世界中でますます多くのデータ保護法が制定される中、コンプライアンスの確保は優先事項となっています。OneTrustは、プライバシー管理とマーケティングコンプライアンスを提供する企業です。このサービスは、GDPRなどのグローバルな規制に準拠するために組織によって利用されています。
このOneTrustインポート連携は、顧客の同意データを収集してTreasure Dataにロードできるインポート連携を提供します。Treasure Dataプラットフォーム上でOneTrustデータにアクセスできることで、マーケティングチームがデータを最適に活用できるようになります。
- Treasure Dataの基礎知識
- OneTrustの基礎知識
- データを制限するための単一のコレクションポイントのGUID(提供されない場合は、すべてのコレクションポイントから取得されます)
必要に応じてOneTrustアプリケーションにサインオンします。
Add New を選択します。
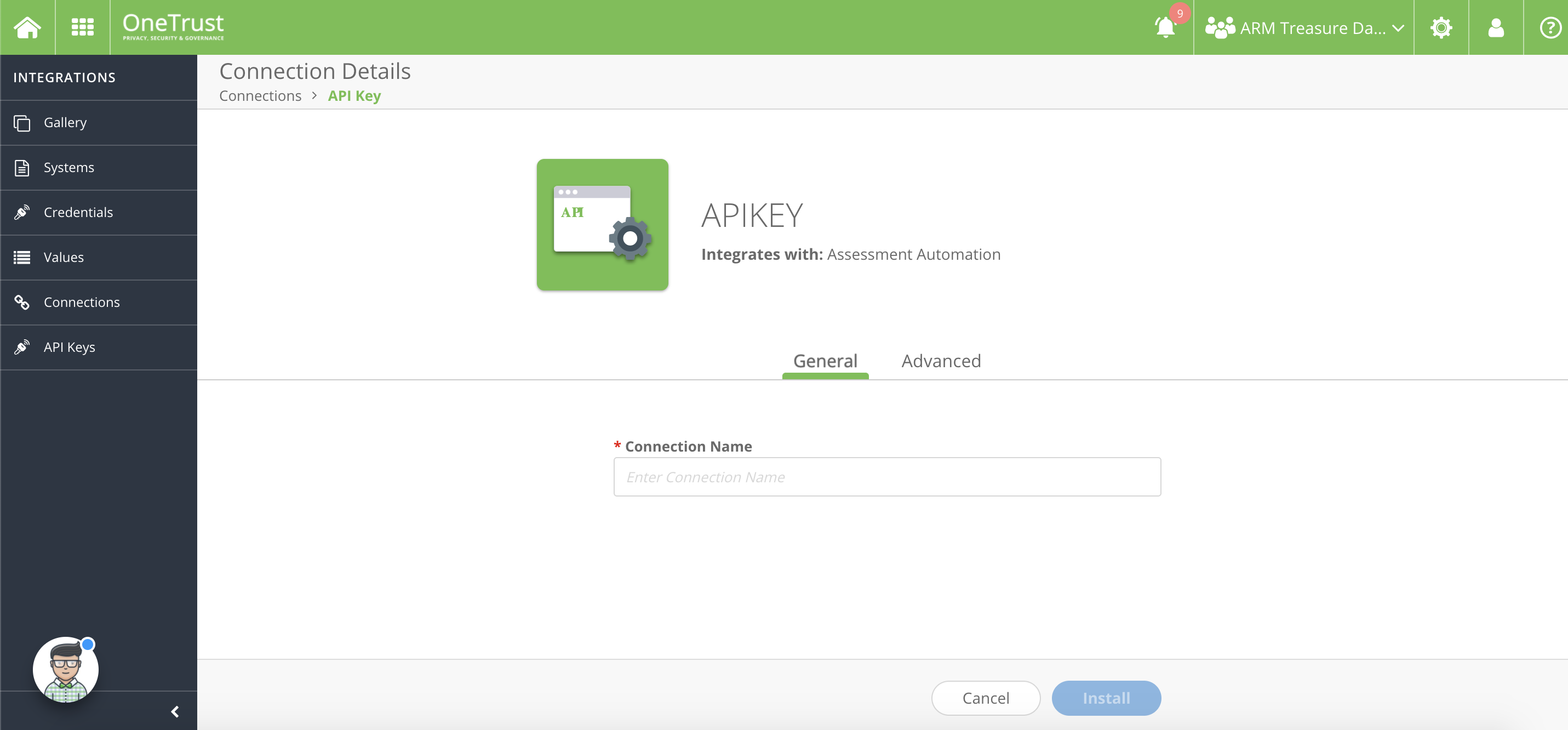
接続名として使用する名前を入力します。
Install を選択します。
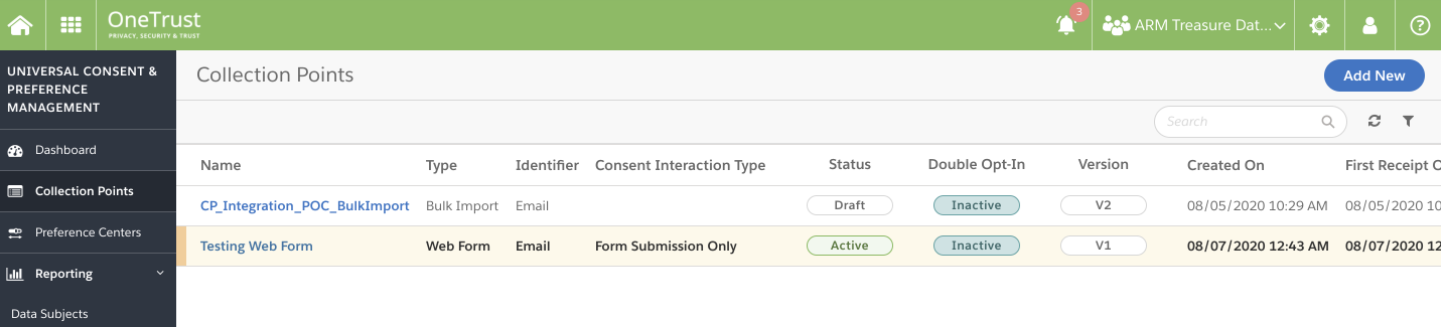
https://app.onetrust.com/consent/collection-points にアクセスします。 コレクションポイント画面が表示されます。
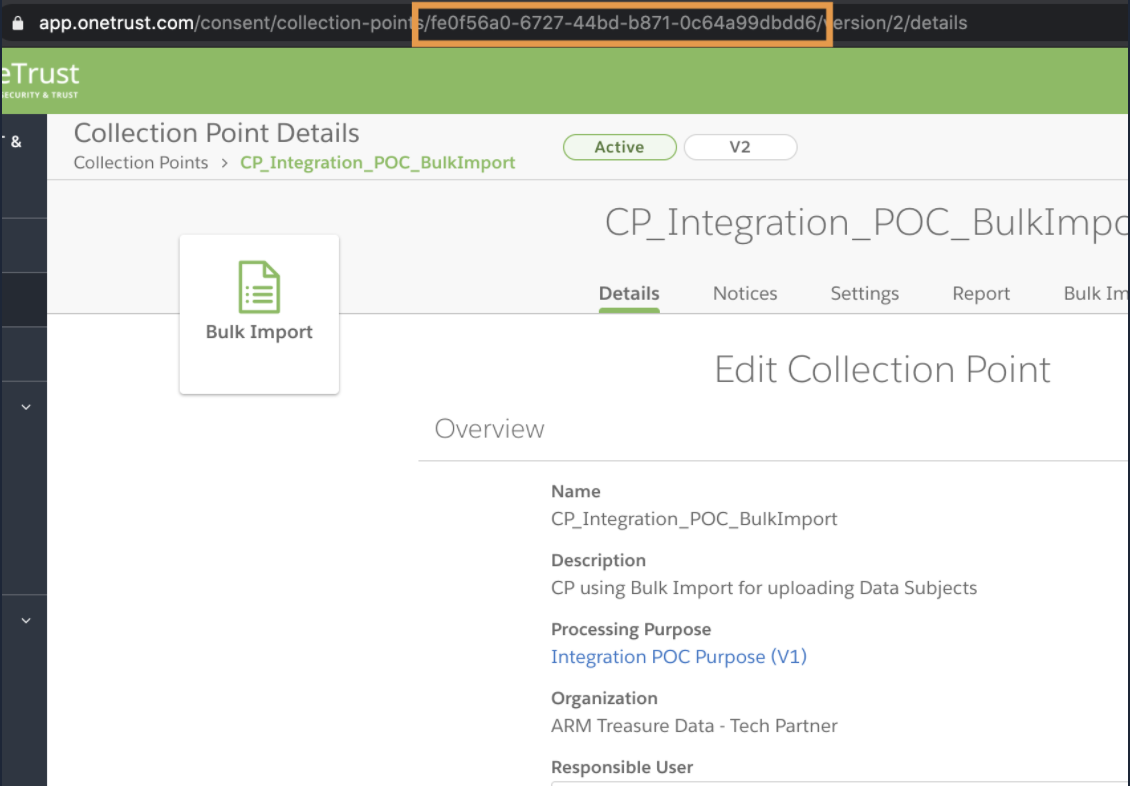
対応するコレクションポイントを選択すると、GUIDがURLに表示されます。例:
クライアントIDとシークレットを保存するためのOneTrustトークンを作成します。 これは短期間有効なトークンです。
https://app.onetrust.com/settings/client-credentials/list にアクセスします。
Add を選択します。
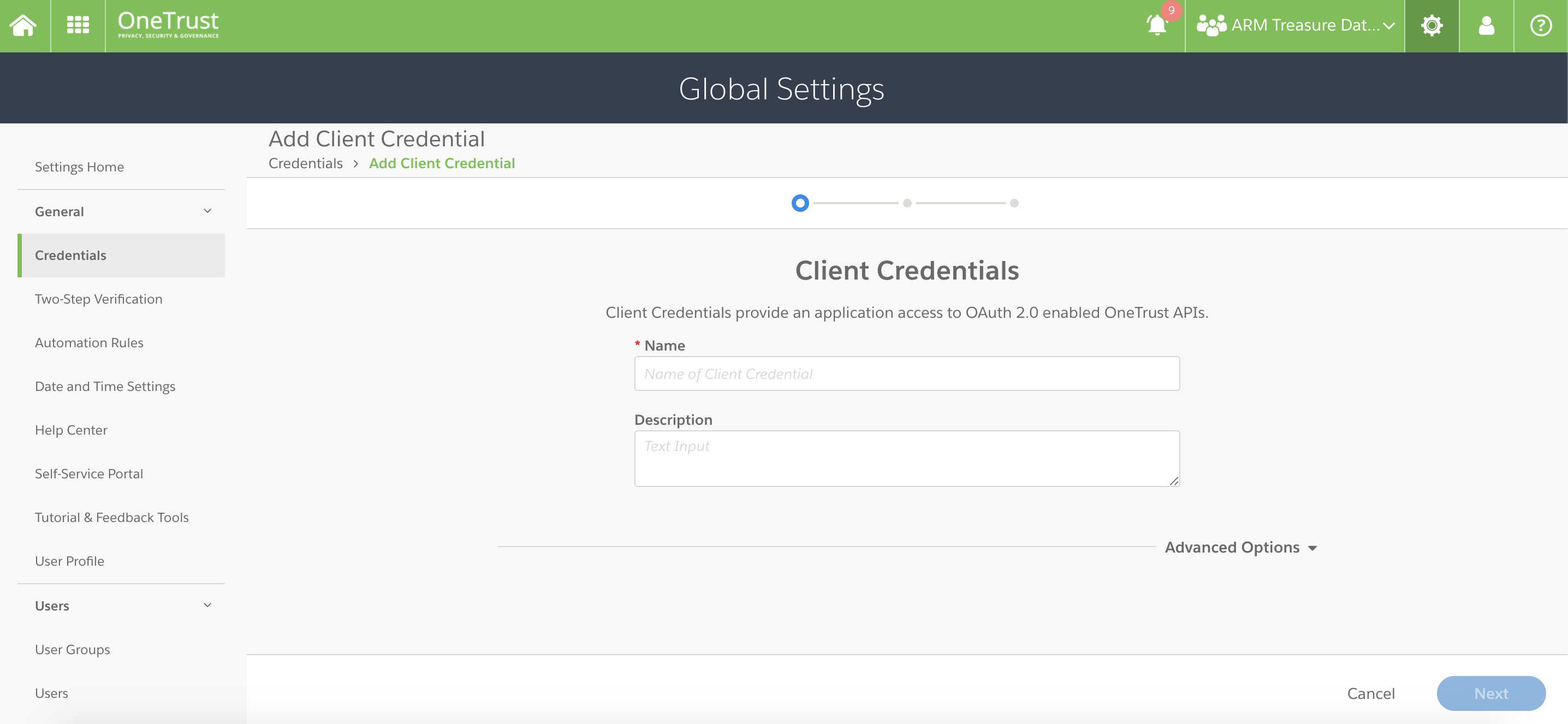
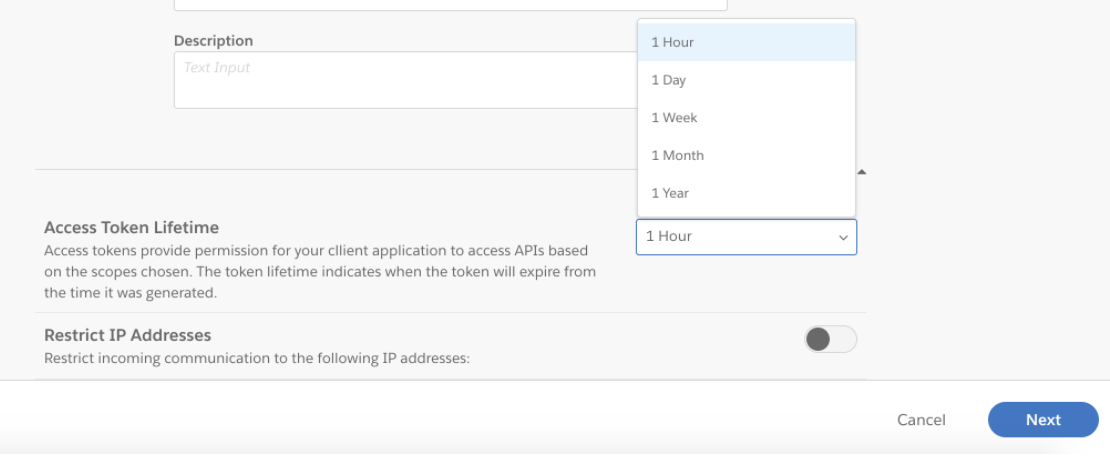
トークンの名前と説明を入力します。
適切な Access Token Lifetime を選択します。デフォルトの有効期間は1時間です。
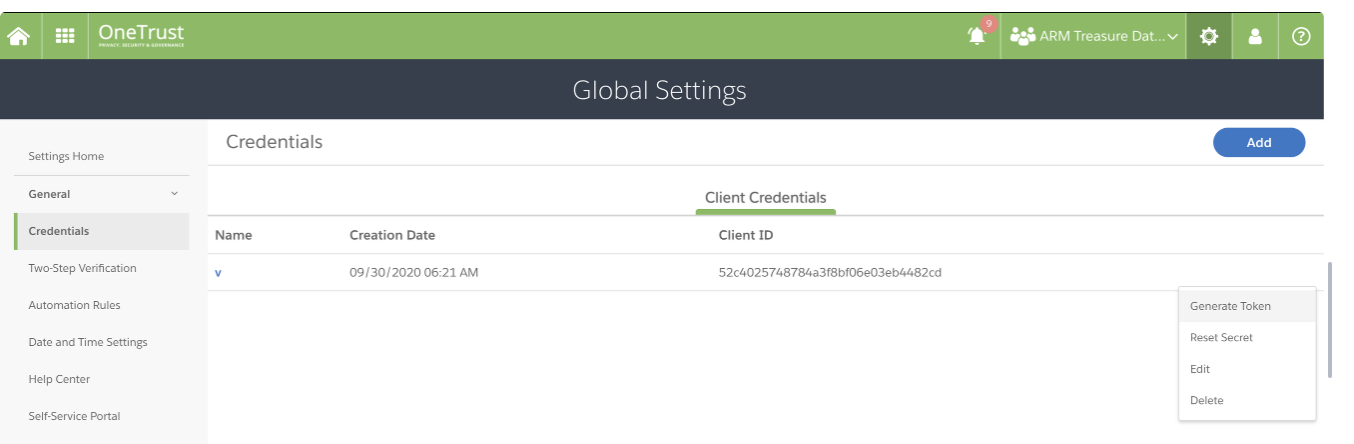
https://app.onetrust.com/settings/client-credentials/list にアクセスします。
認証情報を選択します。
Generate Token を選択します。
