IFTTT.com に精通している方は、シンプルな「If This Then That」のタスク自動化「レシピ」を既にご存知かと思いますが、Zapier のトリガー・レスポンスメカニズムも同様に動作します。1つのWebアプリで簡単な操作を行うと、それが別のアプリでのレスポンスや動作をトリガーします。
webhook を使用することで、Treasure Data へのシンプルなデータインポートが可能です。Zapier には数百ものインテグレーションがあるため、Treasure Data の REST API への webhook を含む「Zap」を作成することで、これらのデータソースと Treasure Data 間のセルフサービス型インテグレーションへの扉が開かれます。
このインテグレーションは、Data Connectors を使用した本格的な Treasure Data の Data Engineering as a Service へのインポートに取って代わるものではありませんが、まだサポートされていないデータソースでデータをモデル化したり、探索的なクエリや分析を構築するための良い基盤となります。
組織内で一部のメンバーがまだスプレッドシートにデータを保存していて、そのデータを分析パイプラインで簡単かつ迅速に使用したいとお考えですか?
このチュートリアルでは、Zapier Zap を使用した Google Sheets と Treasure Data 間のシンプルなインテグレーションを実演します。
- Google Docs アカウント
- Treasure Data アカウント と Treasure Data Write API key。Treasure Data Toolbelt のインストールも推奨します。
