Google BigQuery Import Integrationについてはこちらをご覧ください。
ジョブの結果をGoogle BigQueryに直接書き込むことができます。Google BigQueryからデータをインポートする方法もご確認いただけます。
- TD Toolbeltを含むTreasure Dataの基本的な知識
- Google Cloud Platformアカウント
- ARRAYのようなネストされたデータ型や繰り返しデータ型は、宛先カラムとしてサポートされていません。
Treasure Dataは「append、replace、replace backup、delete」モードをサポートしています。
この機能を使用するには、以下が必要です:
- Project ID
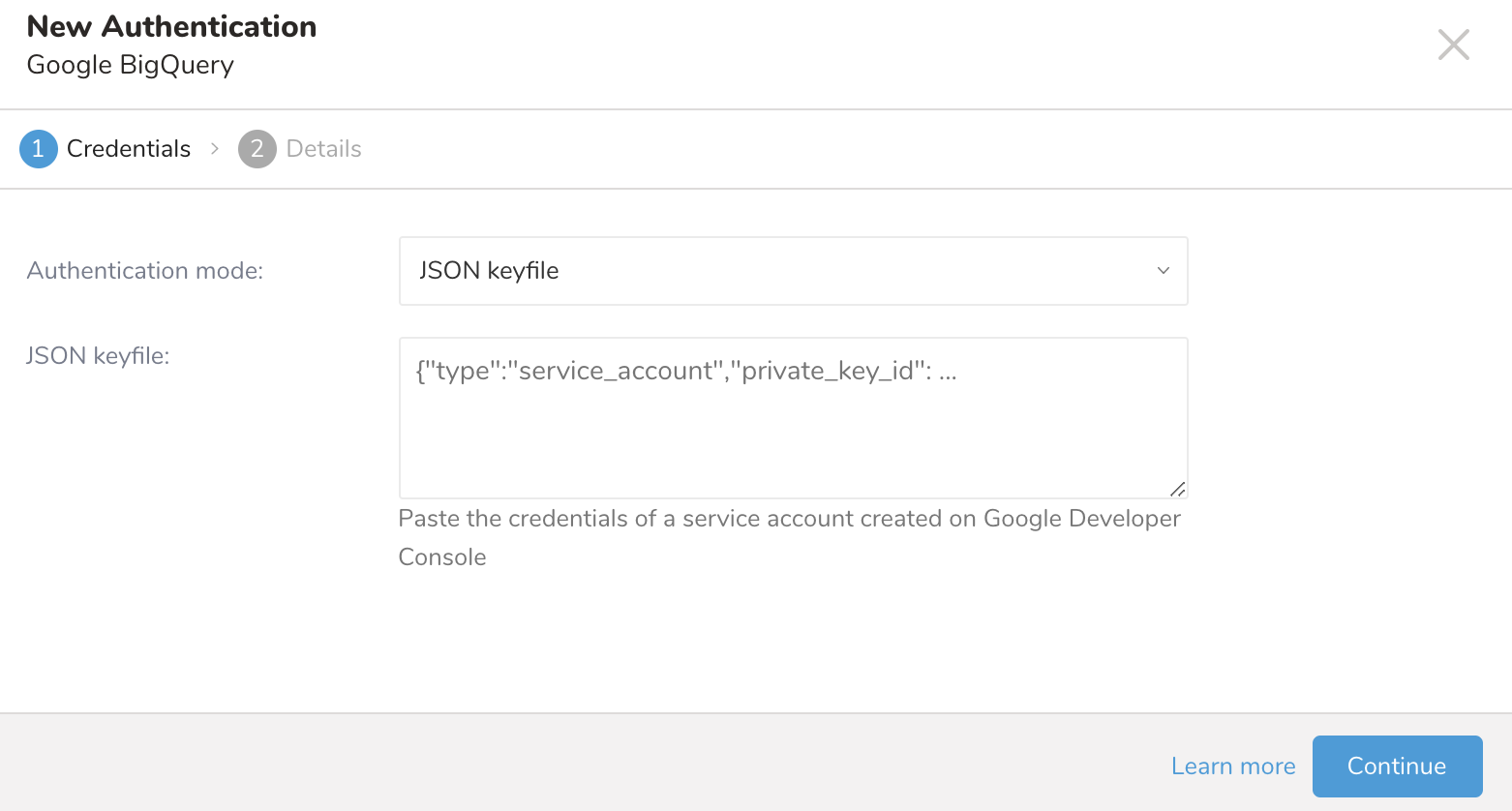
- JSON Credential
Google BigQueryとの統合は、サーバー間APIの認証に基づいています。
Google Developer Consoleに移動します。
APIs & auth > Credentialsを選択します。
Service accountを選択します。
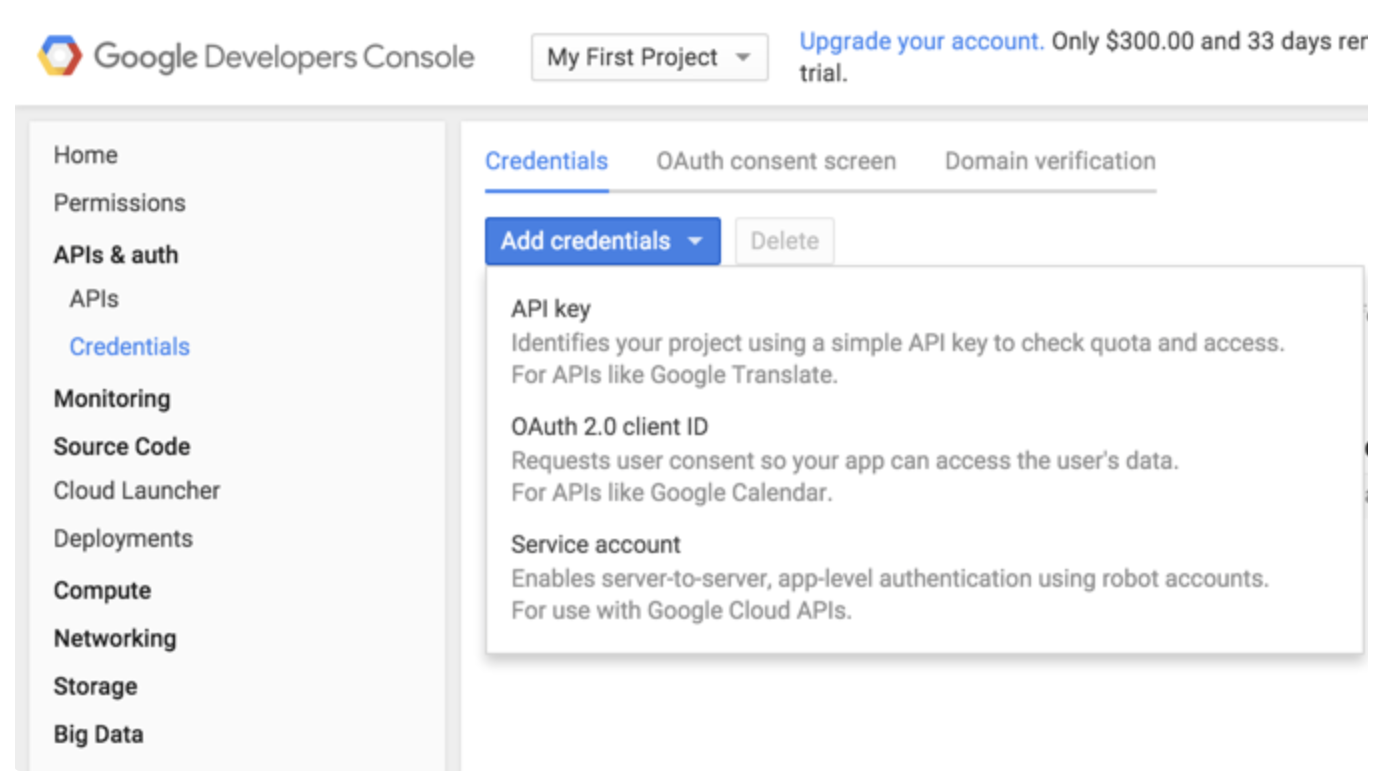
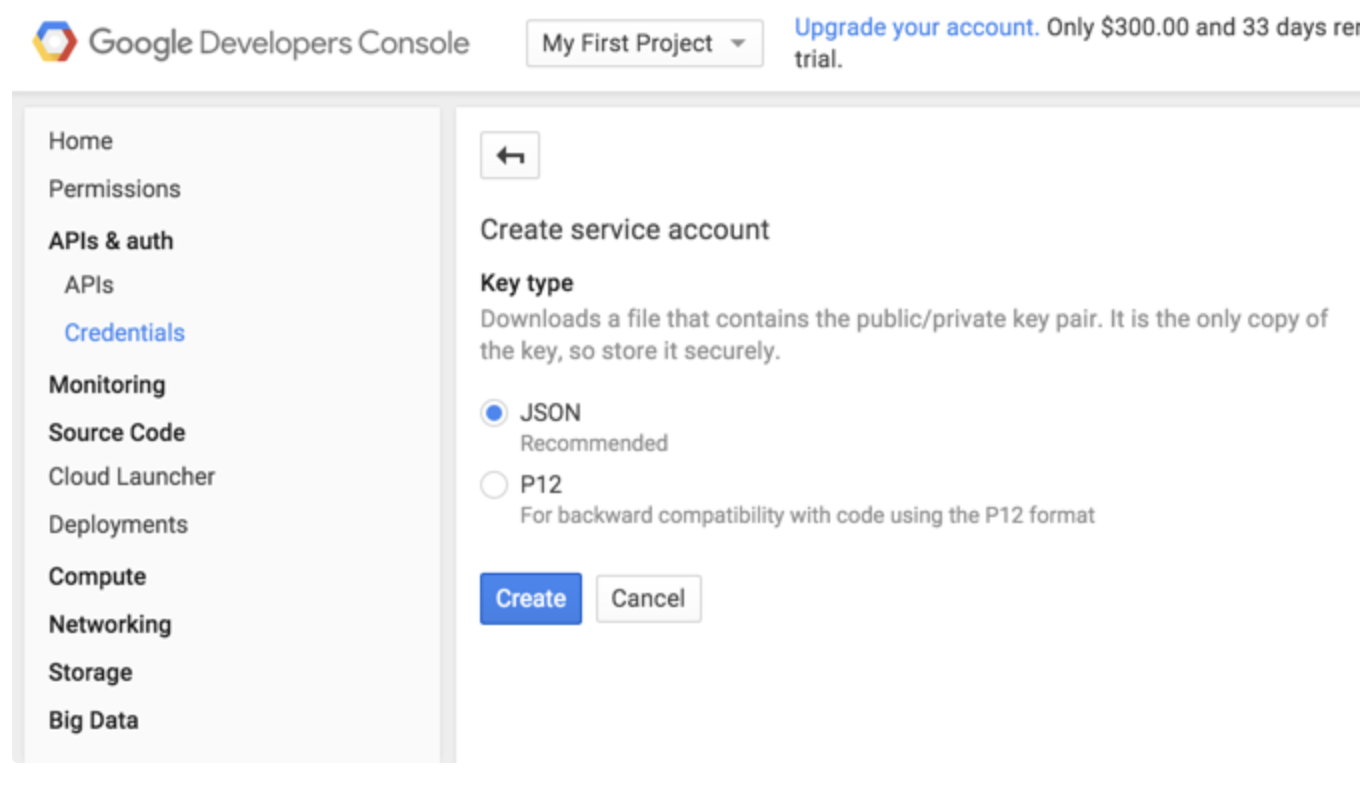
