Shopify Import Connector V2—カスタムクエリは、ShopifyのGraphQL Admin APIと連携し、ユーザーが独自の必要なクエリを定義できるように設計されています。Shopify Import Integration V2で以前実装された機能を引き続き開発します。
新しいインポート操作を追加します:
- カスタムクエリインポート
- 4種類のクエリをサポート:
- クエリ - 複数形のオブジェクトからの通常クエリ
- クエリ - 単数形のオブジェクトからの通常クエリ(idなどの必須フィールドによるフィルタが必要)
- 複数形のNODESを使用したクエリ
- 単数形のNODEを使用したクエリ
- Treasure Dataの基本知識
- Shopifyの基本知識
- Metafieldインポートの制限
- 製品ごとに最大250個のmetafield
- 製品バリアントごとに最大250個のmetafield
- Product Variantsのインポートは、created_atタイムスタンプによる増分読み込みをサポートしなくなりました。現在はupdated_atタイムスタンプによる読み込みのみをサポートしています。
セキュリティポリシーで IP ホワイトリストが必要な場合は、接続を成功させるために Treasure Data の IP アドレスを許可リストに追加する必要があります。
リージョンごとに整理された静的 IP アドレスの完全なリストは、次のリンクにあります: https://api-docs.treasuredata.com/en/overview/ip-addresses-integrations-result-workers/
最初のステップは、認証情報のセットで新しい認証を作成することです。
- Integrations Hubを選択します。
- Catalogを選択します。
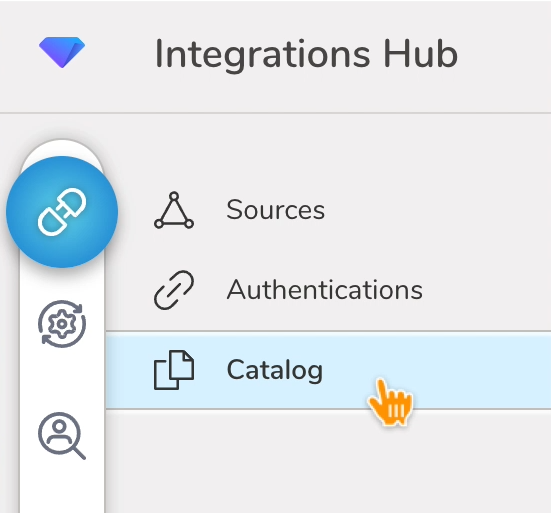 3. CatalogでShopifyを検索し、アイコンの上にマウスを置いてCreate Authenticationを選択します。
3. CatalogでShopifyを検索し、アイコンの上にマウスを置いてCreate Authenticationを選択します。


- Credentialsタブが選択されていることを確認し、統合の認証情報を入力します。
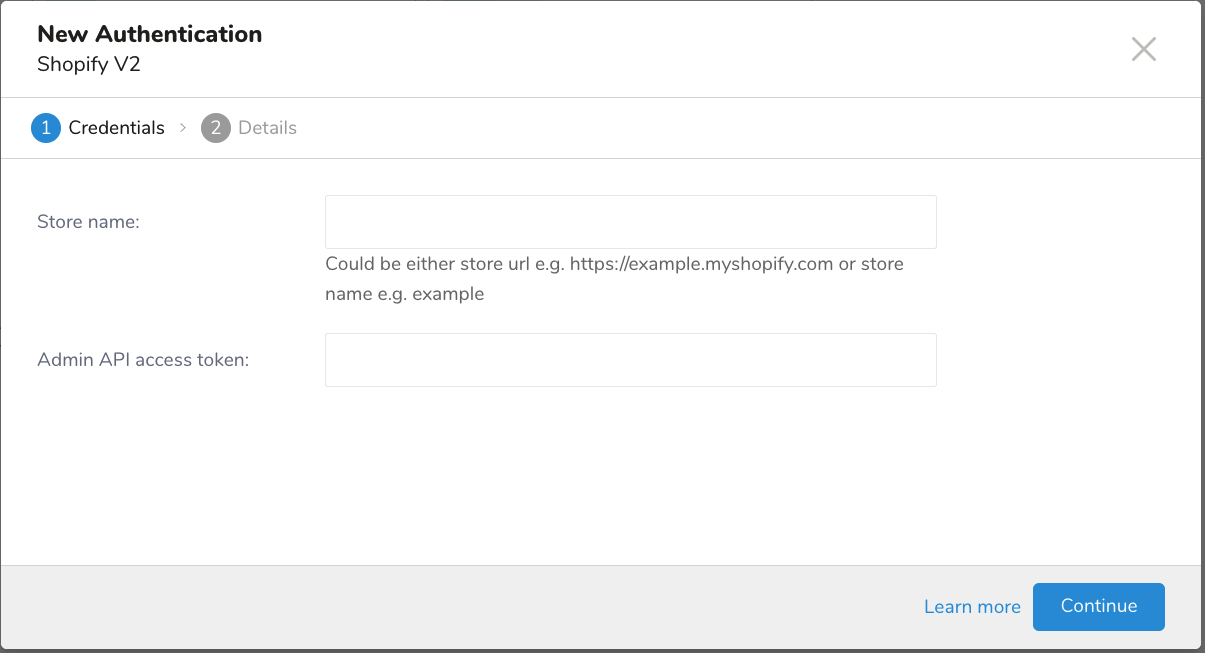
新しい認証フィールド
| パラメータ | 説明 |
|---|---|
| Store name | Shopifyストアのストア識別子。これは2つの形式で入力できます:- 完全なストアURL:例 https://mountbaker.myshopify.com - ストア名のみ:例:mountbakerストア名のみを使用する場合は、.myshopify.comドメインを除いたストアの一意の識別子である必要があります。 |
| Admin API access token | ShopifyのAdmin APIで認証するために使用されるアクセストークン。このトークンは、Apps > Develop apps > Create an app > Configure Admin API scopesからShopify管理パネルで生成できます。トークンには、metafieldの管理などの操作を実行するための適切な権限が必要です。 |
