この機能はベータ版です。詳細については、カスタマーサクセス担当者にお問い合わせください。
Google BigQuery Connector V2は、Google BigQueryへの大量データアップロードプロセスを効率化するように設計されています。以下の主要機能を提供します:
- Big Queryにアップロードされる大量データを処理するためのParquetファイルへの効率的なデータセットのパッケージング
- BigQueryロードジョブを使用した最適化されたデータアップロード
- Truncate同期モードのサポートを追加した柔軟なデータ同期操作
- TD Toolbeltを含むTreasure Dataの基本知識
- Google Cloud Platformアカウント
- ARRAYのようなネストされたデータ型または繰り返しデータ型は、宛先列としてサポートされていません。
このコネクターは「append、replace、replace backup、truncate」モードをサポートしています。
この機能を使用するには、以下が必要です:
- Project ID
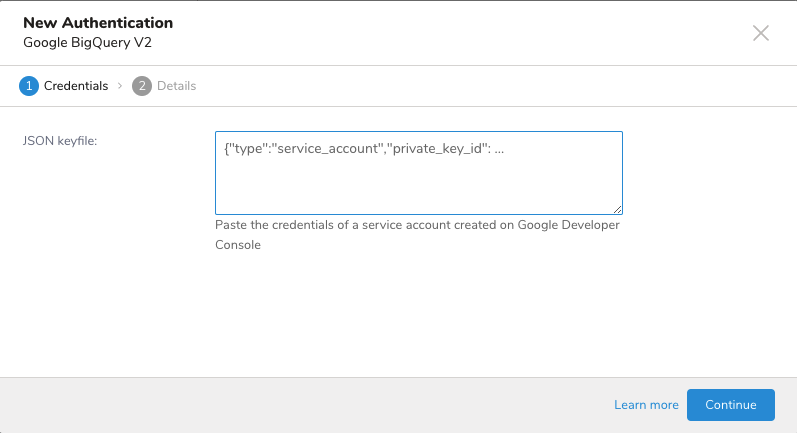
- JSON Credential
Google BigQueryとの統合は、サーバー間API認証に基づいています。
- Google Developer Consoleに移動します。
- APIs & auth > Credentialsを選択します。
- Service accountを選択します。
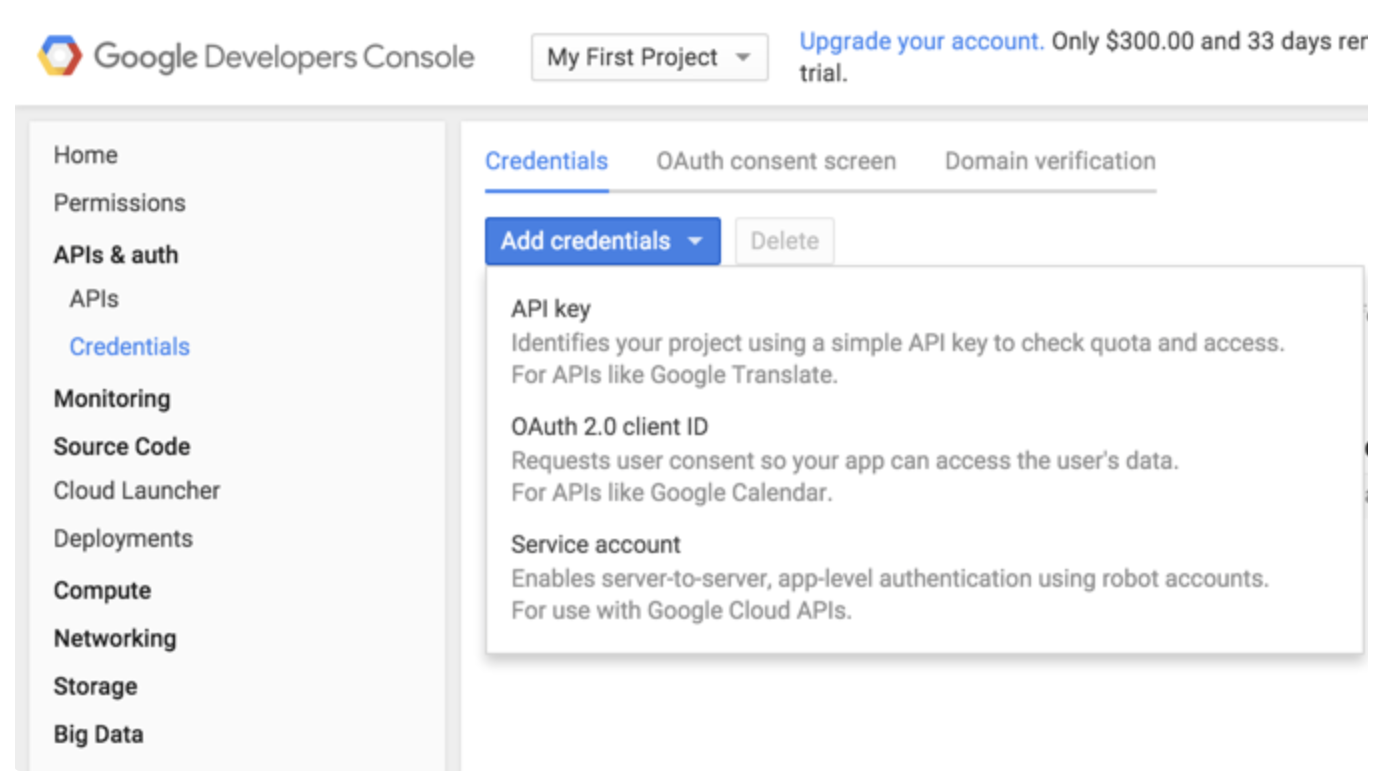 4. GoogleがJSON形式のキータイプを推奨しており、これを選択します。キーはブラウザによって自動的にダウンロードされます。
4. GoogleがJSON形式のキータイプを推奨しており、これを選択します。キーはブラウザによって自動的にダウンロードされます。
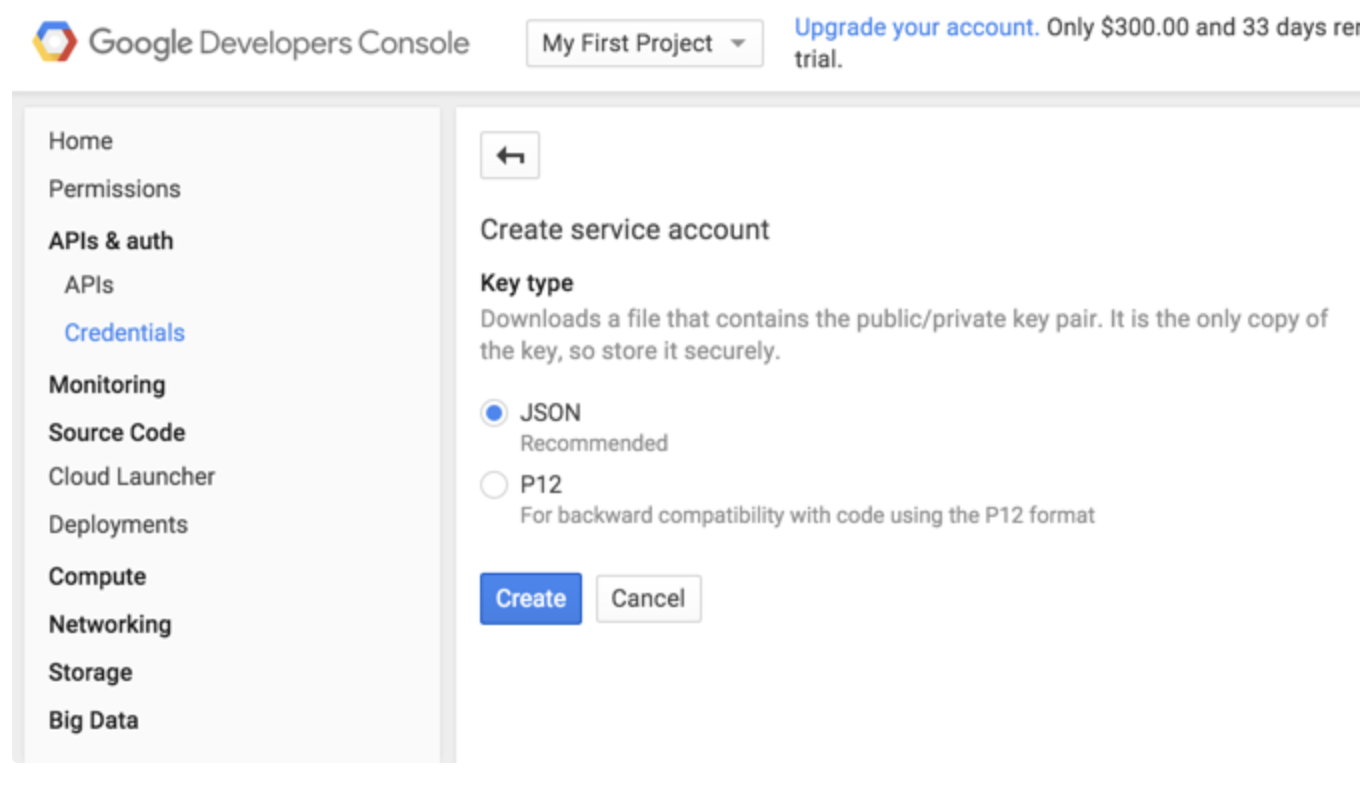
- Google Developer Consoleに移動します。
- Homeを選択します。
- Project IDを確認します。
BigQueryコンソールからDatasetとTableを作成します。
- TD Consoleに移動します。
- Integrations Hub > Catalogに移動します。
- Google Big Query V2を選択します。
 4. 次のようにすべての情報を入力します:
4. 次のようにすべての情報を入力します:
TD Consoleは、データをエクスポートする複数の方法をサポートしています。Data Workbenchからデータをエクスポートするには、次の手順に従います。
- Data Workbench > Queriesに移動します。
- New Queryを選択し、クエリを定義します。
- Export Resultsを選択して、データのエクスポートを設定します。
- 既存のSnapchat CAPI認証を選択するか、前述の手順で新しい認証を作成します
- Doneを選択します。
| フィールド | 説明 |
|---|---|
| Data Sync Mode | データが宛先テーブルにどのように書き込まれるかを決定します。利用可能なオプション: Append Mode: クエリ結果の新しいデータを既存のテーブルに追加し、既存のレコードを変更しません。 Replace Mode: 既存の宛先テーブルを完全に削除し、クエリ結果のスキーマとデータを使用して新しいテーブルを作成します。 Truncate Mode: 既存のテーブル構造を保持しながらすべてのデータを削除し、クエリ結果から新しいデータを挿入します。既存のテーブルスキーマが維持され、クエリ結果またはJSON Schema Fileからのスキーマ定義は無視されます。 Replace_Backup: バックアップ方法を通じて既存のデータを安全に保持しながら宛先テーブルを置き換えます。このモードを選択すると、バックアップ方法を選択するための追加フィールド「Table Backup Operation Type」が表示されます。 |
