ジョブ結果をGoogle Cloud Storageに直接書き込むことができます。Import Integrationについては、Google Cloud Storage Import Integrationを参照してください。
- TD Toolbeltを含むTreasure Dataの基本知識
- 特定の権限を持つGoogle Cloud Platformアカウント
セキュリティポリシーで IP ホワイトリストが必要な場合は、接続を成功させるために Treasure Data の IP アドレスを許可リストに追加する必要があります。
リージョンごとに整理された静的 IP アドレスの完全なリストは、次のリンクにあります: https://api-docs.treasuredata.com/en/overview/ip-addresses-integrations-result-workers/
この機能を使用するには、以下が必要です。
- Google Project ID
- JSON認証情報
- GCSバケットにオブジェクトを作成するためのStorage Object Creatorロール
- GCSバケット内のオブジェクトをリストするためのStorage Object Viewerロール
Cloud Storageバケットをリストします。これらは名前の辞書順にリストされます。
プロジェクト内のバケットをリストするには:
- Google Cloud ConsoleでCloud Storageブラウザを開きます。
- 必要に応じて、フィルタリングを使用してリスト内の結果を絞り込みます。
現在選択されているプロジェクトの一部であるバケットがブラウザリストに表示されます。
新しいストレージバケットを作成するには:
- Google Cloud ConsoleでCloud Storageブラウザを開きます。
- Create bucketを選択してバケット作成フォームを開きます。
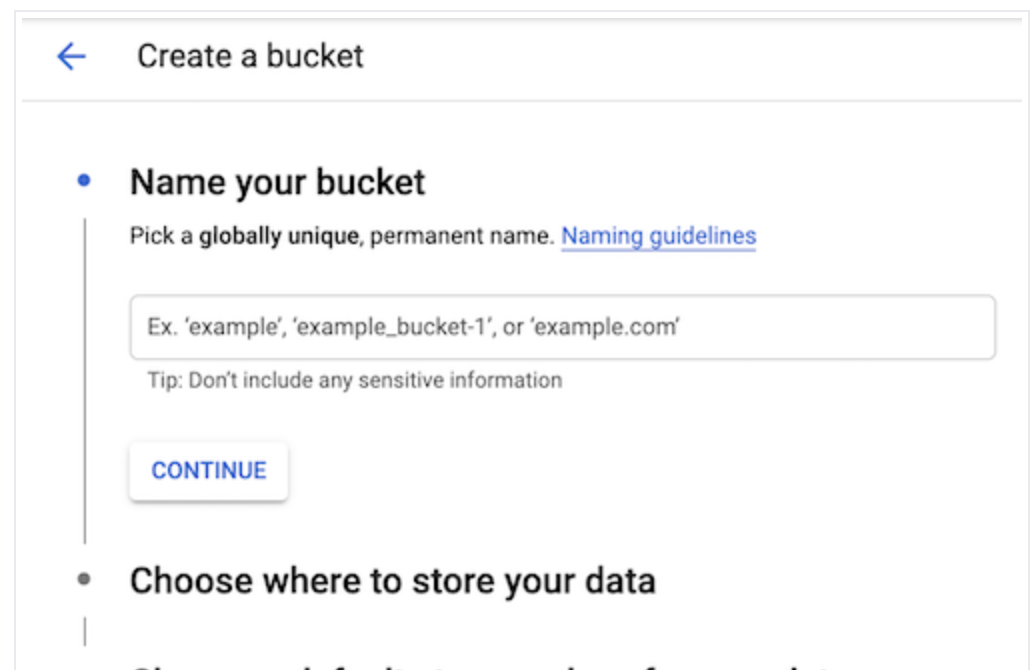
- バケット情報を入力し、各ステップを完了するためにContinueを選択します:
バケット名の要件に従ってNameを指定します。
バケットデータが永続的に保存されるLocation typeとLocationを選択します。
バケットのDefault storage classを選択します。デフォルトのストレージクラスは、バケットにアップロードされるすべてのオブジェクトにデフォルトで割り当てられます。
右側のペインのMonthly cost estimateパネルは、選択したストレージクラスとロケーション、および予想されるデータサイズと操作に基づいて、バケットの月間コストを見積もります。
Access controlモデルを選択して、バケットのオブジェクトへのアクセスを制御する方法を決定します。
必要に応じて、バケットラベルの追加、保持ポリシーの設定、暗号化方法の選択ができます。
- Createを選択します。
Google Cloud Storageとの統合は、サーバー間API認証に基づいています。
JSON認証情報の生成に使用されるService Accountには、宛先バケットに対するStorage Object Creator権限とStorage Object Viewer権限が必要です。
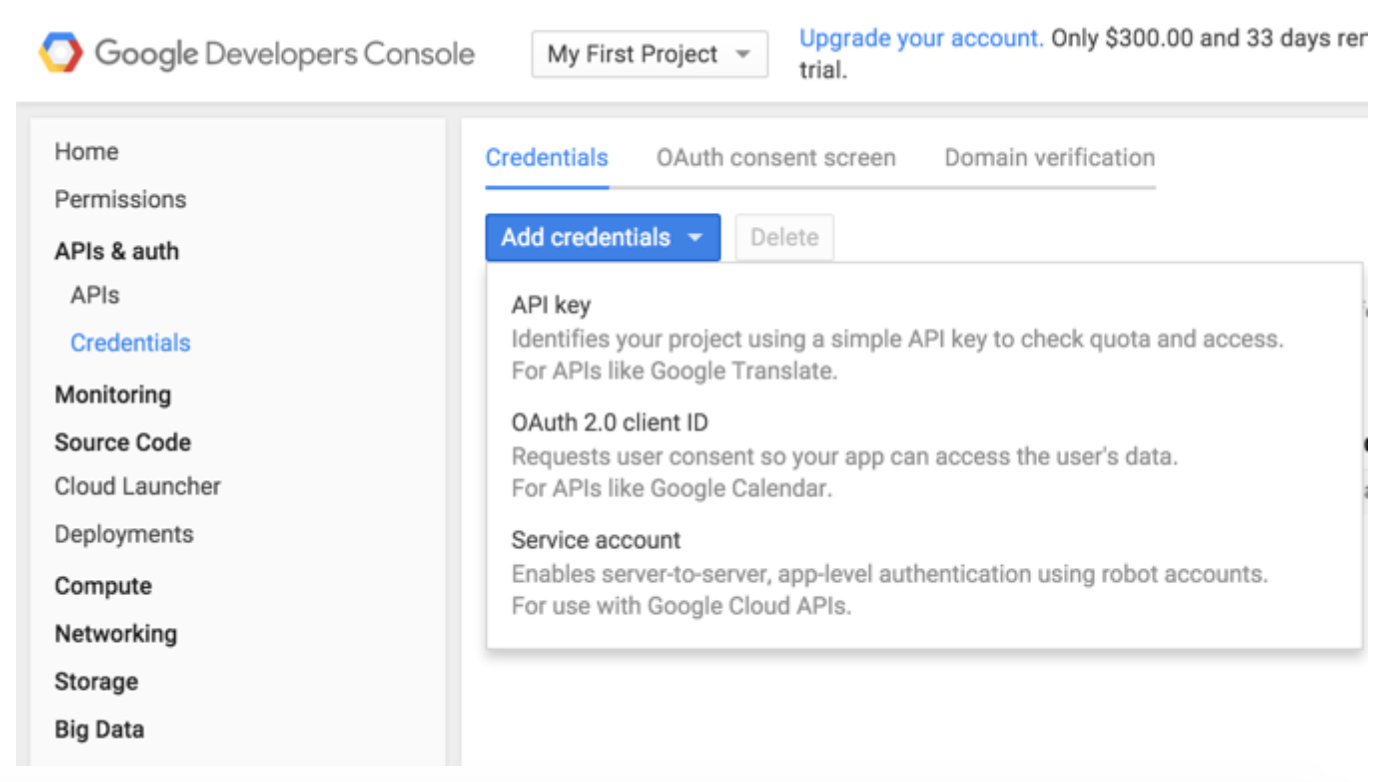
