このインテグレーションは、SFTPサーバーへのデータアップロードを可能にし、以下をサポートしています:
- 複数のファイル形式
- データ圧縮
- サーバーハンドシェイクアルゴリズム
前提条件
- ツールベルトを含むTreasure Dataの基本的な知識
- SFTPサーバー
制限事項
- パスプレフィックスには以下の文字を含めることはできません: * ?
セキュリティポリシーで IP ホワイトリストが必要な場合は、接続を成功させるために Treasure Data の IP アドレスを許可リストに追加する必要があります。
リージョンごとに整理された静的 IP アドレスの完全なリストは、次のリンクにあります: https://api-docs.treasuredata.com/en/overview/ip-addresses-integrations-result-workers/
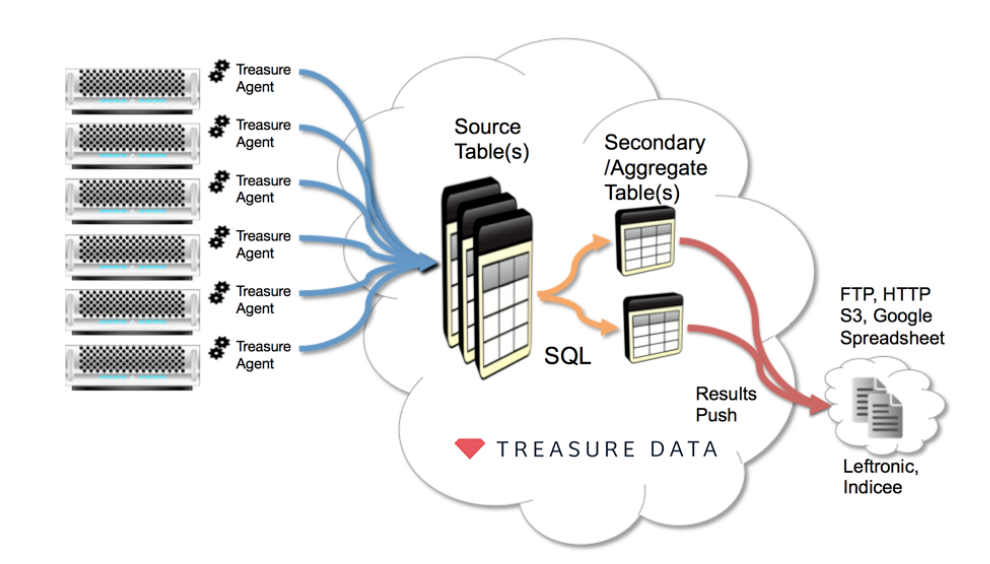
以下の図は、Treasure DataエージェントからSFTPまたは類似のサーバーへデータをエクスポートする典型的な使用シナリオを示しています。
クエリを実行する前に、TD Consoleでデータ接続を作成および設定する必要があります。データ接続の一部として、以下の手順を使用してインテグレーションにアクセスするための認証を提供します:
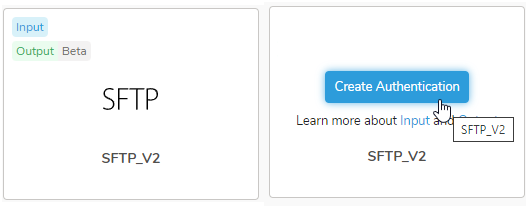
- TD Consoleを開きます。
- Integrations Hub > Catalogに移動します。
- SFTP_V2を検索し、Create Authenticationを選択します。
- 接続認証情報を入力します。
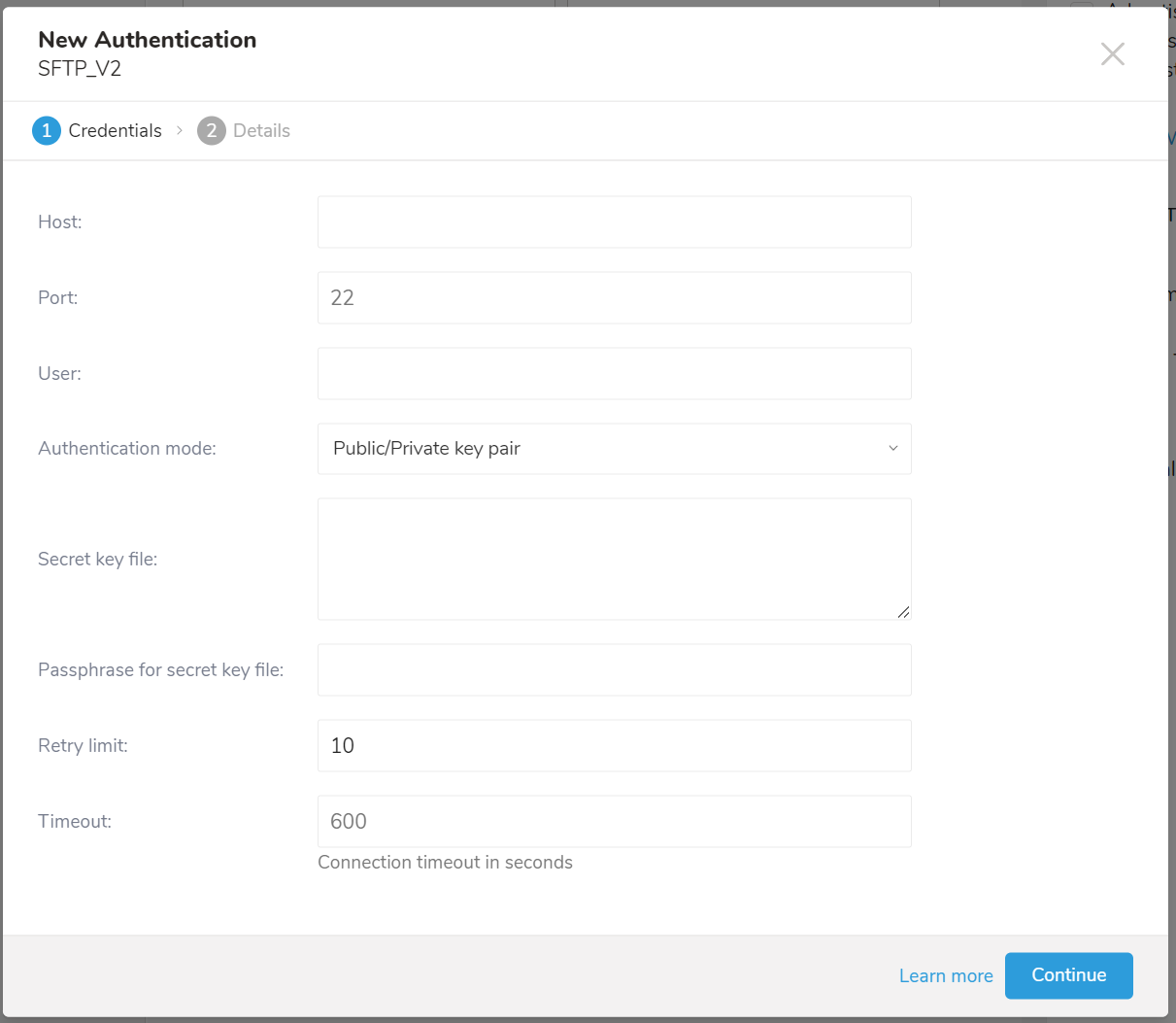
認証フィールド
| パラメータ | データ型 | 説明 |
|---|---|---|
| Host 必須 | string | リモートSFTPインスタンスのホスト情報(例:IPアドレス) |
| Port 必須 | string | リモートSFTPインスタンスの接続ポート。デフォルトのポート番号は22です |
| User 必須 | string | リモートSFTPインスタンスへの接続に使用するユーザー名 |
| Authentication mode 必須 | string | このインテグレーションは2種類の認証をサポートしています:
|
| Password オプション | string | Authentication ModeでPasswordが選択されている場合は必須 |
| Secret key file オプション | string | Authentication Modeでpublic/private key pairが選択されている場合は必須 |
| Passphrase for secret key file オプション | string | 一部のアルゴリズムで必要な秘密鍵ファイルのパスフレーズ |
| Retry limit 必須 | int | 接続失敗時のリトライ回数(デフォルト:10) |
| Timeout 必須 | int | 接続タイムアウト(秒単位、デフォルト:600) |
- Continueを選択し、認証の名前を入力します。
- Doneを選択します。
TD Consoleはデータをエクスポートする複数の方法をサポートしています。Data Workbenchからデータをエクスポートするには、以下の手順を完了します。
- Data Workbench > Queriesに移動します。
- New Queryを選択し、クエリを定義します。
- Export Resultsを選択し、データエクスポートの設定を行います。
