Google Search Analyticsのデータを Treasure Data にインポートできます。ページ、クエリ、国、デバイスなどのディメンションでデータをフィルタリングおよびグループ化できます。定期的にデータをインポートするスケジュールを指定できます。
- Treasure Data の基本知識
- Google Search Analytics の基本知識
- Google Search Console アカウント
データ接続を設定する際、統合にアクセスするための認証を提供します。Treasure Data では、認証を設定してからソース情報を指定します。
Integrations Hub > Catalog に移動し、Google Search Analytics を検索して選択します。

次のダイアログが開きます
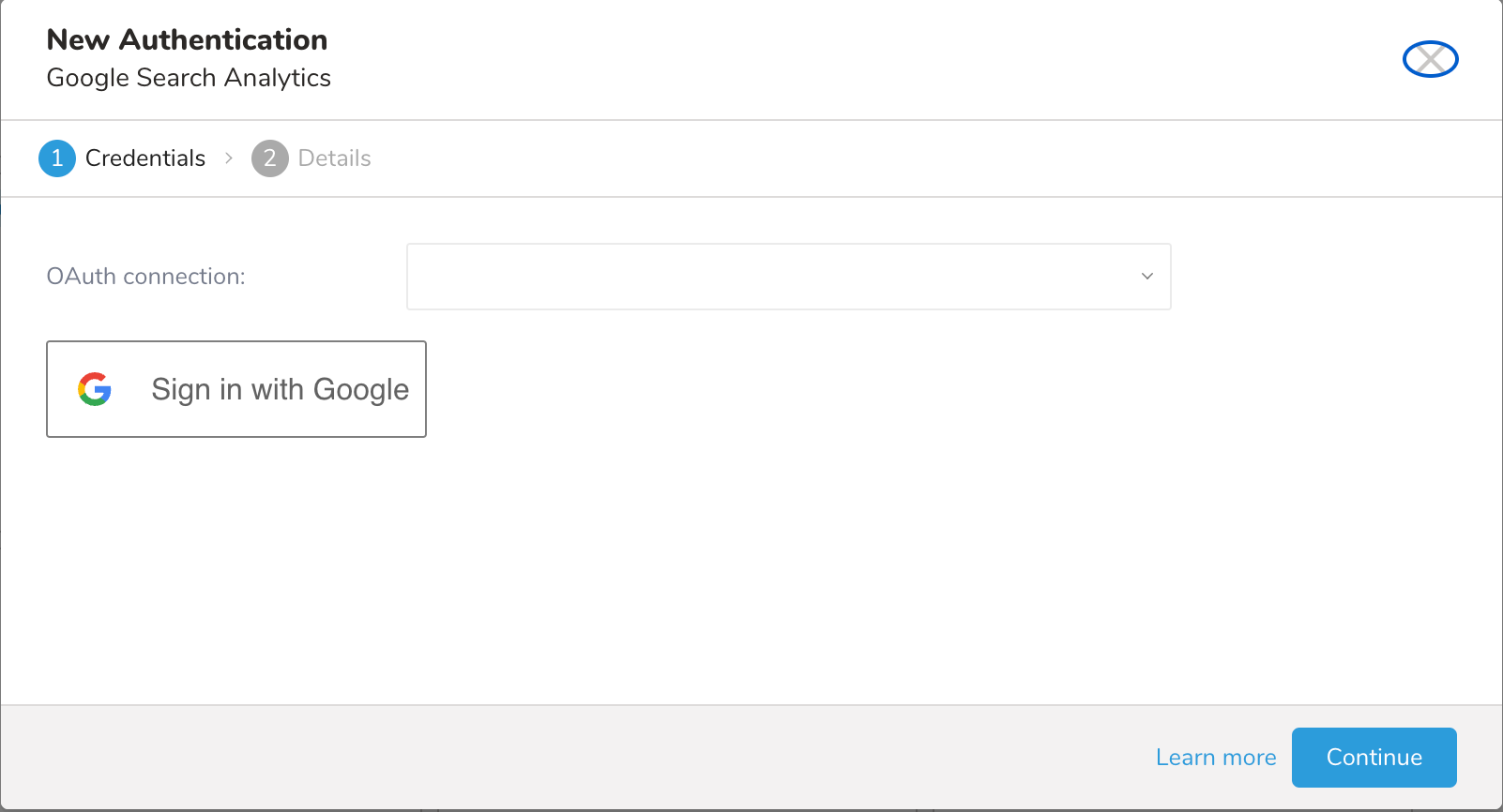
Treasure Data Google Search Analytics へのアクセスには OAuth2 認証が必要です。この認証では、ユーザーが手動で Treasure Data アカウントを各自の Google Search Analytics アカウントに接続する必要があります。
認証を行うには、次の手順を実行します。
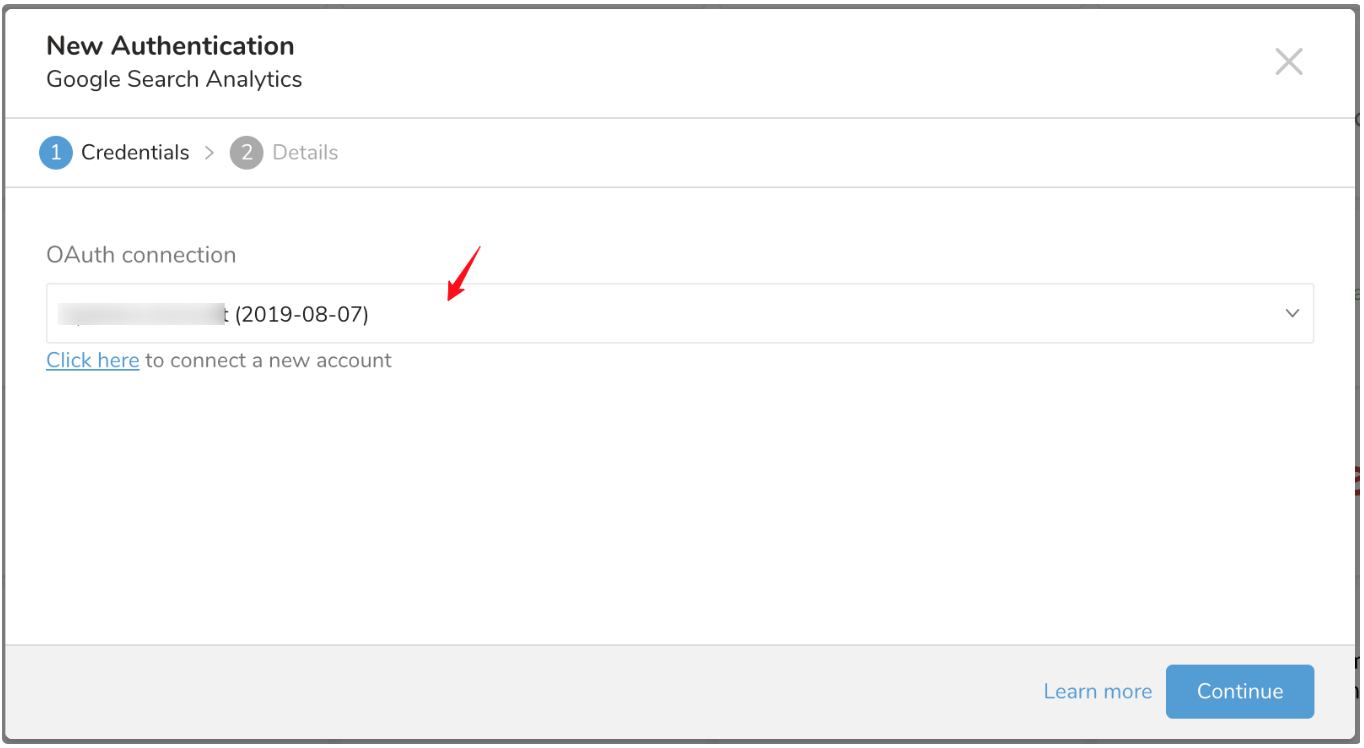
Click here を選択して新しいアカウントに接続します。
ポップアップウィンドウで Google アカウントにログインし、Treasure Data Connector アプリへのアクセスを許可します。
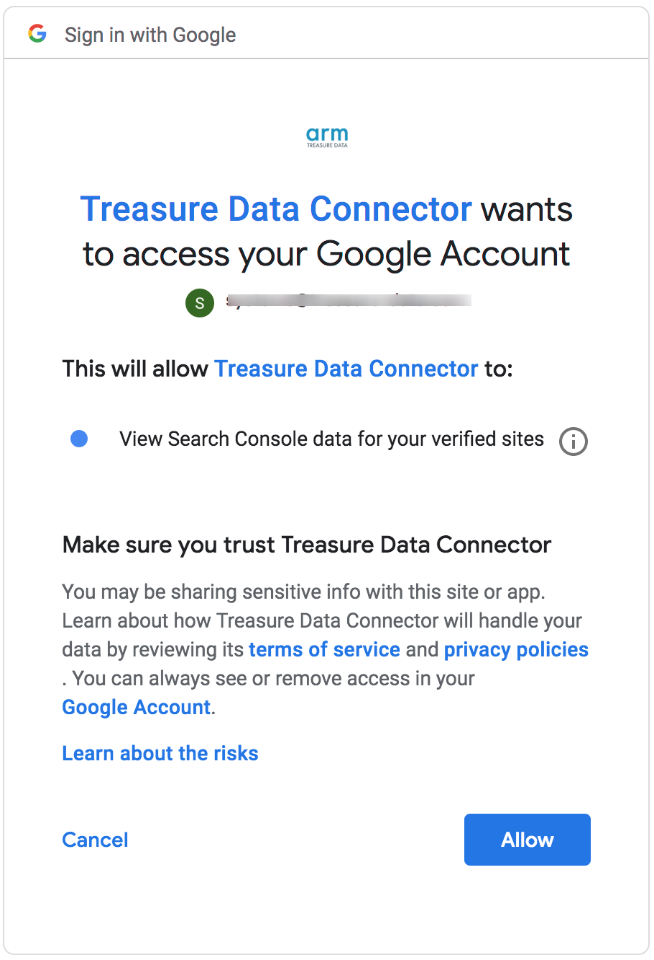
TD Console にリダイレクトされます。最初のステップ(新しい接続の作成)を繰り返し、新しい OAuth 接続を選択します。
新しい OneDrive 接続に名前を付けます。Done を選択します。
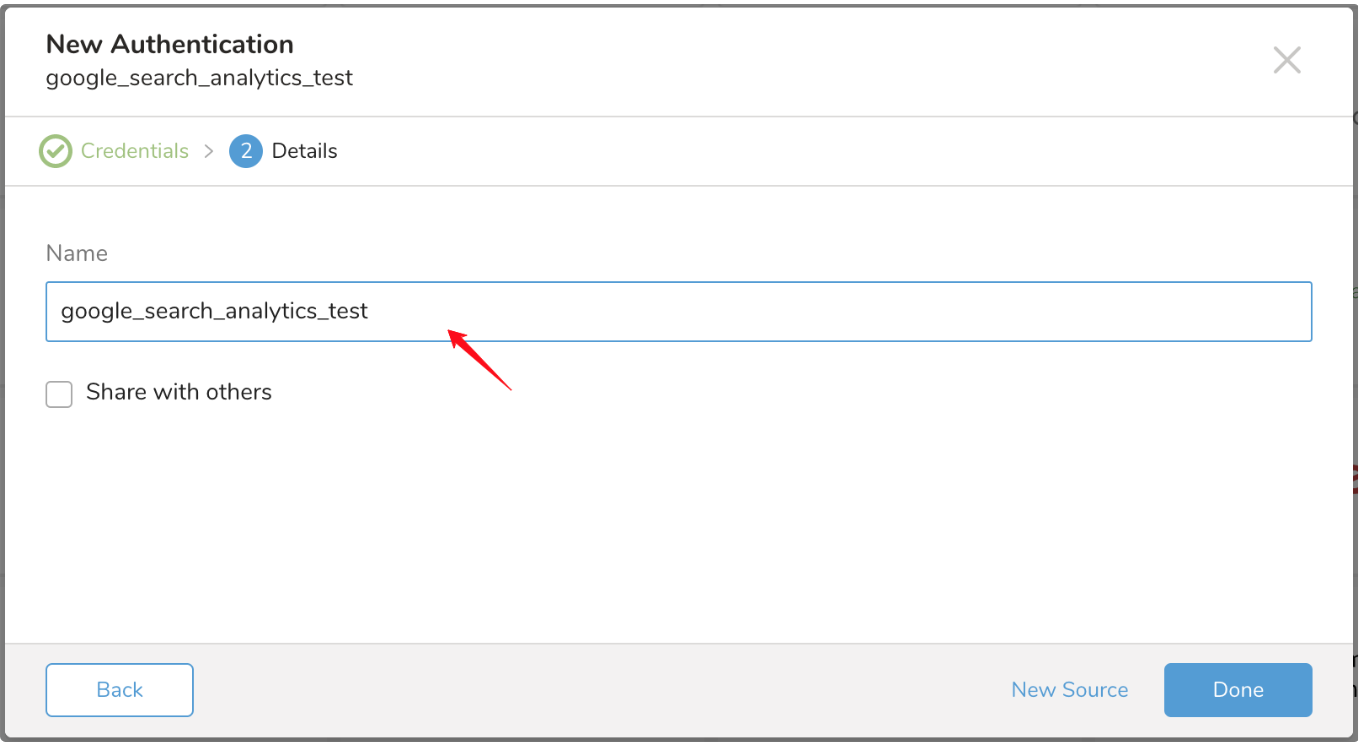
Authentications で、New Source を設定します。

詳細を入力し、Next を選択します。
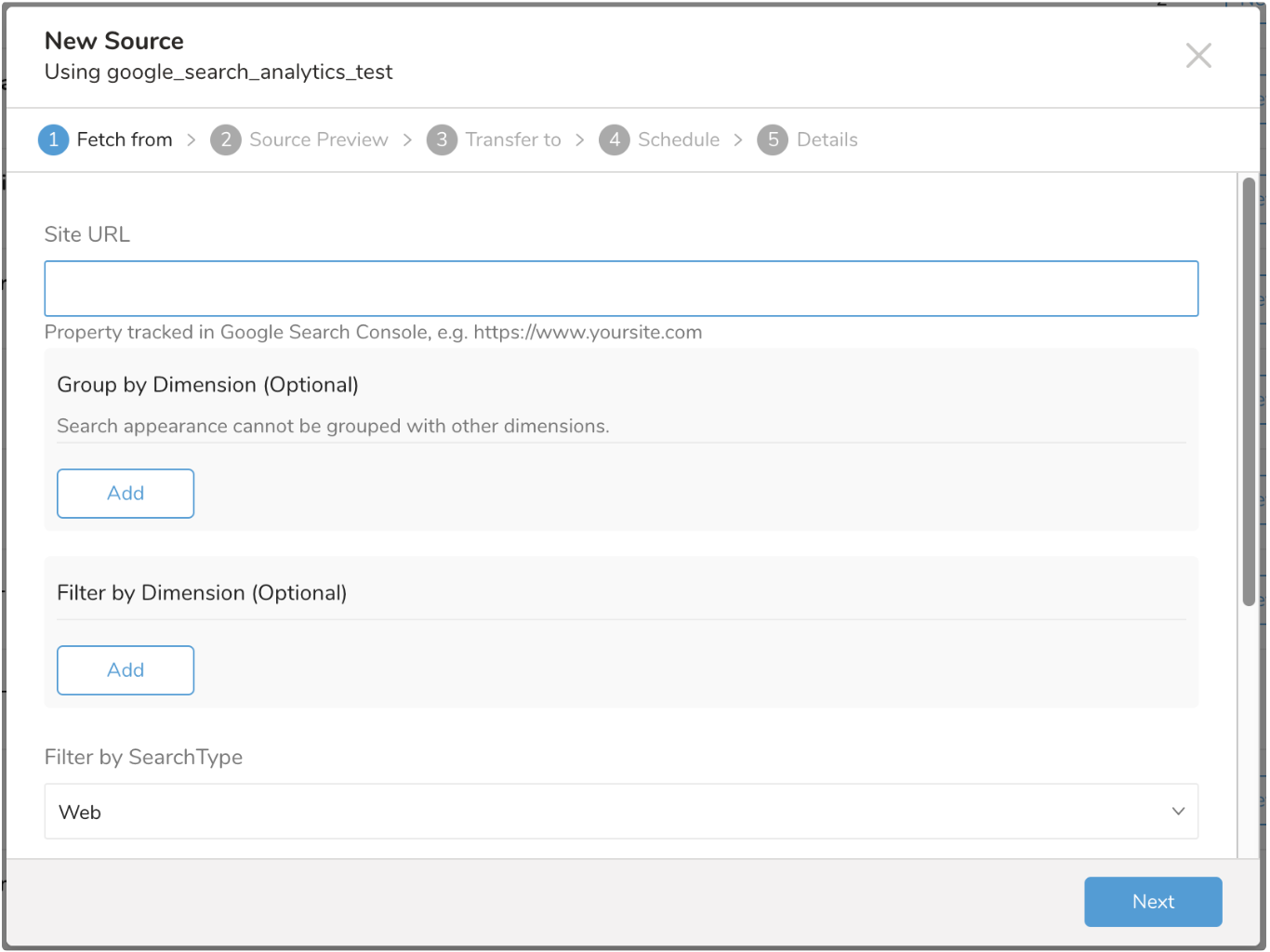
Site URL
Google Search Console で追跡されるプロパティ。Google はプロトコル(http:// または https://)、ドメイン、サブドメイン(例: example.com、m.example.com、www.example.com)を異なるものとして認識するため、データを取得したいドメイン、サブドメイン、またはパスブランチの正確な URL を入力する必要があります。
ドメインプロパティを使用する場合は、ドメインを指定する際に次の形式を使用します: sc-domain:example.com。
Group by Dimension
インポートするデータを 1 つ以上のディメンションでグループ化できます。サポートされているディメンションは、Page、Country、Device、Query、Search Appearance です。
