Treasure DataからGoogle Sheetsに直接ジョブ結果をエクスポートできます。Google Sheetsでデータをさらに分析し、重要なビジネスインサイトを発見できます。
作成または変換したスプレッドシートに対して、最大200万セルまで転送できます。詳細はGoogle Helpをご覧ください。
Google Sheetsにジョブ結果をエクスポートするサンプルワークフローについては、Treasure Boxesをご覧ください。
- TD Toolbeltを含むTreasure Dataの基本知識
- Googleアカウント(Google Drive用)
- 認可されたTreasure Dataアカウントアクセス
以下のようにアクセスURLからspreadsheet keyを取得できます:
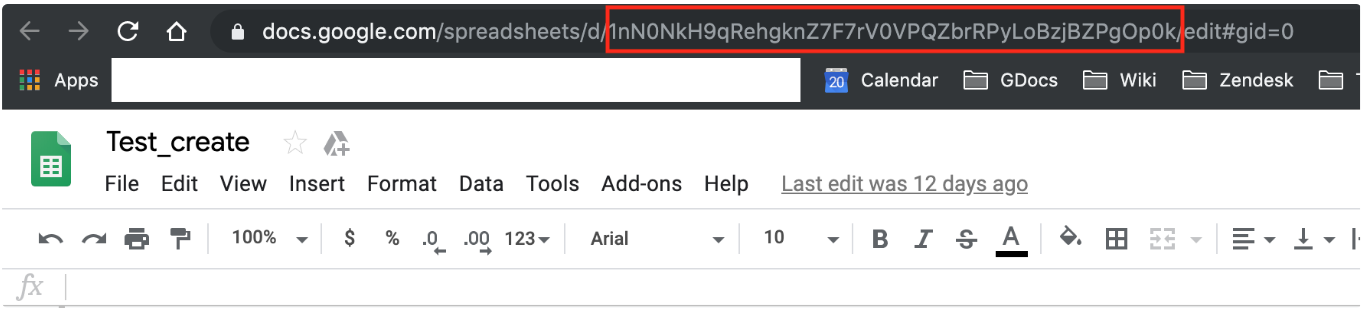
以下のようにアクセスURLからGoogle DriveのFolder Keyを取得できます:

Google Sheet V3の2020年3月の非推奨化により、既存のすべての認証を更新する必要があります。2020年2月中旬までに既存の認証の更新を実行する必要があります。
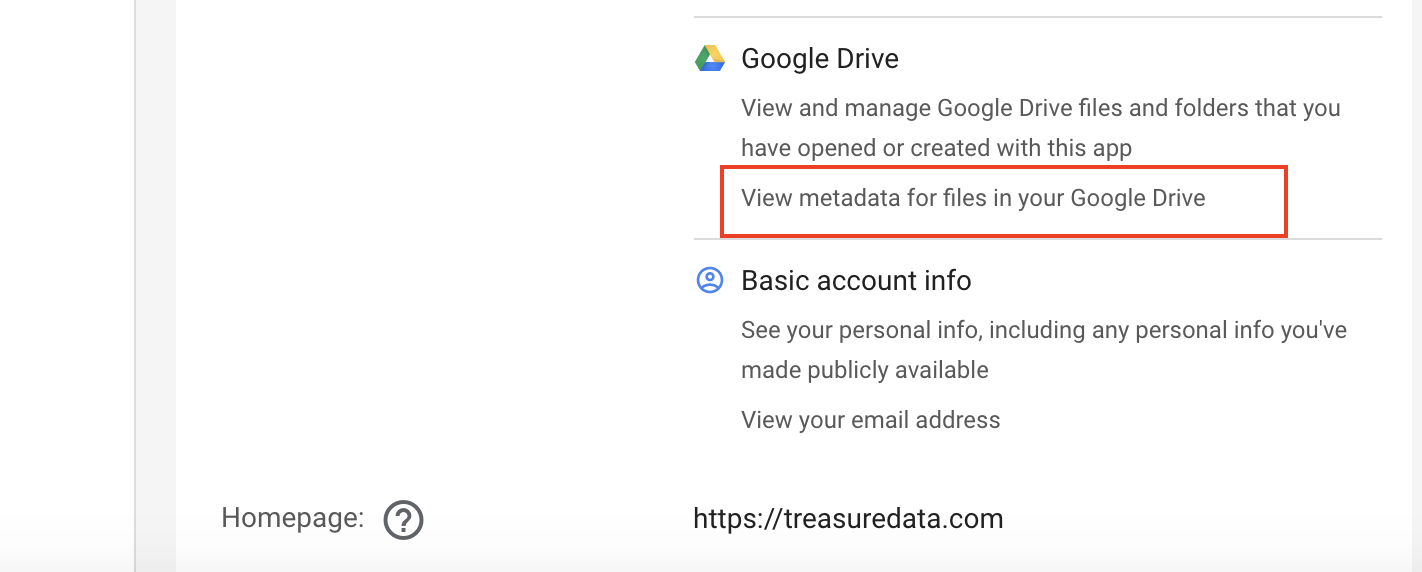
アップグレードには、既存のGoogle Sheet認証にFolder Keyを適用する必要があります。Folder Keyオプションを使用するには、Googleアカウントで「View metadata for files in your Google Drive」権限を選択してください。
Folder Keyオプションで既存の認証を更新しない場合、予測不可能な動作が発生します。
- TD Consoleで、Integrations Hub > Authenticationsに移動します。
- Google Sheet Authenticationオブジェクトを見つけます。
- Click here to connect a new accountを選択して、Googleでの認証にリダイレクトします。
