PostgreSQL用データコネクタを使用すると、PostgreSQLデータベースからTreasure Dataにデータを直接インポートできます。PostgreSQLデータのエクスポートについては、PostgreSQLエクスポート連携を参照してください。
- Treasure Dataの基本知識
- PostgreSQLの基本知識
- リモートで実行されているPostgreSQLインスタンス(例:RDS上)
セキュリティポリシーで IP ホワイトリストが必要な場合は、接続を成功させるために Treasure Data の IP アドレスを許可リストに追加する必要があります。
リージョンごとに整理された静的 IP アドレスの完全なリストは、次のリンクにあります: https://api-docs.treasuredata.com/en/overview/ip-addresses-integrations-result-workers/
データ接続を設定する際、連携にアクセスするためのAuthenticationを提供します。Treasure Dataでは、Authenticationを設定してからソース情報を指定します。
- TD Consoleを開きます。
- Integrations Hub > Catalogに移動します。
- PostgreSQLを検索して選択します。Createを選択します。
 4. 次のダイアログが開きます。
4. 次のダイアログが開きます。
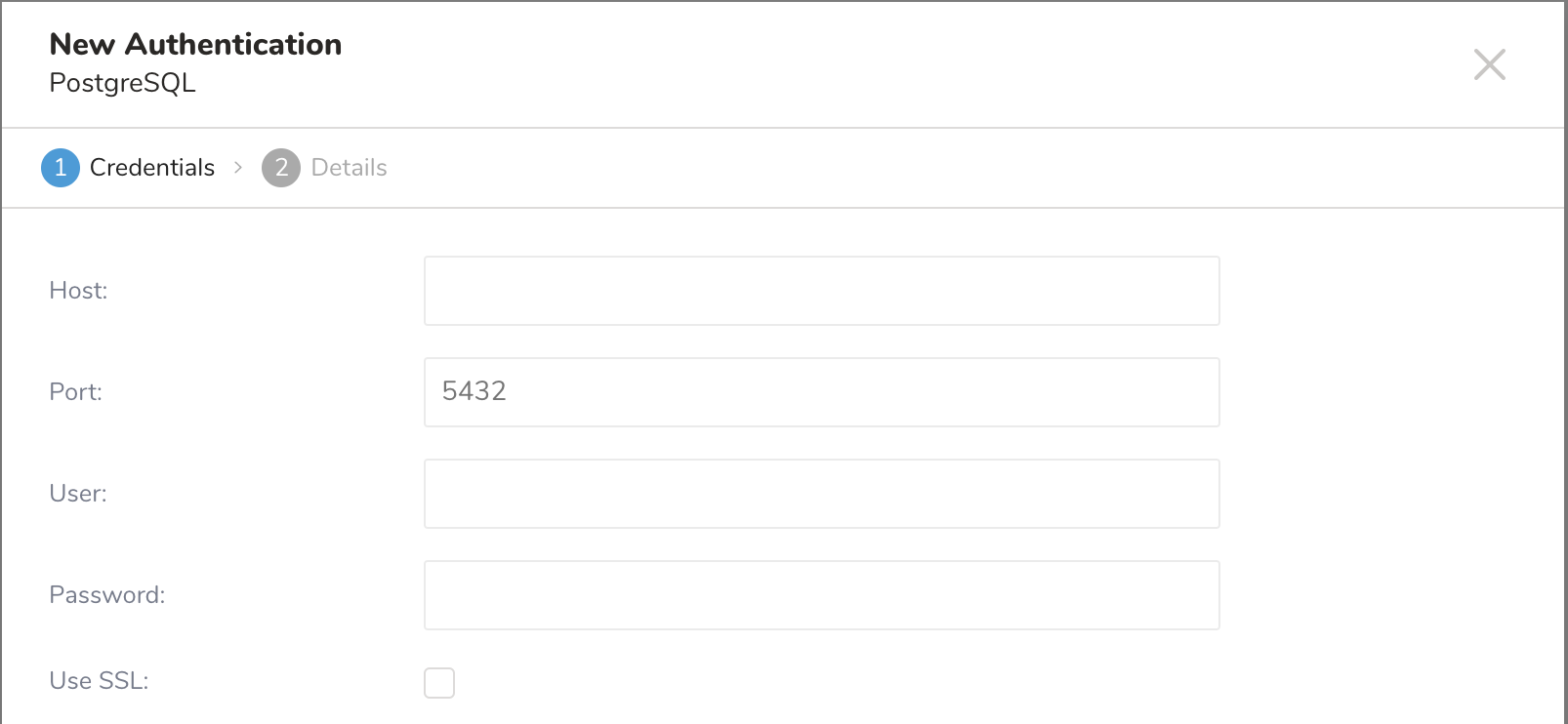
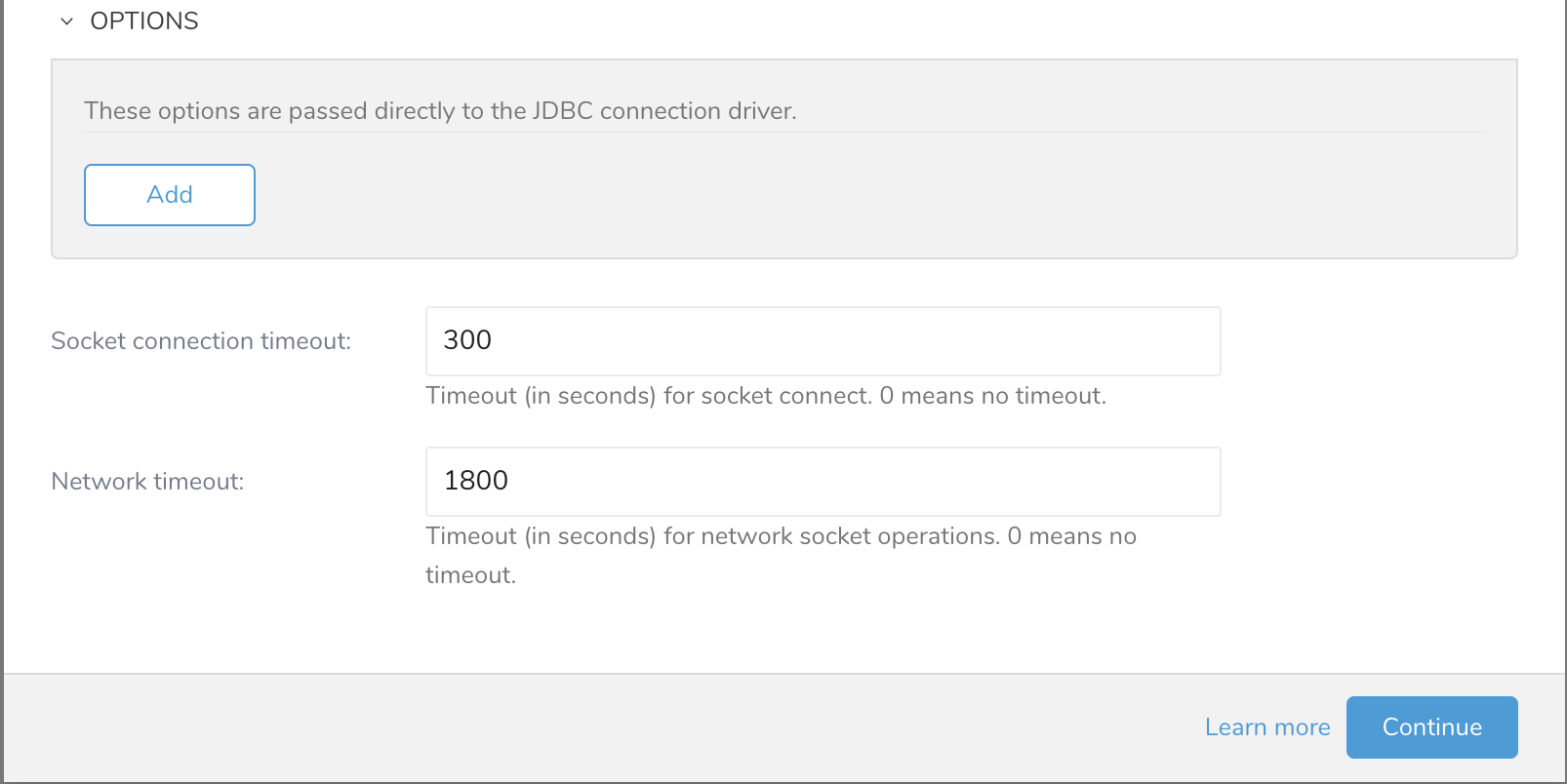 5. 必要なAuthentication情報を入力し、パラメータを設定します。Continueを選択します。
5. 必要なAuthentication情報を入力し、パラメータを設定します。Continueを選択します。
| パラメータ | 説明 |
|---|---|
| Host | IPアドレスなど、ソースデータベースのホスト情報。 |
| Port | ソースインスタンスの接続ポート。PostgreSQLのデフォルトは5432です。 |
| User | ソースデータベースに接続するためのユーザー名。 |
| Password | ソースデータベースに接続するためのパスワード。 |
| Use SSL | SSLを使用して接続する場合は、このボックスをチェックします。 |
| Specify SSL version | 接続に使用するSSLバージョンを選択します。 |