Search Appearance を他の Dimensions とグループ化することはできません。有効なディメンショングループの例: Page、Country、Device。
選択したディメンションの数は、出力スキーマに影響します。例えば、ディメンション Country、Device、Query が選択された場合、インポートには Country、Device、Query のカラムが含まれます。
+----------------+---------------------+---------------+--------------+--------------------+------------+-----------------+----------------------------------+
| country:string | query:string | device:string | click:double | impressions:double | ctr:double | position:double | response_aggregation_type:string |
+----------------+---------------------+---------------+--------------+--------------------+------------+-----------------+----------------------------------+
| usa | a sample data | DESKTOP | 3.0 | 8.0 | 0.375 | 1.25 | byProperty |
| usa | a sample data | MOBILE | 3.0 | 5.0 | 0.6 | 1.0 | byProperty |
| twn | a sample data japan | TABLET | 2.0 | 2.0 | 1.0 | 1.0 | byProperty |
+----------------+---------------------+---------------+--------------+--------------------+------------+-----------------+----------------------------------+Filter by Dimension
複数のカテゴリでデータをフィルタリングできます。例えば、現在クエリでデータをグループ化している場合、「query contains 'treasure data'」というフィルタを追加できます。
Google Search Analytics は現在「AND」演算子のみをサポートしています。そのため、「Country equals'USA'」AND「Device equals'Mobile'」AND「Query contains 'sample data'」のようなフィルタはデータを返しますが、「Country equals'USA'」AND「Country equals 'JPN'」AND「query contains 'sample data'」はデータを返しません。
Search Type