- Googleで適切なアカウントを選択し、「View metadata for files in your Google Drive」スコープを含めてAllowを選択します。
- TD Consoleで、Google Sheet Authenticationを再度開き、ドロップダウンリストの一番下にある最新の認証アカウントを選択します。
- ContinueとDoneを選択して認証を保存します。
- 認証を使用して結果をエクスポートするクエリを保存している場合、既存の結果エクスポート設定を削除し、認証を使用した新しいクエリを作成する必要があります。
- 同じGoogleアカウントを使用する他の認証で、手順4〜6を繰り返します。
認証に権限が含まれているかどうかを確認するには、Googleアカウントにログインし、ブラウザでURL: https://myaccount.google.com/permissionsにアクセスしてください。以下のようにGoogle DriveでのTreasure Data権限を確認します:
セキュリティポリシーで IP ホワイトリストが必要な場合は、接続を成功させるために Treasure Data の IP アドレスを許可リストに追加する必要があります。
リージョンごとに整理された静的 IP アドレスの完全なリストは、次のリンクにあります: https://api-docs.treasuredata.com/en/overview/ip-addresses-integrations-result-workers/
クエリを実行する前に、エクスポートデータ接続を作成して設定する必要があります。データ接続の一部として、統合にアクセスするための認証を提供します。
Integrations Hub > Catalogに移動します。
Google Sheetsを検索して選択します。
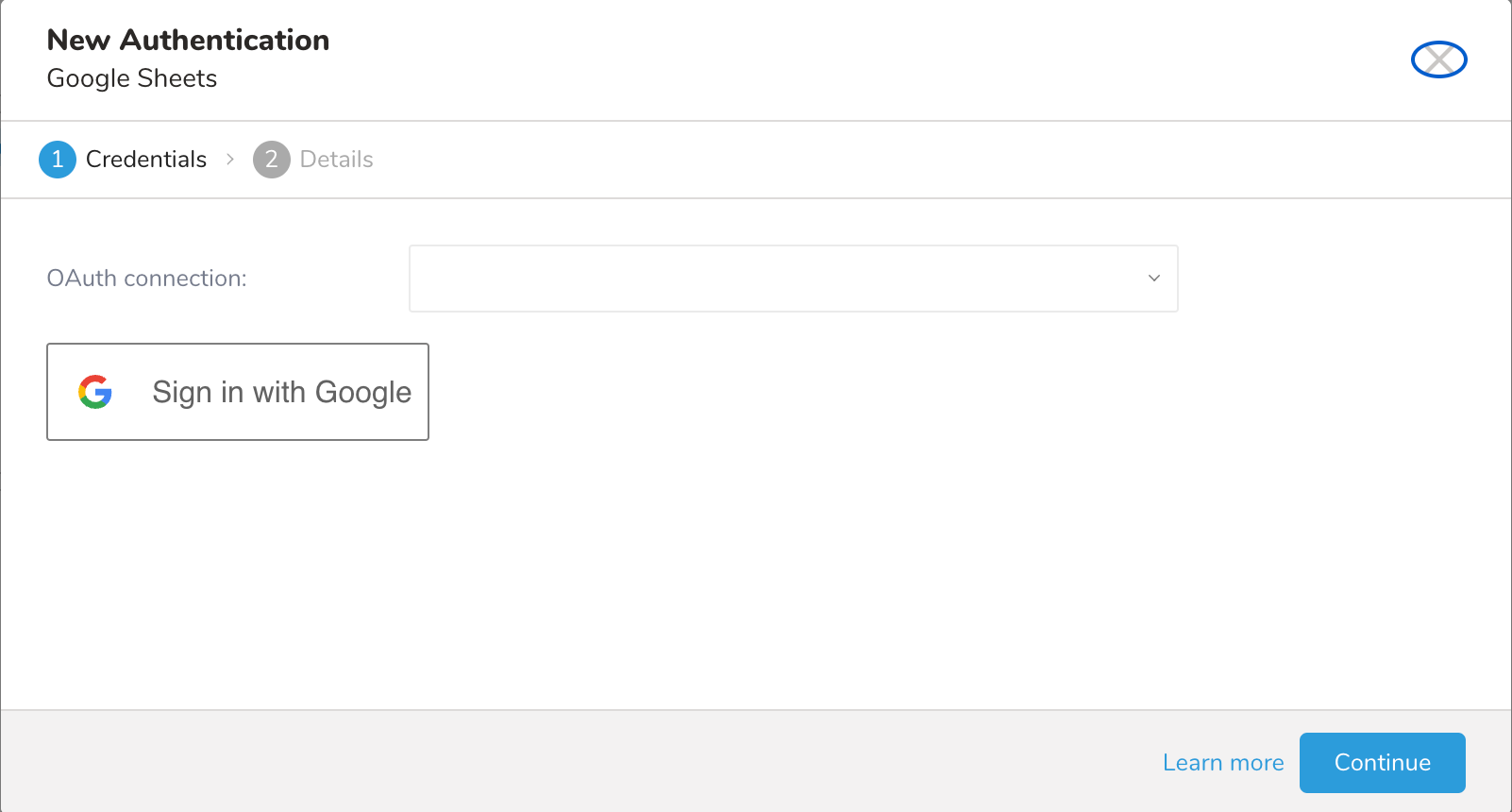
認証ダイアログが開きます。
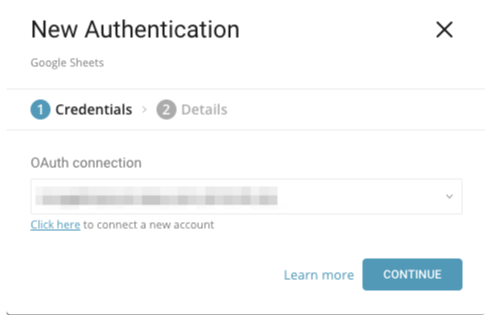
既存のOAuth接続を選択するか、新しい接続を作成して接続を認証します。
新しいGoogle Sheets接続の名前を選択します。