- Continueを選択します。
- 認証の名前を入力し、Doneを選択します。
認証がコンソールで使用可能になったら、インポートジョブを設定します。
- TDコンソールを開きます。
- Integrations Hub > Authenticationsに移動します。
- Shopify認証を見つけて、New Sourceを選択します。
- Data Transfer Nameフィールドにソース名を入力します。
- Nextを選択します。
| パラメータ | 説明 |
|---|---|
| Data Transfer Name | 転送の名前を入力します。 |
| Authentication | このフィールドには、Shopifyとの接続に使用される認証の名前が含まれます。 |
- ソーステーブルのフィールドを設定します
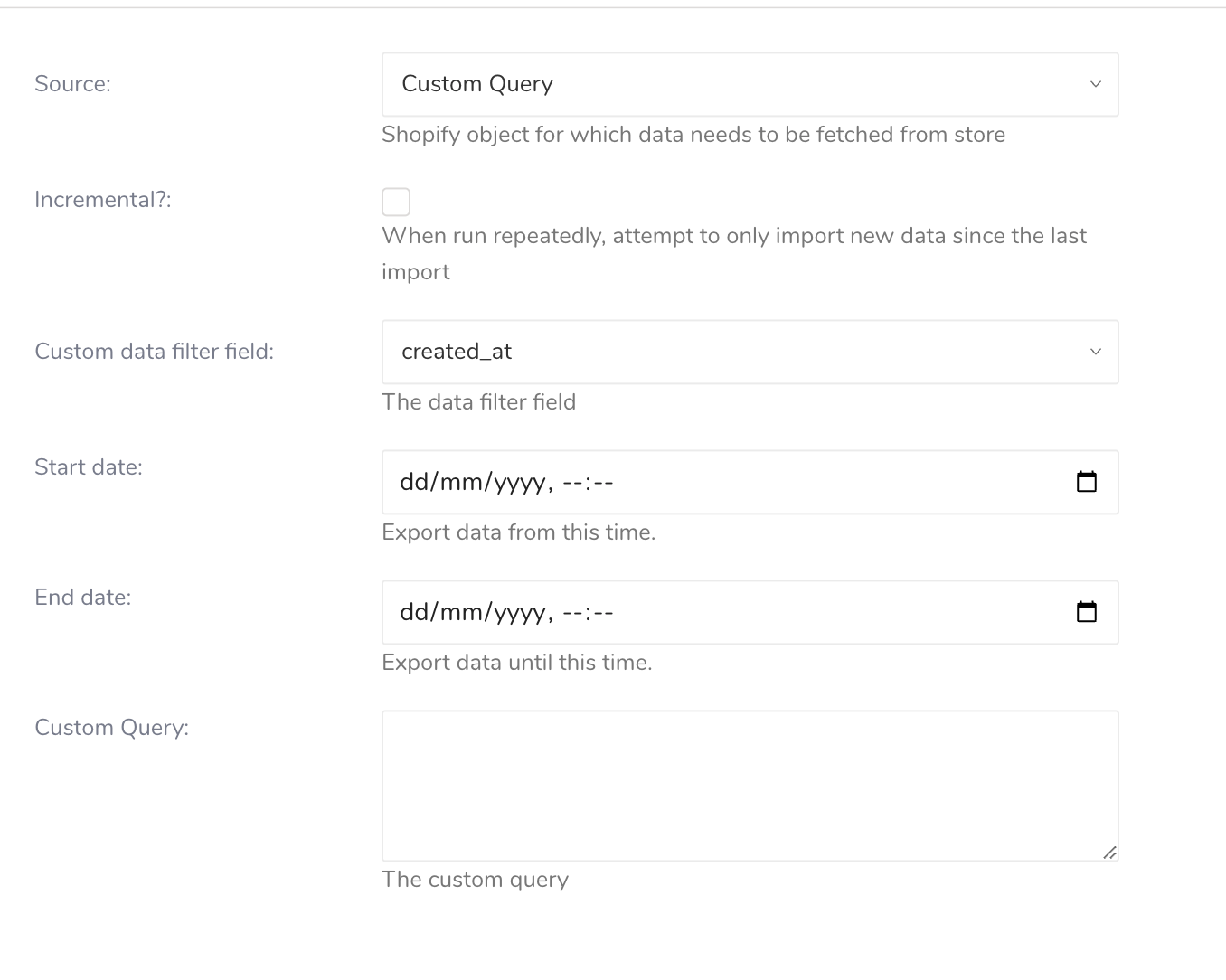
| Field | Description |
|---|---|
Source | 次のShopifyオブジェクトを含むドロップダウンメニュー:
Shopifyストアからインポートするデータを含むShopifyオブジェクトを選択します。 |
| Incremental? | 有効にすると、コネクタは最後のインポート実行以降の新しいデータまたは更新されたデータのみをインポートし、後続のインポートがより効率的になります。 |
| Incremental field | 増分読み込みに使用するタイムスタンプを選択します:
|
| Custom data filter field | データフィルタに使用するタイムスタンプを選択します。Custom Queryソースでは、定義されたカスタムクエリで{{date_filter}}を使用してデータをフィルタすることをサポートしています:
|
| Start date | データのエクスポートを開始する開始タイムスタンプ(形式:dd/mm/yyyy, hh:mm) |
| End date | データのエクスポートを終了する終了タイムスタンプ(形式:dd/mm/yyyy, hh:mm)。空白のままにすると、終了日は現在時刻になります。 |
| Custom Query | ユーザー独自のカスタムクエリを設計します。2つのプレースホルダーオプションを使用できます:
|
- Nextを選択します。
- データ設定を構成します。
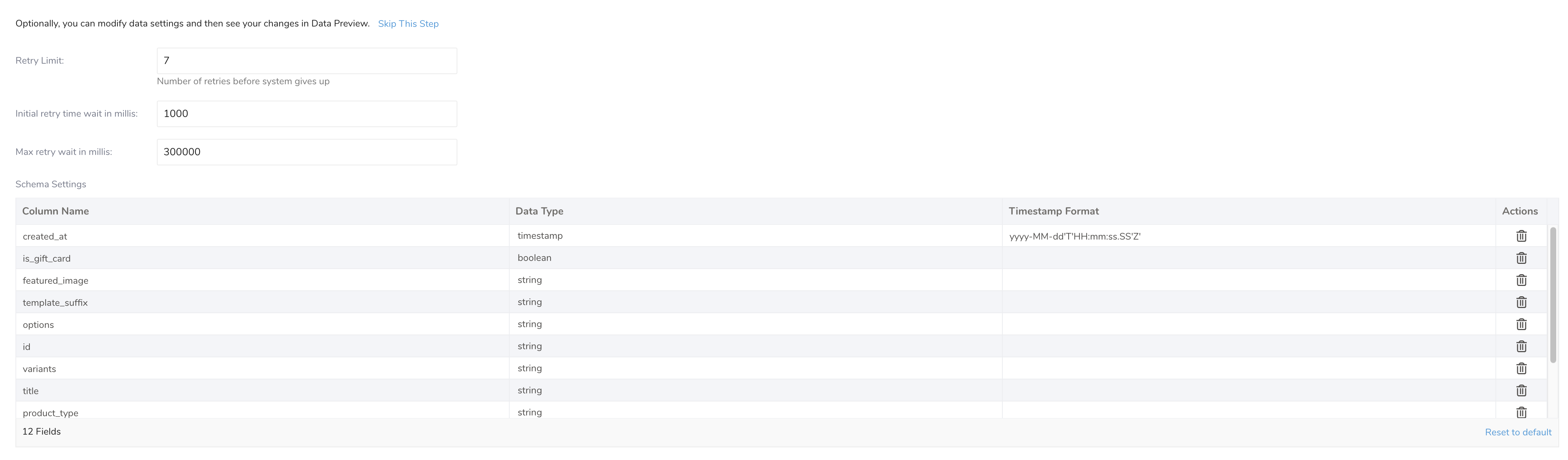
| パラメータ | 説明 |
|---|---|
| Retry Limit | インポートが失敗するまでの再試行回数。 |
| Initial retry time wait in millis | 再試行する前に待機する初期時間(ミリ秒単位)。 |
| Max retry wait in millis | 再試行する前に待機する最大時間(ミリ秒単位)。 |
| Schema Settings | スキーマはサンプルデータから推測されました。PREVIEWとRUNの前にタイプと形式を変更できます。 |
- 注意:
- JSONフィールドのトップレベル1のみをサポートします。JSONオブジェクトのキーと値のペアの解析はサポートしていません。
