Microsoft SQL Server Import Integrationの詳細はこちら。
ジョブ結果をMicrosoft SQL Serverのテーブルに直接書き込むことができます。
SQL Serverテーブルへのエクスポートのサンプルワークフローについては、Treasure Boxesをご覧ください。
- Treasure Dataの基本的な知識
- SQL Serverインスタンス
TD Consoleを開きます。
Data Workbench > Queriesに移動します。
新しいクエリを作成するか、既存のクエリを選択します。
Export Resultsを選択します。
Choose Integrationダイアログが開きます。次の2つのオプションのいずれかを選択します。
Use Existing Integration。既存のintegrationを選択します。
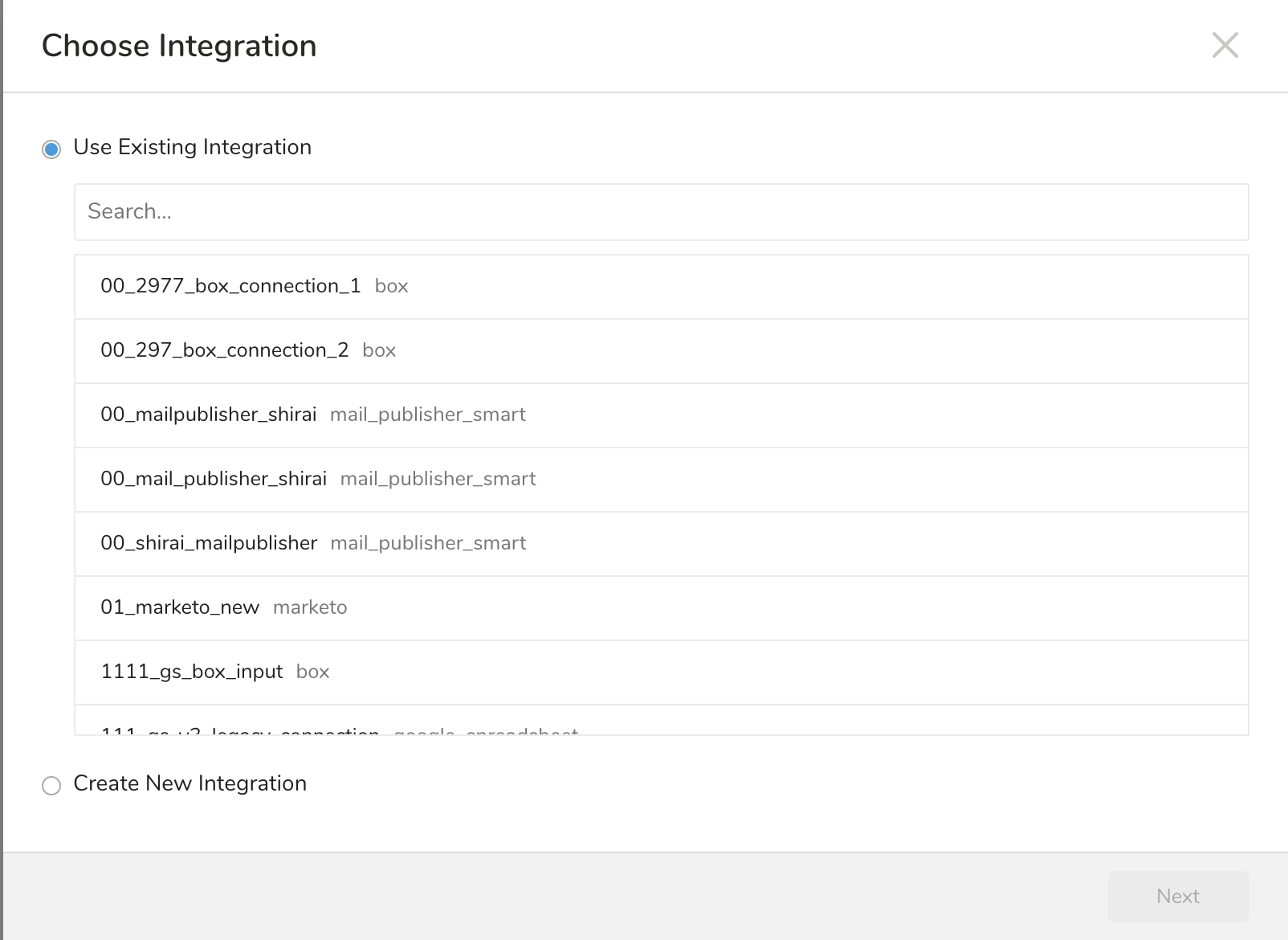
Create New Integration。integrationタイプを選択し、integration Name、Host、User、Passwordを編集します。
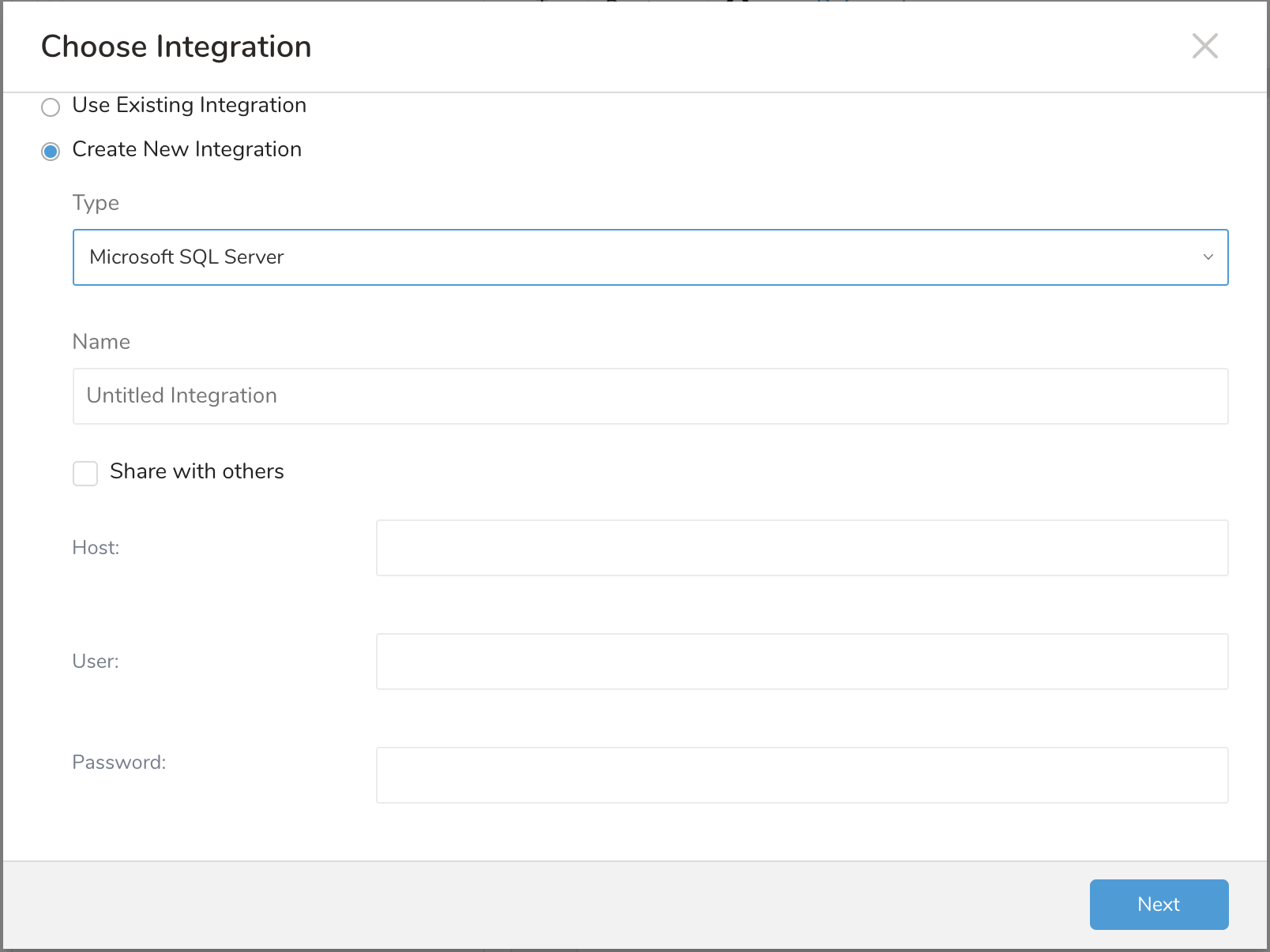
- Azureを使用している場合は、インスタンス名を省略し、ポート番号のみを指定してください。
- Azureを使用しておらず、独自のインスタンスを使用する場合は、ポートなしでインスタンス名のみを使用してデータベースに接続できることを確認してください。これは、ポートが設定されている場合、インスタンス名が無視されるためです。JDBCライブラリは名前からポートへの解決を試みず、代わりに設定のポートを使用します。指定されたポートを使用せずにデータベースコネクタツールで確認してください。
出力データ情報を入力します
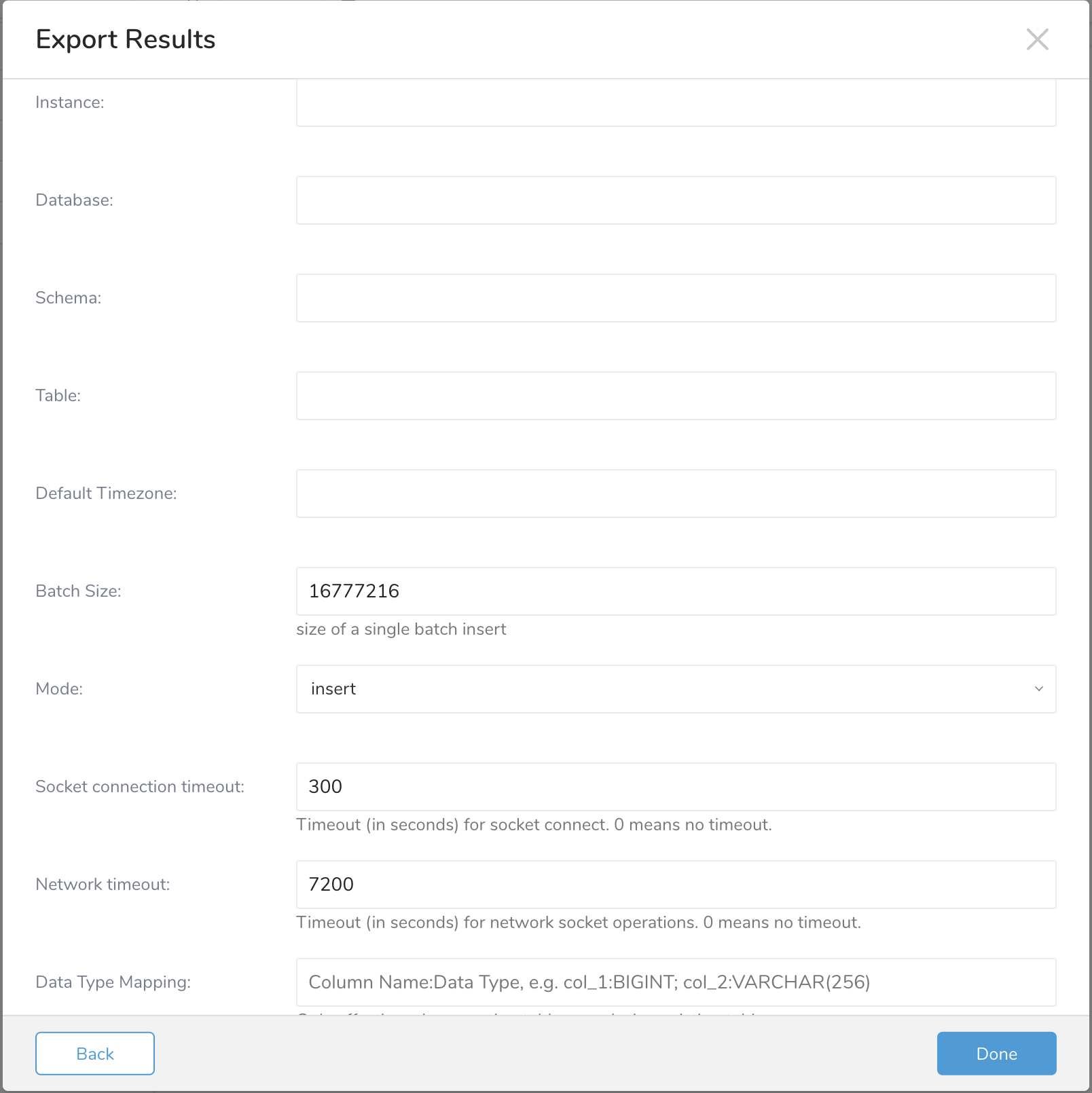
情報には以下が含まれます:
Instance: インスタンス名
Database: データベース名
Schema: スキーマ名
Table: テーブル名
Default Timezone: デフォルトのタイムゾーン
Batch Size: バッチサイズ実行
Mode:
- insert
