レガシーSalesforce Legacyデータコネクタから新しいSalesforceコネクタへ移行するには、以下の手順を完了してください。レガシーデータコネクタはREST APIのみを使用してデータをインポートします。新しいSalesforceデータコネクタでは、BulkインポートとREST APIを使用できます。
ある場所やバージョンからデータを移行する際は、そのデータがどのように変換されるかを認識しておく価値があります。以下のセクションでは、注意すべきいくつかの重要な特性について概説します。
50を超えるアセットを取り込むことができます。
| カラム | 旧データ型 | 新データ型 |
|---|---|---|
| createdDate | string | timestamp |
| modifiedDate | string | timestamp |
| カラム | 旧データ型 | 新データ型 |
|---|---|---|
| createdDate | string | ISO 8601 string |
その他の日時値はUTCに変換されます。
取り込みは以下に制限されています:
ルートおよびシステム定義データ
one-to-oneおよびone-to-manyのリレーションシップ
- one-to-oneのリレーションシップは単一のJSONとして保存されます
- one-to-manyのリレーションシップはJSON配列として保存されます
その他の属性は、Treasure Dataのインジェスチョン機能を使用して取り込む必要があります。
Contact属性はルートとシステムに対して収集され、取り込む属性を制限することはできません。
ページあたりのレコード数はデフォルト値の2000を使用します。
取り込みは以下に制限されています:
- 一度に1つのData Extension
| 旧カラム名 | 新カラム名 |
|---|---|
| data-extension-column-name | column-name |
| カラム | 旧データ型 | 新データ型 | データの形式 |
|---|---|---|---|
| any-datetime | string | timestamp | UTC |
Treasure Dataが生成したプロパティには、簡単に識別できるようにアンダースコアのプレフィックス「_」が付いています。
ページあたりのレコード数はデフォルト値の2500を使用します。
取り込みは、イベントに関連付けられたサブスクライバーを除外します。
Treasure Data Catalogに移動し、Salesforce v2を検索して選択します。

ダイアログボックスに、レガシーSalesforceコネクタで入力した値を入力します。
Salesforce v2コネクタでは、Login URLパラメータから不要な文字を削除する必要があります。たとえば、https://login.salesforce.com/?locale=jpの代わりに、https://login.salesforce.com/を使用します。
