SFTP_V2のData Connectorを使用すると、SFTPサーバーに保存されているファイルをTreasure Dataにインポートできます。
- Treasure Dataの基本的な知識
- このインテグレーションを使用する前に、お使いの環境で有効なプロトコルを確認してください。
SFTPを使用する場合は、このインテグレーションをSFTP用に使用できます。
FTP/FTPSを使用する場合は、FTPインポートインテグレーションへの接続をお試しください。
- ファイアウォールを使用している場合は、許可されているIPレンジとポートを確認してください。サーバー管理者は、セキュリティ上の理由からデフォルトのポート番号をTCP 22から変更することがあります。
- 「PuTTY」やその他の形式はサポートされていません。
- STOREDおよびDEFLATE圧縮方式のみをサポートしています。
- マルチパートgzipファイルは動作しない可能性があります。
セキュリティポリシーで IP ホワイトリストが必要な場合は、接続を成功させるために Treasure Data の IP アドレスを許可リストに追加する必要があります。
リージョンごとに整理された静的 IP アドレスの完全なリストは、次のリンクにあります: https://api-docs.treasuredata.com/en/overview/ip-addresses-integrations-result-workers/
Treasure Dataでは、クエリを実行する前にデータ接続を作成して設定する必要があります。データ接続の一部として、インテグレーションにアクセスするための認証情報を提供します。
TD Consoleを開きます。
Integrations Hub > Catalogに移動します。
SFTP_V2を検索して選択します。
- Create Authenticationを選択します。
以下のダイアログが開きます。パラメータを編集します。Continueを選択します。
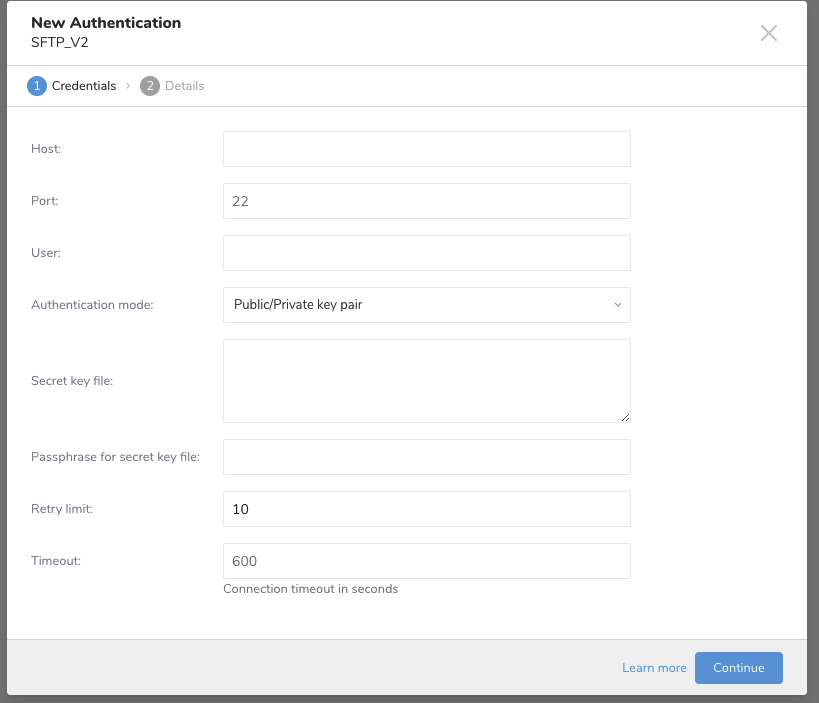
| パラメータ | 説明 |
|---|---|
| Host | リモートSFTPインスタンスのホスト情報。例: IPアドレス |
| Port | リモートSFTPインスタンスの接続ポート。デフォルトは22です。 |
| User | リモートSFTPインスタンスへの接続に使用するユーザー名 |
| Authentication mode | SFTPサーバーで認証する方法を選択します。 |
| Secret key file | Authentication Modeから「public/private key pair」が選択されている場合は必須です。(RSA、DSS、ECDSA、ED25519がサポートされています) |
| Passphrase for secret key file | (オプション) 必要に応じて、提供された秘密鍵ファイルのパスフレーズを入力します。 |
| Retry limit | 接続失敗時のリトライ回数 (デフォルト: 10) |
| Timeout | 接続タイムアウト(秒単位、デフォルト: 600) |