- insert_direct
- truncate_insert
- replace
- merge
Socket connection timeout: ソケット接続のタイムアウト制限
Network timeout: ネットワーク接続のタイムアウト制限
Data Type Mapping: カラムデータ型のマッピング。テーブルの作成または既存テーブルの置換時にのみ有効です。
クエリに名前を付けて保存して実行するか、クエリを実行するだけです。クエリが正常に完了すると、結果は指定されたSQL Server宛先にエクスポートされます。
Scheduled Jobs と Result Export を使用して、指定したターゲット宛先に出力結果を定期的に書き込むことができます。
Treasure Data のスケジューラー機能は、高可用性を実現するために定期的なクエリ実行をサポートしています。
2 つの仕様が競合するスケジュール仕様を提供する場合、より頻繁に実行するよう要求する仕様が優先され、もう一方のスケジュール仕様は無視されます。
例えば、cron スケジュールが '0 0 1 * 1' の場合、「月の日」の仕様と「週の曜日」が矛盾します。前者の仕様は毎月 1 日の午前 0 時 (00:00) に実行することを要求し、後者の仕様は毎週月曜日の午前 0 時 (00:00) に実行することを要求するためです。後者の仕様が優先されます。
Data Workbench > Queries に移動します
新しいクエリを作成するか、既存のクエリを選択します。
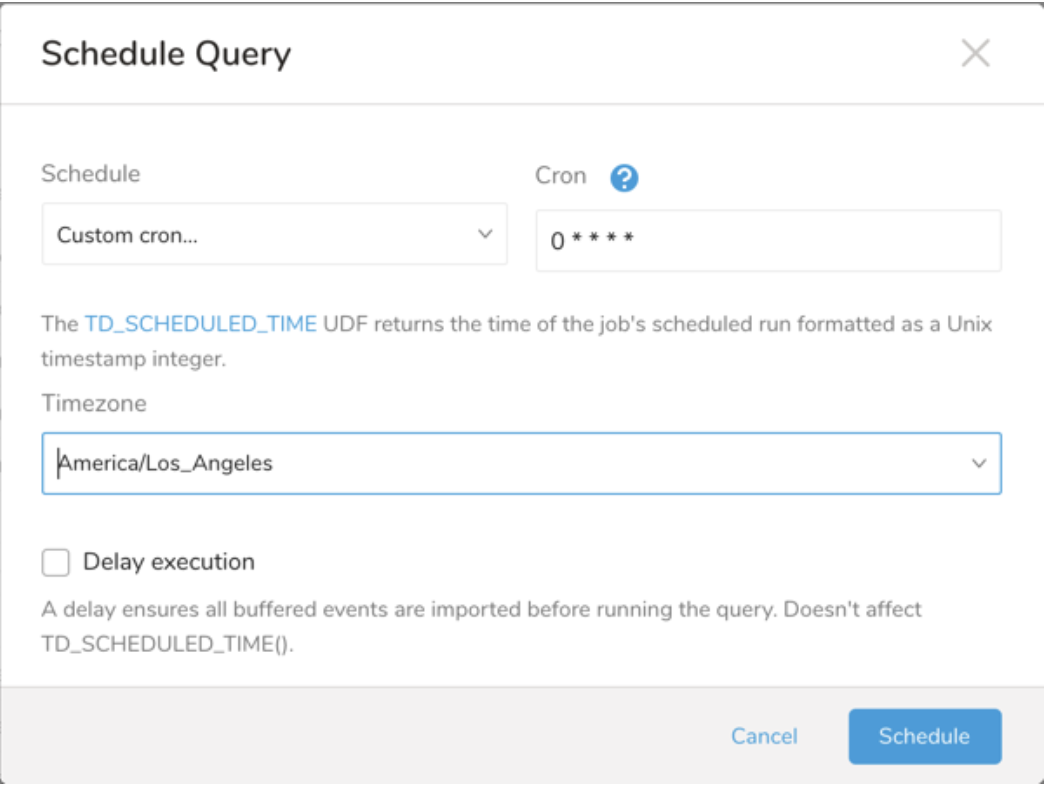
Schedule の横にある None を選択します。

ドロップダウンで、次のスケジュールオプションのいずれかを選択します:
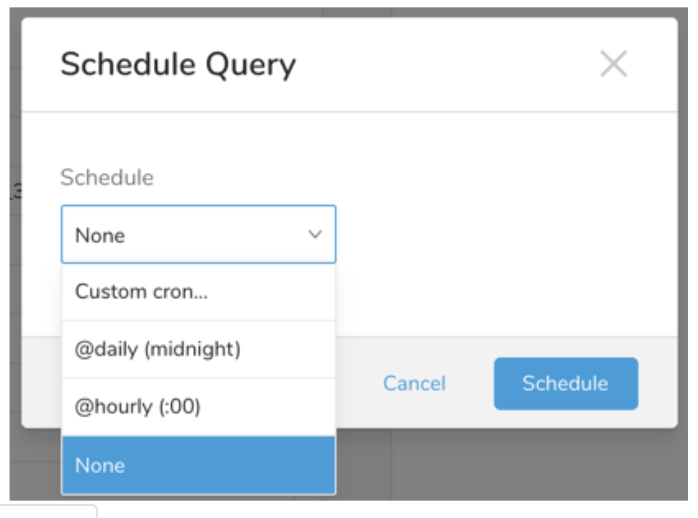
ドロップダウン値 説明 Custom cron... Custom cron... の詳細を参照してください。 @daily (midnight) 指定されたタイムゾーンで 1 日 1 回午前 0 時 (00:00 am) に実行します。 @hourly (:00) 毎時 00 分に実行します。 None スケジュールなし。
| Cron 値 | 説明 |