| Table Backup Operation Type(Replace_Backupモードを選択した場合のみ表示) | 置き換え前に既存のテーブルをバックアップする方法を指定します。2つのオプションがあります: Existing Table Rename: タイムスタンププレフィックス(例:backup_{timestamp}_)を付けて既存のテーブルの名前を変更することで、編集可能なバックアップを作成します。その後、クエリ結果のスキーマを使用して元の名前で新しいテーブルが作成され、クエリ結果からデータがロードされます。 Existing Table Snapshot: BigQueryのスナップショット機能を使用して、既存のテーブルの読み取り専用のポイントインタイムコピーを作成します。スナップショットの作成後、既存のテーブルが削除され、クエリ結果のスキーマとデータを使用して新しいテーブルが作成されます。この方法はストレージ効率が高いですが、バックアップは読み取り専用です。 |
| Google Cloud Project ID | BigQueryデータセットが存在するGoogle CloudプロジェクトのユニークID。これはGoogle Developer Consoleページの上部で確認できます。 |
| Dataset Name | データを保存するBigQueryデータセットの名前。これはGoogle Cloudプロジェクト内のテーブルのコレクションです。 |
| Data Location | BigQueryデータが保存される地理的な場所を指定します。データレジデンシー要件にとって重要です。データをUSまたはEUマルチリージョン以外に保存する必要がある場合は、場所を明示的に指定する必要があります。 |
| Table Name | データが書き込まれる、選択したデータセット内の特定のテーブルの名前。 |
| Auto-create table? | チェックすると、宛先テーブルが存在しない場合にシステムが自動的に作成します。このオプションはTruncate同期モードでは無視されます。 |
| Add missing columns? | 有効にすると、宛先テーブルに存在しないソースデータの列が追加されます。無効にすると、これらの列は無視されます。 |
| Json Schema File | JSON形式を使用してデータの構造を定義し、列名、データ型、制約を指定します。各列定義には名前と型フィールドが必要です。例では、REQUIREDとしてマークされたINTEGER型の「id」フィールドと、STRING型の「comment」フィールドを持つスキーマを示しています。 |
| Skip on invalid records? | 有効にすると、検証に失敗したレコードに遭遇してもジョブは処理を続行し、無効なレコードをスキップします。無効にすると、無効なレコードに遭遇した場合にジョブは完全に停止します。 |
コネクターは、複数のソースからのスキーマを調和させて最終的なテーブル構造またはスキーマを決定する、スキーマ調整または統合プロセスを実装します。このプロセスは、設定された同期モードとユーザー設定に基づいてスキーマ進化シナリオをサポートしながら、データの整合性を保証します。
コネクターは、階層順に3つの潜在的なスキーマソースを評価することで、最終的なテーブルスキーマを決定します。この階層は、データスキーマが宛先BigQueryテーブルでどのように具現化されるかを理解するために重要です。
- 宛先テーブルスキーマ(最高優先順位)
宛先テーブルが存在する場合、そのスキーマはデータロード操作の主要な権限として機能します。
適用される場合:
- 既存のテーブルへのAPPEND操作中
- TRUNCATE操作中
実例:数値型の処理
- クエリ結果データ
| user_id | transaction_amount | transaction_date |
|---|---|---|
| 1001 | 99.99 | 2024-01-15 |
| 1002 | 150.50 | 2024-01-16 |
宛先テーブルスキーマ
user_id: INT64transaction_amount: NUMERIC(38,9)transaction_date: DATE
結果: クエリ結果データがtransaction_amountに対してFLOAT64として提供される場合でも、宛先スキーマに従ってNUMERICに変換されます。
- ユーザー定義のJSONスキーマ(第2優先順位)
JSON Schema File設定を通じて提供される場合、このスキーマはクエリ結果からの型推論を上書きし、明示的な列定義を提供します。
適用される場合:
- テーブル作成中(新しいテーブル)
- 既存のテーブルに新しい列を追加する場合
- 明示的な型キャストと列プロパティ定義の場合
実例:タイムスタンプと日付の変換
- ソースデータ
| event_time | registration_date |
|---|---|
| 2024-01-15 14:30:00 | 2024-01-15 14:30:00+02:00 |
