Snowflake はクラウドベースのデータプラットフォームを提供し、ほぼ無制限のスケール、同時実行性、パフォーマンスでデータの価値を引き出すことができます。Treasure Data の Snowflake Bulk Unloading インテグレーションは、Snowflake のBulk Data Unloading 機能を活用して、Snowflake テーブルから Treasure Data へ大規模データセットをインポートするための高パフォーマンスソリューションを提供します。このインテグレーションは、大規模データセットに対して標準の Snowflake インポートインテグレーションと比較して最大 300% のパフォーマンス向上 を実現します。また、Treasure Data の Snowflake インポート インテグレーションおよびSnowflake エクスポート インテグレーションについても詳しく確認できます。
This feature is in BETA version. For more information, contact your Customer Success Representative.
- Treasure Data の基本知識
- テーブル/ビューへのクエリおよびステージ管理の適切な権限を持つ Snowflake データウェアハウスの既存アカウント
- 大規模データセットの場合、最適なパフォーマンスのために適切なリソース割り当て(特に CPU)を確保してください
Integrations Hub > Catalog に移動して検索します。Snowflake Bulk Unload を選択します。

以下のダイアログが開きます。
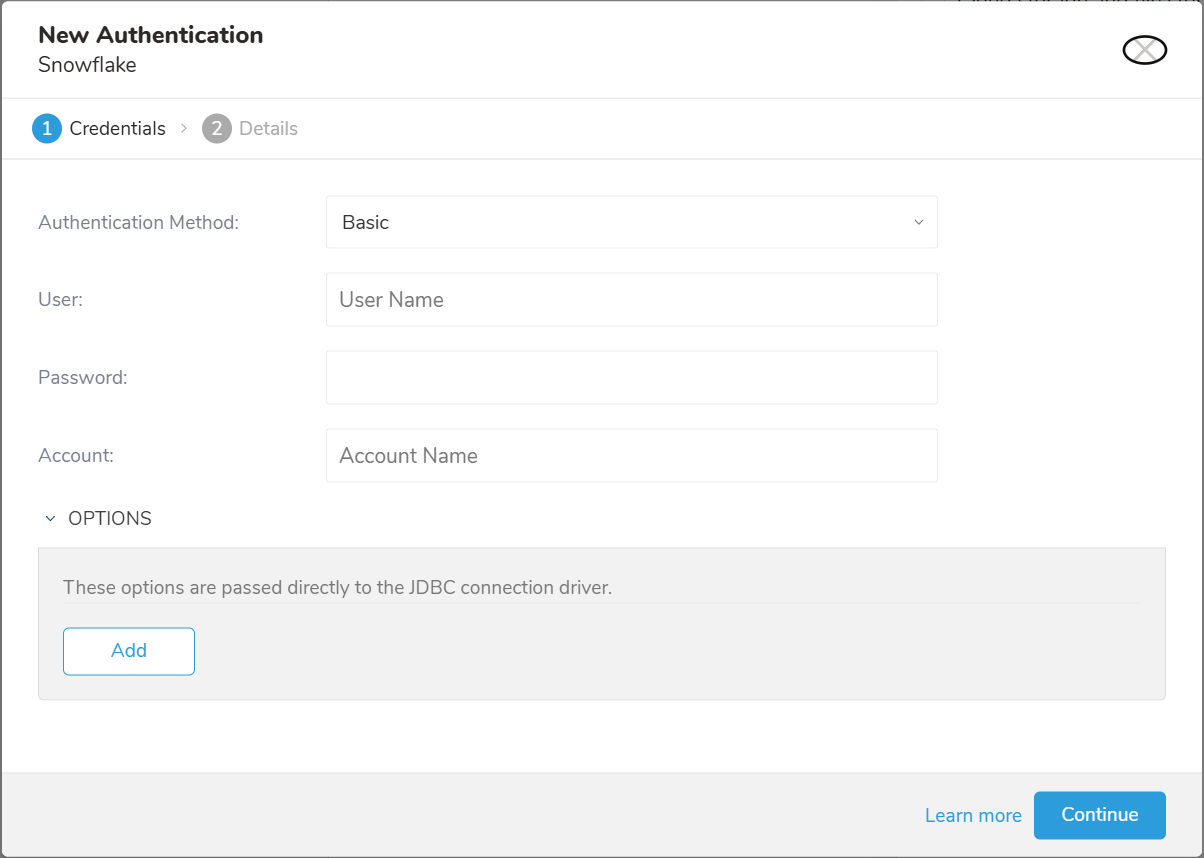
認証方法を選択します:
- Basic: Treasure Data が Snowflake に認証するための必要な認証情報を入力します: User、Password、Account
- User: Snowflake ログインユーザー名
- Password: Snowflake ログインパスワード
- Key Pair: 暗号化された秘密鍵の場合は Private Key とその Passphrase を入力します
- Private Key: 生成された秘密鍵。configuring-key-pair-authentication を参照してください
- Passphrase: 秘密鍵のパスフレーズ。秘密鍵が暗号化されていない場合は空欄のままにします
- User: Snowflake ログインユーザー名
- Account: Snowflake から提供されたアカウント名。Snowflake でアカウント名を見つける方法を参照してください
- OPTIONS: JDBC 接続オプション(ある場合)
Continue を選択します。
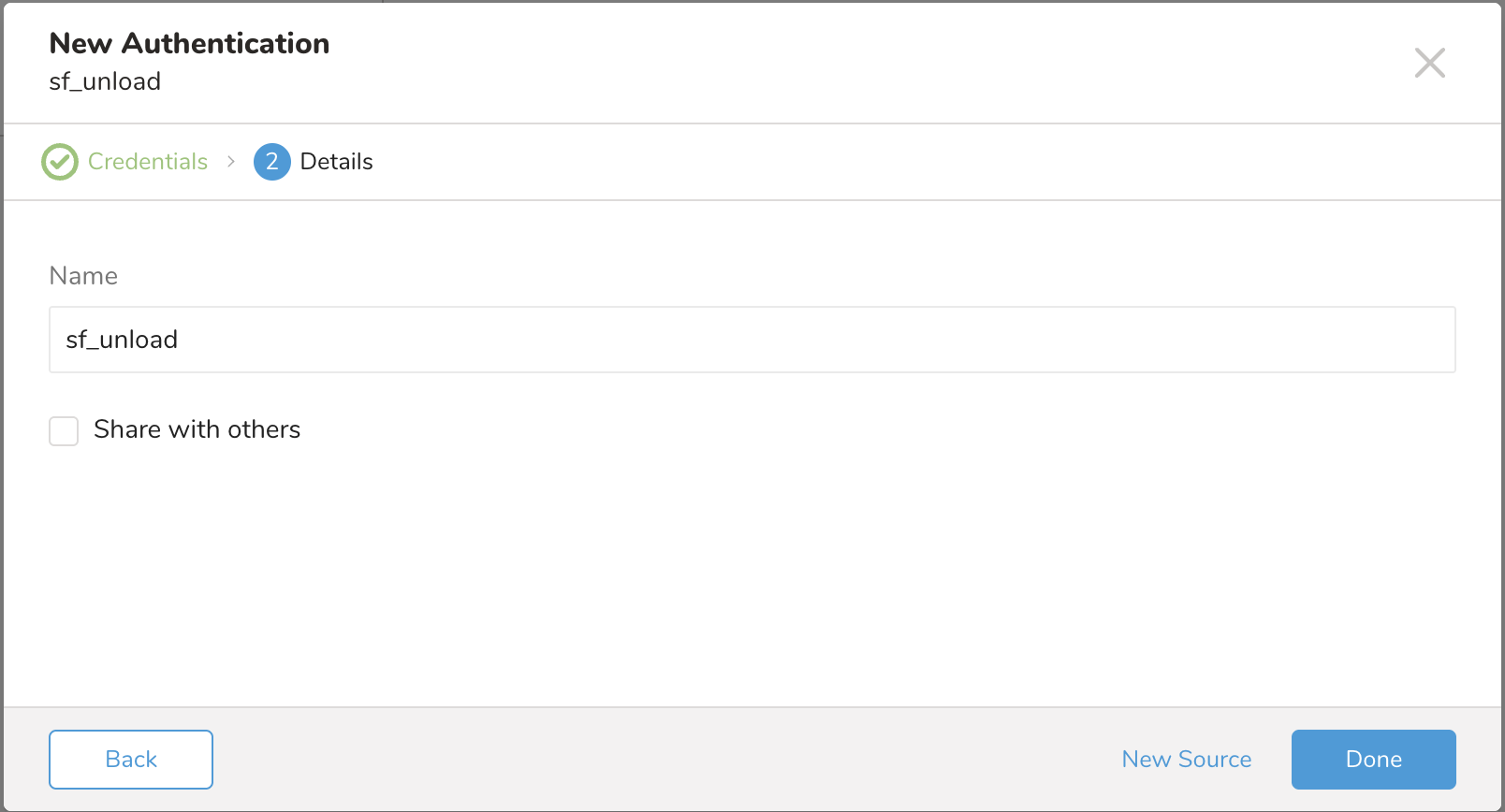
データコネクタの名前を指定します。認証を他のユーザーと共有するかどうかを指定します。共有すると、他のチームメンバーがあなたの認証を使用してコネクタソースを作成できます。Done を選択します。
Authentications ページで New Source を作成します。 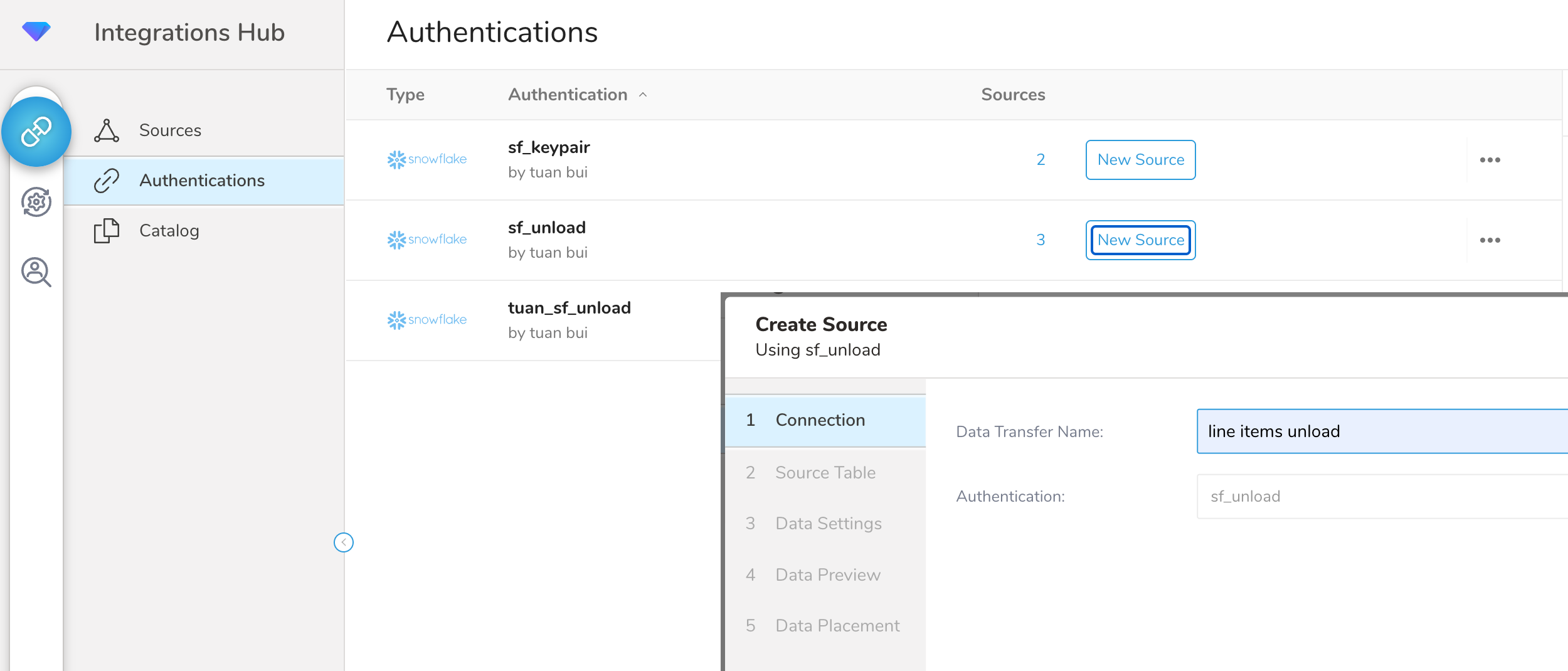 Connection に名前を入力し、Next をクリックします。