| Socket connection timeout | ソケット接続のタイムアウト(秒単位)(デフォルトは300)。 |
| Network timeout | ネットワークソケット操作のタイムアウト(秒単位)。0はタイムアウトなしを意味します。 |
- 接続の名前を入力します。
- Doneを選択します。
Authentication済み接続を作成すると、自動的にAuthenticationsに移動します。
- 作成した接続を検索します。
- New Sourceを選択します。Create Sourceダイアログが開きます。
- Data TransferフィールドにSourceの名前を入力します。
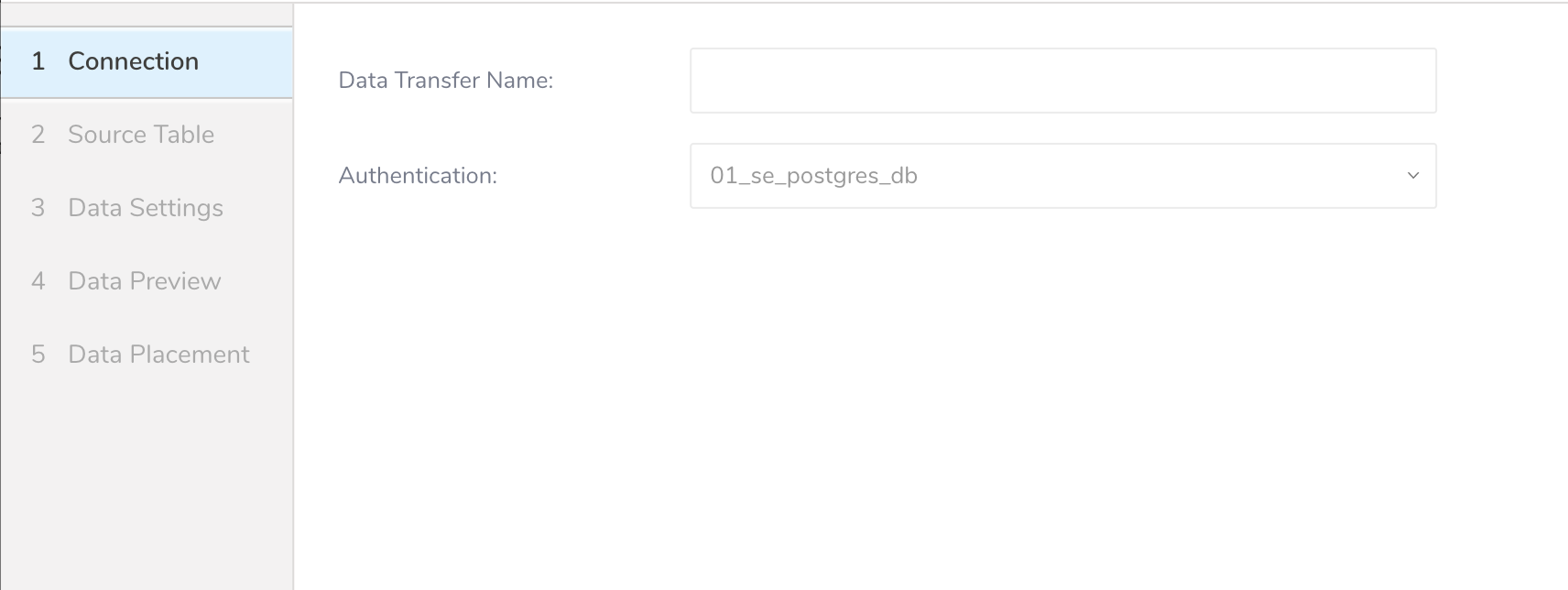
- Nextをクリックします。
- 次のパラメータを編集します
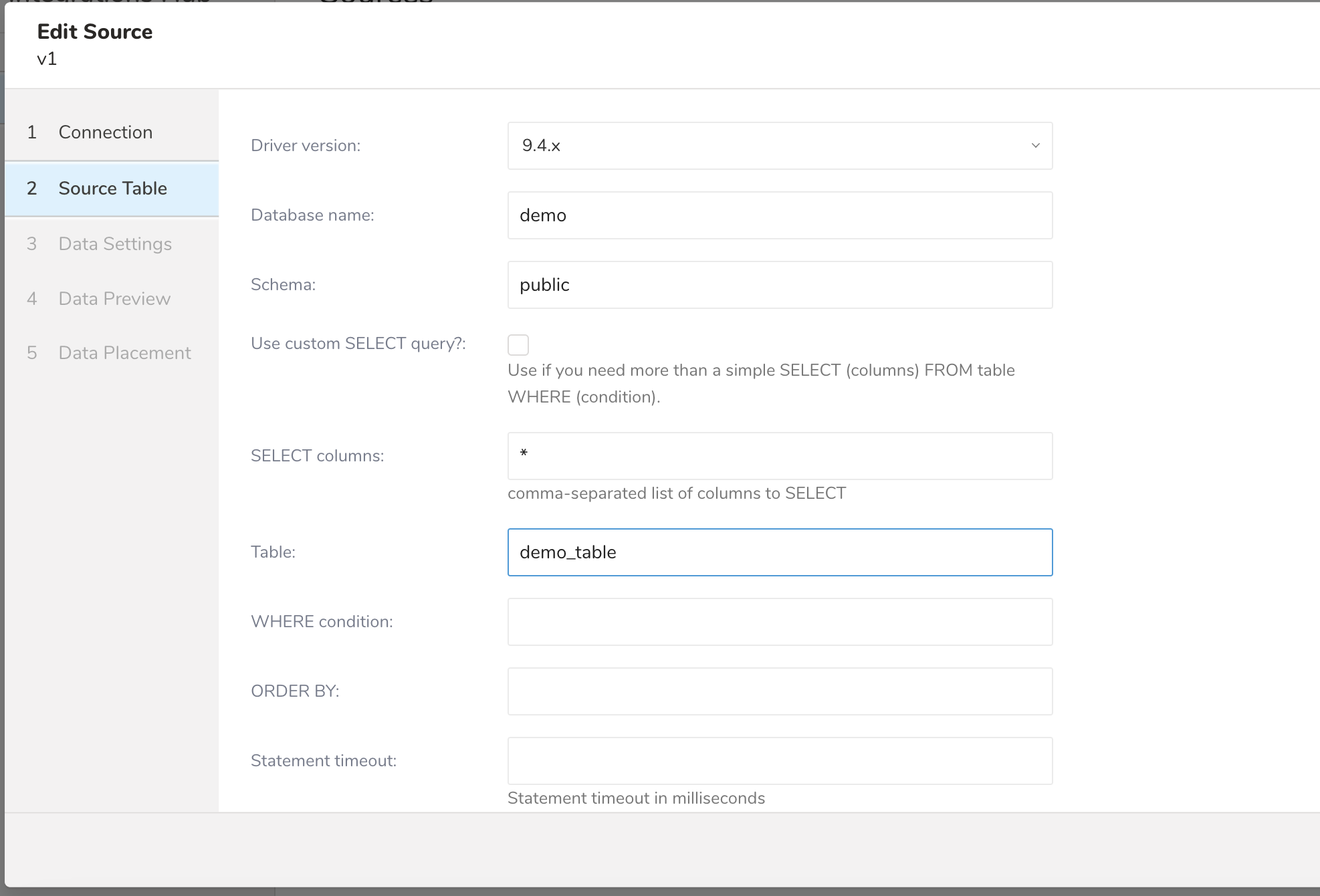
| パラメータ | 説明 |
|---|---|
| Driver version | PostgreSQL JDBCドライバーを選択します |
| Database name | データを転送するデータベースの名前。例:your_database_name。 |
| Use custom SELECT query? | 単純なSELECT (columns) FROM table WHERE (condition)以上のものが必要な場合に使用します。 |
| SELECT columns | データを取得したい特定のカラムがある場合は、ここにリストします。それ以外の場合は、すべてのカラムが転送されます。 |
| Table | データをインポートするテーブル。 |
| WHERE condition | テーブルから取得するデータに追加の条件が必要な場合は、WHERE句の一部として指定します。 |
| ORDER BY | 特定のフィールドでレコードを順序付けする必要がある場合は指定します。 |
- Nextを選択します。Data Settingsページが開きます。
- 必要に応じてデータ設定を編集するか、このページをスキップします。
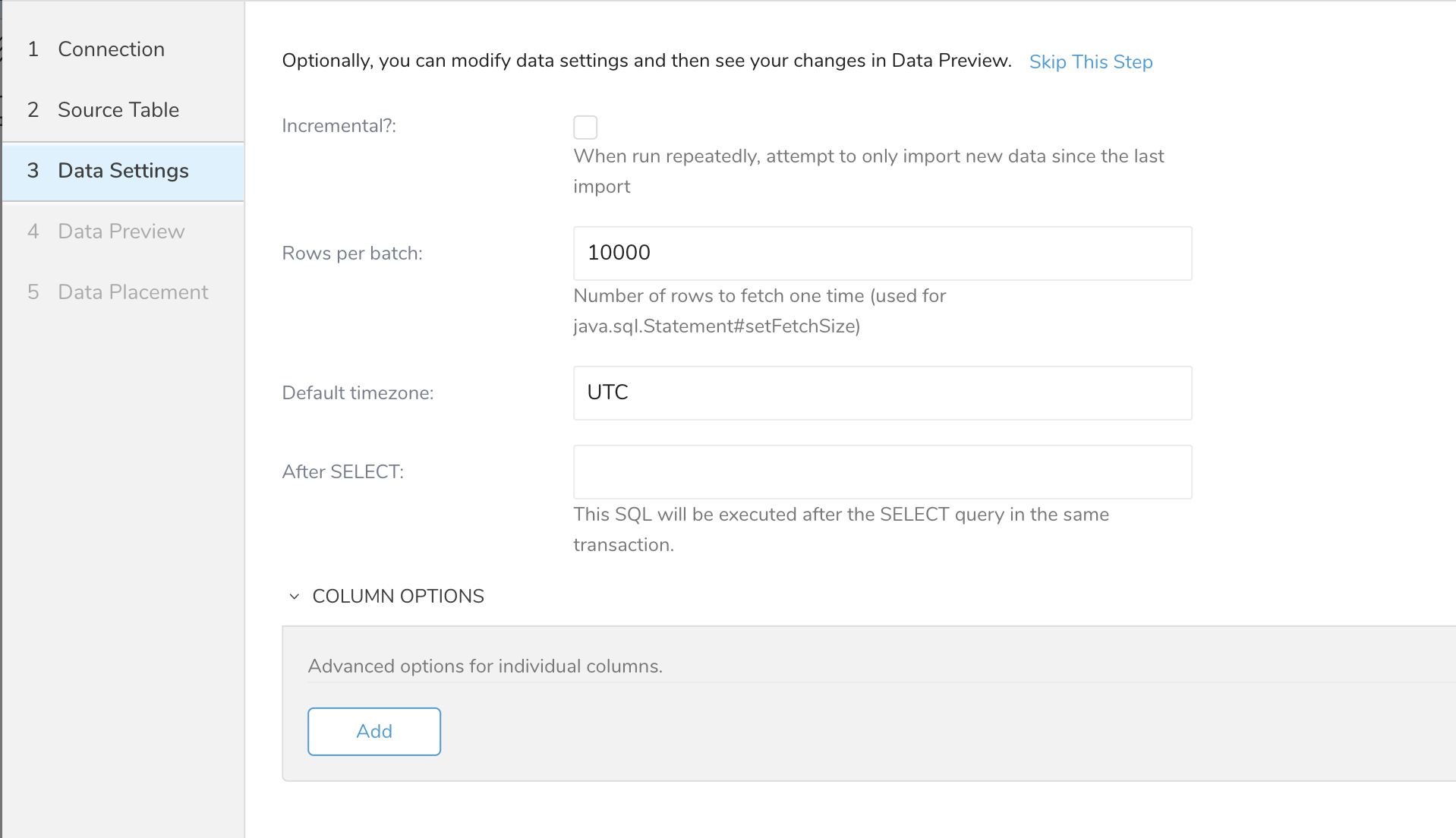
| パラメータ | 説明 |
|---|---|
| Incremental: | この転送を繰り返し実行する場合は、このチェックボックスを選択して、前回インポートが実行されてからのデータのみをインポートします。 |
