Treasure DataからGoogle Driveにジョブ結果を直接エクスポートし、Google Driveでデータをさらに分析、共有して、重要なビジネスインサイトを明らかにすることができます。
Google Driveにジョブ結果をエクスポートするサンプルワークフローについては、Treasure Boxesをご覧ください。
- TD Toolbeltを含むTreasure Dataの基礎知識。
- Googleアカウント(Google Drive用)。
- 認可されたTreasure Dataアカウントアクセス。
次のように、アクセスURLからGoogle Driveフォルダキーを取得できます。

セキュリティポリシーで IP ホワイトリストが必要な場合は、接続を成功させるために Treasure Data の IP アドレスを許可リストに追加する必要があります。
リージョンごとに整理された静的 IP アドレスの完全なリストは、次のリンクにあります: https://api-docs.treasuredata.com/en/overview/ip-addresses-integrations-result-workers/
クエリを実行する前に、エクスポートデータ接続を作成して設定する必要があります。データ接続の一部として、統合にアクセスするための認証を提供します。
Integrations Hub > Catalogに移動します。
Google Driveを検索して選択します。

Authenticationダイアログが開きます。
既存のOAuth接続を選択するか、新しい接続を作成して接続を認証します。
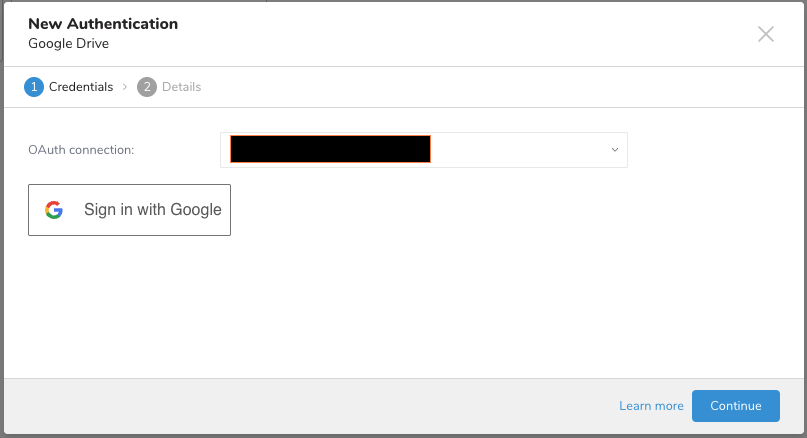
新しいGoogle Drive接続の名前を選択します。
Treasure Data Google Drive統合へのアクセスには、OAuth2認証が必要です。認証には、Treasure DataアカウントをそれぞれのGoogleアカウントに接続する必要があります。
