VTEXは、40か国以上の大手ブランドで使用されているeCommerceソリューションです。この統合により、Master Dataを介して顧客情報と、このeCommerceプラットフォームからの注文を取り込むことができます。
この機能はベータ版です。詳細については、カスタマーサクセス担当者にお問い合わせください。
- Treasure Dataの基本的な知識
- VTEX eCommerceプラットフォームの基本的な知識
- 有効なVTEXアカウント
Ordersでは、カスタムフィルタをサポートして、データのカテゴリー化を強化し、ロードごとのデータサイズを削減します。ただし、f_creationDateはFrom DateとTo Dateパラメータから派生するように設計されているため、レスポンスデータの期待される動作を保証するために、Customer Filtersに含めないでください。Ordersをフィルタリングするためにf_creationDateを使用しないでください。
Incremental Loadingを使用すると、ジョブ実行のたびに重複やデータの欠落なしに新しいデータをインポートできます。
暗黙的に、Ordersデータタイプはincremental loadingにcreationDateフィールドを使用します。各実行後、creationDateの最新値が次のジョブ実行の「From Date」として使用されます。
例えば、Ordersのインポートを設定します。
From Date = 2020-10-11T01:43:47.900Z および
To Date = 2020-11-11T01:43:47.900Z
- 最初の実行後、creationDateフィールドの最新値は2020-11-10T08:00:00.000Zです
- 次のジョブ実行は次の値で開始されます: From Date = 2020-11-10T08:00:00.001Z および To Date = 現在の実行時刻
- 以下同様…
次のジョブ実行のためにcreationDateに1ミリ秒が追加されるのは、ジョブ結果のFrom Dateの包含によるものです。