Connection に名前を入力し、Next をクリックします。
Source Table の詳細を入力します。 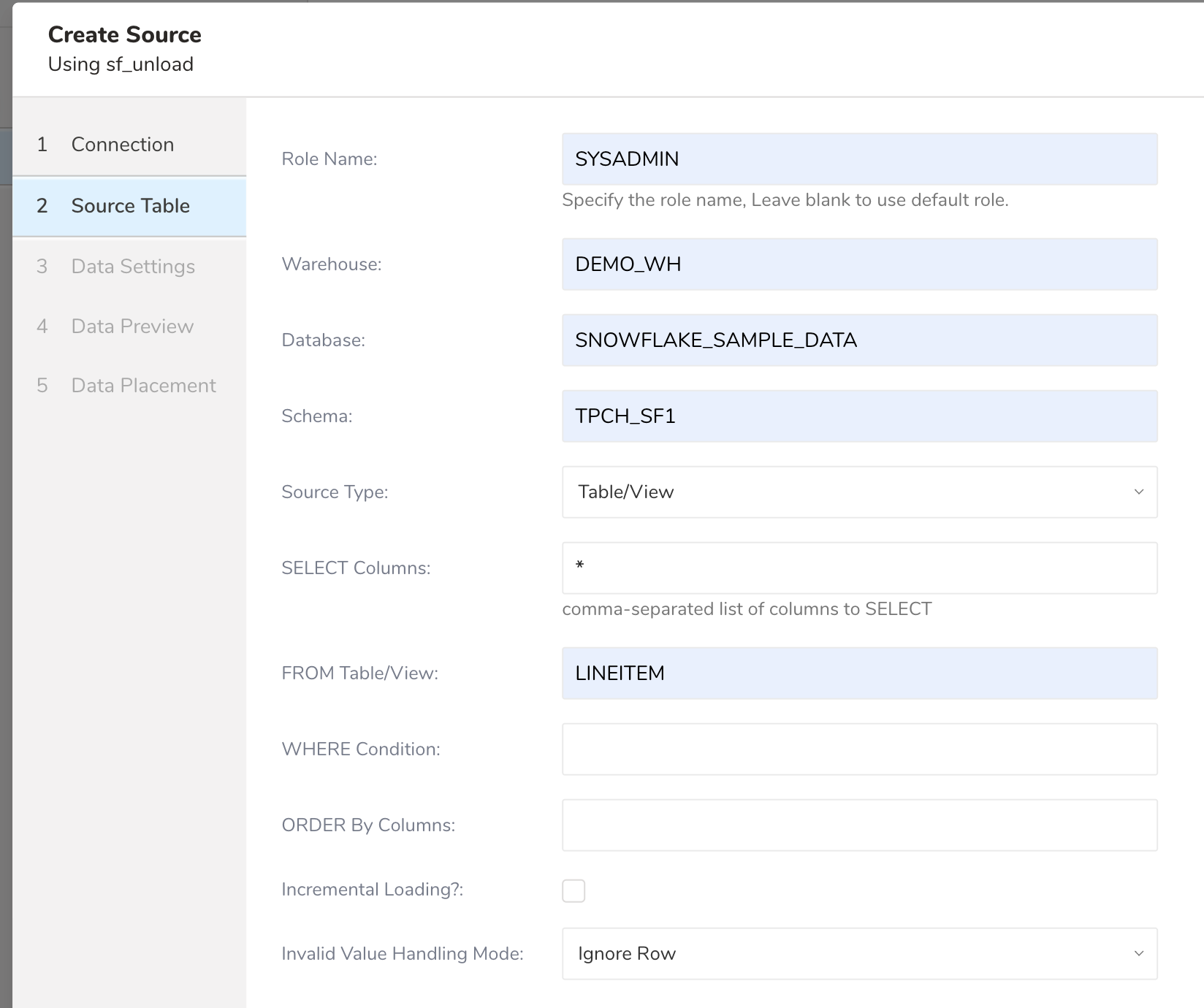
取り込みたい情報を登録する必要があります。パラメータは以下の通りです:
Role Name: Snowflake で使用するデフォルトのアクセス制御ロールを指定します。デフォルトの Role を使用する場合は空欄のままにします
Warehouse: (必須)使用する仮想ウェアハウスを指定します
Database: (必須)Snowflake データベース
Schema: (必須)接続時に指定されたデータベースのデフォルトスキーマを指定します
Source Type: Table/View または Query を選択します
- Query:
- SELECT Query: 実行するRAW SQLクエリ。SELECT タイプのクエリのみ許可されます。INSERT、UPDATE、またはデータ変更クエリは使用できません
- Table/View(デフォルト):
- SELECT Columns: (必須)Table/View からすべての列を選択する場合はカンマ区切りの列名または
*を使用します - From Table/View: (必須)転送先テーブル名
- WHERE Condition: 行をフィルタリングするための WHERE 条件を指定します
- ORDER By Columns: 行をソートするための ORDER BY の式
- SELECT Columns: (必須)Table/View からすべての列を選択する場合はカンマ区切りの列名または
- Query:
Incremental Loading: パフォーマンス最適化を備えた増分ロードを有効にします
- Incremental Column(s): 増分ロードのための列名。Timestamp および Numeric 列を指定できます。指定しない場合、Primary 列(存在する場合)が使用されます
- ORDER BY Columns: Incremental Loading を選択した場合は使用できません
Invalid Value Handling Mode: テーブルに無効なデータが含まれる行がある場合、Fail Job または Ignore Row のオプションがあります。Fail Job を選択すると、現在のジョブが停止し ERROR ステータスになります。Ignore Row を選択すると、無効な値を含む行を無視して処理を継続します。指定しない場合、デフォルトで Fail Job が選択されます
指定した Warehouse、Database、Schema は事前に存在している必要があります。指定した Role は、指定したウェアハウス、データベース、スキーマ、テーブル/ビューへの権限を持っている必要があります。
Warehouse: DEMO_WH
Database: Test_DB
Schema: PUBLIC
Source Type: Query selected
SELECT Query: SELECT column1, column2, column3
FROM table_test
WHERE column4 != 1
Incremental Loading: Checked
