LINEは、アジアにおいてFacebook MessengerやInstagramが米国のモバイルユーザーにとって持つような存在です。友人とのコミュニケーションや、お気に入りの製品やサービスに関する新しいプロモーションを発見するための、迅速かつ簡単な方法です。LINEは台湾でナンバーワンのモバイルメッセージングプラットフォームです。また、日本とタイにおいても最大級のモバイルメッセージングプラットフォームの一つです。Crescendo LabsのMAAC APIを通じて、LINEをアクティベーションするための即座に使えるインテグレーションを開発しています。このインテグレーションにより、顧客情報のメンバーやセグメントをインジェストできます。
- Treasure Dataの基本知識
- MAAC Crescendo Experienceアカウントの基本知識
- アクセストークンの有効期間は、crescendo labとパートナーが署名した契約期間です。
インクリメンタルローディングは、ソースから新しいレコードまたは更新されたレコードのみをTreasure Dataにロードすることです。特に大規模なデータセットに対して、フルロードと比較して効率的に実行されるため有用です。
インクリメンタルローディングは、多くのTreasure Dataインテグレーションで利用できます。場合によっては、単純なチェックボックスの選択で済みますが、他の場合では、インクリメンタルローディングを選択した後、指定する必要がある他のフィールドが提供されます。
- 一部のインテグレーションでは、インクリメンタルローディングを選択する場合、フルテーブルスキャンを回避するために列にインデックスがあることを確認する必要があります。
- incremental_columnsとしてサポートされるのは、Timestamp、Datetime、および数値列のみです。
- 複雑なクエリでは主キーを検出できないため、raw queryではincremental_columnsが必要です。
