Snowflake Import Integrationについて詳しく見る。
ジョブの結果を直接Snowflakeに書き込むことができます。たとえば、複数のソースからTreasure Dataにデータを統合し、クエリを実行してデータを整理した後、コネクタを適用したジョブを使用してSnowflakeにデータをエクスポートできます。
- TD Toolbeltを含むTreasure Dataの基本知識。
- Snowflakeアカウント。
Treasure Data Consoleを使用して接続を設定できます。
Treasure Data Connectionsにアクセスし、Snowflakeを検索して選択します。
次のダイアログが開きます。
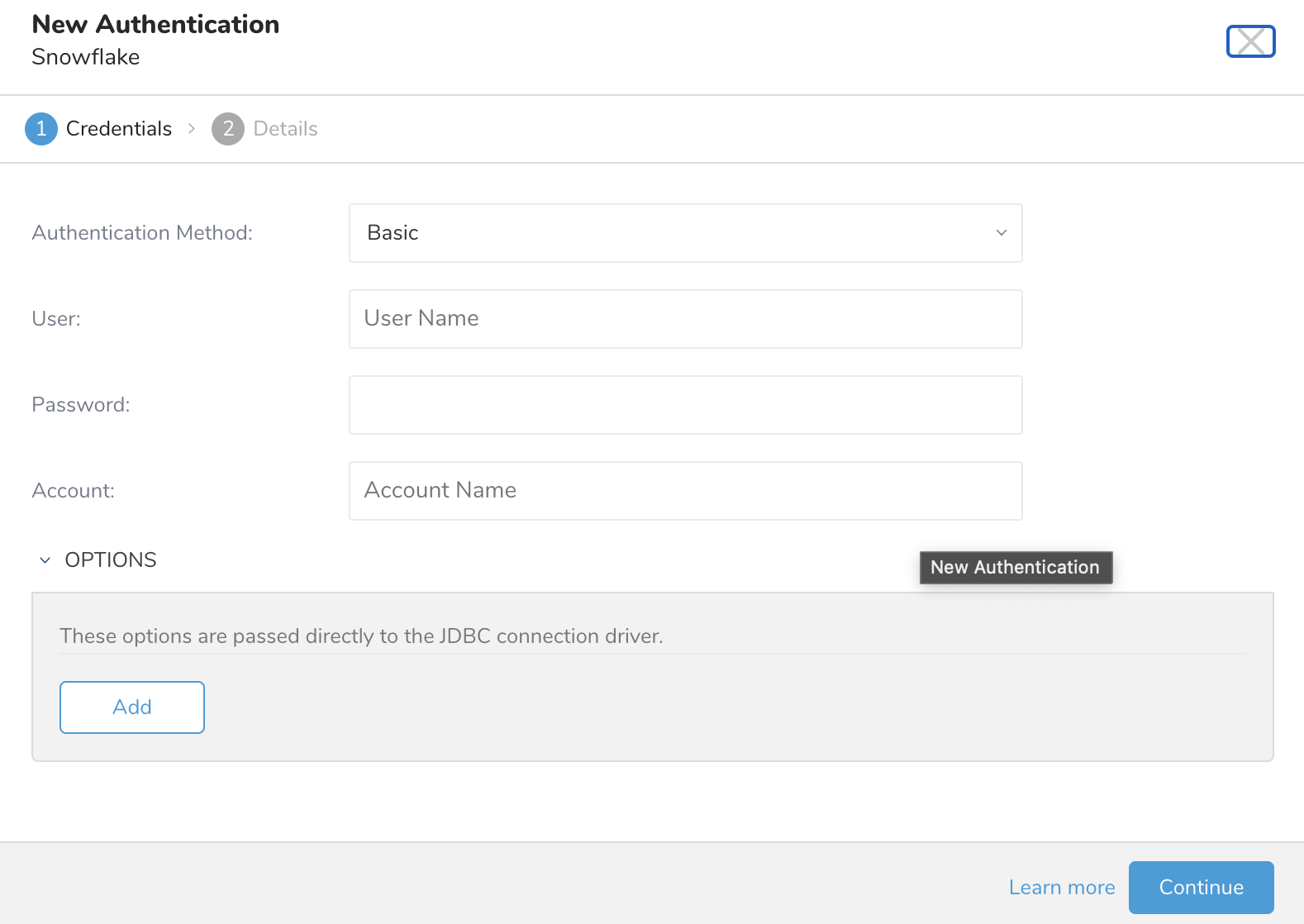
Authentication Methodを選択します:
Basic: 必要な認証情報を入力します: User、Password、Accountを使用してTreasure DataをSnowflakeに認証します。
- User: Snowflakeログインユーザー名。
- Password: Snowflakeログインパスワード。
Key Pair: Private KeyとそのPassphraseを入力します(暗号化された秘密鍵の場合)
- Private Key: 生成した秘密鍵。configuring-key-pair-authenticationを参照してください
- Passphrase: 秘密鍵のパスフレーズ、または秘密鍵が暗号化されていない場合は空のままにします。
- User: Snowflakeログインユーザー名。
Account: Snowflakeから提供されたアカウント名。Snowflakeでアカウント名を見つける方法を参照してください。
OPTIONS: このオプションはこのコネクタではサポートされていません。
必要な認証情報を入力します: User、Password、Snowflake Accountを使用してTreasure DataをSnowflakeに認証します。
次にContinueを選択し、接続に名前を付けます:
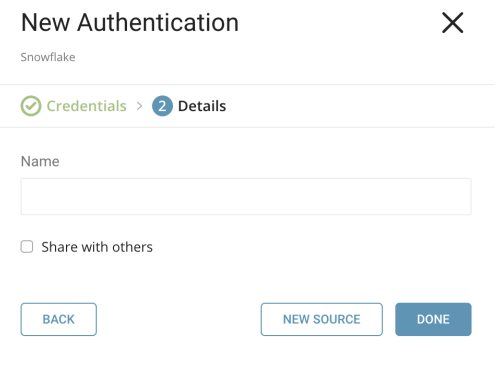
Doneを選択します。
データ接続を設定するクエリを作成または再利用します。
場合によっては、クエリ内でカラムマッピングを定義する必要があります。
Treasure Data consoleにアクセスします。Query Editorに移動します。データをエクスポートするために使用する予定のクエリにアクセスします。
場合によっては、クエリ内でカラムマッピングを定義する必要があります。
例:
WITH sample_data (
c_id,
c_double,
c_long,
c_string,
c_boolean,
c_timestamp,
c_json
) AS (
VALUES
(1, 100.0000, 10, 'T4', TRUE, '2018-01-01', '{ "name":"John"}'),
(2, 100.0000, 99, 'P@#4', FALSE, '2018-01-01', '{ "name":"John"}'),
(3, 100.1234, 22, 'C!%^&*', FALSE, '2018-01-01', '{ "name":"John"}')
)
SELECT
c_id,
c_double,
c_long,
