Salesforce と Treasure Data を連携することで、Salesforce データをより適切に管理し、マーケティングおよびセールスオペレーションスタック内の他のビジネスアプリケーションとの統合を改善できます。Salesforce と Treasure Data の統合により、次のことが簡単になります。
- Salesforce に新しい機能を追加する。 たとえば、Web 使用状況を追跡し、顧客の製品使用量が減少したときにアラートを受信することで、解約を防止できます。
- Salesforce データを使用してマーケティングスタックの他の部分を改善する。 たとえば、Facebook Custom Audiences から新規顧客を自動的に削除することで、Facebook 広告の ROI を向上させることができます。
Salesforce からデータをエクスポートするサンプルワークフローについては、Treasure Boxes を参照してください。
Treasure Data アカウントをまだお持ちでない場合は、お問い合わせください。セットアップのお手伝いをいたします。
フロントエンドアプリケーションは、Log/data collector daemon または Mobile SDKs を介して Treasure Data に収集されるデータをストリーミングします。また、CLI から Bulk Import を使用してデータを一括インポートすることもできます。スケジュール済みクエリが Treasure Data でセットアップされ、データに対して定期的に実行され、各クエリ実行の結果が Salesforce.com Object に書き込まれます。次に示すのは、かなり一般的なアーキテクチャの例です。