データ接続を構成する際、連携にアクセスするための認証を提供します。Treasure Dataでは、認証を構成し、ソース情報を指定します。
TD Consoleを開きます。
Integrations Hub > Catalogに移動します。
OneTrustを検索して選択します。
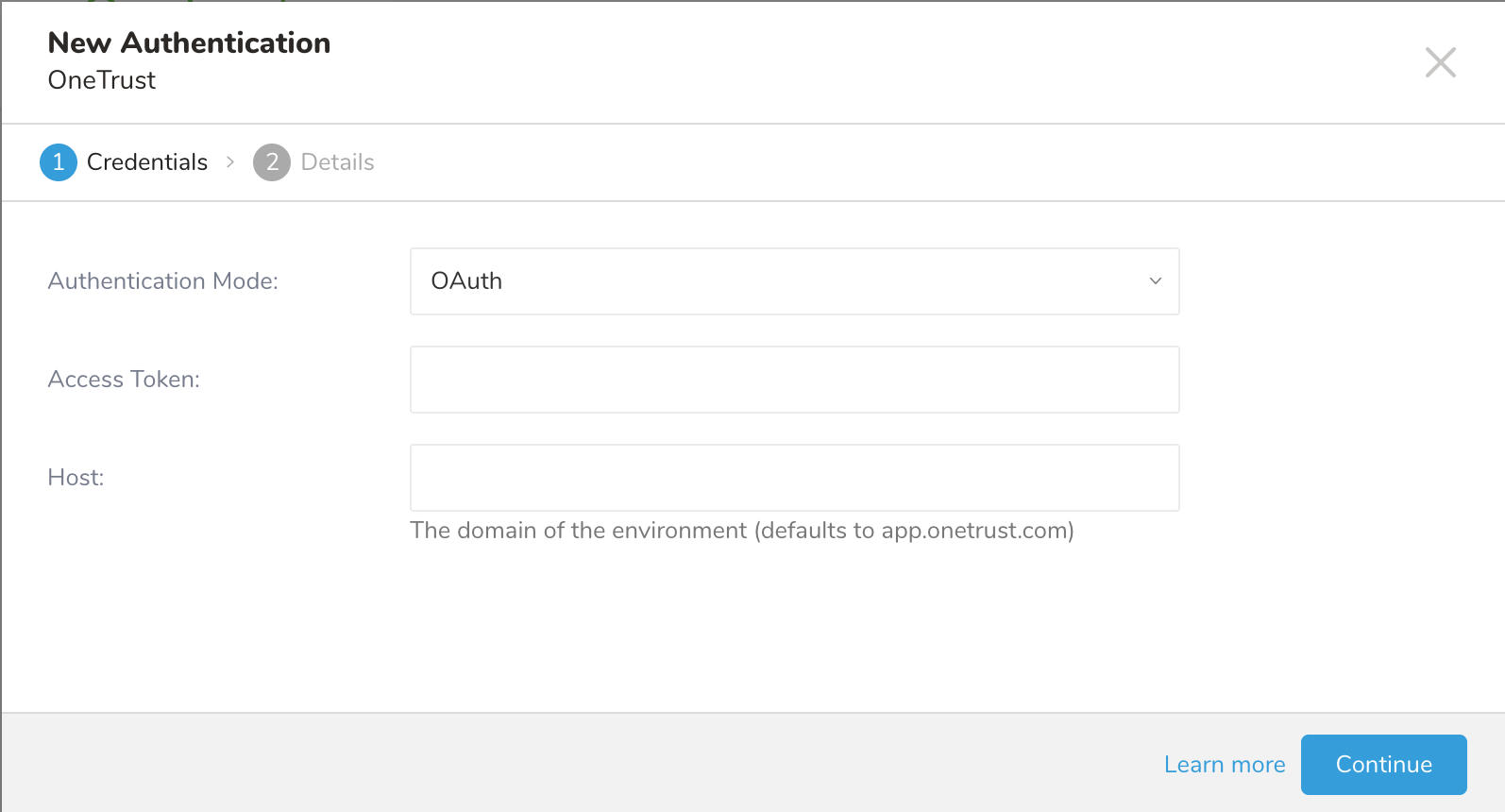
OneTrustアプリケーションで作成したアクセストークンの名前を入力します。
Continueを選択します。
接続の名前を入力します。
Done を選択します。
認証済み接続を作成すると、自動的にAuthenticationsに移動します。
作成した接続を検索します。
New Source を選択します。
データ転送の名前を入力します。
Next を選択します。 Source Tableダイアログが開きます。
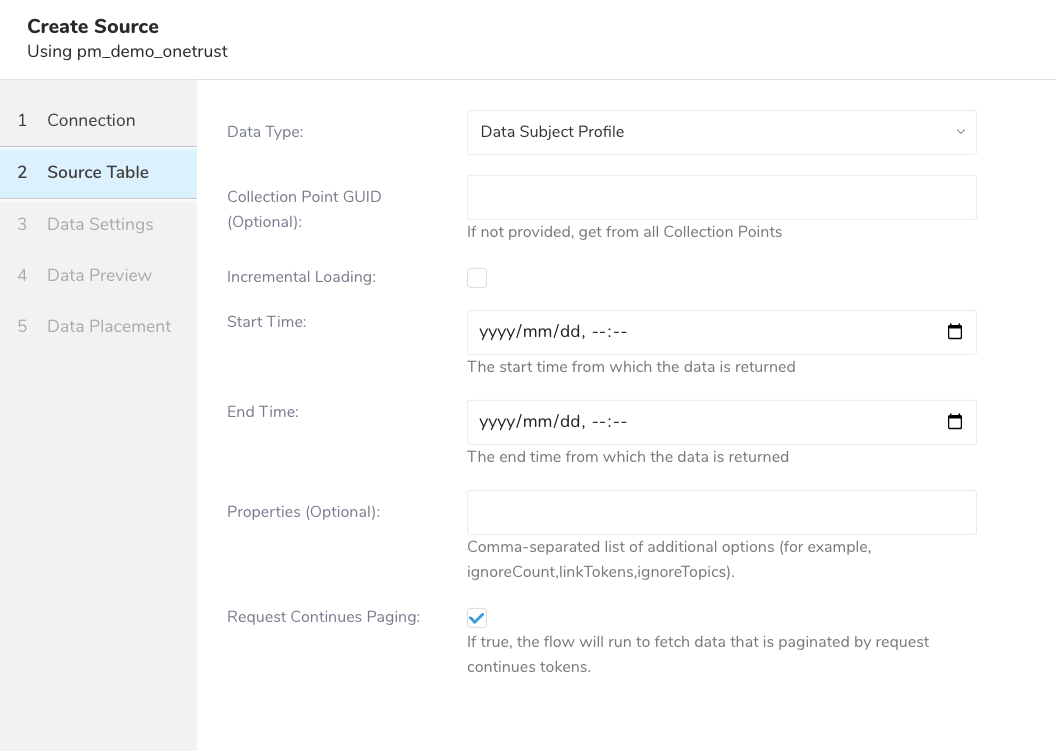
Next を選択します。 Data Settingsダイアログが開きます。
以下のパラメータを編集します:
| パラメータ | 説明 |
|---|---|
| Data Type |
|
| Collection Point GUID(オプション) | データを制限するための単一のコレクションポイントのGUID。提供されない場合は、すべてのコレクションポイントから取得されます。 |
| Incremental Loading | 新しいStart Timeの自動計算による増分レポートの読み込みを有効にします。例えば、Start Time = 2014-10-02T15:01:23Z から 2014-10-03T15:01:23Z で増分読み込みを開始した場合、次のジョブ実行時の新しいStart Timeは 2014-10-03T15:01:23 になります。 |
| Start Time(Incremental Loading選択時に必須。すべてのAPI V4データタイプで必須) | UI設定の場合、対応ブラウザから日付と時刻を選択するか、ブラウザが期待する形式で日付を入力できます。例えば、Chromeでは年、月、日、時、分を選択するカレンダーが表示されます。Safariでは2020-10-25T00:00のようなテキストを入力する必要があります。CLI設定の場合、RFC3339 UTC "Zulu"形式のタイムスタンプ(ナノ秒まで正確)が必要です。例:"2014-10-02T15:01:23Z" |
| Incremental By Modifications of |
|
