Snowflakeは、クラウドベースのデータプラットフォームを提供し、ほぼ無制限のスケール、同時実行性、パフォーマンスでデータの価値を引き出すことができます。Treasure DataのSnowflake連携により、Snowflakeテーブルに保存されているデータをTreasure Dataにインポートできます。また、Treasure DataのExport Integrationについても詳しく知ることができます。
- Treasure Dataの基本知識
- テーブル/ビューをクエリするための適切な権限を持つSnowflakeデータウェアハウスの既存アカウント
Integrations Hub > Catalogに移動して検索します。Snowflakeを選択します。
以下のダイアログが開きます。 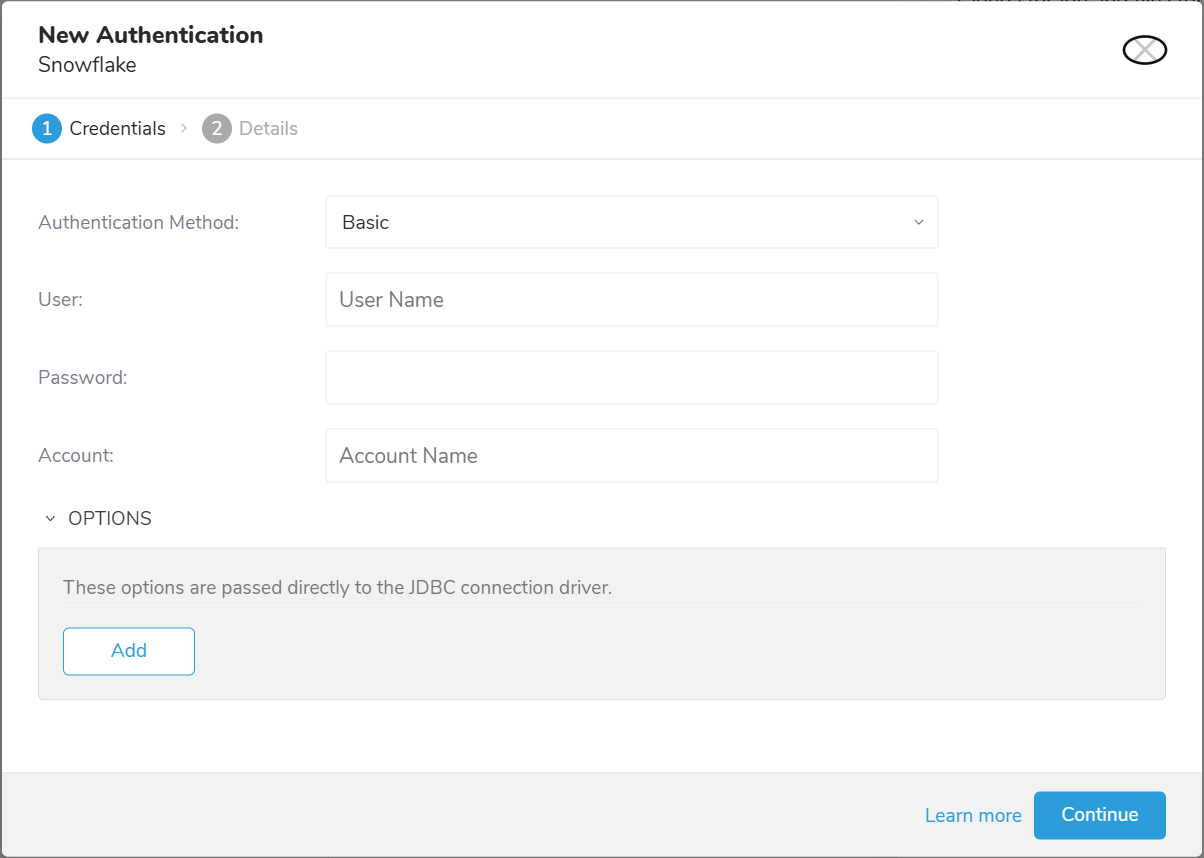
認証方法を選択します:
- Basic: Treasure DataがSnowflakeに認証するための必要な認証情報を入力します: User、Password、Account
- User: Snowflakeログインユーザー名
- Password: Snowflakeログインパスワード
- Key Pair: 暗号化された秘密鍵の場合はPrivate KeyとそのPassphraseを入力します
- Private Key: 生成された秘密鍵。configuring-key-pair-authenticationを参照してください
- Passphrase: 秘密鍵のパスフレーズ。秘密鍵が暗号化されていない場合は空欄のままにします
- User: Snowflakeログインユーザー名
- Account: Snowflakeから提供されたアカウント名。Snowflakeでアカウント名を見つける方法を参照してください
- OPTIONS: JDBC接続オプション(ある場合)
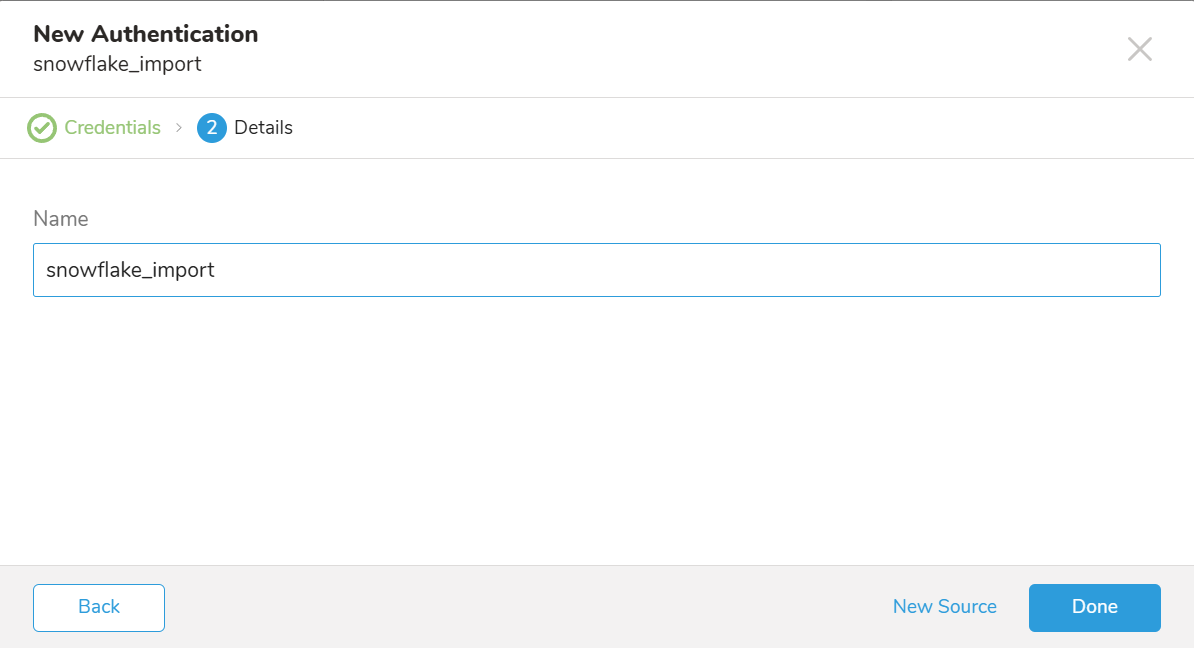
Continueを選択します。
データコネクタの名前を指定します。認証を他のユーザーと共有するかどうかを指定します。共有すると、他のチームメンバーがあなたの認証を使用してコネクタソースを作成できます。Doneを選択します。
AuthenticationsページでNew Sourceを作成します。
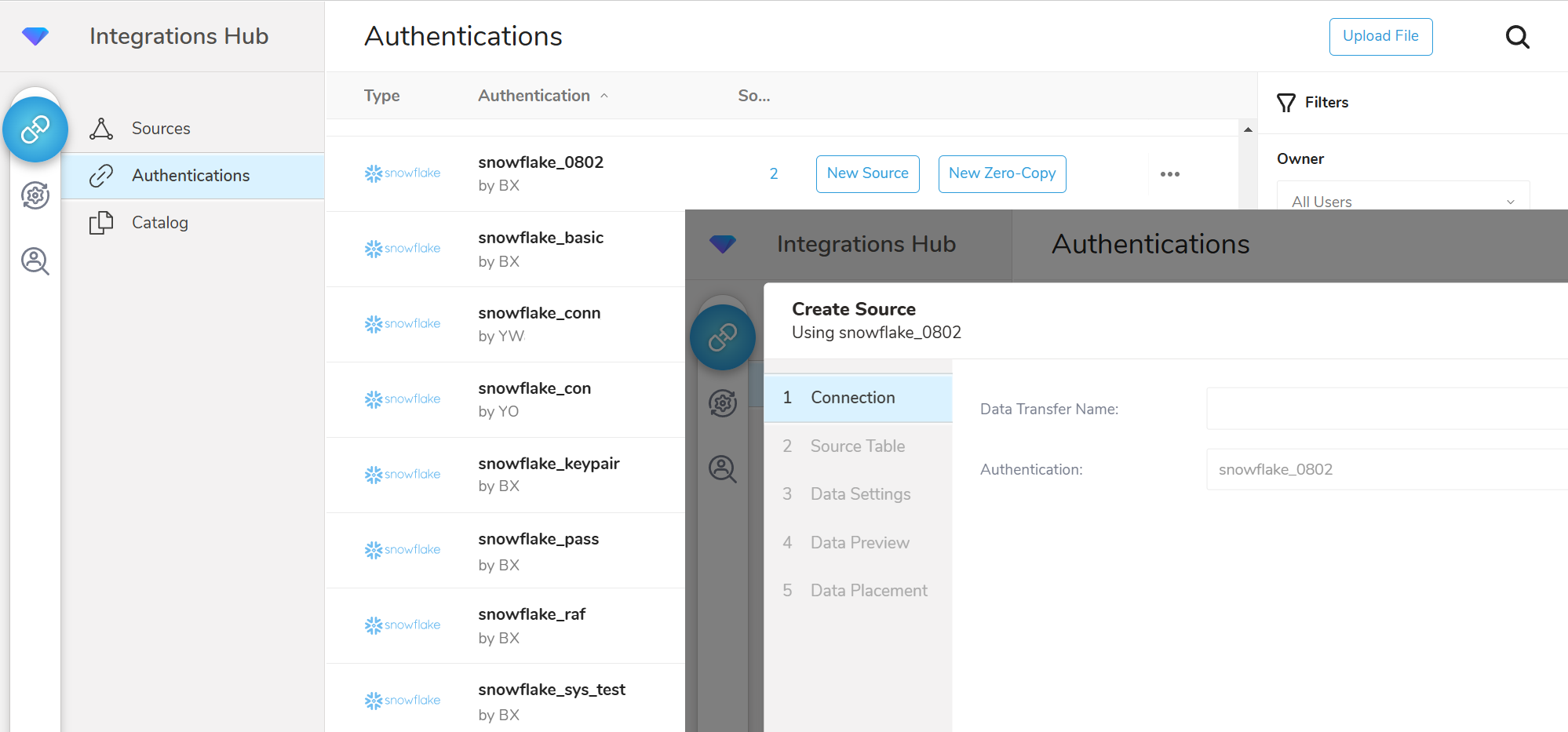
詳細を入力します。
取り込みたい情報を登録する必要があります。パラメータは以下の通りです:
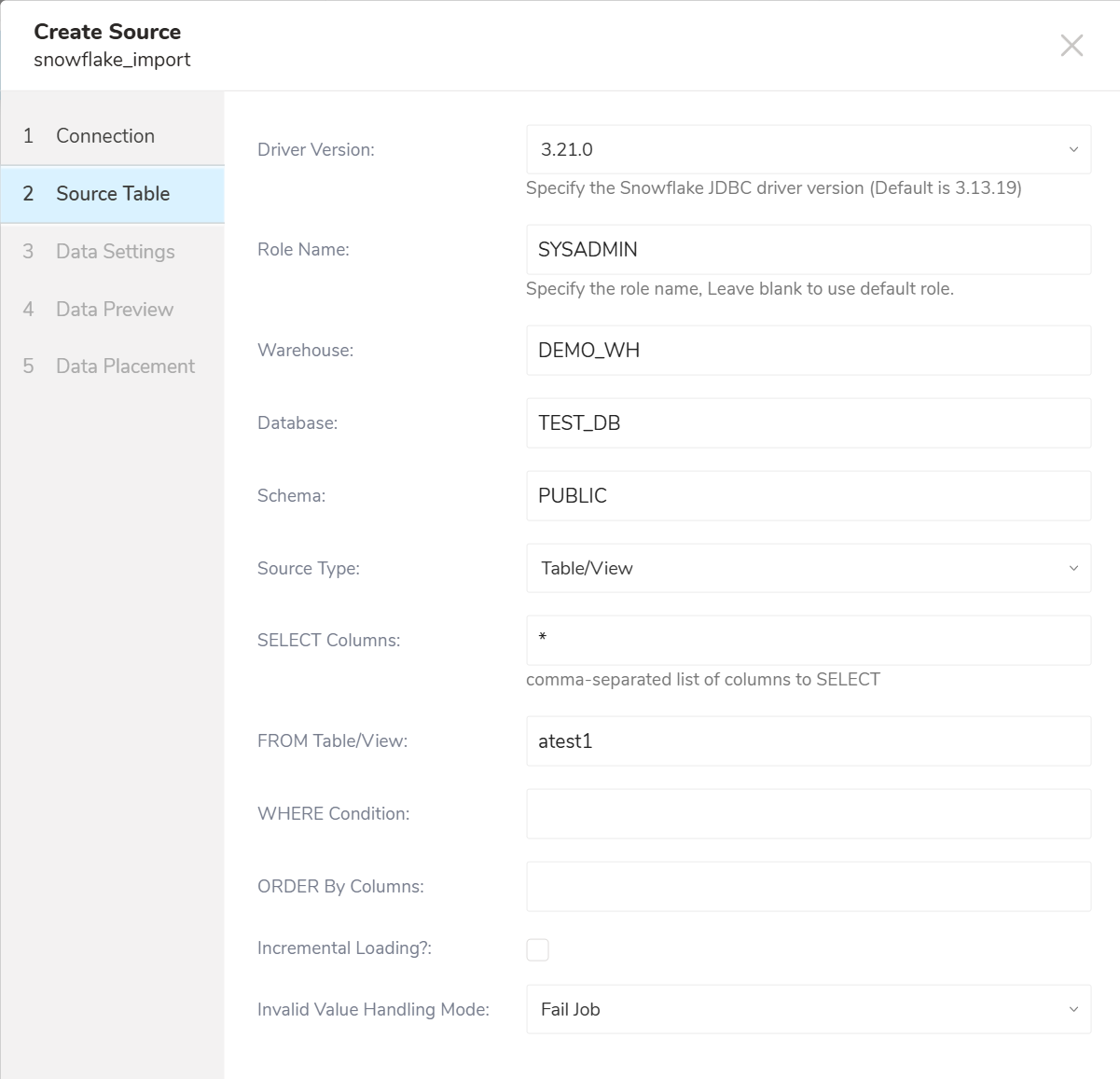
Drive Version: 使用するSnowflake JDBCドライバを指定します。オプションは以下の通りです
- 3.13.19(コネクタがデフォルトで使用する現在のバージョン)
- 3.14.3
- 3.21.0(最新バージョン)
Role Name: Snowflakeで使用するデフォルトのアクセス制御ロールを指定します。デフォルトのRoleを使用する場合は空欄のままにします
Warehouse: (必須)使用する仮想ウェアハウスを指定します
Database: (必須)Snowflakeデータベース
Schema: (必須)接続時に指定されたデータベースのデフォルトスキーマを指定します
Source Type: Table/ViewまたはQueryを選択
- Query:
- SELECT Query: 実行するRaw SQLクエリ。SELECTタイプのクエリのみ許可されます。INSERT、UPDATE、またはデータを変更するクエリは許可されません
- Table/View(デフォルト):
- SELECT Columns: (必須)Table/Viewからすべてのカラムを選択するには、カンマ区切りのカラム名または
*****を入力します - From Table/View: (必須)宛先テーブル名
- WHERE Condition: 行をフィルタリングするWHERE条件を指定
- ORDER By Columns: 行をソートするためのORDER BY式
- SELECT Columns: (必須)Table/Viewからすべてのカラムを選択するには、カンマ区切りのカラム名または
- Query:
Incremental Loading: インクリメンタルローディングを有効にします。インクリメンタルローディングの仕組みを参照してください
- Incremental Column(s): インクリメンタルローディング用のカラム名。TimestampおよびNumericカラムが許可されます。指定しない場合、Primaryカラム(存在する場合)が使用されます
- ORDER By Columns: Incremental Loadingが選択されている場合は許可されません
Invalid Value Handling Mode: テーブルに無効なデータを含む行がある場合、Fail Job、Ignore Invalid ValueまたはIgnore Rowのオプションがあります。Fail Jobが選択されている場合、現在のジョブが停止しERRORステータスになります。Ignore Invalid Valueが選択されている場合、TDテーブルのカラムがstring型でない場合はNull値を保存し、カラムがstring型の場合は値を文字列として保存しようとします。Ignore Rowを選択すると、無効な値を含む行を無視して実行を続けます。デフォルトでは、指定されていない場合はFail Jobが選択されます。
指定されたWarehouse、Database、Schemaはすでに存在している必要があります。指定されたRoleは、指定されたwarehouse、database、schemaに対する権限を持っている必要があります。
Warehouse: DEMO_WH
Database: Test_DB
Schema: PUBLIC
Source Type: Query selected
SELECT Query: SELECT column1, column2, column3
FROM table_test
WHERE column4 != 1
Incremental Loading: Checked
Incremental Column(s): column1Warehouse: DEMO_WH
Database: Test_DB
Schema: PUBLIC
Source Type: Table/View selected
SELECT Columns: column1, column2, column3 FROM table_test WHERE column4 != 1
FROM Table/View: table_test
WHERE Condition: column4 != 1
ORDER By Columns:
Incremental Loading: Checked
Incremental Column(s): column1Nextを選択すると、データのプレビューが表示されます。
クエリの完了に時間がかかる場合、例えば、Order Byカラムを含むがインデックス化されていない大きなテーブルをクエリする場合など、プレビューにはダミーデータが表示されることがあります。
複数の条件やテーブルの結合を伴う複雑なクエリを使用する場合、プレビューに「No records to preview」と表示されることがありますが、ジョブの結果には影響しません。プレビューに関する詳細情報をお読みください。
データ型マッピングの設定など、変更を行う場合はAdvanced Settingsを選択します。それ以外の場合はNextを選択します。
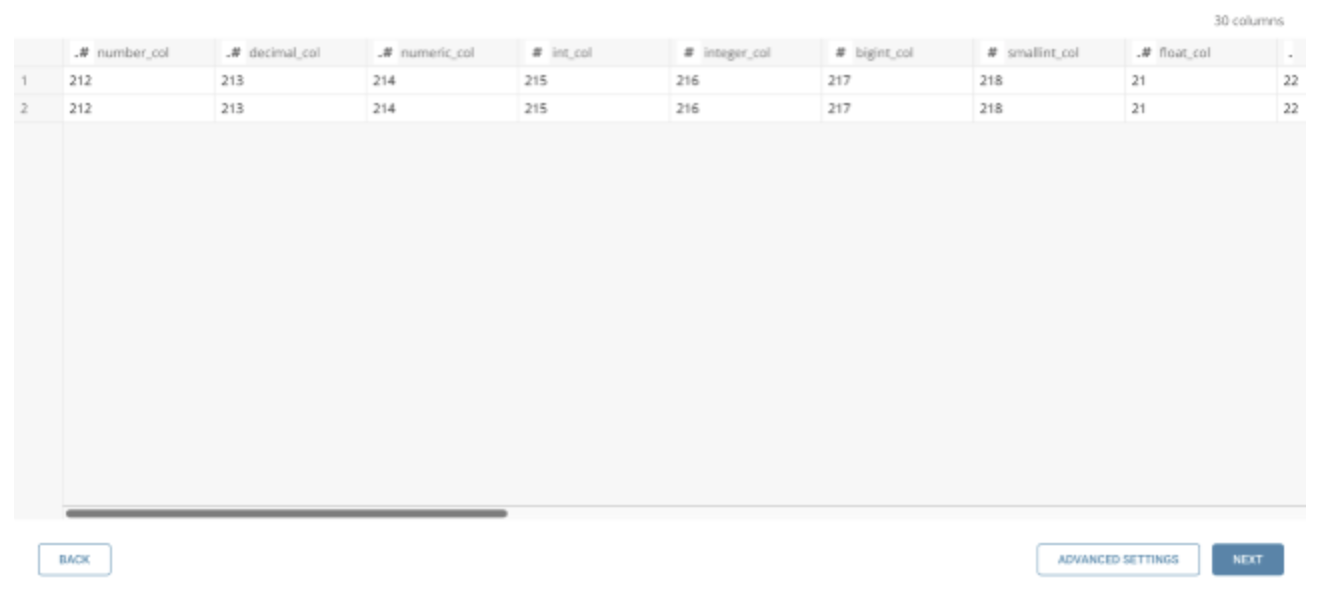
Advanced Settingsでは、転送をカスタマイズできます。必要に応じて以下のセクションを編集します。
データをインポートする際に、source(Snowflakeカラム)からdestination(Treasure Data)へのデフォルトのデータ型変換を変更するには、データ型変換の仕組みに関する付録を参照してください。
- Data Type Mapping: Snowflakeカラム名を入力します
- Get as Type: sourceからこの指定された型としてデータを取得します
- Destination Data Type: 期待されるdestinationのデータ型
- Timestamp Format: Get as Typeが日付、時刻、またはタイムスタンプで、Destination Data Typeが文字列の場合、destination型をフォーマットするために使用されるフォーマットパターン。例: yyyy-MM-dd'T'HH:mm:ssZ