既存の接続がない場合は、新しい認証を作成します。
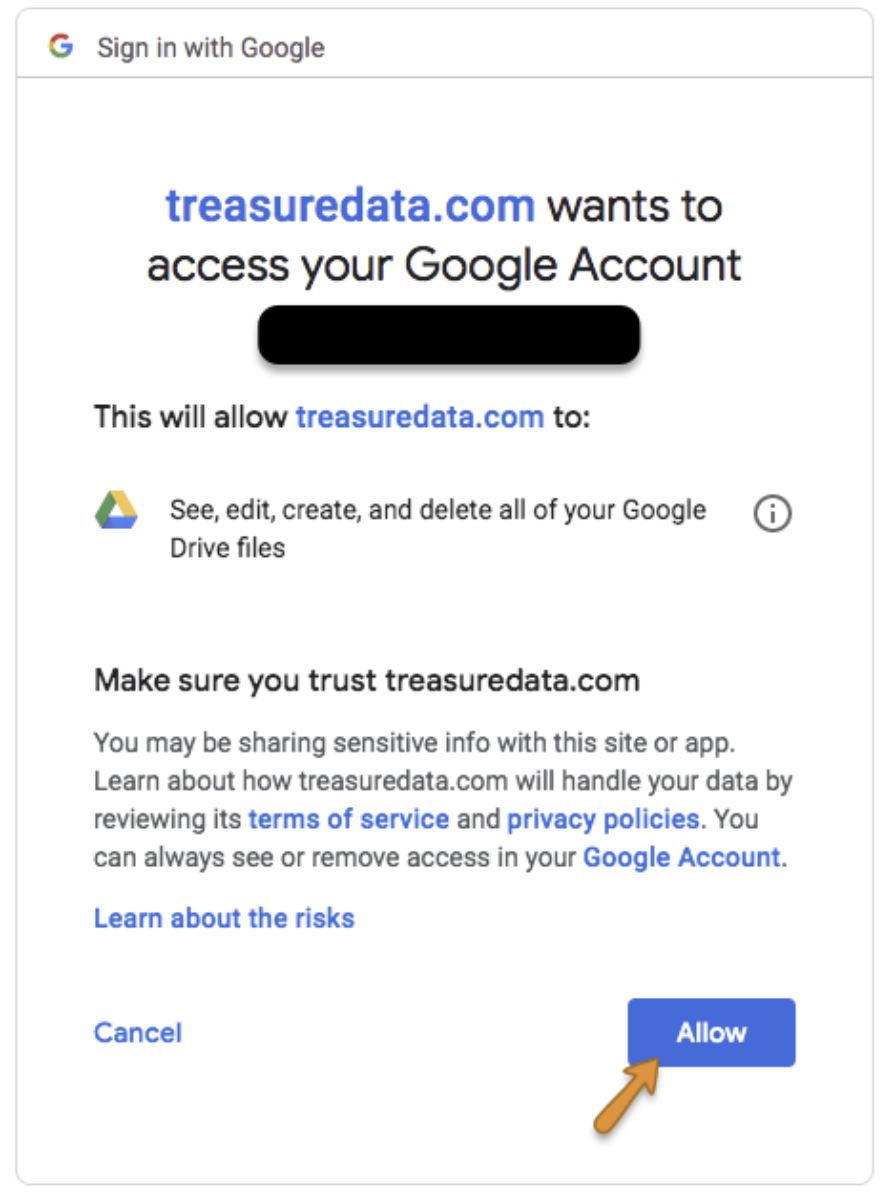
認証ダイアログを開いた後、「Sign in with Google」の下にあるリンクを選択して新しい接続を作成します。
ポップアップウィンドウでGoogle Driveアカウントにログインし、Treasure Dataアプリへのアクセスを許可します。
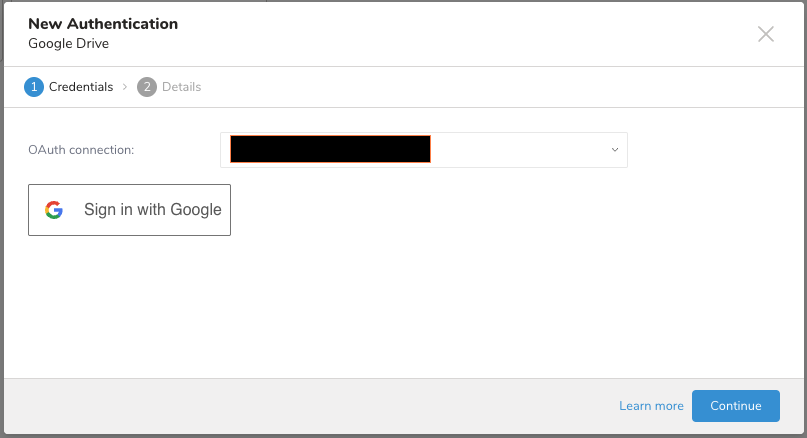
統合ダイアログペインにリダイレクトされます。Google Sheetsを選択してから、ドロップダウンメニューから新しい接続を選択します。
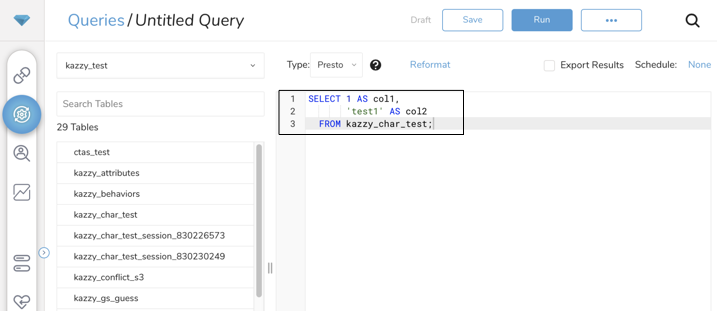
- Data Workbench > Queriesに移動します。
- New Queryを選択します。
- クエリを実行して結果セットを検証します。
Data Workbench > Queriesに移動します。
既存のクエリを選択するか、新しいクエリを作成します。
クエリエディタで、Export Resultsチェックボックスを選択します。

Google Drive接続を選択します。
Export Resultsダイアログパネルが開きます。次のパラメータを編集します。
次の表は、Google Driveエクスポート用に設定できるパラメータを説明しています。
| Parameters | Required? | Description |
|---|---|---|
| File Name | Yes | アップロードするファイルの名前。 |
| Duplication Option | No | 次のいずれか:
|
| Folder ID | No | 親フォルダのID。空の場合はドライブのルートフォルダが使用されます。 |
