Teradata統合により、Teradata ServerからTreasure Dataへのデータのインポートが可能になります。
- Treasure Dataの基本的な知識
- Teradata SQLの基本的な知識
- 実行中のTeradataインスタンス
- Integrations Hub > Catalogに移動します。
- Teradataを検索して選択します。

ダイアログが開きます。
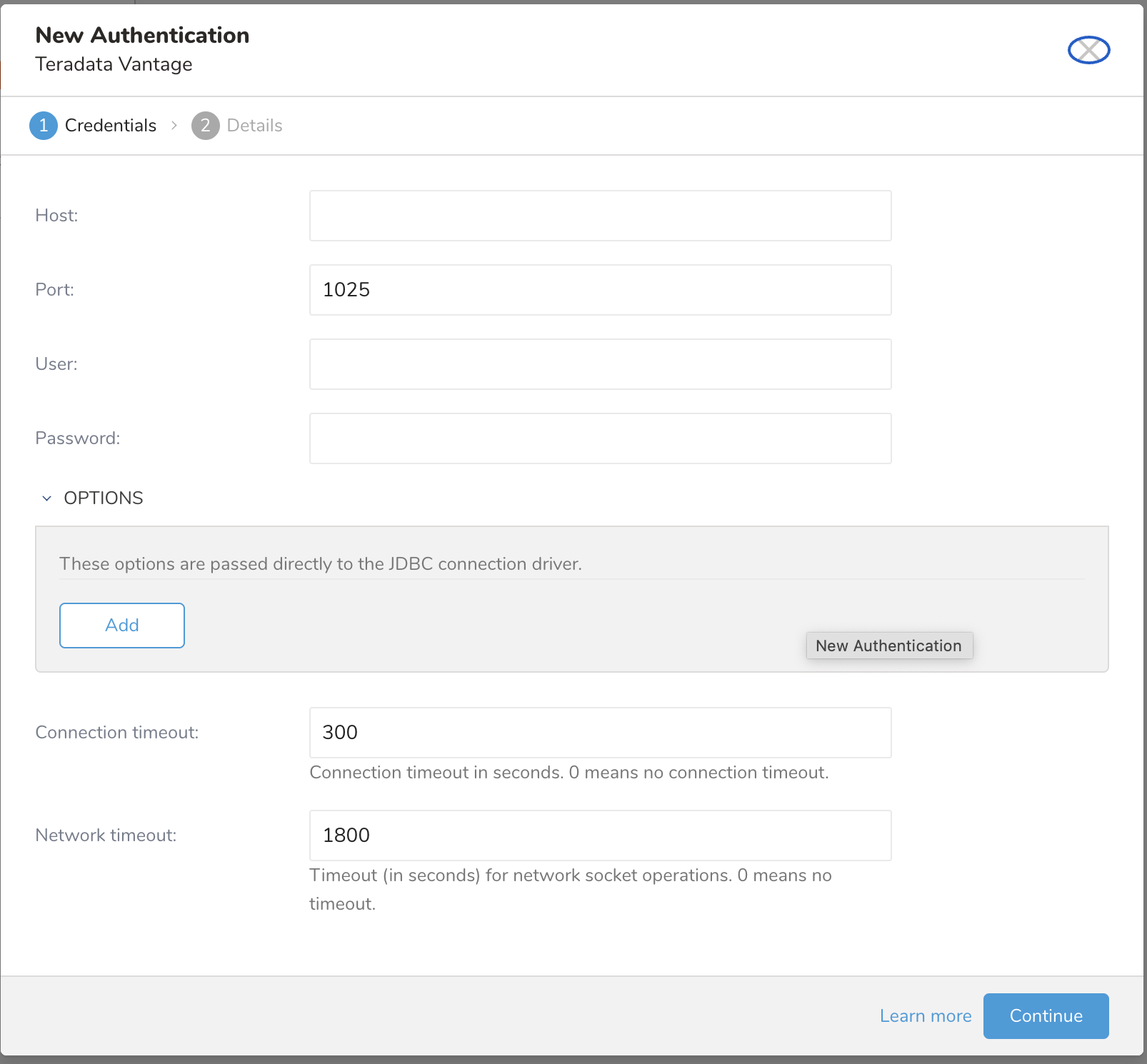
設定を入力します。
Parameters Description Host Teradataデータベースのホスト情報、例:IPアドレス。 Port インスタンスの接続ポート。Teradataのデフォルトは1025です。 Username Teradataデータベースに接続するためのユーザー名。 Password Teradataデータベースに接続するためのパスワード。 OPTIONS JDBC Connection options Teradataデータベースが必要とする特別なJDBC接続。次のJDBCオプションは無視されるため追加しないでください: - DBS_PORT(port設定を使用) - DATABASE(database設定を使用) - USER(user設定を使用) - PASSWORD(password設定を使用) - LOGMECH(現在TD2のみサポート) connection timeout ソケット接続のタイムアウト(秒単位)(デフォルトは300)。 Network timeout ネットワークソケット操作のタイムアウト(秒単位)(デフォルトは1800)。0はタイムアウトなしを意味します。 接続の名前を入力し、Doneを選択します。
SQLクエリからデータをロードする場合は、クエリが有効なSELECTステートメントであることを確認してください。複数のステートメントはサポートされていません。
