Google DriveからTreasure Dataにデータファイルをインポートできます。このデータコネクタは、CSVおよびTSVファイル、またはCSVおよびTSVファイルのgzipのみをサポートしています。
- TD Toolbeltを含むTreasure Dataの基本知識
- Googleアカウント
Integrations Hub > Catalogに移動し、Google Driveを検索して選択します。

Createを選択します。認証された接続を作成しています。
次のダイアログが開きます。
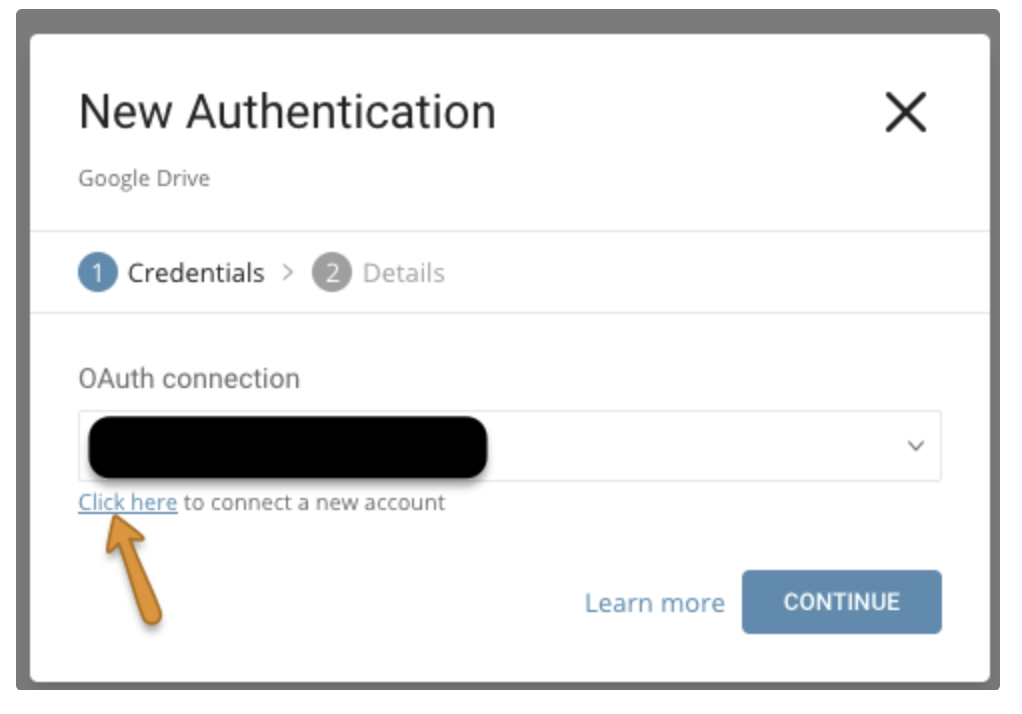
Google Driveへのアクセスには、OAuth2認証が必要です。
Click hereを選択して、Googleアカウントに接続します。
ポップアップウィンドウでGoogleアカウントにログインし、Treasure Dataアプリへのアクセスを許可します。
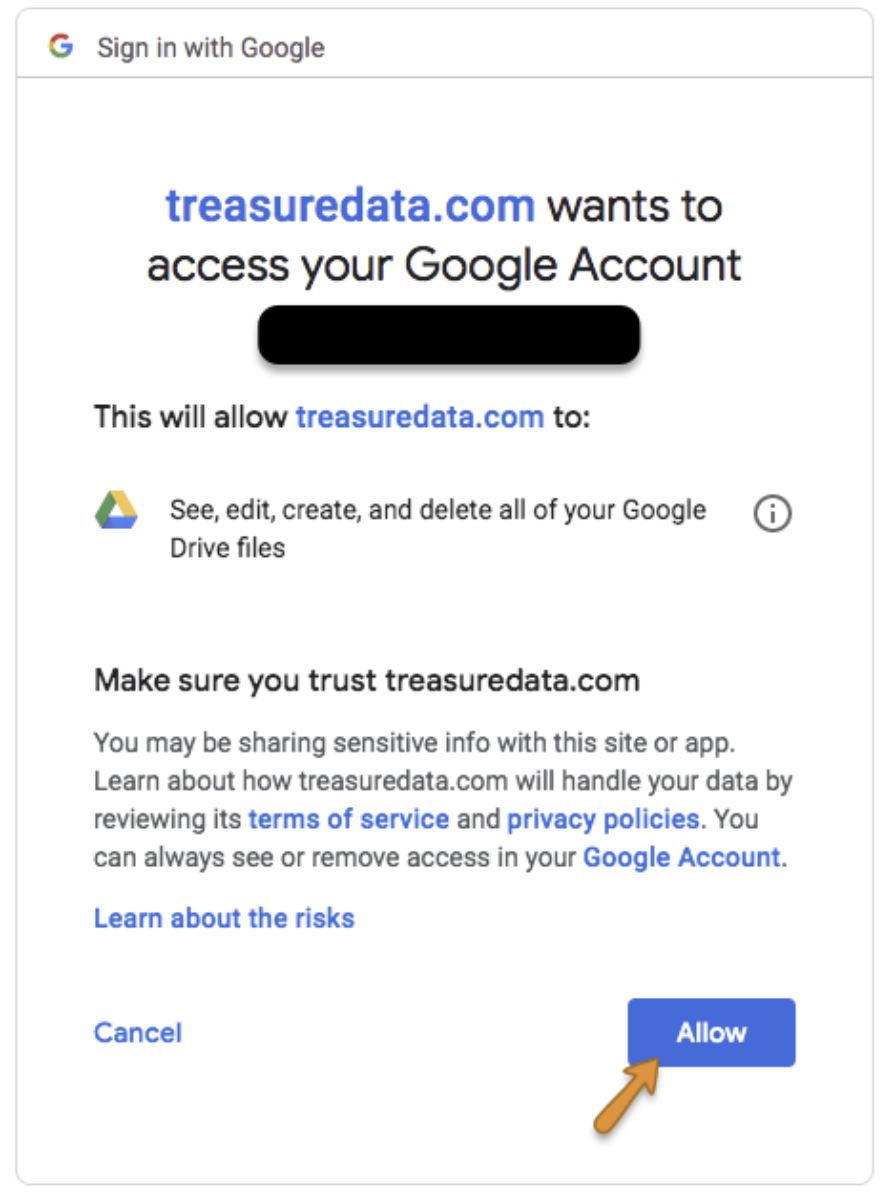
TD Consoleにリダイレクトされます。「新しい接続を作成する」手順を繰り返し、新しいOAuth接続を選択します。Continueを選択します。
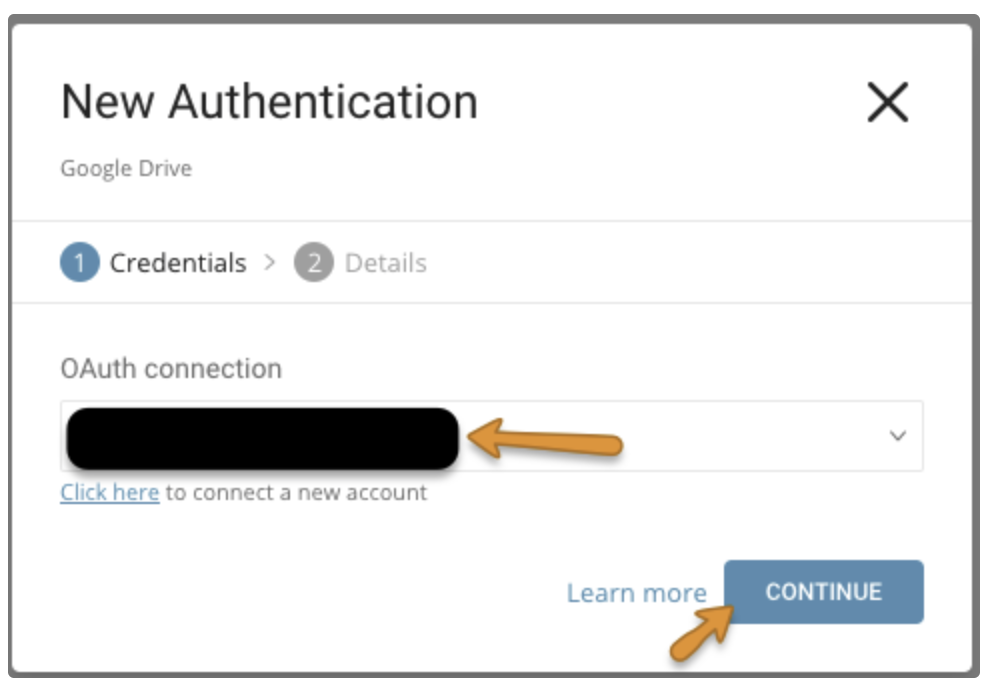
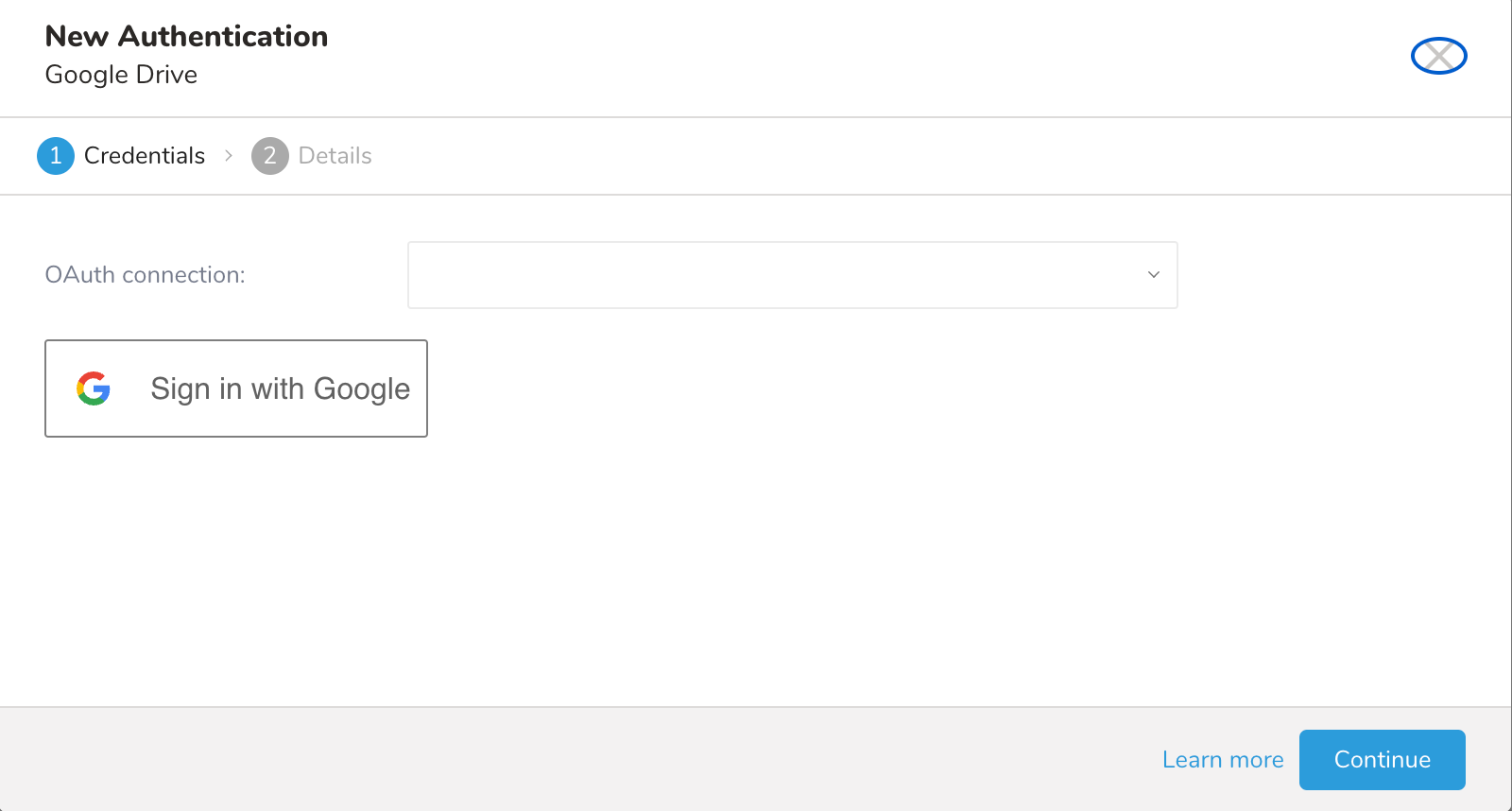
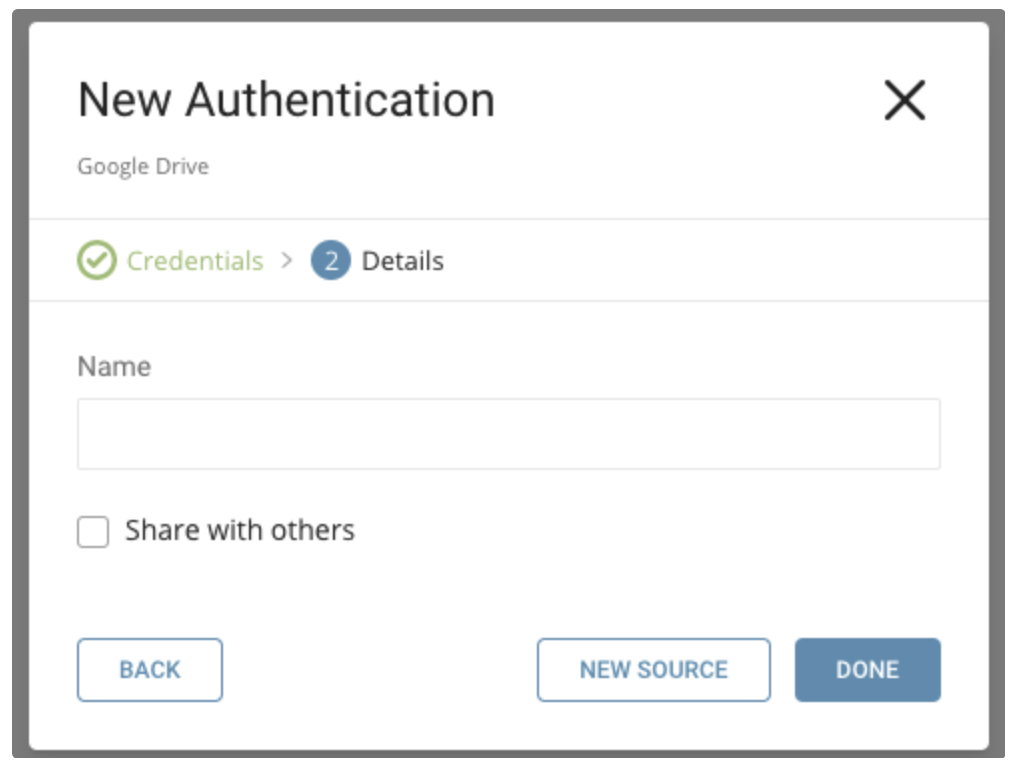
新しいGoogle Drive接続に名前を付けます。Doneを選択します。
認証された接続を作成すると、自動的にAuthenticationsタブに移動します。作成した接続を探して、New Sourceを選択します。
CSVまたはTSVファイルをインポートするか、CSVまたはTSVファイルのgzipをインポートできます。
File typesでは、Fileを選択します。
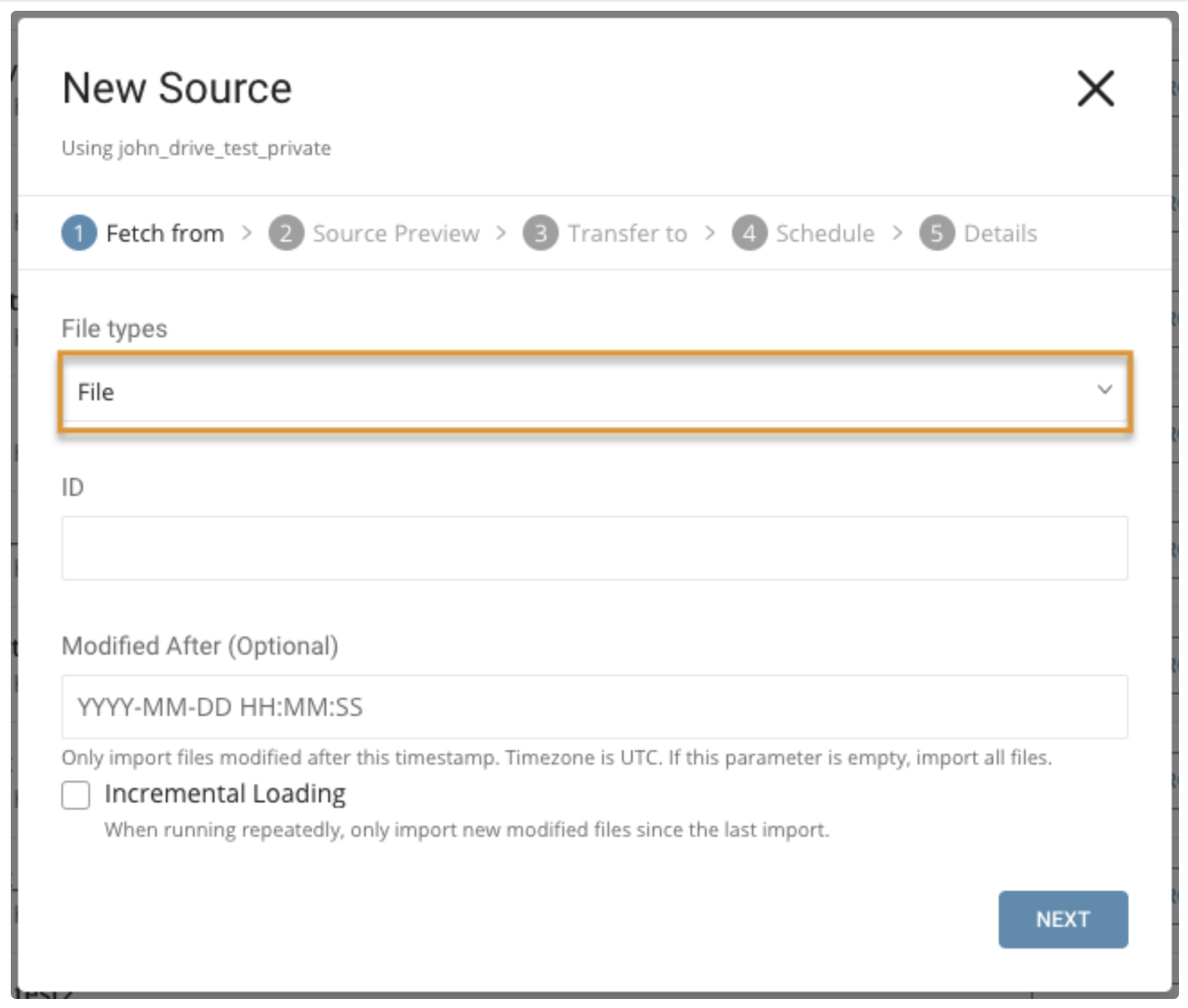
パラメータ:
- ID: Google DriveのファイルID。CSVおよびTSVファイル、またはCSVおよびTSVファイルのgzipのみをサポートします。
- Modified After: 指定したタイムスタンプ以降に変更されたファイルのみをインポートする場合に使用します。
- Incremental Loading: スケジュールに基づいてデータをインポートする場合に使用します。前回のインポート以降の新しい変更されたファイルのみをインポートする場合に使用します。
CSVまたはTSVファイル、またはCSVまたはTSVファイルのgzipのリストをインポートします。フォルダからインポートする場合、フォルダには同じタイプのファイルが含まれている必要があります。例:CSVファイルのみを含むフォルダ。
File typesでは、Folderを選択します。
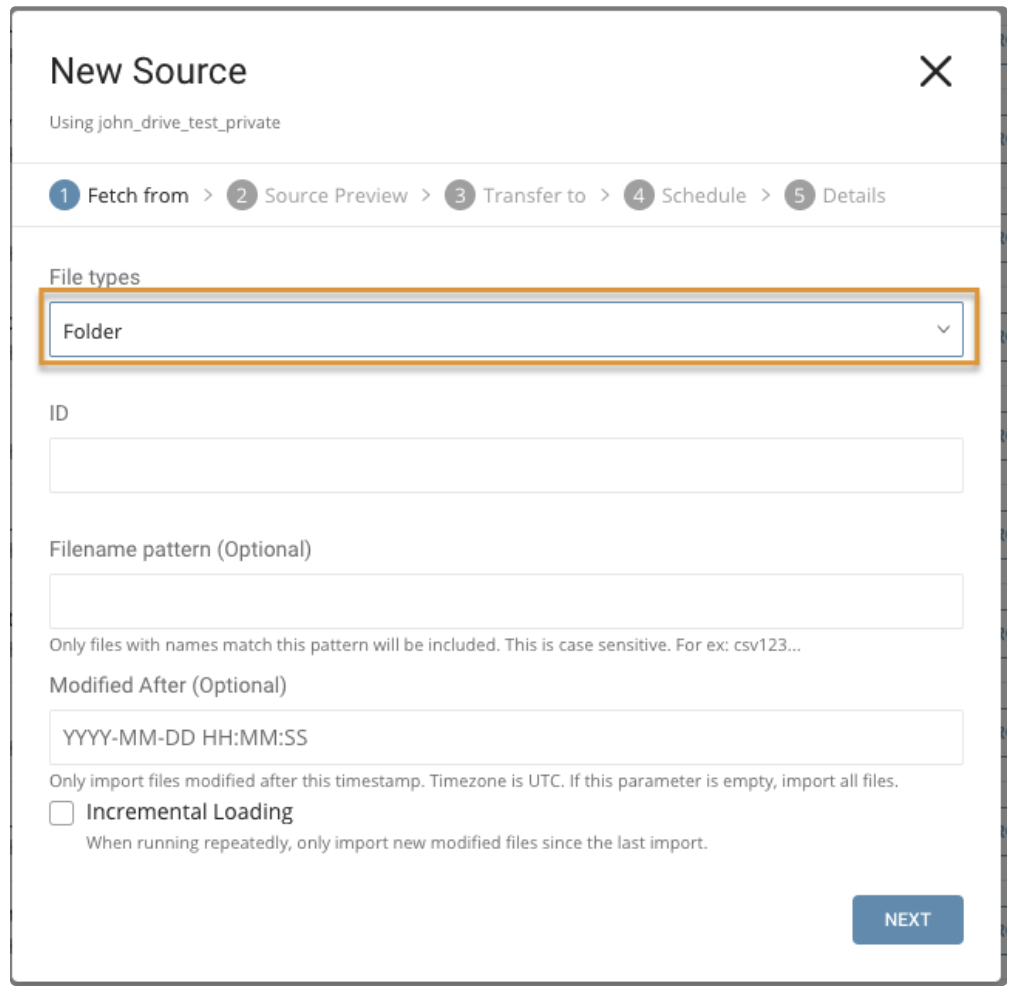
パラメータ:
- ID: Google DriveのファイルID。CSVおよびTSVファイル、またはCSVおよびTSVファイルのgzipのみをサポートします。
- Modified After: 指定したタイムスタンプ以降に変更されたファイルのみをインポートする場合に使用します。
- Filename pattern: 正規表現を使用してファイル名と一致させます。ファイル名がこのパターンと一致しない場合、ファイルはスキップされます。(例えば、ファイル名パターンが*.csv$*の場合、ファイル名がこのパターンと一致しない場合、そのファイルはスキップされます)
- Incremental Loading: スケジュールに基づいてデータをインポートする場合に使用します。前回のインポート以降のフォルダ内の新しい変更されたファイルのみをインポートする場合に使用します。
データのプレビューが表示されます。変更する場合はAdvanced Settingsを選択し、それ以外の場合はNextを選択します。
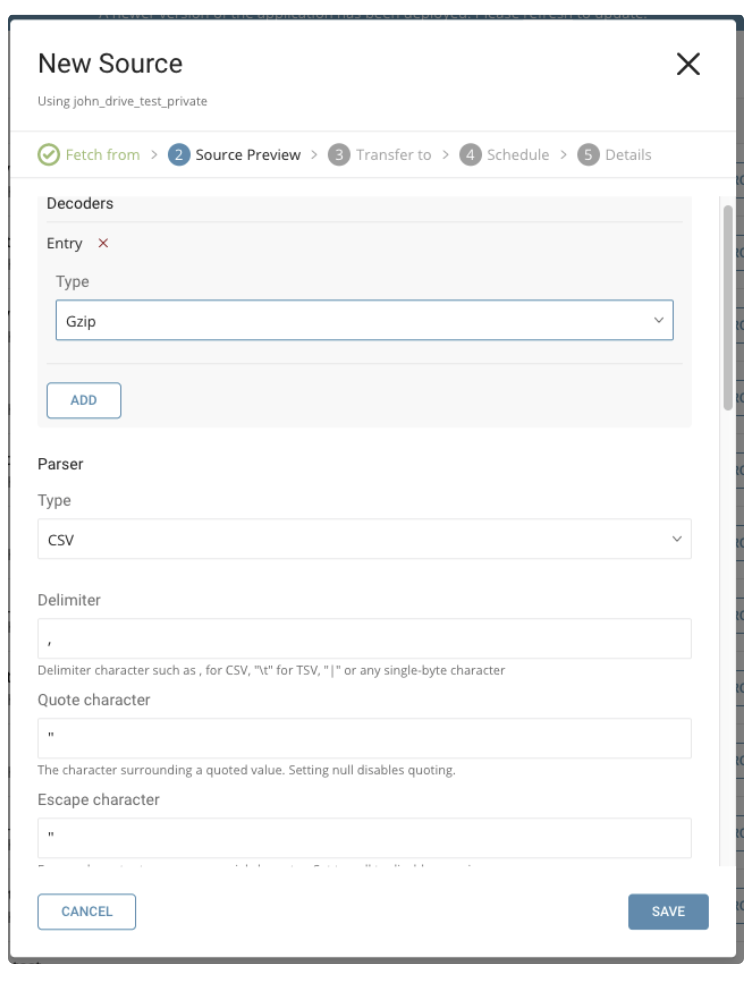
次のパラメータを指定できます:
Decoders: ファイルのエンコードに基づいてファイルデコーダーを変更できます。
Gzip Bzip2 Zip OpenPGP DecryptionParser: 必要に応じて、CSV/TSV Parserの設定を更新します。
charset: UTF-8 newline: LF type: csv delimiter: ',' quote: '"' escape: '"' trim_if_not_quoted: false skip_header_lines: 1 allow_extra_columns: false allow_optional_columns: false columns:Maximum retry interval milliseconds. 再試行間の最大時間を指定します。
Type: number Default: 120000Maximum retry times. 各API呼び出しの最大再試行回数を指定します。
Type: number Default: 7Initial retry interval millisecond. 最初の再試行の待機時間を指定します。