| Create New Folder | No | デフォルトはfalseです。新しいフォルダの作成が必要な場合はチェックします。 |
| New Folder Name | Conditionally required | Create New Folderがチェックされている場合に必要です。 |
| Format | No | csv、tsvのいずれか。デフォルトはcsvです。 |
csv、tsvフォーマッタとエンコーダのパラメータについては、CSV Formatter & Encoderを参照してください。
セグメントデータまたはステージをエクスポートするActivationを作成できます。
Product DocumentationポータルでActivationを作成する手順については、Creating an Activationを参照してください。
SELECT * FROM [table]Scheduled Jobs と Result Export を使用して、指定したターゲット宛先に出力結果を定期的に書き込むことができます。
Treasure Data のスケジューラー機能は、高可用性を実現するために定期的なクエリ実行をサポートしています。
2 つの仕様が競合するスケジュール仕様を提供する場合、より頻繁に実行するよう要求する仕様が優先され、もう一方のスケジュール仕様は無視されます。
例えば、cron スケジュールが '0 0 1 * 1' の場合、「月の日」の仕様と「週の曜日」が矛盾します。前者の仕様は毎月 1 日の午前 0 時 (00:00) に実行することを要求し、後者の仕様は毎週月曜日の午前 0 時 (00:00) に実行することを要求するためです。後者の仕様が優先されます。
Data Workbench > Queries に移動します
新しいクエリを作成するか、既存のクエリを選択します。