c_string,
c_boolean,
c_timestamp,
c_json
FROM sample_data;クエリエディタの上部にあるOutput Resultsを選択します。Choose Saved Connectionダイアログが開きます。
検索ボックスに接続名を入力してフィルタリングし、接続を選択します。
Snowflake接続を選択すると、ConfigurationまたはExport Resultsダイアログペインが表示されます:
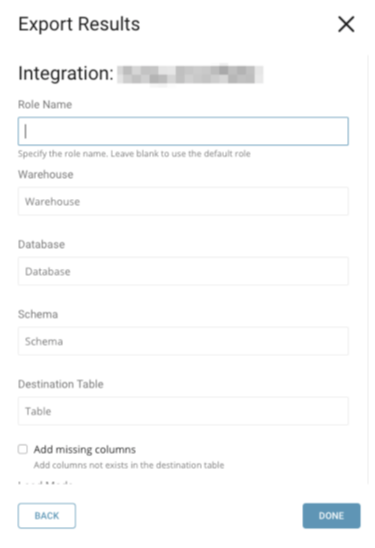
パラメータを指定します。パラメータは次のとおりです:
- Role Name (オプション): エクスポートに使用するデフォルトのアクセス制御ロール。ユーザーに既に割り当てられている既存のロールである必要があります。
- Warehouse (必須): 使用する仮想ウェアハウス。指定されたロールが権限を持つ既存のウェアハウスである必要があります。
- Database (必須): 使用するデータベース。指定されたロールが権限を持つ既存のデータベースである必要があります。
- Schema (必須): 指定されたデータベースに使用するスキーマ。指定されたロールが権限を持つ既存のスキーマである必要があります。
- Destination table (必須): 結果がエクスポートされるテーブル。存在しない場合は、新しいテーブルが作成されます。
- Add missing columns: ターゲットテーブルのカラムがTD結果のカラムより少ない場合、このオプションが選択されていない場合は例外がスローされます。選択されている場合、不足している新しいカラムがターゲットテーブルに追加されます。
- Load mode (必須): Snowflakeテーブルに結果を反映する3つのモードがあります: Append、Overwrite、Merge。Mergeが選択された場合、Merge Field(s)が表示されます。
- Append: TD結果はターゲットテーブルに追加されます
- Overwrite: ターゲットテーブルは削除され、その後TD結果がターゲットテーブルの先頭から追加されます
- Merge: ターゲットテーブルはMerge Fieldsからの条件に基づいてTD結果とマージされます。
- Merge Fields (マージモードの場合必須): ターゲットテーブルとTD結果を比較するために使用されるフィールド。これらのフィールドの値が等しい場合、ターゲットテーブルのレコードは上書きされ、そうでない場合は新しいレコードがターゲットテーブルに挿入されます。マージフィールドの形式はカンマ区切りのテキストフィールドです。
- Data type mapping: これは以下のセクションで説明されます。
これは、ターゲットテーブルが存在しない場合、または新しいカラムが追加される場合に、TD結果のタイプからターゲットテーブルへの1対1マッピングのテーブルです:
| TD results | Snowflake |
|---|---|
| string | STRING |
| double | FLOAT |
| long | BIGINT |
| timestamp | TIMESTAMP |
| boolean | BOOLEAN |
デフォルトとは異なる型を設定したい場合があります。データ型マッピングは、特定の列に特定の型(例:VARCHAR)を明示的に設定するために使用されます。データ型マッピングは、ターゲットテーブル内の列にのみ型を適用します。