Type: number Default: 1000Maximum retry interval milliseconds. 再試行間の最大時間を指定します。
Type: number Default: 120000
既存のソースを選択するか、新しいデータベースとテーブルを作成します。
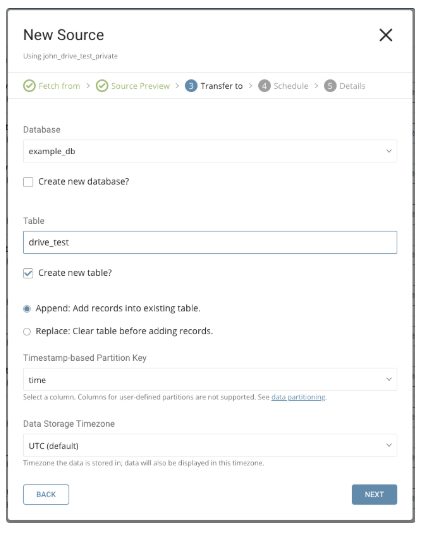
新しいデータベースを作成し、データベースに名前を付けます。Create new tableでも同様の手順を完了します。
既存のテーブルにレコードを追加するか、既存のテーブルを置換するかを選択します。
デフォルトのキーではなく、異なるpartition key seedを設定したい場合は、ポップアップメニューを使用して指定できます。
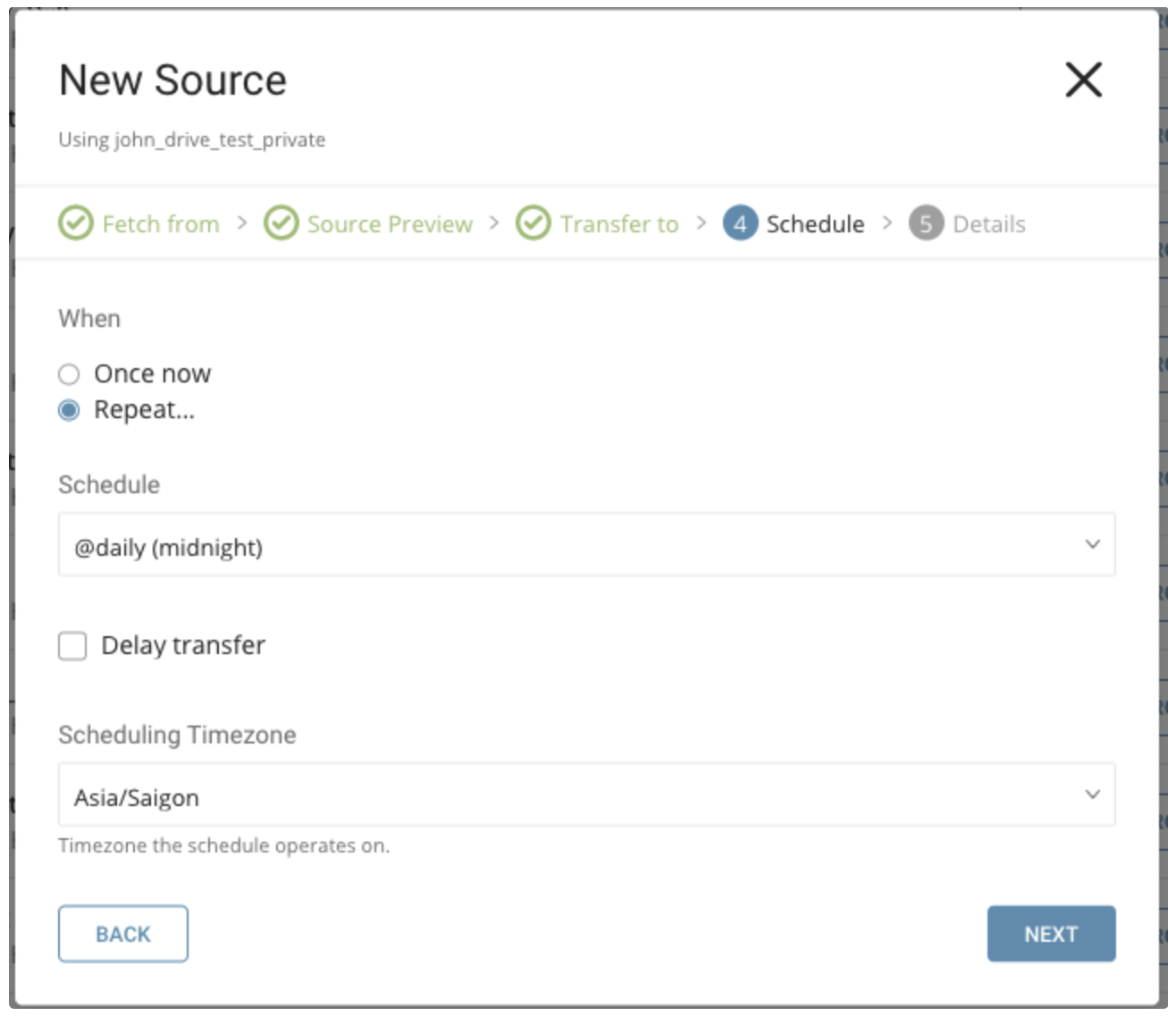
Whenタブでは、1回限りの転送、または自動的な定期転送をスケジュールできます。
パラメータ
Once now: 1回限りのジョブを設定します。
Repeat…
- Schedule: @hourly、@daily、@monthlyの3つのオプション、およびカスタムcronを受け付けます。
- Delay Transfer: 実行時間の遅延を追加します。
TimeZone: 'Asia/Tokyo'のような拡張タイムゾーン形式をサポートします。
Transferに名前を付け、Doneを選択して開始します。
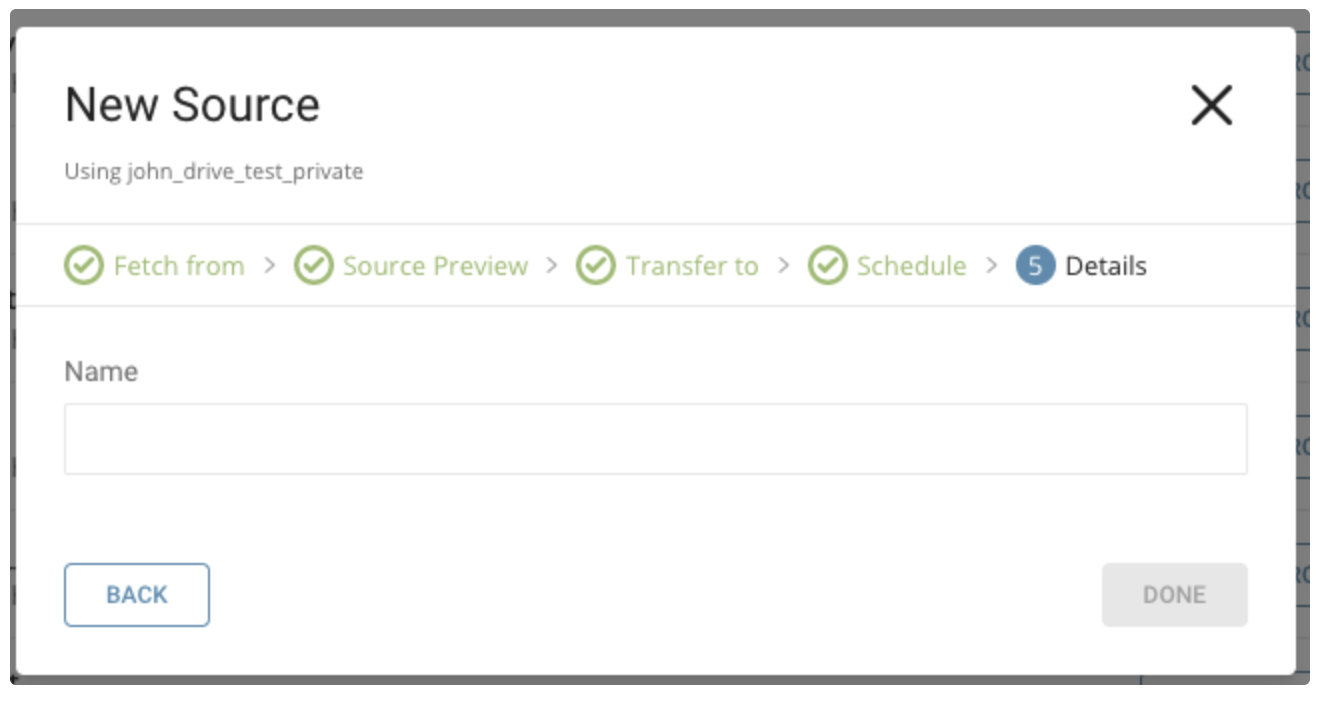
転送が実行されると、Databasesタブで転送の結果を確認できます。
TD Consoleを使用して接続を設定できます。
最新のTD Toolbeltをインストールします。
設定ファイルには、Google Driveからコネクタに取り込むものを指定するin:セクションと、コネクタがTreasure Data内のdatabaseに出力するものを指定するout:セクションが含まれます。利用可能なoutモードの詳細については、Appendixを参照してください。
次の例は、Google Driveからファイルをインポートする方法を示しています。
in:
type: google_drive
client_id: xxxxxxxxxxx
client_secret: xxxxxxxxxxx
refresh_token: xxxxxxxxxxx
target: file
id: xxxxxxxxxxx(drive file id)
last_modified_time: "YYYY-MM-DD HH:MM:SS"
incremental: false
out: mode: append次の例は、Google Driveのフォルダー内のファイルをインポートする方法を示しています。
in:
type: google_drive
client_id: xxxxxxxxxxx
client_secret: xxxxxxxxxxx
refresh_token: xxxxxxxxxxx
target: folder
id: xxxxxxxxxxx(drive folder id)
last_modified_time: "YYYY-MM-DD HH:MM:SS"
filename_pattern: xxxxxxxxxxx (Ex: abc.csv$)
incremental: false
out:
mode: appendtd connector:guess seed.yml -o load.ymltd connector: previewコマンドを使用して、インポートされるデータをプレビューできます。
td connector:preview load.ymltd connector:issueを使用してジョブを実行します。
ロードジョブを実行する前に、データを保存するdatabaseとtableを指定する必要があります。例:td_sample_db、td_sample_table
td connector:issue load.yml \
--database td_sample_db \
--table td_sample_table \
--time-column date_time_columnTreasure Dataのストレージは時間でパーティション分割されているため、--time-columnオプションを指定することをお勧めします。このオプションが指定されていない場合、データコネクタは最初のlong型またはtimestamp型のカラムをパーティション分割時間として選択します。--time-columnで指定するカラムの型は、long型またはtimestamp型である必要があります(プレビュー結果を使用して、利用可能なカラム名と型を確認してください。一般的に、ほとんどのデータ型にはlast_modified_dateカラムがあります)。
データに時間カラムがない場合は、add_timeフィルターオプションを使用してカラムを追加できます。詳細については、add_time filterプラグインを参照してください。
td connector:issueは、database(sample_db)とtable(sample_table)が既に作成されていることを前提としています。TD内にdatabaseまたはtableが存在しない場合、td connector:issueは失敗します。したがって、databaseとtableを手動で作成するか、td connector:issueで--auto-create-tableを使用して自動的にdatabaseとtableを作成する必要があります。
