Google Cloud Storage用のData Connectorは、GCSバケットに保存されている*.tsvおよび*.csvファイルの内容のインポートを可能にします。Export Integrationについては、Google Cloud Storage Export Integrationを参照してください。
- Treasure Dataの基本的な知識
- 既存のGoogle Service Account
- Google Developers ConsoleからJSONキーファイルを生成し取得すること。Generating a service account credentialを参照してください。
セキュリティポリシーで IP ホワイトリストが必要な場合は、接続を成功させるために Treasure Data の IP アドレスを許可リストに追加する必要があります。
リージョンごとに整理された静的 IP アドレスの完全なリストは、次のリンクにあります: https://api-docs.treasuredata.com/en/overview/ip-addresses-integrations-result-workers/
データ接続を設定する際、インテグレーションにアクセスするための認証情報を提供します。Treasure Dataでは、認証を設定してからソース情報を指定します。
TD Consoleを開きます。
Integrations Hub > Catalogに移動します。
Google Cloud Storageを検索して選択します。

次のダイアログが開きます。
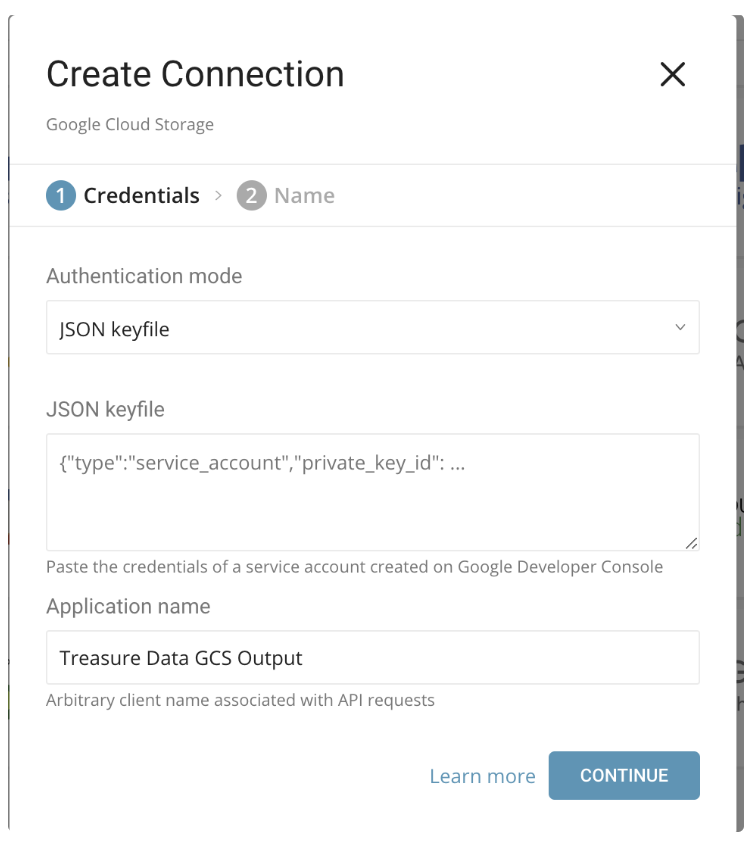
新しいGoogle Cloud Storage Connectorを作成します。
以下のパラメータを設定します:
| パラメータ | 説明 |
|---|---|
| Authentication mode | JSON keyfileを選択します。この方法では、Google Developers Consoleから生成されたJSONキーファイルを使用します。 |
| JSON Keyfile | Google Developers Consoleから生成されたJSONキーファイルの内容をこのフィールドにコピー&ペーストします。 |
| Application Name | Treasure Data GCS Outputがデフォルト値です。これはAPIリクエストに関連付けられる任意のクライアント名であるため、デフォルト値(Treasure Data GCS Output)のままにすることができます。 |
- 接続の名前を入力します。
- Doneを選択します。
認証済み接続を作成すると、自動的にAuthenticationsに移動します。
- 作成した接続を検索します。
- New Sourceを選択します。
- Data TransferフィールドでSourceの名前を入力します。
- Nextをクリックします。
- Nextを選択します。
- Source Tableダイアログが開きます。以下のパラメータを編集します。
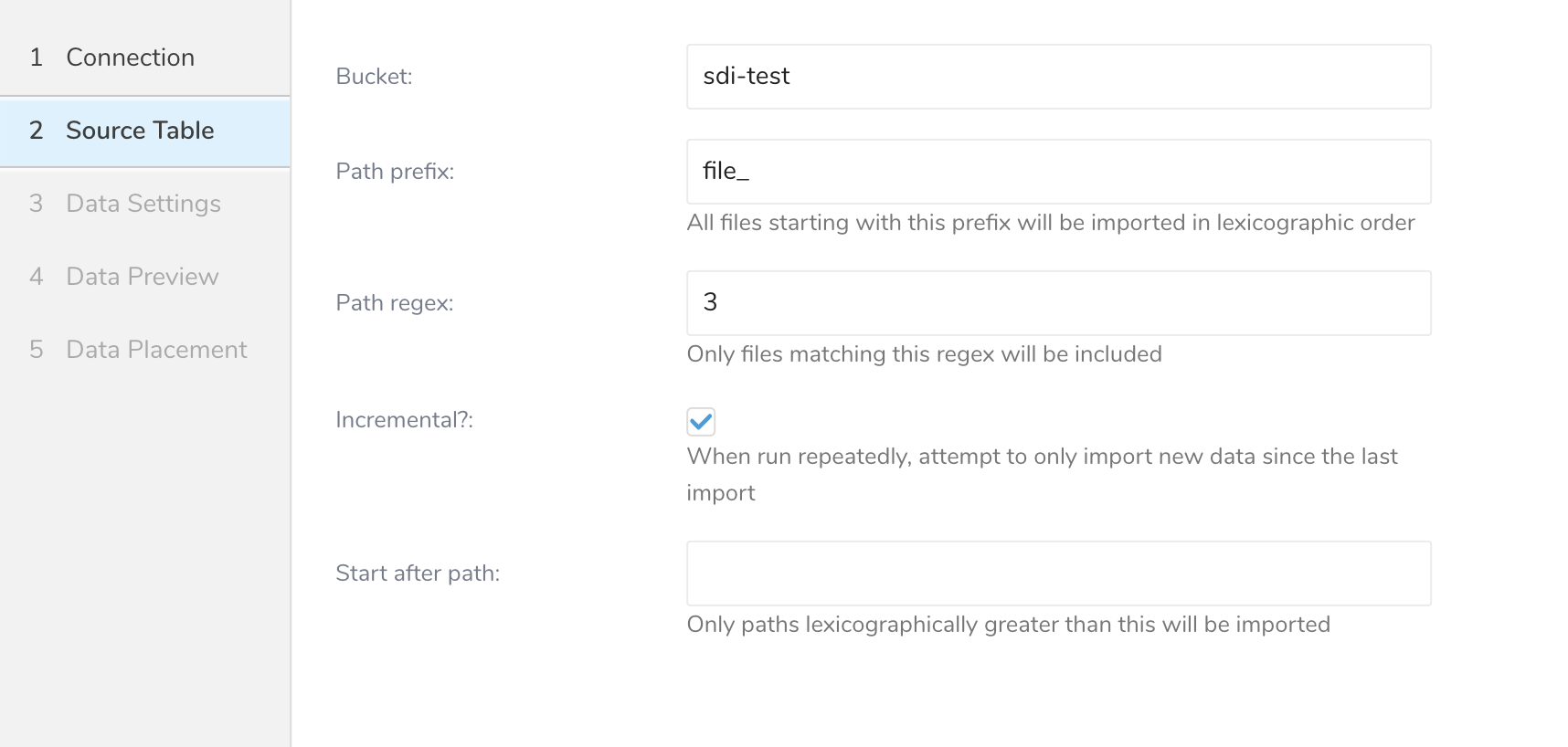
| パラメータ | 説明 |
|---|---|