- Time zone: Timestamp Formatと共に使用します。指定されていない場合、フォーマットはGMT値です。+0800や-1130などのZone offset値をサポートします
- Data Type Mapping: Snowflakeカラム名を入力します
- Get as Type: sourceからこの指定された型としてデータを取得します
- Destination Data Type: 期待されるdestinationのデータ型
Addを選択します。
- Start After (values): Incremental Loadingが選択されている場合、この値を指定すると、この値より大きいデータのみがインポートされます。このフィールドのサイズと順序はIncremental Columnsと等しくなければなりません
- Rows per Batch: 一度に取得する行数。デフォルトは10000行です
- Network Timeout: エラーを返す前に、Snowflakeサービスとやり取りする際の応答の待機時間を指定します
- Query Timeout: エラーを返す前に、クエリが完了するまでの待機時間を指定します。ゼロ(0)は無期限に待機することを示します
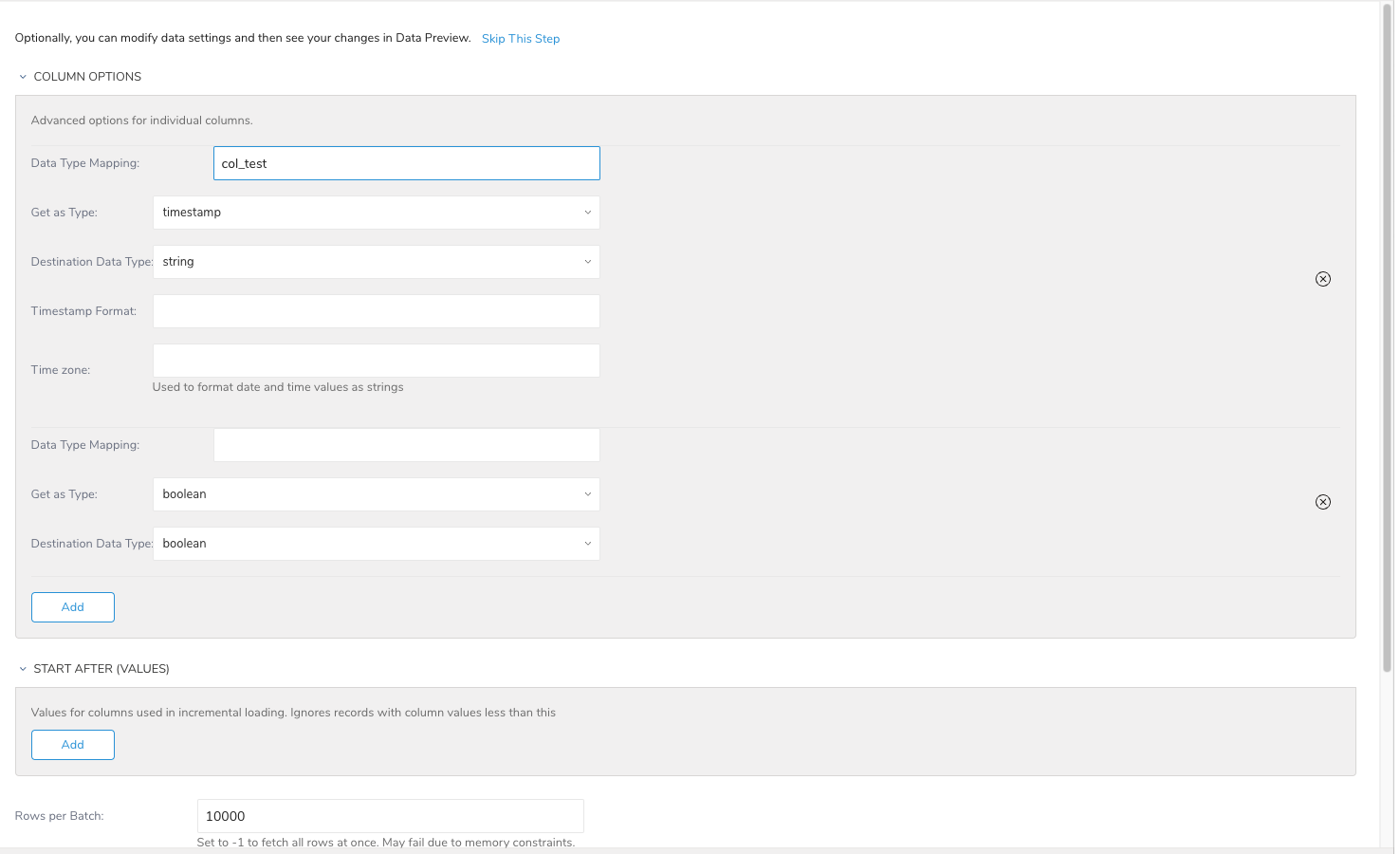
インポート先の既存のデータベースとテーブルを選択するか、新規に作成します。
- Method: Append または Replace。既存のテーブルにレコードを追加するか、既存のテーブルを置換するかを選択します。
- Timestamp-based Partition Key: long型またはtimestamp型のカラムをパーティショニング時間として選択します。デフォルトの時間カラムとして、add_timeフィルターを使用したupload_timeが使用されます。
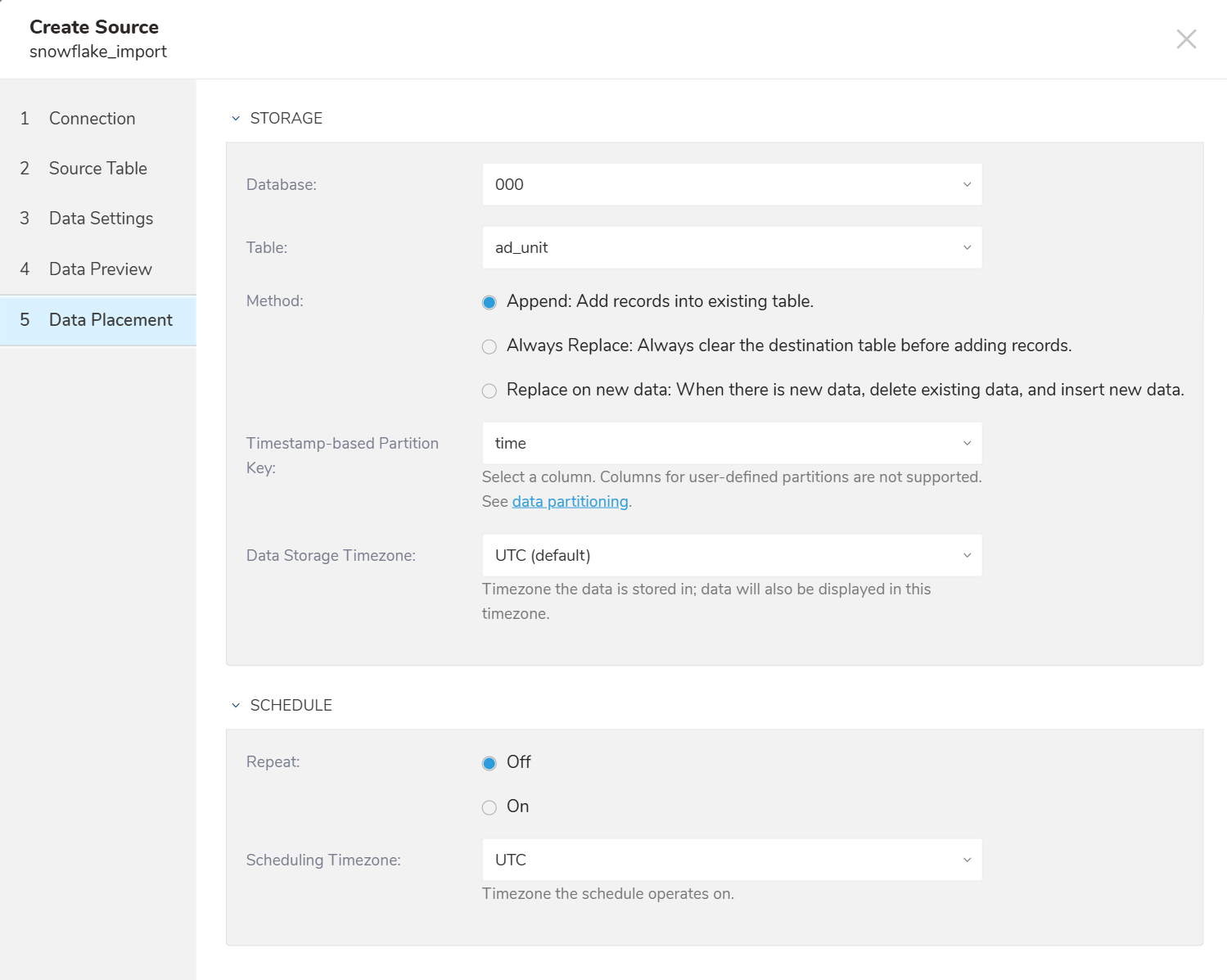
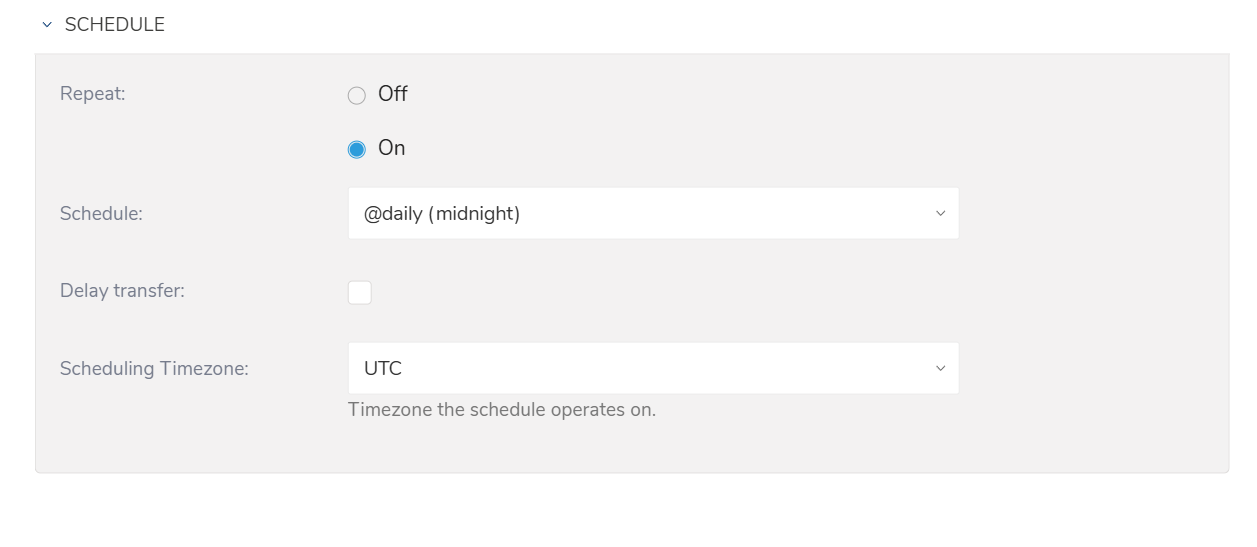
1回限りの転送を指定するか、自動で繰り返し実行される転送をスケジュール設定できます。
パラメータ
Once now: 1回限りのジョブを設定します。
Repeat…
- Schedule: オプション: @hourly、@daily、@monthly、およびカスタムcron。
- Delay Transfer: 実行時間の遅延を追加します。
- Scheduling TimeZone: 'Asia/Tokyo'のような拡張タイムゾーン形式をサポートしています。
新しいソースとして、Snowflakeコネクタの名前を指定します。
Doneを選択します。データコネクタがSourceとして保存されます。
このページでは、既存のジョブを編集できます。また、ジョブアイコンを選択することで、このデータコネクタを使用した過去の転送の詳細を表示できます。
コネクタを設定する前に、'td'コマンドをインストールしてください。Treasure Data Toolbeltをインストールします。
in: セクションでは、Snowflakeからコネクタに取り込まれる内容を指定し、out: セクションでは、コネクタがTreasure Dataのデータベースに出力する内容を指定します。
以下のようにSnowflakeアカウントのアクセス情報を入力してください:
in:
type: snowflake
account_name: treasuredata
user: Test_user
password: xxxx
warehouse: DEMO_WH
db: TEST_DB
schema: PUBLIC
query: |
SELECT column1, column2, column3
FROM table_test
WHERE column4 != 1
out:
mode: append設定キーと説明は以下の通りです:
| Config key | Type | Required | Description | |
|---|---|---|---|---|
| type | string | yes | コネクタタイプ("snowflake"である必要があります) | |
