Google BigQuery Export Integration V2の詳細はこちら
Google BigQuery V2のインテグレーションにより、BigQueryテーブルまたはクエリ結果からTreasure Dataにデータをインポートすることができます。
- Treasure Dataの基本的な知識
- Google Cloud Platform(BigQuery、Cloud Storage、IAM)の基本的な知識
- このコネクタではOAuthはサポートされなくなりました。JSON keyfileのみサポートされています。
- データセットがUSまたはEUマルチリージョン以外の場所にある場合は、ロケーションを指定する必要があります。指定しない場合、TDのジョブは「Cannot find job_id xxxxx」というエラーで失敗します。
- このコネクタは外部テーブルのインポートをサポートしていません。
- ビューからのインポートは、tableではなくqueryのインポートタイプを使用する必要があります。
- テーブルまたはクエリにRange型のフィールドが含まれている場合、GCSへのエクスポートは使用できません。使用すると「Unsupported type for JSON export: RANGE」というエラーが発生します。
- Require partition filterオプションが有効になっているパーティションテーブルからqueryタイプでインポートする場合、SQL文のWHERE句にパーティションフィールドを含める必要があります。含めないと、「Cannot query over table 'xxxxx' without a filter over column(s) '{partition field}' that can be used for partition elimination」というエラーが返されます。
- queryタイプのインポートでlegacyを使用する場合、
INTERVAL、TIMESTAMP(12)、JSON、またはRANGEのデータ型のフィールドを含むソーステーブルはサポートされず、「Querying tables with INTERVAL, TIMESTAMP(12), JSON, or RANGE type is not supported in Legacy SQL」というエラーが返されます。 - Require partition filterオプションが有効になっているPartition Tableは、インポートモードtableでは増分インポートをサポートしていませんが、インポートモードqueryではサポートしています。
このデータコネクタを使用するには、認証されたアカウント(サービスアカウント)に以下の権限またはIAMロールが必要です。
| カテゴリ | 必要な権限 | 最小IAMロール |
|---|---|---|
| テーブルロードを使用する場合 | - bigquery.tables.get - bigquery.tables.getData | - BigQuery Data Viewer |
