Microsoft Azure Data Lake Storageは、ビッグデータ向けの業界をリードするストレージソリューションです。このインポート統合により、Azure Data Lake StorageからParquetファイルをTreasure Dataに取り込み、Treasure Dataで設定された他のデータソースと統合することができます。
- 既存のすべてのデータファイルをコピー: Azure Data LakeのすべてのParquetファイルをTreasure Dataにコピーして、システムから移行できます。
- データを直接取り込む: ブリッジシステムを使用することなく、Azure Data LakeからTreasure Dataへ直接データをインポートします。
- Treasure Dataの基本知識
- Microsoft Azure Data Lakeの基本知識
- Shared Access Signaturesの作成とファイルのダウンロードに十分な権限を持つMicrosoft Azure Data Lakeアカウント
- Azure Data Lake Storage (v2) のみをサポート
- Spark Partition (https://spark.apache.org/docs/2.4.0/sql-data-sources-parquet.html#partition-discovery) として1レベルのパーティションキーのみをサポート
- snappy圧縮コーデックのみをサポート
- ダウンロードとParquetファイルスキーマの読み取りに時間がかかるため、データプレビューは利用できません
- HTTP Proxyメソッドのみをサポート
- AzureのBlobStorageEventsまたはSoftDeleteはサポートされません
- deltaファイル形式はサポートされません。(CSVやTVSなどの他の一般的なファイル形式については、Microsoft Azure Blob Storageを使用してください)
Parquetファイルサイズに関する推奨事項
Treasure Dataでは、Row Group Sizeを3.4GB未満に制限することを推奨しています。Row Group Sizeが3.4GBより大きい場合、インポートジョブで「Out of Memory」エラーが発生する可能性があります。
これが発生した場合は、データをより小さなParquetファイルサイズに再パーティション化してから、インポートジョブを再試行する必要があります。
- Azure PortalでStorage Accountの管理画面に移動します
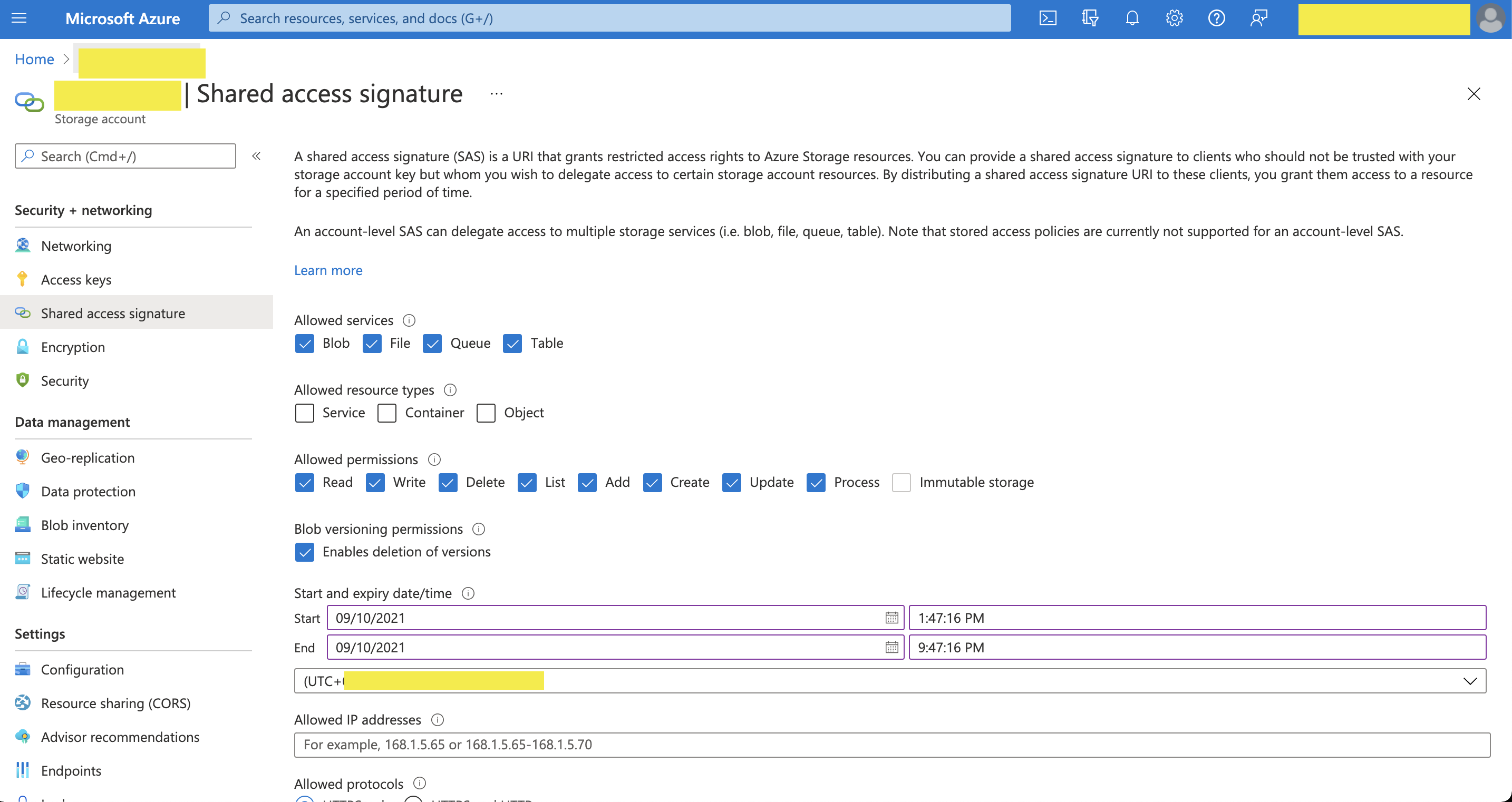
- Access keysまたはShared access signaturesを選択します
- TD認証設定で使用するためにキーをコピーします
Treasure Dataでは、クエリを実行する前にデータ接続を作成して設定する必要があります。データ接続の一部として、統合にアクセスするための認証情報を提供します。
- TD Consoleを開きます。
- Integrations Hub > Catalogに移動します。
- Catalog画面の右端にある検索アイコンをクリックして、「Azure Lake」と入力します。
- Microsoft Azure Data Lakeコネクタにカーソルを合わせて、Create Authenticationを選択します。
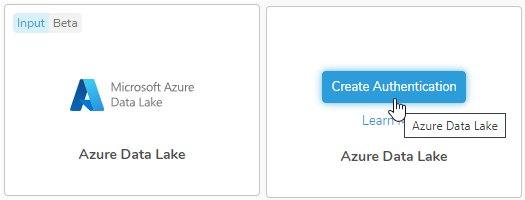
- 以下のいずれかの認証方法を選択します:
Account Key認証方法 Shared Access Signatures認証方法 Proxy Setting (オプション) On Premises Setting (オプション)
- Authentication ModeドロップダウンメニューからShared Access Signatureを選択します。

ストレージのAccount Nameを入力します。
Azure PortalからコピーしたAccount Keyを入力します。
Authentication ModeドロップダウンメニューからShared Access Signatureを選択します。
ストレージのAccount Nameを入力します。
Azure PortalからコピーしたAccount Keyを入力します。
HTTP Proxyを経由して実行する場合は、Proxy Typeを選択します。
 **
**
Proxy Host、Proxy Port、Proxy Username、Proxy Passwordを入力します。
Data Lakeがオンプレミスにある場合は、On Premises Settingを指定します。

- Premises Hostを入力します。 On Premises Settingでは、Shared Access Signatures認証方式のみがサポートされています。
- 接続の名前を入力します。
- 認証を他のユーザーと共有するかどうかを選択します。
- Continueを選択します。
認証接続を作成すると、自動的にAuthenticationsページに移動します。
- 作成した接続を検索します。
- New Sourceを選択します。
- Data Transfer フィールドにSourceの名前を入力します**。**
- Nextを選択します。Source Tableダイアログが開きます。
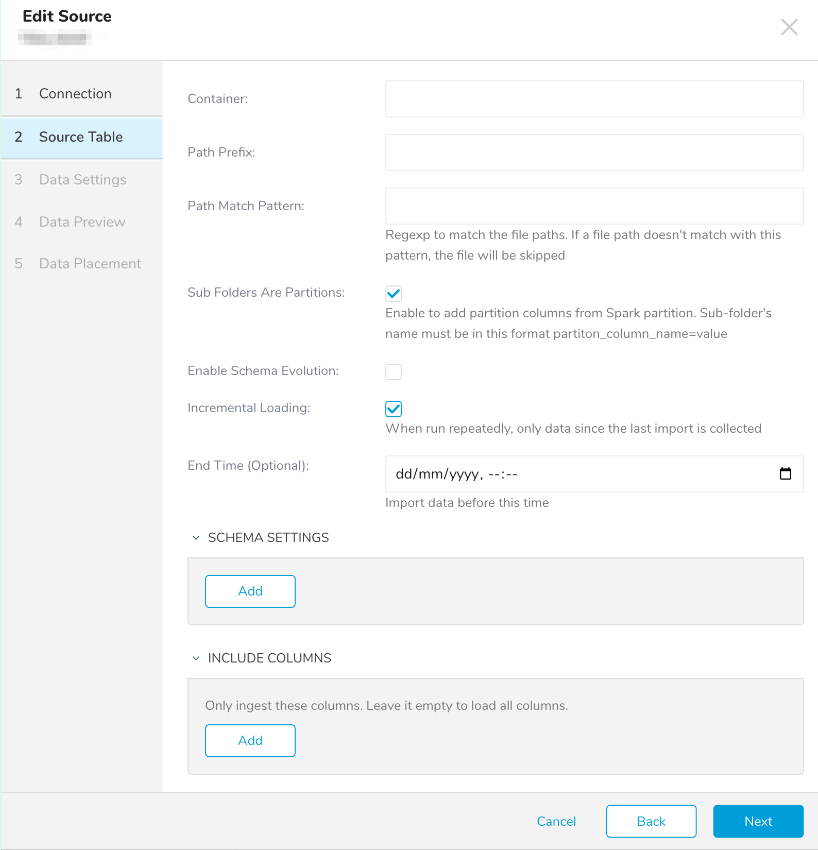
- 以下のパラメータを編集します:
| Parameters | Description |
|---|---|
| Container | Data Lakeのコンテナ名 |
| Path Prefix | 取り込むすべてのファイルを含むフォルダへのパス |
| Path Match Pattern (optional) | この正規表現パターンに一致するファイルのみをインポートします |
| Sub folders are partitions | Spark Partitionフォルダ構造を使用していることを指定する場合に有効にします。サブフォルダは<column_name>=valueの形式で名前を付ける必要があります |
| Enable Schema Evolution | parquet用のスキーマエボリューションを有効にします |
| Incremental Loading | インクリメンタルモードを有効にします。 |
| End time | 指定した時刻以降に変更されたファイルのみがインポートされます。 |
| Schema Settings | 「Sub Folders Are Partitions」が有効な場合、そのパーティションカラムのカラム名とデータ型を指定する必要があります |
| Include Columns | インポートするカラムを制限します。リストで指定されたカラムのみがインポートされます。リストが空の場合、すべてのカラムがインポートされます。 |
Nextを選択します。 Data Settingsページは必要に応じて変更できます。また、このページをスキップすることもできます。