| driver_version | string |
| ||
| account_name | string | yes | アカウント名を指定します(Snowflakeによって提供されます)。Snowflakeのaccount nameを参照してください。 | |
| warehouse | string | yes | 使用する仮想ウェアハウスを指定します | |
| db | string | yes | 使用するSnowflakeのデフォルトデータベース | |
| schema | string | yes | 接続後に指定されたデータベースに使用するデフォルトスキーマを指定します | |
| role | string | no | ドライバーによって開始されるSnowflakeセッションで使用するデフォルトのアクセス制御ロール | |
| auth_method | string | yes | 認証方法。現在サポート: basic、key_pair(デフォルト: "basic") | |
| private_key | string | no | auth_methodがkey_pairの場合は必須 | |
| passphrase | string | no | private_keyのパスフレーズ | |
| user | string | yes | Snowflakeログイン名 | |
| password | string | no | auth_methodがbasicの場合は必須。指定されたユーザーのパスワード | |
| query | string | no | 実行するSQLクエリ | |
| incremental | boolean | no | trueの場合、インクリメンタルローディングの仕組みを有効にします。インクリメンタルローディングの仕組みを参照してください。 | |
| incremental_columns | strings array | no | インクリメンタルロード用のカラム名。指定されていない場合は主キーカラムを使用します | |
| invalid_value_option | string | no | 行内の無効なデータを処理するオプション。利用可能なオプションは fail_job、ignore_row、insert_null です | |
| last_record | オブジェクトの配列 | no | インクリメンタルロードのための最後のレコードの値 | |
| fetch_rows | integer | no | 一度に取得する行数。デフォルト 10000 | |
| network_timeout | integer | no | エラーを返すまでに、Snowflake サービスとのやり取りでレスポンスを待機する時間。デフォルトは未設定 | |
| query_timeout | integer | エラーを返すまでにクエリの完了を待機する時間。デフォルト 0 | ||
| select | string | no | select の式。'query' が設定されていない場合は必須 | |
| table | string | no | 宛先テーブル名。'query' が設定されていない場合は必須 | |
| where | string | no | 行をフィルタリングする条件 | |
| order_by | string | no | 行をソートするための ORDER BY の式 | |
| column_options | キーと値のペア | no | ソース(Snowflake)から宛先(Treasure Data)へのデータ型をカスタマイズするオプション。データ型変換の仕組みを参照してください | |
| value_type | string | no | column_options と併用し、この型を使用して Snowflake JDBC ドライバーからデータを取得しようとします | |
| type | string | no | 宛先データ型。value_type から取得した値はこの型に変換されます | |
| timestamp_format | string | no | Java 言語のタイムスタンプフォーマットパターン。value_type が日付、時刻、またはタイムスタンプで、type が文字列の場合に、宛先値をフォーマットするために使用します | |