| Rows per batch | 非常に大きなデータセットはメモリの問題を引き起こし、結果としてジョブが失敗する可能性があります。このフラグを使用して、行数でインポートジョブをバッチに分割し、メモリの問題やジョブの失敗の可能性を減らします。 |
| Default timezone | インポート時に使用するタイムゾーン。 |
| After SELECT | このSQLは、同じトランザクション内のSELECTクエリの後に実行されます。 |
| Column Options | このオプションを選択して、インポート前にカラムのタイプを変更します。入力したデータ設定を保存するには、Saveを選択します。 |
| Default Column Options | このオプションを選択して、インポート前にデフォルトのSQLタイプに従ってデータタイプを定義します。入力したデータ設定を保存するには、Saveを選択します。 このオプションはTD Consoleでは使用できません。TD CLIまたはTD Workflowを使用してこのオプションを設定します。 |
インポートを実行する前に、Generate Preview を選択してデータのプレビューを表示できます。Data preview はオプションであり、選択した場合はダイアログの次のページに安全にスキップできます。
- Next を選択します。Data Preview ページが開きます。
- データをプレビューする場合は、Generate Preview を選択します。
- データを確認します。
データの配置について、データを配置したいターゲット database と table を選択し、インポートを実行する頻度を指定します。
Next を選択します。Storage の下で、インポートされたデータを配置する新しい database を作成するか、既存の database を選択し、新しい table を作成するか、既存の table を選択します。
Database を選択 > Select an existing または Create New Database を選択します。
オプションで、database 名を入力します。
Table を選択 > Select an existing または Create New Table を選択します。
オプションで、table 名を入力します。
データをインポートする方法を選択します。