| End Time(Incremental Loading選択時に必須。すべてのAPI V4データタイプで必須) | UI設定の場合、対応ブラウザから日付と時刻を選択するか、ブラウザが期待する形式で日付を入力できます。例えば、Chromeでは年、月、日、時、分を選択するカレンダーが表示されます。Safariでは2020-10-25T00:00のようなテキストを入力する必要があります。CLI設定の場合、RFC3339 UTC "Zulu"形式のタイムスタンプ(ナノ秒まで正確)が必要です。例:"2014-10-02T15:01:23Z" |
| Properties(オプション) | Data Subject Profileデータタイプを取得する際にpropertiesクエリパラメータを追加するためのカンマ区切り設定。データタイプでData Subject Profileを選択すると表示されます。注意事項:
|
| Request Continues Paging(オプション) -- チェックした場合、リクエストの継続トークンによってページ分割されたデータを取得するための取り込みプロセスが実行されます。このオプションは、データ量が大きい場合に便利です。 |
- Nextを選択します。 データ設定ページが開きます。
- ダイアログのこのページはスキップします。
インポートを実行する前に、Generate Preview を選択してデータのプレビューを表示できます。Data preview はオプションであり、選択した場合はダイアログの次のページに安全にスキップできます。
- Next を選択します。Data Preview ページが開きます。
- データをプレビューする場合は、Generate Preview を選択します。
- データを確認します。
データの配置について、データを配置したいターゲット database と table を選択し、インポートを実行する頻度を指定します。
Next を選択します。Storage の下で、インポートされたデータを配置する新しい database を作成するか、既存の database を選択し、新しい table を作成するか、既存の table を選択します。
Database を選択 > Select an existing または Create New Database を選択します。
オプションで、database 名を入力します。
Table を選択 > Select an existing または Create New Table を選択します。
オプションで、table 名を入力します。
データをインポートする方法を選択します。
- Append (デフォルト) - データインポートの結果は table に追加されます。 table が存在しない場合は作成されます。