|---|---|
0 * * * * | 1 時間に 1 回実行します。 |
0 0 * * * | 1 日 1 回午前 0 時に実行します。 |
0 0 1 * * | 毎月 1 日の午前 0 時に 1 回実行します。 |
| "" | スケジュールされた実行時刻のないジョブを作成します。 |
* * * * *
- - - - -
| | | | |
| | | | +----- day of week (0 - 6) (Sunday=0)
| | | +---------- month (1 - 12)
| | +--------------- day of month (1 - 31)
| +-------------------- hour (0 - 23)
+------------------------- min (0 - 59)次の名前付きエントリを使用できます:
- Day of Week: sun, mon, tue, wed, thu, fri, sat.
- Month: jan, feb, mar, apr, may, jun, jul, aug, sep, oct, nov, dec.
各フィールド間には単一のスペースが必要です。各フィールドの値は、次のもので構成できます:
| フィールド値 | 例 | 例の説明 |
|---|---|---|
| 各フィールドに対して上記で表示された制限内の単一の値。 | ||
フィールドに基づく制限がないことを示すワイルドカード '*'。 | '0 0 1 * *' | 毎月 1 日の午前 0 時 (00:00) に実行するようにスケジュールを設定します。 |
範囲 '2-5' フィールドの許可される値の範囲を示します。 | '0 0 1-10 * *' | 毎月 1 日から 10 日までの午前 0 時 (00:00) に実行するようにスケジュールを設定します。 |
カンマ区切りの値のリスト '2,3,4,5' フィールドの許可される値のリストを示します。 | 0 0 1,11,21 * *' | 毎月 1 日、11 日、21 日の午前 0 時 (00:00) に実行するようにスケジュールを設定します。 |