Treasure Data Google Sheets統合へのアクセスには、OAuth2認証が必要です。認証では、Treasure DataアカウントをそれぞれのGoogleアカウントに接続する必要があります。
既存の接続がない場合は、新しい認証を作成します。
認証ダイアログを開いた後、「OAuth connection」の下にあるリンクを選択して新しい接続を作成します。
ポップアップウィンドウでGoogle Sheetsアカウントにログインし、Treasure Dataアプリへのアクセスを許可します。

統合ダイアログペインにリダイレクトされます。Google Sheetsを選択し、ドロップダウンメニューから新しい接続を選択します。
- Data Workbench > Queriesに移動します。
- New Queryを選択します。
- クエリを実行して結果セットを検証します。
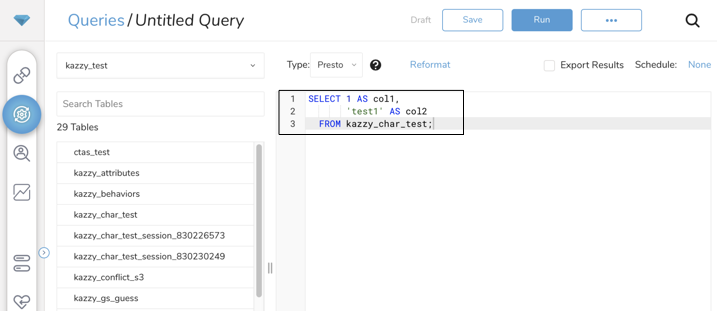
Data Workbench > Queriesに移動します。
既存のクエリを選択するか、新しいクエリを作成します。
クエリエディタで、Export Resultsチェックボックスを選択します。

Google Sheet接続を選択します。
Export Resultsダイアログペインが開きます。以下のパラメータを編集します。
| Parameters | Description |
|---|---|
| spreadsheet_idまたはspreadsheet_titleのいずれかを指定する必要があります。両方を使用することはできません。 | |
| Use Spreadsheet Key | チェックを外すと、spreadsheet_titleがキーとして使用されます。それ以外の場合は、spreadsheet_idが使用されます。 |
| Spreadsheet name | 新しいスプレッドシートのタイトル。同じタイトル(大文字小文字を区別)のスプレッドシートが宛先フォルダ(Folder Keyで指定)または任意のフォルダ(FolderKeyが空の場合)に複数存在する場合、ジョブは失敗します。この場合は、代わりにspreadsheet keyで指定してください。 |