$ td connector:issue load.yml \
--database td_sample_db \
--table td_sample_table \
--time-column date_time_column \
--auto-create-tableコマンドラインからロードジョブを送信します。データサイズによっては、処理に数時間かかる場合があります。
定期的なファイルまたはフォルダーのインポートのために、定期的なデータコネクタの実行をスケジュールできます。高可用性を確保するために、スケジューラーを慎重に設定しています。この機能を使用することで、ローカルのデータセンターでcronデーモンを使用する必要がなくなります。
スケジュール実行は、Google Driveからデータを取得する定期的な試行中のデータコネクタの動作を制御する設定パラメーターをサポートしています:
incrementalこの設定は、ロードモードを制御するために使用され、ファイルまたはフォルダー内のファイルの最終更新時刻に基づいてデータコネクタがGoogle Driveからデータを取得する方法を管理します。- last_modified_time この設定は、前回のロードジョブからのファイルの最終更新時刻を制御するために使用されます。
詳細と例については、以下のAppendixの「Incremental Loadingの仕組み」を参照してください。
td connector:createコマンドを使用して新しいスケジュールを作成できます。スケジュールの名前、cron形式のスケジュール、データを保存するdatabaseとtable、およびデータコネクタ設定ファイルが必要です。
cronパラメーターは、@hourly、@daily、@monthlyのオプションを受け入れます。
デフォルトでは、スケジュールはUTCタイムゾーンで設定されます。-tまたは--timezoneオプションを使用して、タイムゾーンでスケジュールを設定できます。--timezoneオプションは、'Asia/Tokyo'、'America/Los_Angeles'などの拡張タイムゾーン形式のみをサポートします。PST、CSTなどのタイムゾーン略語は*サポートされておらず*、予期しないスケジュールにつながる可能性があります。
$ td connector:create \
daily_import \
"10 0 * * *" \
td_sample_db \
td_sample_table \
load.ymlTreasure Dataのストレージは時間でパーティション分割されているため、--time-columnオプションを指定することをお勧めします。
$ td connector:create \
daily_import \
"10 0 * * *" \
td_sample_db \
td_sample_table \
load.yml \
--time-column created_attd connector:listコマンドを入力すると、スケジュールされたエントリのリストを表示できます。
$ td connector:list+--------------+------------+----------+-------+--------------+-----------------+--------------------------------------------+| Name | Cron | Timezone | Delay | Database | Table | Config |+--------------+------------+----------+-------+--------------+-----------------+--------------------------------------------+| daily_import | 10 0 * * * | UTC | 0 | td_sample_db | td_sample_table | {"in"=>{"type"=>"google_drive", |+--------------+------------+----------+-------+--------------+-----------------+--------------------------------------------+load.ymlファイルのoutセクションでファイルインポートモードを指定できます。
out:セクションは、データをTreasure Data tableにインポートする方法を制御します。 たとえば、Treasure Dataの既存のtableにデータを追加したり、データを置き換えたりすることができます。
出力モードは、データがTreasure Dataに配置されるときにデータを変更する方法です。
- Append(デフォルト): レコードはターゲットtableに追加されます。
- Replace(td 0.11.10以降で利用可能): ターゲットtableのデータを置き換えます。ターゲットtableに加えられた手動のスキーマ変更はそのまま残ります。
例:
in:
...