Treasure Dataのインクリメンタルローディングには4つのパターン(3種類のデータコネクタ + 1つのワークフローtd_loadオペレータ)があり、3つのデータコネクタのロード例は次のとおりです:
- クラウドストレージサービス(例:AWS S3、GCSなど)
- ファイル名の辞書順
- クエリ(例:MySQL、BigQueryなど)
- 日時
- 可変期間(Google Analyticsなど)
- ロードにstart_dateを使用
インクリメンタルローディングが選択されている場合、コネクタのデータはインクリメンタルにロードされます。
このモードは、前回のスケジュール実行以降に変更されたオブジェクトターゲットのみを取得する場合に便利です。
例えば、UIでは:

MySQL、BigQuery、SQL Serverなどのデータベースインテグレーションでは、インクリメンタルデータをロードするために列またはフィールド名が必要です。

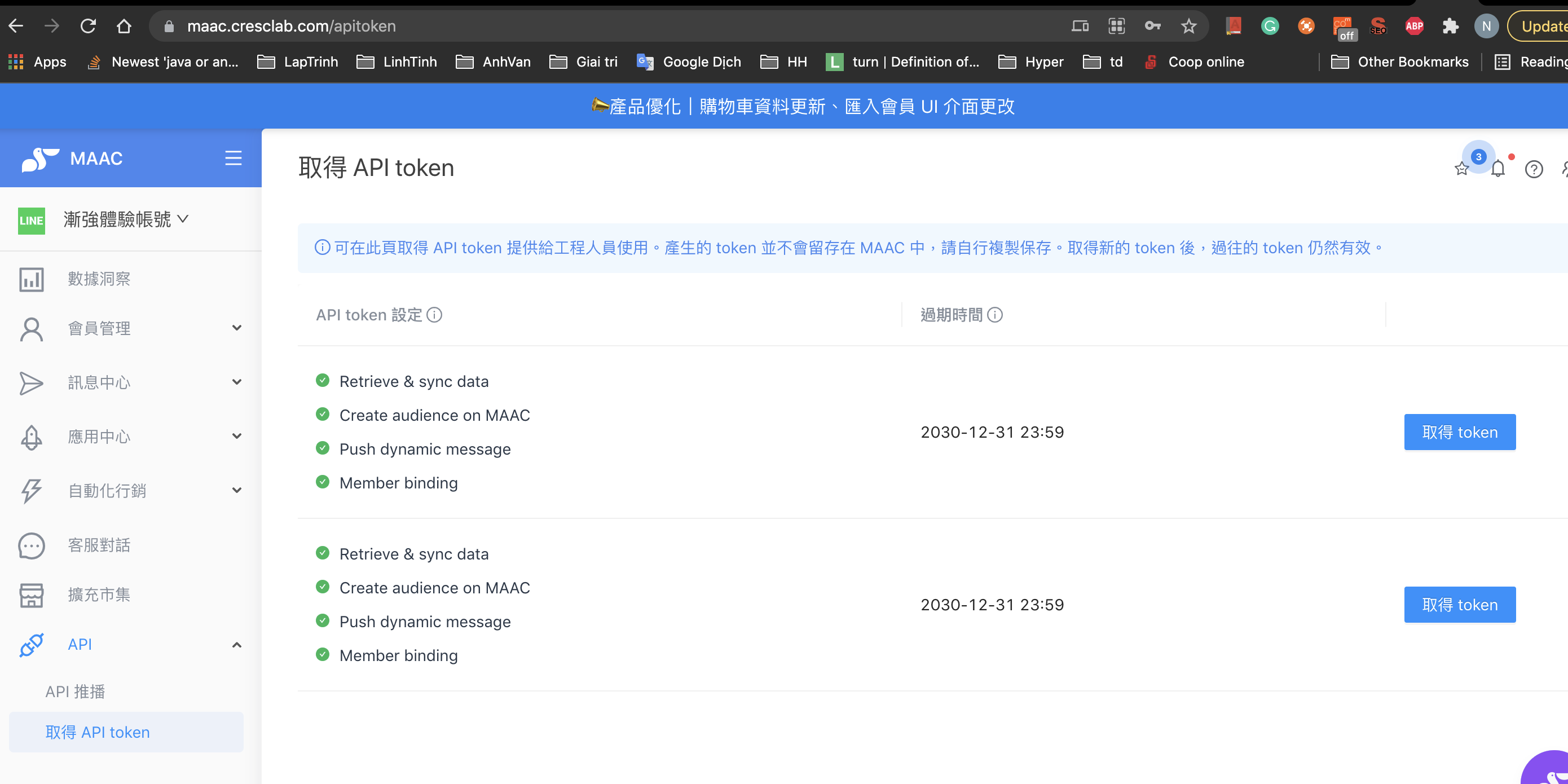
- Get tokenを選択します
Treasure Dataでは、クエリを実行する前にデータ接続を作成および設定する必要があります。データ接続の一部として、インテグレーションにアクセスするための認証を提供します。
- TDコンソールを開きます。
- Integrations Hub > Catalogに移動します。
- LINEvia Crescendoを検索して選択します。
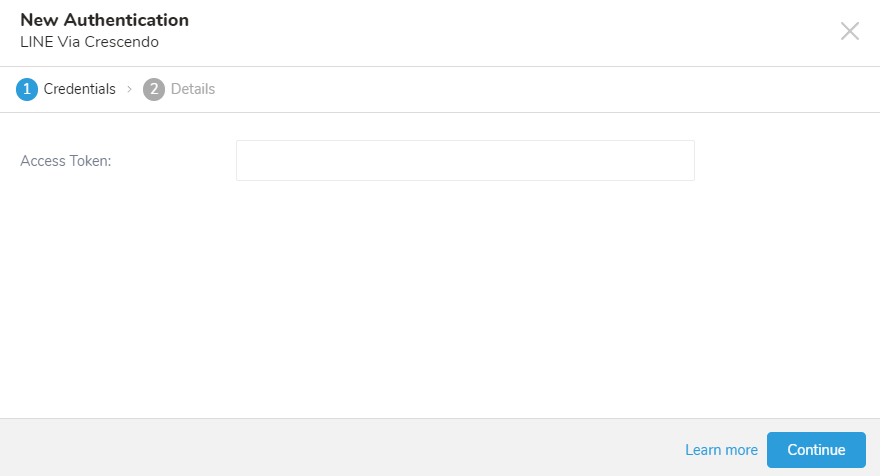
- Create Authenticationを選択します。
- 認証するための認証情報を入力します。
- 接続の名前を入力します。
- Continueを選択します。
認証された接続を作成すると、自動的にAuthenticationsに移動します。
- 作成した接続を検索します。
- New Sourceを選択します。
- Data TransferフィールドにSourceの名前を入力します。