Google Developer Consoleにアクセスします。
左側のメニューのAPIs & authの下にあるCredentialsを選択します。
Service accountを選択します:
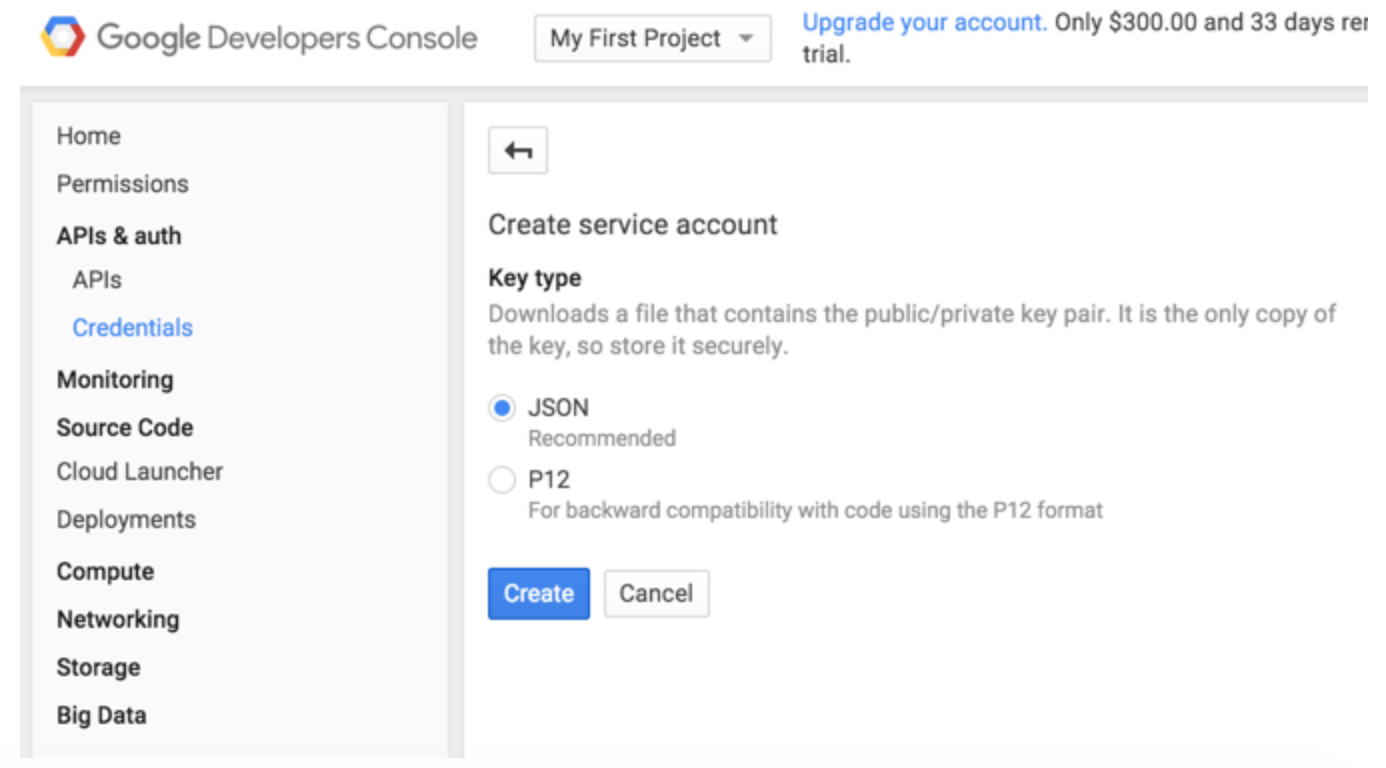
Googleが推奨するJSON形式のキータイプを選択します。キーはブラウザによって自動的にダウンロードされます。
Treasure Dataでは、クエリを実行する前にデータ接続を作成して設定する必要があります。データ接続の一部として、統合にアクセスするための認証を提供します。
- TD Consoleを開きます。
- Integrations Hub > Catalogに移動します。
- Google Cloud Storageを検索して選択します。

- Create Authenticationを選択します。
- 認証するための認証情報を入力します。
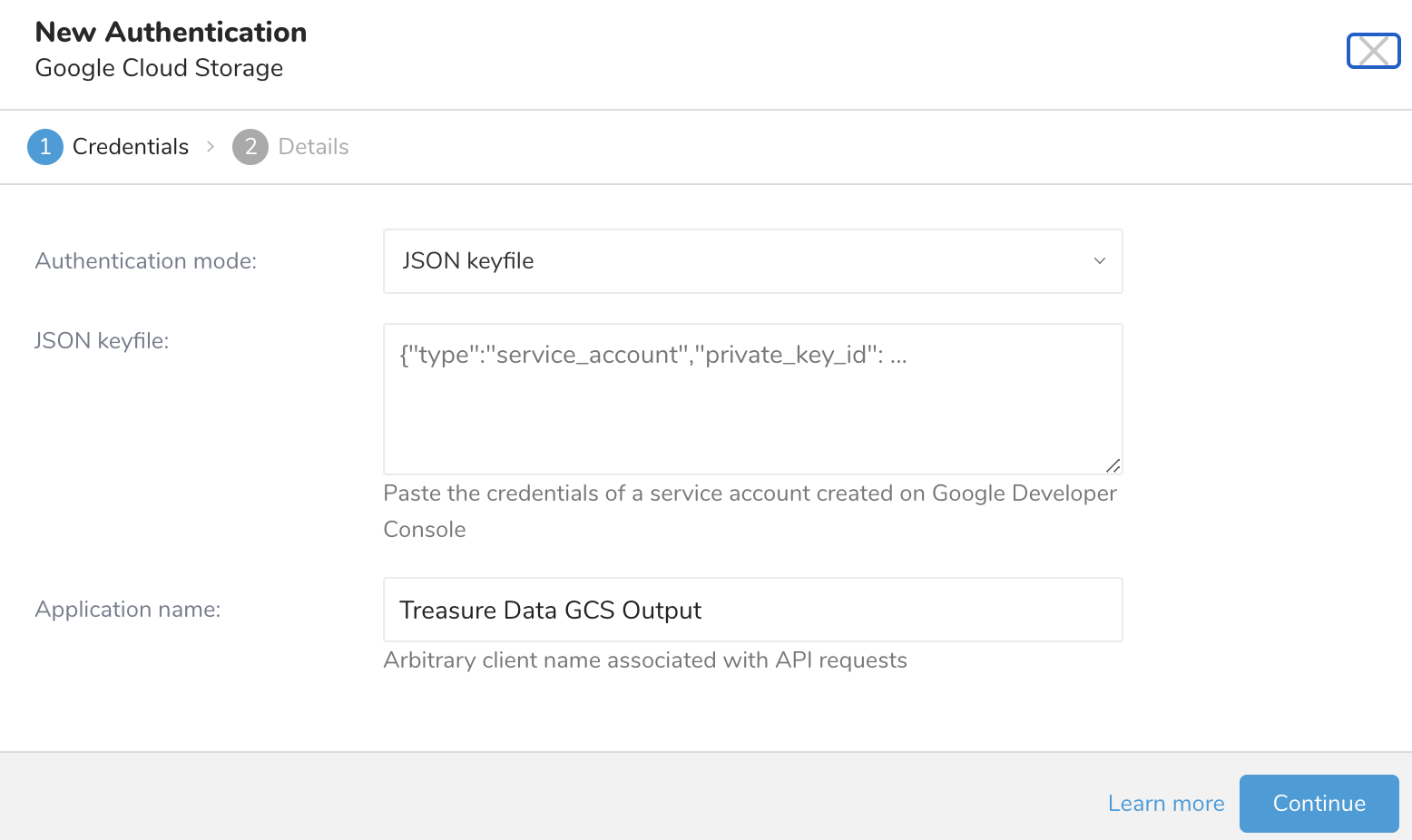
- 接続の名前を入力します。
- Continueを選択します。
- Creating a Destination Integrationの手順を完了します。
- Data Workbench > Queriesに移動します。
- データをエクスポートするクエリを選択します。
- クエリを実行して結果セットを検証します。
- Export Resultsを選択します。
- 既存の統合認証を選択します。
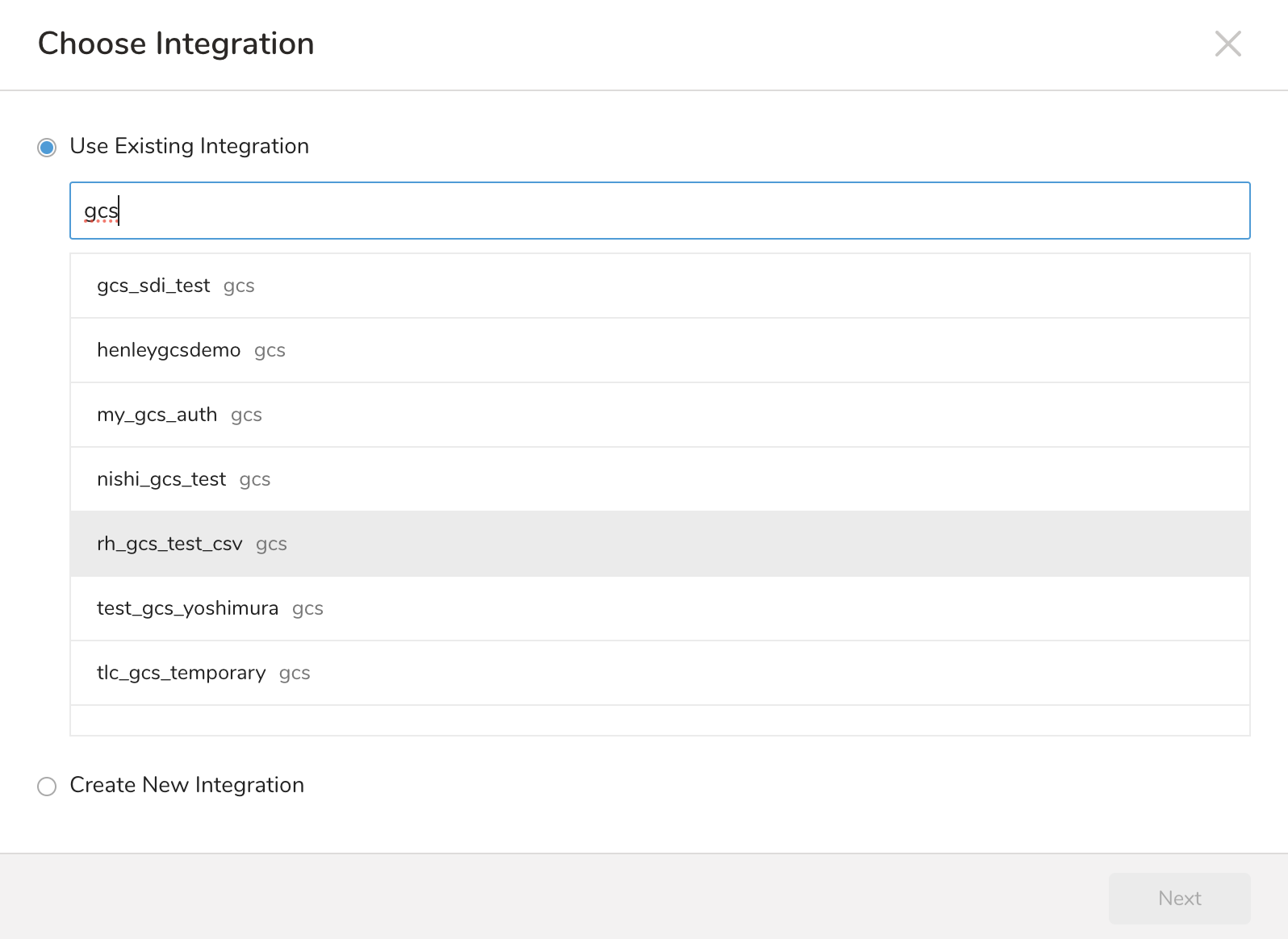
