Dynalyst Export Integrationの詳細はこちらをご覧ください。
Dynalystデータコネクタを使用すると、S3バケットに保存されているJSON、TSV、CSVファイルからTreasure Dataのカスタマーデータプラットフォームにデータをインポートできます。
Dynalystは、ストレージ場所としてAWS S3を使用しており、インポートプロセスはAWS S3からのデータインポートと同様です。
このコネクタを使用してOneDriveへエクスポートすることもできます。Dynalyst Export Integrationをご覧ください。
インポートまたはクエリエクスポートを実行する前に、Dynalystで使用する接続と認証を完了する必要があります。
- Dynalyst Import and Export Integrationで以下を確認し、完了してください。
- 前提条件
- 新しい接続を作成する
- Dynalyst認証を検索します。
- New Sourceを選択します。

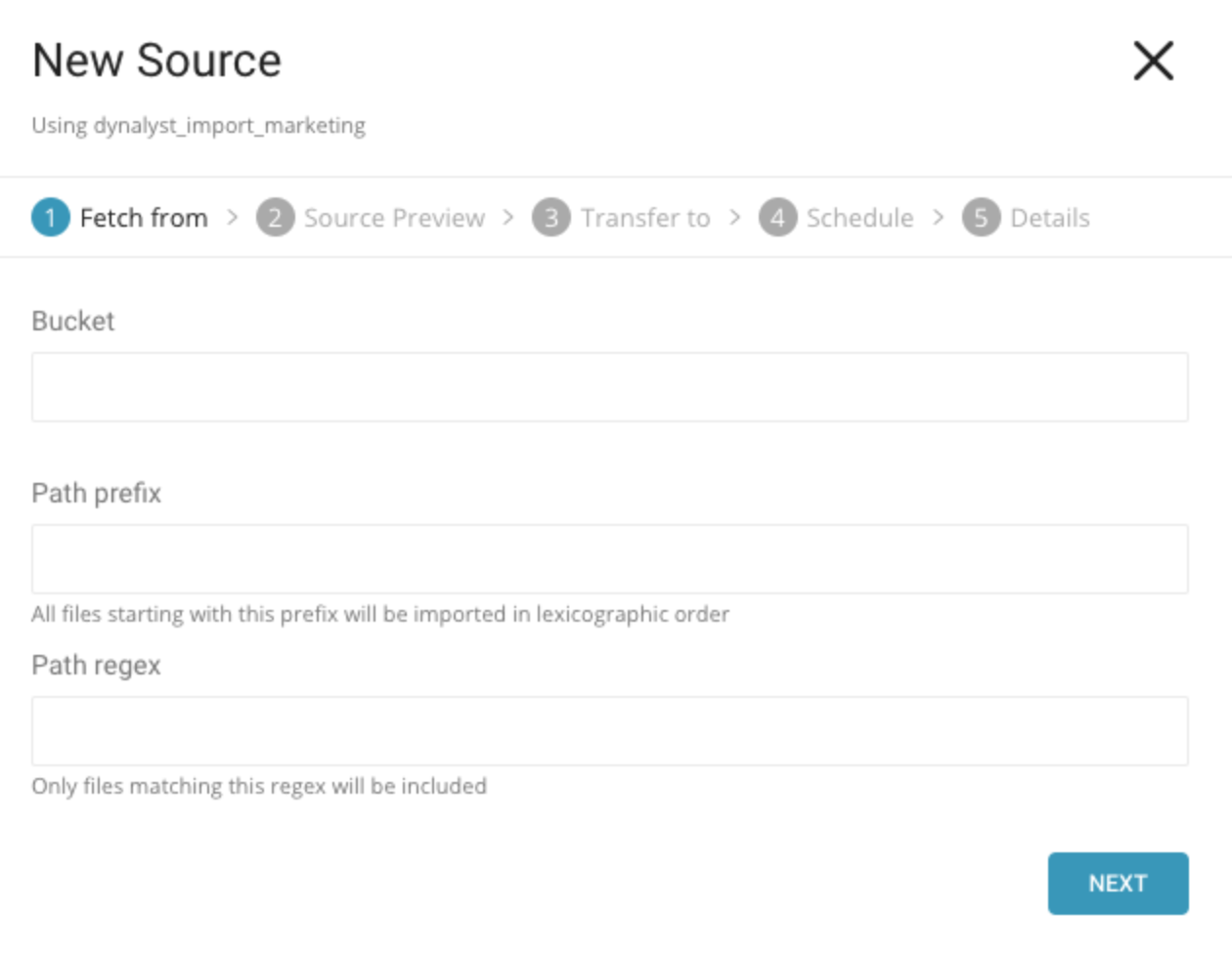
- New Sourceウィンドウで、インポートするファイルを含むバケットの名前を入力します。
Path prefix: 指定されたプレフィックスに一致するすべてのファイルをインポートするようにソースを設定します。(例:/path/to/customers.csv)
Path regex: 指定された正規表現パターンを使用して一致するすべてのファイルをインポートするようにソースを設定します。
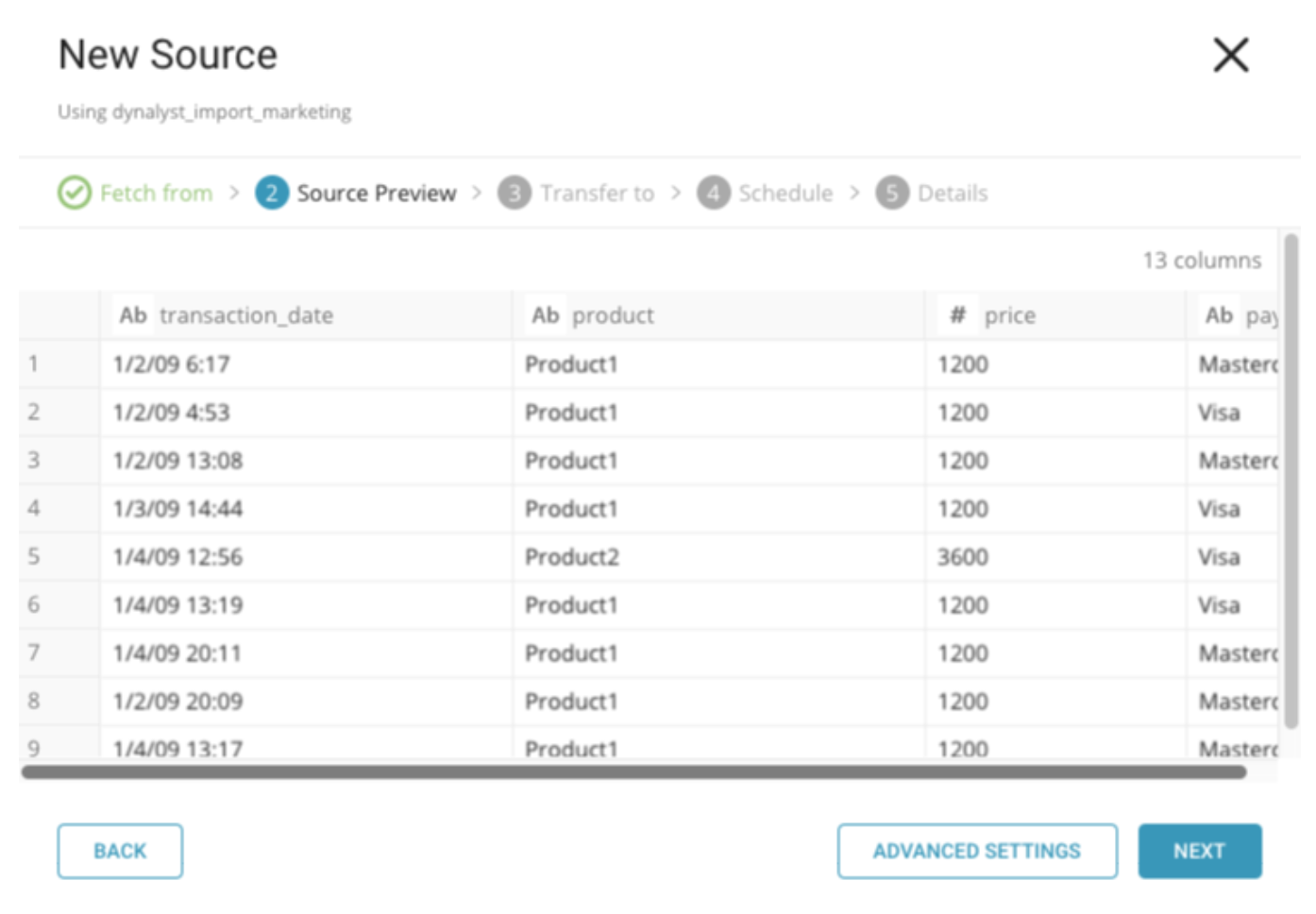
- ソースプレビューウィンドウで、advanced settingsを選択して、インポートに必要な調整を行います。たとえば、インポートパーサーをCSVからJSONに変更したり、行区切り文字を設定したりします*。*
- Nextを選択します。
データの配置について、データを配置したいターゲット database と table を選択し、インポートを実行する頻度を指定します。
Next を選択します。Storage の下で、インポートされたデータを配置する新しい database を作成するか、既存の database を選択し、新しい table を作成するか、既存の table を選択します。