接続を作成すると、自動的にAuthenticationsタブに移動します。作成した接続を探し、Sourceを選択します。
インポートのソースタイプを選択します。テーブル/ビュー全体をロードする(table/view loading)か、SQLの結果をロードする(query loading)かを選択します。
テーブル/ビュー全体をロードする場合は、「Table/View」を選択し、ロードする「Table/View name」を入力します。
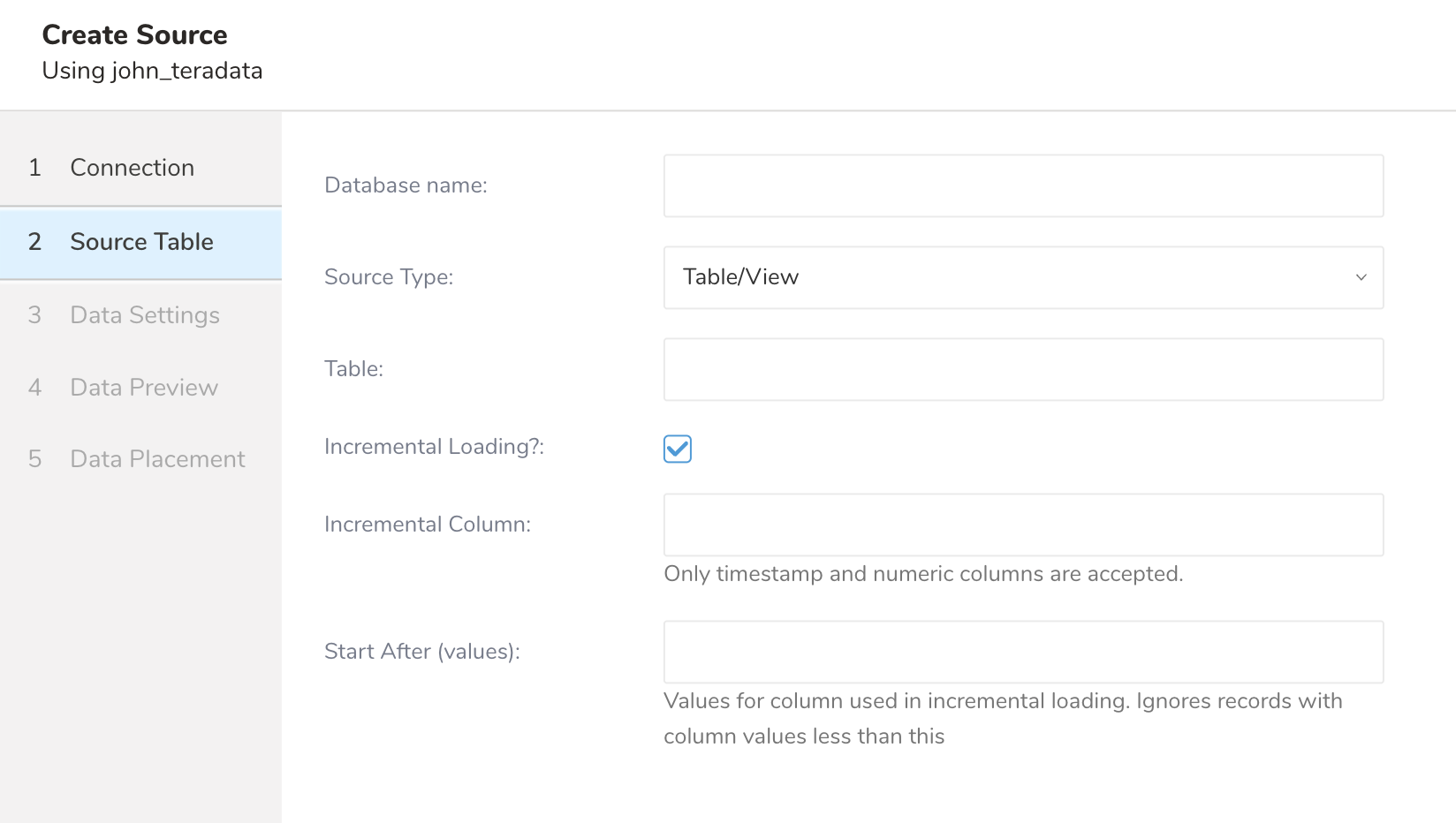
SQLの結果をロードする場合は、「Query statement」を選択し、「SQL statement」にSQLクエリを入力します。
転送を作成する前に、クエリが有効なSELECTクエリであり、単一のステートメントであることを確認してください。QueryとIncrementalからデータを取得する場合、クエリステートメントはORDER BY句を除外する必要があります
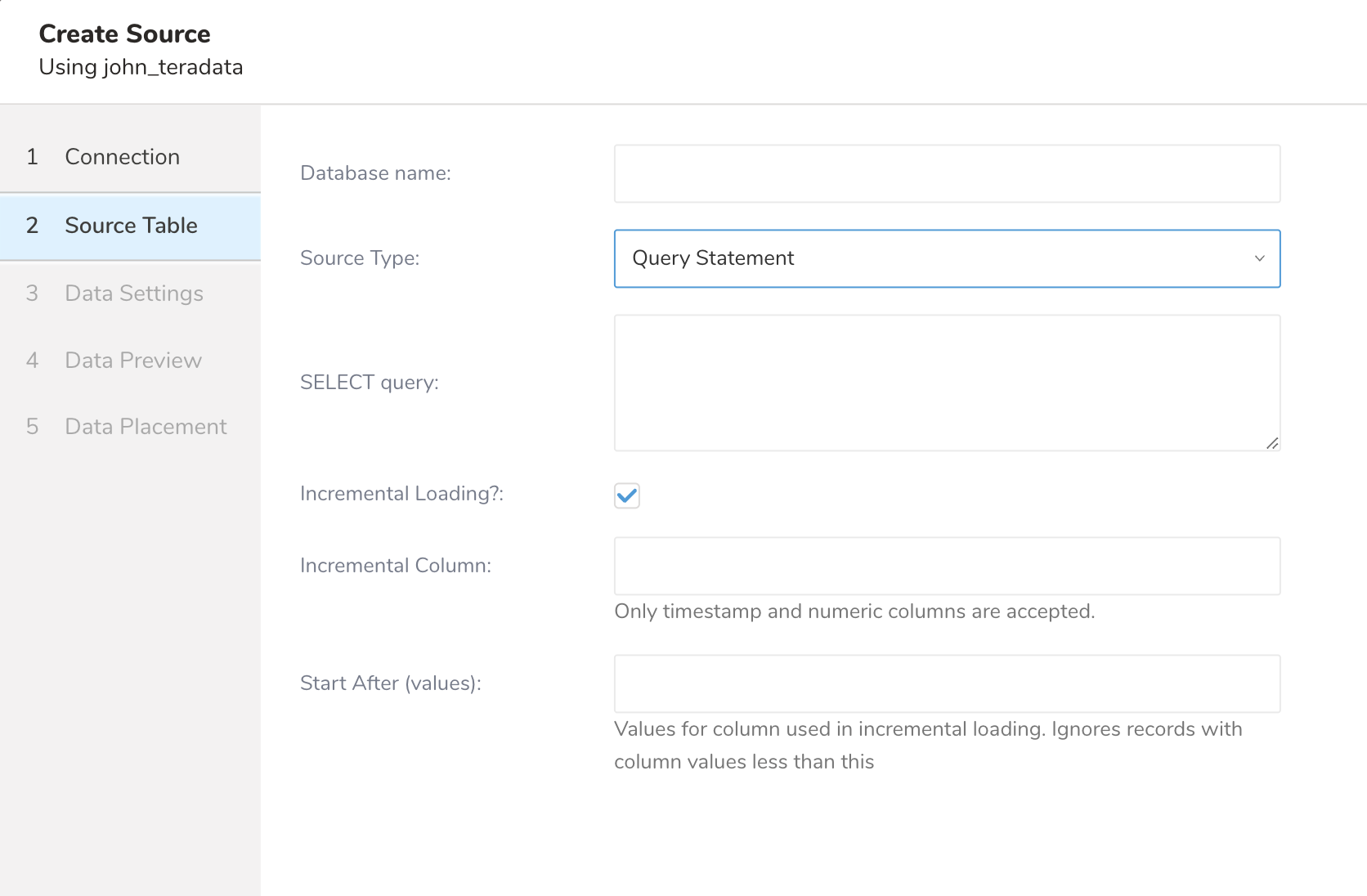
Incremental Loadingは、自動増分IDカラムやタイムスタンプカラムなど、増加する一意のカラムを使用して、前回の実行後の新しいレコードのみをロードできます。
これを有効にするには、Incremental Loadingをチェックし、「Incremental Column Name」に増分するカラム名を指定します。
インクリメンタルカラムとしてサポートされているのは、INTEGERまたはBIGINT型とTIMESTAMP型のみです。
この値からインクリメンタルローディングを開始する場合は、Start Afterを入力します。インクリメンタルカラムがTimestamp型の場合、入力はyyyy-MM-dd'T'HH:mm:ss.SSSSSS形式のTimestamp文字列である必要があり、値はUTCタイムゾーンとして扱われます。