データマッピングを使用する場合、以下が該当します:
- ターゲットテーブルが存在しない場合、エクスポートジョブは新しいターゲットテーブルを作成します。
- ターゲットテーブルにTDの結果と比較して十分な列がない場合、列を追加するように指定できます。
データ型マッピングパラメータの構文は:col_name_1: VARCHAR; col_name2: BIGINT です。列名とSnowflakeのデータ型を指定する必要があります。
Treasure DataのPrestoまたはHiveクエリを使用してデータをエクスポートする場合、JSONは完全にはサポートされていません。そのため、ターゲットテーブルが存在せず作成される場合、JSONデータ型の値はデフォルトで新しく作成されたターゲットテーブルにVARCHARとして保存されます。
代わりにJSON値を半構造化型として保存したい場合は、型マッピングを更新する必要があります。データマッピング構文を使用して半構造化データ型を指定します。例えば、次のクエリでは:
SELECT c_id, c_double, c_long, c_string, c_boolean, c_timestamp, c_json FROM (
VALUES (1, 100, 10, 'T4', true, '2018-01-01','{ "name":"John"}'),
(2, 100, 99, 'P@#4', false, '2018-01-01', '{ "name":"John"}'),
(3, 100.1234, 22, 'C!%^&*', false, '2018-01-01','{ "name":"John"}')
) tbl1 (c_id, c_double, c_long, c_string, c_boolean, c_timestamp, c_json)c_json 列にはJSONコンテンツが含まれていますが、Snowflake内のその c_json 列の型はデフォルトでVARCHARになります。SnowflakeでVARIANT型にしたい場合は、Data type mapping フィールドを c_json: VARIANT に更新して、c_json を明示的に VARIANT 型に設定します。
Scheduled Jobs と Result Export を使用して、指定したターゲット宛先に出力結果を定期的に書き込むことができます。
Treasure Data のスケジューラー機能は、高可用性を実現するために定期的なクエリ実行をサポートしています。
2 つの仕様が競合するスケジュール仕様を提供する場合、より頻繁に実行するよう要求する仕様が優先され、もう一方のスケジュール仕様は無視されます。
例えば、cron スケジュールが '0 0 1 * 1' の場合、「月の日」の仕様と「週の曜日」が矛盾します。前者の仕様は毎月 1 日の午前 0 時 (00:00) に実行することを要求し、後者の仕様は毎週月曜日の午前 0 時 (00:00) に実行することを要求するためです。後者の仕様が優先されます。
Data Workbench > Queries に移動します
新しいクエリを作成するか、既存のクエリを選択します。
Schedule の横にある None を選択します。

ドロップダウンで、次のスケジュールオプションのいずれかを選択します:
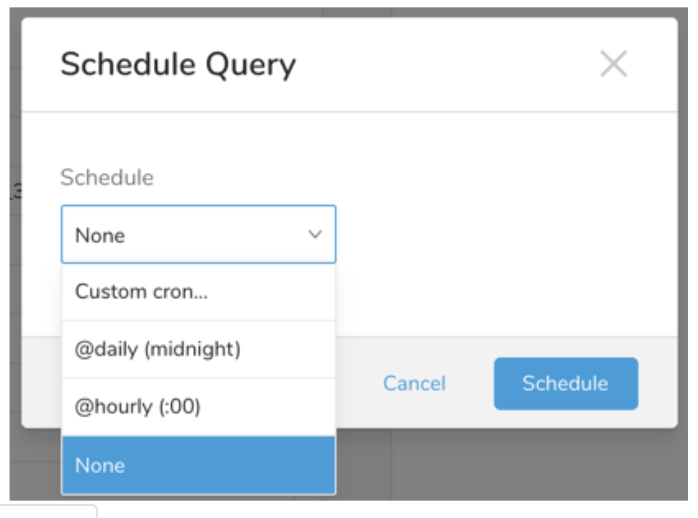
ドロップダウン値 説明 Custom cron... Custom cron... の詳細を参照してください。 @daily (midnight) 指定されたタイムゾーンで 1 日 1 回午前 0 時 (00:00 am) に実行します。 @hourly (:00) 毎時 00 分に実行します。 None スケジュールなし。
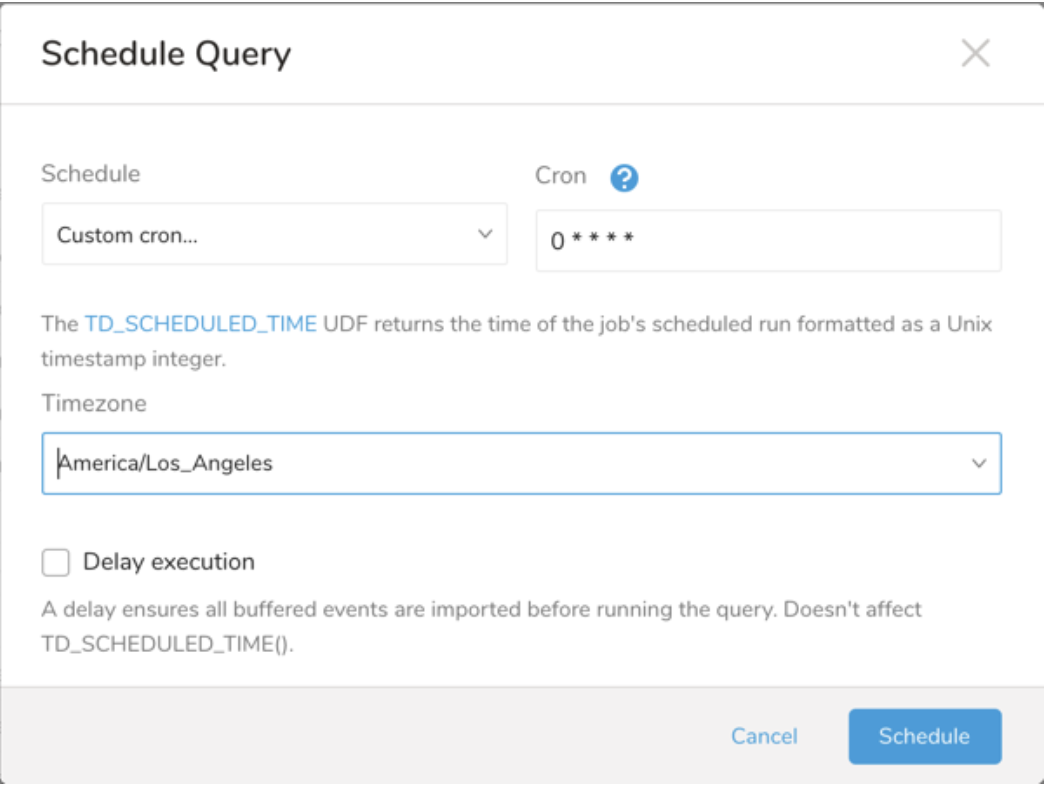
| Cron 値 | 説明 |
|---|---|
0 * * * * | 1 時間に 1 回実行します。 |
0 0 * * * | 1 日 1 回午前 0 時に実行します。 |
0 0 1 * * | 毎月 1 日の午前 0 時に 1 回実行します。 |
| "" | スケジュールされた実行時刻のないジョブを作成します。 |
* * * * *
- - - - -
| | | | |
| | | | +----- day of week (0 - 6) (Sunday=0)
| | | +---------- month (1 - 12)
| | +--------------- day of month (1 - 31)
| +-------------------- hour (0 - 23)
+------------------------- min (0 - 59)次の名前付きエントリを使用できます:
- Day of Week: sun, mon, tue, wed, thu, fri, sat.
- Month: jan, feb, mar, apr, may, jun, jul, aug, sep, oct, nov, dec.
各フィールド間には単一のスペースが必要です。各フィールドの値は、次のもので構成できます:
| フィールド値 | 例 | 例の説明 |
|---|---|---|
| 各フィールドに対して上記で表示された制限内の単一の値。 | ||
フィールドに基づく制限がないことを示すワイルドカード '*'。 | '0 0 1 * *' | 毎月 1 日の午前 0 時 (00:00) に実行するようにスケジュールを設定します。 |
範囲 '2-5' フィールドの許可される値の範囲を示します。 | '0 0 1-10 * *' | 毎月 1 日から 10 日までの午前 0 時 (00:00) に実行するようにスケジュールを設定します。 |
カンマ区切りの値のリスト '2,3,4,5' フィールドの許可される値のリストを示します。 | 0 0 1,11,21 * *' | 毎月 1 日、11 日、21 日の午前 0 時 (00:00) に実行するようにスケジュールを設定します。 |
周期性インジケータ '*/5' フィールドの有効な値の範囲に基づいて、 スケジュールが実行を許可される頻度を表現します。 | '30 */2 1 * *' | 毎月 1 日、00:30 から 2 時間ごとに実行するようにスケジュールを設定します。 '0 0 */5 * *' は、毎月 5 日から 5 日ごとに午前 0 時 (00:00) に実行するようにスケジュールを設定します。 |
'*' ワイルドカードを除く上記の いずれかのカンマ区切りリストもサポートされています '2,*/5,8-10' | '0 0 5,*/10,25 * *' | 毎月 5 日、10 日、20 日、25 日の午前 0 時 (00:00) に実行するようにスケジュールを設定します。 |