| Folder key | エクスポートするデータのフォルダID。空の場合、宛先フォルダはスプレッドシート名の一致によって決定されるか、一致しない場合はMy Driveのルートフォルダが使用されます。このパラメータはスプレッドシート名を使用する場合にのみ利用可能です。 |
| Worksheet | スプレッドシート内のワークシートの名前。この名前は(スペースを含めて)Googleワークシート名と比較されます。空の場合、データは最初のワークシートにエクスポートされます。 |
| Upload mode | スプレッドシート内のデータを変更するモード。 |
| Range | データが書き込まれる初期セル位置。 |
| Batch rows to upload | 1回の呼び出しでスプレッドシートにアップロードする行数。バッチアップロードの行数が多いほど、アップロードされるペイロードボリュームが大きくなり、すべてのデータのアップロードを完了するために必要な呼び出し回数が少なくなります。 |
| Value Input Option | RAWを使用してデータをスプレッドシートに直接アップロードするか、USER_ENTEREDを使用します。USER_ENTEREDは、ユーザーがユーザーインターフェースに入力したかのようにデータを解析します。数値は数値のままですが、文字列はGoogle Sheet UIを介してセルにテキストを入力する際に適用されるのと同じルールに従って、数値や日付などに変換される可能性があります。 |
| Set Cell to Null | 無効な値(0で除算するなど)が検出された場合のセルの表示値を制御します。 |
セグメントデータまたはステージをエクスポートするためのactivationを作成できます。
Product DocumentationポータルでActivationを作成する手順を確認してください:Creating an Activation
SELECT * FROM www_access次の方法でスプレッドシートデータを操作できます:Replace、Append、Truncate、Update。