ユーザー名(メールアドレス)とパスワード、およびClient ID、Client Secret、Security Tokenを入力します。
レガシー設定は、TD ConsoleまたはCLIから保存できます。
- Campaign
- Contact
- Data Extension
- Email Event
- TD Consoleを使用する場合
- CLIとワークフローを使用する場合
- TD Consoleを使用する場合
- CLIを使用する場合
- ワークフローを使用する場合
Integration Hub > Sourcesに移動します。スケジュール設定されたSalesforceソースを検索し、ソースを選択してEditを選択します。
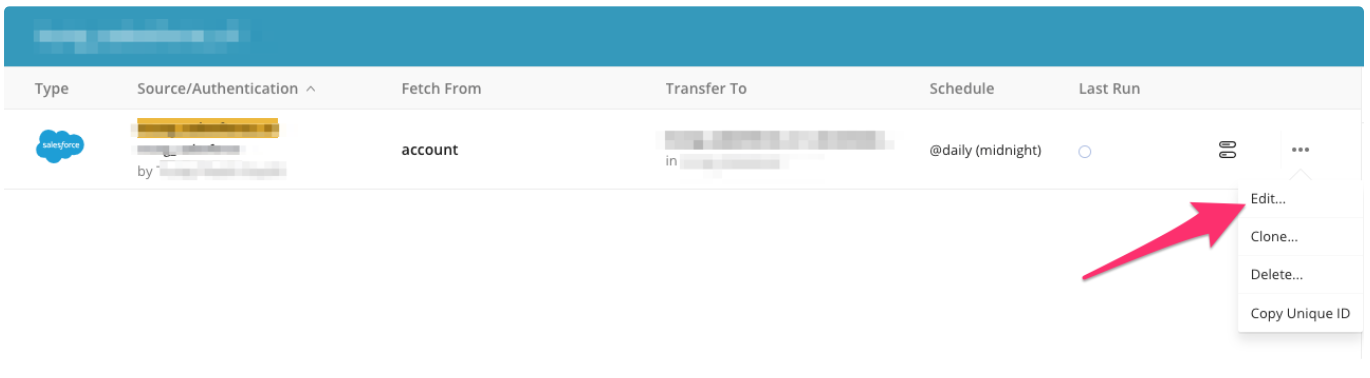
ダイアログボックスで、後で使用するために設定をコピーします:
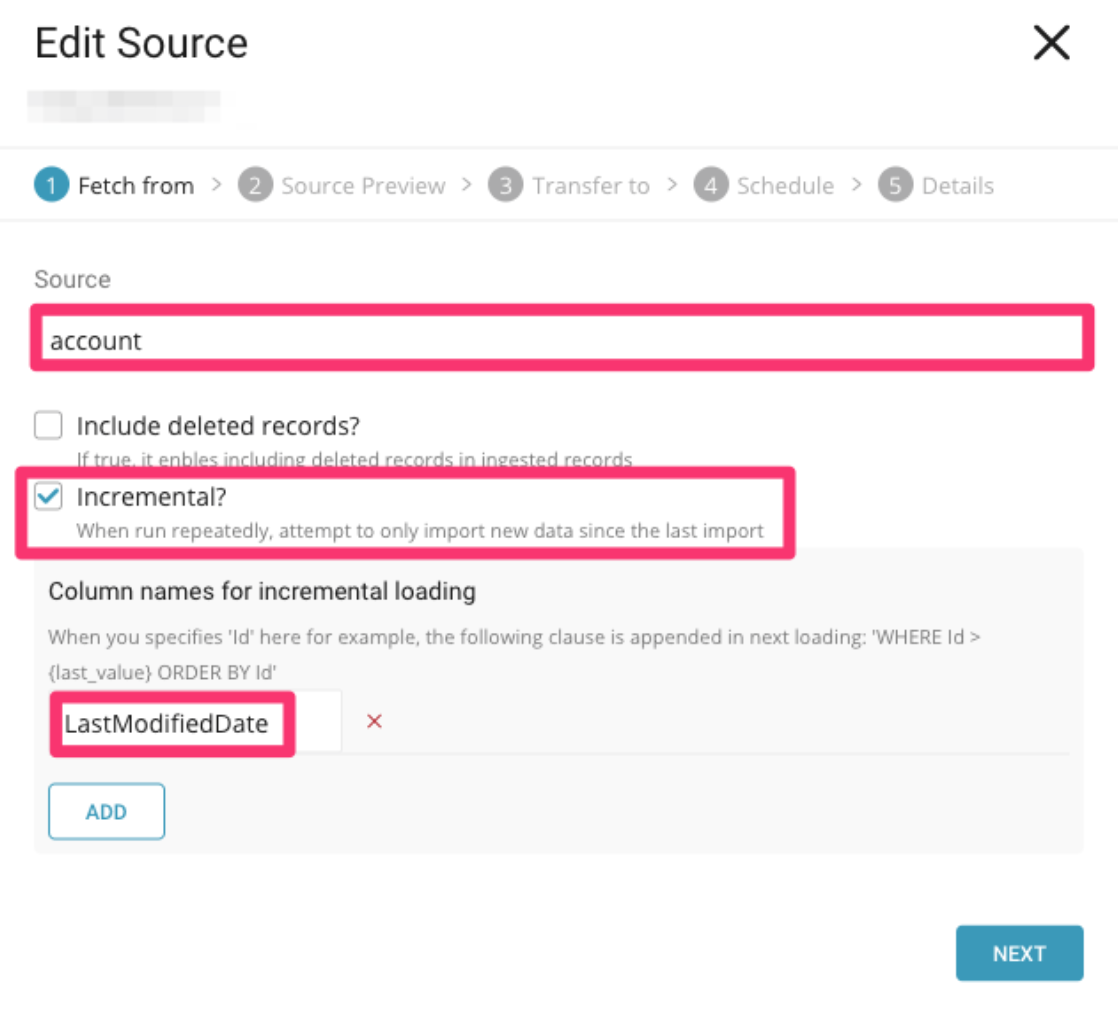
また、詳細設定もコピーします:
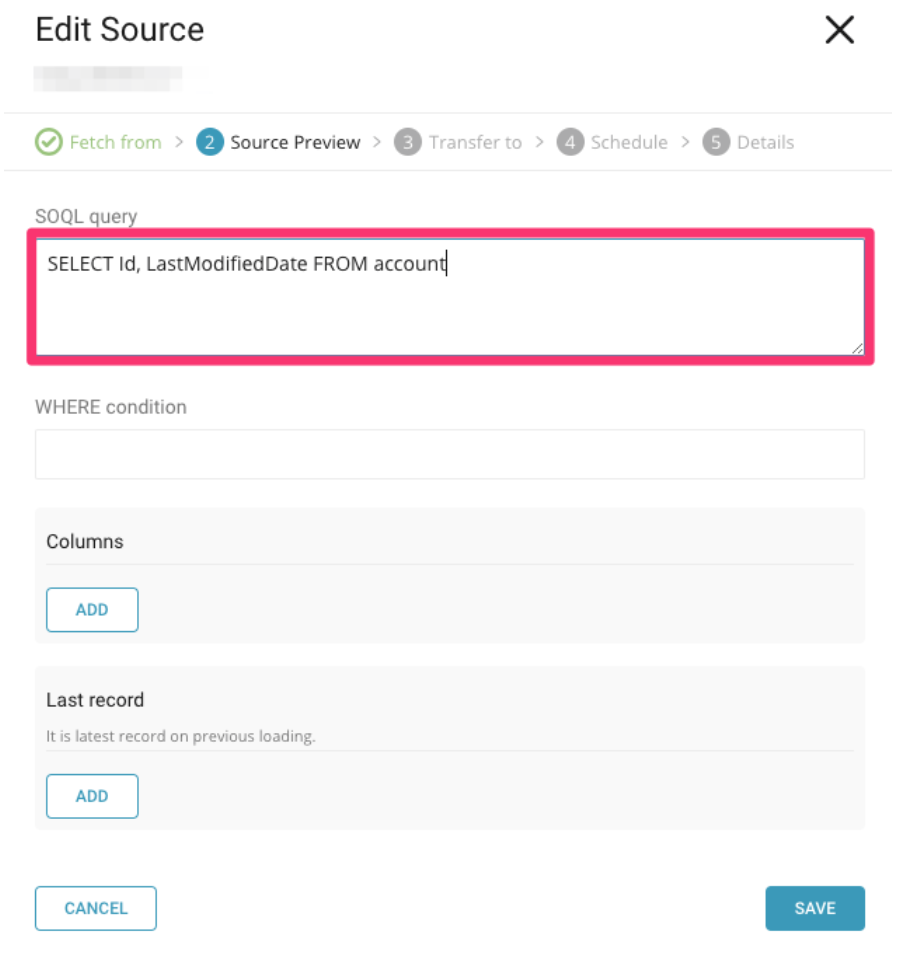
次に、レガシーデータコネクタで最後の実行を設定して、config-diffを実行できる一時テーブルを作成します。diffを使用して、Treasure Dataにインポートされた最新のデータを特定し、確認します。
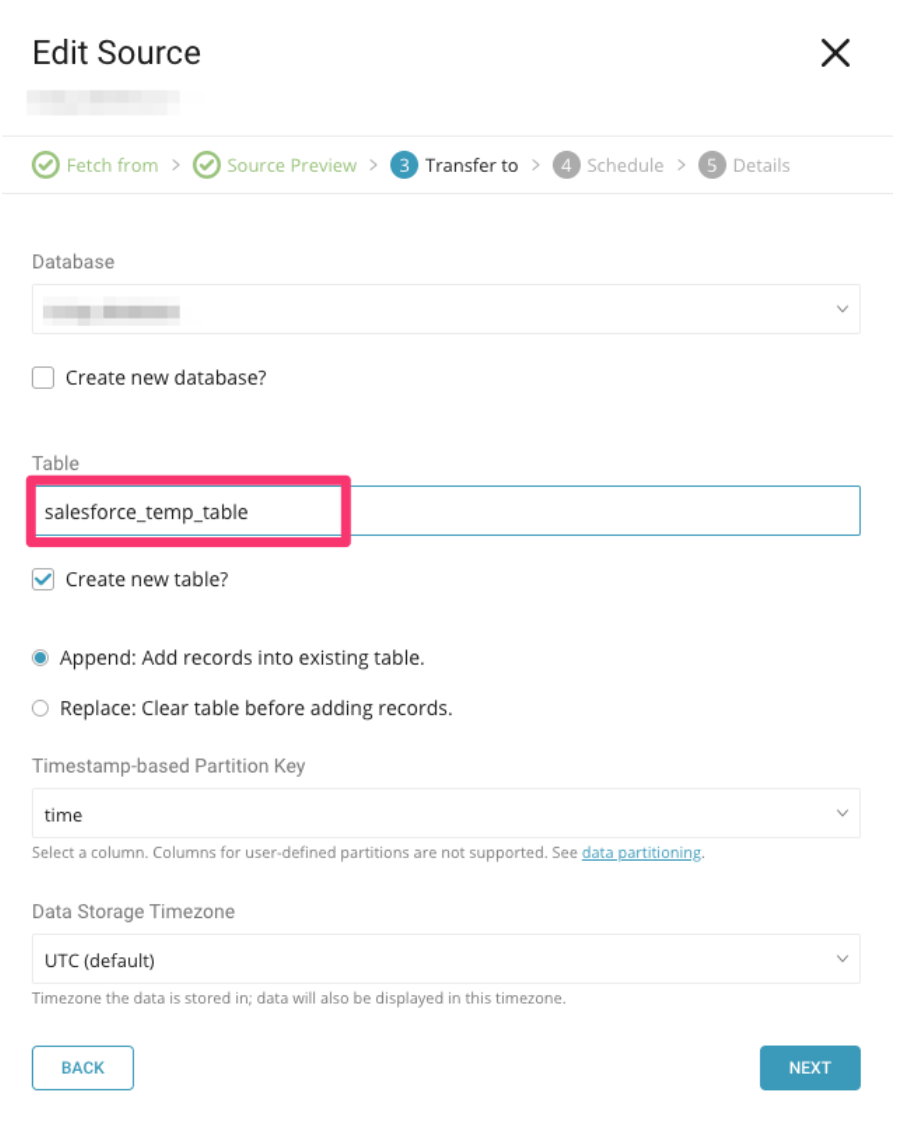