検索タイプで分析データをフィルタリングします。サポートされている値: Web、Image、Video。デフォルトでは Web が選択されます。選択された値は、search_type カラムの下の出力スキーマに含まれます。
Start Date and End Date
要求された日付範囲、Start Date と End Date は必須です。YYYY-MM-DD 形式で指定します。End Date は Start Date 以上である必要があります。値は包括的です: Start Date の開始時刻(Start Date の 00:00:00)から End Date の終了時刻(End Date の 23:59:59)までです。特定の日にインポートする場合は、Start Date を End Date と等しく設定します。例: Start Date = 2018-06-11、End Date = 2018-06-11。
データは Start Date と End Date によって集約されます。日付範囲を 1 日より長く設定すると、クリック、ctr、インプレッション、ポジションの値は、指定された日付範囲内の個別の日の合計になります。
結果のデータは PST 時間(UTC-8:00)です。
データには 2~3 日の遅延がある可能性があり、Google Search Console でデータが利用可能になるまで待機します。ベストプラクティスとして、データが利用可能な日付よりも大きい End Date を設定しないでください。
Incremental Loading
Incremental Loading を有効にすることで、ジョブを反復的に実行するようにスケジュールできます。ジョブ実行の次の反復は、Start Date と End Date の値から計算されます。
次は single day と multiple days の時間範囲の次の反復の例です:
Single-day range
| Jobs | Start Date | End Date |
|---|---|---|
| First run | 2018-01-01 | 2018-01-01 |
| Second run | 2018-01-02 | 2018-01-02 |
| Third run | 2018-01-03 | 2018-01-03 |
1 Week range
| Jobs | Start Date | End Date |
|---|---|---|
| First run | 2018-01-01 | 2018-01-07 |
| Second run | 2018-01-08 | 2018-01-15 |
| Third run | 2018-01-16 | 2018-01-23 |
次のダイアログのようなデータのプレビューが表示されます。Preview の詳細をご覧ください。
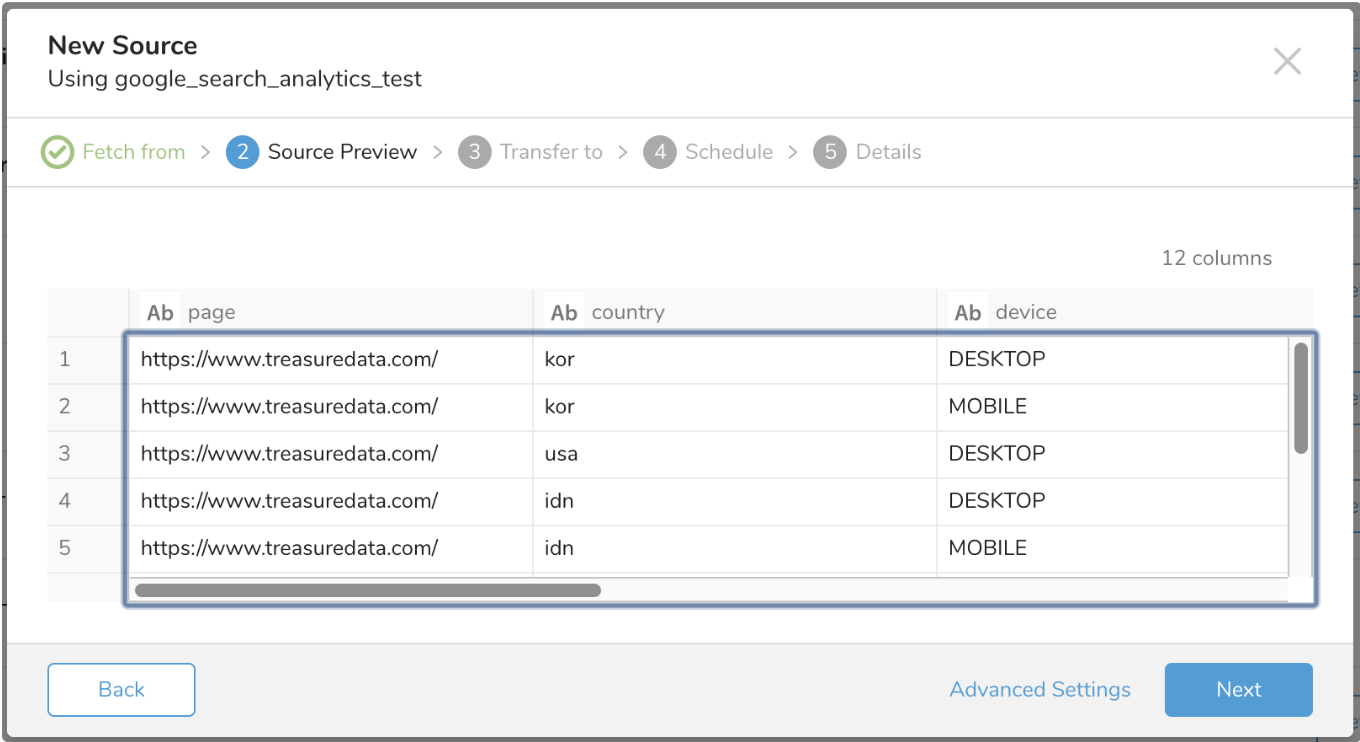
Advanced Settings を選択して、データコネクタの動作をカスタマイズします。
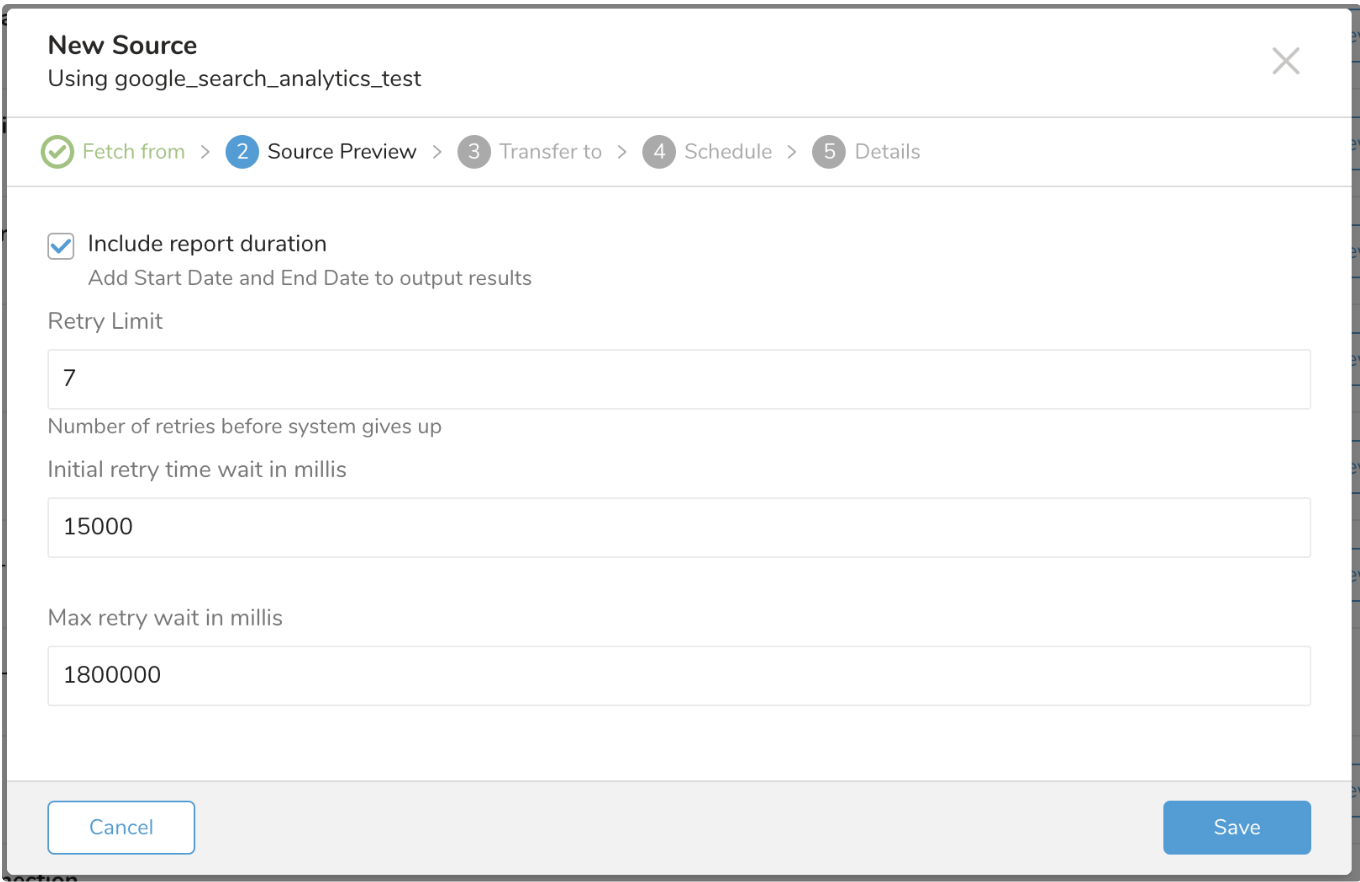
Include Report Duration