Master Dataは、incremental loadingにIncremental Fieldを使用します。暗黙的に、Master DataのAPIリクエストは、Incremental Fieldの降順で並べ替えられます。例:_sort=creationDate desc。
APIからレスポンスされる最初の値が、次の実行のフィルタパラメータとして使用されます。
例:_where=creationDate>2020-11-11T01:43:47.900Z
例えば、Incremental FieldがcreationDateの場合
- 最初の実行、リクエストURL:https://…./scroll?_sort=creationDate desc
- レスポンスの最初の値はcreationDate=2020-11-11T01:43:47.900Zです
- 次の実行、リクエストURLは次のようになります:https://…./scroll?_sort=creationDate desc&_where=creationDate>2020-11-11T01:43:47.900Z
- 以下同様…
データはIncremental Fieldで並べ替えられるため、フィールドは次の条件を満たす必要があります:
- タイムスタンプまたは数値フィールドである必要があります。
- nullであってはなりません
- インデックス化されたフィールドである必要があります。
Treasure Dataでは、クエリを実行する前にデータ接続を作成および設定する必要があります。データ接続の一部として、統合にアクセスするための認証を提供します。
TD Consoleを開きます。
Integrations Hub > Catalogに移動します。
VTEXを検索して選択します。
次のダイアログが開きます。
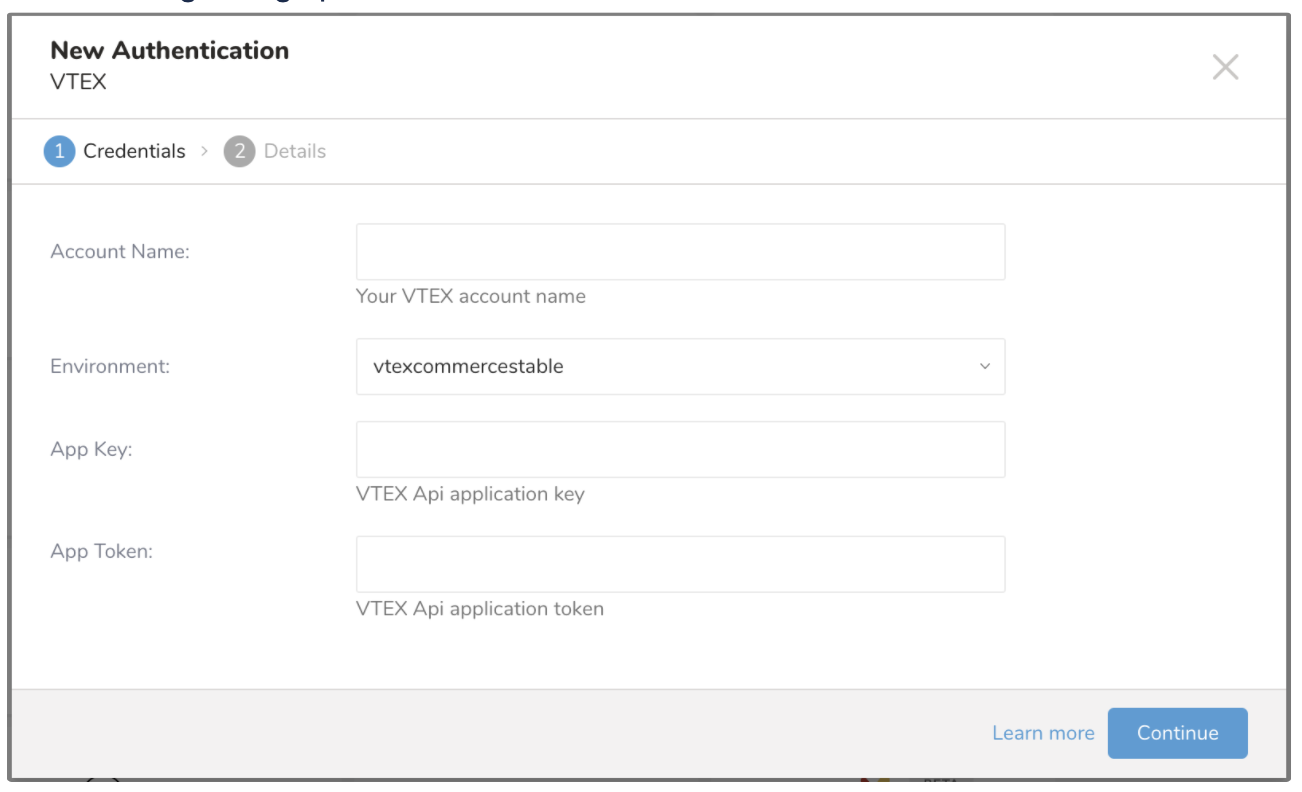
VTEXアカウント名、APP Key、App Tokenを入力し、Environmentを選択します
CONTINUEを選択します。
- 接続の名前を入力します。
- Doneを選択します。
認証された接続を作成すると、自動的にAuthenticationsに移動します。
- 作成した接続を検索します。
- New Sourceを選択します。