レガシーコネクタで最終インポートを実行する前に、スケジュールを1回のみの実行に変更してください:
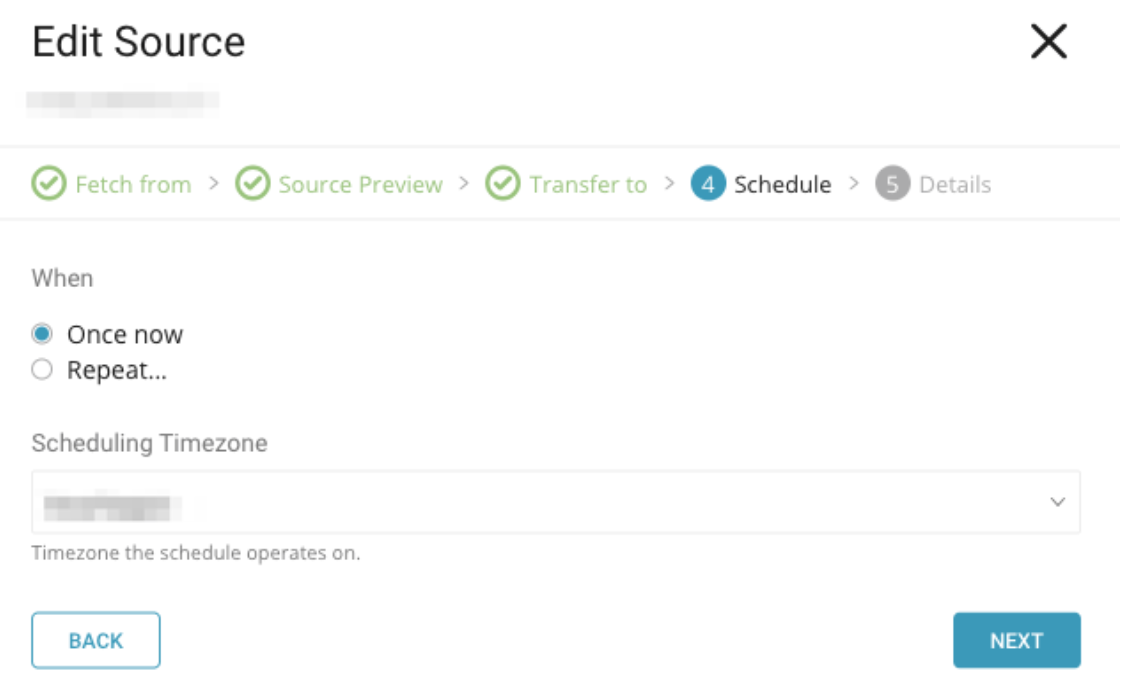
ジョブが完了したら、ジョブクエリ情報のconfig_diffを確認し、後で使用するためにどこかにコピーします。
Integration Hub > Authentication に移動します。作成した新しい Salesforce v2 接続を検索します:

新しいソースを選択します。前のステップでコピーしたすべての基本設定と詳細設定を入力します。次に、新しいソースがレガシーコネクタが中断した地点から取り込みを続行する場合は、前のジョブでコピーした config_diff 情報を Last Record フィールドに入力します。
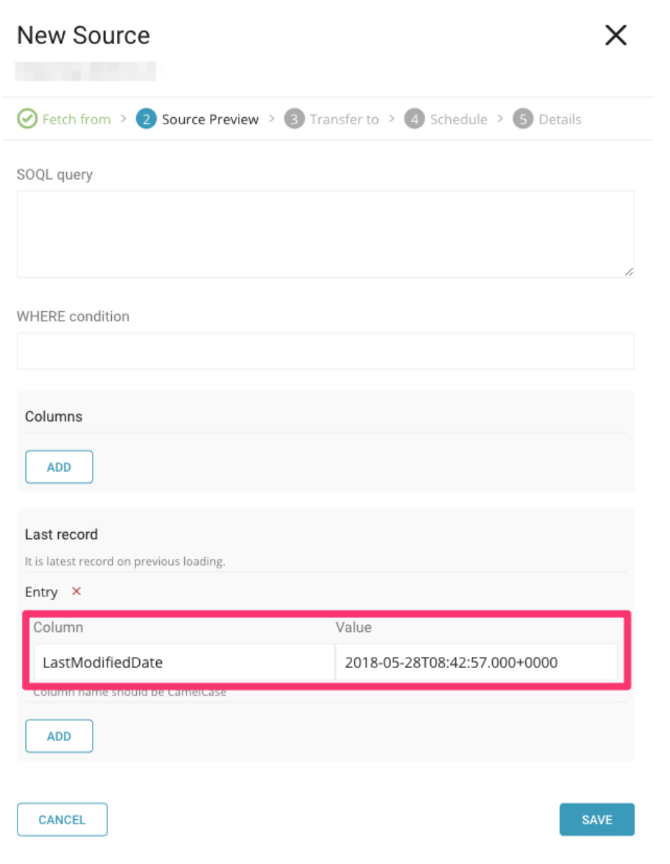
設定を完了したら、データを投入するデータベースとテーブルジョブを選択し、ジョブをスケジュールして、新しいデータコネクタの名前を指定します。Save を選択してから、新しいデータコネクタを実行します。
in: type を sfdc から sfdc_v2 に yml 設定で更新します。
例えば、既存の workflow 設定は次のようになっているかもしれません:
in:
type: sfdc
username: ${secret:sfdc.username}
password: ${secret:sfdc.password}
client_id: ${secret:sfdc.client_id}