Schedule の横にある None を選択します。

ドロップダウンで、次のスケジュールオプションのいずれかを選択します:
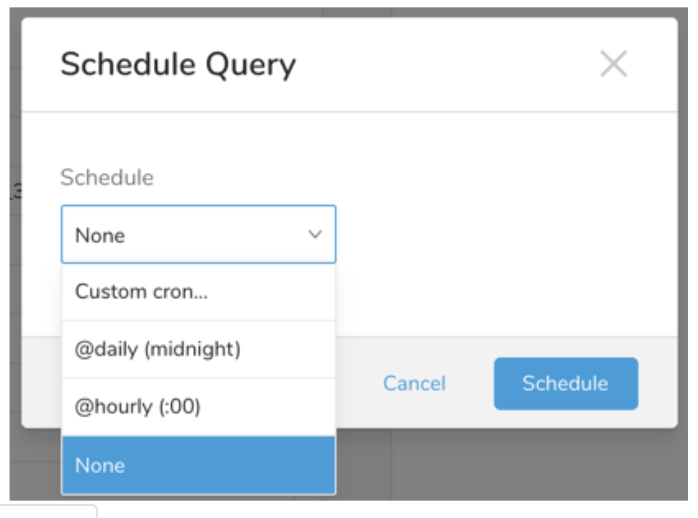
ドロップダウン値 説明 Custom cron... Custom cron... の詳細を参照してください。 @daily (midnight) 指定されたタイムゾーンで 1 日 1 回午前 0 時 (00:00 am) に実行します。 @hourly (:00) 毎時 00 分に実行します。 None スケジュールなし。
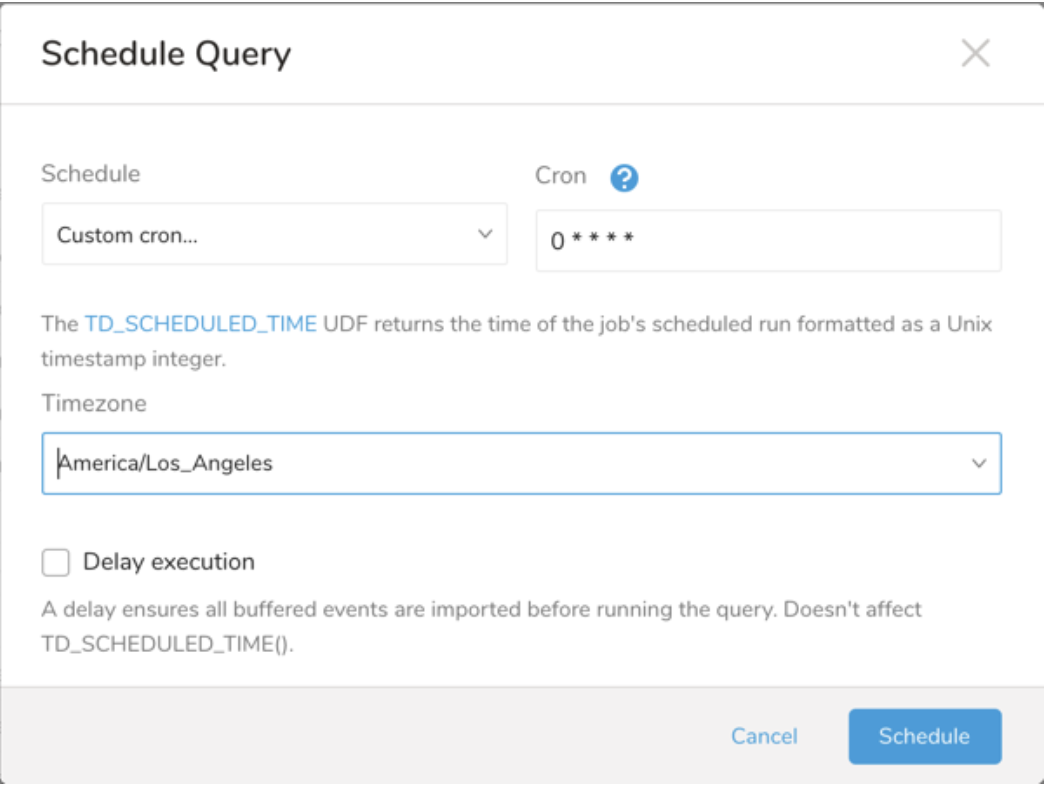
| Cron 値 | 説明 |
|---|---|
0 * * * * | 1 時間に 1 回実行します。 |
0 0 * * * | 1 日 1 回午前 0 時に実行します。 |
0 0 1 * * | 毎月 1 日の午前 0 時に 1 回実行します。 |
| "" | スケジュールされた実行時刻のないジョブを作成します。 |
* * * * *
- - - - -
| | | | |
| | | | +----- day of week (0 - 6) (Sunday=0)
| | | +---------- month (1 - 12)
| | +--------------- day of month (1 - 31)
| +-------------------- hour (0 - 23)
+------------------------- min (0 - 59)次の名前付きエントリを使用できます:
- Day of Week: sun, mon, tue, wed, thu, fri, sat.
- Month: jan, feb, mar, apr, may, jun, jul, aug, sep, oct, nov, dec.