周期性インジケータ '*/5' フィールドの有効な値の範囲に基づいて、 スケジュールが実行を許可される頻度を表現します。 | '30 */2 1 * *' | 毎月 1 日、00:30 から 2 時間ごとに実行するようにスケジュールを設定します。 '0 0 */5 * *' は、毎月 5 日から 5 日ごとに午前 0 時 (00:00) に実行するようにスケジュールを設定します。 |
'*' ワイルドカードを除く上記の いずれかのカンマ区切りリストもサポートされています '2,*/5,8-10' | '0 0 5,*/10,25 * *' | 毎月 5 日、10 日、20 日、25 日の午前 0 時 (00:00) に実行するようにスケジュールを設定します。 |
- (オプション) Delay execution を有効にすることで、クエリの開始時刻を遅延させることができます。
クエリに名前を付けて保存して実行するか、単にクエリを実行します。クエリが正常に完了すると、クエリ結果は指定された宛先に自動的にエクスポートされます。
設定エラーにより継続的に失敗するスケジュールジョブは、複数回通知された後、システム側で無効化される場合があります。
(オプション) Delay execution を有効にすることで、クエリの開始時刻を遅延させることができます。
Audience Studio で activation を作成することで、segment データをターゲットプラットフォームに送信することもできます。
- Audience Studio に移動します。
- parent segment を選択します。
- ターゲット segment を開き、右クリックして、Create Activation を選択します。
- Details パネルで、Activation 名を入力し、前述の Configuration Parameters のセクションに従って activation を設定します。
- Output Mapping パネルで activation 出力をカスタマイズします。

- Attribute Columns
- Export All Columns を選択すると、変更を加えずにすべての列をエクスポートできます。
- + Add Columns を選択して、エクスポート用の特定の列を追加します。Output Column Name には、Source 列名と同じ名前があらかじめ入力されます。Output Column Name を更新できます。+ Add Columns を選択し続けて、activation 出力用の新しい列を追加します。