必要に応じて、以下のパラメータを編集します:
| Parameter | Description |
|---|---|
| --- | --- |
| Retry Limit | 最大リトライ回数 |
| Initial retry interval in millis | 初回リトライ間隔(ミリ秒) |
| Max retry wait in millis | 最大リトライ間隔。初回リトライ後、待機間隔は最大値に達するまで2倍になります。 |
| repartition_number | Out Of Memory例外を回避するために、入力ファイルを小さなファイルに分割します。大きなデータファイルに適用されます。デフォルト値は100です。 |
- Nextを選択します。
Data Previewはこの統合ではサポートされていません。プレビューにはサンプルデータのみが表示されます。
データの配置について、データを配置したいターゲット database と table を選択し、インポートを実行する頻度を指定します。
Next を選択します。Storage の下で、インポートされたデータを配置する新しい database を作成するか、既存の database を選択し、新しい table を作成するか、既存の table を選択します。
Database を選択 > Select an existing または Create New Database を選択します。
オプションで、database 名を入力します。
Table を選択 > Select an existing または Create New Table を選択します。
オプションで、table 名を入力します。
データをインポートする方法を選択します。
- Append (デフォルト) - データインポートの結果は table に追加されます。 table が存在しない場合は作成されます。
- Always Replace - 既存の table の全体の内容をクエリの結果出力で置き換えます。table が存在しない場合は、新しい table が作成されます。
- Replace on New Data - 新しいデータがある場合のみ、既存の table の全体の内容をクエリの結果出力で置き換えます。
Timestamp-based Partition Key 列を選択します。 デフォルトキーとは異なるパーティションキーシードを設定したい場合は、long または timestamp 列をパーティショニング時刻として指定できます。デフォルトの時刻列として、add_time フィルターで upload_time を使用します。
データストレージの Timezone を選択します。
Schedule の下で、このクエリを実行するタイミングと頻度を選択できます。
- Off を選択します。
- Scheduling Timezone を選択します。
- Create & Run Now を選択します。
- On を選択します。
- Schedule を選択します。UI では、@hourly、@daily、@monthly、またはカスタム cron の 4 つのオプションが提供されます。
- Delay Transfer を選択して、実行時間の遅延を追加することもできます。
- Scheduling Timezone を選択します。
- Create & Run Now を選択します。
転送が実行された後、Data Workbench > Databases で転送の結果を確認できます。
Treasure Workflow内で、ワークフロー内でこのデータコネクタの使用を指定できます。