| Bucket | Google Cloud Storageバケット名(例: your_bucket_name) |
| Path Prefix | ターゲットキーのプレフィックス。(例: logs/data_) |
| Path Regex | ファイルパスに一致させるための正規表現。ファイルパスがこのパターンに一致しない場合、そのファイルはスキップされます。(例: .csv$ # この場合、パスがこのパターンに一致しないファイルはスキップされます。) |
| Start after path | last_pathパラメータを挿入して、最初の実行時にこのパスより前のファイルをスキップします。(例: logs/data_20170101.csv) |
| Incremental | インクリメンタルローディングを有効にします。インクリメンタルローディングが有効な場合、次回実行の設定差分にはlast_pathパラメータが含まれるため、次回実行時にそのパスより前のファイルがスキップされます。それ以外の場合、last_pathは含まれません。 |
例: CloudFront Log
Amazon CloudFrontは、静的および動的Webコンテンツの配信を高速化するWebサービスです。CloudFrontを設定して、CloudFrontが受信するすべてのユーザーリクエストに関する詳細情報を含むログファイルを作成できます。ロギングを有効にすると、次のようにCloudFrontログファイルを保存できます:
[your_bucket] - [logging] - [E231A697YXWD39.2017-04-23-15.a103fd5a.gz]
[your_bucket] - [logging] - [E231A697YXWD39.2017-04-23-15.b2aede4a.gz]
[your_bucket] - [logging] - [E231A697YXWD39.2017-04-23-16.594fa8e6.gz]
[your_bucket] - [logging] - [E231A697YXWD39.2017-04-23-16.d12f42f9.gz]この場合、Source Tableの設定は次のようになります:
- Bucket: your_bucket
- Path Prefix: logging/
- Path Regex: .gz$ (必須ではありません)
- Start after path: logging/E231A697YXWD39.2017-04-23-15.b2aede4a.gz (2017-04-23-16からログファイルをインポートしたい場合を想定)
- Incremental: true (このジョブをスケジュールしたい場合)
- Nextを選択します。
- Data Settingsページが開きます。
オプションで、データ設定を編集するか、ダイアログのこのページをスキップします。
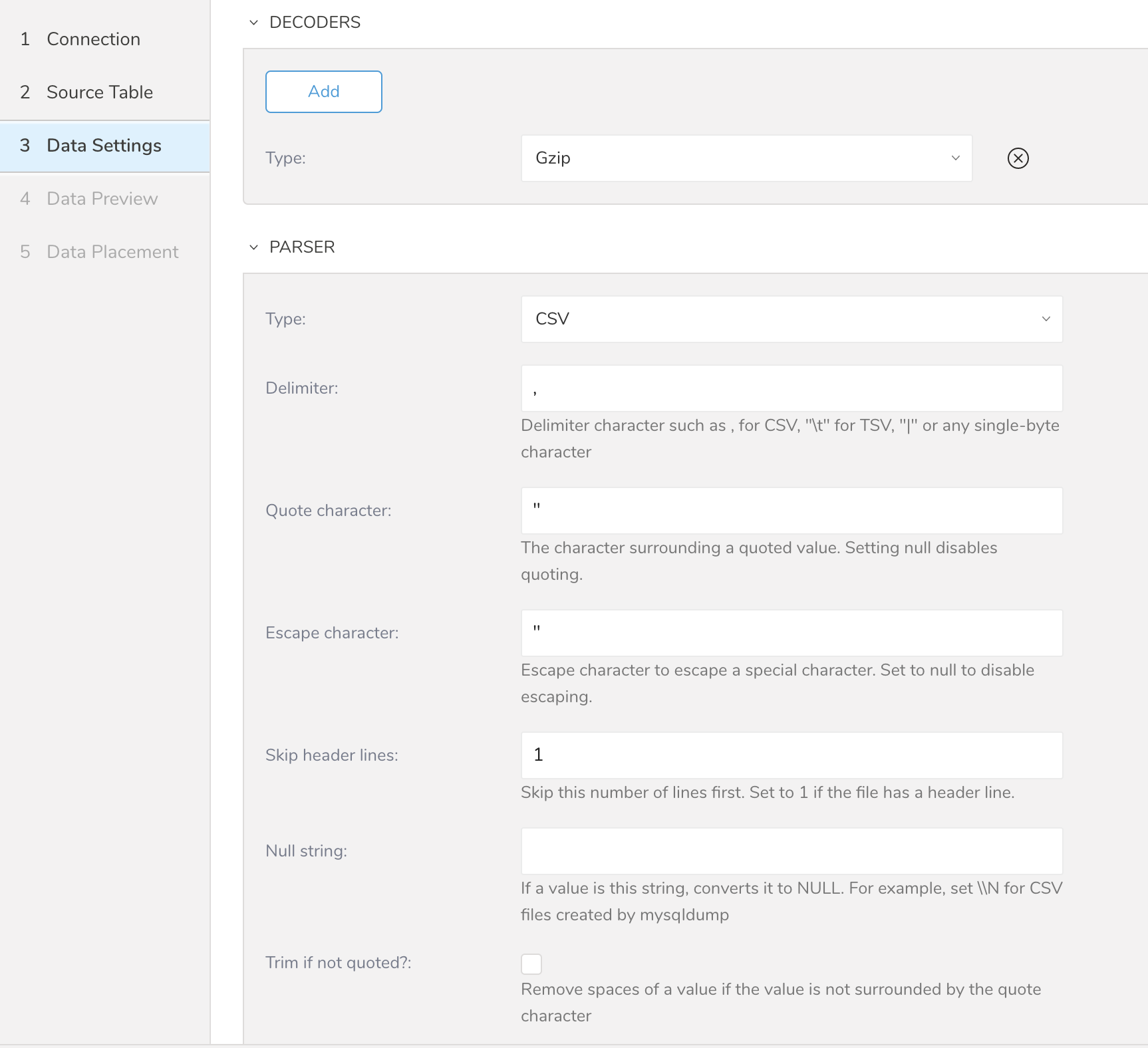
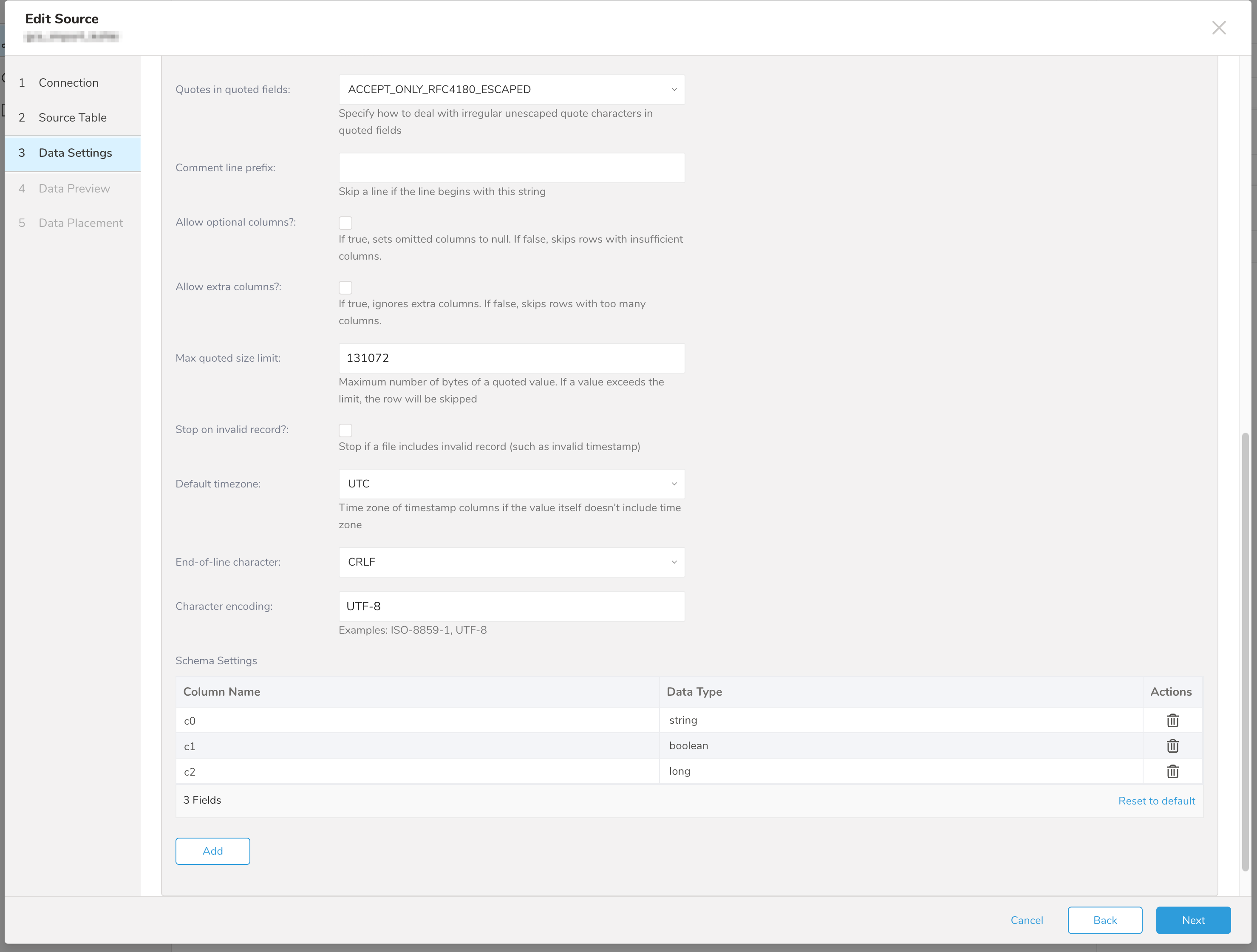
| パラメータ | 説明 |
|---|---|
| Type | 以下のタイプがサポートされています: - Avro - CSV - json - Query String |