テーブルが既に存在する場合、既存のテーブルの行はクエリ結果で置き換えられます。テーブルが存在しない場合は、新しいテーブルが作成されます。これがデフォルトのモードです。
クエリ結果はスプレッドシートの末尾に追加されます。テーブルがまだ存在しない場合は、新しいテーブルが作成されます。
例えば、1000行の空の行があるデフォルトのシートがある場合、APPENDモードはスプレッドシートで表示される最後の行の次の行(この例では1001行目)からクエリ結果の行を追加し始めます。
テーブルがすでに存在する場合、既存の行がクリアされ、クエリ結果がテーブル内で更新されます。テーブルがまだ存在しない場合は、新しいテーブルが作成されます。
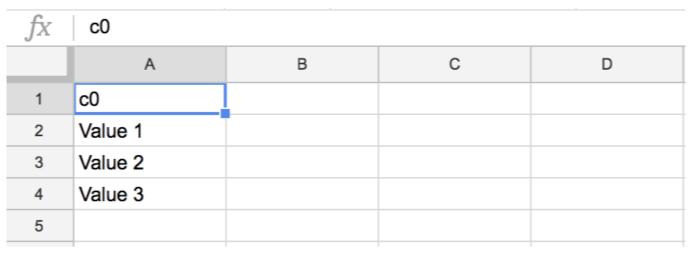
以下は、truncateモードを実行する前のテーブル値の例です。
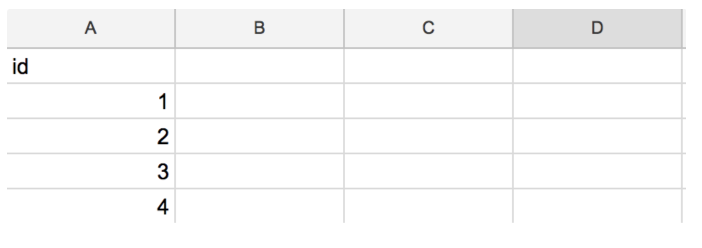
以下は、truncateモードを実行した後、idカラムにクエリ結果が入ったテーブル値の例です。
テーブルがすでに存在する場合、既存の行がクエリ結果によってテーブル内で更新されます。テーブルがまだ存在しない場合は、新しいテーブルが作成されます。
以下は、updateモードを実行する前のテーブル値の例です。
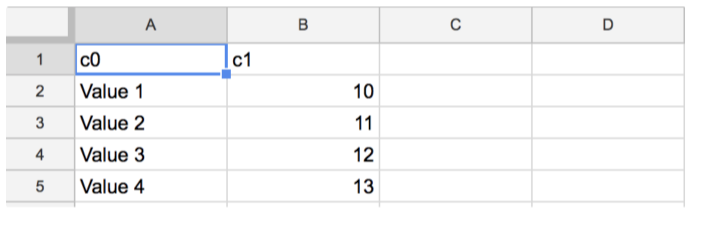
以下は、updateモードを実行した後のテーブル値の例です。範囲A1から、カラムが更新されます。
Scheduled Jobs と Result Export を使用して、指定したターゲット宛先に出力結果を定期的に書き込むことができます。
Treasure Data のスケジューラー機能は、高可用性を実現するために定期的なクエリ実行をサポートしています。
2 つの仕様が競合するスケジュール仕様を提供する場合、より頻繁に実行するよう要求する仕様が優先され、もう一方のスケジュール仕様は無視されます。