Include Report Duration オプションは出力スキーマに影響します。チェックボックスが選択されている場合(デフォルト)、インポートジョブの結果には 2 つの追加カラム(Start Date と End Date、タイプは string)が含まれます。次の例のように表示されます:
+--------------------------+--------------+--------------------+--------------------+--------------------+------------------+-----------------+
| query:string | click:double | impressions:double | ctr:double | position:double |start_date:string | end_date:string |
+--------------------------+--------------+--------------------+--------------------+--------------------+------------------+-----------------+
| a sample data | 11.0 | 35.0 | 0.3142857142857143 | 1.342857142857143 | 2018-05-05 | 2018-05-05 |
| a sampledata | 3.0 | 8.0 | 0.375 | 1.625 | 2018-05-05 | 2018-05-05 |
| a sample data japan | 2.0 | 2.0 | 1.0 | 1.0 | 2018-05-05 | 2018-05-05 |
| cdp vs dmp | 1.0 | 3.0 | 0.3333333333333333 | 1.6666666666666665 | 2018-05-05 | 2018-05-05 |
| cmp vs dmp | 1.0 | 1.0 | 1.0 | 7.0 | 2018-05-05 | 2018-05-05 |
| a sample treasure | 1.0 | 1.0 | 1.0 | 1.0 | 2018-05-05 | 2018-05-05 |
| hive guide | 1.0 | 2.0 | 0.5 | 4.5 | 2018-05-05 | 2018-05-05 |
| postgresql elasticcloud | 1.0 | 4.0 | 0.25 | 8.5 | 2018-05-05 | 2018-05-05 |
| s3 elasticcloud | 1.0 | 1.0 | 1.0 | 11.0 | 2018-05-05 | 2018-05-05 |
| a sample data | 1.0 | 1.0 | 1.0 | 1.0 | 2018-05-05 | 2018-05-05 |
+--------------------------+--------------+--------------------+--------------------+--------------------+------------------+-----------------+Retry Limit