- データを取得するには、JSONフィールドをstringからJSONデータタイプに変更することを忘れないでください。通常、推測されたフィールドデータタイプはstringです。
- 必要がない場合は、フィールド名を変更しないでください。
- カスタムクエリで何かを変更した後は、スキーマ設定を再度確認して編集する必要があります。
インポートを実行する前に、Generate Preview を選択してデータのプレビューを表示できます。Data preview はオプションであり、選択した場合はダイアログの次のページに安全にスキップできます。
- Next を選択します。Data Preview ページが開きます。
- データをプレビューする場合は、Generate Preview を選択します。
- データを確認します。
データの配置について、データを配置したいターゲット database と table を選択し、インポートを実行する頻度を指定します。
Next を選択します。Storage の下で、インポートされたデータを配置する新しい database を作成するか、既存の database を選択し、新しい table を作成するか、既存の table を選択します。
Database を選択 > Select an existing または Create New Database を選択します。
オプションで、database 名を入力します。
Table を選択 > Select an existing または Create New Table を選択します。
オプションで、table 名を入力します。
データをインポートする方法を選択します。
- Append (デフォルト) - データインポートの結果は table に追加されます。 table が存在しない場合は作成されます。
- Always Replace - 既存の table の全体の内容をクエリの結果出力で置き換えます。table が存在しない場合は、新しい table が作成されます。
- Replace on New Data - 新しいデータがある場合のみ、既存の table の全体の内容をクエリの結果出力で置き換えます。
Timestamp-based Partition Key 列を選択します。 デフォルトキーとは異なるパーティションキーシードを設定したい場合は、long または timestamp 列をパーティショニング時刻として指定できます。デフォルトの時刻列として、add_time フィルターで upload_time を使用します。
データストレージの Timezone を選択します。
Schedule の下で、このクエリを実行するタイミングと頻度を選択できます。
- Off を選択します。
- Scheduling Timezone を選択します。
- Create & Run Now を選択します。
- On を選択します。
- Schedule を選択します。UI では、@hourly、@daily、@monthly、またはカスタム cron の 4 つのオプションが提供されます。
- Delay Transfer を選択して、実行時間の遅延を追加することもできます。
- Scheduling Timezone を選択します。
- Create & Run Now を選択します。
転送が実行された後、Data Workbench > Databases で転送の結果を確認できます。