| timezone | string | no | RFC 822 タイムゾーン。timestamp_format と併用します。例:+0300 または -0530 |
インクリメンタルと column_options を使用した load.yml の例
in:
type: snowflake
account_name: treasuredata
user: snowflake_user
password: xxxxx
warehouse: DEMO_WH
db: TEST_DB
schema: PUBLIC
query: |
SELECT column1, column2, column3
FROM table_test
WHERE column4 != 1
incremental: true
incremental_columns: [column1, column3]
last_record: [140, 1500.5]
column_options:
colum5 : {value_type: "timestamp", type: "string", timestamp_format: "yyyy-MMM-dd HH:mm:ss Z", timezone: "+0700"}
out:
mode: append利用可能な out モードの詳細については、モードを参照してください。
データをプレビューするには、preview コマンドを実行します
$ td connector:preview load.yml
+--------------+-----------------+----------------+
| COLUMN1:long | COLUMN2:string | COLUMN3:double |
+--------------+-----------------+----------------+
| 100 | "Sample value1" | 1900.1 |
| 120 | "Sample value3" | 1700.3 |
| 140 | "Sample value5" | 1500.5 |
+--------------+-----------------+----------------+ロードジョブを送信します。データのサイズによっては数時間かかる場合があります。データが保存されるデータベースとテーブルを指定する必要があります。
Treasure Data のストレージは時間によってパーティション分割されているため、--time-column オプションを指定することをお勧めします。このオプションが指定されていない場合、データコネクターは最初の long または timestamp カラムをパーティション分割時間として選択します。--time-column で指定するカラムの型は、long または timestamp 型のいずれかである必要があります。
データに時間カラムがない場合は、add_time フィルターオプションを使用して追加できます。詳細については、add_time フィルタープラグインを参照してください。
$ td connector:issue load.yml --database td_sample_db --table td_sample_table
--time-column created_attd connector:issue は、database(td_sample_db) と table(td_sample_table) がすでに作成されていることを前提としています。データベースまたはテーブルが TD に存在しない場合、td connector:issue は失敗します。したがって、データベースとテーブルを手動で作成するか、td connector:issue コマンドで --auto-create-table オプションを使用して、データベースとテーブルを自動的に作成する必要があります。
$ td connector:issue load.yml --database td_sample_db --table td_sample_table --time-column created_at --auto-create-tabletime という名前のフィールドがある場合、--time-column オプションを指定する必要はありません。
