Microsoft SQL Server Tables Export Integrationについて詳しく見る。
この記事では、Microsoft SQL Server のデータコネクタの使用方法について説明します。このコネクタを使用すると、Microsoft SQL Server から Treasure Data に直接データをインポートできます。
Microsoft SQL Server からデータをインポートする方法のサンプルワークフローについては、Treasure Boxes をご覧ください。
- Treasure Data の基本的な知識
- Microsoft SQL Server の基本的な知識
- リモートで実行されている Microsoft SQL Server インスタンス(例: RDS 上)
• Microsoft SQL Server 2017
• Microsoft SQL Server 2016
• Microsoft SQL Server 2014
• Microsoft SQL Server 2012
• Microsoft SQL Server 2008 R2
• Azure SQL Database
• Azure SQL Data Warehouse または Parallel Data Warehouse
• Azure SQL Managed Instance (Extended Private Preview)
TD Console を使用して接続を設定できます。
データ接続を設定する際は、連携にアクセスするための認証情報を提供します。Treasure Data では、認証を設定してからソース情報を指定します。
Integrations Hub -> Catalog に移動し、Microsoft SQL Server を検索して選択します。

次のダイアログが開きます。
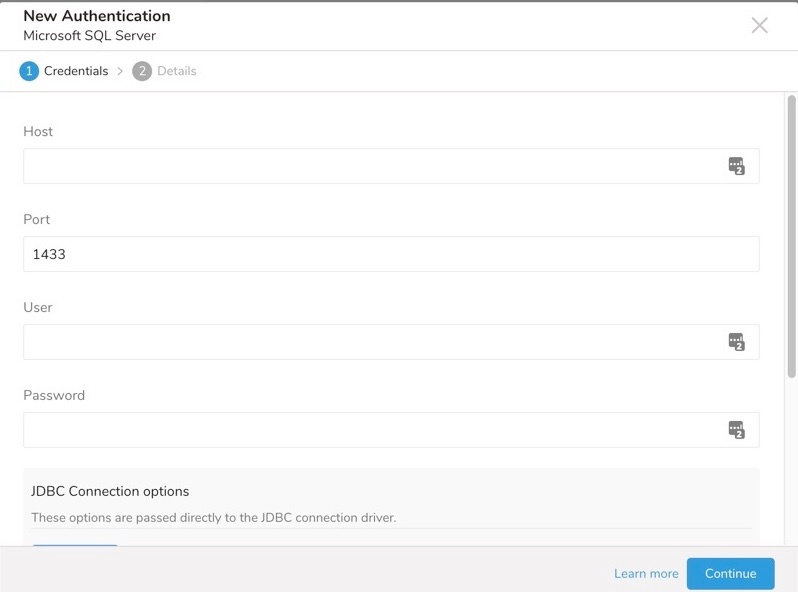
Microsoft SQL Server へのアクセスに必要なホスト名、ポート、ユーザー名、パスワードなどの必要な認証情報を入力します。
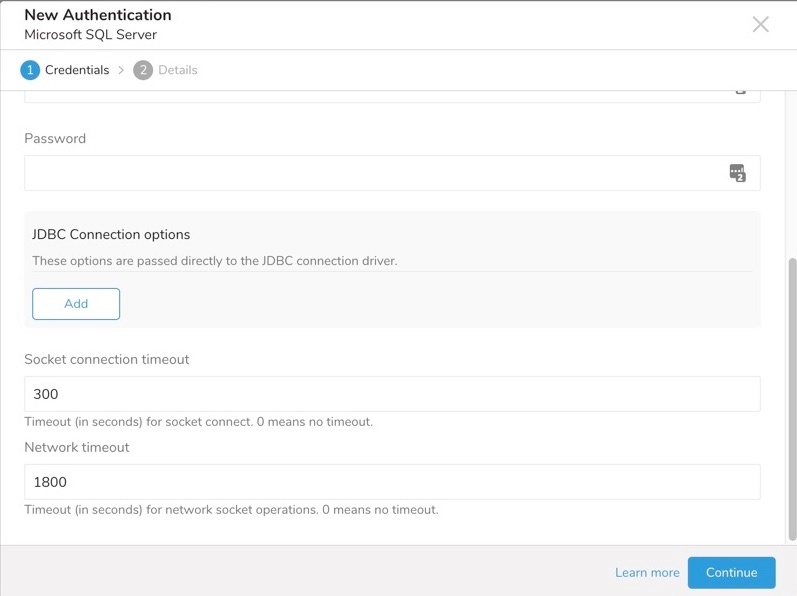
encrypt=true オプションを追加し、証明書が検証できない場合は、証明書検証をバイパスするために trustServerCertificate=true オプションを追加する必要があります。
Continue を選択します。
新しい Microsoft SQL Server 接続に名前を付けます。New Source を選択します。
認証された接続を作成したので、次にソース接続を作成します。 詳細を入力し、Next を選択します。
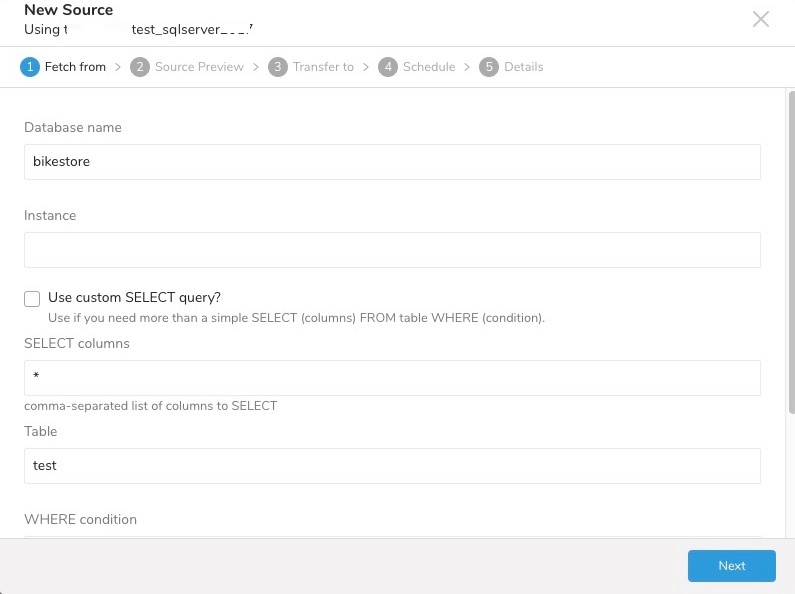
スキーマを指定する場合は、次のように Use custom SELECT query を選択します:
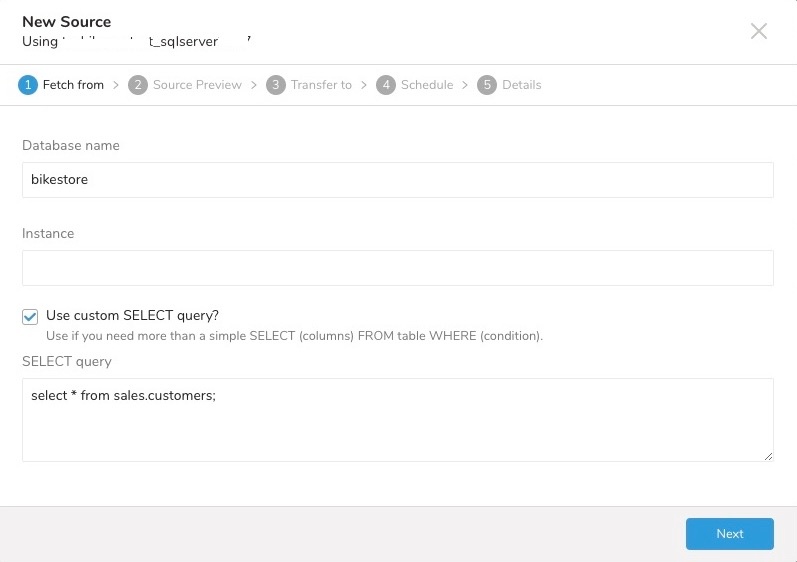
データのプレビューが表示されます。変更を行う場合は Advanced Settings を選択し、そうでない場合は Next を選択します。
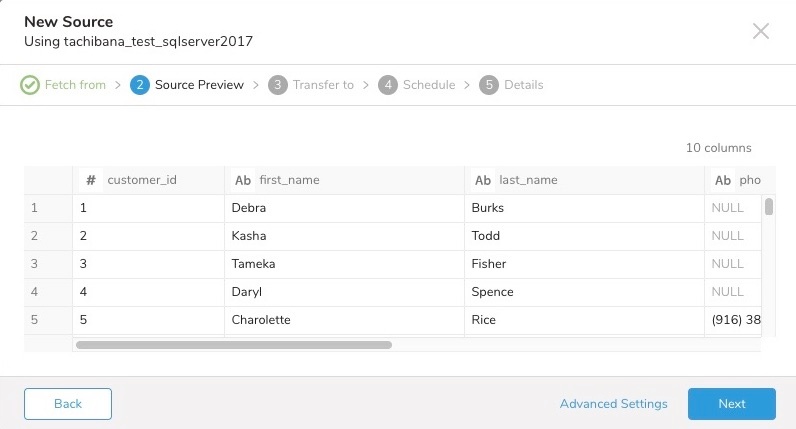
ターゲットデータベースとテーブルを選択する
データを転送する既存のデータベースとテーブルを選択するか、新しく作成します:
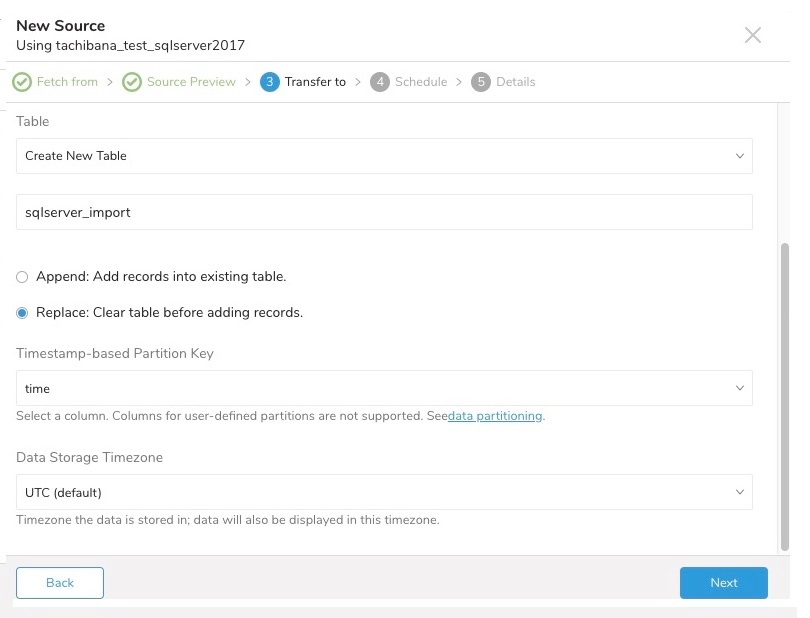
新しいデータベースを作成し、データベースに名前を付けます。Create new table についても同様の手順を実行します。
既存のテーブルにレコードを**追加(append)するか、既存のテーブルを置換(replace)**するかを選択します。
デフォルトのキーではなく、別のパーティションキーシードを設定する場合は、指定できます。
Schedule タブでは、1回限りの転送を指定するか、自動的に繰り返される転送をスケジュールできます。Once now を選択した場合は、Start Transfer を選択します。Repeat… を選択した場合は、スケジュールオプションを指定してから Schedule Transfer を選択します。
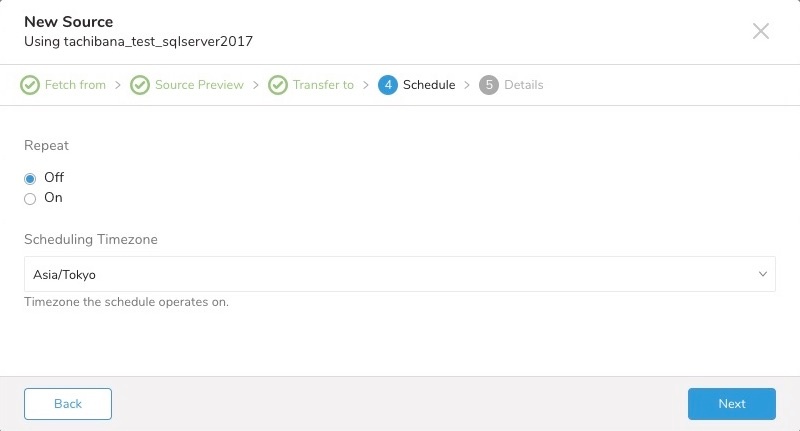
ソースコネクタに名前を付けます。コネクタを保存するか、Create & Run を選択できます。
CLI を使用して接続を設定できます。
最新の TD Toolbelt をインストールします。
Microsoft SQL Server のアクセス情報を含む seed.yml を準備します:
in:
type: sqlserver
host: sqlserver_host_name
port: 1433
user: test_user
password: test_password
database: test_database
table: test_table
out:
mode: replaceこの例では、テーブル内のすべてのレコードをダンプします。追加パラメータを使用して、より詳細な制御を行うことができます。
利用可能な out モードの詳細については、以下の付録を参照してください。
次に connector:guess を使用します。このコマンドは、ターゲットデータを自動的に読み取り、データ形式をインテリジェントに推測します。
$ td connector:guess seed.yml -o load.ymlload.yml を開くと、ファイル形式、エンコーディング、カラム名、型などを含む、推測されたファイル形式定義が表示されます。
td connector:previewコマンドを使用して、インポートされるデータをプレビューできます。
$ td connector:preview load.yml
+---------+--------------+----------------------------------+------------+---------------------------+
| id:long | name:string | description:string | price:long | created_at:timestamp |
+---------+--------------+----------------------------------+------------+---------------------------+
| 1 | "item name1" | "26e3c3625366591bc2ffc6e262976e" | 2419 | "2014-02-16 13:01:06 UTC" |