- 既存のインテグレーションを使用するか、新しいインテグレーションを作成します。
- エクスポートパラメータを設定し、Doneを選択します。
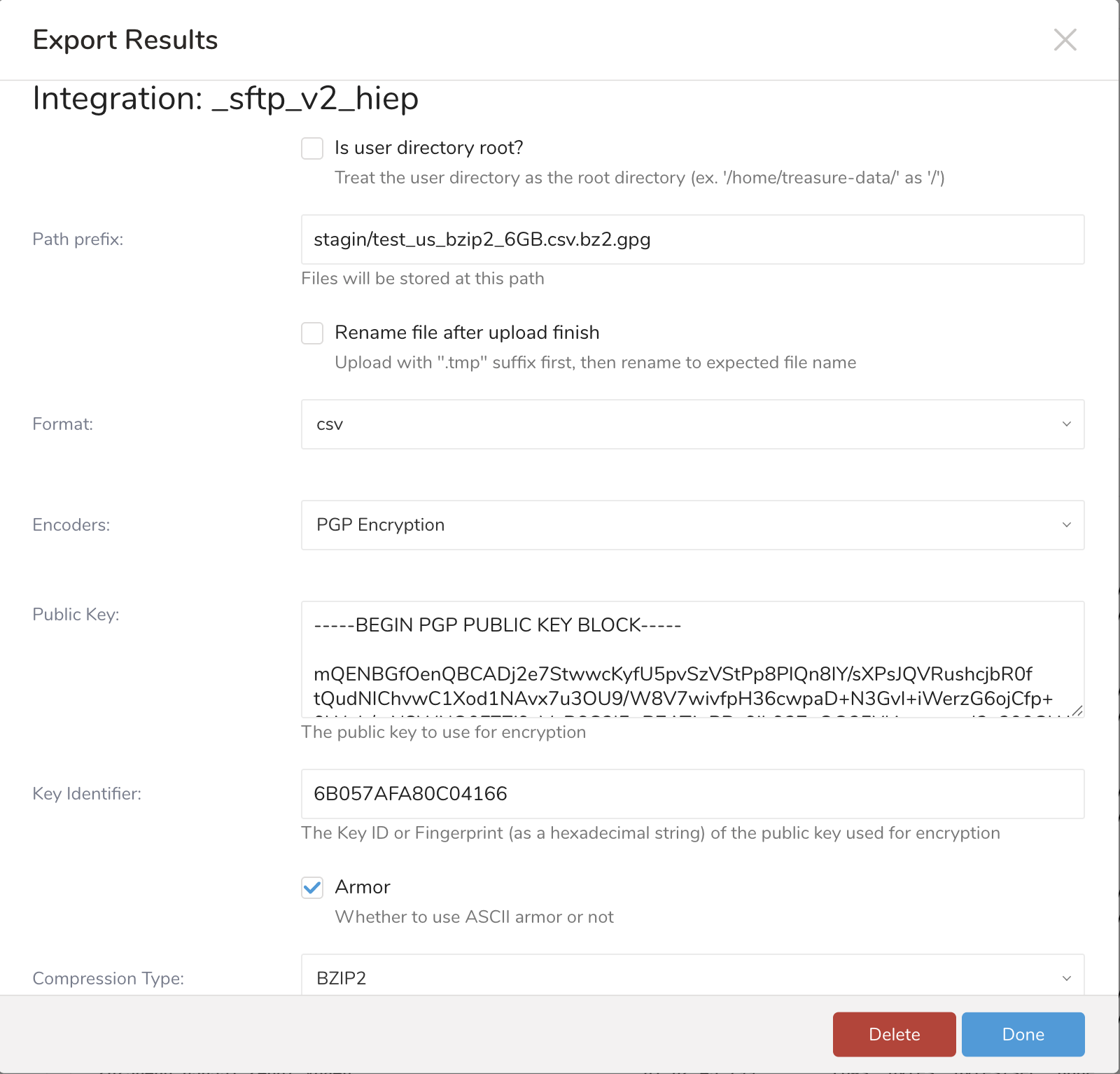
エクスポート設定パラメータ
| パラメータ | データ型 | 説明 |
|---|---|---|
| Is user directory Root? 必須 | boolean | 選択した場合、ユーザーディレクトリがルートディレクトリとして扱われます(例:'/home/treasure-data' を '/' として扱う) |
| Path prefix 必須 | string | ファイルが保存されるファイルパス |
| Rename file after upload finish 必須 | string | 選択した場合、ファイルは.tmpサフィックス付きでSFTPにアップロードされ、データ転送完了後にサフィックスが削除されます。一部のデータ統合ツールはファイルの存在を検出して独自のタスクをトリガーしようとします。このオプションはそのようなケースに有用です。 |
| Format 必須 | string |
|
| Encoders 必須 | string |
|
| Public Key EncoderがPGP encryptionの場合は必須 | string |
|
| Key Identifier EncoderがPGP encryptionの場合は必須 | string |
|
| Armor オプション | check box |
|
| Compression Type オプション | string |
|
| Header line? 必須 | string | 選択した場合、カラム名が最初の行として追加されます。 |
| Delimiter 必須 | string | 区切り文字:
|
| Quote policy オプション | string | クォートのポリシー:
|
| Null string 必須 | string | クエリ結果のnull値の表示方法:
|
| End-of-line character 必須 | string | EOL(行末)文字:
|
| Temp filesize threshold 必須 | long | エクスポートデータがこのしきい値より大きい場合、アップロードはしきい値自体をバッチサイズとしてバッチで実行されます。channel is brokenエラーが発生した場合、この値を減らすとエラーが解決する可能性があります。 |
Audience Studio で activation を作成することで、segment データをターゲットプラットフォームに送信することもできます。
- Audience Studio に移動します。
- parent segment を選択します。
- ターゲット segment を開き、右クリックして、Create Activation を選択します。
- Details パネルで、Activation 名を入力し、前述の Configuration Parameters のセクションに従って activation を設定します。
- Output Mapping パネルで activation 出力をカスタマイズします。

- Attribute Columns
- Export All Columns を選択すると、変更を加えずにすべての列をエクスポートできます。
- + Add Columns を選択して、エクスポート用の特定の列を追加します。Output Column Name には、Source 列名と同じ名前があらかじめ入力されます。Output Column Name を更新できます。+ Add Columns を選択し続けて、activation 出力用の新しい列を追加します。