Data TransferフィールドにSourceの名前を入力します。
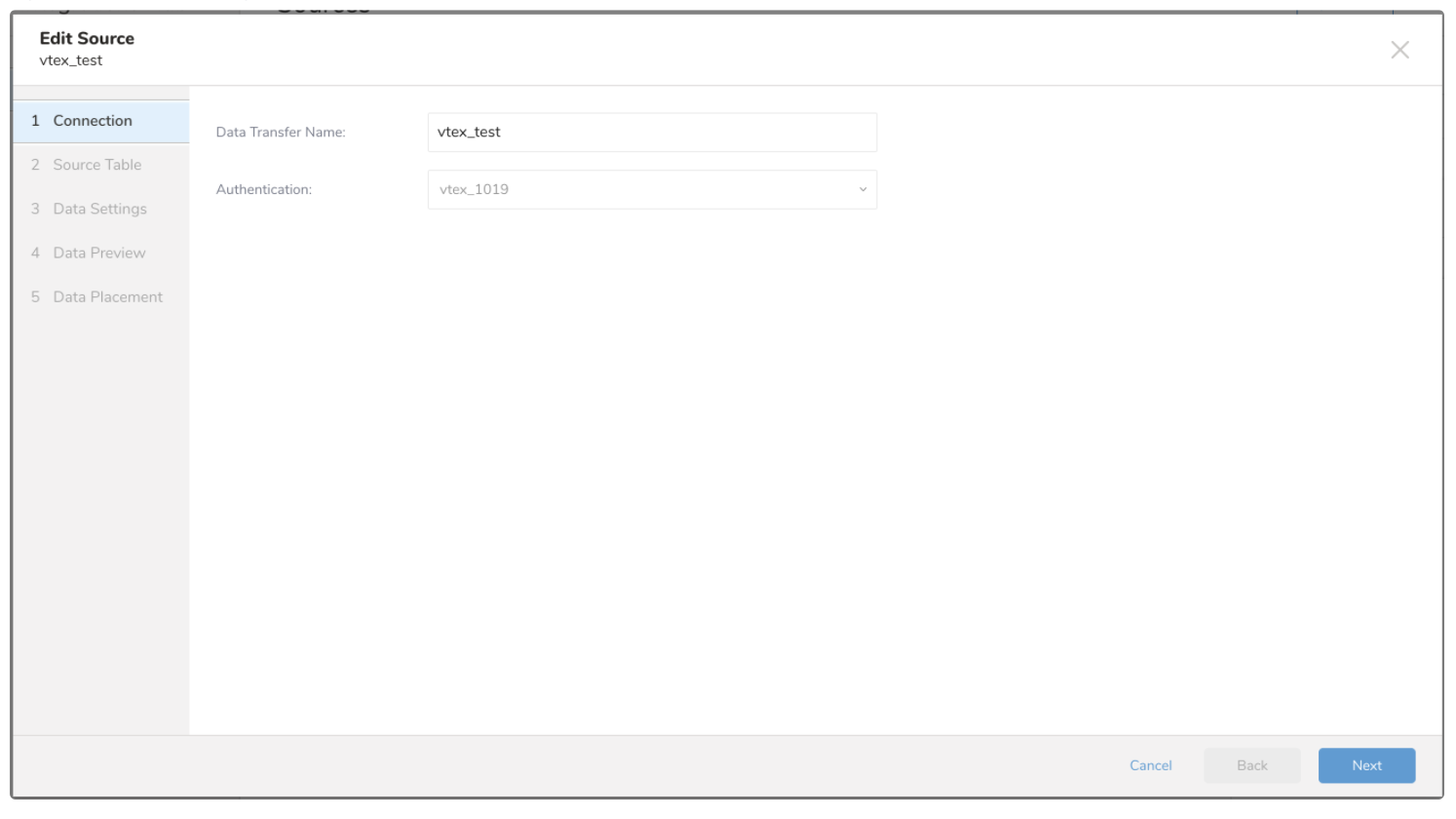
- Nextを選択します。 Source Tableダイアログが開きます。
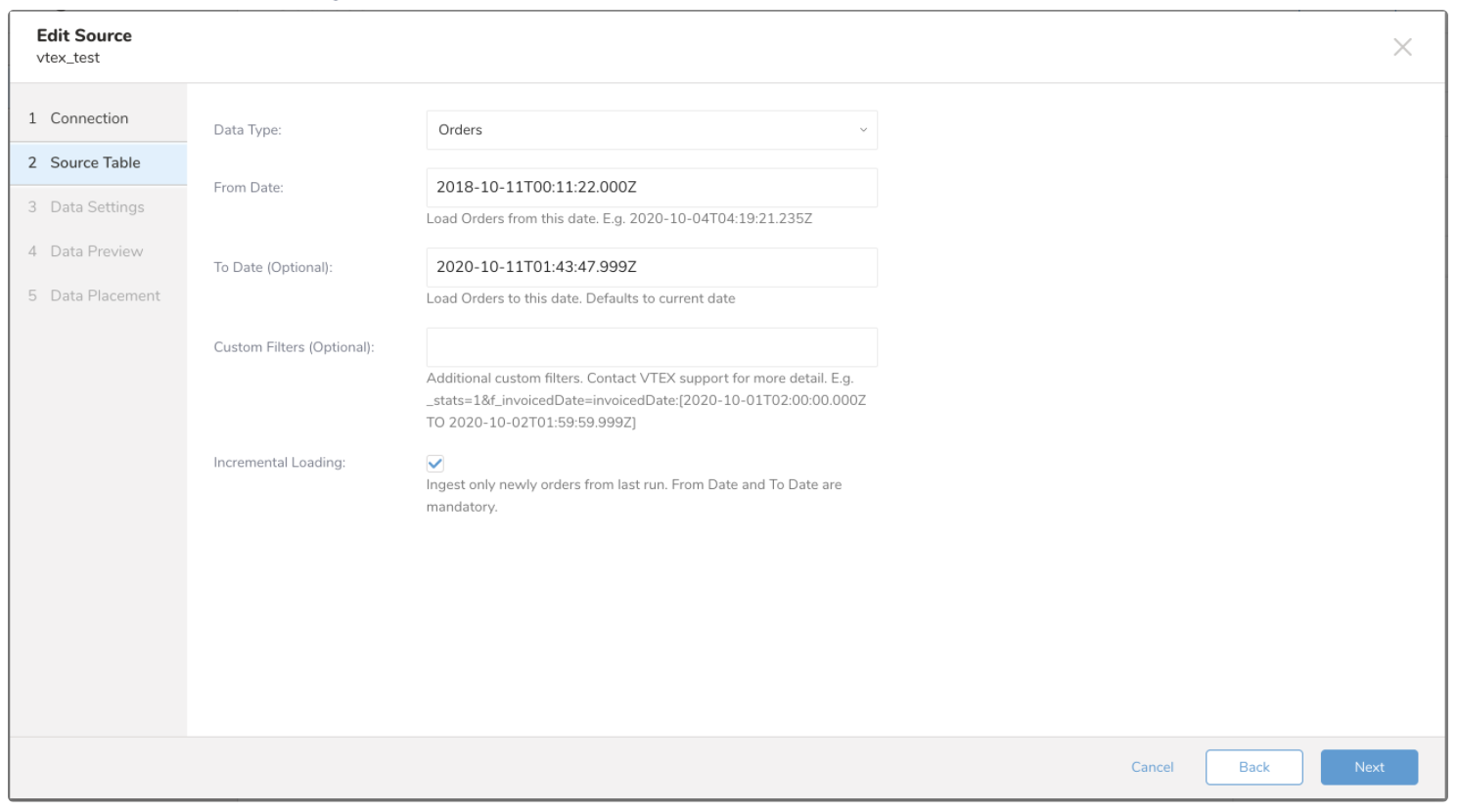
- 次のパラメータを編集します:
| Parameters | Description |
|---|---|
| Data Type | インポートするデータタイプ。選択できます: - Orders - Master Data V2 |
| From Date | この日付からOrdersをロードします。タイムスタンプ形式をサポート:yyyy-MM-dd'T'HH:mm:ss.SSSZ |
| To Date(オプション) | この日付までOrdersをロードします。空白のままにすると、現在の日付までOrdersがインポートされます |
| Custom Filters(オプション) | Ordersインポートの追加カスタムフィルタ。これはList Orders APIリクエストのリクエストパラメータセグメントです。param_name=value形式でサポートされているパラメータを入力できます。例:q=rodrigo.cunha@vtex.com&q=21133355524 |
| Incremental Loading | 前回の実行から新しいデータのみをインポートします。About Incremental Loadingを参照してください |
| Data Entity Acronym | データを取り込むData Entityの略語。例:AL(Address Support用) |
| Filter Condition(オプション) | Master Data _whereパラメータ値。結果値をフィルタリングするために使用します。例:firstName=Jon OR lastName=Smith |
| Keywords(オプション) | Master Data _keywordパラメータ値。このキーワードのみに一致するようにMaster Dataをフィルタリングするために使用します。例:Maria |