接続の名前を入力します。
認証を他のユーザーと共有するかどうかを選択します。
Continueを選択します。
認証済み接続を作成すると、自動的にAuthentications画面に移動します。
作成した接続を検索します。
New Sourceを選択します。
Data Transfer Name フィールドにSourceの名前を入力します。
Nextを選択します。
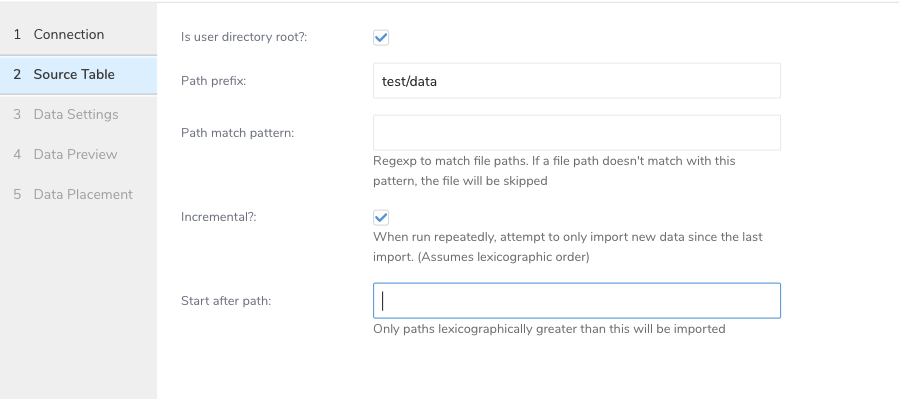
以下のパラメータを編集します:
| パラメータ | 説明 |
|---|---|
| User directory root | パスプレフィックスがユーザーディレクトリ配下にあるかをチェックします。例: /home/test_user |
Path prefix | 対象ファイルのプレフィックス。フォルダを指す必要があります(文字列、必須)。SFTP v1とは異なり、パスプレフィックスはフォルダパスである必要があります。ファイルパスに部分的なファイル名が含まれている場合、 SFTP v1からSFTP v2 Importに移行する場合、v2のpath_prefixはv1と同じように動作しないことに注意してください。例えば、SFTP v1とは異なり、パスプレフィックスはフォルダパスである必要があります。 |
| Path match pattern | ファイルパスをクエリするための正規表現を入力します。ファイルパスが指定されたパターンと一致しない場合、そのファイルはスキップされます。例えば、パターン.csv$を指定すると、パスがパターンと一致しないファイルはスキップされます。 |
| Incremental | インクリメンタルロードを有効にします(boolean、オプション。デフォルト: true)。インクリメンタルロードが有効な場合、次回実行用の設定差分にlast_pathパラメータが含まれるため、次回実行時にはそのパスより前のファイルがスキップされます。それ以外の場合、last_pathは含まれません。 |
| Start after path | この値よりも辞書式順序で大きいパスのみがインポートされます。 |
- Nextを選択します。
Data Settings ページは必要に応じて変更できますが、スキップすることもできます。
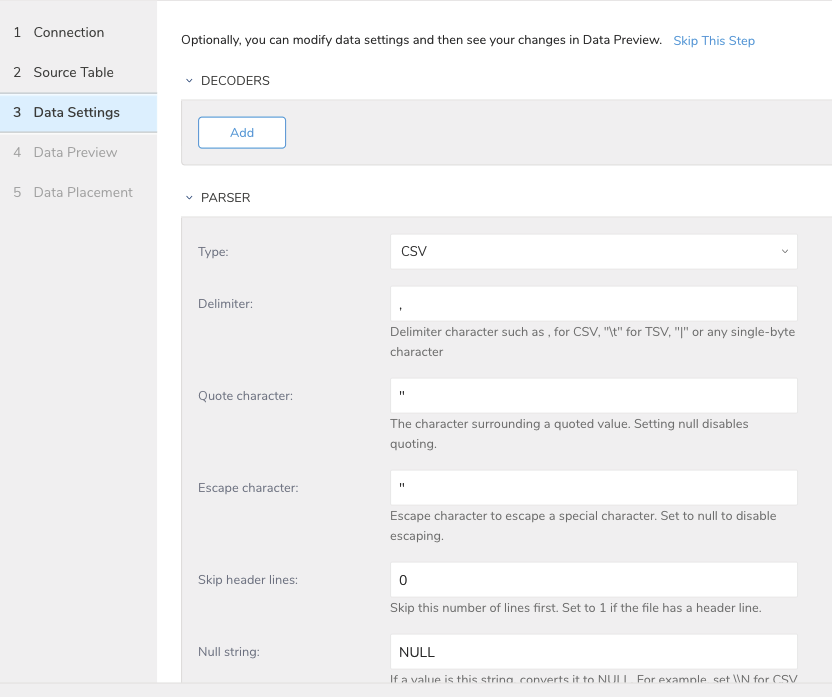
インポートを実行する前に、Generate Preview を選択してデータのプレビューを表示できます。Data preview はオプションであり、選択した場合はダイアログの次のページに安全にスキップできます。
- Next を選択します。Data Preview ページが開きます。
- データをプレビューする場合は、Generate Preview を選択します。
- データを確認します。
データの配置について、データを配置したいターゲット database と table を選択し、インポートを実行する頻度を指定します。
Next を選択します。Storage の下で、インポートされたデータを配置する新しい database を作成するか、既存の database を選択し、新しい table を作成するか、既存の table を選択します。