out:
mode: append
in:
...
out:
mode: replaceインクリメンタルローディングは、最終更新時刻を使用して、最終更新時刻以降に変更されたファイルのみを読み込みます。
インクリメンタルを使用したファイルからのインポート:
初回実行時、このコネクタはこのファイルを読み込みます。incremental が true の場合、最新の更新時刻がファイル更新時刻として保存されます。
例:
ファイル File0001.csv をインポート:
+--------------+--------------------------+ | Filename | modified time | +--------------+--------------------------+ | File0001.csv | 2019-05-04T10:00:00.123Z |
ジョブが完了すると、last_modified_time は 2019-05-04T10:00:00.123Z に設定されます。
次回実行時には、ファイルの更新時刻が '2019-05-08T10:00:00.123Z' より大きい場合にのみ、ファイル File0001.csv がインポートされます。これは、初回実行後にファイルが更新されたことを意味します。
インクリメンタルを使用したフォルダからのインポート:
初回実行時、このコネクタはファイルタイプが CSV/TSV または CSV/TSV の gzip であるすべてのファイルを読み込みます。incremental が true の場合、フォルダ内のファイルリストを確認し、ファイルから最大更新時刻を取得します。
例:
インポートフォルダに含まれるファイル:
+--------------+--------------------------+ | Filename | Last update | +--------------+--------------------------+ | File0001.csv | 2019-05-04T10:00:00.123Z | | File0011.csv | 2019-05-05T10:00:00.123Z | | File0012.csv | 2019-05-06T10:00:00.123Z | | File0013.csv | 2019-05-07T10:00:00.123Z | | File0014.csv | 2019-05-08T10:00:00.123Z |最大更新時刻: 2019-05-08T10:00:00.123Z
ジョブが完了すると、last_modified_time は最大更新時刻 (2019-05-08T10:00:00.123Z) に設定されます。
次回実行時には、更新時刻が 2019-05-08T10:00:00.123Z より大きいファイルのみがインポートされます。
例:
インポートフォルダに新規追加および更新されたファイル:
+--------------+--------------------------+ | Filename | Last update | +--------------+--------------------------+ | File0001.csv | 2019-05-04T10:00:00.123Z | | File0011.csv | 2019-05-05T10:00:00.123Z | | File0012.csv | 2019-05-06T10:00:00.123Z | | File0013.csv | 2019-05-09T10:00:00.123Z | | File0014.csv | 2019-05-08T10:00:00.123Z | | File0015.csv | 2019-05-09T13:00:00.123Z |最大更新時刻: 2019-05-09T13:00:00.123Z