| Default timezone | 値自体にタイムゾーンが含まれていない場合、タイムスタンプカラムのタイムゾーンを変更します。 |
| Total file count limit | 読み取るファイルの最大数。(オプション) |
| Schema Settings | カラムに名前を付けてデータ型を設定できます。TDは指定されたデータ型として値を解析します。その後、Treasure Dataスキーマに変換して保存します。 - boolean - long - timestamp: Treasure DataではString型としてインポートされます(例: 2017-04-01 00:00:00.000) - double - string - json |
インポートを実行する前に、Generate Preview を選択してデータのプレビューを表示できます。Data preview はオプションであり、選択した場合はダイアログの次のページに安全にスキップできます。
- Next を選択します。Data Preview ページが開きます。
- データをプレビューする場合は、Generate Preview を選択します。
- データを確認します。
データの配置について、データを配置したいターゲット database と table を選択し、インポートを実行する頻度を指定します。
Next を選択します。Storage の下で、インポートされたデータを配置する新しい database を作成するか、既存の database を選択し、新しい table を作成するか、既存の table を選択します。
Database を選択 > Select an existing または Create New Database を選択します。
オプションで、database 名を入力します。
Table を選択 > Select an existing または Create New Table を選択します。
オプションで、table 名を入力します。
データをインポートする方法を選択します。
- Append (デフォルト) - データインポートの結果は table に追加されます。 table が存在しない場合は作成されます。
- Always Replace - 既存の table の全体の内容をクエリの結果出力で置き換えます。table が存在しない場合は、新しい table が作成されます。
- Replace on New Data - 新しいデータがある場合のみ、既存の table の全体の内容をクエリの結果出力で置き換えます。
Timestamp-based Partition Key 列を選択します。 デフォルトキーとは異なるパーティションキーシードを設定したい場合は、long または timestamp 列をパーティショニング時刻として指定できます。デフォルトの時刻列として、add_time フィルターで upload_time を使用します。
データストレージの Timezone を選択します。
Schedule の下で、このクエリを実行するタイミングと頻度を選択できます。
- Off を選択します。
- Scheduling Timezone を選択します。
- Create & Run Now を選択します。
- On を選択します。