Incremental Column(s): column1Warehouse: DEMO_WH
Database: Test_DB
Schema: PUBLIC
Source Type: Table/View selected
SELECT Columns: column1, column2, column3
FROM Table/View: table_test
WHERE Condition: column4 != 1
ORDER By Columns:
Incremental Loading: Checked
Incremental Column(s): column1Next を選択すると、データの詳細設定が表示されます
Data Settings では転送のカスタマイズができます。必要に応じて以下のセクションを編集してください。
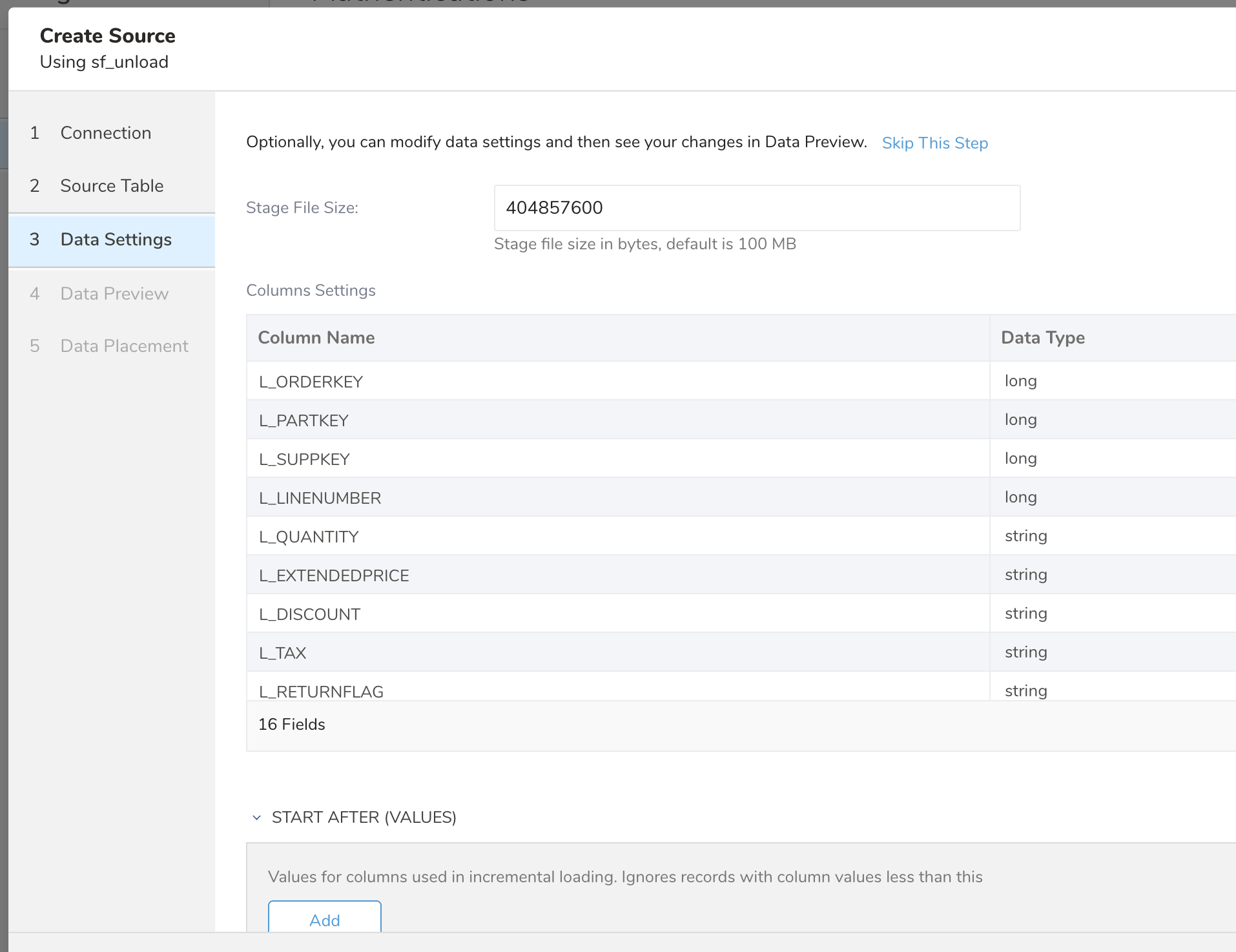
- Stage File Size: 個々のステージファイルのサイズをバイト単位で制御します。デフォルトは 100 MB(104,857,600 バイト)です。ファイルサイズを大きくすると非常に大きなデータセットのパフォーマンスが向上する場合がありますが、より多くのメモリが必要になる場合があります(500 MB ファイルは 6GB のデータセットでテスト済みで良好な結果が得られています)
列は実際のデータセットから推測されます。列のデータタイプが実際のデータと一致しない場合は変更できます。
- Column Name: Snowflake の列名(変更しないでください)
- Data Type: 転送先のデータタイプを選択します(string、boolean、timestamp、double、long、json)
- Timestamp Format: 転送先タイプが string の場合のタイムスタンプ列のフォーマットパターン。例: %Y-%m-%dT%H:%M:%S.%L%z
- Start After (values): Incremental Loading が選択されている場合、この値を指定すると、この値より大きいデータのみがインポートされます。このフィールドのサイズと順序は Incremental Columns と同じでなければなりません
Network Timeout: エラーを返す前に Snowflake サービスとのやり取りでレスポンスを待つ時間を指定します。
Query Timeout: エラーを返す前にクエリの完了を待つ時間を指定します。ゼロ(0)は無制限に待機することを示します。
Next を選択すると、データのプレビューが表示されます。
プレビューは Snowflake の SAMPLE 機能を使用して、データセット全体を処理せずにサンプル行を効率的に表示します。これは特に大きなテーブルで有効です。
Order By 列を使用しているがインデックスが付いていない大きなテーブルへのクエリなど、クエリの完了に時間がかかる場合、プレビューにダミーデータが表示される場合があります。
複数の条件、テーブルの結合を含む複雑なクエリを使用する場合、プレビューに「No records to preview」と表示されることがありますが、ジョブの実行結果には影響しません。プレビューの詳細を参照してください。
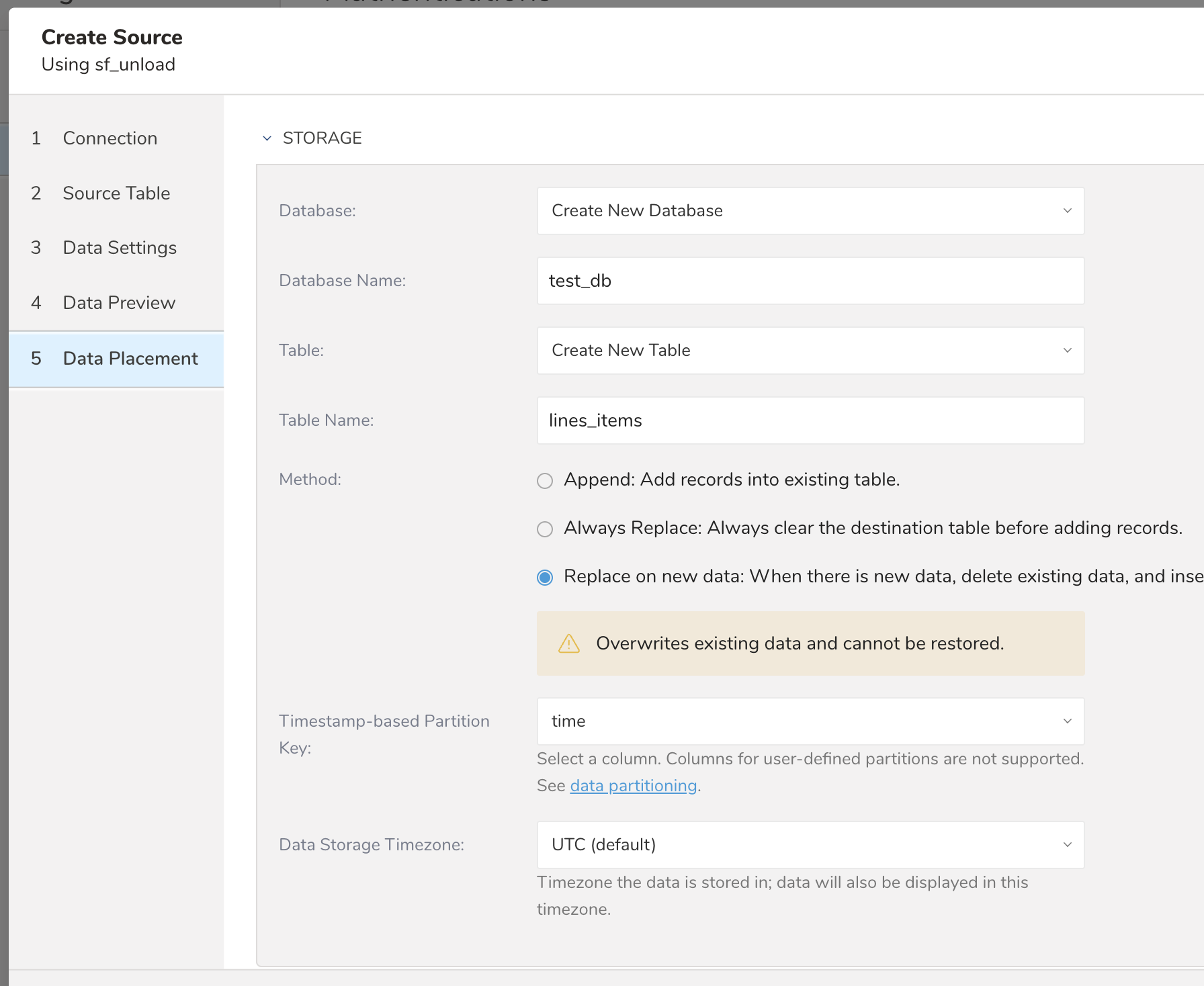
インポートしたいデータベースとテーブルを既存のものから選択するか、新規作成します。