| 2024-01-16 09:15:00 | 2024-01-16 09:15:00+08:00 |
ユーザー定義スキーマ
event_time: TIMESTAMPregistration_date: DATE効果
event_time:
- ソースデータはTIMESTAMPとして解析されます
- マイクロ秒の精度を維持します
- UTCで保存されます
- クエリ結果スキーマ(最低優先順位)
ソースデータ構造から派生したスキーマ。他のスキーマが指定されていない場合のベースラインスキーマとして機能します。
適用される場合:
- JSONスキーマ定義なしで新しいテーブルを作成する場合
- 明示的な型定義なしで新しい列を追加する場合
- オーバーライドが存在しない場合の型推論のソースとして
実例:整数から文字列への変換
- クエリ結果データ
| product_id | status_code |
|---|---|
| "SKU-001" | 200 |
| "SKU-002" | 404 |
クエリ結果スキーマ
product_id: STRINGstatus_code: Int可能な変換先
- status_code as STRING:
- INT64 → STRING(互換性のある変換)
- 結果: "200", "404"
- status_code as INT64:
- 元の型を維持
- 結果: 200, 404
以下は、同期モード、テーブルの状態、設定によってスキーマがどのように処理されるかを示す構造化された参照表です。
| Sync Mode | Destination Table | Add Missing Columns | Column Type | Schema Handling Logics |
|---|---|---|---|---|
| Append | Exists | Enabled | 宛先テーブルの元の列 | 宛先テーブルスキーマを使用 |
| クエリ結果データからの新しい列 | クエリ結果 + ユーザー定義スキーマを使用 | |||
| Disabled | 宛先テーブルの元の列 | 宛先テーブルスキーマを使用 | ||
| クエリ結果データからの新しい列 | これらの列を無視 | |||
| Create New | N/A | すべての列 | クエリ結果 + ユーザー定義スキーマを使用 | |
| Replace/Replace_Backup | Exists | N/A | すべての列 | クエリ結果 + ユーザー定義スキーマを使用 |
| Create New | N/A | すべての列 | クエリ結果 + ユーザー定義スキーマを使用 | |
| Truncate | Exists | Enabled | 宛先テーブルの元の列 | 宛先テーブルスキーマを使用 |
| クエリ結果データからの新しい列 | クエリ結果 + ユーザー定義スキーマを使用 | |||
| Disabled | 宛先テーブルの元の列 | 宛先テーブルスキーマを使用 | ||
| クエリ結果データからの新しい列 | これらの列を無視 | |||
| Create New | N/A | すべての列 | エラー: テーブルが存在する必要があります |
コネクターは、ソースデータ型とBigQueryネイティブ型の間の包括的な型システムマッピングを実装しており、3つのカテゴリーの変換があります:
- デフォルトマッピング(ロスレス変換)
| Query Result Type | BigQuery Type | 実装の詳細 |
|---|---|---|
| int32/int64 | INT64 | ネイティブBigQuery整数、64ビット符号付き |
| double | FLOAT64 | IEEE 754倍精度浮動小数点 |
| boolean | BOOL | 1ビットブール値 |
| timestamp | TIMESTAMP | マイクロ秒の精度、UTCタイムゾーン |
| string | STRING | UTF-8エンコードされた文字シーケンス |
- 互換性のあるマッピング(型強制)
| Query Result Type | BigQuery Type | 技術実装 |
|---|---|---|
| int64 | NUMERIC | 精度: 38桁、スケール: 9桁の小数点以下 |
| int64 | BIGNUMERIC | 精度: 76.76桁、スケール: 38桁の小数点以下 |
| double | STRING | 完全な精度でtoString()を使用してフォーマット |
| boolean | STRING | リテラル「true」/「false」表現 |