| クエリロードを使用する場合 | - bigquery.jobs.create | - BigQuery Job User |
| "Import Large Dataset"を使用する場合 | - bigquery.tables.export - bigquery.tables.delete - storage.buckets.get - storage.objects.list - storage.objects.create - storage.objects.delete - storage.objects.get | - BigQuery Data Editor - Storage Legacy Bucket Writer - Storage Legacy Object Reader |
IAMの権限とロールの詳細については、Google Cloudのドキュメントを参照してください:BigQueryおよびCloud Storage
- Integrations Hub > Catalogに移動します。
- Google BigQueryを検索して選択します。
- ダイアログが開きます。JSON keyfileのみがサポートされています。
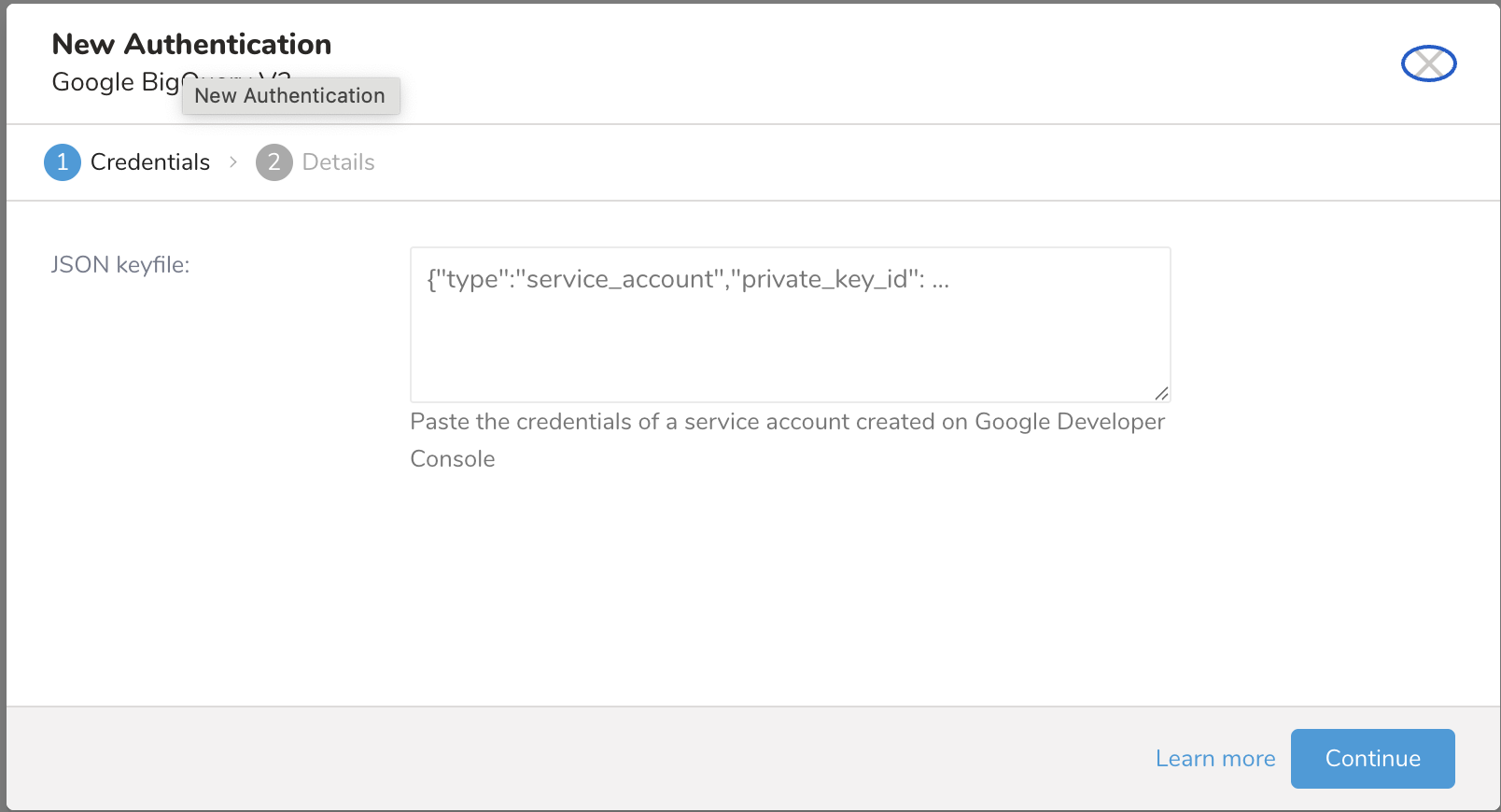
- サービスアカウントキーのJSON文字列を「JSON keyfile」セクションに入力します。
- 新しいサービスアカウントキーの作成については、Google Cloudのドキュメントを参照してください。
SQL結果をロードする場合は、「Query statement」を選択し、「SQL statement」にSQLクエリを入力します。 転送を作成する前に、BigQuery Web UIでクエリが有効であることを確認してください。https://docs.cloud.google.com/bigquery/docs/bigquery-web-ui
接続を作成すると、自動的にAuthenticationsタブに移動します。作成した接続を探してSourceを選択します。
インポートするデータソースを設定します。 Google Cloud PlatformプロジェクトのIDを「Project ID」に入力します。 テーブルを保存するデータセット名を入力します。
インポートのタイプを選択します。テーブル全体をロードする(table loading)か、SQL結果をロードする(query loading)かを選択します。
テーブル全体をロードする場合は、「Table」を選択し、エクスポートしたい「Table name」を入力します。
マテリアライズドビューをロードする場合は、代わりに「Query Statement」を選択してください。
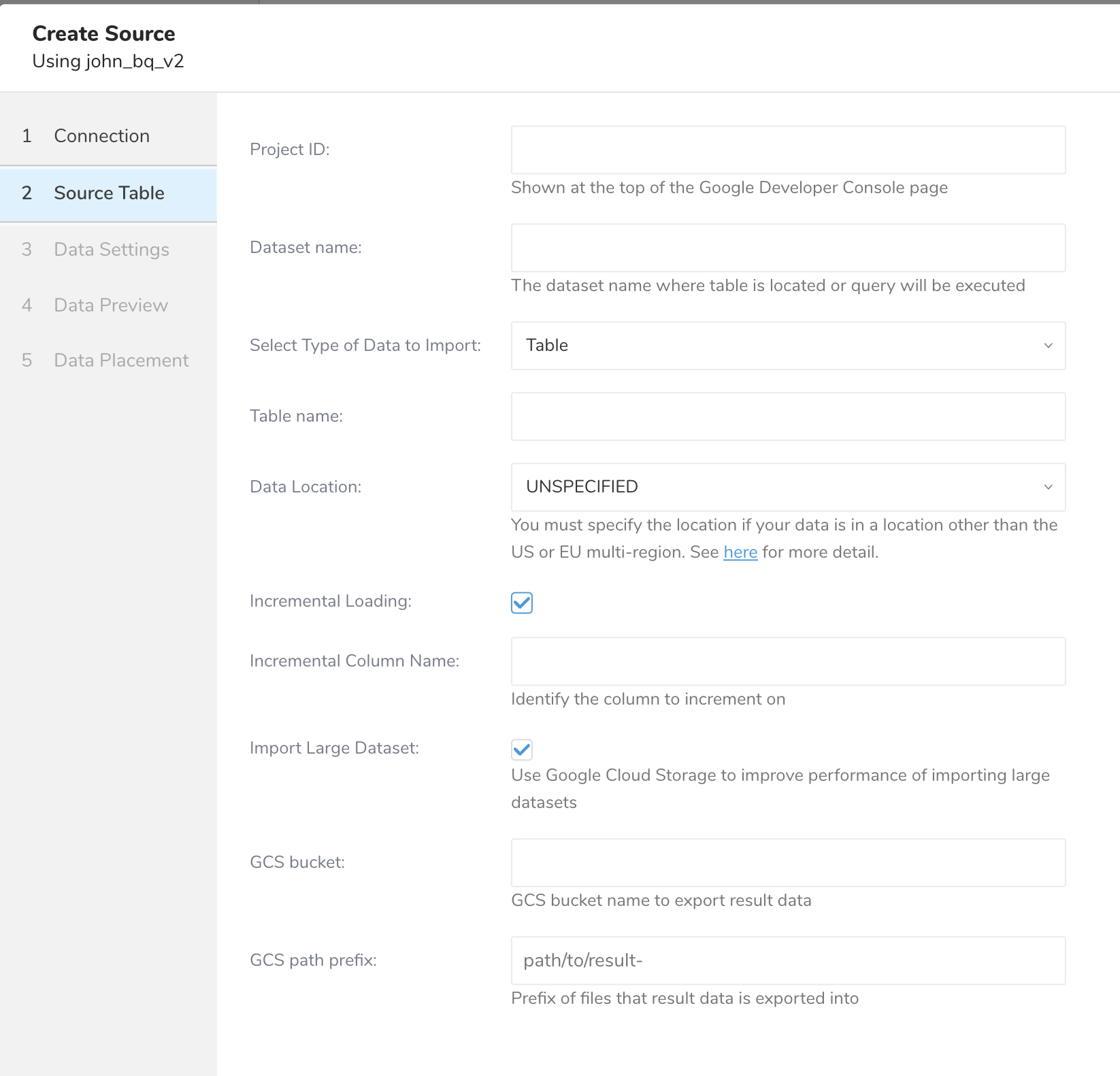
SQL結果をロードする場合は、「Query statement」を選択し、「SQL statement」にSQLクエリを入力します。
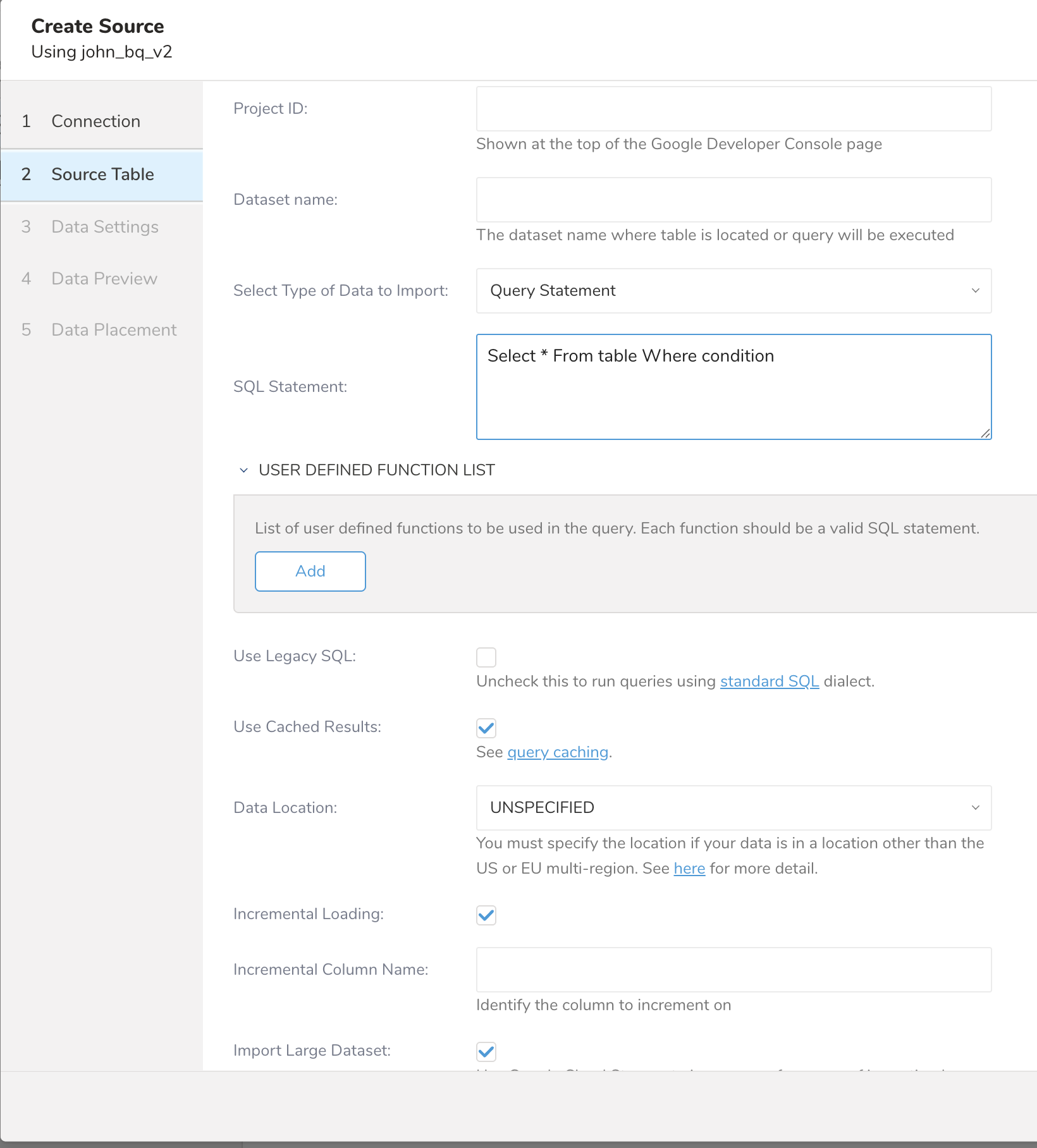
デフォルトのSQL方言はStandard SQLです。Legacy SQLを使用する場合は、Use Legacy SQLをチェックしてください。