- 追加のExport Resultsの詳細を定義します。エクスポート統合コンテンツで、統合パラメータを確認してください。たとえば、Export Results画面が異なる場合や、入力する追加の詳細がない場合があります。
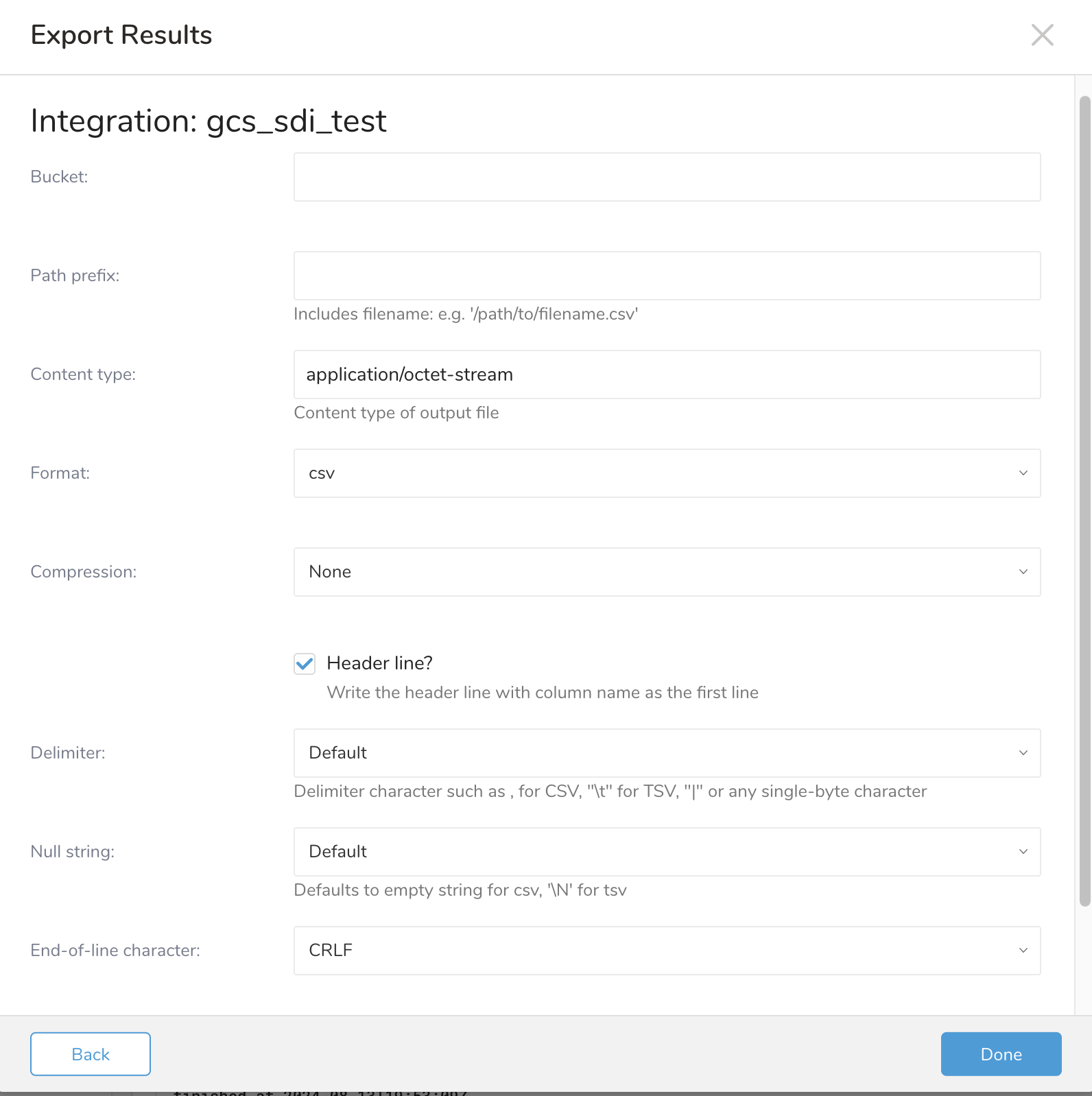
- Doneを選択します。
- クエリを実行します。
- 指定した宛先にデータが移動したことを検証します。
| パラメータ | 値 | 説明 |
|---|---|---|
bucket | 宛先Google Cloud Storageバケット名(文字列、必須)。 | |
path_prefix | ファイル名を含むオブジェクトパスプレフィックス(文字列、必須)。例: /path/to/filename.csv。 | |
content_type | 出力ファイルのMIMEタイプ(文字列、オプション)。デフォルト: application/octet-stream。 | |
format | csv, tsv | 出力ファイル形式(文字列、必須)。 |
compression | none, gz, bzip2, zip_builtin, zlib_builtin, bzip2_builtin | エクスポートされたファイルに適用される圧縮(文字列、オプション)。デフォルト: none。 |
header_line | true, false | 最初の行として列名を持つヘッダー行を書き込む(ブール値、オプション)。デフォルト: true。 |
delimiter | ,, \t, ` | `, 1バイト文字 |
null_string | NULL値の置換文字列(文字列、オプション)。デフォルト: CSVの場合は空文字列、TSVの場合は\N。 | |