- (オプション) Delay execution を有効にすることで、クエリの開始時刻を遅延させることができます。
クエリに名前を付けて保存して実行するか、単にクエリを実行します。クエリが正常に完了すると、クエリ結果は指定された宛先に自動的にエクスポートされます。
設定エラーにより継続的に失敗するスケジュールジョブは、複数回通知された後、システム側で無効化される場合があります。
(オプション) Delay execution を有効にすることで、クエリの開始時刻を遅延させることができます。
Audience Studio で activation を作成することで、segment データをターゲットプラットフォームに送信することもできます。
- Audience Studio に移動します。
- parent segment を選択します。
- ターゲット segment を開き、右クリックして、Create Activation を選択します。
- Details パネルで、Activation 名を入力し、前述の Configuration Parameters のセクションに従って activation を設定します。
- Output Mapping パネルで activation 出力をカスタマイズします。

- Attribute Columns
- Export All Columns を選択すると、変更を加えずにすべての列をエクスポートできます。
- + Add Columns を選択して、エクスポート用の特定の列を追加します。Output Column Name には、Source 列名と同じ名前があらかじめ入力されます。Output Column Name を更新できます。+ Add Columns を選択し続けて、activation 出力用の新しい列を追加します。
- String Builder
- + Add string を選択して、エクスポート用の文字列を作成します。次の値から選択します:
- String: 任意の値を選択します。テキストを使用してカスタム値を作成します。
- Timestamp: エクスポートの日時。
- Segment Id: segment ID 番号。
- Segment Name: segment 名。
- Audience Id: parent segment 番号。
- + Add string を選択して、エクスポート用の文字列を作成します。次の値から選択します:
- Schedule を設定します。

- スケジュールを定義する値を選択し、オプションでメール通知を含めます。
- Create を選択します。
batch journey の activation を作成する必要がある場合は、Creating a Batch Journey Activation を参照してください。
Treasure Workflow内で、このデータコネクタを使用してデータを出力するように指定できます。
timezone: UTC
_export:
td:
database: sample_datasets
+td-result-into-snowflake:
td>: queries/sample.sql
result_connection: your_connection_name
result_settings:
role_name: role
warehouse: wh