- Always Replace - 既存の table の全体の内容をクエリの結果出力で置き換えます。table が存在しない場合は、新しい table が作成されます。
- Replace on New Data - 新しいデータがある場合のみ、既存の table の全体の内容をクエリの結果出力で置き換えます。
Timestamp-based Partition Key 列を選択します。 デフォルトキーとは異なるパーティションキーシードを設定したい場合は、long または timestamp 列をパーティショニング時刻として指定できます。デフォルトの時刻列として、add_time フィルターで upload_time を使用します。
データストレージの Timezone を選択します。
Schedule の下で、このクエリを実行するタイミングと頻度を選択できます。
- Off を選択します。
- Scheduling Timezone を選択します。
- Create & Run Now を選択します。
- On を選択します。
- Schedule を選択します。UI では、@hourly、@daily、@monthly、またはカスタム cron の 4 つのオプションが提供されます。
- Delay Transfer を選択して、実行時間の遅延を追加することもできます。
- Scheduling Timezone を選択します。
- Create & Run Now を選択します。
転送が実行された後、Data Workbench > Databases で転送の結果を確認できます。
統合を設定する前に、最新バージョンのTD Toolbeltをインストールしてください。
in:
type: onetrust
base_url: ***************
auth_method: oauth
access_token: ***************
data_type: data_subject_profile
incremental: false
start_time: 2025-01-30T00:49:04Z
end_time: 2025-02-28T17:00:00.000Z
thread_count: 5
out:
mode: replaceこの例は、データサブジェクトプロファイルオブジェクトのリストを取得します。start_timeは、データの取得を開始する日付を指定します。この場合、インポートは2025年1月30日の00:49からデータを取得し始めます。
パラメータリファレンス