Treasure Data へのデータインポート中には、ネットワークの変動や Google サーバーの同時実行制限など、プロセスに影響を与える多くの要因があります。コネクタは、指定した回数だけインポートを再試行します。
Initial retry time wait in millis
コネクタは、インポートを再試行する前に、指定したミリ秒数だけ最初に待機します。次の再試行は 2 * initial retry time、というように続きます。
Max retry wait in millis
待機時間が指定した制限に達すると、コネクタは再試行を中止します。
既存のデータベースとテーブルを選択するか、新しいデータベースとテーブルを作成します。
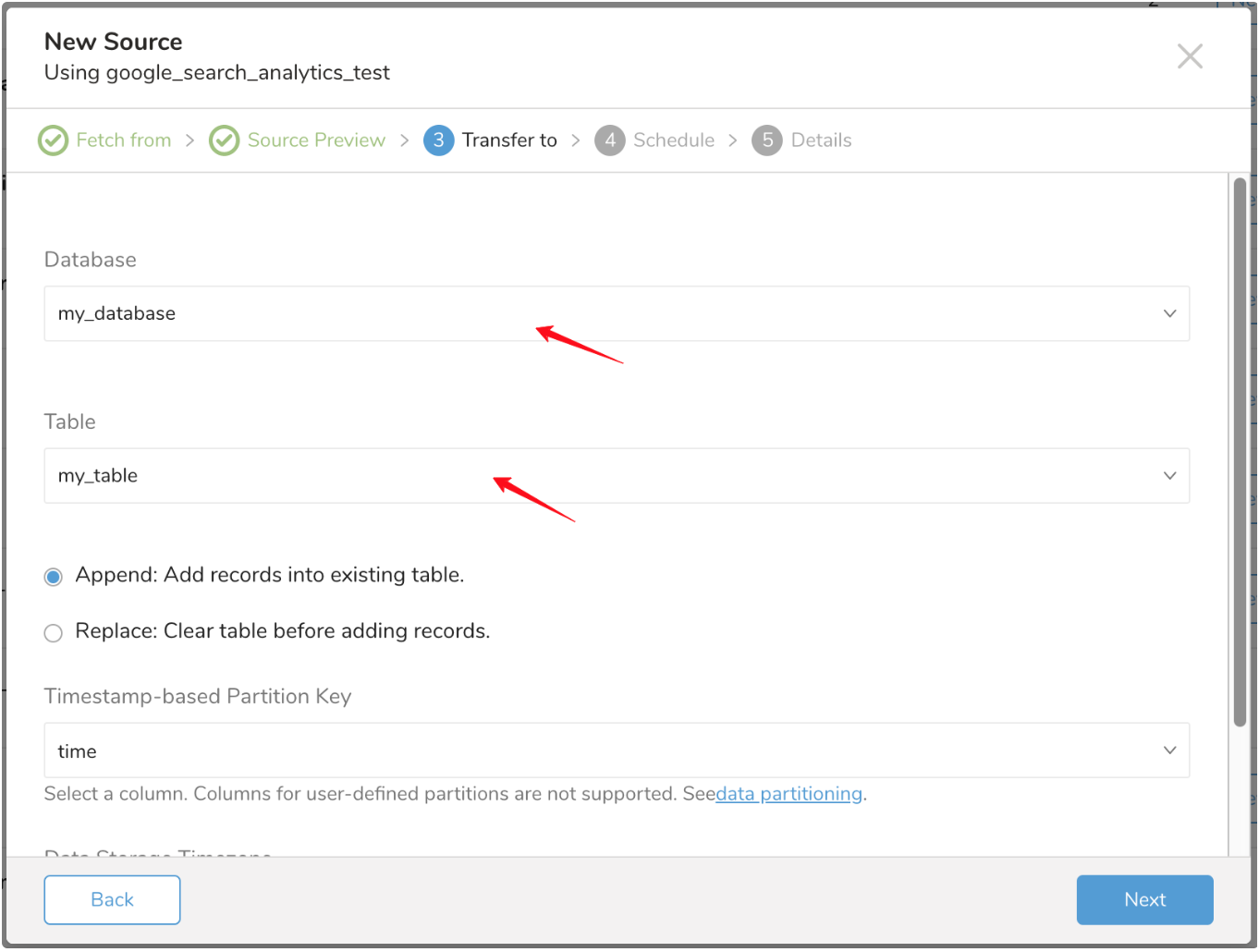
新しいデータベースを作成し、データベースに名前を付けます。Create new table についても同様の手順を実行します。
既存のテーブルにレコードを append するか、既存のテーブルを replace するかを選択します。
デフォルトのキーではなく別の partition key seed を設定する場合は、ポップアップメニューを使用して指定できます。
Schedule タブでは、1 回限りの転送を指定するか、自動化された繰り返し転送をスケジュールできます。Once now を選択した場合は、Start Transfer を選択します。Repeat… を選択した場合は、スケジュールオプションを指定してから、Schedule Transfer を選択します。
New Source 名を入力し、Done を選択します。
Treasure Data Toolbelt をインストールします。
'td' コマンドのコネクタ設定には以下が必要です:
* client_id
* client_secret
* refresh_tokenこれらのパラメータは次の手順で取得できます:
すでに OAuth 2 を設定し、Google Search Console APIs アクセスを有効にし、client ID と client secret を持っている場合は、このステップをスキップできます。
client ID と client secret を取得するには、開発者向け Google Search Console APIs の手順に従ってください: https://developers.google.com/webmaster-tools/search-console-api-original/v3/how-tos/authorizing
また、Google Search Console API Wizard を使用することもできます。これにより、プロジェクトをすばやく作成し、Google Search Console API をオンにすることができます。Credentials > Create Credentials > OAuth ClientID > Web Application に移動します。名前を入力して Create を選択します。次の画面に client ID と client secret が表示されます。