- Zapier アカウント。無料の基本プランで十分です。
通常通り(データテーブルとして使用するために)Google Sheet をセットアップします。上部にヘッダー行を必ず含めてください。
GIF を選択してアニメーションを表示します。
これは、TD Toolbelt を使用してコマンドラインから行うのが最も簡単です。
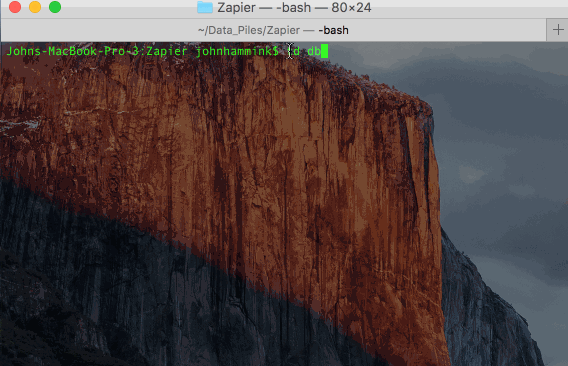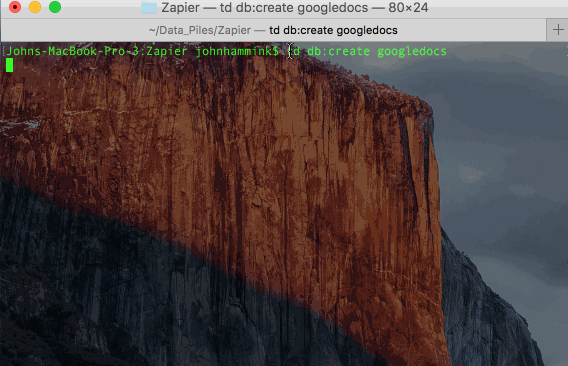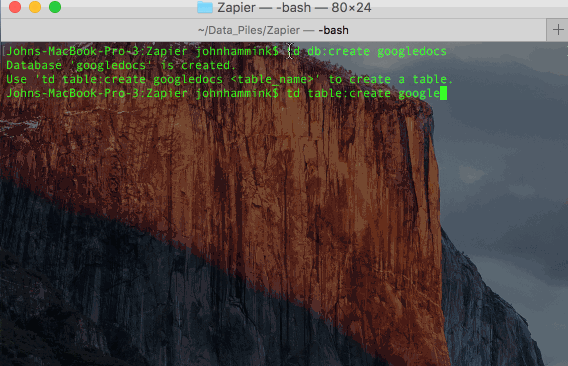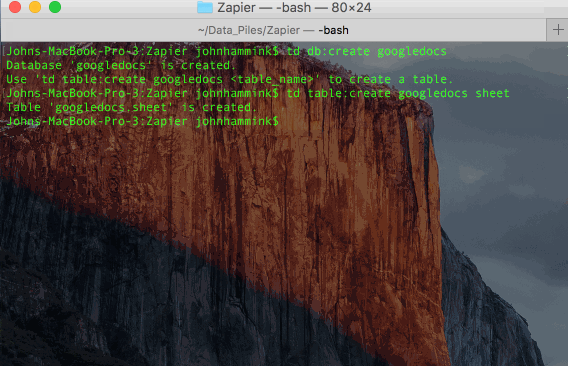
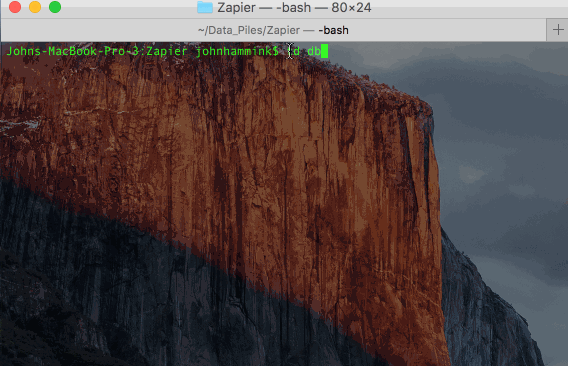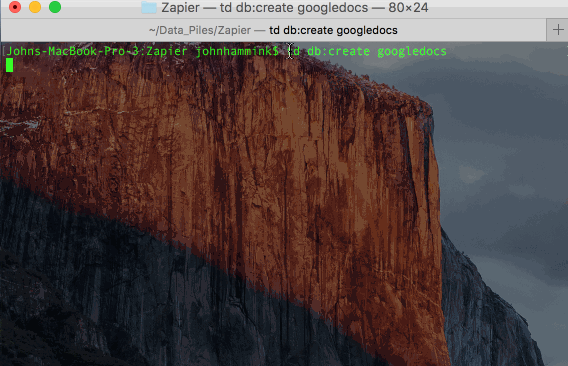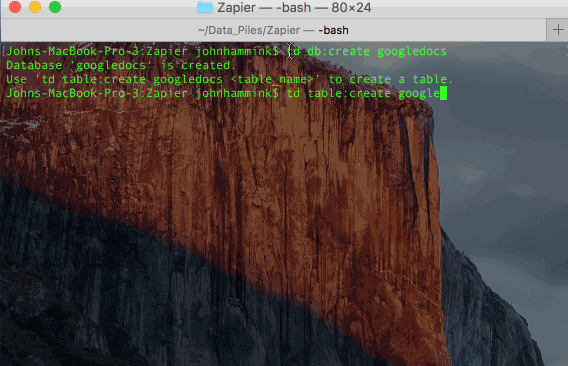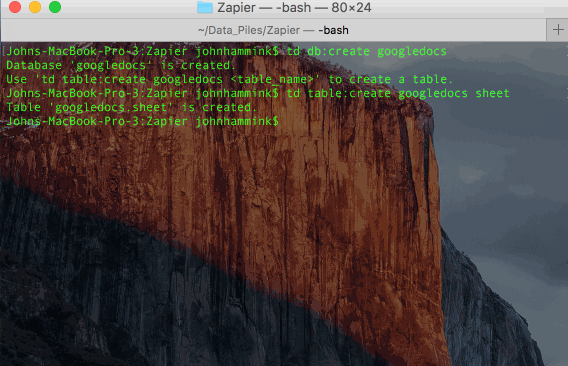
td db:create database_name
td table:create database_name table_namehttps://blog.treasuredata.com/wp-content/uploads/2016/04/td_create_db_and_table.gif
{kind=link}
Zapier Dashboard の上部で、以下を選択します