各フィールド間には単一のスペースが必要です。各フィールドの値は、次のもので構成できます:
| フィールド値 | 例 | 例の説明 |
|---|---|---|
| 各フィールドに対して上記で表示された制限内の単一の値。 | ||
フィールドに基づく制限がないことを示すワイルドカード '*'。 | '0 0 1 * *' | 毎月 1 日の午前 0 時 (00:00) に実行するようにスケジュールを設定します。 |
範囲 '2-5' フィールドの許可される値の範囲を示します。 | '0 0 1-10 * *' | 毎月 1 日から 10 日までの午前 0 時 (00:00) に実行するようにスケジュールを設定します。 |
カンマ区切りの値のリスト '2,3,4,5' フィールドの許可される値のリストを示します。 | 0 0 1,11,21 * *' | 毎月 1 日、11 日、21 日の午前 0 時 (00:00) に実行するようにスケジュールを設定します。 |
周期性インジケータ '*/5' フィールドの有効な値の範囲に基づいて、 スケジュールが実行を許可される頻度を表現します。 | '30 */2 1 * *' | 毎月 1 日、00:30 から 2 時間ごとに実行するようにスケジュールを設定します。 '0 0 */5 * *' は、毎月 5 日から 5 日ごとに午前 0 時 (00:00) に実行するようにスケジュールを設定します。 |
'*' ワイルドカードを除く上記の いずれかのカンマ区切りリストもサポートされています '2,*/5,8-10' | '0 0 5,*/10,25 * *' | 毎月 5 日、10 日、20 日、25 日の午前 0 時 (00:00) に実行するようにスケジュールを設定します。 |
- (オプション) Delay execution を有効にすることで、クエリの開始時刻を遅延させることができます。
クエリに名前を付けて保存して実行するか、単にクエリを実行します。クエリが正常に完了すると、クエリ結果は指定された宛先に自動的にエクスポートされます。
設定エラーにより継続的に失敗するスケジュールジョブは、複数回通知された後、システム側で無効化される場合があります。
(オプション) Delay execution を有効にすることで、クエリの開始時刻を遅延させることができます。
Audience Studio で activation を作成することで、segment データをターゲットプラットフォームに送信することもできます。
- Audience Studio に移動します。
- parent segment を選択します。
- ターゲット segment を開き、右クリックして、Create Activation を選択します。
- Details パネルで、Activation 名を入力し、前述の Configuration Parameters のセクションに従って activation を設定します。
- Output Mapping パネルで activation 出力をカスタマイズします。

- Attribute Columns
- Export All Columns を選択すると、変更を加えずにすべての列をエクスポートできます。
- + Add Columns を選択して、エクスポート用の特定の列を追加します。Output Column Name には、Source 列名と同じ名前があらかじめ入力されます。Output Column Name を更新できます。+ Add Columns を選択し続けて、activation 出力用の新しい列を追加します。
- String Builder
- + Add string を選択して、エクスポート用の文字列を作成します。次の値から選択します:
- String: 任意の値を選択します。テキストを使用してカスタム値を作成します。
- Timestamp: エクスポートの日時。
- Segment Id: segment ID 番号。
- Segment Name: segment 名。
- Audience Id: parent segment 番号。
- + Add string を選択して、エクスポート用の文字列を作成します。次の値から選択します:
- Schedule を設定します。

- スケジュールを定義する値を選択し、オプションでメール通知を含めます。
- Create を選択します。
batch journey の activation を作成する必要がある場合は、Creating a Batch Journey Activation を参照してください。
Treasure Workflow内で、このデータコネクタを使用してデータをエクスポートすることを指定できます。
詳細については、Using Workflows to Export Data with the TD Toolbeltを参照してください。
TD Toolbeltを使用して、CLIからGoogle Driveへのクエリ結果のエクスポートをトリガーできます。td queryコマンドの--resultオプションを使用して、エクスポートジョブのパラメータを指定する必要があります。詳細については、Querying and Importing Data to Treasure Data from the Command Lineを参照してください。
td query --database your_database --result configuration query次の表は、設定キーとその説明を示しています。
| Config Key | Type | Required | Description |
|---|---|---|---|
| type | string | yes | エクスポートタイプ: google_drive |
| file_name | string | yes | アップロードするファイルの名前。 |
duplicate_option | string | yes | allow_duplication、replace、append_datetimeのいずれか |
folder_id | string | No | 親フォルダのID。空の場合はドライブのルートフォルダが使用されます。 |
create_new_folder | boolean | No | デフォルトはfalseです。新しいフォルダの作成が必要な場合はチェックします。 |
new_folder_name | string | No | Create New Folderがチェックされている場合に必要です。 |
format | string | No | csv、tsvのいずれか。デフォルトはcsvです。 |
skip_invalid_records | boolean | No | trueに設定すると、無効なレコードをスキップし、有効なレコードのアップロードを続行します。 falseに設定すると(デフォルト)、無効なレコードが検出されたときにジョブを終了します。 |
td query --database [database name] --query '[sql query]' --type presto \
--result '{"type":"google_drive","file_name":"[file name]","client_id":"[oauth client id]","client_secret":"[oauth client secret]","refresh_token":"[oauth refresh token]","folder_id": "[parent folder id]","create_new_folder": true,"new_folder_name": "[new folder name]"}';csv、tsv形式を設定するには、https://www.embulk.org/docs/built-in.html#csv-formatter-pluginを参照してください。
エンコーダを設定するには、Encryptio Encoder for Output Pluginを参照してください。