| 2 | "item name2" | "3e9dd9474dacb78afd607f9e0a3366" | 1298 | "2014-05-24 13:59:26 UTC" |
| 3 | "item name3" | "9b6c9e4a140284d3951681e9e047f6" | 9084 | "2014-06-21 00:18:21 UTC" |
| 4 | "item name4" | "a11faf5e63c1b02a3d4c2b5cbb7331" | 669 | "2014-05-02 03:44:08 UTC" |
| 6 | "item name6" | "6aa15471c373ddc8a6469e1c918f98" | 3556 | "2014-03-29 08:30:23 UTC" |
+---------+--------------+----------------------------------+------------+---------------------------+最後に、ロードジョブを送信します。ジョブはデータサイズに応じて実行に数時間かかる場合があります。ユーザーはデータが保存されるデータベースとテーブルを指定する必要があります。
Treasure Dataのストレージは時間でパーティション化されているため、--time-columnオプションを指定することをお勧めします。このオプションが指定されていない場合、Data Connectorは最初のlong型またはtimestamp型のカラムをパーティション化時間として選択します。--time-columnで指定するカラムの型は、long型またはtimestamp型のいずれかである必要があります。
データに時間カラムがない場合は、add_timeフィルターオプションを使用して追加できます。詳細はadd_timeフィルタープラグインを参照してください。
$ td connector:issue load.yml --database td_sample_db --table td_sample_table上記のコマンドは、*database(td_sample_db)とtable(td_sample_table)*がすでに作成されていることを前提としています。TDにデータベースまたはテーブルが存在しない場合、このコマンドは成功しないため、データベースとテーブルを手動で作成するか、td connector:issueコマンドで--auto-create-tableオプションを使用してデータベースとテーブルを自動作成してください。
$ td connector:issue load.yml --database td_sample_db --table td_sample_table --time-column created_at --auto-create-table"--time-column"オプションで、時間フォーマットカラムを"パーティショニングキー"に割り当てることができます。
テーブル内のカラムを指定することで、incremental_columnsとlast_recordオプションを利用してレコードを増分的にロードできます。
in:
type: sqlserver
host: sqlserver_host_name
port: 1433
user: test_user
password: test_password
database: test_database