| timestamp | STRING | タイムゾーン付きISO 8601形式 |
- 潜在的にロスのあるマッピング(検証が必要)
| Query Result Type | BigQuery Type | データ損失の考慮事項 |
|---|---|---|
| timestamp | DATE | 時刻コンポーネントを切り捨て、タイムゾーン情報が失われる |
| string | DATE | 'YYYY-MM-DD'と一致する必要があり、無効な形式はNULLになる |
| FLOAT64 | INT64 | 小数点の切り捨て、精度が失われる可能性 |
| TIMESTAMP | DATE | 時間の粒度が失われ、タイムゾーンの正規化が行われる |
Scheduled Jobs と Result Export を使用して、指定したターゲット宛先に出力結果を定期的に書き込むことができます。
Treasure Data のスケジューラー機能は、高可用性を実現するために定期的なクエリ実行をサポートしています。
2 つの仕様が競合するスケジュール仕様を提供する場合、より頻繁に実行するよう要求する仕様が優先され、もう一方のスケジュール仕様は無視されます。
例えば、cron スケジュールが '0 0 1 * 1' の場合、「月の日」の仕様と「週の曜日」が矛盾します。前者の仕様は毎月 1 日の午前 0 時 (00:00) に実行することを要求し、後者の仕様は毎週月曜日の午前 0 時 (00:00) に実行することを要求するためです。後者の仕様が優先されます。
Data Workbench > Queries に移動します
新しいクエリを作成するか、既存のクエリを選択します。
Schedule の横にある None を選択します。

ドロップダウンで、次のスケジュールオプションのいずれかを選択します:
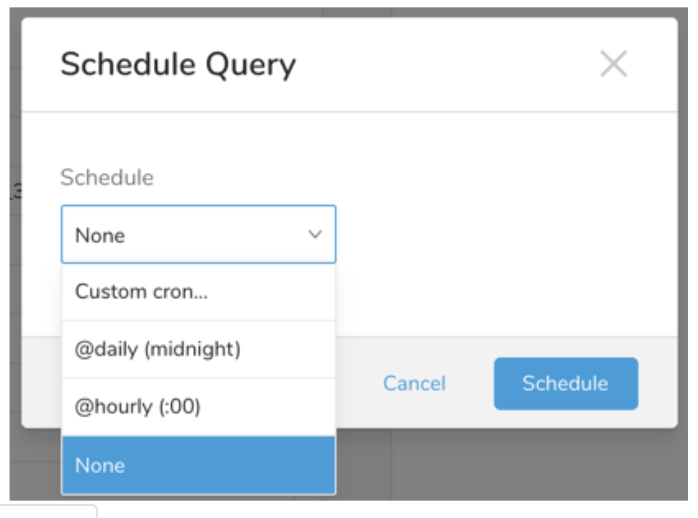
ドロップダウン値 説明 Custom cron... Custom cron... の詳細を参照してください。 @daily (midnight) 指定されたタイムゾーンで 1 日 1 回午前 0 時 (00:00 am) に実行します。 @hourly (:00) 毎時 00 分に実行します。 None スケジュールなし。
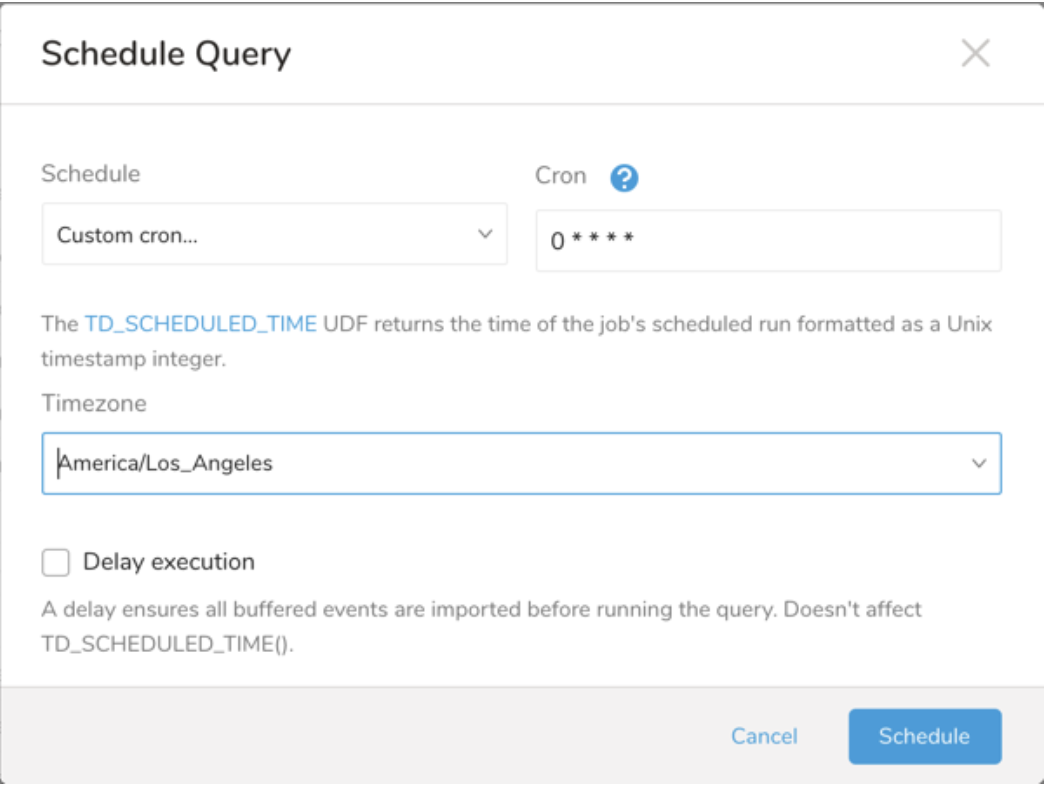
| Cron 値 | 説明 |
|---|---|
0 * * * * | 1 時間に 1 回実行します。 |
0 0 * * * | 1 日 1 回午前 0 時に実行します。 |
0 0 1 * * | 毎月 1 日の午前 0 時に 1 回実行します。 |
| "" | スケジュールされた実行時刻のないジョブを作成します。 |
* * * * *
- - - - -
| | | | |
| | | | +----- day of week (0 - 6) (Sunday=0)
| | | +---------- month (1 - 12)
| | +--------------- day of month (1 - 31)
| +-------------------- hour (0 - 23)
+------------------------- min (0 - 59)次の名前付きエントリを使用できます:
- Day of Week: sun, mon, tue, wed, thu, fri, sat.
- Month: jan, feb, mar, apr, may, jun, jul, aug, sep, oct, nov, dec.
各フィールド間には単一のスペースが必要です。各フィールドの値は、次のもので構成できます:
| フィールド値 | 例 | 例の説明 |
|---|---|---|
| 各フィールドに対して上記で表示された制限内の単一の値。 | ||
フィールドに基づく制限がないことを示すワイルドカード '*'。 | '0 0 1 * *' | 毎月 1 日の午前 0 時 (00:00) に実行するようにスケジュールを設定します。 |
範囲 '2-5' フィールドの許可される値の範囲を示します。 | '0 0 1-10 * *' | 毎月 1 日から 10 日までの午前 0 時 (00:00) に実行するようにスケジュールを設定します。 |
カンマ区切りの値のリスト '2,3,4,5' フィールドの許可される値のリストを示します。 | 0 0 1,11,21 * *' | 毎月 1 日、11 日、21 日の午前 0 時 (00:00) に実行するようにスケジュールを設定します。 |