| 名前 | 説明 | 値 | デフォルト値 | 必須 | |
|---|---|---|---|---|---|
| type | インポートのソース。 | "onetrust" | Yes | ||
| base_url | OnetrustサーバーのベースURL。 | 文字列 | "app.onetrust.com" | Yes | |
| auth_method | 認証方法「oauth」または「api_key」 | 文字列 | "oauth" | Yes | |
| access_token | oauth認証モードの場合に必要なOAuthアクセストークン。 | 文字列 | auth_methodが「oauth」の場合Yes | ||
| api_key | api_key認証モードの場合に必要なAPIキー。 | 文字列 | auth_medthod が「api_key」の場合Yes | ||
| data_type | Onetrustから取得したいデータタイプ。
| 文字列。サポートされているdata_type:
| Yes | ||
| collection_point_guid(オプション) | データを制限するための単一のコレクションポイントのGUID。指定されていない場合は、すべてのコレクションポイントから取得します。データタイプがData Subject Profileおよび**Purpose (API V4)**の場合に表示されます。 | 文字列 | No | ||
| incremental | 新しい開始時刻を自動計算して、増分レポートの読み込みを有効にします。例えば、開始時刻が2014-10-02T15:01:23Zで終了時刻が2014-10-03T15:01:23Zの増分読み込みを開始すると、次のジョブ実行時の新しい開始時刻は2014-10-03T15:01:23になります。 | Boolean | False | Yes | |
start_time | UI設定の場合、サポートされているブラウザから日付と時刻を選択するか、ブラウザが期待する日時形式に適した日付を入力できます。例えば、Chromeでは年、月、日、時、分を選択できるカレンダーが表示され、Safariでは CLI設定の場合、RFC3339 UTC「Zulu」形式のタイムスタンプが必要です。ナノ秒まで正確に記述します。例: | タイムスタンプ | 増分ロードを選択した場合Yes。 すべてのAPI V1データタイプ(data_subject_apiおよびcollection_point)の場合No。 すべてのAPI V4データタイプ(data_subject_profile_v4、link_token_api_v4、purpose_api_v4)の場合Yes。 | ||