すべてのソーシャル/モバイルアプリケーションは、"X の上位 N"(例: 今日視聴された映画のトップ 5)を計算します。Treasure Data はすでに生のデータウェアハウジングを処理しています。"write-to-salesforce.com" 機能により、Treasure Data は "上位 N" データも検索できるようになります。
データサイエンティストの場合、毎時/毎日/毎月のさまざまなメトリクスを追跡し、可視化を通じてアクセス可能にする必要があります。この "write-to-Salesforce.com" 機能を使用すると、プロセスを合理化し、Salesforce.com 組織のレポートとダッシュボードを介してクエリ結果の可視化の構築に集中できます。
- TD Toolbelt を含む Treasure Data の基本的な知識。
- API 統合用の Salesforce.com 組織、ユーザー名、パスワード、およびセキュリティトークン。
- "API Enabled" 権限を持っていること。
- ターゲットの Salesforce.com Object が読み取りおよび書き込み権限付きで存在すること。
SFDC output は、これらの認証タイプをサポートしています。
- 認証情報
- セッション
TD Console を使用して Salesforce に接続するのは、迅速かつ簡単です。または、コマンドラインを使用して Salesforce 接続を作成します。エクスポート統合は認証情報をサポートしています。認証情報を使用して認証するには、クライアント ID とクライアントシークレットが必要です。
これらの手順では、認証情報を使用して認証するために必要なクライアント ID とクライアントシークレットを見つける方法を案内します。
これは Lightning Experience UI のガイドです。
- Setup >Apps > App Manager に移動します。
- New Connected App を選択します。