- Method: Append または Replace。既存のテーブルにレコードを追加するか、既存のテーブルを置き換えるかを選択します
- Timestamp-based Partition Key: パーティショニング時間として long または timestamp 列を選択します。デフォルトの時間列として、add_time フィルターを使用した upload_time が使用されます
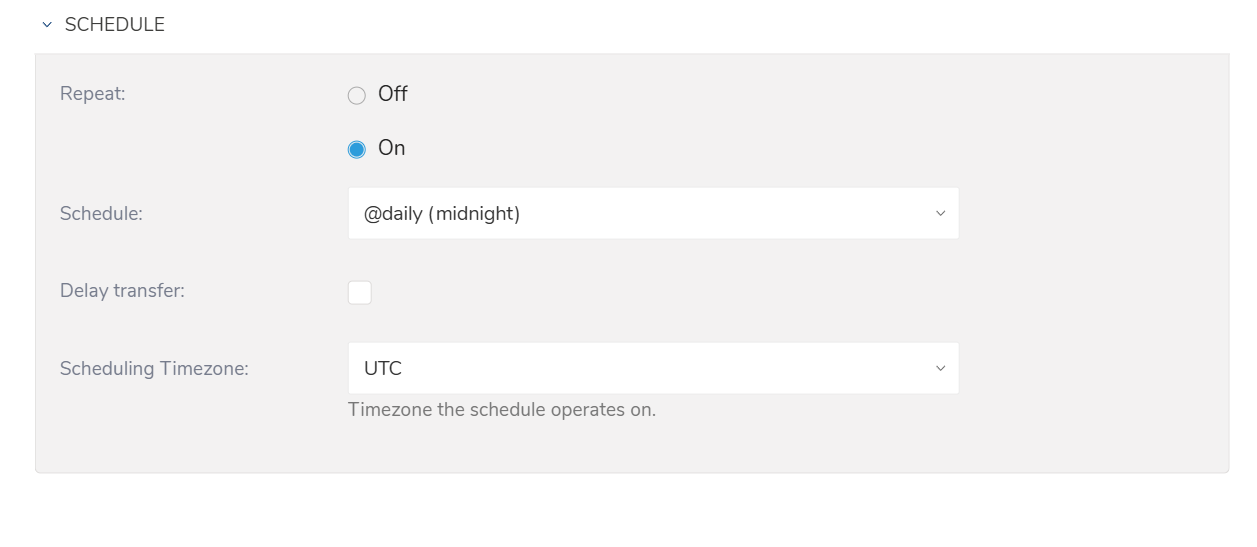
1回限りの転送を指定するか、自動繰り返し転送をスケジュールすることができます。
パラメータ
- Once now: 1回限りのジョブを設定します
- Repeat…
- Schedule: オプション: @hourly、@daily、@monthly、カスタム cron
- Delay Transfer: 実行時間の遅延を追加します
- Scheduling TimeZone: 'Asia/Tokyo' などの拡張タイムゾーン形式をサポートします
コネクタを設定する前に、'td' コマンドをインストールしてください。Treasure Data Toolbelt をインストールしてください。
in: セクションでは Snowflake からコネクタに入ってくるデータを指定し、out: セクションでは Treasure Data のデータベースにコネクタが出力するデータを指定します。
Snowflake アカウントのアクセス情報を以下のように入力します:
in:
type: snowflake_unload
account_name: treasuredata
user: Test_user
password: xxxx
warehouse: DEMO_WH
db: TEST_DB
schema: PUBLIC
query: |
SELECT column1, column2, column3
FROM table_test
WHERE column4 != 1
invalid_value_option: ignore_row
out:
mode: append設定キーと説明は以下の通りです:
| 設定キー | タイプ | 必須 | 説明 |
|---|---|---|---|
| type | string | yes | コネクタのタイプ("snowflake_unload" である必要があります) |
| account_name | string | yes | アカウント名を指定します(Snowflake から提供されます)。Snowflake のアカウント名を参照してください |
| warehouse | string | yes | 使用する仮想ウェアハウスを指定します |
| db | string | yes | 使用する Snowflake のデフォルトデータベース |
| schema | string | yes | 接続後に指定されたデータベースに使用するデフォルトスキーマを指定します |
| role | string | no | ドライバーによって開始された Snowflake セッションで使用するデフォルトのアクセス制御ロール |
| auth_method | string | yes | 認証方法。現在サポート: basic、key_pair(デフォルト "basic") |