| incremental_type | Onetrustからデータを取得する時刻タイプを選択します。 | 文字列
| collection_point。同意情報の最終同意日による増分。 | "data_subject_profile" | data_subject_profile Data Typeで増分読み込みを選択した場合はYes。 |
data_subject_properties(オプション) | Data Subject Profile Data Typeを取得する際に Data Type Data Subject Profileを選択した場合に表示されます。 | String | No | ||
end_time | UI設定の場合、サポートされているブラウザから日付と時刻を選択するか、ブラウザの日時形式に適した日付を入力できます。たとえば、Chromeでは年、月、日、時、分を選択するカレンダーが表示されます。Safariでは CLI設定の場合、RFC3339 UTC "Zulu"形式のタイムスタンプが必要で、ナノ秒まで正確である必要があります。例: | TimeStamp | すべてのAPI V1 Data Type(data_subject_apiおよびcollection_point)ではNo。 すべてのAPI V4 Data Type(data_subject_profile_v4、link_token_api_v4、およびpurpose_api_v4)ではYes。 | ||
| request_continues_paging | trueの場合、取り込みプロセスはリクエスト継続トークンによってページ分割されたデータを取得するために実行されます。このオプションは、データ量が大きい場合に便利です。 | Boolean | false | No | |
| ingest_duration_minutes | targetがdata_subject_profileでrequest_continues_pagingがtrueの場合の取り込み期間の時間範囲を設定します | Integer | 1440 | No |
データをプレビューするには、 td connector:preview コマンドを使用します。