周期性インジケータ '*/5' フィールドの有効な値の範囲に基づいて、 スケジュールが実行を許可される頻度を表現します。 | '30 */2 1 * *' | 毎月 1 日、00:30 から 2 時間ごとに実行するようにスケジュールを設定します。 '0 0 */5 * *' は、毎月 5 日から 5 日ごとに午前 0 時 (00:00) に実行するようにスケジュールを設定します。 |
'*' ワイルドカードを除く上記の いずれかのカンマ区切りリストもサポートされています '2,*/5,8-10' | '0 0 5,*/10,25 * *' | 毎月 5 日、10 日、20 日、25 日の午前 0 時 (00:00) に実行するようにスケジュールを設定します。 |
- (オプション) Delay execution を有効にすることで、クエリの開始時刻を遅延させることができます。
クエリに名前を付けて保存して実行するか、単にクエリを実行します。クエリが正常に完了すると、クエリ結果は指定された宛先に自動的にエクスポートされます。
設定エラーにより継続的に失敗するスケジュールジョブは、複数回通知された後、システム側で無効化される場合があります。
(オプション) Delay execution を有効にすることで、クエリの開始時刻を遅延させることができます。
Audience Studio で activation を作成することで、segment データをターゲットプラットフォームに送信することもできます。
- Audience Studio に移動します。
- parent segment を選択します。
- ターゲット segment を開き、右クリックして、Create Activation を選択します。
- Details パネルで、Activation 名を入力し、前述の Configuration Parameters のセクションに従って activation を設定します。
- Output Mapping パネルで activation 出力をカスタマイズします。

- Attribute Columns
- Export All Columns を選択すると、変更を加えずにすべての列をエクスポートできます。
- + Add Columns を選択して、エクスポート用の特定の列を追加します。Output Column Name には、Source 列名と同じ名前があらかじめ入力されます。Output Column Name を更新できます。+ Add Columns を選択し続けて、activation 出力用の新しい列を追加します。
- String Builder
- + Add string を選択して、エクスポート用の文字列を作成します。次の値から選択します:
- String: 任意の値を選択します。テキストを使用してカスタム値を作成します。
- Timestamp: エクスポートの日時。
- Segment Id: segment ID 番号。
- Segment Name: segment 名。
- Audience Id: parent segment 番号。
- + Add string を選択して、エクスポート用の文字列を作成します。次の値から選択します:
- Schedule を設定します。

- スケジュールを定義する値を選択し、オプションでメール通知を含めます。
- Create を選択します。
batch journey の activation を作成する必要がある場合は、Creating a Batch Journey Activation を参照してください。
CLI(Toolbelt)を使用してBigQueryに結果をエクスポートすることもできます。
td queryコマンドの*--resultオプションを使用して、Snapchatサーバーへのエクスポート情報を指定する必要があります。td query*コマンドの詳細については、この記事を参照してください。
オプションの形式はJSONで、一般的な構造は次のとおりです。
APPENDモード:
type: 'bigquery_v2'
json_keyfile: |
{
"type": "service_account",
"private_key_id": "xxx",
"private_key": "-----BEGIN PRIVATE KEY-----xxx-----END PRIVATE KEY-----\n",
"client_email": "account@xxx.iam.gserviceaccount.com",
"client_id": "xxx",
"auth_uri": "https://accounts.google.com/o/oauth2/auth",