Googleが推奨するJSONベースのキータイプを選択します。キーはブラウザによって自動的にダウンロードされます。
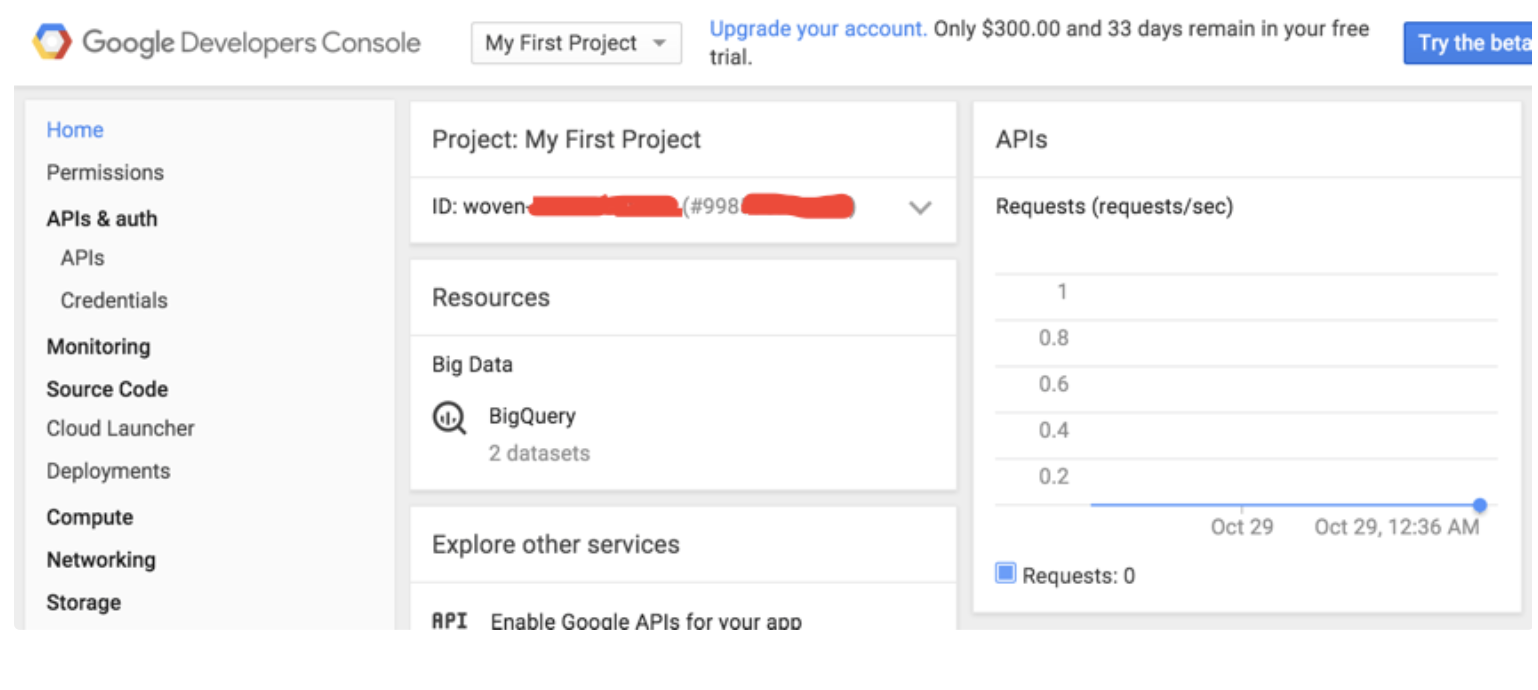
- Google Developer Consoleに移動します。
- Homeを選択します。
- Project IDを確認します。
BigQueryコンソールからDatasetとTableを作成します。
TD Consoleに移動します。
Integrations Hub > Catalogに移動します。
Google Big Queryを選択します。

以下の通り、すべての情報を入力します:
クエリを記述します。クエリ結果はBigQuery上で事前に定義されたスキーマと一致する必要があります。ジョブを実行すると、Treasure Dataのクエリ結果が自動的にGoogle BigQueryにインポートされます。
BigQueryにテーブルがすでに存在する場合、以下のようなペインが表示されます:
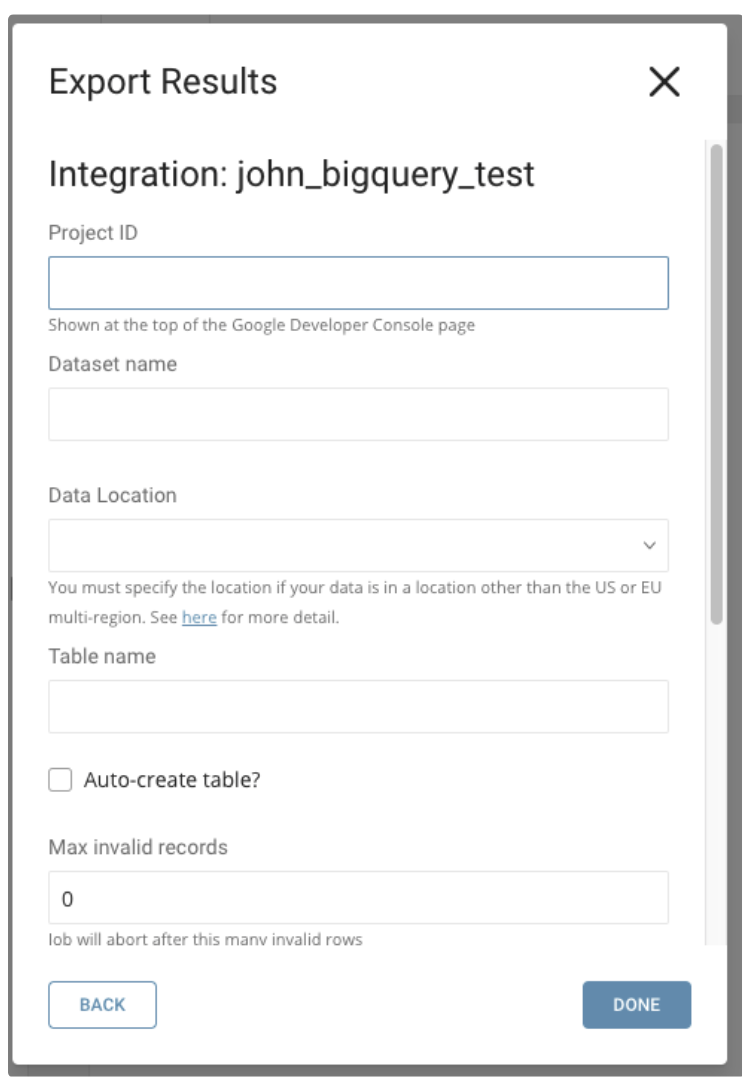
BigQueryから取得したProject ID、Dataset Name、Table Nameを入力します。
クエリを記述します。クエリ結果はBigQuery上で事前に定義されたスキーマと一致する必要があります。ジョブを実行すると、Treasure Dataのクエリ結果が自動的にGoogle BigQueryにインポートされます。