- Schedule を選択します。UI では、@hourly、@daily、@monthly、またはカスタム cron の 4 つのオプションが提供されます。
- Delay Transfer を選択して、実行時間の遅延を追加することもできます。
- Scheduling Timezone を選択します。
- Create & Run Now を選択します。
転送が実行された後、Data Workbench > Databases で転送の結果を確認できます。
GCSからデータをインポートするサンプルワークフローについては、Treasure Boxesを参照してください。
コネクタを設定する前に、最新のTD Toolbeltをインストールしてください。
Data Connectorは、"boolean"、"long"、"double"、"string"、"timestamp"タイプの解析をサポートしています。
JSONキーファイルを使用してseed.ymlを準備します。また、バケット名とターゲットファイル名(または複数ファイルのプレフィックス)を指定する必要があります。
in:
type: gcs
bucket: sample_bucket
path_prefix: path/to/sample_file # path the the *.csv or *.tsv file on your GCS bucket
auth_method: json_key
json_keyfile:
content: |
{
"private_key_id": "1234567890",
"private_key": "-----BEGIN PRIVATE KEY-----\nABCDEF",
"client_id": "...",
"client_email": "...",
"type": "service_account"
}
out:
mode: appendData Connector for Google Cloud Storageは、指定されたプレフィックスに一致するすべてのファイルをインポートします。(例: path_prefix: path/to/sample_ –> path/to/sample_201501.csv.gz, path/to/sample_201502.csv.gz, …, path/to/sample_201505.csv.gz)
connector:guessを使用します。このコマンドは、対象ファイルを自動的に読み取り、ファイル形式をインテリジェントに推測します。
td connector:guess seed.yml -o load.ymlload.ymlを開くと、ファイル形式、エンコーディング、カラム名、型など、推測されたファイル形式定義が表示されます。
in:
type: gcs
bucket: sample_bucket
path_prefix: path/to/sample_file
auth_method: json_key
json_keyfile:
content: |
{
"private_key_id": "1234567890",
"private_key": "-----BEGIN PRIVATE KEY-----\nABCDEF",
"client_id": "...",
"client_email": "...",