このコネクタは、インクリメンタルカラムで順序付けられた最新のレコードである「last record」を記録します。次の実行では、last recordを使用して次のルールで構築されたクエリを実行してレコードをロードします:
テーブルローディングでは、すべてのフィールドがWHERE句で選択されます。
SELECT * FROM `${dataset}.${table}` WHERE ${incremental_column} > ${value_of_last_record}クエリローディングでは、生のクエリがWHERE句でラップされます。
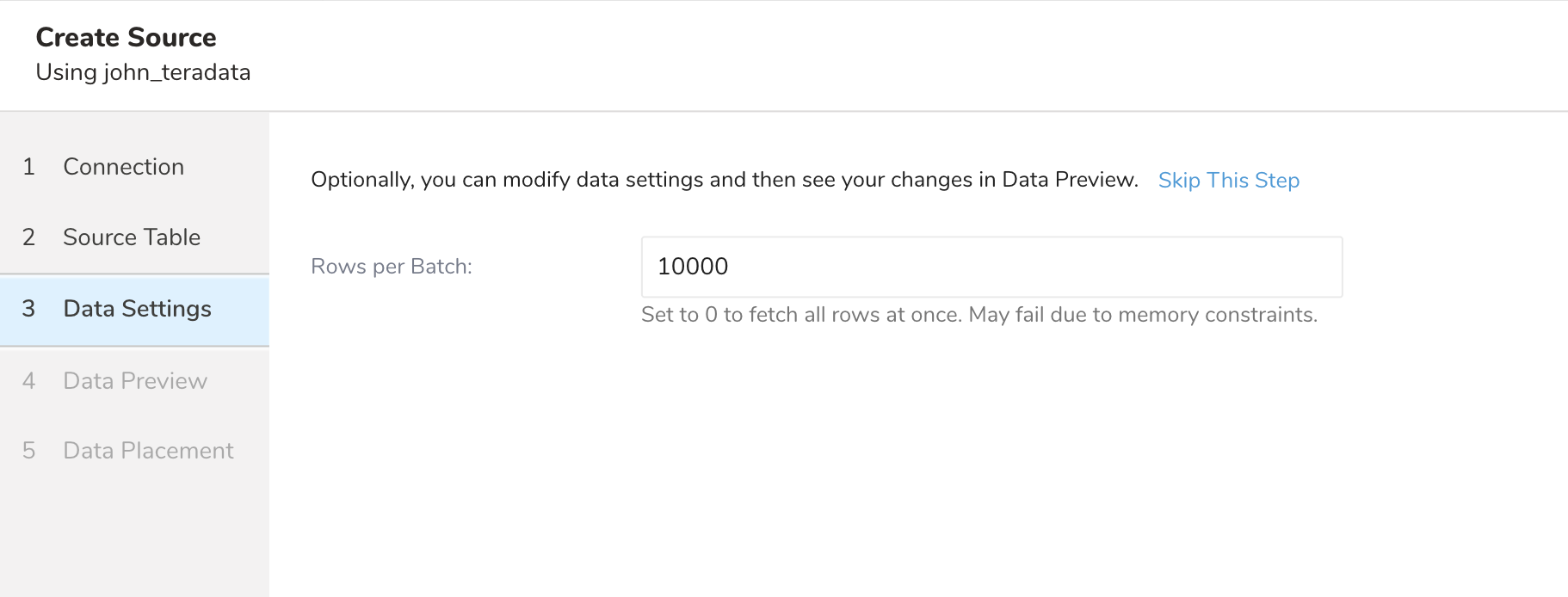
SELECT * FROM (${query}) embulk_incremental_ WHERE ${incremental_column} > ${value_of_last_record}- Nextを選択します。Data Settingsページが開きます。
- 必要に応じてデータ設定を編集するか、このページをスキップします。
| Parameters | Description |
|---|---|
| Rows per batch | 非常に大きなデータセットはメモリの問題を引き起こし、その結果ジョブが失敗する可能性があります。このフラグを使用して、インポートジョブを行数でバッチに分割し、メモリの問題やジョブの失敗の可能性を減らします。無制限の場合は0に設定します。それ以外の場合、値は0より大きい必要があります |
データソースを設定した後、Nextを選択し、次にNextをクリックしてGenerate Previewをクリックすると、ソースからのサンプル結果が表示されます。
プレビューからNextを選択すると、データを転送するTreasure Dataのデータベースとテーブルを選択するように求められます。新しいデータベースを作成する場合は、Create new databaseを選択してデータベースに名前を付けます。Create new tableでも同様の手順を実行します。