BigQueryにテーブルが存在しない場合:
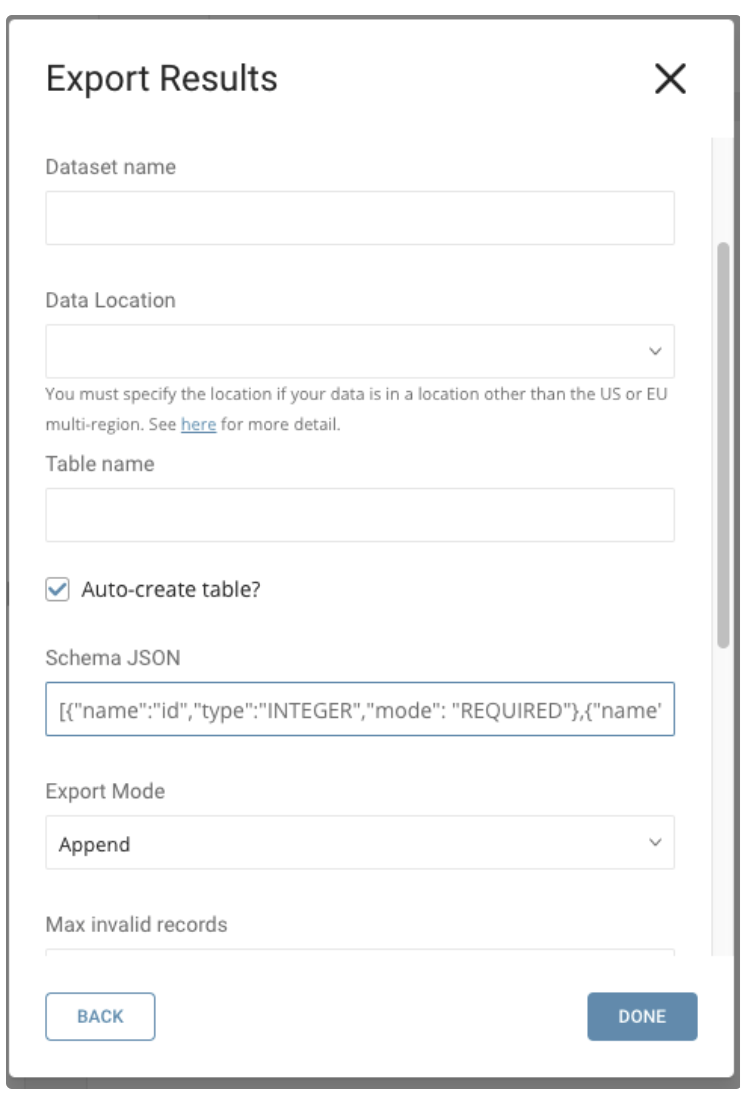
BigQueryから取得したProject ID、Dataset Nameを入力します。
BigQuery Datasetに作成されるテーブルの名前を指定します。Auto-create tableをチェックし、新しいテーブルのスキーマを提供します。Schema JSONはクエリ結果(フィールド数とデータ型)と一致する必要があります。ジョブを実行すると、入力した名前とスキーマを持つ新しいテーブルが作成され、Treasure Dataのクエリ結果が自動的にこのテーブルにインポートされます。
Schema JSONの例:
[{"name":"id","type":"INTEGER","mode": "REQUIRED"},{"name":"name","type":"STRING"}]
以下のようなペインが表示されます:
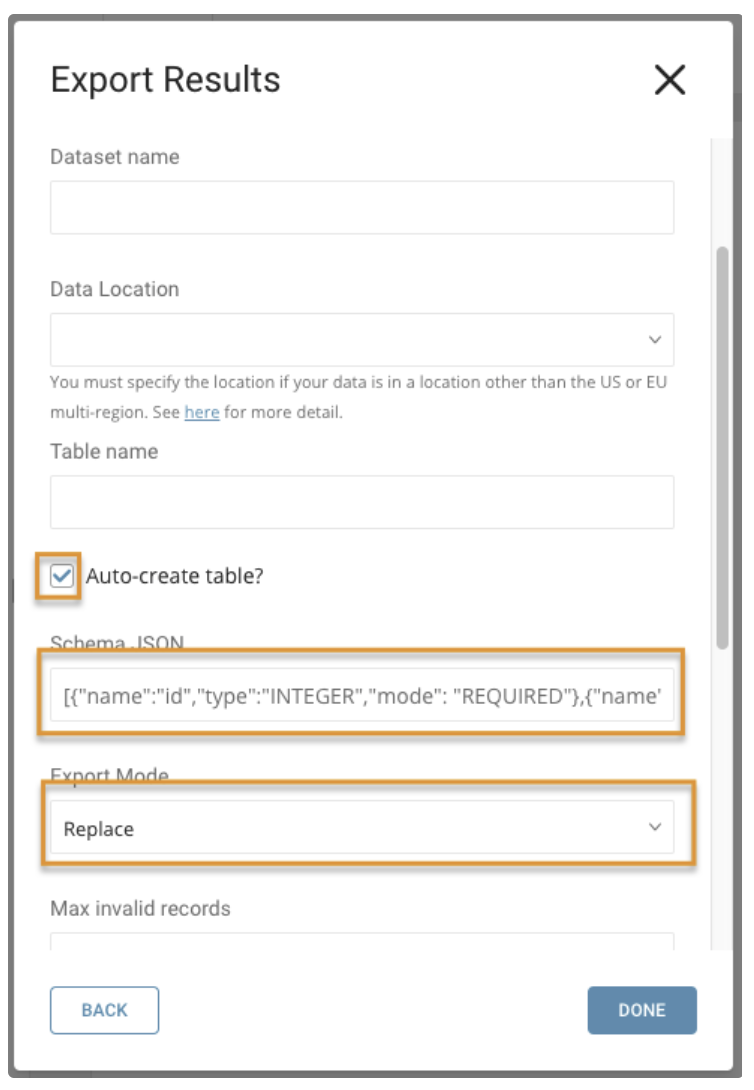
BigQueryから取得したProject ID、Dataset Name、Table Nameを入力します。