td_load>: src_idを使用してワークフロー経由でShopifyレポートからデータをインポートできます。既にソースを作成している場合は実行できます。ソースを作成したくない場合は、.ymlファイルを使用してインポートできます。
- Integrations Hub>Sourcesを選択します。
- 画面の右端のFiltersペインで、Integration Typeドロップダウンメニューを使用してShopify V2を選択します。
- Sourcesペインで、使用するソースを含む行を識別し、その行のmore(•••アイコン)ドロップダウンメニューを使用してCopy Unique IDを選択します。
- ワークフロータスクを定義し、td_load>:にステップ3でコピーしたIDを使用します。
+load:
td_load>: unique_id_of_your_source
database: ${td.dest_db}
table: ${td.dest_table}- ワークフローを実行します。
- .ymlファイルを識別します。
.ymlファイルを作成する必要がある場合は、Create Seed Config File (seed.yml)に記載されている手順を参照してください。 2. ワークフロータスクを定義し、td_load>: に.ymlファイルを指定します。
+load:
td_load>: config/daily_load.yml
database: ${td.dest_db}
table: ${td.dest_table}- ワークフローを実行します。
サンプルワークフローコードについては、Treasure Boxesをご覧ください。
統合を設定する前に、最新バージョンのTD Toolbeltをインストールしてください。
in:
type: shopify_v2
admin_api_access_token: xxxxxxxx
target: custom_query
store_name: xxxxxxx
from_date: '2024-12-31T17:00:00.000Z'
incremental_field: created_at
incremental: true
query: |
{
products(first: 10, query: "{{incremental_filter}}") {
pageInfo {
hasNextPage
endCursor
}
edges {
node {
id
title
productType
createdAt
...
...
...
}
}
}
}
out:
mode: replaceパラメータリファレンス
| 名前 | 説明 | 値 | デフォルト値 | 必須 |
|---|---|---|---|---|
| type | インポートのソース。 | "shopify_v2" | はい | |
| admin_api_access_token | Shopify Admin APIでの認証に使用されるアクセストークン。このトークンは、Shopify管理パネルのApps > Develop apps > Create an app > Configure Admin API scopesから生成できます。トークンには、メタフィールドの管理などの操作を実行するための適切な権限が必要です。 | String | はい | |