取得する必要がある残りの認証情報は refresh token です。refresh token を取得する 1 つの方法は、Google OAuth 2.0 Playground を使用することです。こちらで利用できます: Google OAuth 2.0 Playground
まず、OAuth 2.0 Playground 内で、右上隅の歯車アイコンを選択し、Use your own OAuth credentials チェックボックスを選択してください。OAuth Client ID と OAuth Client secret に、API コンソールから取得した認証情報を挿入します。
ステップ 1 で、Search Console API v3 を選択します。次に "https://www.googleapis.com/auth/webmasters.readonly" を選択し、"Authorize APIs" を選択して、指示に従って Search Console API から Google Search Console アカウントへのアクセスを許可します。
ステップ 2 で、Exchange authorization code for tokens を選択すると、Refresh Token と Access Token フィールドが入力されます。refresh token フィールドの値が、次のステップでコネクタ設定を準備するために使用されます。
次のように config.yml を準備します:
in:
type: "google_search_analytics"
client_id: "[Your Client ID]"
client_secret: "[Your Client Secret]"
refresh_token: "[Your Refresh Token]"
site_url: "[Your tracked site]"
dimensions: ["query"]
filters:
- {
"dimension": "query",
"operator": "equals",
"expression": "a sample"
}
search_type: web
start_date: "2018-06-01"
end_date: "2018-06-01"
include_report_period: false
out:
mode: append
filters:
- {
type: "add_time",
to_column: {"name": "time"},
from_value: {"mode": "upload_time"}
}利用可能な out モードの詳細については、Appendix A を参照してください
filters の詳細については、Appendix B を参照してください
その後、preview コマンドを使用してデータのプレビューを表示できます。
$ td connector:preview config.ymlGoogle Search Analytics コネクタでは td connector:guess を実行する必要はありません。
ロードジョブを送信します。データのサイズによっては、処理に数時間かかる場合があります。