| private_key | string | no | auth_method が key_pair の場合は必須 |
| passphrase | string | no | private_key のパスフレーズ |
| user | string | yes | Snowflake ログイン名 |
| password | string | no | auth_method が basic の場合は必須。指定したユーザーのパスワード |
| query | string | no | 実行する SQL クエリ |
| incremental | boolean | no | true の場合、ORDER BY の代わりに最大値比較を使用した増分ロードを有効にします |
| incremental_columns | strings array | no | 増分ロードの列名。指定しない場合は Primary キー列が使用されます |
| invalid_value_option | string | no | 行の無効なデータを処理するオプション。使用可能なオプション: fail_job および ignore_row |
| last_record | objects array | no | 増分ロードの最後のレコードの値 |
| stage_file_size | integer | no | ステージファイルサイズ(バイト単位)。デフォルト 104857600(100 MB) |
| network_timeout | integer | no | エラーを返す前に Snowflake サービスとのやり取りでレスポンスを待つ時間。デフォルト 0 |
| query_timeout | integer | no | エラーを返す前にクエリの完了を待つ時間。デフォルト 0 |
| select | string | no | select の式。'query' が設定されていない場合は必須 |
| table | string | no | 転送先テーブル名。'query' が設定されていない場合は必須 |
| where | string | no | 行をフィルタリングするための条件 |
| order_by | string | no | 行をソートするための ORDER BY の式 |
| columns | array | no | タイプとフォーマット仕様を含む列設定。列は Snowflake のサンプルデータに基づいて推測されます |
| stage_folder | string | no | 内部ステージフォルダの設定(自動管理) |
コネクタを実行する前に、td connector:guess コマンドを使用して列タイプを自動検出し、完全な設定を生成することをお勧めします。このコマンドは Snowflake からデータをサンプリングして最適な列設定を推測します。
td connector:guess seed.yml -o load.ymlこれにより、以下を含む完全な load.yml ファイルが生成されます:
- 検出された列名とタイプ
- Snowflake データタイプに基づく最適なデータタイプマッピング
- 一括アンロードのパフォーマンス設定
guess コマンド実行後に生成される load.yml の例:
in:
type: snowflake_unload
account_name: treasuredata
user: snowflake_user