| target | データを収集するソース | String. "custom_query" | はい | |
| store_name | Shopifyストアのストア識別子。これは次の2つの形式で入力できます: - 完全なストアURL: 例 https://mountbaker.myshopify.com - ストア名のみ: 例: mountbaker ストア名のみを使用する場合は、.myshopify.comドメインを除いたストアの一意の識別子にする必要があります。 | String. | はい | |
| incremental | レポートのグループ化に使用するメトリクスのリスト。許可される値はレポートタイプによって異なります。 | Boolean. | False | いいえ |
| incremental_field | 増分ロードに使用するタイムスタンプ。 | String. "created_at" または "updated_at" | created_at | いいえ |
| date_filter_field | 定義されたカスタムクエリで{{date_filter}}を使用してデータをフィルタリングするために使用するタイムスタンプ | String. "created_at" または "updated_at" | created_at | いいえ |
| start_date | データのエクスポートを開始する開始タイムスタンプ | String. フォーマット: yyyy-MM-dd'T'HH:mm:ss.SS'Z' | いいえ | |
| end_date | データのエクスポートを終了する終了タイムスタンプ | String. フォーマット: yyyy-MM-dd'T'HH:mm:ss.SS'Z' | いいえ | |
| query | ユーザー独自に設計したカスタムクエリ。2つのプレースホルダーオプションが使用できます: - {{incremental_filter}}:** カスタムクエリで増分を使用するために使用します(必須) - {{date_filter}}: カスタムクエリで日付フィルタを使用するために使用します(オプション)。 - 注意: カスタムクエリでページネーションを使用する場合は、カスタムクエリに追加してください。 | String. | はい |
データを推測するには、 td connector:guess コマンドを使用します。(最初にguessを使用してスキーマを推測し、"columns"プロパティで期待通りにスキーマを変更する必要があります)。
$ td connector:guess guess.ymlin:
type: shopify_v2
admin_api_access_token: xxxxxxxx
target: custom_query
store_name: xxxxxxx
from_date: '2024-12-31T17:00:00.000Z'
incremental_field: created_at
incremental: true
query: |
{
products(first: 10, query: "{{incremental_filter}}") {
pageInfo {
hasNextPage
endCursor
}
edges {
node {
id
title
productType
createdAt
...