- String Builder
- + Add string を選択して、エクスポート用の文字列を作成します。次の値から選択します:
- String: 任意の値を選択します。テキストを使用してカスタム値を作成します。
- Timestamp: エクスポートの日時。
- Segment Id: segment ID 番号。
- Segment Name: segment 名。
- Audience Id: parent segment 番号。
- + Add string を選択して、エクスポート用の文字列を作成します。次の値から選択します:
- Schedule を設定します。

- スケジュールを定義する値を選択し、オプションでメール通知を含めます。
- Create を選択します。
batch journey の activation を作成する必要がある場合は、Creating a Batch Journey Activation を参照してください。
次のコマンドを使用すると、Result OutputがSQL Serverにエクスポートされるスケジュールクエリを設定できます。
json_keyを指定し、改行をバックスラッシュでエスケープしてください。
例:
td sched:create scheduled_sqlserver "10 6 * * *" \
-d dataconnector_db "SELECT id,account,purchase,comment,time FROM payment_history" \
-r '{ "type":"sqlserver", "user":"user", "database":"mydb", "table":"payments", "batch_size":16777216, "mode":"insert"}'| モード | 説明 |
|---|---|
| insert | このモードは、最初にいくつかの中間テーブルに行を書き込みます。すべてのタスクが正しく実行されると、INSERT INTO target_table SELECT * FROM intermediate_table_1 UNION ALL SELECT * FROM intermediate_table_2 UNION ALL ...クエリを実行します。ターゲットテーブルが存在しない場合は、自動的に作成されます。 |