"type": "service_account"
}
decoders:
- {type: gzip}
parser:
charset: UTF-8
newline: CRLF
type: csv
delimiter: ','
quote: '"'
escape: ''
skip_header_lines: 1
columns:
- name: id
type: long
- name: company
type: string
- name: customer
type: string
- name: created_at
type: timestamp
format: '%Y-%m-%d %H:%M:%S'
out:
mode: appendpreviewコマンドを使用すると、システムがファイルをどのように解析するかをプレビューできます。
td connector:preview load.ymlguessコマンドは、ソースデータファイルに3行以上、2列以上必要です。これは、ソースデータのサンプル行を使用してカラム定義を推測するためです。
システムがカラム名やカラム型を予期せず検出した場合は、load.ymlを直接修正して再度プレビューしてください。
previewコマンドは、指定されたバケットから1つのファイルをダウンロードし、そのファイルからの結果を表示します。そのため、previewコマンドとissueコマンドの結果に違いが生じる場合があります。
ロードジョブを送信します。データのサイズによっては、数時間かかる場合があります。ユーザーは、データが保存されるデータベースとテーブルを指定する必要があります。
Treasure Dataのストレージは時間によってパーティション分割されているため、--time-columnオプションを指定することをお勧めします。オプションが指定されていない場合、Data Connectorは最初のlongまたはtimestampカラムをパーティション分割時間として選択します。--time-columnで指定するカラムの型は、longまたはtimestamp型のいずれかである必要があります。
データに時間カラムがない場合は、add_timeフィルターオプションを使用して追加できます。詳細については、add_timeフィルタープラグインを参照してください。
td connector:issue load.yml --database td_sample_db --table td_sample_table --time-column created_at前述のコマンドは、database(td_sample_db)とtable(td_sample_table)がすでに作成されていることを前提としています。データベースまたはテーブルがTDに存在しない場合、このコマンドは成功しないため、データベースとテーブルを手動で作成するか、td connector:issueコマンドで--auto-create-tableオプションを使用してデータベースとテーブルを自動作成してください。
td connector:issue load.yml --database td_sample_db --table td_sample_table --time-column created_at --auto-create-tableData Connectorはサーバー側でレコードをソートしません。時間ベースのパーティション分割を効果的に使用するには、ファイル内のレコードを事前にソートしてください。