デフォルトでは、このコネクタは特定の条件下でキャッシュされた結果を使用します。キャッシュを無効にする場合は、Use Cached Resultsのチェックを外してください。
User Defined Function List: クエリで使用する関数
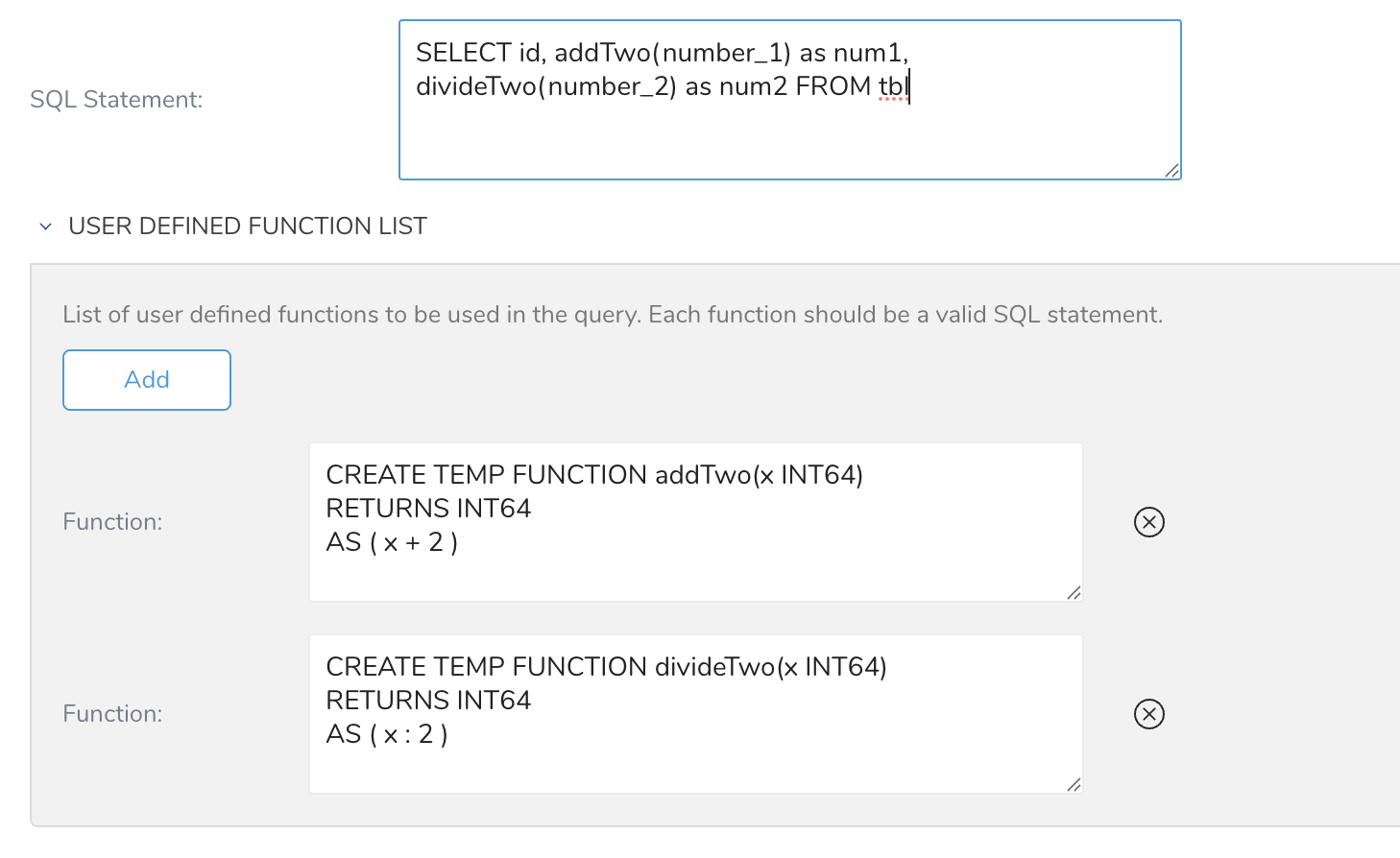
Legacy SQLの場合は以下に従ってください:https://cloud.google.com/bigquery/docs/user-defined-functions-legacy#register
Standard SQLの場合は以下に従ってください:https://cloud.google.com/bigquery/docs/user-defined-functions#sql-udf-structure
UDFがすでに存在する場合、クエリはエラーになる可能性があります。
データがUSまたはEUマルチリージョン以外の場所にある場合は、ロケーションを指定する必要があります。
データがasia-northeast1リージョンにある場合は、ロケーションを指定する必要があります。
ロケーションの詳細については、Google Cloudのドキュメントを参照してください。
インクリメンタルローディングは、自動増分ID列や作成日のタイムスタンプ列など、増加する一意の列を使用して、前回の実行後の新しいレコードのみをロードできます。
これを有効にするには、Incremental Loading をチェックし、「Incremental Column Name」に増分する列名を指定します。 インクリメンタル列としてサポートされているのは、INTEGER型とTIMESTAMP型のみです。
このコネクタは、インクリメンタル列で順序付けられた最新のレコードである「最終レコード」を記録します。次回の実行時には、最終レコードを使用して以下のルールで構築されたクエリを実行してレコードをロードします。
テーブルローディングの場合、すべてのフィールドがWHERE句で選択されます。
SELECT * FROM `${dataset}.${table}` WHERE ${incremental_column} > ${value_of_last_record}クエリローディングの場合、生のクエリがWHERE句でラップされます。
SELECT * FROM (${query}) embulk_incremental_ WHERE ${incremental_column} > ${value_of_last_record}大規模なデータセット(ベンチマークとして500MB以上)をロードする場合は、この「Import Large Dataset」オプションの使用を推奨します。このオプションは、データをGCS(Google Cloud Storage)オブジェクトとしてエクスポートし、複数のタスクでデータをロードします。そのため、ロードが高速化されます。
このオプションを有効にするには、Import Large Dataset をチェックし、「GCS bucket」と「GCS path prefix」を指定します。