...
...
}
}
}
}
out:
mode: replaceデータをプレビューするには、 td connector:preview コマンドを使用します。
$ td connector:preview load.ymlデータのサイズによっては、数時間かかる場合があります。データを保存するTreasure Dataデータベースとテーブルを必ず指定してください。Treasure Dataのストレージは時間で分割されているため、--time-columnオプションを指定することをお勧めします(データパーティショニングを参照)。このオプションが指定されていない場合、データコネクタは最初のlongまたはtimestamp列をパーティショニング時間として選択します。--time-columnで指定される列の型は、longまたはtimestamp型のいずれかである必要があります。
データに時間列がない場合は、add_timeフィルターオプションを使用して時間列を追加できます。詳細については、add_time Filter Functionのドキュメントを参照してください。
$ td connector:issue load.yml --database td_sample_db --table td_sample_table \--time-column created_atconnector:issueコマンドは、データベース(td_sample_db)とテーブル(td_sample_table)が既に作成されていることを前提としています。データベースまたはテーブルがTDに存在しない場合、このコマンドは失敗します。データベースとテーブルを手動で作成するか、td connector:issueコマンドで--auto-create-tableオプションを使用してデータベースとテーブルを自動作成してください。
$ td connector:issue load.yml --database td_sample_db --table td_sample_table--time-column created_at --auto-create-tableデータコネクタはサーバー側でレコードをソートしません。時間ベースのパーティショニングを効果的に使用するには、事前にファイル内のレコードをソートしてください。
timeというフィールドがある場合は、--time-columnオプションを指定する必要はありません。
$ td connector:issue load.yml --database td_sample_db --table td_sample_tableload.ymlファイルのout:セクションでファイルインポートモードを指定します。out:セクションは、データがTreasure Dataテーブルにインポートされる方法を制御します。たとえば、既存のテーブルにデータを追加したり、データを置き換えたりすることができます。
| モード | 説明 | 例 |
|---|---|---|
| Append | レコードがターゲットテーブルに追加されます。 | in: ... out: mode: append |
| AlwaysReplace | ターゲットテーブルのデータを置き換えます。ターゲットテーブルに対して手動で行われたスキーマの変更は保持されます。 | in: ... out: mode: replace |
| Replace on new data | インポートする新しいデータがある場合にのみ、ターゲットテーブルのデータを置き換えます。 | in: ... out: mode: replace_on_new_data |
増分ファイルインポートのために、定期的なデータコネクタの実行をスケジュールできます。Treasure Dataスケジューラは高可用性を確保するために最適化されています。
スケジュールされたインポートでは、指定されたプレフィックスに一致し、次のいずれかの条件を満たすすべてのファイルをインポートできます:
- use_modified_timeが無効になっている場合、最後のパスは次の実行のために保存されます。2回目以降の実行では、統合はアルファベット順で最後のパスの後に来るファイルのみをインポートします。
- それ以外の場合、ジョブが実行された時刻が次の実行のために保存されます。2回目以降の実行では、コネクタはその実行時刻以降にアルファベット順で変更されたファイルのみをインポートします。
新しいスケジュールは、td connector:createコマンドを使用して作成できます。
$ td connector:create daily_import "10 0 * * *" \td_sample_db td_sample_table load.ymlTreasure Dataのストレージは時間で分割されているため、--time-columnオプションを指定することもお勧めします(データパーティショニングを参照)。
$ td connector:create daily_import "10 0 * * *" \td_sample_db td_sample_table load.yml \--time-column created_atcronパラメータは、@hourly、@daily、@monthlyの3つの特別なオプションも受け入れます。
デフォルトでは、スケジュールはUTCタイムゾーンで設定されます。-tまたは--timezoneオプションを使用して、タイムゾーンでスケジュールを設定できます。--timezoneオプションは、Asia/Tokyo、America/Los_Angelesなどの拡張タイムゾーン形式のみをサポートします。PST、CSTなどのタイムゾーン略語はサポートされておらず、予期しないスケジュールになる可能性があります。