既存のテーブルにレコードを追加するか、既存のテーブルを置き換えるかを選択します。
デフォルトのキーとは異なるパーティションキーシードを設定する場合は、「Partition key seed」から選択できます。
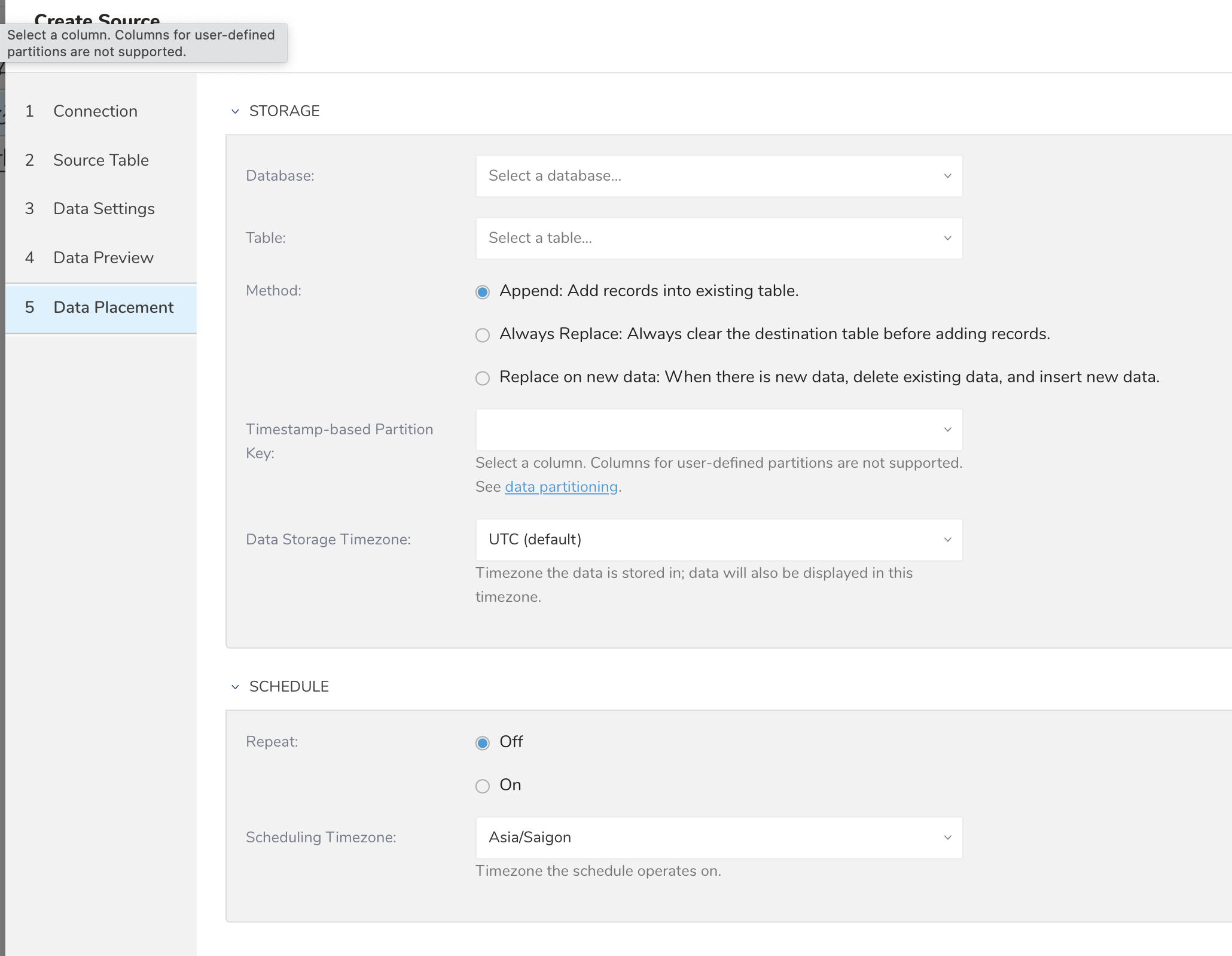
SCHEDULEセクションでは、インポートジョブを1回限りの転送として指定するか、自動化された定期的な転送をスケジュールできます。
転送が実行された後、Databasesタブで転送の結果を確認できます。
Teradataのデータ型は、次の表に示すように、対応するTreasure Dataの型に自動的に変換されます。テーブル/ビューまたはクエリ結果のスキーマにサポートされていない型を含めると、エラーが発生します。
| Teradata Data Type | TD Data Type |
|---|---|
| BYTEINT | Long |
| SMALLINT | Long |
| INTEGER | Long |
| BIGINT | Long |
| FLOAT | Double |
| DECIMAL | String |
| CHAR | String |
| VARCHAR | String |
| BYTE | Unsupport |
| VARBYTE | Unsupport |
| DATE | String |
| TIME | String |
| TIMESTAMP | Timestamp |
| CLOB | String |
| BLOB | Unsupport |
| Structured UDT | String |
| INTERVAL | String |
| JSON | String |
| XML | String |