- いくつかの値を設定し、Enable OAuth Settings をチェックします。次に、OAuth 権限スコープを付与します。
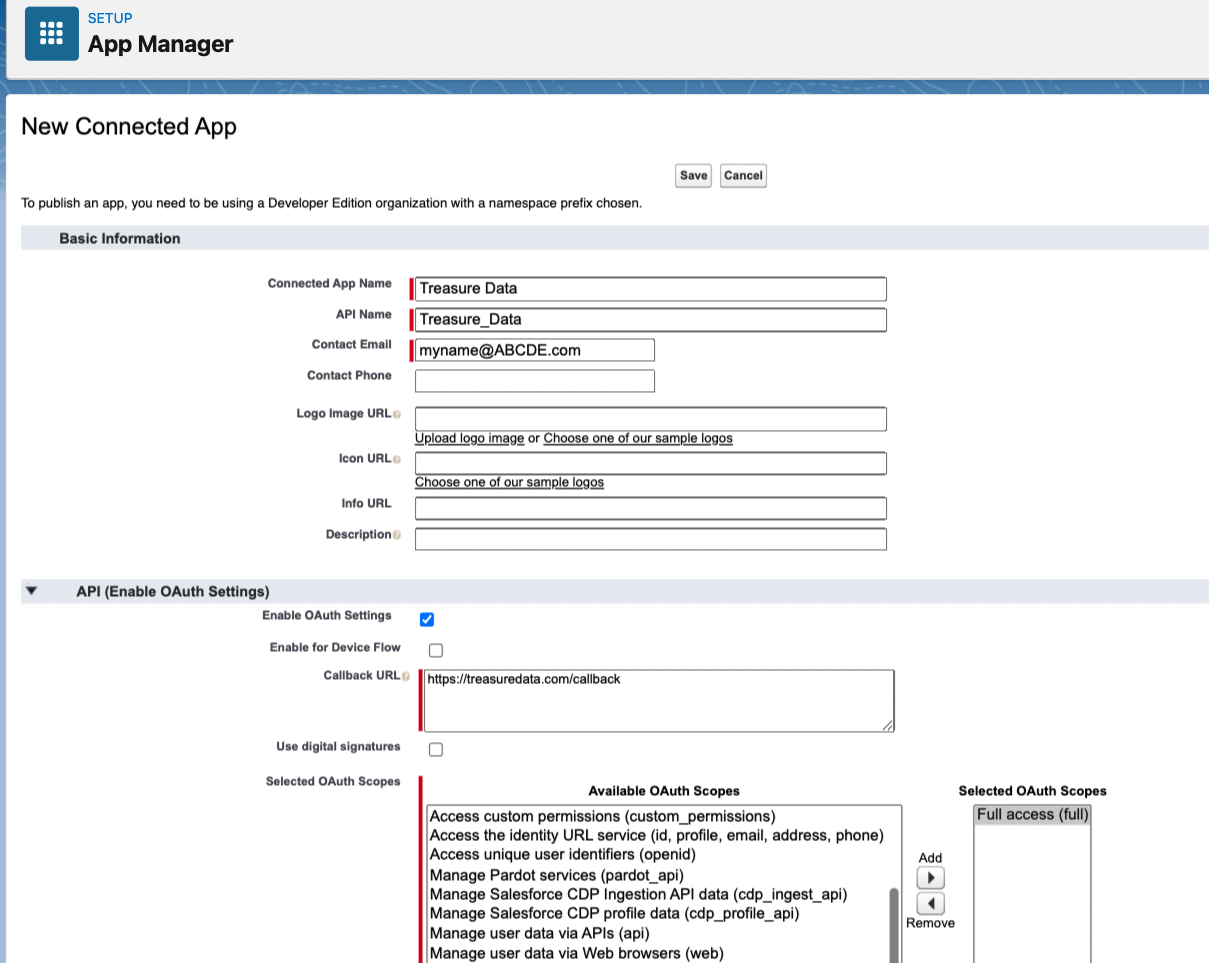 4. Save をクリックします。有効化には最大 10 分かかる場合があります。 5. Setup > Apps > App Manager に移動します。 6. 接続済みアプリを見つけ、▼ をクリックして、View を選択します。
4. Save をクリックします。有効化には最大 10 分かかる場合があります。 5. Setup > Apps > App Manager に移動します。 6. 接続済みアプリを見つけ、▼ をクリックして、View を選択します。
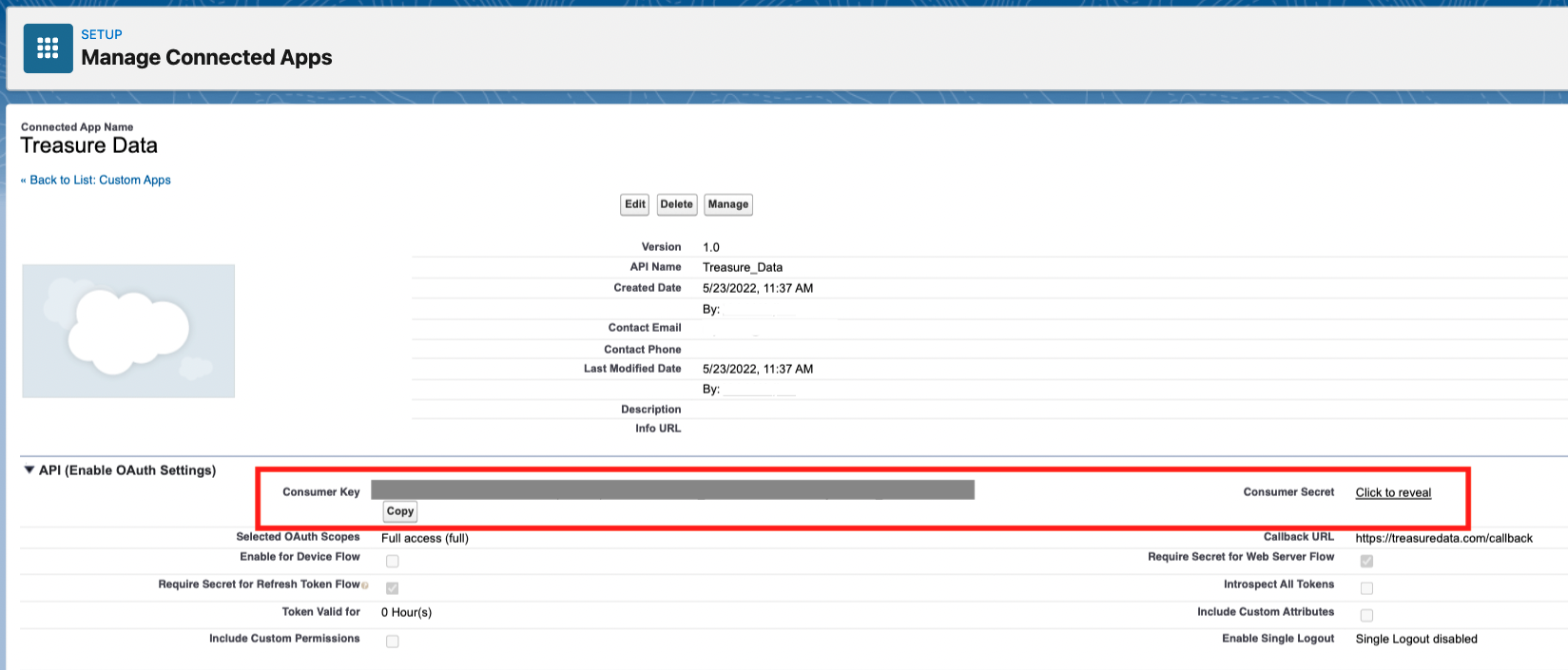
 7. Consumer Key(client_id)と Consumer Secret(client_secret)を書き留めるかコピーします。
7. Consumer Key(client_id)と Consumer Secret(client_secret)を書き留めるかコピーします。
 8. セキュアなアカウントアクセスのために、Salesforce セキュリティトークンを取得します。セキュリティトークンを持っていない場合は、Account > Settings > Reset My Security Token に移動し、Reset Security Token を選択します。セキュリティトークンがメールで送信されます。
8. セキュアなアカウントアクセスのために、Salesforce セキュリティトークンを取得します。セキュリティトークンを持っていない場合は、Account > Settings > Reset My Security Token に移動し、Reset Security Token を選択します。セキュリティトークンがメールで送信されます。