$ td connector:issue load.yml --database td_sample_db --table td_sample_table定期的な Snowflake インポートのために、データコネクターの定期実行をスケジュールできます。
td connector:create コマンドを使用して、新しいスケジュールを作成できます。以下が必要です:
- スケジュールの名前
- cron 形式のスケジュール
- データが保存されるデータベースとテーブル
- データコネクター設定ファイル
$ td connector:create
daily_import
"10 0 * * *"
td_sample_db
td_sample_table
load.ymlTreasure Dataのストレージは時間で区切られているため、--time-column オプションの指定も推奨されます(データパーティショニングも参照)。
$ td connector:create
daily_import
"10 0 * * *"
td_sample_db
td_sample_table
load.yml
--time-column created_atcron パラメータは3つの特別なオプション @hourly、@daily、@monthly も受け入れます。
デフォルトでは、スケジュールはUTCタイムゾーンで設定されます。-t または --timezone オプションを使用して、タイムゾーンでスケジュールを設定できます。--timezone オプションは、'Asia/Tokyo'、'America/Los_Angeles' などの拡張タイムゾーン形式のみをサポートしています。PST、CSTなどのタイムゾーンの略語はサポートされておらず、予期しないスケジュールになる可能性があります。
td connector:list コマンドを実行すると、スケジュールされたエントリのリストを確認できます。
$ td connector:listSnowflakeへの接続は、公式JDBCドライバを介して行われます。JDBCドライバは、デフォルトで必須としてSSLの使用を強制します(つまり、SSL = falseでの接続は拒否されます)。
Snowflakeへの接続に、このツールは2つのJDBC認証オプションを提供します:
- Basic (ユーザー名/パスワード): この標準的なログイン方法は、ユーザーのSnowflakeアカウントで多要素認証(MFA)がアクティブな場合、失敗します。これは、ジョブ実行中のコネクタの認証プロセスとの潜在的な競合によるものです。
- キーペア認証: この安全な方法は、暗号化キーペアを使用します。これが推奨されるアプローチであり、MFAが有効かどうかに関係なく確実に機能します。
データ型変換は、カラム型マッピングまたはcolumn_optionsとも呼ばれ、Connectorがソースデータ型(Snowflake)からデスティネーション(type)データ型(Treasure Data)にデータを変換するために使用します。ConnectorはソースからGet as type (value_type)を取得し、その後デスティネーションへの変換を実行します。以下の表はデフォルトの変換です。
| ソース (Snowflake) | Get as Type (value_type) | デスティネーション (type) |
|---|---|---|
| NUMBER (scale > 0) | double | double |
| DECIMAL (scale > 0) | double | double |
| NUMERIC (scale > 0) | double | double |
| NUMERIC (scale = 0) | long | long |
| INT | long | long |
| INTEGER | long | long |
| BIGINT | long | long |
| SMALLINT | long | long |
| FLOAT | double | double |
| FLOAT4 | double | double |
| FLOAT8 | double | double |
| DOUBLE | double | double |