| PERIOD | String |
| GEO | String |
Teradata Serverのクォータと制限。
必要に応じて、TD Toolbeltを介してコネクタを使用できます。
CLIでTD Toolbeltをセットアップします。
ここでは「config.yml」と呼ばれる設定YAMLファイルを作成します。
例:bigintegerデータ型のインクリメンタルカラムとlast_recordを設定したテーブルからのインポート
in:
type: teradata
host: xxx
options: {"xxx": "xxx"}
connect_timeout:300
socket_timeout:1800
user: xxx
port: 1025
password: xxxx
database: xxxxx
source_type: table_view
table: xxxx
fetch_rows: 10000
incremental: true
incremental_column: big_int_column
last_record: 100例:timestampデータ型のインクリメンタルカラムとlast_recordを設定したQueryからのインポート
in:
type: teradata
host: xxx
options: {"xxx": "xxx"}
connect_timeout:300
socket_timeout:1800
user: xxx
port: 1025
password: xxxx
database: xxxxx
source_type: query
query: |
SELECT * FROM tbl; fetch_rows: 10000 incremental: true incremental_column: created_at last_record: '2025-08-26T12:10:42.010000'| Name | Description | Type | Value | Default Value | Required |
|---|---|---|---|---|---|
| type | コネクタタイプ | string | teradata | N/A | Yes |
| host | Teradataサーバーホスト | string | N/A | N/A | Yes |
| port | Teradataサーバーポート | number | N/A | 1025 | |
| options | Teradata JDBCオプション | string (ハッシュオブジェクト形式) | N/A | N/A | No |
| connect_timeout | Teradataログオンタイムアウト | number | N/A | 300 | No |
| socket_timeout | ネットワークソケット操作のタイムアウト | number | N/A | 1800 | No |
| database | Teradataデータベース | string | N/A | N/A | Yes |
| source_type | ソースインポート | string | サポート値: - table_view - query | table | Yes |
| table | テーブル名 | string | N/A | N/A | source_typeがtable_viewの場合は必須 |
| query | SQLステートメント | string | N/A | N/A | source_typeがqueryの場合は必須 |
| incremental | インクリメンタルローディングを有効にするかどうか | boolean | true/false | false | No |