Database を選択 > Select an existing または Create New Database を選択します。
オプションで、database 名を入力します。
Table を選択 > Select an existing または Create New Table を選択します。
オプションで、table 名を入力します。
データをインポートする方法を選択します。
- Append (デフォルト) - データインポートの結果は table に追加されます。 table が存在しない場合は作成されます。
- Always Replace - 既存の table の全体の内容をクエリの結果出力で置き換えます。table が存在しない場合は、新しい table が作成されます。
- Replace on New Data - 新しいデータがある場合のみ、既存の table の全体の内容をクエリの結果出力で置き換えます。
Timestamp-based Partition Key 列を選択します。 デフォルトキーとは異なるパーティションキーシードを設定したい場合は、long または timestamp 列をパーティショニング時刻として指定できます。デフォルトの時刻列として、add_time フィルターで upload_time を使用します。
データストレージの Timezone を選択します。
Schedule の下で、このクエリを実行するタイミングと頻度を選択できます。
- Off を選択します。
- Scheduling Timezone を選択します。
- Create & Run Now を選択します。
- On を選択します。
- Schedule を選択します。UI では、@hourly、@daily、@monthly、またはカスタム cron の 4 つのオプションが提供されます。
- Delay Transfer を選択して、実行時間の遅延を追加することもできます。
- Scheduling Timezone を選択します。
- Create & Run Now を選択します。
転送が実行された後、Data Workbench > Databases で転送の結果を確認できます。
ワークフローを作成して実行します
_export:
td:
database: workflow_sftp_v2
table: workflow_sftp_v2
+import_from_sftp_v2:
td_load>: imports/seed.yml
database: ${td.database}
table: ${td.table}インポート用のSFTP接続の詳細をseed.ymlファイルに設定します。
in:
type: sftp_v2
host: HOST
port: <PORT, default is 22>
auth_method: key_pair
user: USER
secret_key_file:
content: |
-----BEGIN RSA PRIVATE KEY-----
Proc-Type: 4,ENCRYPTED
DEK-Info: AES-128-CBC...
...