"token_uri": "https://accounts.google.com/o/oauth2/token",
"auth_provider_x509_cert_url": "https://www.googleapis.com/oauth2/v1/certs",
"client_x509_cert_url": "https://www.googleapis.com/robot/v1/metadata/x509/account%40xxx.iam.gserviceaccount.com"
}
mode: APPEND
project: gcp project id
dataset: bigquery dataset
table: bigquery table
location: gcp location
auto_create_table: true
add_missing_columns: true
schema_file: |
[
{"name": "c1", "type": "STRING", "mode": "NULLABLE"},
{"name": "c2", "type": "INTEGER", "mode": "REQUIRED"}
]
skip_invalid_records: trueREPLACEモード:
type: 'bigquery_v2'
json_keyfile: |
{
"type": "service_account",
"private_key_id": "xxx",
"private_key": "-----BEGIN PRIVATE KEY-----xxx-----END PRIVATE KEY-----\n",
"client_email": "account@xxx.iam.gserviceaccount.com",
"client_id": "xxx",
"auth_uri": "https://accounts.google.com/o/oauth2/auth",
"token_uri": "https://accounts.google.com/o/oauth2/token",
"auth_provider_x509_cert_url": "https://www.googleapis.com/oauth2/v1/certs",
"client_x509_cert_url": "https://www.googleapis.com/robot/v1/metadata/x509/account%40xxx.iam.gserviceaccount.com"
}
mode: REPLACE
project: gcp project id
dataset: bigquery dataset
table: bigquery table
location: gcp location
auto_create_table: true
add_missing_columns: true
schema_file: |
[
{"name": "c1", "type": "STRING", "mode": "NULLABLE"},
{"name": "c2", "type": "INTEGER", "mode": "REQUIRED"}
]
skip_invalid_records: trueREPLACE_BACKUPモード:
type: 'bigquery_v2'
json_keyfile: |
{
"type": "service_account",
"private_key_id": "xxx",
"private_key": "-----BEGIN PRIVATE KEY-----xxx-----END PRIVATE KEY-----\n",
"client_email": "account@xxx.iam.gserviceaccount.com",
"client_id": "xxx",
"auth_uri": "https://accounts.google.com/o/oauth2/auth",
"token_uri": "https://accounts.google.com/o/oauth2/token",
"auth_provider_x509_cert_url": "https://www.googleapis.com/oauth2/v1/certs",
"client_x509_cert_url": "https://www.googleapis.com/robot/v1/metadata/x509/account%40xxx.iam.gserviceaccount.com"
}
mode: REPLACE_BACKUP
backup_mode: TABLE_RENAME