Database を選択 > Select an existing または Create New Database を選択します。
オプションで、database 名を入力します。
Table を選択 > Select an existing または Create New Table を選択します。
オプションで、table 名を入力します。
データをインポートする方法を選択します。
- Append (デフォルト) - データインポートの結果は table に追加されます。 table が存在しない場合は作成されます。
- Always Replace - 既存の table の全体の内容をクエリの結果出力で置き換えます。table が存在しない場合は、新しい table が作成されます。
- Replace on New Data - 新しいデータがある場合のみ、既存の table の全体の内容をクエリの結果出力で置き換えます。
Timestamp-based Partition Key 列を選択します。 デフォルトキーとは異なるパーティションキーシードを設定したい場合は、long または timestamp 列をパーティショニング時刻として指定できます。デフォルトの時刻列として、add_time フィルターで upload_time を使用します。
データストレージの Timezone を選択します。
Schedule の下で、このクエリを実行するタイミングと頻度を選択できます。
- Off を選択します。
- Scheduling Timezone を選択します。
- Create & Run Now を選択します。
- On を選択します。
- Schedule を選択します。UI では、@hourly、@daily、@monthly、またはカスタム cron の 4 つのオプションが提供されます。
- Delay Transfer を選択して、実行時間の遅延を追加することもできます。
- Scheduling Timezone を選択します。
- Create & Run Now を選択します。
転送が実行された後、Data Workbench > Databases で転送の結果を確認できます。
- ソースの名前を入力します。
- Doneを選択します。ソースジョブは、指定したスケジュールに従って実行されます。