- String Builder
- + Add string を選択して、エクスポート用の文字列を作成します。次の値から選択します:
- String: 任意の値を選択します。テキストを使用してカスタム値を作成します。
- Timestamp: エクスポートの日時。
- Segment Id: segment ID 番号。
- Segment Name: segment 名。
- Audience Id: parent segment 番号。
- + Add string を選択して、エクスポート用の文字列を作成します。次の値から選択します:
- Schedule を設定します。

- スケジュールを定義する値を選択し、オプションでメール通知を含めます。
- Create を選択します。
batch journey の activation を作成する必要がある場合は、Creating a Batch Journey Activation を参照してください。
TD Toolbeltを使用して、CLIからSFTPへのクエリ結果のエクスポートをトリガーできます。td queryコマンドの--resultオプションを使用してエクスポートジョブのパラメータを指定する必要があります。詳細については、コマンドラインからのTreasure Dataへのデータのクエリとインポートを参照してください。
オプションの形式はJSONで、一般的な構造は以下の通りです:
- ユーザー名とパスワードを使用した認証:
{
"type": "sftp_v2",
"host": "SFTPサーバーのIPまたはホスト",
"port": "オープンポート",
"path_prefix": "/upload/2024Aug29/TC01.csv",
"temp_file_threshold": "一時ファイルのサイズ",
"timeout": 600,
"user_directory_is_root": false,
"rename_file_after_upload": true,
"auth_method": "password",
"username": "ログインユーザー",
"password": "auth_methodがpasswordの場合のユーザーパスワード"
}- 公開鍵/秘密鍵ペアを使用した認証
{
"type": "sftp_v2",
"host": "SFTPサーバーのIPまたはホスト",
"port": "オープンポート",
"path_prefix": "/upload/2024Aug29/TC01.csv",
"temp_file_threshold": "一時ファイルのサイズ",
"timeout": 600,
"user_directory_is_root": false,
"rename_file_after_upload": true,
"auth_method": "key_pair",
"secret_key_file": "秘密鍵ファイルの内容",
"secret_key_passphrase": "td@123"
}| 名前 | 説明 | 値 | デフォルト値 | 必須 |
|---|---|---|---|---|
| type | typeはsftp_v2である必要があります | String | NULL | YES |
| host | IPアドレスまたはドメイン名で指定されたSFTPサーバーのアドレス
| String | NULL | YES |
| port | SFTPサーバーとの接続用ポート | Number | 22 | NO |