-----END RSA PRIVATE KEY-----
secret_key_passphrase: PASSPHRASE
user_directory_is_root: true
timeout: 600
path_prefix: /path/to/sample
parser:
skip_header_lines: 1
charset: UTF-8
newline: CRLF
type: csv
delimiter: ','
quote: '"'
columns:
- {name: id, type: long}
- {name: account, type: long}
- {name: time, type: timestamp, format: "%Y-%m-%d %H:%M:%S"}
- {name: purchase, type: timestamp, format: "%Y%m%d"}
- {name: comment, type: string}
- {name: json_column, type: json}
out:
mode: append| 設定パラメータ | 値 |
|---|---|
| host: | (string, 必須) |
| port: | (string, デフォルト: 22) |
| auth_method: | (string ['password', 'key_pair'], 必須) |
| user: | (string, 必須) |
| password: | (string, デフォルト: null) |
| secret_key_file: | (string, デフォルト: null)。OpenSSH形式が必要です。 |
| secret_key_passphrase: | (string, デフォルト: "") |
| user_directory_is_root: | (boolean, デフォルト: true) |
| timeout: sftp接続のタイムアウト秒数 | (integer, デフォルト: 600) |
| path_prefix: 出力パスのプレフィックス | (string, 必須) |
| incremental: 増分ロードを有効化 | (boolean, オプション。デフォルト: true)。増分ロードが有効な場合、次回実行の設定差分にlast_pathパラメータが含まれ、次回実行時にそのパスより前のファイルをスキップします。それ以外の場合、last_pathは含まれません。 |
| path_match_pattern: | ファイルパスに一致する正規表現。ファイルパスがこのパターンに一致しない場合、そのファイルはスキップされます (regexp string, オプション) |
| total_file_count_limit: | 読み取るファイルの最大数 (integer, オプション) |
| min_task_size (実験的): | タスクの最小サイズ。これが0より大きい場合、1つのタスクに複数の入力ファイルが含まれます。これは、タスク数が多すぎることが出力プラグインやエグゼキュータープラグインのパフォーマンスに悪影響を与える場合に有用です。 (integer, オプション) |
最新のTreasure Data Toolbeltをインストールしてください。
$ td --version以下の例に示すように、SFTP_v2の詳細情報を含むseed.ymlを準備します。公開鍵/秘密鍵ペアとパスワードの2つの認証方法をサポートしています。
以下の内容でseed.ymlを作成します。
in:
type: sftp_v2
host: HOST
port: <PORT, default is 22>
auth_method: key_pair
user: USER
secret_key_file:
content: |
-----BEGIN RSA PRIVATE KEY-----
Proc-Type: 4,ENCRYPTED
DEK-Info: AES-128-CBC...
...
-----END RSA PRIVATE KEY-----
secret_key_passphrase: PASSPHRASE
user_directory_is_root: true
timeout: 600
path_prefix: /path/to/sample
out:
mode: append
exec: {}secret\_key\_fileにはOpenSSH形式が必要です。
以下の内容でseed.ymlを作成します。
in:
type: sftp_v2
host: HOST
port: <PORT, default is 22>
auth_method: password
user: USER
password: PASSWORD
user_directory_is_root: true
timeout: 600
path_prefix: /path/to/sample
out:
mode: append
exec: {}パスワードには次の特殊文字を使用できます: "#$!*@"
SFTP_v2統合は、指定されたプレフィックスに一致するすべてのファイルをインポートします。path_prefixはファイルまたはフォルダを指定する必要があります (例: path_prefix: path/to/sample–> path/to/sample/201501.csv.gz、path/to/sample/201502.csv.gz、…、path/to/sample/201505.csv.gz)。
connector:guessを使用します。このコマンドは、ソースファイルを自動的に読み取り、ファイル形式を評価 (ロジックを使用して推測) します。
$ td connector:guess seed.yml -o load.ymlload.ymlを開くと、ファイル形式、エンコーディング、カラム名、型を含む推測されたファイル形式定義が表示されます。この例では、CSVファイルをロードしようとしています。
in:
type: sftp_v2
host: HOST
port: <PORT, default is 22>
auth_method: key_pair
user: USER
secret_key_file:
content: |
-----BEGIN RSA PRIVATE KEY-----
Proc-Type: 4,ENCRYPTED
DEK-Info: AES-128-CBC...
...