この場合、File0013.csv と File0015.csv のファイルのみがインポートされます。ジョブが完了すると、last_modified_time は最大更新時刻 (2019-05-09T13:00:00.123Z) に設定されます。
CLI からジョブを発行するには、client_id、client_secret、refresh_token が必要です。
https://console.cloud.google.com/projectcreate にアクセスしてプロジェクトを登録します。
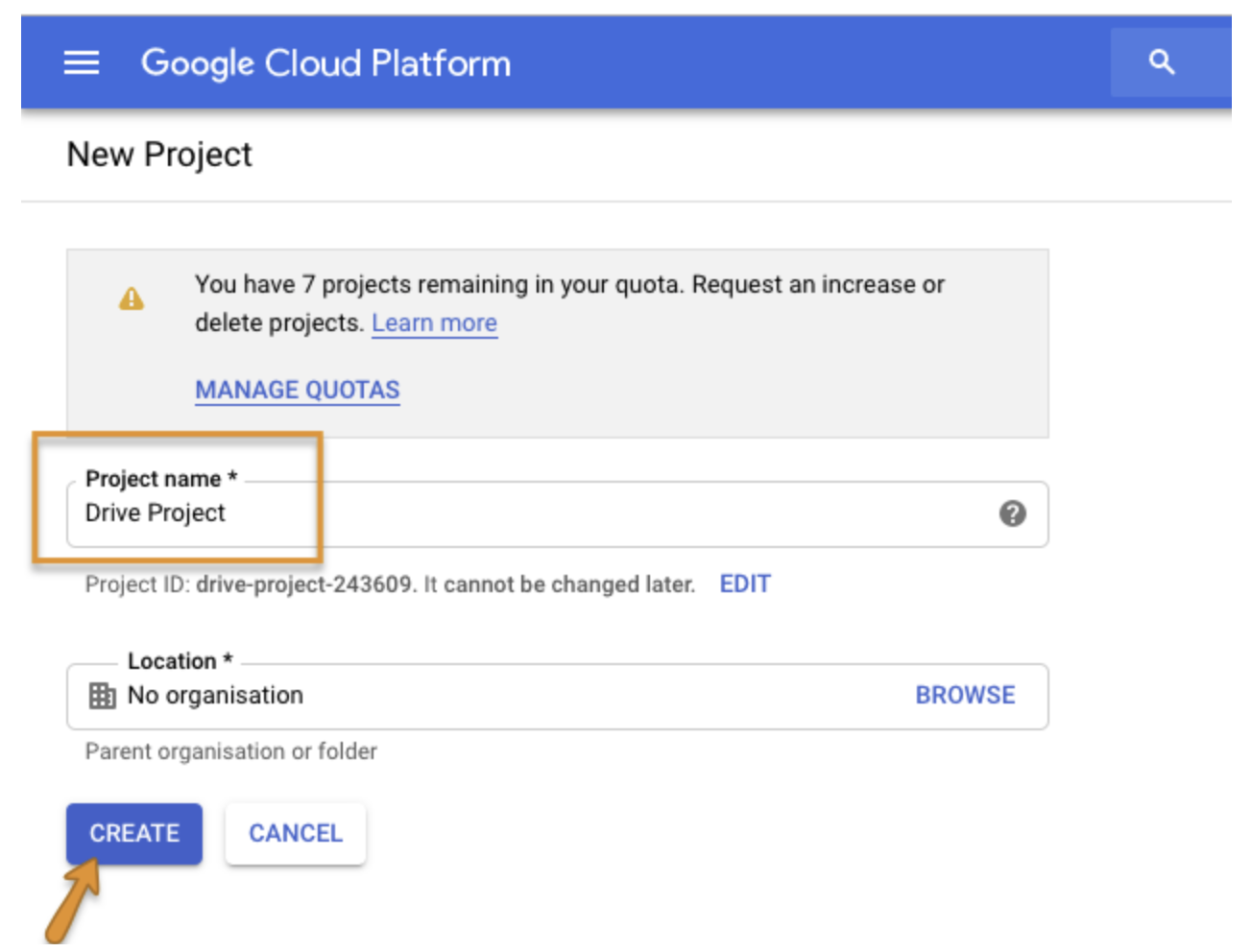
プロジェクトに名前を付け、Create を選択します。
https://console.cloud.google.com/apis/dashboard? にアクセスして、プロジェクトの Drive Service を有効にします。
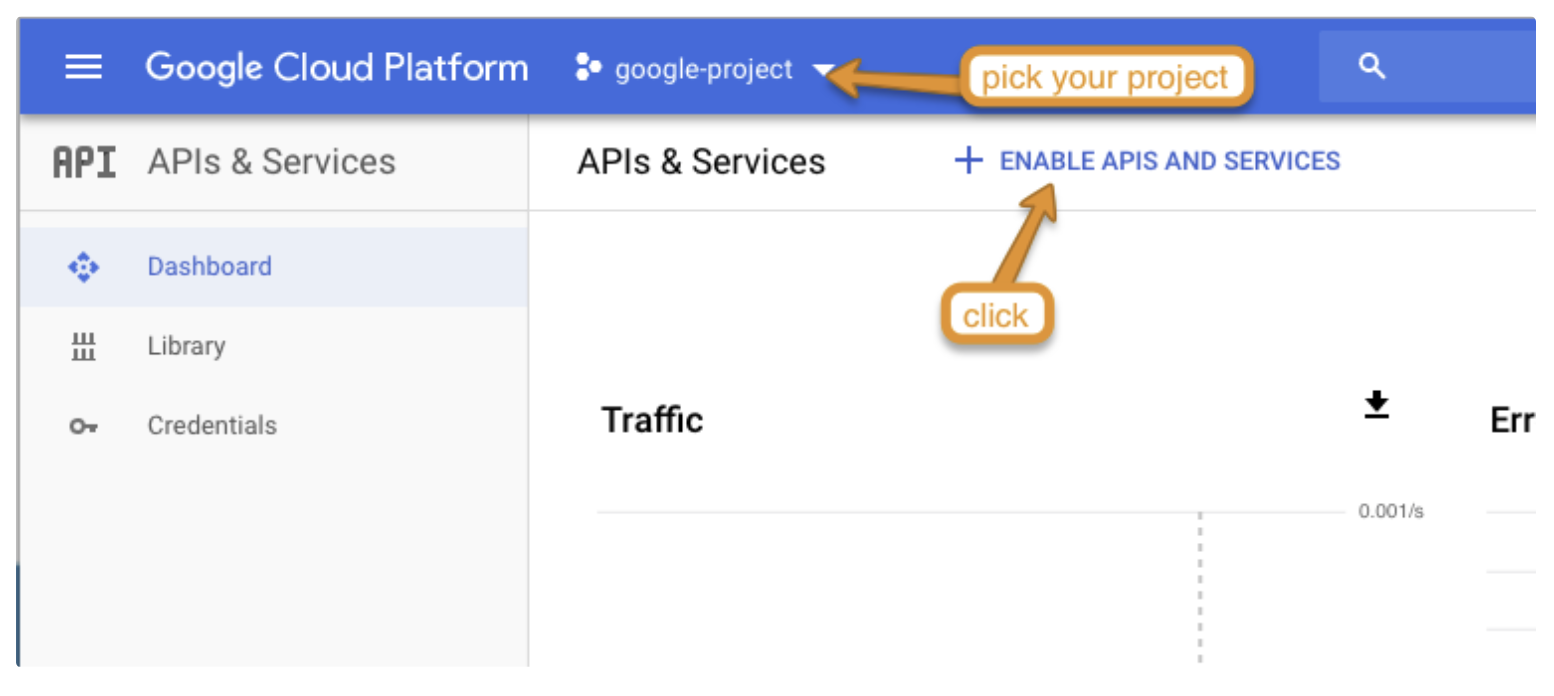
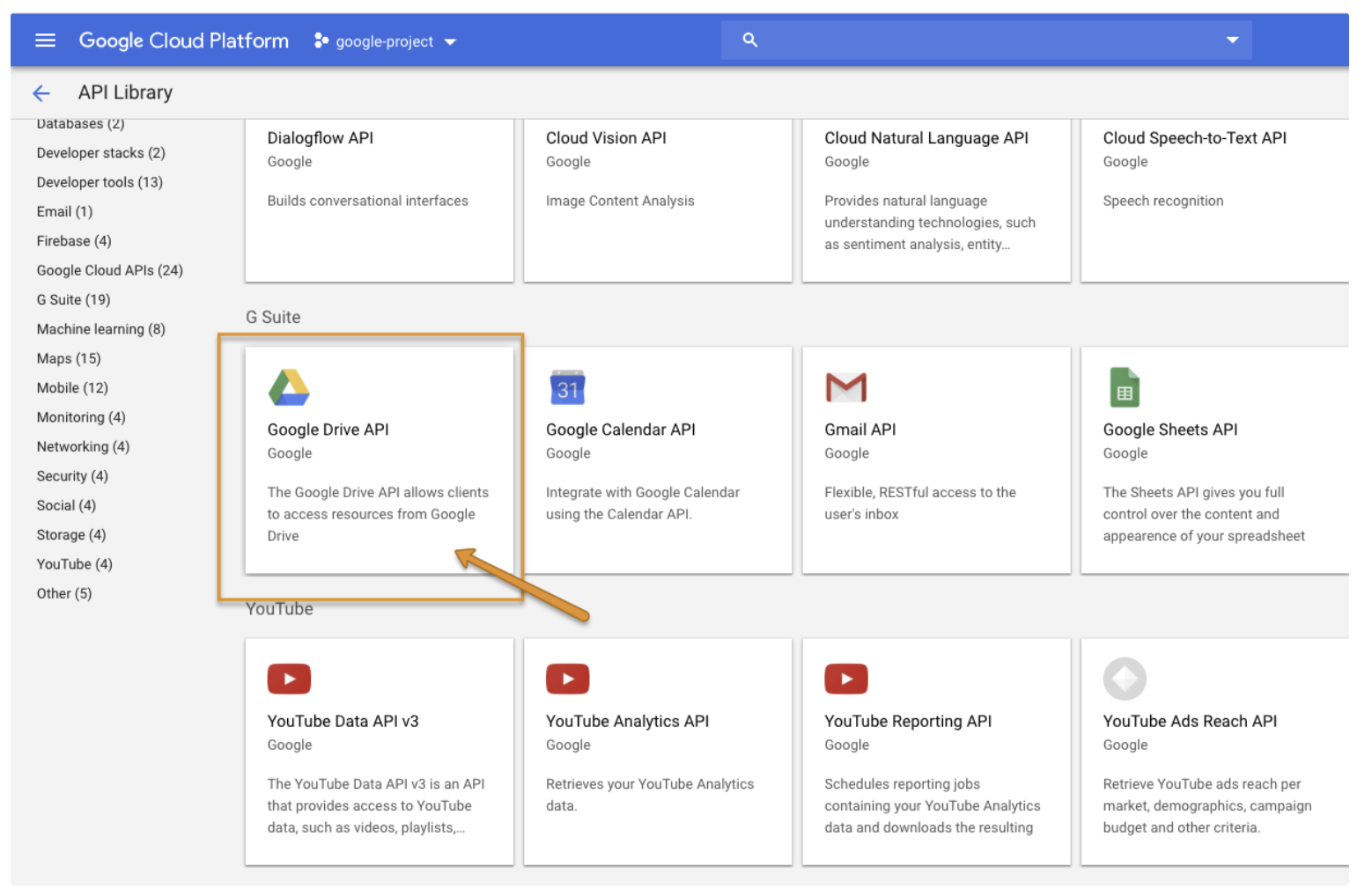
Google Drive API を選択し、Enable を選択します。
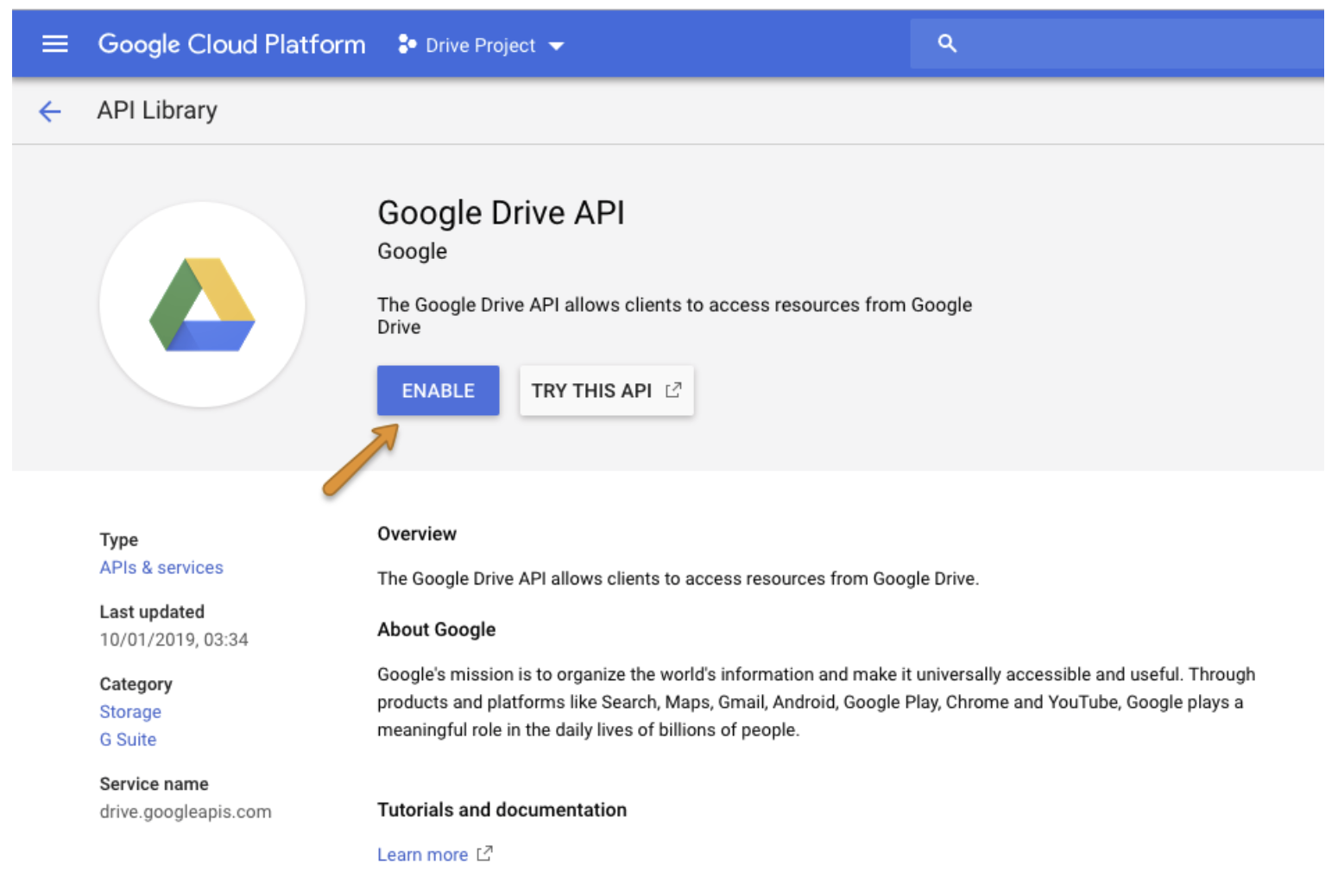
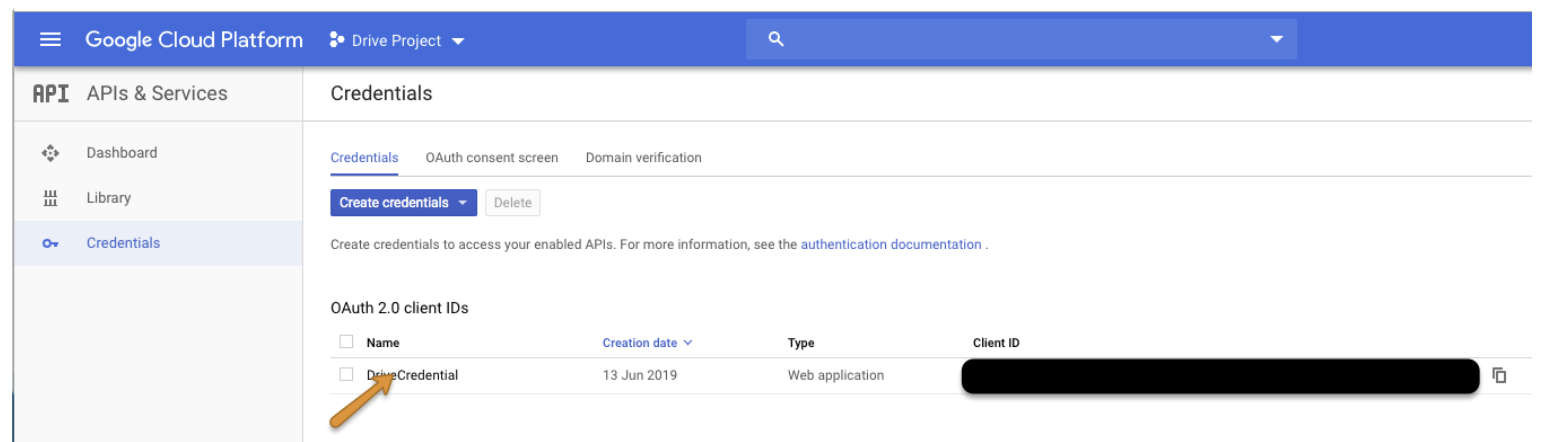
https://console.cloud.google.com/apis/credentials にアクセスし、プロジェクトを選択して新しい認証情報を作成します。
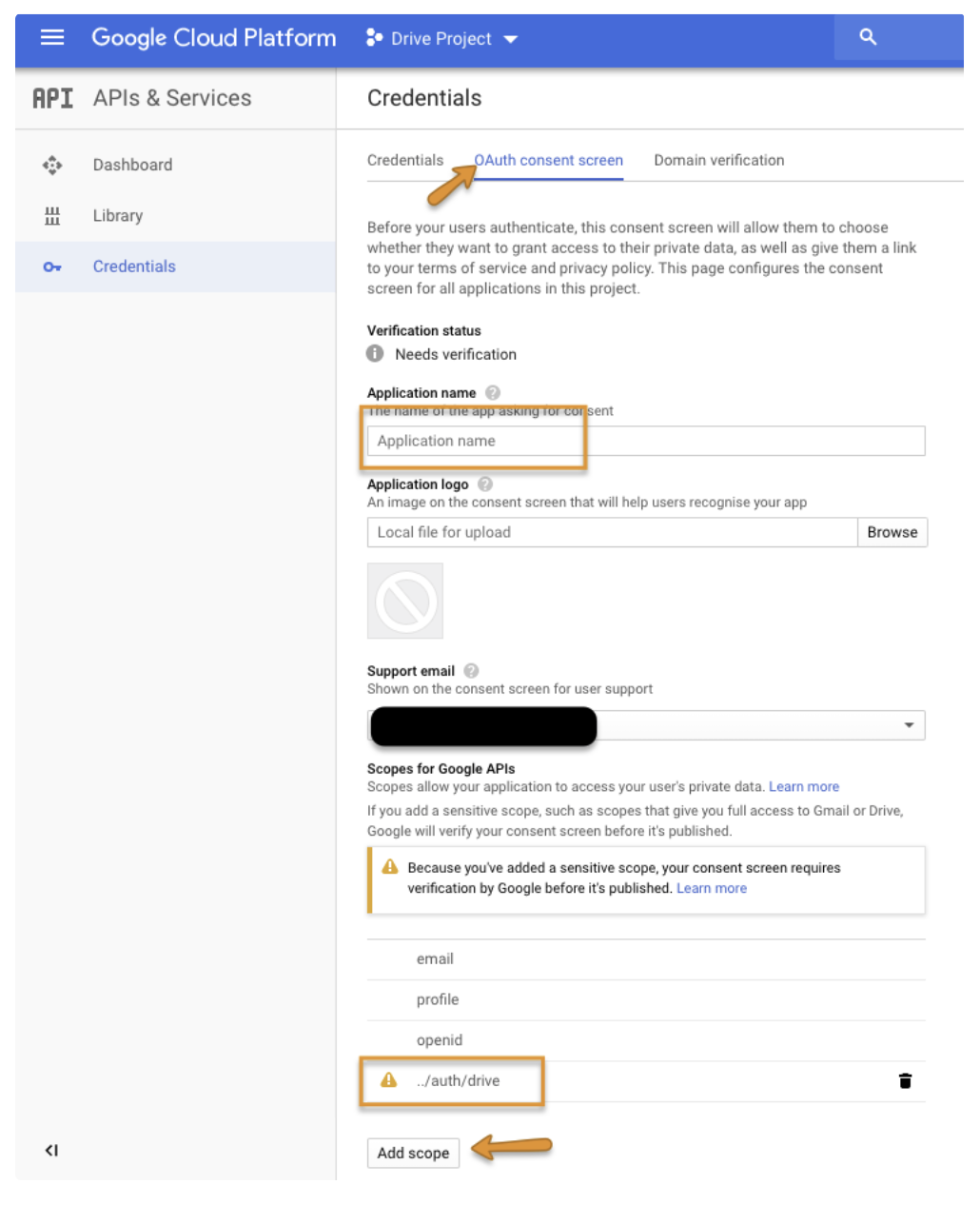