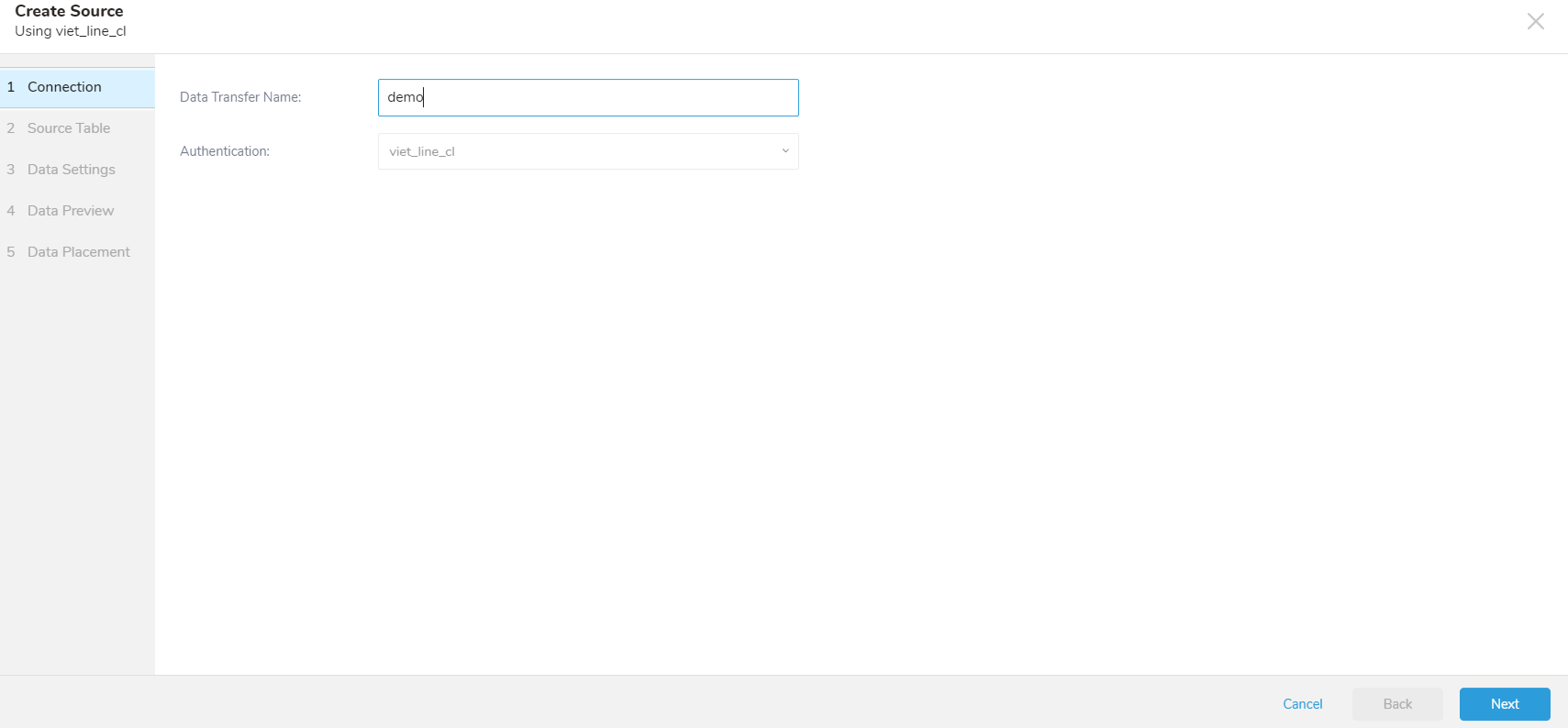
- Nextを選択します。 Source Tableダイアログが開きます。
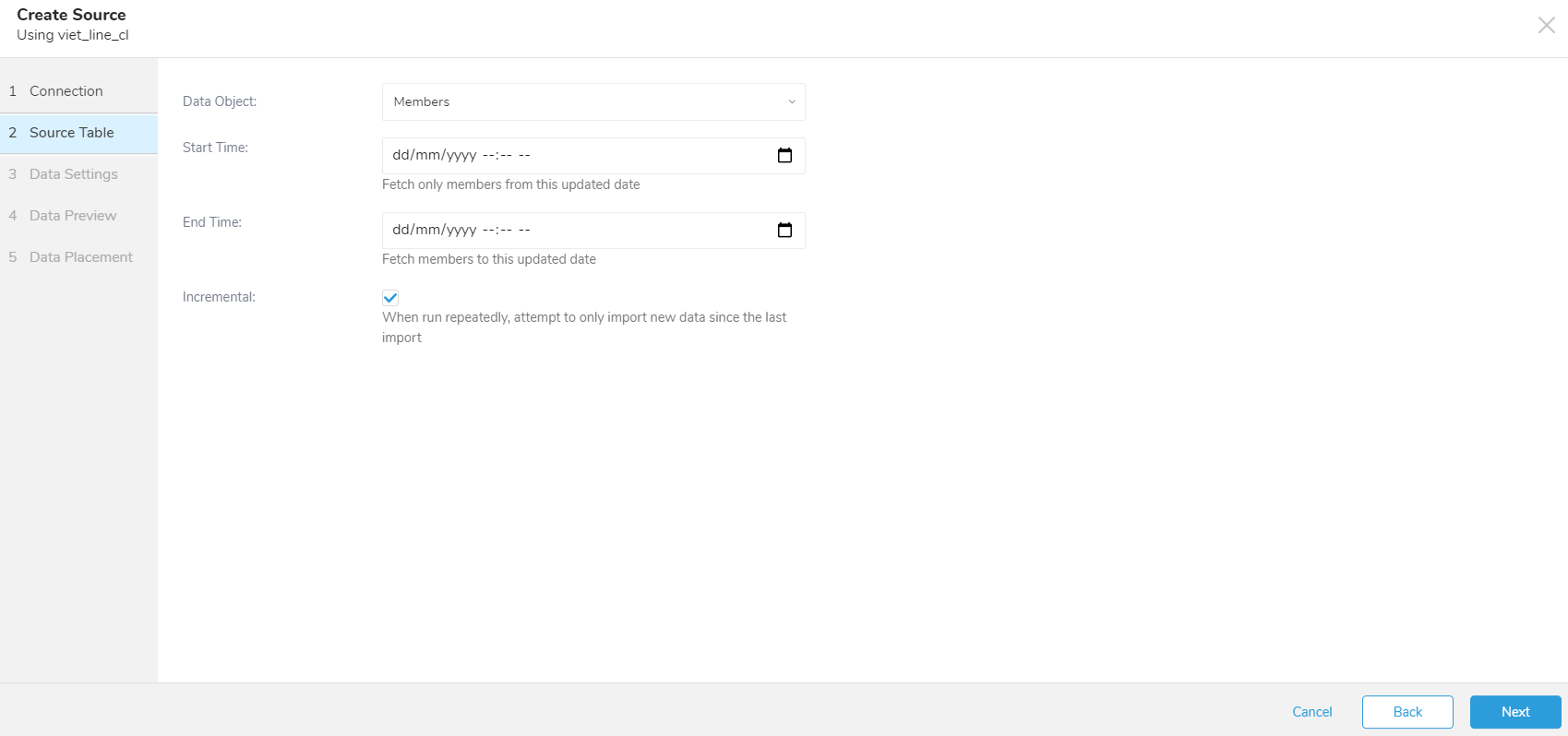
- 以下のパラメータを編集します:
| パラメータ | 説明 |
|---|---|
| Data Objects | インポートするデータオブジェクトタイプ:- Members - Segments |
| Start Time(Membersデータオブジェクト選択時にオプション表示) | UI設定の場合、サポートされているブラウザから日付と時刻を選択するか、ブラウザの日時の期待に合った日付を入力できます。例えば、Chromeではカレンダーから年、月、日、時間、分を選択できます。Safariでは2020-10-25T00:00のようなテキストを入力する必要があります。CLI設定の場合、RFC3339 UTC "Zulu"形式でナノ秒まで正確なタイムスタンプが必要です。例:"2014-10-02T15:01:23Z"。 |
| End Time(Membersデータオブジェクト選択時にオプション表示) | UI設定の場合、サポートされているブラウザから日付と時刻を選択するか、ブラウザの日時の期待に合った日付を入力できます。例えば、Chromeではカレンダーから年、月、日、時間、分を選択できます。Safariでは2020-10-25T00:00のようなテキストを入力する必要があります。CLI設定の場合、RFC3339 UTC "Zulu"形式でナノ秒まで正確なタイムスタンプが必要です。例:"2014-10-02T15:01:23Z"。 |
| Incremental | 前回の実行から新しいデータのみをインポートします。インクリメンタルローディングについてを参照してください。 |
- Nextを選択します。 Data Settingsページは必要に応じて変更できますが、スキップすることもできます。