password: xxxxx
warehouse: DEMO_WH
db: TEST_DB
schema: PUBLIC
query: |
SELECT column1, column2, column3
FROM table_test
WHERE column4 != 1
incremental: true
incremental_columns: [column1, column3]
last_record: [140, 1500.5]
stage_file_size: 104857600
invalid_value_option: ignore_row
columns:
- name: column1
type: long
- name: column2
type: string
- name: column3
type: timestamp
format: "%Y-%m-%dT%H:%M:%S.%L%z"
out:
mode: append使用可能な out モードの詳細については、modes を参照してください。
データをプレビューするには、preview コマンドを実行します
td connector:preview load.yml
+--------------+-----------------+----------------+
| COLUMN1:long | COLUMN2:string | COLUMN3:double |
+--------------+-----------------+----------------+
| 100 | "Sample value1" | 1900.1 |
| 120 | "Sample value3" | 1700.3 |
| 140 | "Sample value5" | 1500.5 |
+--------------+-----------------+----------------+ロードジョブを送信します。データのサイズによっては数時間かかる場合があります。データが保存されているデータベースとテーブルを指定する必要があります。
Treasure Data のストレージは時間でパーティション分割されているため、--time-column オプションを指定することをお勧めします。オプションが指定されない場合、データコネクタは最初の long または timestamp 列をパーティショニング時間として選択します。--time-column で指定される列のタイプは long または timestamp タイプのいずれかである必要があります。
データに時間列がない場合は、add_time フィルターオプションを使用して追加できます。詳細については、add_time フィルタープラグインを参照してください。
td connector:issue load.yml --database td_sample_db --table td_sample_table \
--time-column created_attd connector:issue は database(td_sample_db) と table(td_sample_table) がすでに作成されていることを前提としています。データベースまたはテーブルが TD に存在しない場合、td connector:issue は失敗します。そのため、データベースとテーブルを手動で作成するか、td connector:issue コマンドの --auto-create-table オプションを使用してデータベースとテーブルを自動的に作成してください。