OAuth consent screen タブに移動し、アプリケーション名を入力してから、Add scope を選択して /auth/drive スコープを追加し、Save を選択します。
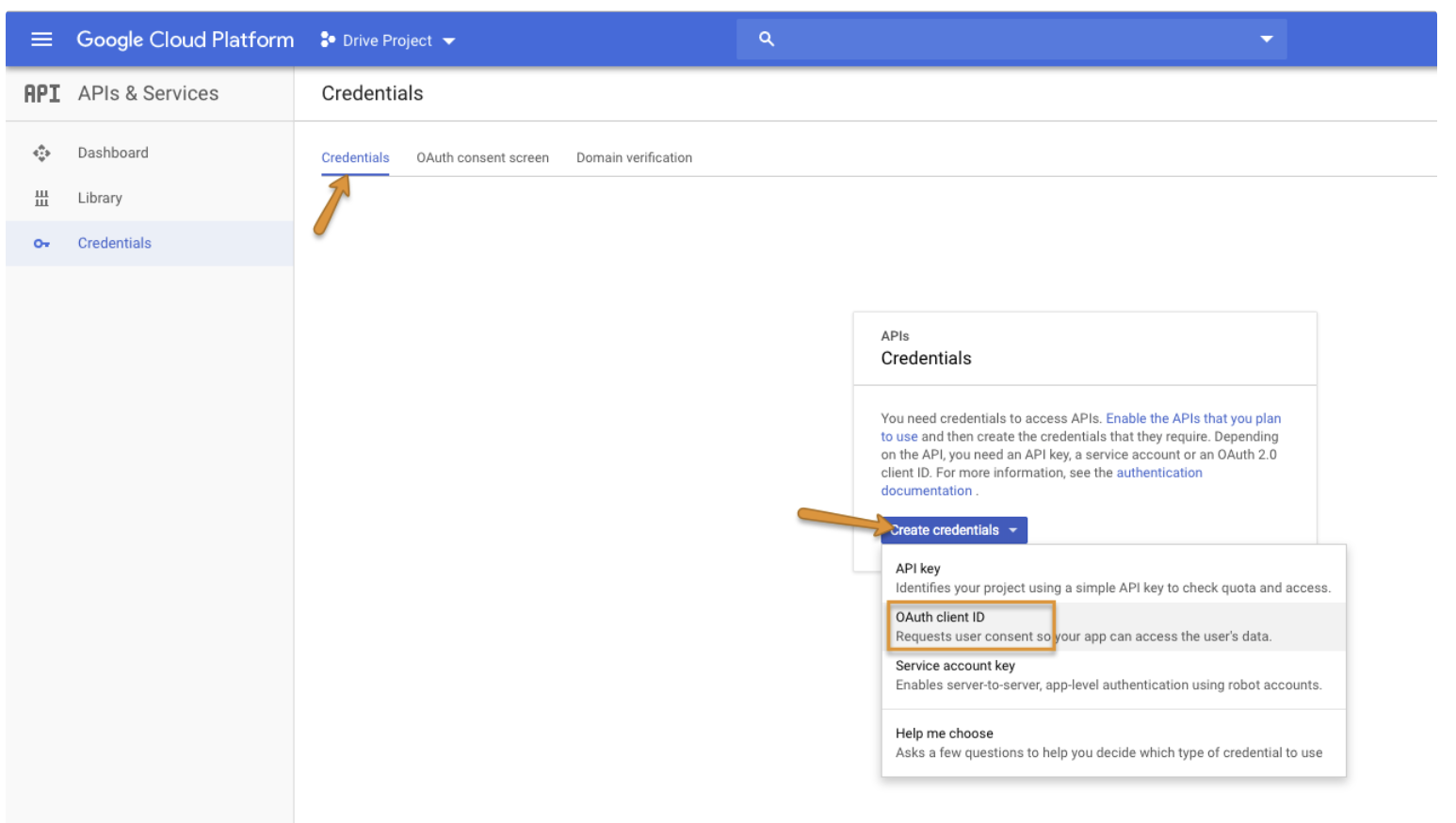
Credentials タブに移動し、Create credentials をクリックしてから OAuth client ID を選択します。
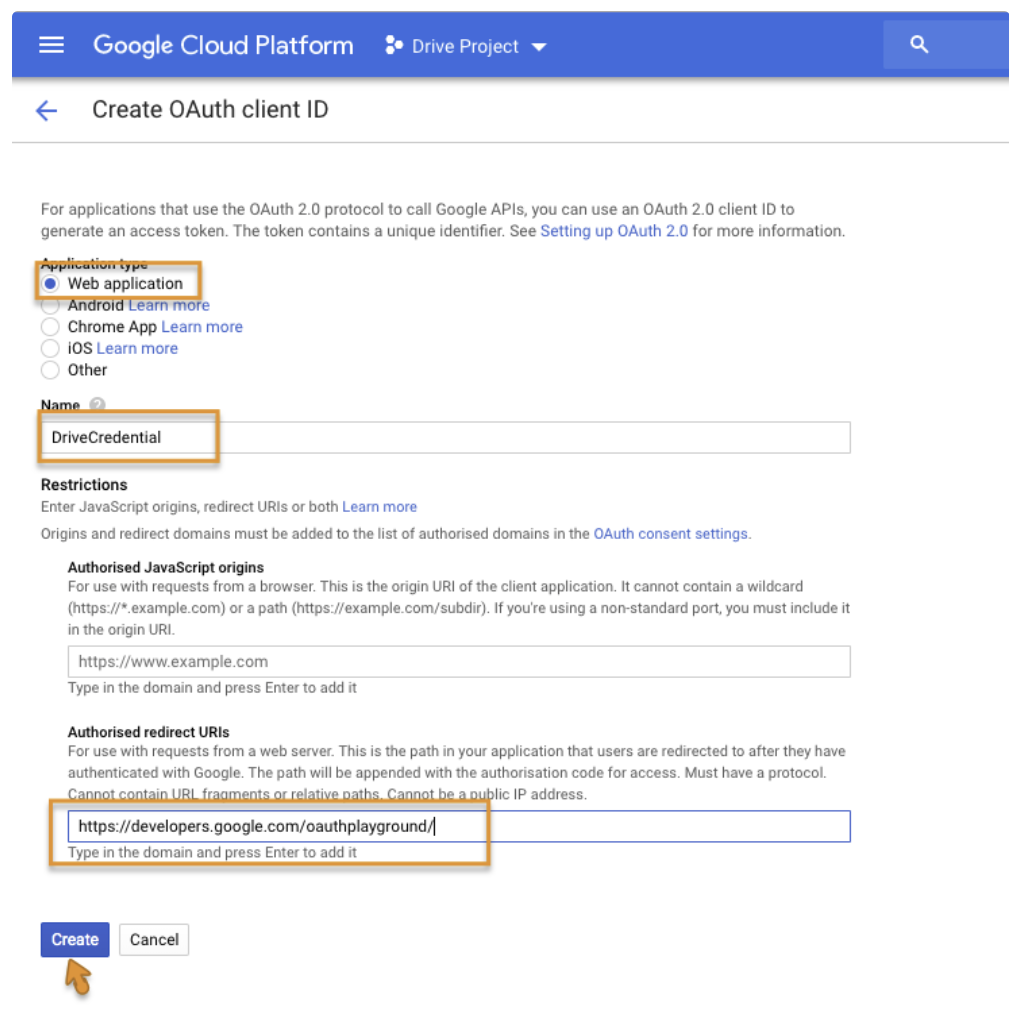
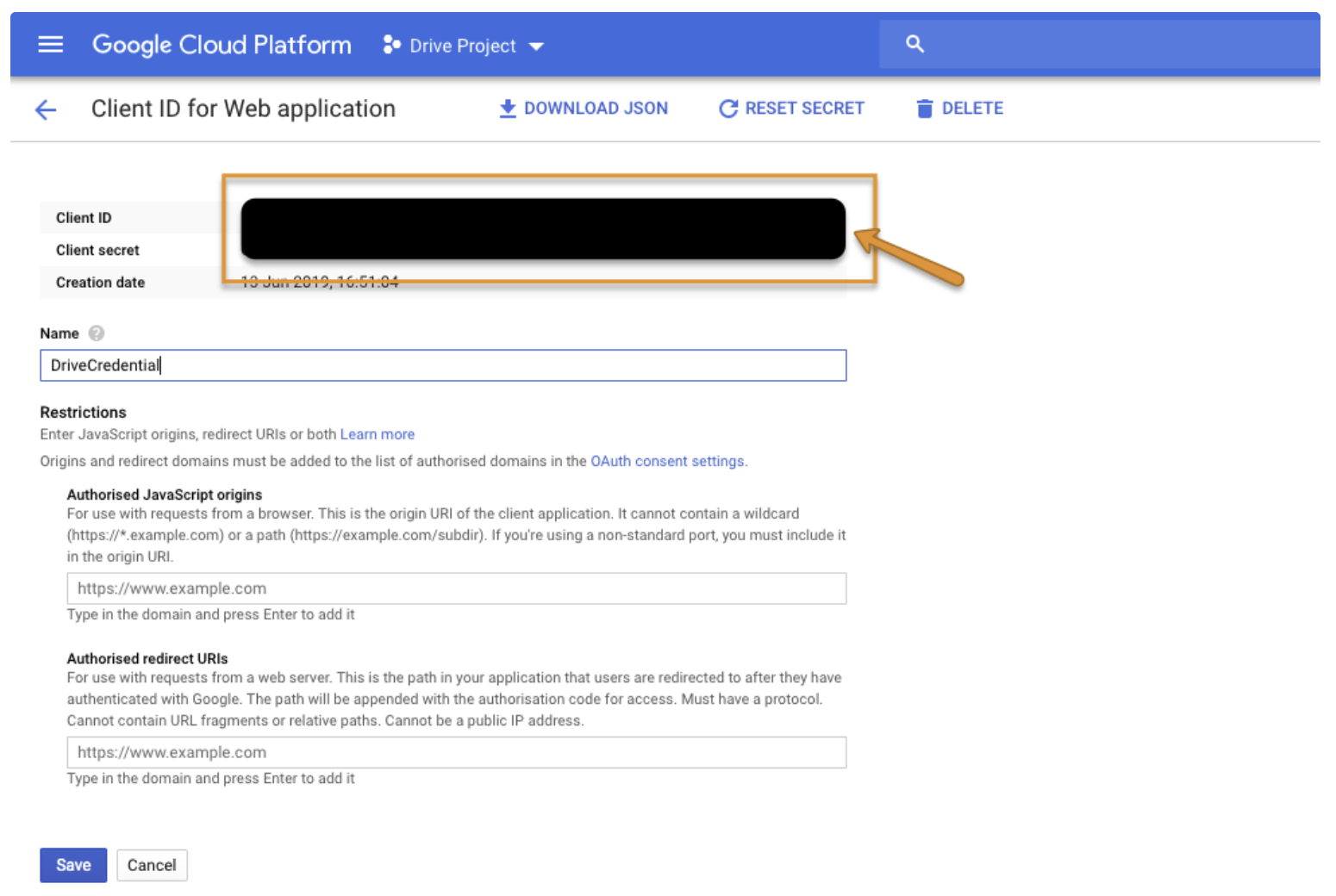
認証情報に名前を付け、リダイレクト URL として https://developers.google.com/oauthplayground/ を追加します。
認証情報を選択して、client_id と client_secret を取得します。
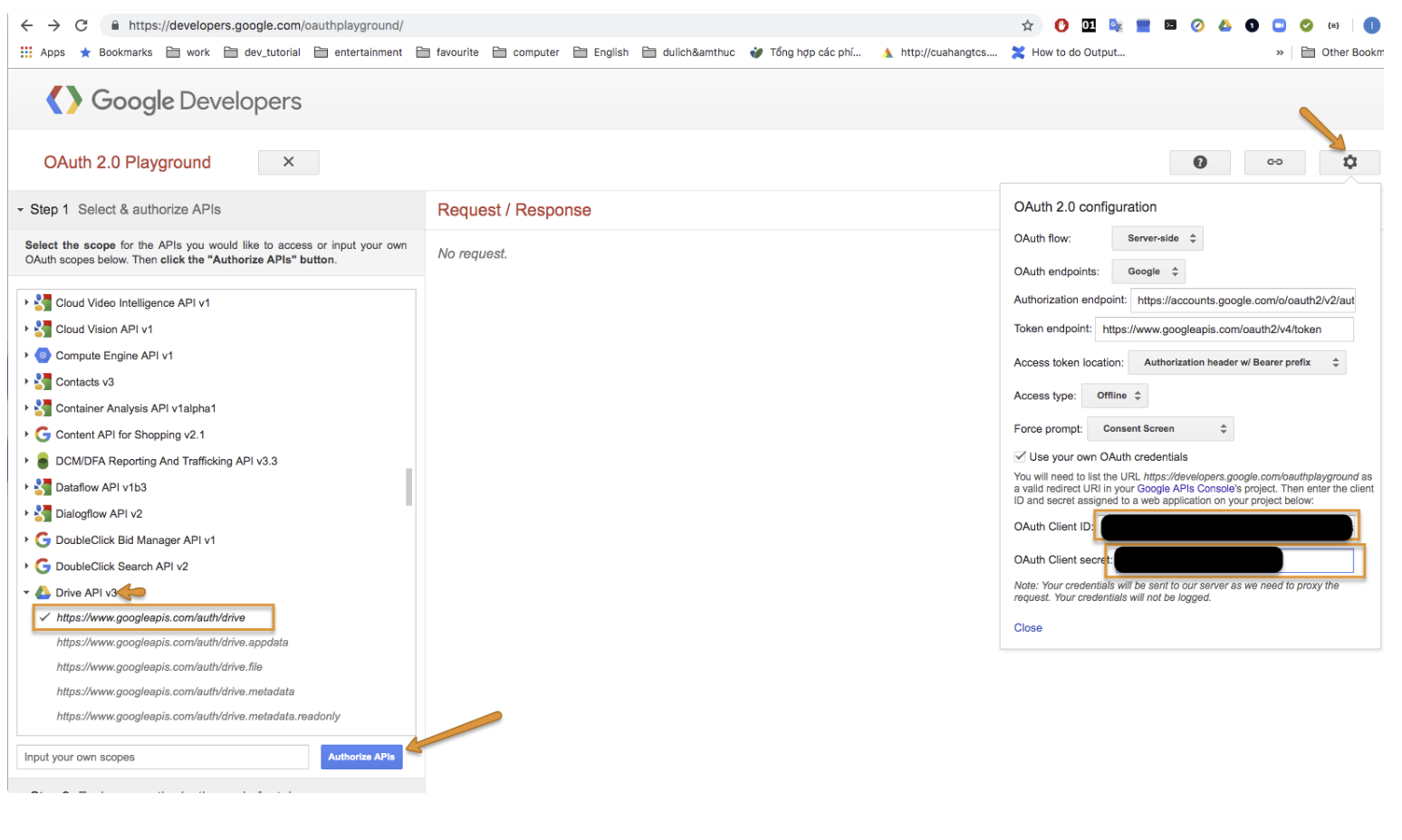
https://developers.google.com/oauthplayground にアクセスして refresh_token を取得します。
まず、Drive API v3 とスコープ auth/drive を選択し、Settings を選択して認証情報から取得できる client id、client secret を入力してから、Authorize APIs を選択します。
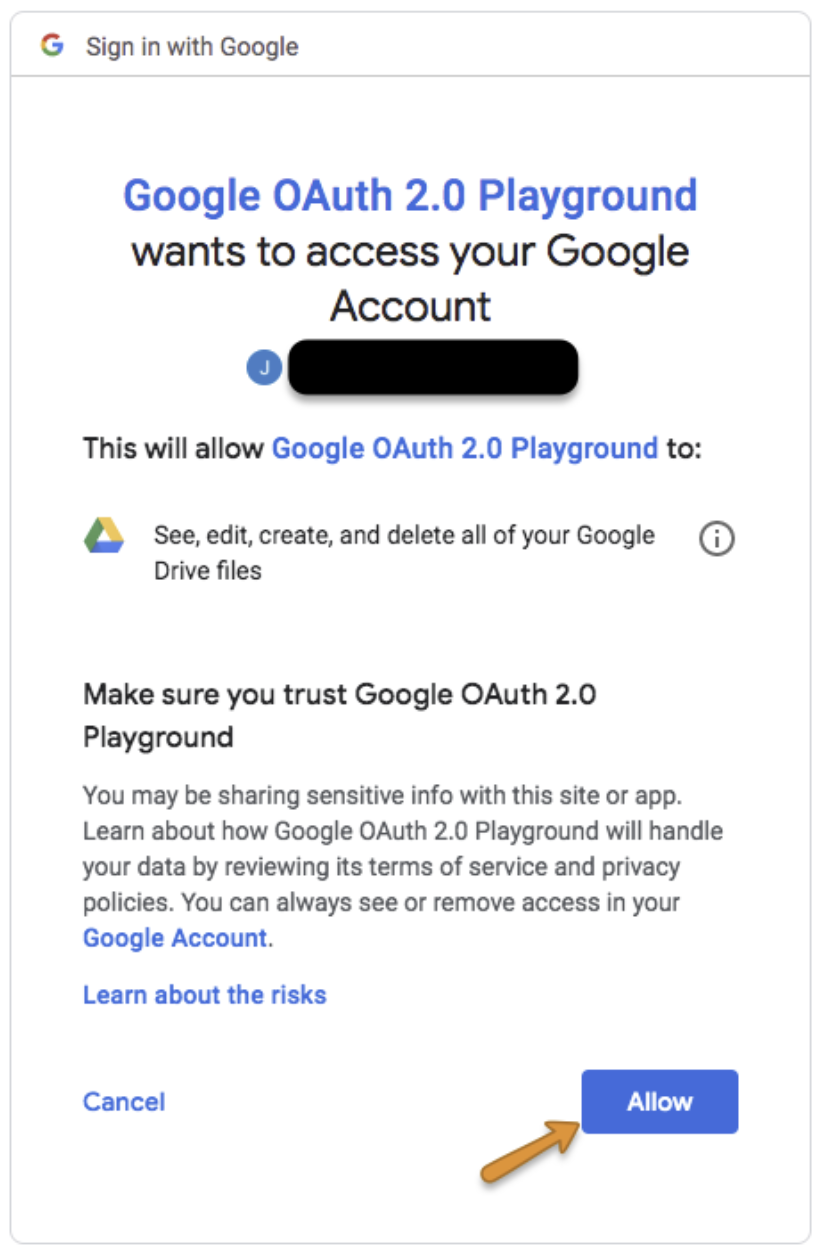
Google アカウントでログインし、Allow を選択します。
Exchange authorization code for tokens を選択します。
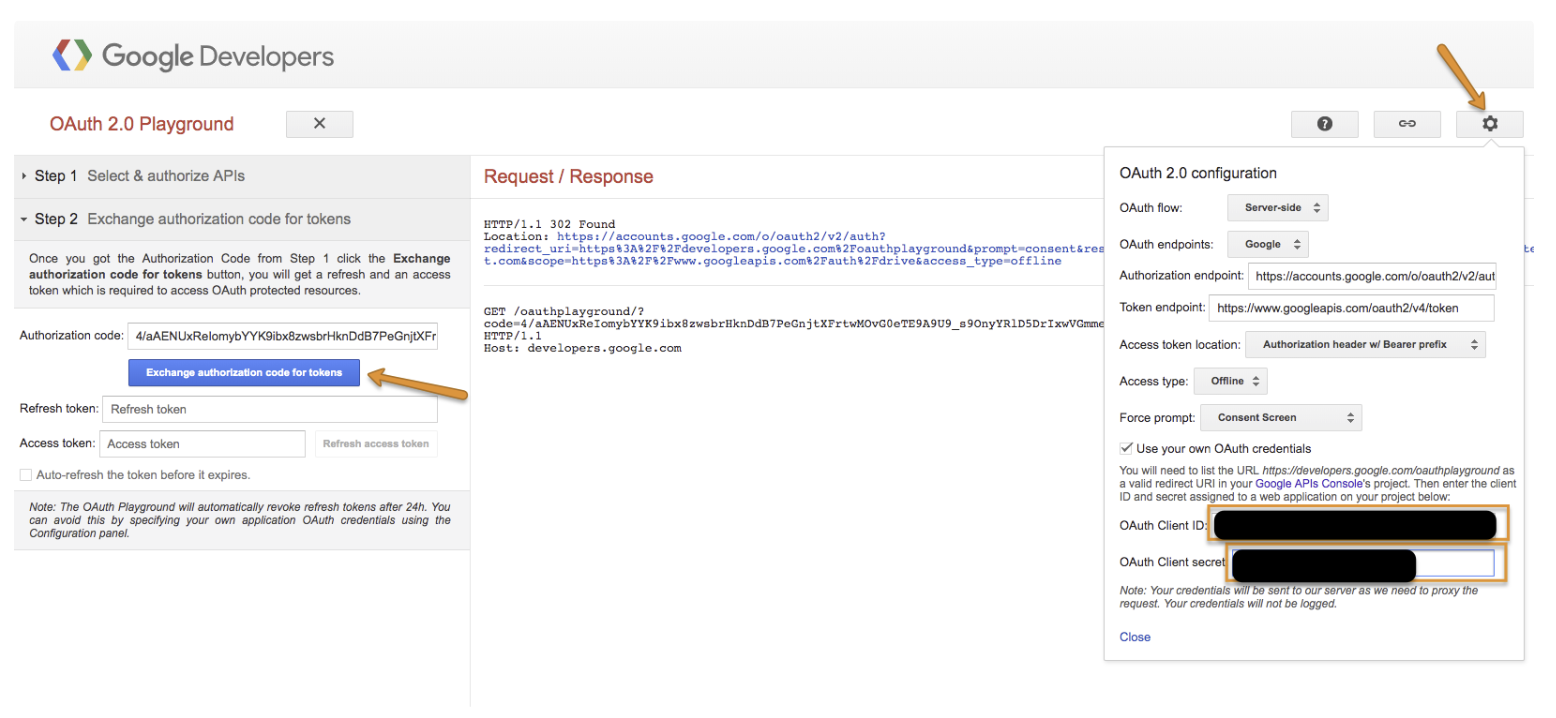