schema: public
database: OUTPUT
table: TARGET_TABLE
mode: insert
is_add_missing_columns: falseワークフローでデータコネクタを使用してデータをエクスポートする方法について学習してください。
TD Toolbeltをインストールします。
td query コマンドの -r / --result オプションを使用して、Snowflake結果出力先を追加します:
$ td query -d mydb -w 'SELECT id, name FROM source_table' --type presto -r '{"type":"snowflake", "warehouse":"wh", "user":"owner", "account_name":"owner", "password":"********", "role_name":"role", "schema":"public", "database":"OUTPUT", "table":"TARGET_TABLE", "mode":"insert", "is_add_missing_columns":"false"}'warehouse、database などの一部のパラメータは自明であり、TD Console で使用されるパラメータと同じです(「パラメータを指定して接続を設定する」セクションで説明)。ただし、一部のパラメータはキーまたは値が異なります:
- mode (必須): mode の値は Load Mode パラメータの生の値です:
- insert: TD結果はターゲットテーブルに追加されます
- truncate_insert: ターゲットテーブルが消去され、TD結果がターゲットテーブルの先頭から追加されます。
- merge: ターゲットテーブルは、条件に基づいてTD結果とマージされます
- merge_keys: マージモードで比較するフィールド、Merge Field(s) と同じです。
- column_options: データ型マッピング。
td sched:create コマンドの -r / --result オプションを使用して、Snowflake結果出力先を追加します:
$ td sched:create every_6_mins "*/6 * * * *" -d mydb -w 'SELECT id, name FROM source_table' --type presto -r '{"type":"snowflake", "warehouse":"wh", "user":"owner", "account_name":"owner", "password":"********", "role_name":"role", "schema":"public", "database":"OUTPUT", "table":"TARGET_TABLE", "mode":"insert", "is_add_missing_columns":"false"}'データ型マッピングを参照してください
Result Outputでスケジュールジョブを使用して、指定したターゲット先に出力結果を定期的に書き込むことができます。
Snowflakeサーバーへの接続は、公式JDBCドライバを介して行われます。JDBCドライバは、デフォルトかつ必須としてSSLの使用を強制します(つまり、SSL = falseの接続は拒否されます)。