- Append (デフォルト) - データインポートの結果は table に追加されます。 table が存在しない場合は作成されます。
- Always Replace - 既存の table の全体の内容をクエリの結果出力で置き換えます。table が存在しない場合は、新しい table が作成されます。
- Replace on New Data - 新しいデータがある場合のみ、既存の table の全体の内容をクエリの結果出力で置き換えます。
Timestamp-based Partition Key 列を選択します。 デフォルトキーとは異なるパーティションキーシードを設定したい場合は、long または timestamp 列をパーティショニング時刻として指定できます。デフォルトの時刻列として、add_time フィルターで upload_time を使用します。
データストレージの Timezone を選択します。
Schedule の下で、このクエリを実行するタイミングと頻度を選択できます。
- Off を選択します。
- Scheduling Timezone を選択します。
- Create & Run Now を選択します。
- On を選択します。
- Schedule を選択します。UI では、@hourly、@daily、@monthly、またはカスタム cron の 4 つのオプションが提供されます。
- Delay Transfer を選択して、実行時間の遅延を追加することもできます。
- Scheduling Timezone を選択します。
- Create & Run Now を選択します。
転送が実行された後、Data Workbench > Databases で転送の結果を確認できます。
最新のTreasure Data Toolbeltをインストールします。
PostgreSQLアクセス情報でseed.ymlを設定します:
in:
type: postgresql
host: postgresql_host_name
port: 5432
ssl: true
ssl_version: TLS
user: test_user
password: test_password
driver_version: 42.7.x
database: test_database
table: test_table
select: "*"
default_column_options:
TIMESTAMP: {type: string, timestamp_format: '%Y-%m-%d', timezone: '+0900'}
BIGINT: {type: string}
mode: replaceこの例では、テーブル内のすべてのレコードをインポートします。追加パラメータを使用して、より詳細な制御を行うことができます。
利用可能なoutモードまたは利用可能なssl_versionの詳細については、付録を参照してください。
td connector:guessを使用します。このコマンドは、ターゲットデータを自動的に読み取り、データ形式をインテリジェントに推測します。
td connector:guess seed.yml -o load.ymlload.ymlを開くと、場合によってはファイル形式、エンコーディング、カラム名、タイプを含む、推測されたファイル形式定義が表示されます。
td connector:previewコマンドを使用して、インポートするデータをプレビューできます。
td connector:preview load.ymlロードジョブを送信します。データサイズに応じて、ジョブの実行に数時間かかる場合があります。データが保存されているデータベースとテーブルを指定する必要があります。
Treasure Dataのストレージは時間でパーティション分割されているため、--time-columnオプションを指定することをお勧めします(データパーティショニングも参照)。オプションが指定されていない場合、データコネクタは最初のlongまたはtimestampカラムをパーティショニング時間として選択します。--time-columnで指定されたカラムのタイプは、longまたはtimestampタイプである必要があります。
データに時間カラムがない場合は、add_timeフィルターオプションを使用して追加できます。詳細については、add_timeフィルタープラグインを参照してください。
td connector:issue load.yml --database td_sample_db --table td_sample_tableconnector:issueコマンドは、database(td_sample_db)とtable(td_sample_table)をすでに作成していることを前提としています。データベースまたはテーブルがTDに存在しない場合、connector:issueコマンドは失敗します。この場合、データベースとテーブルを手動で作成するか、td connector:issueコマンドで--auto-create-tableオプションを使用して、データベースとテーブルを自動作成します:
td connector:issue load.yml \
--database td_sample_db --table td_sample_table \
--time-column created_at --auto-create-table"--time-column"オプションで、Time FormatカラムをPartitioning Keyに割り当てることができます。
PostgreSQLからデータをインポートする方法を示すサンプルワークフローについては、Treasure Boxesを参照してください。
テーブルからカラムをincremental_columnsパラメータに指定することで、レコードをインクリメンタルにロードできます。オプションで、last_recordパラメータにいくつかの初期値を指定できます。
in:
type: postgresql
host: postgresql_host_name
port: 5432
user: test_user
password: test_password
database: test_database
table: test_table
incremental: true
incremental_columns: [id, created_at]
last_record: [10000, '2014-02-16T13:01:06.000000Z']
out:
mode: append
exec: {}incremental\_columns:オプションを最適に使用するには、関連するカラムにインデックスを作成して、フルテーブルスキャンを回避します。この例では、次のインデックスを作成する必要があります:
CREATE INDEX embulk_incremental_loading_index ON test_table (id, created_at);-- last_recordが指定されていない場合
SELECT * FROM(
...original query is here
)
ORDER BY id, created_at-- last_recordが指定された場合
SELECT * FROM(
...original query is here
)
WHERE id > 10000 OR (id = 10000 AND created_at > '2014-02-16T13:01:06.000000Z')