| DOUBLE PRECISION | double | double |
| REAL | double | double |
| VARCHAR | string | string |
| CHARACTER | string | string |
| CHAR | string | string |
| STRING | string | string |
| TEXT | string | string |
| BOOLEAN | boolean | boolean |
| DATE | date | string |
| TIME | time | string |
| DATETIME | timestamp | timestamp |
| TIMESTAMP | timestamp | timestamp |
| TIMESTAMP_LTZ | timestamp | timestamp |
| TIMESTAMP_NTZ | timestamp | timestamp |
| TIMESTAMP_TZ | timestamp | timestamp |
| VARIANT (公式にはサポートされていません) | string | string |
| OBJECT (公式にはサポートされていません) | string | string |
| ARRAY (公式にはサポートされていません) | string | string |
| BINARY | サポートされていません | |
| VARBINARY | サポートされていません |
value_type でサポートされるデータ型
- boolean
- date
- double
- decimal
- json
- long
- string
- time
- timestamp
type でサポートされるデータ型
- boolean
- long
- double
- string
- json
- timestamp
value_type は、Snowflakeデータ型からデータを取得するために使用できます
| value_type | Snowflakeデータ型 |
|---|---|
| boolean | BOOLEAN, NUMERIC, INT, INTEGER, BIGINT, SMALLINT, FLOAT, DOUBLE, REAL, VARCHAR, CHARACTER, CHAR, STRING, TEXT |
| date | DATE, CHAR, VARCHAR, STRING, TIMESTAMP, TEXT |
| double | INT, SMALLINT, INTEGER, BIGINT, REAL, DECIMAL, NUMERIC, BIT, CHAR, VARCHAR, STRING, TEXT |
| decimal | DECIMAL, INT, SMALLINT, INTEGER, BIGINT, REAL, FLOAT, DOUBLE, BIT, CHAR, VARCHAR, STRING, TEXT |
| json | VARCHAR, CHAR, STRING, TEXT, VARIANT, OBJECT, ARRAY |
| long | LONG, INT, SMALLINT, INTEGER, REAL, FLOAT, DOUBLE, DECIMAL, NUMERIC, CHAR, VARCHAR, STRING, TEXT |
| time | TIME, CHAR, VARCHAR, STRING, TIMESTAMP, TEXT |
| timestamp | TIMESTAMP, CHAR, VARCHAR, DATE, TIME, STRING, TEXT |
| string | ほとんどのSnowflakeデータ型の取得に使用できます |
value_type は type に変換できます
| value_type | type |
|---|---|
| boolean | boolean, double, long, string |
| date | long, timestamp, string |
| double | boolean, double, long, string |
| decimal | boolean, double, long, string |