Spring 19 classic UI の場合: My account > My Settings > Personal > Reset My Security Token
- TD Console を開きます。
- Integrations Hub > Catalog に移動します。
- Salesforce を検索します。
 4. 認証情報で認証するには
4. 認証情報で認証するには
- 認証情報で認証するには、ユーザー名(メールアドレス)とパスワード、およびクライアント ID、クライアントシークレット、セキュリティトークンを入力します。
- ダイアログボックスで、ログイン URL として login.salesforce.com を入力します。Login URL パラメータから不要な文字を削除します。
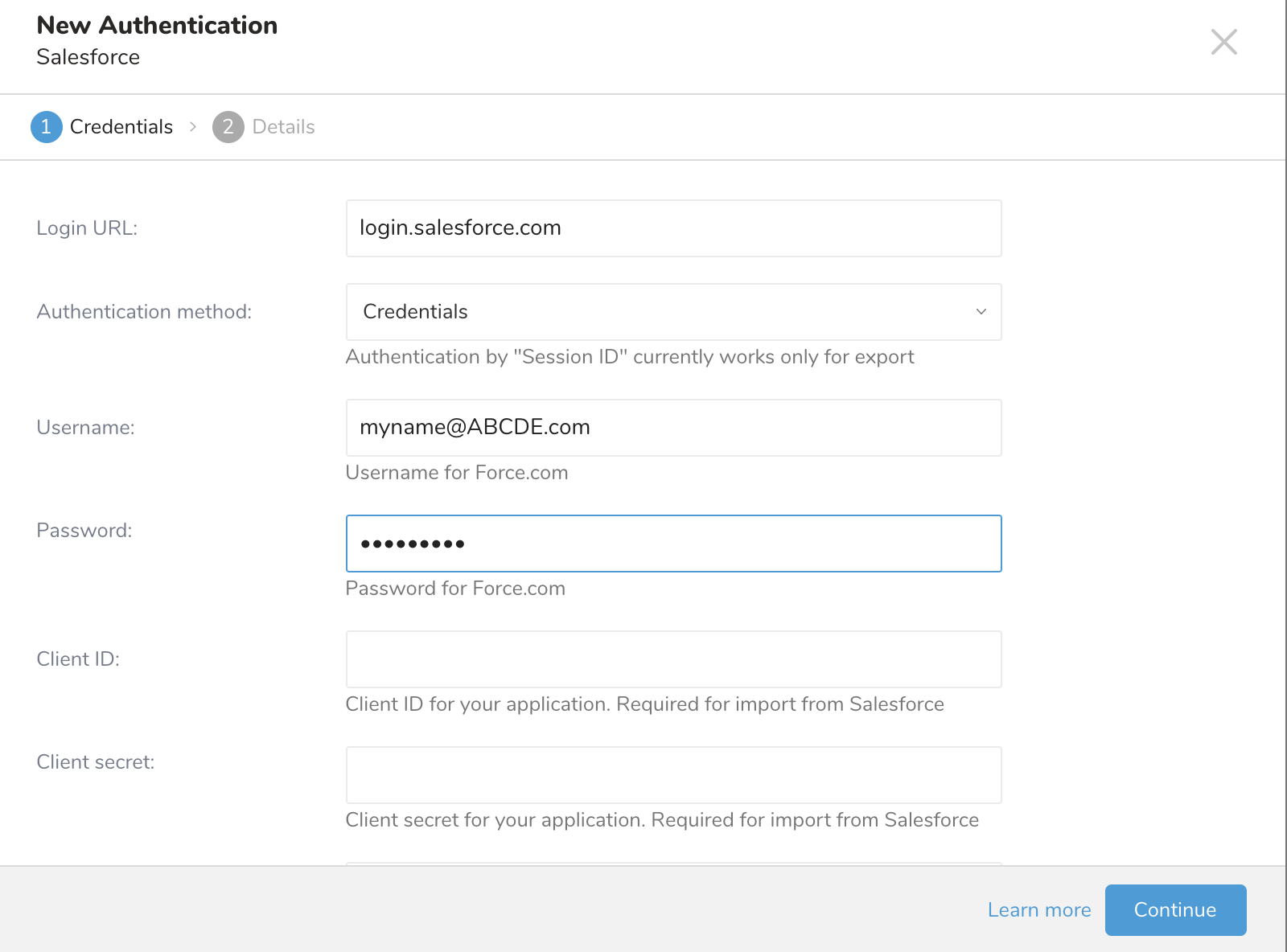
- Continue を選択します。
- 接続にわかりやすい名前を付け、Create Connection を選択します。
ユーザー権限を検証するには、必ず Salesforce を使用して検証してください。
- 権限: Salesforce エクスポート統合接続の手順を確認してください。
- Treasure Data から Salesforce へのアクセスが許可されていること: これを設定するには、TD 静的 IP アドレスを知って設定する必要がある場合があります。静的 IP アドレス情報が必要な場合は、サポートにお問い合わせください。
権限とアクセスが適切に設定されていないと、アクセス制限エラーが発生する可能性があります。例えば:
Response not 2xx:
400 Bad Request {"error":"invalid_grant","error_description":"authentication failure"}クエリを定義する
ポップアップメニューからデータベースとテーブルを選択します。クエリを入力して、Output results を選択します。
結果のエクスポートに問題が発生しないようにするには、クエリの列エイリアスを定義して、クエリから得られる列名がデフォルトフィールドの Salesforce フィールド名、およびカスタムフィールドの API 名(通常は __c で終わる)と一致するようにします。
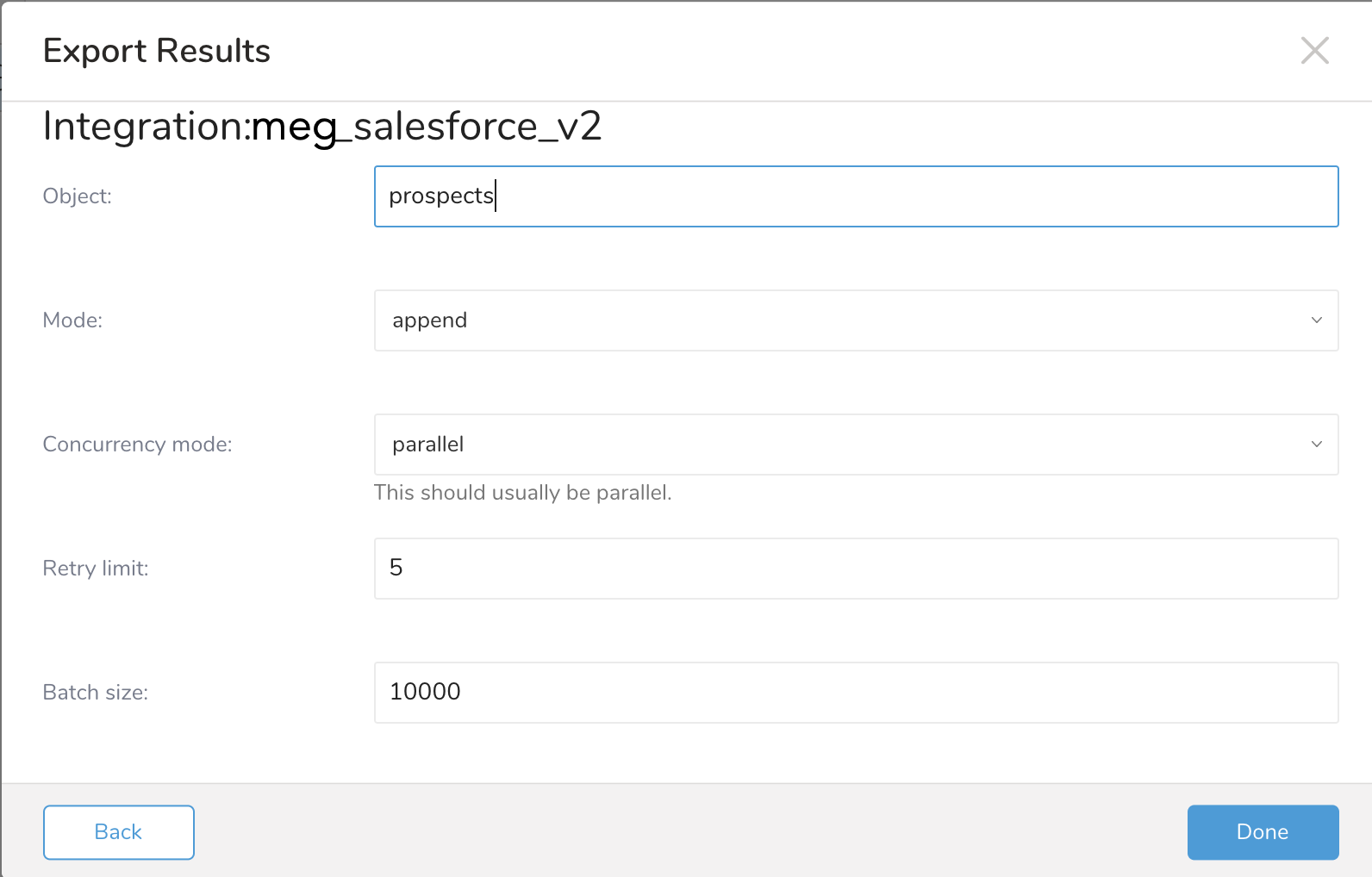
| パラメータ | 説明 |
|---|---|
| Object | Salesforce.com Object |
| Mode | - append モードは、URL にモードオプションが指定されていない場合に使用されるデフォルトです。このモードでは、クエリ結果がオブジェクトに追加されます。 - truncate モードでは、システムは最初に Salesforce.com Object の既存のレコードを切り捨ててゴミ箱に移動し、次にクエリ結果を挿入します。 - update モードでは、"unique" パラメータで指定された外部キー列に重複値が発生しない限り、行が挿入されます。そのような場合、代わりに更新が実行されます。"unique" パラメータはこのモードで必須であり、update モードで使用する場合は外部キーとして定義する必要があります。 |