$ td connector:issue config.yml --database td_sample_db --table td_sample_tableSearch Analytics データの増分インポートのために、定期的なデータコネクタ実行をスケジュールできます。
スケジュールされたインポートの場合、最初の実行時に、Search Analytics 用 Data Connector は "start_date" と "end_date" で指定されたすべてのデータをインポートします。
2 回目以降の実行では、コネクタは前回のロードよりも新しいデータのみをインポートします。
td connector:create コマンドを使用してスケジュールを作成できます。次の項目が必要です: スケジュールの名前、cron 形式のスケジュール、データが保存されるデータベースとテーブル、データコネクタ設定ファイル。
$ td connector:create \
daily_import \
"10 0 * * *" \
td_sample_db \
td_sample_table \
config.ymlcron パラメータは、3 つの特別なオプション @hourly、@daily、@monthly も受け付けます。| デフォルトでは、スケジュールは UTC タイムゾーンで設定されます。-t または --timezone オプションを使用して、タイムゾーンでスケジュールを設定できます。--timezone オプションは、'Asia/Tokyo'、'America/Los_Angeles' などの拡張タイムゾーン形式のみをサポートしています。PST、CST などのタイムゾーンの略語は*サポートされておらず*、予期しないスケジュールになる可能性があります。
td connector:list コマンドで、現在のすべてのスケジュールエントリのリストを確認できます。
$ td connector:listtd connector:show は、スケジュールエントリの実行設定を表示します。
$ td connector:show daily_importtd connector:history は、スケジュールエントリの実行履歴を表示します。個々の実行の結果を調査するには、td job jobid を使用します。
$ td connector:history daily_importtd connector:delete は、スケジュールを削除します。
$ td connector:delete daily_import次の表は、モードで利用可能なオプションの詳細を示しています。
| Option name | Description | Type | Required? | Default Value |
|---|---|---|---|---|
| client_id | アプリ client id | string | yes | |
| client_secret | アプリ client secret | string | yes | |
| refresh_token | アプリ refresh token | string | yes | |