- クエリ(クエリローディングまたはインクリメンタルローディング付きのテーブルローディング)を実行すると、クエリ結果はデータセット設定内の一時的なBigQueryテーブルにエクスポートされます。
- その後、一時テーブルは、パスプレフィックスを使用してGoogle Cloud Storageバケットに「gs://my-bucket/data-connector/result-[12桁の数字].jsonl.gz」としてgzip圧縮されたJSON Linesファイルとしてエクスポートされます。ファイルの数は結果データのサイズによって異なります。
- インクリメンタルローディングなしのテーブルローディングの場合、ソーステーブル内のすべてのデータが直接GCSにエクスポートされます。
- 完了後、一時テーブルとGCSオブジェクトは削除されます。
- データセットが「US」に設定されていない場合、GCSバケットもテーブルと同じロケーションにある必要があります。米国ベースのデータセットから別のリージョンのCloud Storageバケットにデータをエクスポートできます。詳細については、Google Cloudのエクスポート制限ドキュメントを参照してください。
インポートを実行する前に、Generate Preview を選択してデータのプレビューを表示できます。Data preview はオプションであり、選択した場合はダイアログの次のページに安全にスキップできます。
- Next を選択します。Data Preview ページが開きます。
- データをプレビューする場合は、Generate Preview を選択します。
- データを確認します。
データの配置について、データを配置したいターゲット database と table を選択し、インポートを実行する頻度を指定します。
Next を選択します。Storage の下で、インポートされたデータを配置する新しい database を作成するか、既存の database を選択し、新しい table を作成するか、既存の table を選択します。
Database を選択 > Select an existing または Create New Database を選択します。
オプションで、database 名を入力します。
Table を選択 > Select an existing または Create New Table を選択します。
オプションで、table 名を入力します。
データをインポートする方法を選択します。
- Append (デフォルト) - データインポートの結果は table に追加されます。 table が存在しない場合は作成されます。
- Always Replace - 既存の table の全体の内容をクエリの結果出力で置き換えます。table が存在しない場合は、新しい table が作成されます。
- Replace on New Data - 新しいデータがある場合のみ、既存の table の全体の内容をクエリの結果出力で置き換えます。