ORDER BY id, created_atコネクタは自動的にlast_recordを生成し、次のスケジュール実行時にそれを使用します。
in:
type: postgresql
...
out:
...
Config Diff
---
in:
last_record:
- 20000
- '2015-06-16T16:32:14.000000Z'incremental: trueを設定すると、queryオプションは使用できません。 incremental_columnsとしてサポートされているのは、文字列、整数、timestamp、およびtimestamptz(タイムゾーン付きタイムスタンプ)のみです。
PostgreSQLのarray型は、文字列型として取得されます。
PostgreSQLのhstore型は、データコネクタが最初に読み取るときに文字列型として取得されます。したがって、hstore型をjson型として使用する場合は、config_optionsを指定して、明示的に型をjson型に変換する必要があります。
例えば、v_hstoreがPostgreSQLでhstore型の場合:
in:
type: postgresql
host: xxx
...
table: my_tbl
select: "*"
column_options:
v_hstore: {type: json} # 明示的な型変換: string型からjson型へ
out:
...ssl_versionオプションを使用して、PostgreSQLサーバーが使用している特定のSSLバージョンを使用できます。
in:
type: postgresql
...
ssl: true
ssl_version: TLSv1.1サポートされている値は次のとおりです。
- TLS
- TLSv1.1
- TLSv1.2
- TLSv1.3
SQLデータ型の特定のデフォルト形式を使用できます。 以下の例では、TIMESTAMPは%Y-%m-%d形式でタイムゾーン+0900の文字列に変換されます。 SQLタイプは、TIMESTAMPやBIGINTなどの大文字である必要があります。
in:
type: postgresql
...
default_column_options:
TIMESTAMP: {type: string, timestamp_format: '%Y-%m-%d', timezone: '+0900'}
BIGINT: {type: string}