| user_directory_is_root | 一部のサーバーでは、ユーザーはホームディレクトリをルートディレクトリとして持ちます。例えば、johnという名前のユーザーは/home/johnというルートディレクトリを持つことができます。そのユーザーが/home/john/day1/my_data.csvというディレクトリにファイルをアップロードしたい場合、2つのオプションがあります:
| String | False | NO |
| path_prefix | SFTPサーバー上でファイルをアップロードしたいパス。path_prefixの値は、user_directory_is_rootがtrueかfalseかによって異なります。 | String | NULL | YES |
| rename_file_after_upload | アップロード完了後にファイルの名前を変更するかどうかを決定します | Boolean | False | NO |
| temp_file_threshold | エクスポート中に使用される一時ファイルのサイズ。一時ファイルサイズに達すると、インテグレーションはそのファイルからデータを読み取り、リモートファイルに書き込み、一時ファイルを削除します。 | Number | 5,368,709,120(5 GB) | NO |
| auth_method | SFTPサーバーとの認証に使用される認証タイプを決定します:
| サポートされている値:
| key_pair | YES |
| username | 認証に使用されるユーザー名 | String | NULL | YES |
| password | 認証に使用されるパスワード | String | NULL | YES(auth_methodがpasswordの場合) |
secret_key_file | 認証に使用される秘密鍵ファイル。ファイルの内容は1行に整形する必要があります。 例 td ... --result \
'{"type":"sftp_v2", "secret_key_file": "-----BEGIN OPENSSH PRIVATE KEY-----\nline1\nline2\nline3\n-----END OPENSSH PRIVATE KEY-----\n\n"}'整形前の秘密鍵ファイルの内容: -----BEGIN OPENSSH PRIVATE KEY-----
line1
line2
line3
-----END OPENSSH PRIVATE KEY-----整形後 -----BEGIN OPENSSH PRIVATE KEY-----line1line2line3-----END OPENSSH PRIVATE KEY----- | String | NULL | YES(auth_methodがkey_pairの場合) |
| secret_key_passphrase | 秘密鍵がパスワード付きで生成された場合、ここにそのパスワードを入力します。 | String | NULL | NO |
| sequence_format | アップロードされるファイルのサフィックス名。例:"%03d.%02d" | String | 空白 | NO |
| format | アップロードされるファイルの出力形式 | サポートされている値:
| csv | NO |
| encoders | 出力のエンコーダータイプを指定します | サポートされている値:
| "" | NO |
| public_key | 暗号化に使用する公開鍵 | String | ||
| key_identifier | ファイルを保護するために使用される暗号化サブキーのKey IDを指定します。マスターキーは暗号化プロセスから除外されます。(string、必須) | String | ||
| armor | 暗号化された出力にASCIIアーマーを使用します(boolean) | Boolean | ||