| incremental_column | インクリメンタルローディング用のカラム名 INTEGER、BIGINTまたはTIMESTAMPデータ型のみサポート | string | N/A | N/A | incrementalがtrueの場合は必須 |
| last_record | この値からインクリメンタルインポートを開始します。カラムインクリメンタルがtimestampデータ型の場合、この値はyyyy-MM-dd'T'HH:mm:ss.SSSSSS形式に従う必要があり、UTCタイムゾーンとして扱われます | string | N/A | N/A | No |
設定ファイルを検証するために、td td connector:previewコマンドを実行します
td connector:preview config.ymltd connector:createを実行します。
次の例では、Teradataコネクタを使用した日次インポートセッションが作成されます。
td connector:create daily_teradata_import \
"10 0 * * *" td_sample_db td_sample_table config.ymlコネクタセッションでは、結果データにデータパーティションキーとして使用される少なくとも1つのタイムスタンプカラムが必要であり、デフォルトでは最初のタイムスタンプカラムがキーとして選択されます。カラムを明示的に指定する場合は、「--time-column」オプションを使用します。
$ td connector:create --time-column created_at \
daily_teradata_import ...結果データにタイムスタンプカラムがない場合は、次のようにフィルタ設定を追加して「time」カラムを追加します。
in:
type: teradata
...
filters:
- type: add_time
from_value:
mode: upload_time
to_column:
name: time
out:
type: td