Auto-create tableを選択し、置き換えるテーブルのスキーマを提供します。Schema JSONフィールドの値はクエリ結果(フィールド数とデータ型)と一致する必要があります。ドロップダウンからReplaceを選択します。ジョブを実行すると、BigQueryにテーブルがすでに存在する場合、またはSchema JSONの値がテーブルスキーマと異なる場合、テーブルは置き換えデータとして処理されます。BigQueryにテーブルが存在しない場合、入力した名前とスキーマを持つ新しいテーブルが作成されます。Treasure Dataのクエリ結果が自動的にこのテーブルにインポートされます。
以下のようなペインが表示されます:
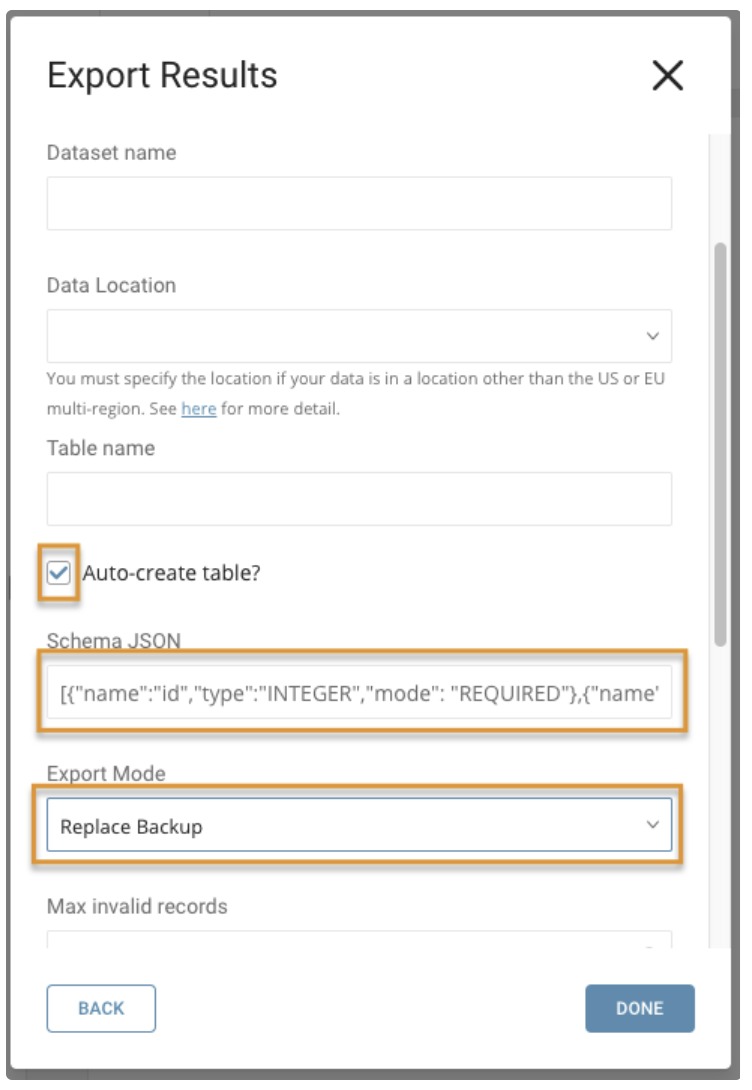
Replace backupモードはreplaceモードに似ていますが、replace backupモードでは、データとスキーマの両方が、元の名前に「_old」というサフィックスを付けたテーブルにバックアップされます。
以下のようなペインが表示されます:
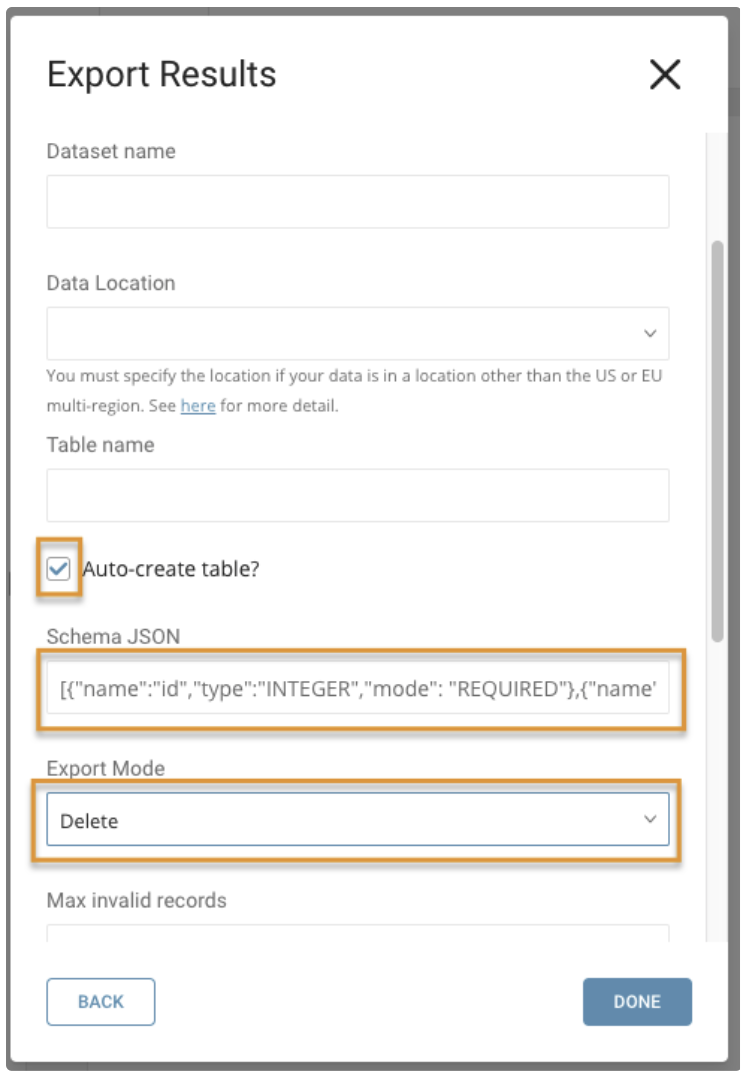
BigQueryから取得したProject ID、Dataset Name、Table Nameを入力します。
Auto-create tableを選択し、置き換えるテーブルのスキーマを提供します。Schema JSONフィールドの値はクエリ結果(フィールド数とデータ型)と一致する必要があります。ドロップダウンからDeleteを選択します。