compression_type | 暗号化する前にデータを圧縮するかどうかを決定する圧縮タイプ。 | サポートされている値
注意:アップロード前にファイルを圧縮してから暗号化してください。復号化すると、ファイルは.gzや.bz2などの圧縮形式に戻ります。 | ||
| delimiter | カラム区切り文字 | サポートされている値:
| "," | NO |
quote_policy | クォートの処理ポリシー | サポートされている値:
ポリシーALLのコード例 設定: quote_policy: ALL,
quote: "'",出力 'id'|'column01'|'column02'|'column03'|'column04'|'column05'
'1'|'data01'|'data02'|'data03'|'data04'|'data05'ポリシーMINIMALのコード例 設定: quote_policy: MINIMAL,
quote: "'",出力 id|column01|column02|column03|column04|column05
1|data01|data02|data03|data04|data05 | ||
quote | クォートにシングルクォートまたはダブルクォートを使用するかを決定します。 | シングルクォート 設定 quote_policy: ALL,
quote: "'",出力 'id'|'column01'|'column02'
'1'|'data01'|'data02'ダブルクォート 設定 quote_policy: ALL,
quote: "\"",出力 "id"|"column01"|"column02"
"1"|"data01"|"data02" | ||
| null_string | nullカラムのデフォルト値を決定します。 | サポートされている値:
| "" | |
| newline | CSVファイルで新しい行を開始する方法を決定します。 | サポートされている値:
| CRLF |
パスワード認証を使用する場合
td --database your_db --wait "SELECT email FROM (VALUES ('test01@test.com')) tbl(email)" \ --type presto \ --result '{"type":"sftp_v2","host":"your_ip","port": 22,"auth_method":"password","username":"user_name","password":"your_pass", "user_directory_is_root": true, "rename_file_after_upload": true,"path_prefix":"/sftp/2024aug/test.csv"}'パスワード認証とデータ圧縮を使用する場合
td --database your_db --wait "SELECT email FROM (VALUES ('test01@test.com')) tbl(email)" \ --type presto \ --result '{"type":"sftp_v2","host":"your_ip","port": 22,"auth_method":"password","username":"user_name","password":"password","user_directory_is_root":true,"path_prefix":"/sftp/2024aug/test.csv","rename_file_after_upload":true,"format": "csv", "compression": "gz","header_line":true,"quote_policy":"ALL","delimiter":"\t","null_string":"","newline":"CRLF","temp_file_threshold":0,"sequence_format":".%01d%01d"}'パスワードフレーズ付きの公開鍵/秘密鍵認証を使用する場合