例えば、cron スケジュールが '0 0 1 * 1' の場合、「月の日」の仕様と「週の曜日」が矛盾します。前者の仕様は毎月 1 日の午前 0 時 (00:00) に実行することを要求し、後者の仕様は毎週月曜日の午前 0 時 (00:00) に実行することを要求するためです。後者の仕様が優先されます。
Data Workbench > Queries に移動します
新しいクエリを作成するか、既存のクエリを選択します。
Schedule の横にある None を選択します。

ドロップダウンで、次のスケジュールオプションのいずれかを選択します:
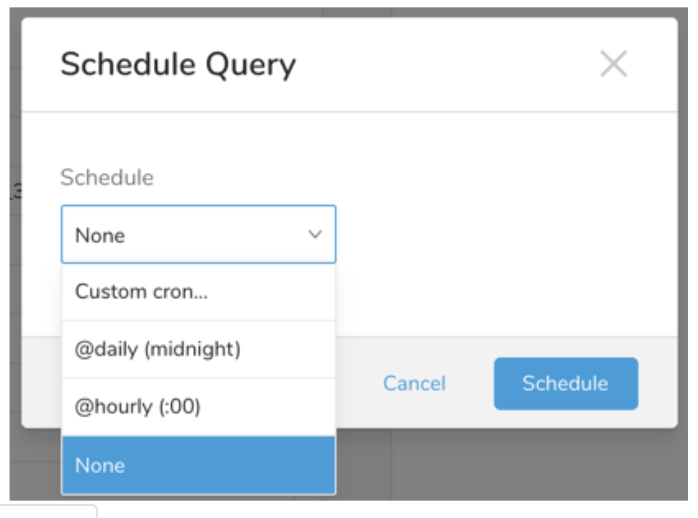
ドロップダウン値 説明 Custom cron... Custom cron... の詳細を参照してください。 @daily (midnight) 指定されたタイムゾーンで 1 日 1 回午前 0 時 (00:00 am) に実行します。 @hourly (:00) 毎時 00 分に実行します。 None スケジュールなし。
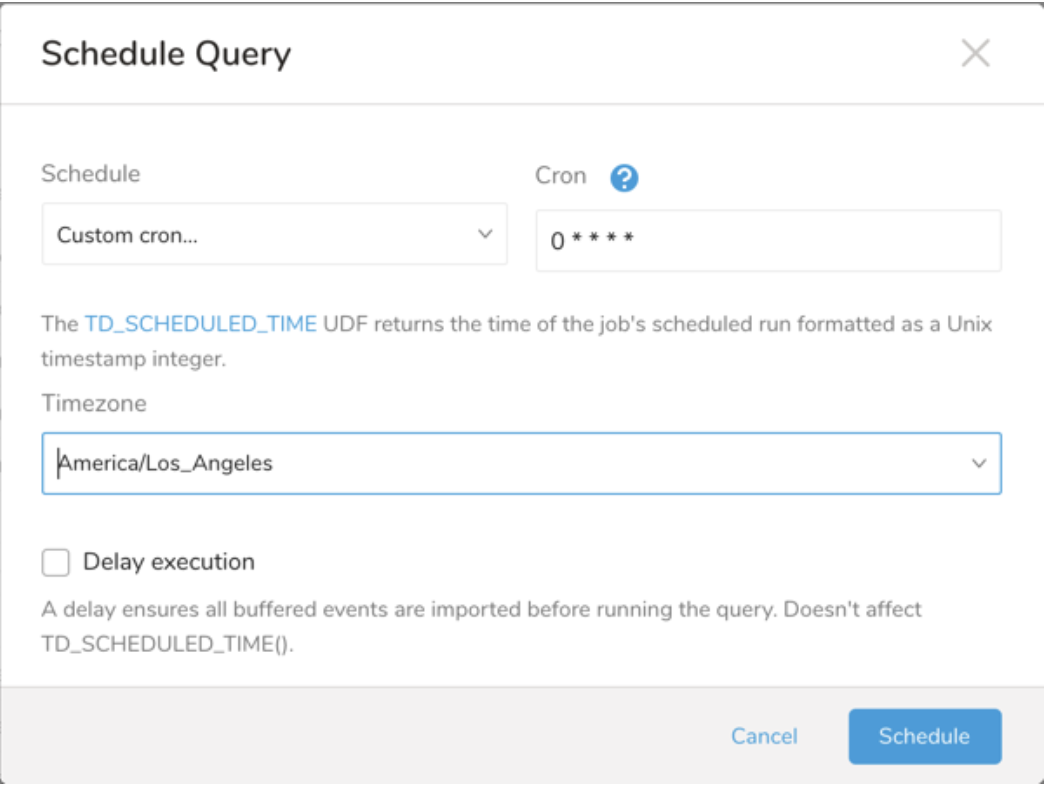
| Cron 値 | 説明 |
|---|---|
0 * * * * | 1 時間に 1 回実行します。 |
0 0 * * * | 1 日 1 回午前 0 時に実行します。 |
0 0 1 * * | 毎月 1 日の午前 0 時に 1 回実行します。 |
| "" | スケジュールされた実行時刻のないジョブを作成します。 |
* * * * *
- - - - -
| | | | |
| | | | +----- day of week (0 - 6) (Sunday=0)
| | | +---------- month (1 - 12)
| | +--------------- day of month (1 - 31)
| +-------------------- hour (0 - 23)
+------------------------- min (0 - 59)次の名前付きエントリを使用できます:
- Day of Week: sun, mon, tue, wed, thu, fri, sat.