td connector:preview load.ymlデータのサイズによっては、数時間かかる場合があります。データを保存するTreasure Dataのデータベースとテーブルを必ず指定してください。Treasure Dataのストレージは時間でパーティション化されているため、--time-columnオプションも指定することを推奨します(データパーティショニングを参照)。このオプションが指定されていない場合、データコネクターは最初のlong型またはtimestamp型の列をパーティショニング時間として選択します。--time-columnで指定する列の型は、long型またはtimestamp型のいずれかである必要があります。
データに時間列がない場合は、add_timeフィルターオプションを使用して時間列を追加できます。詳細については、add_timeフィルター関数のドキュメントを参照してください。
$ td connector:issue load.yml --database td_sample_db --table td_sample_table \--time-column created_atconnector:issueコマンドは、すでにデータベース(td_sample_db)とテーブル(td_sample_table)が作成されていることを前提としています。TDにデータベースまたはテーブルが存在しない場合、このコマンドは失敗します。データベースとテーブルを手動で作成するか、td connector:issueコマンドで--auto-create-tableオプションを使用してデータベースとテーブルを自動作成してください。
$ td connector:issue load.yml --database td_sample_db --table td_sample_table--time-column created_at --auto-create-tableデータコネクターはサーバー側でレコードをソートしません。時間ベースのパーティショニングを効果的に使用するには、事前にファイル内のレコードをソートしてください。
timeというフィールドがある場合は、--time-columnオプションを指定する必要はありません。
$ td connector:issue load.yml --database td_sample_db --table td_sample_tableload.ymlファイルのout:セクションでファイルインポートモードを指定します。out:セクションは、データがTreasure Dataテーブルにどのようにインポートされるかを制御します。たとえば、既存のテーブルにデータを追加するか、データを置き換えるかを選択できます。
| モード | 説明 | 例 |
|---|---|---|
| Append | レコードがターゲットテーブルに追加されます。 | in: ... out: mode: append |