詳細はUsing Workflows to Export Data with the TD Toolbeltを参照してください。
+setup:
echo>: start ${session_time}
+import-with-sql:
td_load>: config.yml
database: ${td.some_database}
table: ${td.some_table2}
+teardown:
echo>: finish ${session_time}
以下は、Azure Data Lakeからファイルを取得するための設定ファイルの例です:
input: type: azure_datalake authentication_mode: account_key account_name: tdadl account_key: fjZliu61iZV sas_token: ?sv=sas_token container_name: test path_prefix: /traffic_data/partition/collisionrecords2/ path_match_pattern: /traffic_data/partition/collisionrecords2/* subfolder_partitions: true proxy_type: none proxy_host: host proxy_port: 3128 proxy_username: tdpy proxy_password: 321tre repartition_number: 100 schema_evolution: false incremental: true last_updated_at: "2023-12-20T03:51:20.937Z" include_columns: [ col0, col3, col4, ]`"Soft delete for blobs"機能を有効にすると、コネクタはREST APIを使用するため動作しません。
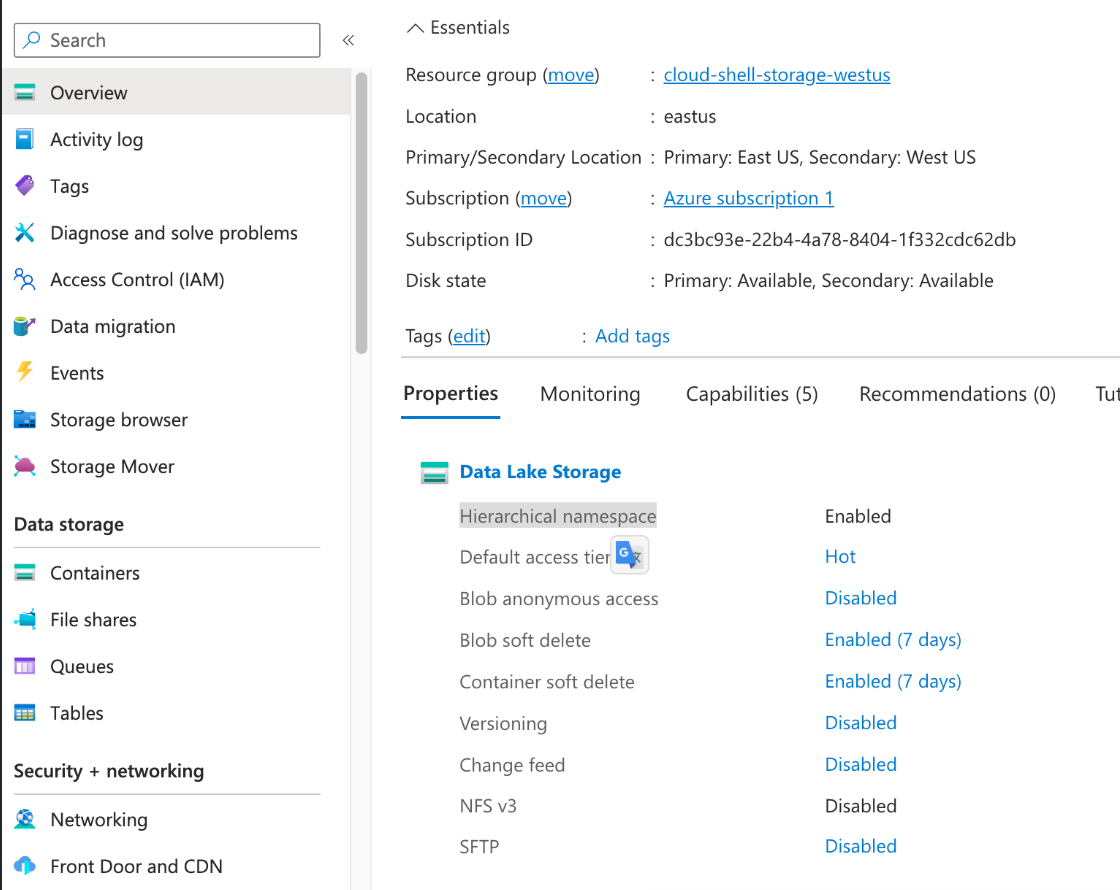
この機能を使用するには、Azure Portalにログインし、概要ページからData Lake StorageのPropertiesを変更して、"Hierarchical namespace"を有効にします。
エラー例は次のようになります。
Caused by: org.apache.hadoop.fs.azurebfs.contracts.exceptions.AbfsRestOperationException: Operation failed: "Server failed to authenticate the request. Make sure the value of Authorization header is formed correctly including the signature.", 403, HEAD, https://kfcusprdanalyticsadl.dfs.core.windows.net/data-science-container/?upn=false&action=getAccessControl&timeout=90&sp=racwdlmep&st=2024-08-26T15:03:55Z&se=2024-10-15T23:03:55Z&spr=https&sv=2022-11-02&sr=d&sig=XXXXX&sdd=2s, rId: 596f51a1-601f-000d-6fe0-f7dd2e000000