timeというフィールドがある場合は、--time-columnオプションを指定する必要はありません。
td connector:issue load.yml --database td_sample_db --table td_sample_table増分Google Cloud Storageファイルインポートのために、定期的なData Connector実行をスケジュールできます。TDはスケジューラーを慎重に管理して、高可用性を確保します。この機能を使用することで、ローカルデータセンターでcronデーモンを使用する必要がなくなります。
スケジュールインポートの場合、Data Connector for Google Cloud Storageは、最初に指定されたプレフィックスに一致するすべてのファイルをインポートし(例: path_prefix: path/to/sample_ –> path/to/sample_201501.csv.gz, path/to/sample_201502.csv.gz, …, path/to/sample_201505.csv.gz)、次回の実行のために最後のパス(path/to/sample_201505.csv.gz)を記憶します。
2回目以降の実行では、アルファベット順(辞書順)で最後のパスの後に来るファイルのみをインポートします。(path/to/sample_201506.csv.gz, …)
新しいスケジュールは、td connector:createコマンドを使用して作成できます。スケジュールの名前、cron形式のスケジュール、データが保存されるデータベースとテーブル、およびData Connector設定ファイルが必要です。
td connector:create daily_import "10 0 * * *" td_sample_db td_sample_table load.ymlTreasure Dataのストレージは時間によってパーティション分割されているため、--time-columnオプションを指定することもお勧めします。
td connector:create daily_import "10 0 * * *" td_sample_db td_sample_table load.yml --time-column created_atcronパラメータは、3つの特別なオプションも受け入れます:@hourly、@daily、@monthly。デフォルトでは、スケジュールはUTCタイムゾーンで設定されます。-tまたは--timezoneオプションを使用して、タイムゾーンでスケジュールを設定できます。--timezoneオプションは、'Asia/Tokyo'、'America/Los_Angeles'などの拡張タイムゾーン形式のみをサポートしています。PST、CSTなどのタイムゾーン略語は*サポートされておらず*、予期しないスケジュールになる可能性があります。
td connector:listコマンドを実行すると、現在スケジュールされているエントリのリストを確認できます。
$ td connector:list