秘密鍵ファイルの内容(パスワードフレーズは
123):-----BEGIN OPENSSH PRIVATE KEY----- line1 line2 line3 -----END OPENSSH PRIVATE KEY-----CLI用の形式:
-----BEGIN OPENSSH PRIVATE KEY-----\nline1\nline2\nline3\n-----END OPENSSH PRIVATE KEY-----\n\nCLIコマンド:
td --database your_db --wait "SELECT email FROM (VALUES ('test01@test.com')) tbl(email)" \ --type presto \ --result '{"type":"sftp_v2","host":"your_ip","port": 22,"auth_method":"key_pair","username":"user_name", "path_prefix": "/sftp/2024aug/test.csv","sequence_format":"","max_connection_retry":5,"secret_key_passphrase":"123","timeout":600,"secret_key_file":"-----BEGIN OPENSSH PRIVATE KEY-----\nline1\nline2\nline3\n-----END OPENSSH PRIVATE KEY-----\n\n"}'新しい顧客を作成する場合
td --database luan_db --wait "SELECT customer_list_id,first_name,last_name,birthday,company_name,email,fax,gender,job_title,phone_business,phone_home,phone_mobile,second_name,credentials FROM (VALUES ('site_1','fname_201','lname_1','1990-05-12','Test Company','test01@example.com','03-0000-0000','male','Engineer','03-0000-0001','03-0000-0002','090-0000-0000','second_name','credential_1')) AS t(customer_list_id,first_name,last_name,birthday,company_name,email,fax,gender,job_title,phone_business,phone_home,phone_mobile,second_name,credentials)" \ --type presto \ --result '{"type":"sftp_v2","host":"your_ip","port": 22,"auth_method":"password","username":"user_name","password":"your_pass","user_directory_is_root":true,"path_prefix":"/sftp/2024aug/customer.csv","rename_file_after_upload":true}'暗号化エンコーダーを使用する場合