| json | json, string |
| long | boolean, double, long, string |
| time | long, timestamp, string |
| timestamp | long, timestamp, string |
| string | double, long, string, json |
注意:
Get as Type が date、time、または timestamp で、デスティネーションが string の場合、値をフォーマットするための追加オプションがあります。
- Timestamp Format: 標準的なJavaの日時フォーマットパターンを受け入れます 例: yyyy-MM-dd HH:mm:ss Z
- Timezone: RFC822タイムゾーンフォーマットを受け入れます 例: +0800
Get as Type の 'decimal' 型はサポートされていますが、デフォルトでは使用されません。ソースにデスティネーションの数値範囲に収まらない数値が含まれている場合は、Get as Type を decimal にし、デスティネーションを string にしてください。
インクリメンタルローディングは、単調増加する一意のカラム(AUTO_INCREMENTカラムなど)を使用して、前回の実行後に挿入(または更新)されたレコードをロードします。 まず、incremental: true が設定されている場合、このコネクタは追加のORDER BYでレコードをすべてロードします。このモードは、前回のスケジュール実行以降に変更されたオブジェクトターゲットのみを取得する場合に便利です。たとえば、incremental_columns: [updated_at, id] オプションが設定されている場合、クエリは次のようになります:
SELECT * FROM (
...original query is here...
)
ORDER BY updated_at, idバルクデータのロードが正常に終了すると、次回の実行で使用されるように、last_record: パラメータをconfig-diffとして出力します。 次回の実行時に、last_record: も設定されている場合、このコネクタは最後のレコードより大きいレコードをロードするための追加のWHERE条件を生成します。たとえば、last_record: ["2017-01-01T00:32:12.000000", 5291] が設定されている場合、
SELECT * FROM (
...original query is here...
)
WHERE updated_at > '2017-01-01T00:32:12.000000' OR (updated_at = '2017-01-01T00:32:12.000000' AND id > 5291)
ORDER BY updated_at, idその後、次回の実行で更新されたlast_recordが使用されるように、last_record: を更新します。 重要: incremental_columns: オプションを設定する場合は、フルテーブルスキャンを避けるために、カラムにインデックスがあることを確認してください。この例では、次のインデックスを作成する必要があります:
CREATE INDEX embulk_incremental_loading_index ON table (updated_at, id);推奨される使用方法は、incremental_columns を未設定のままにして、コネクタが自動的にAUTO_INCREMENTプライマリキーを見つけるようにすることです。
incremental_columnsとしてサポートされているのは、Timestamp、Datetime、および数値カラムのみです。 生のクエリの場合、複雑なクエリのプライマリキーを検出できないため、incremental_columnsが必要です。
incremental: false が設定されている場合、データコネクタは、最後に更新された時期に関係なく、指定されたSnowflakeテーブル/ビューのすべてのレコードを取得します。このモードは、'replace' モードを使用してデスティネーションテーブルにデータを書き込む場合に最適です。