| insert_direct | このモードは、ターゲットテーブルに直接行を挿入します。ターゲットテーブルが存在しない場合は、自動的に作成されます。 |
| truncate_insert | insertモードと同じですが、最後のINSERT ...クエリの直前にターゲットテーブルをtruncateします。 |
| replace | このモードは、最初に中間テーブルに行を書き込みます。すべてのタスクが正しく実行されると、ターゲットテーブルを削除し、中間テーブルの名前をターゲットテーブル名に変更します。 |
| merge | このモードは、最初にいくつかの中間テーブルに行を書き込みます。すべてのタスクが正しく実行されると、MERGE INTO ... WHEN MATCHED THEN UPDATE ... WHEN NOT MATCHED THEN INSERT ...クエリを実行します。つまり、中間テーブルのレコードのマージキーがターゲットテーブルに既に存在する場合、ターゲットレコードは中間レコードによって更新され、そうでない場合は中間レコードが挿入されます。ターゲットテーブルが存在しない場合は、自動的に作成されます。 |
Azure SQL Databaseにエクスポート中に「Connection reset」エラーでMS SQL Server Result Outputが失敗する
Azure SQL Databaseはマルチテナントサービスです。リソースの問題により、タイムアウトが発生することがあります。この問題を回避するために、次の回避策を試すことをお勧めします:
- まずAzure Blob Storage Data Result Outputを使用してAzure Blob Storageにダンプし、その後Azure SQL Databaseにエクスポートします。
- 各挿入リクエストのバイトサイズを削減するために、batch_sizeオプションの値を3000程度に減らします。この変更により、ジョブの実行時間が長くなる可能性があることに注意してください。