- Nextを選択します。
インポートを実行する前に、Generate Preview を選択してデータのプレビューを表示できます。Data preview はオプションであり、選択した場合はダイアログの次のページに安全にスキップできます。
- Next を選択します。Data Preview ページが開きます。
- データをプレビューする場合は、Generate Preview を選択します。
- データを確認します。
データの配置について、データを配置したいターゲット database と table を選択し、インポートを実行する頻度を指定します。
Next を選択します。Storage の下で、インポートされたデータを配置する新しい database を作成するか、既存の database を選択し、新しい table を作成するか、既存の table を選択します。
Database を選択 > Select an existing または Create New Database を選択します。
オプションで、database 名を入力します。
Table を選択 > Select an existing または Create New Table を選択します。
オプションで、table 名を入力します。
データをインポートする方法を選択します。
- Append (デフォルト) - データインポートの結果は table に追加されます。 table が存在しない場合は作成されます。
- Always Replace - 既存の table の全体の内容をクエリの結果出力で置き換えます。table が存在しない場合は、新しい table が作成されます。
- Replace on New Data - 新しいデータがある場合のみ、既存の table の全体の内容をクエリの結果出力で置き換えます。
Timestamp-based Partition Key 列を選択します。 デフォルトキーとは異なるパーティションキーシードを設定したい場合は、long または timestamp 列をパーティショニング時刻として指定できます。デフォルトの時刻列として、add_time フィルターで upload_time を使用します。
データストレージの Timezone を選択します。
Schedule の下で、このクエリを実行するタイミングと頻度を選択できます。
- Off を選択します。
- Scheduling Timezone を選択します。
- Create & Run Now を選択します。
- On を選択します。
- Schedule を選択します。UI では、@hourly、@daily、@monthly、またはカスタム cron の 4 つのオプションが提供されます。
- Delay Transfer を選択して、実行時間の遅延を追加することもできます。
- Scheduling Timezone を選択します。
- Create & Run Now を選択します。
転送が実行された後、Data Workbench > Databases で転送の結果を確認できます。
必要に応じて、TDコンソールの代わりにCLIからデータコネクタを作成できます。
Ruby gemを使用して最新のtdツールをインストールします:
gem install td
td --version他のインストール方法もあります。詳細については、Treasure Data Toolbeltを参照してください。
以下は、YouTubeチャンネルのすべての動画の日次基本統計をリクエストするための設定ファイルの例です。
in:
type: line_via_crescendo
api_token: dummy_token
data_object: members
incremental: true
start_time: 2021-01-01T07:16:00.000Z
end_time: 2021-07-15T07:16:00.000Z
out:
mode: append