end_of_line_character | CRLF, LF, CR | 行終端文字(文字列、オプション)。デフォルト: CRLF。 |
SELECT
c0 AS EMAIL
FROM
e_1000
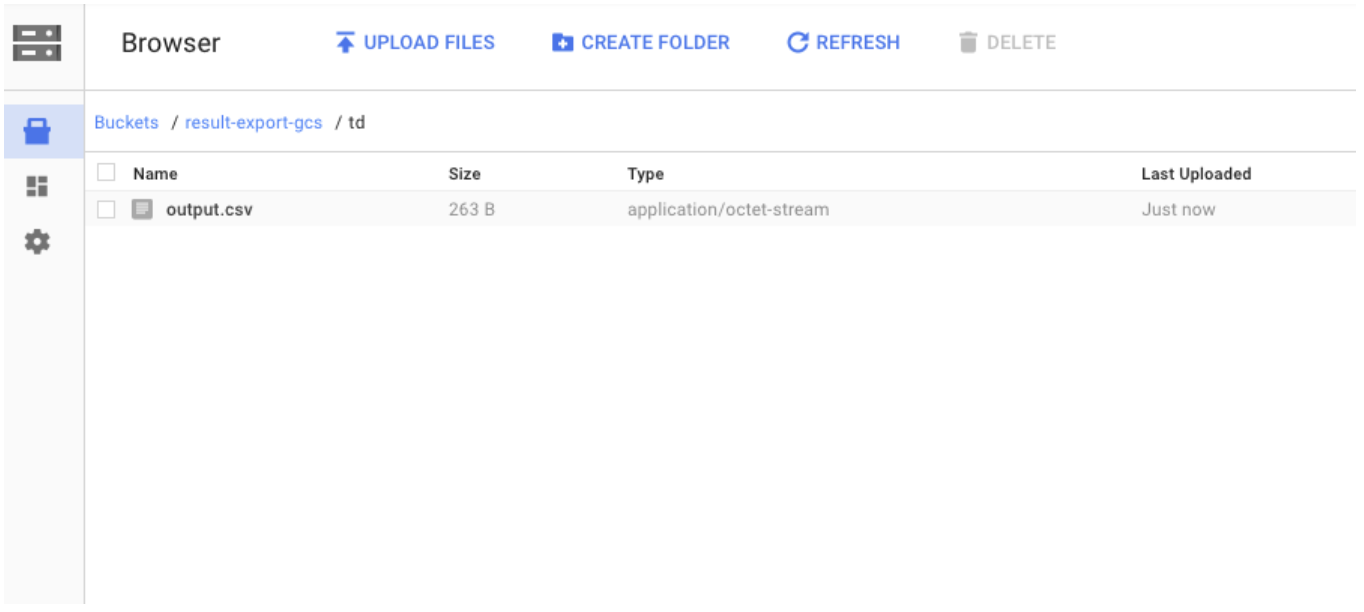
WHERE c0 != 'email'クエリが正常に完了すると、結果は指定したGoogle Cloud Storageの宛先に自動的にインポートされます:
Audience Studio で activation を作成することで、segment データをターゲットプラットフォームに送信することもできます。
- Audience Studio に移動します。
- parent segment を選択します。
- ターゲット segment を開き、右クリックして、Create Activation を選択します。
- Details パネルで、Activation 名を入力し、前述の Configuration Parameters のセクションに従って activation を設定します。
- Output Mapping パネルで activation 出力をカスタマイズします。

- Attribute Columns
- Export All Columns を選択すると、変更を加えずにすべての列をエクスポートできます。
- + Add Columns を選択して、エクスポート用の特定の列を追加します。Output Column Name には、Source 列名と同じ名前があらかじめ入力されます。Output Column Name を更新できます。+ Add Columns を選択し続けて、activation 出力用の新しい列を追加します。