Timestamp-based Partition Key 列を選択します。 デフォルトキーとは異なるパーティションキーシードを設定したい場合は、long または timestamp 列をパーティショニング時刻として指定できます。デフォルトの時刻列として、add_time フィルターで upload_time を使用します。
データストレージの Timezone を選択します。
Schedule の下で、このクエリを実行するタイミングと頻度を選択できます。
- Off を選択します。
- Scheduling Timezone を選択します。
- Create & Run Now を選択します。
- On を選択します。
- Schedule を選択します。UI では、@hourly、@daily、@monthly、またはカスタム cron の 4 つのオプションが提供されます。
- Delay Transfer を選択して、実行時間の遅延を追加することもできます。
- Scheduling Timezone を選択します。
- Create & Run Now を選択します。
転送が実行された後、Data Workbench > Databases で転送の結果を確認できます。
BigQueryのデータ型は、次の表に示すように、対応するTreasure Dataの型に自動的に変換されます。テーブルまたはクエリ結果のスキーマにサポートされていない型が含まれている場合、エラーが発生します。
| BigQuery | Treasure Data |
|---|---|
| STRING | string |
| BYTES | string |
| INTERVAL | string |
| RANGE | string |
| GEOGRAPHY | string |
| INTEGER | long |
| FLOAT | double |
| NUMERIC | string |
| BIGNUMERIC | string |
| BOOLEAN | long (trueは1、falseは0) |
| TIMESTAMP | string (yyyy-MM-dd HH:mm:ss.SSS) |
| DATE | string |
| TIME | string |
| DATETIME | string |
| RECORD | string (JSONとして) |
| REPEATED (PRIMITIVE or RECORD) | string (JSONとして) |
BigQueryとCloud Storageのすべてのクォータと制限は、GCPプロジェクトに適用されます。
必要に応じて、TD Toolbelt経由でコネクタを使用できます。
CLI上でTDツールベルトをセットアップします。
ここでは「config.yml」と呼ばれる設定YAMLファイルを作成します。
- GCSへのエクスポートとインクリメンタルを使用したテーブルからのインポート例
in:
type: bigquery_v2
json_keyfile:
content: |
{
xxxxxxxx
}
project_id: xxxx
dataset: xxx