| Always Replace | ターゲットテーブルのデータを置き換えます。ターゲットテーブルに対して行われた手動のスキーマ変更はそのまま残ります。 | in: ... out: mode: replace |
| Replace on new data | インポートする新しいデータがある場合にのみ、ターゲットテーブルのデータを置き換えます。 | in: ... out: mode: replace_on_new_data |
増分ファイルインポートのために、定期的なデータコネクターの実行をスケジュールできます。Treasure Dataスケジューラーは、高可用性を確保するように最適化されています。
スケジュールされたインポートの場合、指定されたプレフィックスに一致し、次のいずれかの条件を満たすすべてのファイルをインポートできます:
- use_modified_timeが無効になっている場合、最後のパスが次回の実行のために保存されます。2回目以降の実行では、統合はアルファベット順で最後のパスより後のファイルのみをインポートします。
- それ以外の場合、ジョブが実行された時刻が次回の実行のために保存されます。2回目以降の実行では、コネクターはその実行時刻以降にアルファベット順で変更されたファイルのみをインポートします。
td connector:createコマンドを使用して新しいスケジュールを作成できます。
$ td connector:create daily_import "10 0 * * *" \td_sample_db td_sample_table load.ymlTreasure Dataのストレージは時間でパーティション化されているため、--time-columnオプションも指定することを推奨します(データパーティショニングを参照)。
$ td connector:create daily_import "10 0 * * *" \td_sample_db td_sample_table load.yml \--time-column created_atcronパラメータは、@hourly、@daily、@monthlyの3つの特別なオプションも受け入れます。
デフォルトでは、スケジュールはUTCタイムゾーンで設定されます。-tまたは--timezoneオプションを使用して、タイムゾーンでスケジュールを設定できます。--timezoneオプションは、Asia/Tokyo、America/Los_Angelesなどの拡張タイムゾーン形式のみをサポートしています。PST、CSTなどのタイムゾーンの略語はサポートされておらず、予期しないスケジュールになる可能性があります。