project: gcp project id
dataset: bigquery dataset
table: bigquery table
location: gcp location
auto_create_table: true
add_missing_columns: true
schema_file: |
[
{"name": "c1", "type": "STRING", "mode": "NULLABLE"},
{"name": "c2", "type": "INTEGER", "mode": "REQUIRED"}
]
skip_invalid_records: trueTRUNCATEモード:
type: 'bigquery_v2'
json_keyfile: |
{
"type": "service_account",
"private_key_id": "xxx",
"private_key": "-----BEGIN PRIVATE KEY-----xxx-----END PRIVATE KEY-----\n",
"client_email": "account@xxx.iam.gserviceaccount.com",
"client_id": "xxx",
"auth_uri": "https://accounts.google.com/o/oauth2/auth",
"token_uri": "https://accounts.google.com/o/oauth2/token",
"auth_provider_x509_cert_url": "https://www.googleapis.com/oauth2/v1/certs",
"client_x509_cert_url": "https://www.googleapis.com/robot/v1/metadata/x509/account%40xxx.iam.gserviceaccount.com"
}
mode: TRUNCATE
project: gcp project id
dataset: bigquery dataset
table: bigquery table
location: gcp location
auto_create_table: true
add_missing_columns: true
schema_file: |
[
{"name": "c1", "type": "STRING", "mode": "NULLABLE"},
{"name": "c2", "type": "INTEGER", "mode": "REQUIRED"}
]
skip_invalid_records: true| Name | Description | Value | Default Value | Required |
|---|---|---|---|---|
| type | コネクタータイプ | bigquery_v2 | N/A | Yes |
| json_keyfile | GCP JSON keyfile | JSON形式 | N/A | Yes |
| mode | エクスポートモード | サポートされるモード: - APPEND - REPLACE - REPLACE_BACKUP - TRUNCATE | APPEND | Yes |
| backup_mode | BigQueryでのテーブルのバックアップ | サポートされる値: - TABLE_RENAME - TABLE_SNAPSHOT | TABLE_RENAME | modeがREAPLCE_BACKUPの場合はYes |
| project | GCPプロジェクトID | N/A | N/A | Yes |
| dataset | BigQueryデータセット | N/A | N/A | Yes |
| table | BigQueryテーブル | N/A | N/A | Yes |
| location | BigQueryデータの場所 | N/A | N/A | No |
| auto_create_table | テーブルが存在しない場合にBigQueryで自動作成を許可します。このオプションはTRUNCATEモードではサポートされません | true/false | false | No |
| add_missing_columns | BigQueryテーブルに存在しない追加の列を許可します。 | true/false | false | No |
| skip_invalid_records | 無効なレコードを処理するときにジョブを継続または停止するフラグ。 | true/false | true | No |