- String Builder
- + Add string を選択して、エクスポート用の文字列を作成します。次の値から選択します:
- String: 任意の値を選択します。テキストを使用してカスタム値を作成します。
- Timestamp: エクスポートの日時。
- Segment Id: segment ID 番号。
- Segment Name: segment 名。
- Audience Id: parent segment 番号。
- + Add string を選択して、エクスポート用の文字列を作成します。次の値から選択します:
- Schedule を設定します。

- スケジュールを定義する値を選択し、オプションでメール通知を含めます。
- Create を選択します。
batch journey の activation を作成する必要がある場合は、Creating a Batch Journey Activation を参照してください。
次のコマンドを使用すると、クエリ結果をGoogle Cloud Storageに送信するスケジュールされたクエリを設定できます。
- 次のサンプル構文でJSONキーを指定します。
- コード構文を壊さずに行を分割するにはバックスラッシュを使用します。
'{"type":"gcs","bucket":"samplebucket","path_prefix":"/output/test.csv","format":"csv","compression":"","header_line":false,"delimiter":",","null_string":"","newline":"CRLF", "json_keyfile":"{\"private_key_id\": \"ABCDEFGHIJ\", \"private_key\": \"-----BEGIN PRIVATE KEY-----\\nABCDEFGHIJ\\ABCDEFGHIJ\\n-----END PRIVATE KEY-----\\n\", \"client_email\": \"ABCDEFGHIJ@developer.gserviceaccount.com\", \"client_id\": \"ABCDEFGHIJ.apps.googleusercontent.com\", \"type\": \"service_account\"}"}'例えば、
$ td sched:create scheduled_gcs "10 6 * * *" \
-d dataconnector_db "SELECT id,account,purchase,comment,time FROM data_connectors" \
-r '{"type":"gcs","bucket":"samplebucket","path_prefix":"/output/test.csv","format":"csv","compression":"","header_line":false,"delimiter":",","null_string":"","newline":"CRLF", "json_keyfile":"{\"private_key_id\": \"ABCDEFGHIJ\", \"private_key\": \"-----BEGIN PRIVATE KEY-----\\nABCDEFGHIJ\\ABCDEFGHIJ\\n-----END PRIVATE KEY-----\\n\", \"client_email\": \"ABCDEFGHIJ@developer.gserviceaccount.com\", \"client_id\": \"ABCDEFGHIJ.apps.googleusercontent.com\", \"type\": \"service_account\"}"}'オプション
| オプション | 値 |
|---|---|
format | csvまたはtsv |
compression | ""またはgz |
null_string | ""または\N |
newline | CRLF、CR、またはLF |
json_keyfile | 改行\nをバックスラッシュでエスケープ |
- Result Exportは、ターゲットの宛先に定期的にデータをアップロードするためにスケジュールできます。
- すべてのimportおよびexport integrationは、Treasure Workflowに追加できます。tdオペレーターを使用して、クエリ結果を指定したコネクタにエクスポートできます。詳細については、Workflow Operatorsを参照してください。
The Embulk-encoder-Encryption document
注意: 暗号化してアップロードする前に、ファイルを圧縮してください。
非ビルトイン暗号化を使用して復号化する場合、ファイルは.gzや.bz2などの圧縮形式に戻ります。
ビルトイン暗号化を使用して復号化する場合、ファイルは生データに戻ります。