import_type: table
table: xxxx
location: US
export_to_gcs: true
gcs_bucket: xxxx
gcs_path_prefix: xxxx
incremental: true
incremental_column: xxxin:
type: bigquery_v2
json_keyfile:
content: |
{
xxxxxxxx
}
project_id: xxxx
dataset: xxx
import_type: query
query: xxxxxxx
location: US
udf:
- function: |
CREATE TEMP FUNCTION addTwo(x INT64)
RETURNS INT64
AS ( x + 2 )
- function: |
CREATE TEMP FUNCTION addTwo(x INT64)
RETURNS INT64
AS ( x + 2 )
location: US
export_to_gcs: true
gcs_bucket: xxxx
gcs_path_prefix: xxxx
incremental: true
incremental_column: xxx| 名前 | 説明 | タイプ | 値 | デフォルト値 | 必須 |
|---|---|---|---|---|---|
| type | コネクタタイプ | string | bigquery_v2 | N/A | Yes |
| json_keyfile | Google サービスアカウント JSON キー | content プロパティを持つオブジェクト 例: json_keyfile: content: | xxxxxxxx | N/A | N/A |
| project_id | BigQuery プロジェクト ID | string | N/A | N/A | Yes |
| dataset | BigQuery データセット | string | N/A | N/A | Yes |
| import_type | ソースインポート | string | サポートされる値: - table - query | table | Yes |
| table | テーブル名 | string | N/A | N/A | import_type が table の場合は Yes |
| query | SQL ステートメント | string | N/A | N/A | import_type が query の場合は Yes |
| udf | ユーザー定義関数リスト | 関数の配列 例: udf: - function: | xxxxxxx - function: | xxxxxxxxx | N/A |
| use_legacy_sql | レガシー SQL ダイアレクトを使用 | boolean | true/false | false | No |
| use_query_cache | キャッシュされた結果を使用 | boolean | true/false | true | No |