td connector:issue load.yml \
--database td_sample_db --table td_sample_table \
--time-column created_at --auto-create-tabletime というフィールドがある場合は、--time-column オプションを指定する必要はありません。
td connector:issue load.yml --database td_sample_db --table td_sample_table定期的な Snowflake 一括アンロードインポートのために、データコネクタの定期実行をスケジュールすることができます。
td connector:create コマンドを使用して新しいスケジュールを作成できます。以下が必要です:
- スケジュールの名前
- cron 形式のスケジュール
- データが保存されるデータベースとテーブル
- Data Connector 設定ファイル
td connector:create \
daily_bulk_import \
"10 0 * * *" \
td_sample_db \
td_sample_table \
load.ymlTreasure Data のストレージは時間でパーティション分割されているため、--time-column オプションを指定することもお勧めします(データパーティショニングも参照してください)。
td connector:create \
daily_bulk_import \
"10 0 * * *" \
td_sample_db \
td_sample_table \
load.yml \
--time-column created_atcron パラメータは @hourly、@daily、@monthly の3つの特別なオプションも受け付けます。
デフォルトでは、スケジュールは UTC タイムゾーンで設定されます。-t または --timezone オプションを使用してタイムゾーンを指定してスケジュールを設定できます。--timezone オプションは 'Asia/Tokyo'、'America/Los_Angeles' などの拡張タイムゾーン形式のみをサポートします。PST、CST などのタイムゾーン略語はサポートされておらず、予期しないスケジュールが設定される可能性があります。
td connector:list コマンドを実行することで、スケジュールされたエントリの一覧を確認できます。
td connector:listSnowflake への接続は、Snowflake の公式 JDBC ドライバーを介して行われます。JDBC ドライバーはデフォルトかつ必須として SSL の使用を強制します(つまり、SSL = false の接続は拒否されます)。
Snowflake への接続には、このツールは2つの JDBC 認証オプションを提供します:
- Basic(ユーザー名/パスワード): この標準ログイン方法は、ユーザーの Snowflake アカウントで多要素認証(MFA)が有効になっている場合は失敗します。これは、ジョブ実行中のコネクタの認証プロセスとの競合の可能性によるものです。