td query -d luan_db -w "select * from luan_db.sfcc_500k" -T presto --result '{ "type": "sftp_v2", "host": "ホストサーバー", "auth_method": "password", "username": "ユーザー名", "password": "パスワード", "path_prefix": "cli/test_27_3_500K.csv.bz2.gpg", "file_ext": ".gpg", "rename_file_after_upload": false, "formatter": { "type": "csv", "quote_policy": "MINIMAL", "delimiter": ",", "null_string": "null", "newline": "\n" }, "compression": "encrypt_pgp", "public_key": "公開鍵", "key_identifier": "キー識別子", "armor": true/false, "compression_type": "bzip2/gzip/none" }'
Treasure Workflow内で、このインテグレーションを使用してデータをエクスポートするよう指定できます。サンプルワークフローについては、Treasure Boxesを参照してください。
- 結果エクスポートは、ターゲット先に定期的にデータをアップロードするようにスケジュールできます
- ほとんどのインポートおよびエクスポートインテグレーションは、より高度なデータパイプラインに関与するためにTD Workflowに追加できます。詳細についてはこちらを参照してください。
- Embulk-encoder-Encryptionドキュメント:embulk-encoder-encryption-pgp
Q: SFTPサーバーに接続できません。どうすればよいですか?
A: 以下の点を確認してください:
- プロトコルが有効であることを確認してください。SFTPを使用する場合は、このインテグレーションを使用できます。FTP/FTPSを使用する場合は、FTPサーバーインポートインテグレーションを試してください。
- ファイアウォールを使用している場合は、許可されているIPレンジとポートを確認してください。サーバー管理者はセキュリティ上の理由から、デフォルトのポート番号をTCP 22から変更することがあります。
- 秘密鍵がOpenSSH形式であることを確認してください。Treasure Dataは「PuTTY」などの他の形式をサポートしていません。
- Treasure DataはOpenSSH 7.8以降のデフォルト形式の秘密鍵をサポートしていません。'-m PEM'オプションを使用して鍵を再生成してください。
Q: SFTPサーバー上にアップロードしたファイルが見つかりません。何が起こったのですか?
A: SFTPサーバーがAppendモードをサポートしていない場合、インテグレーションは「SFTP Exception: no such file.」というエラーでファイルを更新できない可能性があります。安定性の理由から、インテグレーションはファイルコンテンツをバッチでアップロードします。そのため、SFTPサーバーでAppendモードを有効にする必要があります。SFTPサーバーでAppendモードを有効にできない場合は、この機能をバイパスするためにtemp_file_thresholdを0に設定する必要があります。
注意:暗号化してアップロードする前に、必ずファイルを圧縮してください。
非組み込み暗号化を使用して復号化すると、ファイルは.gzや.bz2などの圧縮形式に戻ります。
組み込み暗号化を使用して復号化すると、ファイルは生データに戻ります。