| Schema(オプション) | スキーマの互換性によってドキュメントをフィルタリングするMaster Dataスキーマ名 |
| Incremental Field | Master Dataタイプでincremental Loadingを選択した場合、フィールド名を入力する必要があります。フィールドはTimestampまたはNumericフィールドである必要があり、インデックス化されていて、nullであってはなりません。 |
- Nextを選択します。 Data Settingsページが開きます。
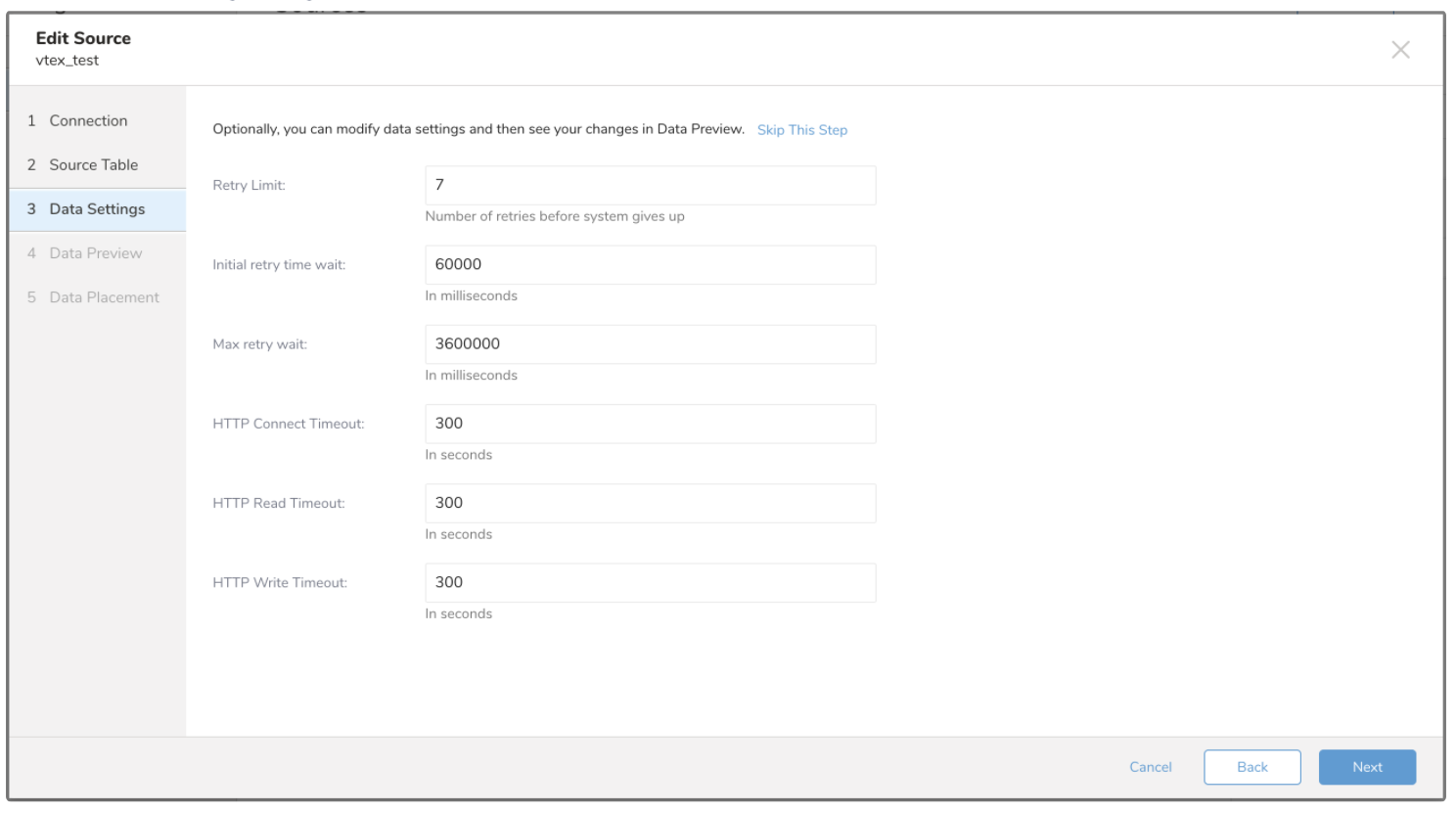
- 必要に応じてデータ設定を編集するか、このページをスキップします。
| Parameters | Description |
| --- | --- | | Retry Limit | 各API呼び出しの最大再試行回数。 | | Initial retry time wait | 最初の再試行の待機時間。 | | Max retry wait | 再試行間の最大時間。 | | HTTP Connect Timeout | API呼び出し時に接続がタイムアウトするまでの時間。 | | HTTP Read Timeout | リクエストへのデータ書き込みを待機する時間。 | | HTTP Write Timeout | レスポンスからのデータ読み取りを待機する時間。 |
インポートを実行する前に、Generate Preview を選択してデータのプレビューを表示できます。Data preview はオプションであり、選択した場合はダイアログの次のページに安全にスキップできます。
- Next を選択します。Data Preview ページが開きます。
- データをプレビューする場合は、Generate Preview を選択します。
- データを確認します。
データの配置について、データを配置したいターゲット database と table を選択し、インポートを実行する頻度を指定します。
Next を選択します。Storage の下で、インポートされたデータを配置する新しい database を作成するか、既存の database を選択し、新しい table を作成するか、既存の table を選択します。
