bz2.gpgになります注意:暗号化してアップロードする前に、ファイルを圧縮してください。復号化すると、ファイルは元の.gzや.bz2などの圧縮形式に戻ります。 | String |
| Delimiter (delimiter) | CSVの場合は「,」、TSVの場合は「\t」、「 | 」、または任意の1バイト文字などの区切り文字 |
| Null string (null_string) | NULL値を表すために使用する値。デフォルトは空文字列 | |
| End-of-line character (newline) | 結果ファイルの行末文字 |
クエリに名前を付けて保存してから実行するか、そのまま実行します。クエリが正常に完了すると、結果は指定されたコンテナの宛先に自動的にインポートされます。
Scheduled Jobs と Result Export を使用して、指定したターゲット宛先に出力結果を定期的に書き込むことができます。
Treasure Data のスケジューラー機能は、高可用性を実現するために定期的なクエリ実行をサポートしています。
2 つの仕様が競合するスケジュール仕様を提供する場合、より頻繁に実行するよう要求する仕様が優先され、もう一方のスケジュール仕様は無視されます。
例えば、cron スケジュールが '0 0 1 * 1' の場合、「月の日」の仕様と「週の曜日」が矛盾します。前者の仕様は毎月 1 日の午前 0 時 (00:00) に実行することを要求し、後者の仕様は毎週月曜日の午前 0 時 (00:00) に実行することを要求するためです。後者の仕様が優先されます。
Data Workbench > Queries に移動します
新しいクエリを作成するか、既存のクエリを選択します。
Schedule の横にある None を選択します。

ドロップダウンで、次のスケジュールオプションのいずれかを選択します:
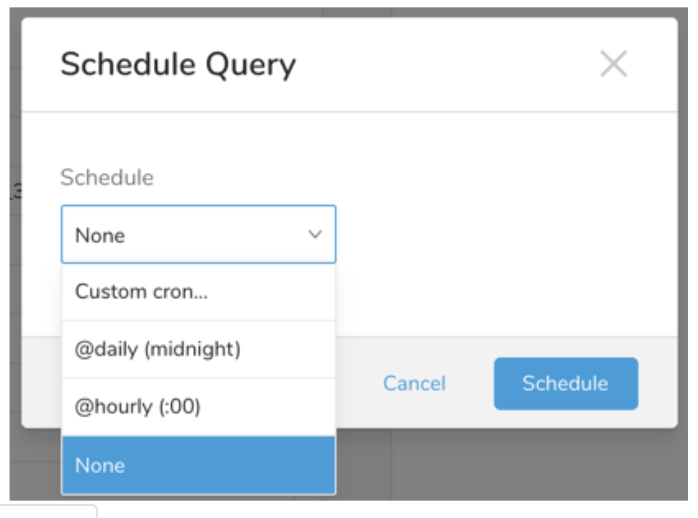
ドロップダウン値 説明 Custom cron... Custom cron... の詳細を参照してください。 @daily (midnight) 指定されたタイムゾーンで 1 日 1 回午前 0 時 (00:00 am) に実行します。 @hourly (:00) 毎時 00 分に実行します。 None スケジュールなし。
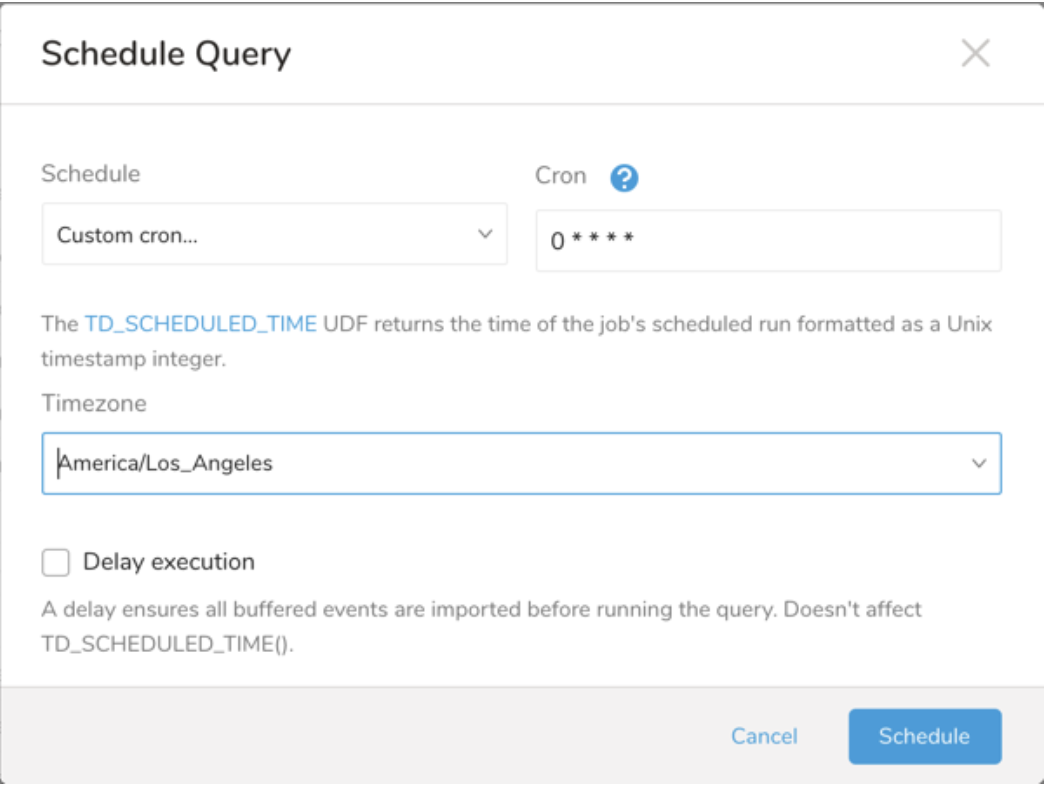
| Cron 値 | 説明 |
|---|---|
0 * * * * | 1 時間に 1 回実行します。 |
0 0 * * * | 1 日 1 回午前 0 時に実行します。 |
0 0 1 * * | 毎月 1 日の午前 0 時に 1 回実行します。 |
| "" | スケジュールされた実行時刻のないジョブを作成します。 |
* * * * *
- - - - -
| | | | |
| | | | +----- day of week (0 - 6) (Sunday=0)
| | | +---------- month (1 - 12)
| | +--------------- day of month (1 - 31)
| +-------------------- hour (0 - 23)
+------------------------- min (0 - 59)次の名前付きエントリを使用できます:
- Day of Week: sun, mon, tue, wed, thu, fri, sat.
- Month: jan, feb, mar, apr, may, jun, jul, aug, sep, oct, nov, dec.
各フィールド間には単一のスペースが必要です。各フィールドの値は、次のもので構成できます:
| フィールド値 | 例 | 例の説明 |
|---|---|---|
| 各フィールドに対して上記で表示された制限内の単一の値。 | ||
フィールドに基づく制限がないことを示すワイルドカード '*'。 | '0 0 1 * *' | 毎月 1 日の午前 0 時 (00:00) に実行するようにスケジュールを設定します。 |
範囲 '2-5' フィールドの許可される値の範囲を示します。 | '0 0 1-10 * *' | 毎月 1 日から 10 日までの午前 0 時 (00:00) に実行するようにスケジュールを設定します。 |
カンマ区切りの値のリスト '2,3,4,5' フィールドの許可される値のリストを示します。 | 0 0 1,11,21 * *' | 毎月 1 日、11 日、21 日の午前 0 時 (00:00) に実行するようにスケジュールを設定します。 |
周期性インジケータ '*/5' フィールドの有効な値の範囲に基づいて、 スケジュールが実行を許可される頻度を表現します。 | '30 */2 1 * *' | 毎月 1 日、00:30 から 2 時間ごとに実行するようにスケジュールを設定します。 '0 0 */5 * *' は、毎月 5 日から 5 日ごとに午前 0 時 (00:00) に実行するようにスケジュールを設定します。 |
'*' ワイルドカードを除く上記の いずれかのカンマ区切りリストもサポートされています '2,*/5,8-10' | '0 0 5,*/10,25 * *' | 毎月 5 日、10 日、20 日、25 日の午前 0 時 (00:00) に実行するようにスケジュールを設定します。 |
- (オプション) Delay execution を有効にすることで、クエリの開始時刻を遅延させることができます。
クエリに名前を付けて保存して実行するか、単にクエリを実行します。クエリが正常に完了すると、クエリ結果は指定された宛先に自動的にエクスポートされます。
設定エラーにより継続的に失敗するスケジュールジョブは、複数回通知された後、システム側で無効化される場合があります。
(オプション) Delay execution を有効にすることで、クエリの開始時刻を遅延させることができます。
Audience Studio で activation を作成することで、segment データをターゲットプラットフォームに送信することもできます。
- Audience Studio に移動します。
- parent segment を選択します。
- ターゲット segment を開き、右クリックして、Create Activation を選択します。
- Details パネルで、Activation 名を入力し、前述の Configuration Parameters のセクションに従って activation を設定します。
- Output Mapping パネルで activation 出力をカスタマイズします。