table: test_table
incremental: true
incremental_columns: [id, sub_id]
last_record: [10000, 300]
out:
mode: append
exec: {}その後、プラグインは自動的にクエリを再作成し、内部で値をソートします。
# when last_record wasn't given
SELECT * FROM(
...original query is here
)
ORDER BY id, sub_id
::: terminal
# when last_record was given
SELECT * FROM(
...original query is here
)
WHERE id > 10000 OR (id = 10000 AND sub_id > 300)
ORDER BY id, sub_idスケジュール実行と併用する場合、プラグインは自動的にlast_recordを生成し、内部で保持します。次回のスケジュール実行時にそれを使用できます。
in:
type: sqlserver
...
out:
...
Config Diff
---
in:
last_record:
- 20000
- 400incremental: trueを設定した場合、queryオプションは使用できません。 incremental_columnsとしてサポートされるのは、文字列と整数のみです。
| --- |
定期的なMicrosoft SQL Serverインポートのために、定期的なData Connector実行をスケジュールできます。高可用性を確保するために、スケジューラーを慎重に設定しています。この機能を使用することで、ローカルデータセンターでcronデーモンを実行する必要がなくなります。
td connector:createコマンドを使用して、新しいスケジュールを作成できます。スケジュールの名前、cron形式のスケジュール、データが保存されるデータベースとテーブル、およびData Connector設定ファイルが必要です。
$ td connector:create \
daily_sqlserver_import \
"10 0 * * *" \
td_sample_db \
td_sample_table \
load.ymlcronパラメータは、@hourly、@daily、@monthlyの3つのオプションも受け入れます。 | デフォルトでは、スケジュールはUTCタイムゾーンで設定されます。-tまたは--timezoneオプションを使用して、タイムゾーンでスケジュールを設定できます。--timezoneオプションは、'Asia/Tokyo'、'America/Los_Angeles'などの拡張タイムゾーン形式のみをサポートします。PST、CSTなどのタイムゾーンの略語は*サポートされておらず*、予期しないスケジュールになる可能性があります。
load.ymlのoutセクションでファイルインポートモードを指定できます。
これはデフォルトモードで、レコードはターゲットテーブルに追加されます。
in:
...
out:
mode: appendこのモードは、ターゲットテーブルのデータを置き換えます。ターゲットテーブルに対して行われた手動のスキーマ変更は、このモードで維持されます。
in:
...
out:
mode: replace