| location | データセットのロケーション(リージョン) | string | サポートされる値: UNSPECIFIED および以下のリストの値 https://cloud.google.com/bigquery/docs/dataset-location | UNSPECIFIED | No |
| incremental | 差分読み込みを有効にするかどうか | boolean | true/false | false | No |
| incremental_column | 差分読み込み用のカラム名 | string | N/A | N/A | incremental が true の場合は Yes |
| export_to_gcs | GCS へのエクスポート機能を使用するかどうか | boolean | true/false | true | No |
| gcs_bucket | 結果をエクスポートする GCS バケット | string | N/A | N/A | export_to_gcs が true の場合は Yes |
| gcs_path_prefix | GCS ファイルのファイルパスのプレフィックス | string | N/A | N/A | export_to_gcs が true の場合は Yes |
(オプション) プレビュー
td td connector:preview コマンドを実行して、設定ファイルを検証します
td connector:preview config.ymltd connector:create を実行します。
次の例では、BigQuery コネクタを使用した日次インポートセッションが作成されます。
$ td connector:create daily_bigquery_import \ "10 0 * * *" td_sample_db td_sample_table config.yml Name : daily_bigquery_import Cron : 10 0 * * * Timezone : UTC Delay : 0 Database : td_sample_db Table : td_sample_table Config --- in: ...コネクタセッションでは、結果データ内に少なくとも 1 つのタイムスタンプカラムがデータパーティションキーとして使用される必要があり、デフォルトでは最初のタイムスタンプカラムがキーとして選択されます。カラムを明示的に指定する場合は、"--time-column" オプションを使用します。
$ td connector:create --time-column created_at \ daily_bigquery_import ...結果データにタイムスタンプカラムがない場合は、次のようにフィルタ設定を追加して "time" カラムを追加します。
in:
type: bigquery
...
filters:
- type: add_time
from_value:
mode: upload_time
to_column:
name: time
out:
type: td