- Month: jan, feb, mar, apr, may, jun, jul, aug, sep, oct, nov, dec.
各フィールド間には単一のスペースが必要です。各フィールドの値は、次のもので構成できます:
| フィールド値 | 例 | 例の説明 |
|---|---|---|
| 各フィールドに対して上記で表示された制限内の単一の値。 | ||
フィールドに基づく制限がないことを示すワイルドカード '*'。 | '0 0 1 * *' | 毎月 1 日の午前 0 時 (00:00) に実行するようにスケジュールを設定します。 |
範囲 '2-5' フィールドの許可される値の範囲を示します。 | '0 0 1-10 * *' | 毎月 1 日から 10 日までの午前 0 時 (00:00) に実行するようにスケジュールを設定します。 |
カンマ区切りの値のリスト '2,3,4,5' フィールドの許可される値のリストを示します。 | 0 0 1,11,21 * *' | 毎月 1 日、11 日、21 日の午前 0 時 (00:00) に実行するようにスケジュールを設定します。 |
周期性インジケータ '*/5' フィールドの有効な値の範囲に基づいて、 スケジュールが実行を許可される頻度を表現します。 | '30 */2 1 * *' | 毎月 1 日、00:30 から 2 時間ごとに実行するようにスケジュールを設定します。 '0 0 */5 * *' は、毎月 5 日から 5 日ごとに午前 0 時 (00:00) に実行するようにスケジュールを設定します。 |
'*' ワイルドカードを除く上記の いずれかのカンマ区切りリストもサポートされています '2,*/5,8-10' | '0 0 5,*/10,25 * *' | 毎月 5 日、10 日、20 日、25 日の午前 0 時 (00:00) に実行するようにスケジュールを設定します。 |
- (オプション) Delay execution を有効にすることで、クエリの開始時刻を遅延させることができます。
クエリに名前を付けて保存して実行するか、単にクエリを実行します。クエリが正常に完了すると、クエリ結果は指定された宛先に自動的にエクスポートされます。
設定エラーにより継続的に失敗するスケジュールジョブは、複数回通知された後、システム側で無効化される場合があります。
(オプション) Delay execution を有効にすることで、クエリの開始時刻を遅延させることができます。
Treasure Workflow内で、このデータコネクタを使用してデータを出力するように指定できます。
使用可能なパラメータは次のとおりです。
- spreadsheet_id: String。Spreadsheetキー。必須。
- spreadsheet_title: String。Spreadsheet名。必須。
- spreadsheet_folder: String。デフォルトはnull。フォルダID。
- sheet_title: String。デフォルトはnull。Worksheet名。
- mode: String(append|replace|truncate|update)。デフォルトはappend。
- range: String。デフォルトはA1で、シートの左上隅。rangeはAPPENDモードでは効果がありません。これは、新しい行が最後の行の後に追加されるためです。
- rows_threshold: Integer。デフォルトは50000、最大は2000000。Google APIは各リクエストペイロードに対して10MBの閾値があります。このデータコネクタは、どちらの閾値に先に到達するかを自動的に検出します。
- value_input_option: String
(RAW, USER_ENTERED)。デフォルトはRAW。 - set_nil_for_double_nan: デフォルトはtrue。例えば、NaNを空文字列に変換します。
spreadsheet_idまたはspreadsheet_titleを選択してください。
timezone: UTC
_export:
td:
database: sample_datasets
+td-result-into-target:
td>: queries/sample.sql
result_connection: my_googlesheet_connector
result_settings:
spreadsheet_title: value1
mode: replace
....Treasure Workflow内で、このデータコネクタを使用してデータをエクスポートするように指定できます。
詳細については、Exporting Data with Parametersを参照してください。