APPENDモード
$ td query --result '{"type": "bigquery_v2", "td_authentication_id": 123456, "mode": "APPEND", "project": "gcp_project_id", "dataset": "bg_dataset", "table": "bg_table", "location": "US", "auto_create_table": true, "add_missing_columns": true, "schema_file": "[{\"name\": \"c1\", \"type\": \"INTEGER\"}, {\"name\": \"c2\", \"type\": \"STRING\"}]", "skip_invalid_records":true}' -d sample_datasets "select ........ from ........" -T prestoREPLACEモード
$ td query --result '{"type": "bigquery_v2", "td_authentication_id": 123456, "mode": "REPLACE", "project": "gcp_project_id", "dataset": "bg_dataset", "table": "bg_table", "location": "US", "auto_create_table": true, "add_missing_columns": true, "schema_file": "[{\"name\": \"c1\", \"type\": \"INTEGER\"}, {\"name\": \"c2\", \"type\": \"STRING\"}]", "skip_invalid_records":true}' -d sample_datasets "select ........ from ........" -T prestoREPLACE_BACKUPモード
$ td query --result '{"type": "bigquery_v2", "td_authentication_id": 123456, "mode": "REPLACE_BACKUP", "backup_mode": "TABLE_RENAME", "project": "gcp_project_id", "dataset": "bg_dataset", "table": "bg_table", "location": "US", "auto_create_table": true, "add_missing_columns": true, "schema_file": "[{\"name\": \"c1\", \"type\": \"INTEGER\"}, {\"name\": \"c2\", \"type\": \"STRING\"}]", "skip_invalid_records":true}' -d sample_datasets "select ........ from ........" -T prestoTRUNCATEモード
$ td query --result '{"type": "bigquery_v2", "td_authentication_id": 123456, "mode": "TRUNCATE", "project": "gcp_project_id", "dataset": "bg_dataset", "table": "bg_table", "location": "US", "auto_create_table": true, "add_missing_columns": true, "schema_file": "[{\"name\": \"c1\", \"type\": \"INTEGER\"}, {\"name\": \"c2\", \"type\": \"STRING\"}]", "skip_invalid_records":true}' -d sample_datasets "select ........ from ........" -T presto- Result Exportをスケジュールして、定期的にターゲット先にデータをアップロードできます。
- すべてのインポートおよびエクスポート統合は、TD Workflowに追加できます。tdデータオペレーターは、クエリ結果を指定された統合にエクスポートできます。詳細については、Reference for Treasure Data Operatorsを参照してください。