- Attribute Columns
- Export All Columns を選択すると、変更を加えずにすべての列をエクスポートできます。
- + Add Columns を選択して、エクスポート用の特定の列を追加します。Output Column Name には、Source 列名と同じ名前があらかじめ入力されます。Output Column Name を更新できます。+ Add Columns を選択し続けて、activation 出力用の新しい列を追加します。
- String Builder
- + Add string を選択して、エクスポート用の文字列を作成します。次の値から選択します:
- String: 任意の値を選択します。テキストを使用してカスタム値を作成します。
- Timestamp: エクスポートの日時。
- Segment Id: segment ID 番号。
- Segment Name: segment 名。
- Audience Id: parent segment 番号。
- + Add string を選択して、エクスポート用の文字列を作成します。次の値から選択します:
- Schedule を設定します。

- スケジュールを定義する値を選択し、オプションでメール通知を含めます。
- Create を選択します。
batch journey の activation を作成する必要がある場合は、Creating a Batch Journey Activation を参照してください。
Microsoft Azure Blob StorageへのResult ExportにCLIを使用することもできます。
td query --result '{"type":"azure_blob_storage","account_name":"xxxx","account_key":"xxxx","container":"xxxx","path_prefix":"/path/to/file.csv","sequence_format":"","header_line":true,"quote_policy":"MINIMAL","delimiter":",","null_string":"","newline":"CRLF"}' -d sample_datasets "select * from www_access" -T prestoTreasure Workflow内で、このデータコネクタを使用してデータを出力するように指定できます。
timezone: UTC
_export:
td:
database: sample_datasets
+td-result-into-target:
td>: queries/sample.sql
result_connection: my_azure_blob
result_settings:
container: test_container
path_prefix: /path/to/file.csv
format: csv
blob_type: BLOCK_BLOBCLIを使用してワークフロー内でデータコネクタを使用したデータのエクスポートの詳細をご覧ください。
- Embulk-encoder-Encryptionドキュメント:Embulk Encoder Encryption PGP