BigQueryにテーブルがすでに存在する場合、ジョブを実行するとテーブルが削除され、スキーマとしてJSONを持つ新しいテーブルが追加されます。BigQueryにテーブルが存在しない場合、入力した名前とスキーマを持つ新しいテーブルが作成されます。Treasure Dataのクエリ結果が自動的にこの新しく作成されたテーブルにインポートされます。
BigQueryのデータ型は、以下の表に示すように、対応するTreasure Dataの型に自動的に変換されます。schema JSONにサポートされていない型を含めたり、クエリ結果がschema JSONのデータ型と一致しない場合、エラーが発生します。
| Treasure Data | BigQuery |
|---|---|
| string | STRING |
| long | INTEGER |
| double | FLOAT |
| long (true is 1, false is 0) | BOOLEAN |
| string (yyyy-MM-dd HH:mm:ss.SSS) | TIMESTAMP |
以下のコマンドを使用すると、BigQueryへの結果出力を含むスケジュールされたクエリを設定できます。 json_keyを指定し、改行をバックスラッシュでエスケープしてください。
例:
$ td sched:create scheduled_bigquery "10 6 14 12 *" \
-d dataconnector_db "SELECT id,account,purchase,comment,time FROM data_connectors" \
-r '{"type":"bigquery","project":"YOUR_PROJECT","dataset":"YOUR_DB","table":"YOUR_TABLE","auto_create_table":true,"max_bad_records":0,"ignore_unknown_values":true,"allow_quoted_newlines":true,"schema_file":"[{\"name\": \"id\", \"type\": \"INTEGER\"}, {\"name\": \"account\", \"type\": \"STRING\"},{\"name\": \"purchase\", \"type\": \"STRING\"}, {\"name\": \"comment\", \"type\": \"STRING\", \"mode\": \"REQUIRED\"}, {\"name\": \"time\", \"type\": \"TIMESTAMP\", \"mode\": \"REQUIRED\"}]", "json_keyfile":"{\"private_key_id\": \"ABDE\", \"private_key\": \"-----BEGIN