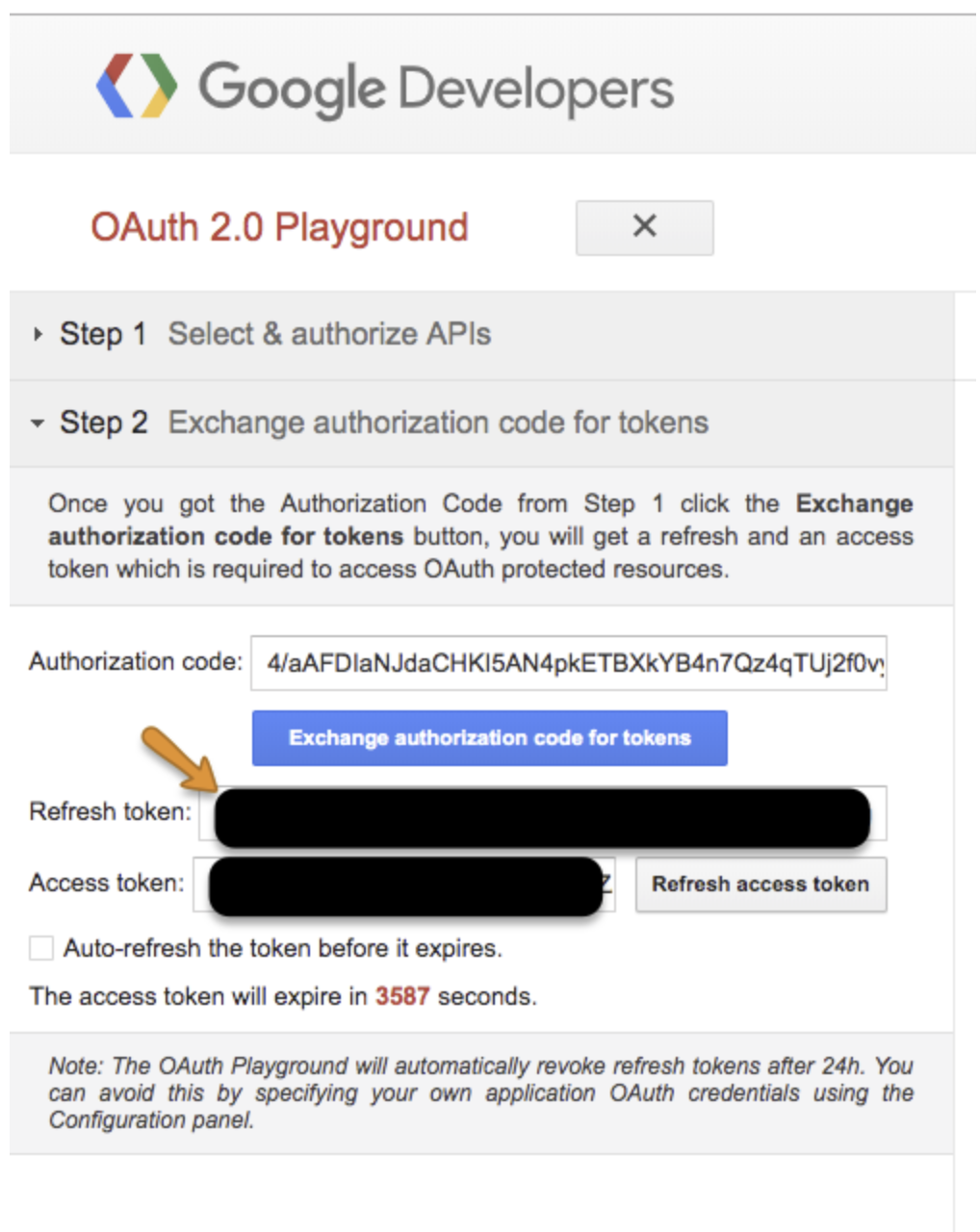
refresh token をコピーして、後で使用するために保存します。
refresh token は、次のいずれかの理由で機能しなくなる可能性があります:
- ユーザーがアプリへのアクセスを取り消した。
- refresh token が 6 か月間使用されていない。
- ユーザーがパスワードを変更し、refresh token に Gmail スコープが含まれている。
- ユーザーアカウントが付与された (有効な) refresh token の最大数を超えた。
現在、クライアントごとのユーザーアカウントあたりの refresh token の制限は 50 です。制限に達すると、新しい refresh token を作成すると、警告なしに最も古い refresh token が自動的に無効になります。
参照: https://developers.google.com/identity/protocols/OAuth2
https://drive.google.com にアクセスし、Google アカウントでログインします。
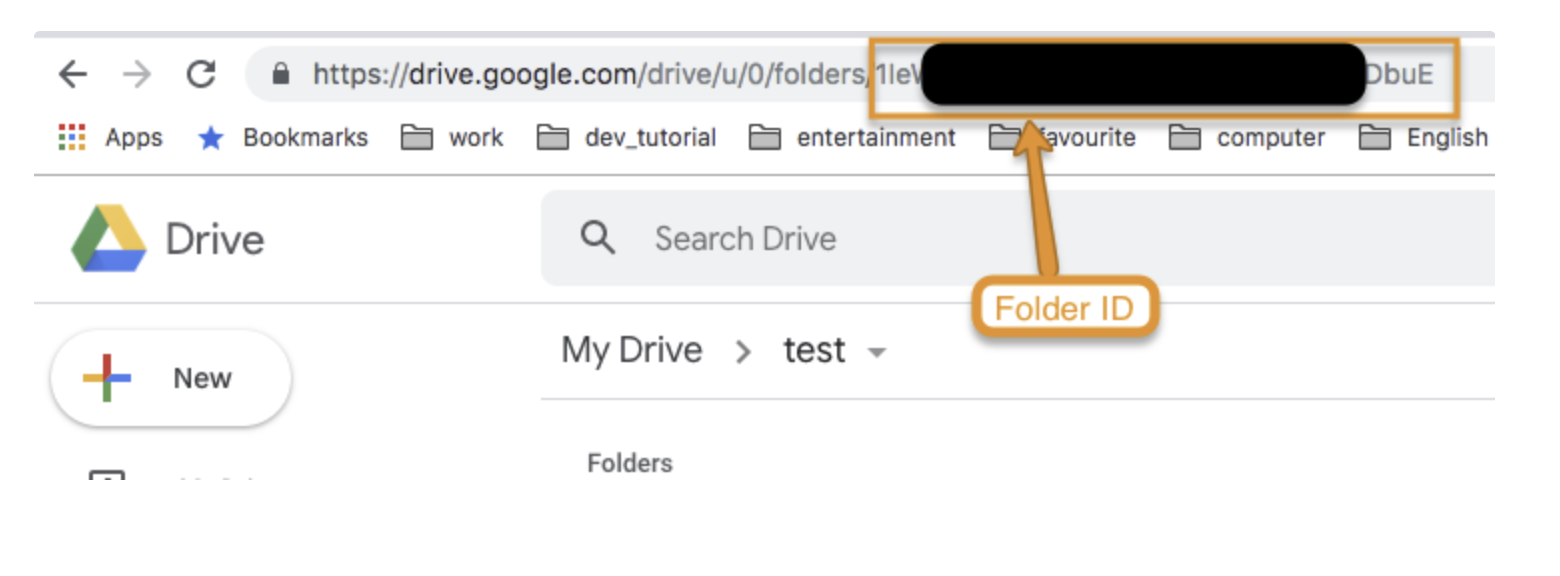
Folder ID の取得:
Folder ID を取得したいフォルダを選択し、URL から ID をコピーします。
File ID の取得:
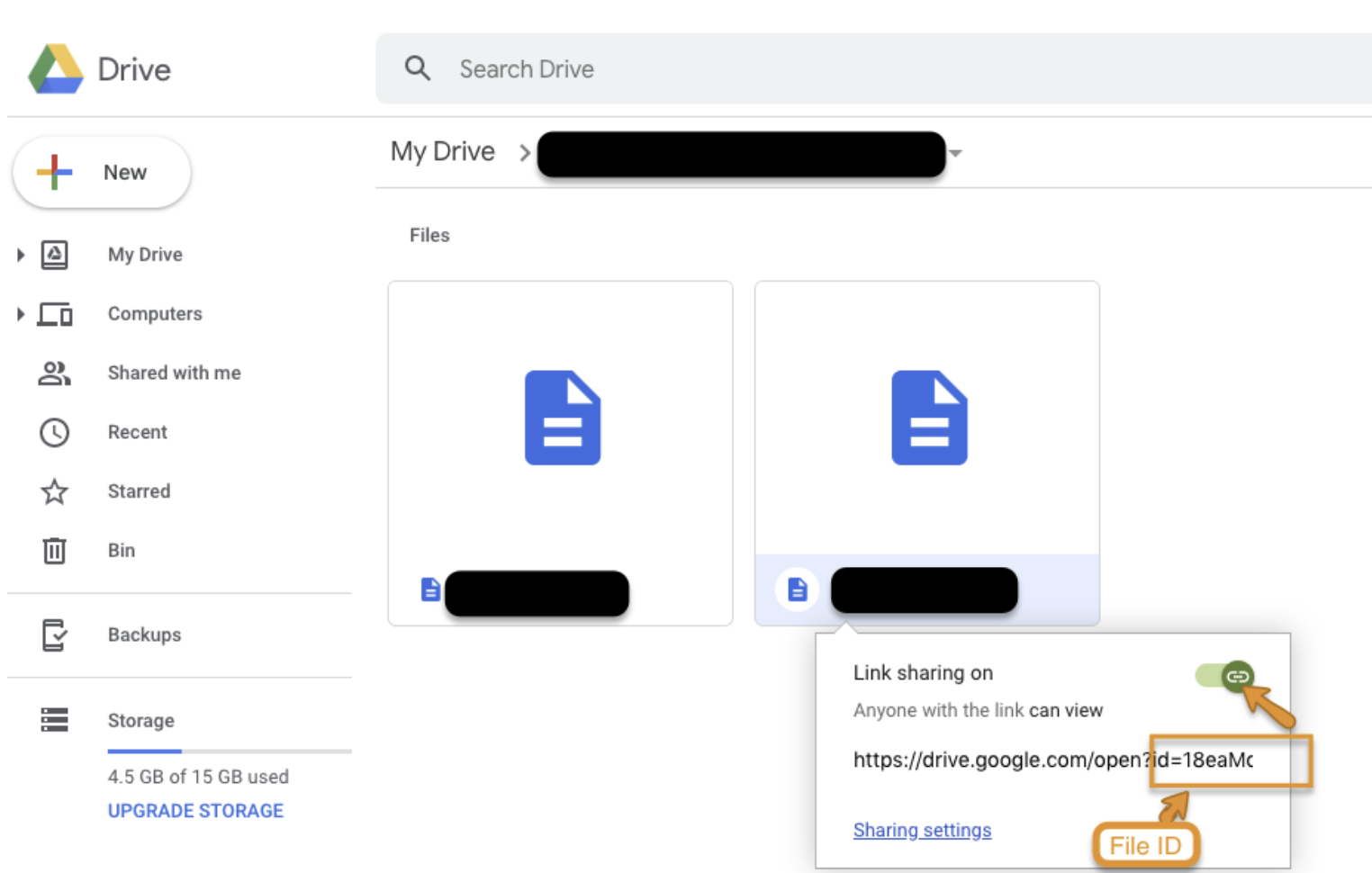
ドライブからファイルを選択し、右クリックして「Get shareable link」を選択します。
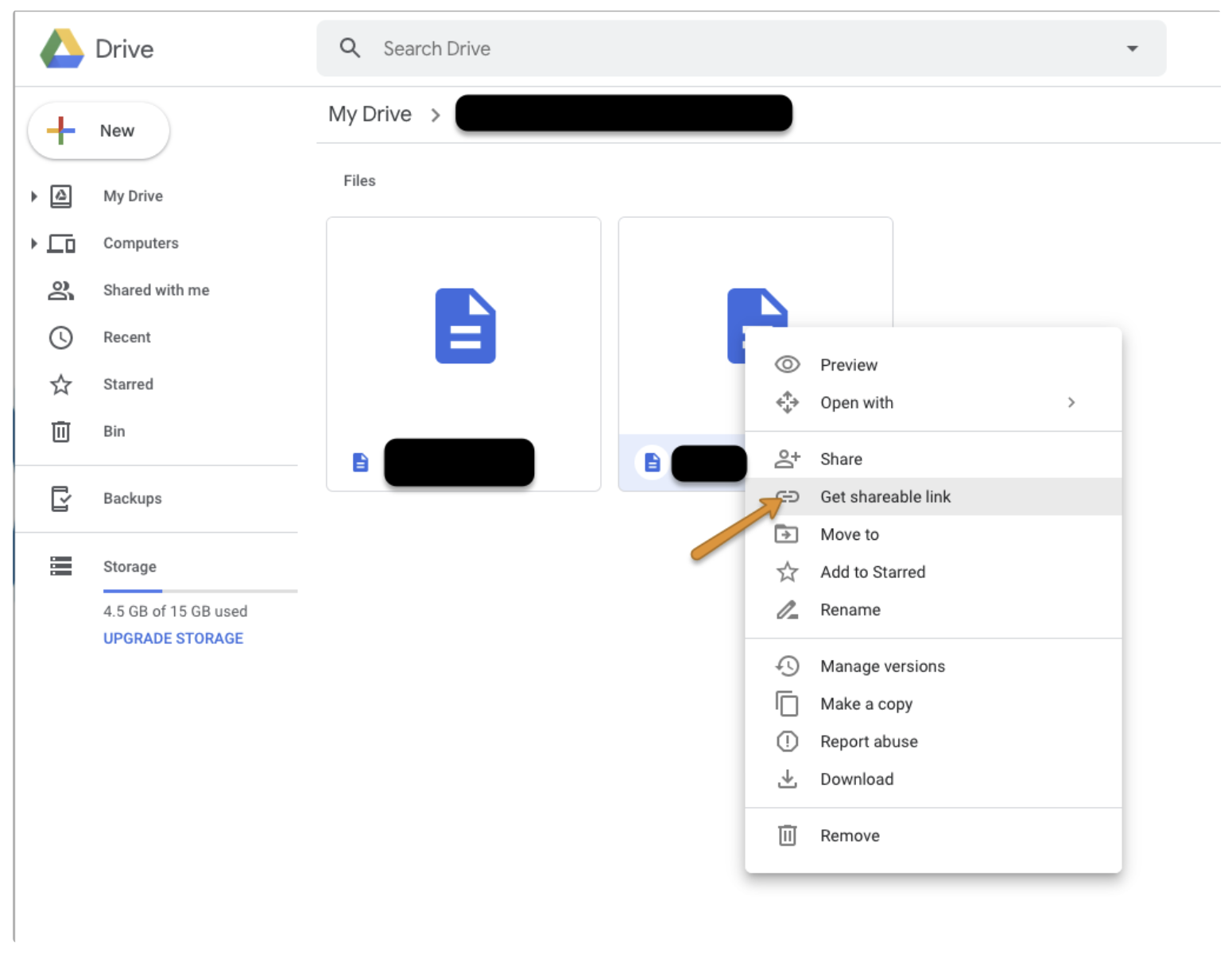
Link sharing をオンにして、リンクから File ID をコピーします。