| site_url | 追跡するサイト URL | string | yes | |
| dimensions | 結果をグループ化する search analytics dimension | enum | optional | |
| filters | ディメンションでフィルタリング | enum | optional | |
| search_type | 検索タイプでフィルタリング。web、image、video | string | optional | web |
| start_date | リクエスト日付範囲の開始日 | string | yes | |
| end_date | リクエスト日付範囲の終了日 | string | yes | |
| incremental | スケジュールインポート用の次の start_date と end_date を生成 | bool | optional | true |
| include_report_period | 出力結果に start_date と end_date を含めるかどうかを指定 | bool | optional | true |
| retry_limit | 再試行可能なエラーが発生したときに諦める回数 | integer | optional | 7 (times) |
| retry_initial_wait_millis | 再試行可能なエラーが発生したときの初期待機時間。次の値は前の値の 2 倍になります | integer | optional | 15000 (15 seconds) |
| max_retry_wait_millis | 各再試行の最大待機時間 | integer | optional | 1800000 (30 minutes) |
config.yml の out セクションで mode を指定することにより、新しいデータを Treasure data にインポートする方法を指定できます。
これはデフォルトのモードで、レコードはターゲットテーブルに追加されます。
in:
...
out:
mode: appendこのモードは、ターゲットテーブルのデータを置き換えます。ターゲットテーブルに対して行われた手動のスキーマ変更は、このモードでもそのまま維持されます。
in:
...
out:
mode: replaceData Connector 用の add_time フィルタプラグインを使用すると、スキーマ内の既存の別のカラムから値をコピーするか、値を指定することにより、スキーマに新しい時間ベースのカラムを追加できます。詳細については、add_time Filter Plugin for Integrations のドキュメントを参照してください。
- Page
- Country
- Device
- Query
- Search Appearance
- Contains
- Equals
- NotContains
- NotEquals
バージョン v0.1.4 から、Search Type フィルタをサポートしているため、新しいカラム名 search_type がジョブ結果に追加されます。ジョブ設定を変更しない場合、デフォルト値は "web" です。