PRIVATE KEY-----\\nABCDE\\nABCDE\\nABCDE\\n-----END PRIVATE KEY-----\\n\", \"client_email\": \"ABCDE.gserviceaccount.com\", \"client_id\": \"ABCDE.apps.googleusercontent.com\", \"type\": \"service_account\"}"}'Audience Studio で activation を作成することで、segment データをターゲットプラットフォームに送信することもできます。
- Audience Studio に移動します。
- parent segment を選択します。
- ターゲット segment を開き、右クリックして、Create Activation を選択します。
- Details パネルで、Activation 名を入力し、前述の Configuration Parameters のセクションに従って activation を設定します。
- Output Mapping パネルで activation 出力をカスタマイズします。

- Attribute Columns
- Export All Columns を選択すると、変更を加えずにすべての列をエクスポートできます。
- + Add Columns を選択して、エクスポート用の特定の列を追加します。Output Column Name には、Source 列名と同じ名前があらかじめ入力されます。Output Column Name を更新できます。+ Add Columns を選択し続けて、activation 出力用の新しい列を追加します。
- String Builder
- + Add string を選択して、エクスポート用の文字列を作成します。次の値から選択します:
- String: 任意の値を選択します。テキストを使用してカスタム値を作成します。
- Timestamp: エクスポートの日時。
- Segment Id: segment ID 番号。
- Segment Name: segment 名。
- Audience Id: parent segment 番号。
- + Add string を選択して、エクスポート用の文字列を作成します。次の値から選択します:
- Schedule を設定します。

- スケジュールを定義する値を選択し、オプションでメール通知を含めます。
- Create を選択します。
batch journey の activation を作成する必要がある場合は、Creating a Batch Journey Activation を参照してください。