| Concurrency mode | concurrency_mode オプションは、データが Salesforce.com 組織にアップロードされる方法を制御します。デフォルトモードは parallel です。 parallel メソッドでは、データが並列でアップロードされます。これはほとんどの状況で最も信頼性が高く効果的なメソッドです。 エラーメッセージに "UNABLE_TO_LOCK_ROW" が表示される場合は、代わりに concurrency_mode=serial を試してください。 |
| Retry Limit | このオプションは、エラーが発生した場合に設定された Salesforce.com 宛先に結果を書き込む試行回数を設定します。設定された再試行回数よりも多くエクスポートが失敗した場合、クエリは失敗します。デフォルトの再試行回数は retry=2 です。 |
| Batch size | デフォルトでは、クエリの結果のレコードを 10000 レコードのチャンクに分割し、一度に 1 つのチャンクを一括アップロードします。 |
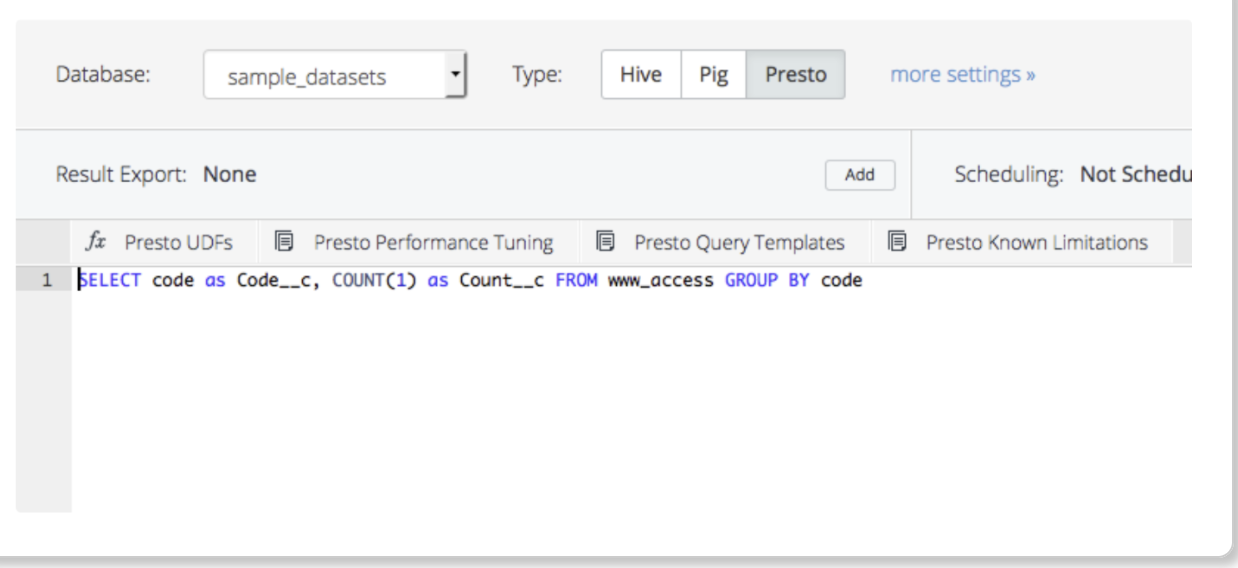
SELECT identifier_type, identifier
FROM table my_tableScheduled Jobs と Result Export を使用して、指定したターゲット宛先に出力結果を定期的に書き込むことができます。
Treasure Data のスケジューラー機能は、高可用性を実現するために定期的なクエリ実行をサポートしています。
2 つの仕様が競合するスケジュール仕様を提供する場合、より頻繁に実行するよう要求する仕様が優先され、もう一方のスケジュール仕様は無視されます。
例えば、cron スケジュールが '0 0 1 * 1' の場合、「月の日」の仕様と「週の曜日」が矛盾します。前者の仕様は毎月 1 日の午前 0 時 (00:00) に実行することを要求し、後者の仕様は毎週月曜日の午前 0 時 (00:00) に実行することを要求するためです。後者の仕様が優先されます。