トリガーアプリとして Google Sheets を選択します。

トリガーとして New Spreadsheet Row を選択し、Save and Continue を選択します。
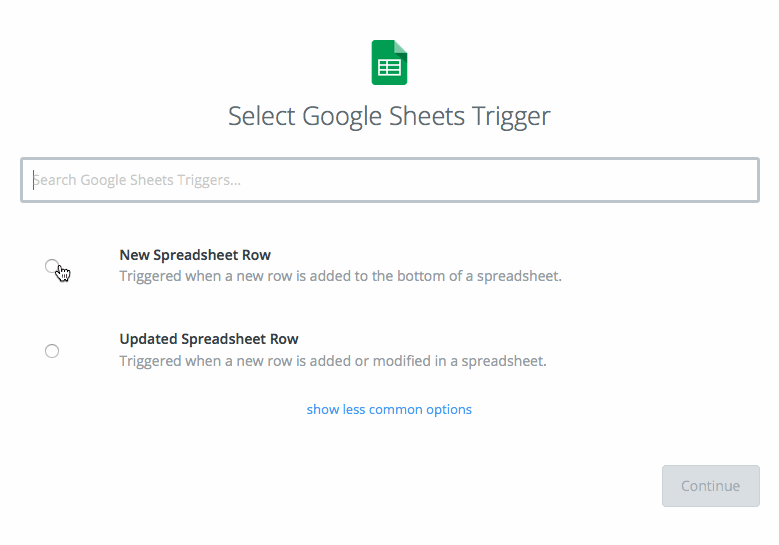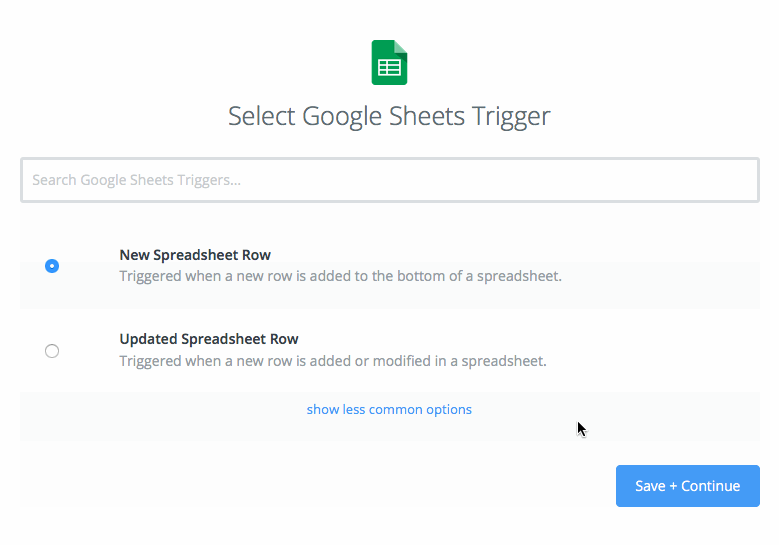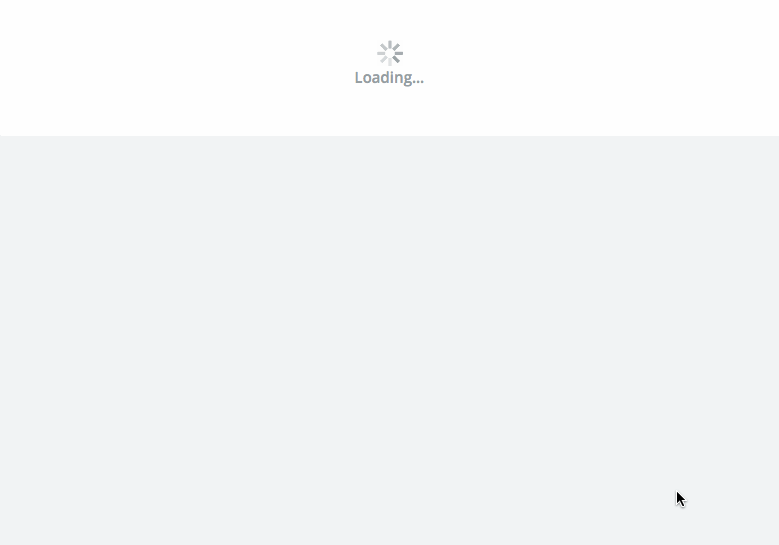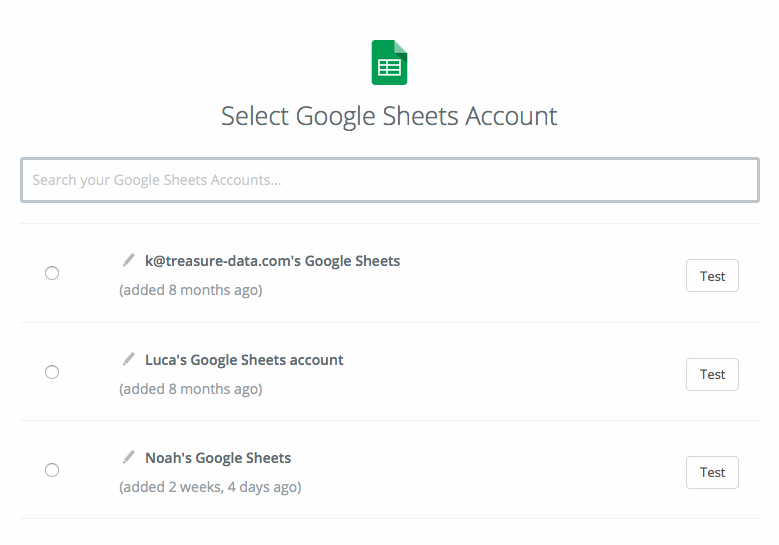
- Google Sheets アカウントを選択します。Test and Save and Continue を選択します。
- データを取得したい Spreadsheet と Worksheet を選択します。Save and Continue を選択します。
- 次の画面で、スプレッドシートにデータ行を追加した後、Fetch + Continue を選択します。
- 次に、Action アプリとして Webhooks を選択します。
- Post アクションを選択します。Save + Continue を押します。
- 以下の情報を入力します
URL: http://in.treasuredata.com/postback/v3/event/database_name/table_namePayload Type: JsonWrap Request in Array: NoUnflatten: yesHeaders:Content-Type: application/jsonX-TD-Write-Key: your_Treasure_Data_Write_API_Key