Database を選択 > Select an existing または Create New Database を選択します。
オプションで、database 名を入力します。
Table を選択 > Select an existing または Create New Table を選択します。
オプションで、table 名を入力します。
データをインポートする方法を選択します。
- Append (デフォルト) - データインポートの結果は table に追加されます。 table が存在しない場合は作成されます。
- Always Replace - 既存の table の全体の内容をクエリの結果出力で置き換えます。table が存在しない場合は、新しい table が作成されます。
- Replace on New Data - 新しいデータがある場合のみ、既存の table の全体の内容をクエリの結果出力で置き換えます。
Timestamp-based Partition Key 列を選択します。 デフォルトキーとは異なるパーティションキーシードを設定したい場合は、long または timestamp 列をパーティショニング時刻として指定できます。デフォルトの時刻列として、add_time フィルターで upload_time を使用します。
データストレージの Timezone を選択します。
Schedule の下で、このクエリを実行するタイミングと頻度を選択できます。
- Off を選択します。
- Scheduling Timezone を選択します。
- Create & Run Now を選択します。
- On を選択します。
- Schedule を選択します。UI では、@hourly、@daily、@monthly、またはカスタム cron の 4 つのオプションが提供されます。
- Delay Transfer を選択して、実行時間の遅延を追加することもできます。
- Scheduling Timezone を選択します。
- Create & Run Now を選択します。
転送が実行された後、Data Workbench > Databases で転送の結果を確認できます。