Data Workbench > Queries に移動します
新しいクエリを作成するか、既存のクエリを選択します。
Schedule の横にある None を選択します。

ドロップダウンで、次のスケジュールオプションのいずれかを選択します:
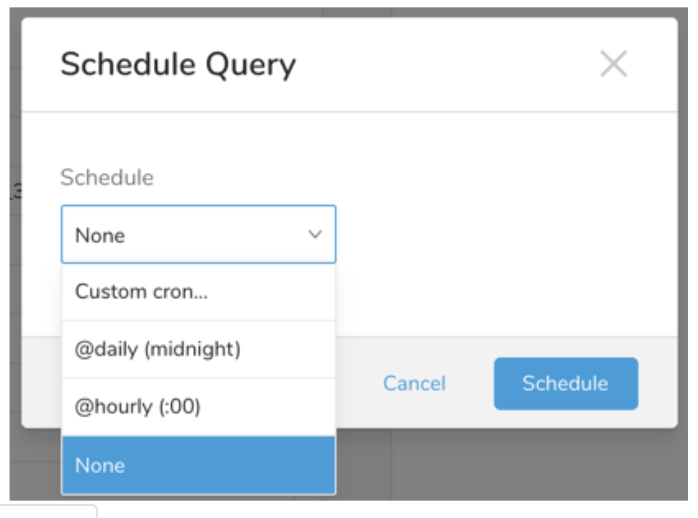
ドロップダウン値 説明 Custom cron... Custom cron... の詳細を参照してください。 @daily (midnight) 指定されたタイムゾーンで 1 日 1 回午前 0 時 (00:00 am) に実行します。 @hourly (:00) 毎時 00 分に実行します。 None スケジュールなし。
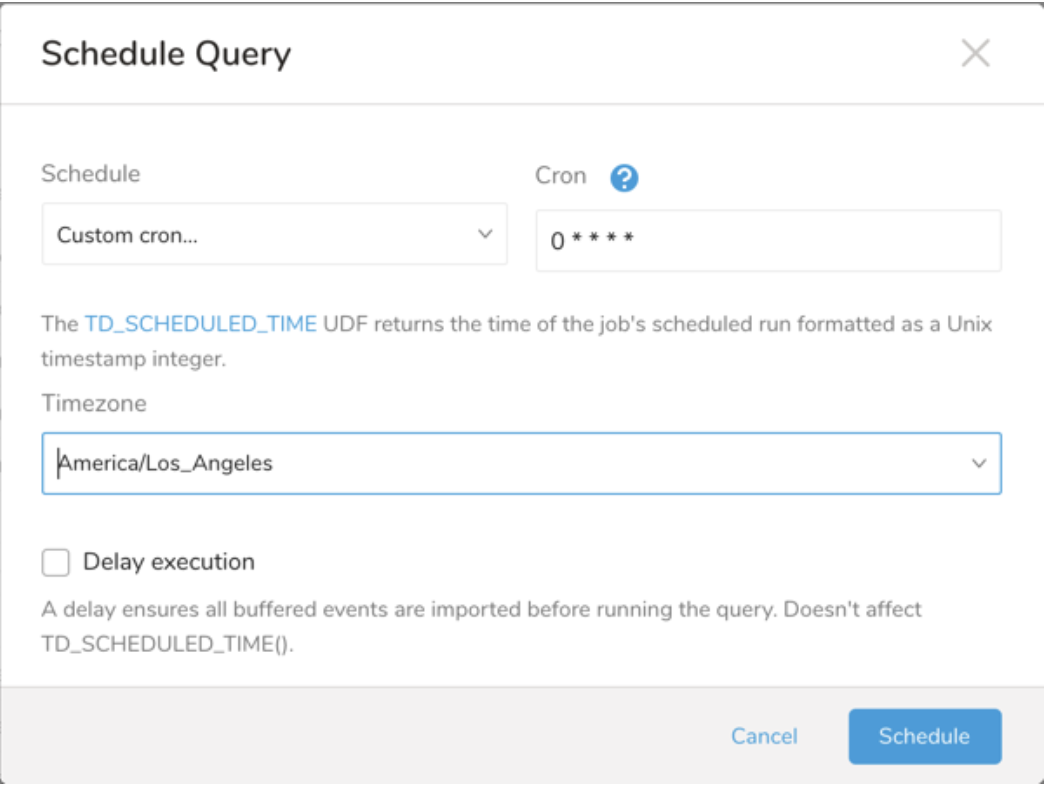
| Cron 値 | 説明 |
|---|---|
0 * * * * | 1 時間に 1 回実行します。 |
0 0 * * * | 1 日 1 回午前 0 時に実行します。 |
0 0 1 * * | 毎月 1 日の午前 0 時に 1 回実行します。 |
| "" | スケジュールされた実行時刻のないジョブを作成します。 |
* * * * *
- - - - -
| | | | |
| | | | +----- day of week (0 - 6) (Sunday=0)
| | | +---------- month (1 - 12)
| | +--------------- day of month (1 - 31)
| +-------------------- hour (0 - 23)
+------------------------- min (0 - 59)次の名前付きエントリを使用できます:
- Day of Week: sun, mon, tue, wed, thu, fri, sat.