- Key Pair 認証: この安全な方法は暗号化鍵ペアを使用します。MFA が有効かどうかに関わらず確実に動作するため、推奨されるアプローチです。
このコネクタは Snowflake の Bulk Data Unloading 機能を使用して高パフォーマンスのデータ転送を実現します。このプロセスには以下が含まれます:
COPY INTO コマンド: COPY INTO <location> コマンドを使用して、Snowflake データベーステーブルからSnowflake ステージのファイルにデータをコピーします。
ファイルダウンロード: GET コマンドを使用して、ステージからコネクタに直接ファイルをダウンロードします。
並列処理: ダウンロードされたファイルは並列で処理され、取り込みパフォーマンスが大幅に向上します。
一括アンロードコネクタの増分ロードは、標準の Snowflake コネクタとは異なるアプローチを使用します:
- 最大値アプローチ: ORDER BY ステートメントを使用する代わりに、コネクタは最大値関数クエリを使用して上限と下限を決定します:
SELECT Max(inc_col) FROM table - 辞書順: 複数の増分列の場合、コネクタは辞書順に並んだ列の組み合わせを使用して境界を特定します。
- パフォーマンス向上: このアプローチにより、大規模データセットでの高コストな ORDER BY 操作を回避できます。
2つの増分列を使用した例:
SELECT *
FROM my_table
WHERE (("region" > ?) OR ("region" = ? AND "date" > ?))
AND (("region" < ?) OR ("region" = ? AND "date" <= ?))最初の実行ではすべてのレコードがロードされ、以降の実行では最大値によって決定された新しい境界内に収まるレコードのみがロードされます。
重要な注意事項:
- incremental_columns としてサポートされるのは Timestamp、Datetime、数値列のみです
- 生クエリの場合、複雑なクエリでは主キーを自動的に検出できないため、incremental_columns が必要です
- 最適なパフォーマンスのために、増分列に適切なインデックスが設定されていることを確認してください
- リソース割り当て: このコネクタは最適なパフォーマンスのために通常のコネクタよりも大きな CPU 割り当てが必要です
- Stage File Size:
stage_file_sizeパラメータを調整することで、データセットサイズと利用可能なメモリに基づいてパフォーマンスを最適化できます - Warehouse サイズ: より大きな Snowflake ウェアハウスを使用すると、非常に大きなデータセットのアンロードパフォーマンスが向上する場合があります
- 並列処理: コネクタはアンロードされたファイルの並列処理を自動的に処理して最大スループットを実現します
- ステージファイルの問題: 指定したウェアハウスにアンロード操作のための十分なリソースがあることを確認してください
- プレビューの問題: 大きなテーブルのプレビューはサンプリングを使用するため、実際のデータ分布を反映しない場合があります
- パフォーマンスの問題: パフォーマンスを向上させるために、ウェアハウスのサイズを大きくするか、ステージファイルサイズを調整することを検討してください