client_secret: ${secret:sfdc.client_secret}
security_token: ${secret:sfdc.security_token}
login_url: ${secret:sfdc.login_url}
target: Lead
out: {}
exec: {}
filters: []新しい workflow 設定は次のようになります:
in:
type: sfdc_v2
username: ${secret:sfdc.username}
password: ${secret:sfdc.password}
client_id: ${secret:sfdc.client_id}
client_secret: ${secret:sfdc.client_secret}
security_token: ${secret:sfdc.security_token}
login_url: ${secret:sfdc.login_url}
target: Lead
out: {}
exec: {}
filters: []SFDC 接続はデータコネクタと Result Output で共有されていますが、Result Output には変更はありませんが、いずれかを使用している場合は、こちらもアップグレードする必要があります。
TD Console に移動します。Query Editor に移動します。SFDC を接続に使用している Query を開きます。

SFDC コネクタを選択し、既存の接続の詳細をコピーして保存し、後で使用できるようにします。
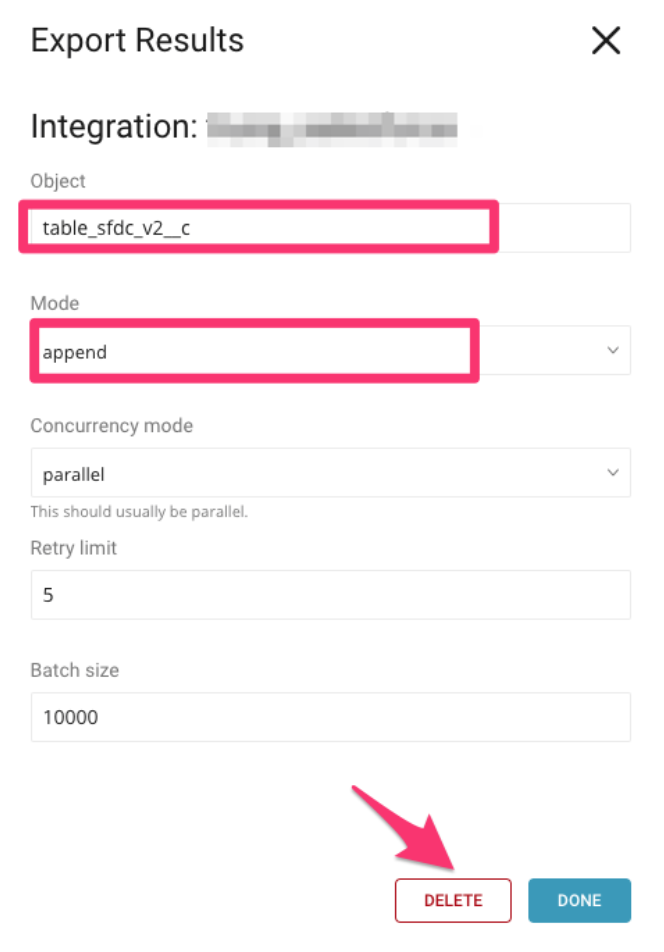
DELETE を選択してレガシーのものを削除します。
Query で Output Results を選択します。次に、作成した SFDC v2 Export コネクタを検索して選択することで、SFDC v2 コネクタをセットアップします。
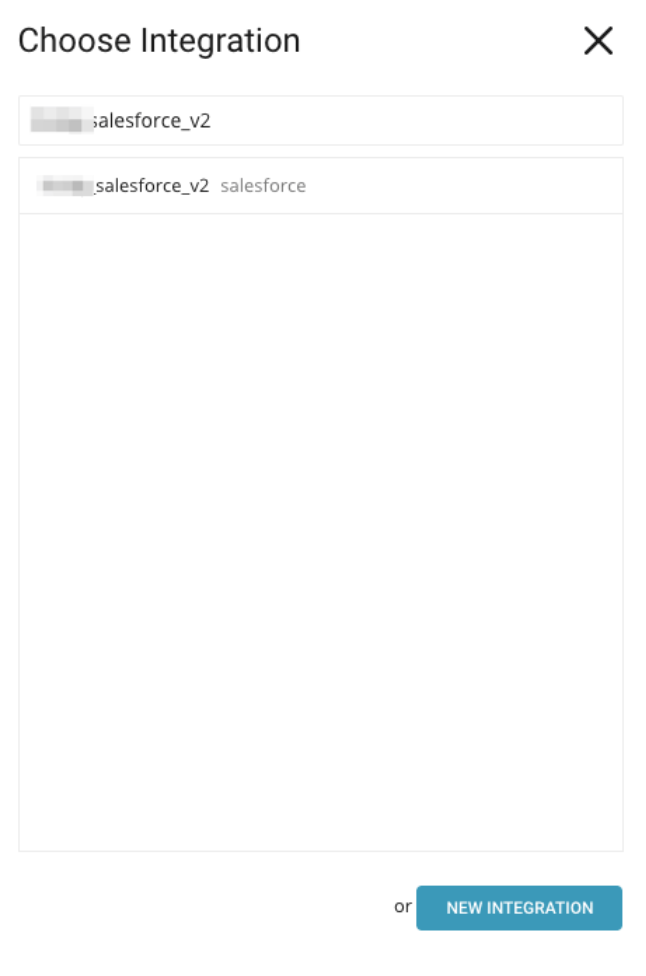
Configuration ペインで、前のステップで保存したフィールドを指定し、Done を選択します。
Output results to... を確認して、作成した Output 接続を使用していることを確認します。Save を選択します。
| 最初のデータエクスポートにテストターゲットを作成して使用し、エクスポートされたデータが期待通りに見えること、および新しいエクスポートが既存のデータを破損しないことを確認することを強くお勧めします。テストケースでは、テストターゲットに別の「Object」を選択してください。 |
Result type プロトコルは sfdc から sfdc_v2 に更新する必要があります。例えば、次のように:
sfdc://username:passwordsecurity_token@hostname/object_nameから:
sfdc_v2://username:passwordsecurity_token@hostname/object_nameSFDC を使用した workflow がある場合、result 設定は同じままにできますが、result_connection を新しい connection_name に更新する必要があります。
古い workflow の result output 設定の例は次のとおりです:
+td-result-output-sfdc:
td>: queries/sample.sql
database: sample_datasets
result_connection: your_old_connection_name
result_settings:
object: object_name
mode: append
concurrency_mode: parallel
retry: 2
split_records: 10000新しい workflow の result output 設定の例は次のとおりです:
+td-result-output-sfdc:
td>: queries/sample.sql
database: sample_datasets
result_connection: your_new_connection_name
result_settings:
object: object_name
mode: append
concurrency_mode: parallel
retry: 2
split_records: 10000