- Month: jan, feb, mar, apr, may, jun, jul, aug, sep, oct, nov, dec.
各フィールド間には単一のスペースが必要です。各フィールドの値は、次のもので構成できます:
| フィールド値 | 例 | 例の説明 |
|---|---|---|
| 各フィールドに対して上記で表示された制限内の単一の値。 | ||
フィールドに基づく制限がないことを示すワイルドカード '*'。 | '0 0 1 * *' | 毎月 1 日の午前 0 時 (00:00) に実行するようにスケジュールを設定します。 |
範囲 '2-5' フィールドの許可される値の範囲を示します。 | '0 0 1-10 * *' | 毎月 1 日から 10 日までの午前 0 時 (00:00) に実行するようにスケジュールを設定します。 |
カンマ区切りの値のリスト '2,3,4,5' フィールドの許可される値のリストを示します。 | 0 0 1,11,21 * *' | 毎月 1 日、11 日、21 日の午前 0 時 (00:00) に実行するようにスケジュールを設定します。 |
周期性インジケータ '*/5' フィールドの有効な値の範囲に基づいて、 スケジュールが実行を許可される頻度を表現します。 | '30 */2 1 * *' | 毎月 1 日、00:30 から 2 時間ごとに実行するようにスケジュールを設定します。 '0 0 */5 * *' は、毎月 5 日から 5 日ごとに午前 0 時 (00:00) に実行するようにスケジュールを設定します。 |
'*' ワイルドカードを除く上記の いずれかのカンマ区切りリストもサポートされています '2,*/5,8-10' | '0 0 5,*/10,25 * *' | 毎月 5 日、10 日、20 日、25 日の午前 0 時 (00:00) に実行するようにスケジュールを設定します。 |
- (オプション) Delay execution を有効にすることで、クエリの開始時刻を遅延させることができます。
クエリに名前を付けて保存して実行するか、単にクエリを実行します。クエリが正常に完了すると、クエリ結果は指定された宛先に自動的にエクスポートされます。
設定エラーにより継続的に失敗するスケジュールジョブは、複数回通知された後、システム側で無効化される場合があります。
(オプション) Delay execution を有効にすることで、クエリの開始時刻を遅延させることができます。
Audience Studio で activation を作成することで、segment データをターゲットプラットフォームに送信することもできます。
- Audience Studio に移動します。
- parent segment を選択します。
- ターゲット segment を開き、右クリックして、Create Activation を選択します。
- Details パネルで、Activation 名を入力し、前述の Configuration Parameters のセクションに従って activation を設定します。
- Output Mapping パネルで activation 出力をカスタマイズします。

- Attribute Columns
- Export All Columns を選択すると、変更を加えずにすべての列をエクスポートできます。
- + Add Columns を選択して、エクスポート用の特定の列を追加します。Output Column Name には、Source 列名と同じ名前があらかじめ入力されます。Output Column Name を更新できます。+ Add Columns を選択し続けて、activation 出力用の新しい列を追加します。
- String Builder
- + Add string を選択して、エクスポート用の文字列を作成します。次の値から選択します:
- String: 任意の値を選択します。テキストを使用してカスタム値を作成します。
- Timestamp: エクスポートの日時。
- Segment Id: segment ID 番号。
- Segment Name: segment 名。
- Audience Id: parent segment 番号。
- + Add string を選択して、エクスポート用の文字列を作成します。次の値から選択します:
- Schedule を設定します。

- スケジュールを定義する値を選択し、オプションでメール通知を含めます。
- Create を選択します。
batch journey の activation を作成する必要がある場合は、Creating a Batch Journey Activation を参照してください。
Treasure Workflow 内で、このデータコネクタを使用してデータをエクスポートすることを指定できます。
詳細については、Exporting Data with Parameters を参照してください。
timezone: UTC
+td-result-output-sfdc:
td>: queries/sample.sql
database: sample_datasets
result_connection: your_connection_name
result_settings:
object: object_name
mode: append
concurrency_mode: parallel
retry: 2
split_records: 10000