view rawwebhook post hosted with ❤ by GitHub- Continue を選択し、スプレッドシートに新しい行を追加し、次のステップで Create & Continue を選択してテストします。
- Finish を選択して Zap をオンにします。See it in your Dashboard ボタンですべての Zap を表示できます。
Zapier がシート内の新しい行を認識して webhook を実行するまでに最大15分かかりますが、場合によってはドロップダウンメニューを選択して Zap を簡単に実行させることができます。
GIF を選択してアニメーションを表示します。
データが Treasure Data に入った後(webhook が実行されたときに取り込まれました)、Treasure Data CLI と SQL を使用してクエリできます。当社の SQL エンジンは Hive と Presto によって動作し、数十億行にスケールします。
カラムヘッダーは元のスプレッドシートのものと完全には一致しません。Zapier は、元のシートで定義したヘッダーに「gsx_」プレフィックスを追加し、さらにいくつかの Zapier 固有のフィールドも追加します。
ただし、クエリで Zapier が追加したカラムを除外することで、元のシートと同じデータをクエリから取得できます。
CLI からこれを行うには、いくつかの異なる方法があります。クエリをプレーンテキスト文字列として実行できます。
td query -d googledocs "select gsx_userid, gsx_lastname, gsx_streetname, gsx_city, gsx_zip from sheet"または、お好みであれば、クエリ自体をテキストファイルに保存し、CLI から呼び出すこともできます(上記のように job ID で結果にアクセスします)。
query.txt
SELECT
gsx_userid,
gsx_lastname,
gsx_streetname,
gsx_city,
gsx_zip
FROM
sheetコマンドラインからクエリを実行します。
td query -d googledocs -q query.txt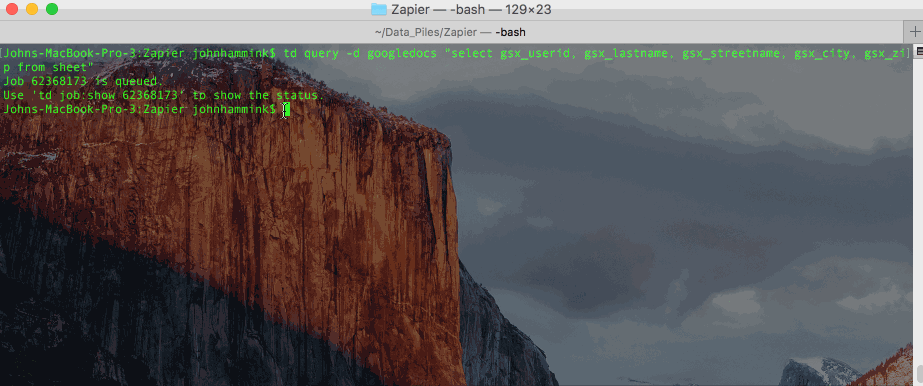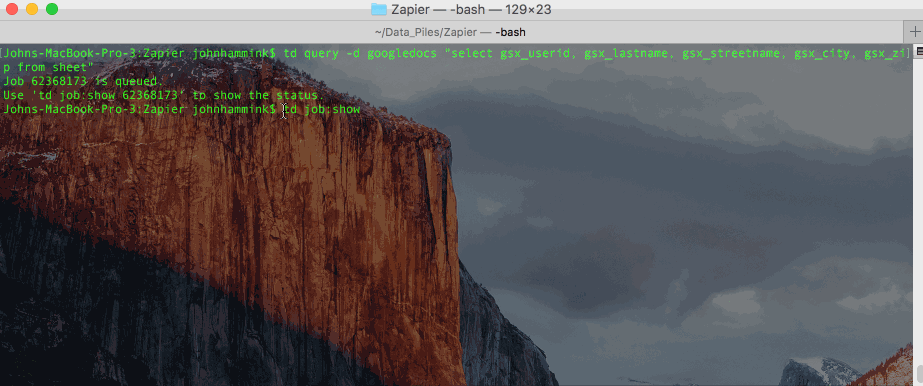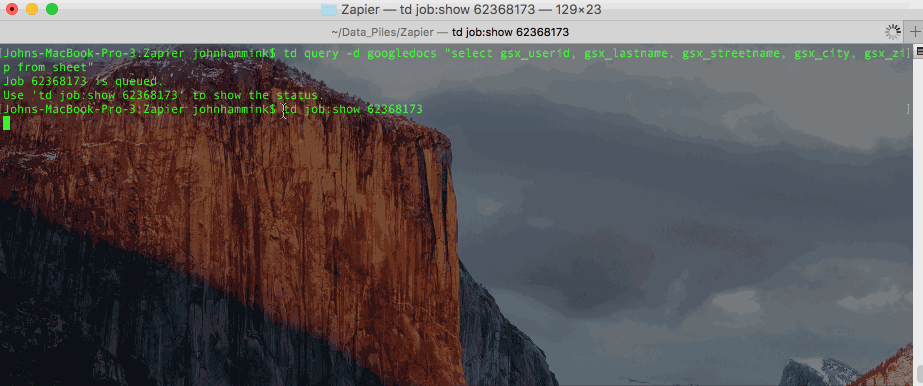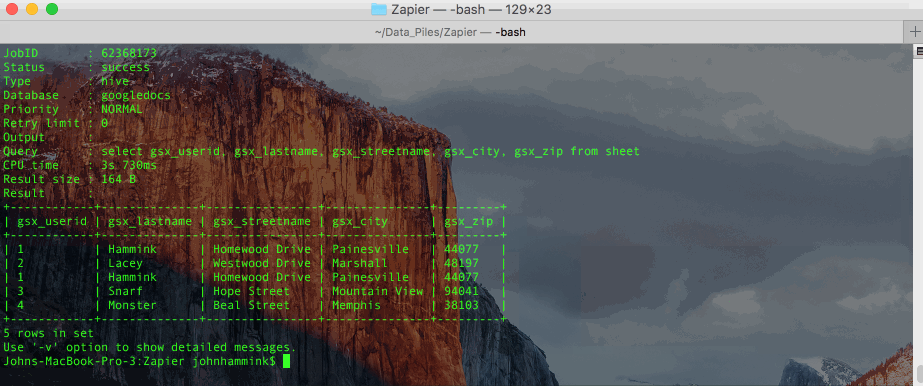
本日は、Google Sheets からデータを取得して Treasure Data に送信する Zapier Zap を紹介しましたが、他の多数のソースからデータを取り込む Zap を構築することは非常に簡単です。
利用可能な Zapier インテグレーション(および可能なデータソース)の完全なリストについては、Zapier の Zapbook をご確認ください。
SQL(Hive または Presto 経由)を使用して、別々のソースからインポートした2つの別々のテーブルに対して(共通のフィールドを共有していると仮定して)、他のリレーショナルデータベースと同様に定期的に内部結合を実行することもできます。ぜひお試しください!