-----END RSA PRIVATE KEY-----
secret_key_passphrase: PASSPHRASE
user_directory_is_root: true
timeout: 600
path_prefix: /path/to/sample
parser:
skip_header_lines: 1
charset: UTF-8
newline: CRLF
type: csv
delimiter: ','
quote: '"'
columns:
- {name: id, type: long}
- {name: account, type: long}
- {name: time, type: timestamp, format: "%Y-%m-%d %H:%M:%S"}
- {name: purchase, type: timestamp, format: "%Y%m%d"}
- {name: comment, type: string}
- {name: json_column, type: json}
out:
mode: append
exec: {}次に、preview コマンドを使用して、システムがファイルをどのように解析するかをプレビューできます。
td connector:preview load.ymlguess コマンドは、ソースデータファイルに3行以上、2列以上必要です。これは、ソースデータのサンプル行を使用してカラム定義を推測するためです。
システムが予期しない列名または列タイプを検出した場合は、load.yml を直接修正して、再度プレビューしてください。
この連携では、"boolean"、"long"、"double"、"string"、"timestamp" タイプの解析をサポートしています。
また、データロードジョブを実行する前に、データベースとテーブルを作成する必要があります。次の手順に従ってください:
td database:create td_sample_db
td table:create td_sample_db td_sample_tableロードジョブを送信します。データのサイズによっては、数時間かかる場合があります。データを保存する Treasure Data のデータベースとテーブルを指定します。
--time-column オプションを指定することをお勧めします。Treasure Data のストレージは時間でパーティション分割されているためです(データパーティショニングを参照)。オプションが指定されていない場合、連携は最初の long または timestamp カラムをパーティショニング時間として選択します。--time-column で指定するカラムのタイプは、long または timestamp タイプのいずれかである必要があります。
データに時間カラムがない場合は、add_time フィルターオプションを使用して時間カラムを追加できます。詳細については、add_time フィルター関数を参照してください。
td connector:issue load.yml --database td_sample_db --table td_sample_table --time-column created_atconnector:issue コマンドは、database(td_sample_db) と table(td_sample_table) をすでに作成していることを前提としています。データベースまたはテーブルが TD に存在しない場合、connector:issue コマンドは失敗します。この場合、データベースを作成し、テーブルを作成を手動で行うか、td connector:issue コマンドで --auto-create-table オプションを使用して、データベースとテーブルを自動作成してください:
td connector:issue load.yml --database td_sample_db --table td_sample_table --time-column created_at --auto-create-tableこの連携は、サーバー側でレコードをソートしません。時間ベースのパーティショニングを効果的に使用するには、事前にレコードをソートしてください。
time というフィールドがある場合は、--time-column オプションを指定する必要はありません。
td connector:issue load.yml --database td_sample_db --table td_sample_table増分 SFTP_v2 ファイルインポートの定期的な連携実行をスケジュールできます。高可用性を確保するために、スケジューラーを慎重に設定しています。この機能を使用することで、ローカルデータセンターで cron デーモンを使用する必要がなくなります。
スケジュールされたインポートの場合、SFTP_v2 の連携は、最初に指定されたプレフィックスと一致するすべてのファイル(例: path_prefix: path/to/sample –> path/to/sample/201501.csv.gz, path/to/sample/201502.csv.gz, …, path/to/sample/201505.csv.gz)をインポートし、次の実行のために最後のパス(path/to/sample/201505.csv.gz)を記憶します。
2回目以降の実行では、アルファベット順(辞書順)で最後のパスの後に来るファイルのみをインポートします。(path/to/sample/201506.csv.gz, …)
新しいスケジュールは、td connector:create コマンドを使用して作成できます。以下が必要です: スケジュールの名前、cron スタイルのスケジュール、データを保存するデータベースとテーブル、および連携設定ファイル。
td connector:create \
daily_import \
"10 0 * * *" \
td_sample_db \
td_sample_table \
load.ymlTreasure Data のストレージは時間でパーティション分割されているため、--time-column オプションを指定することをお勧めします。
td connector:create \
daily_import \
"10 0 * * *" \
td_sample_db \
td_sample_table \
load.yml \
--time-column created_atcron パラメータは、3つの特別なオプション @hourly、@daily、@monthly も受け入れます。
デフォルトでは、スケジュールは UTC タイムゾーンで設定されます。-t または --timezone オプションを使用して、タイムゾーンでスケジュールを設定できます。--timezone オプションは、'Asia/Tokyo'、'America/Los_Angeles' などの拡張タイムゾーン形式のみをサポートしています。PST、CST などのタイムゾーンの略語は*サポートされておらず*、予期しないスケジュールにつながる可能性があります。
td connector:list コマンドを実行すると、現在スケジュールされているエントリのリストを確認できます。
td connector:listtd connector:show は、スケジュールエントリの実行設定を表示します。
td connector:show daily_importtd connector:history は、スケジュールエントリの実行履歴を表示します。個々の実行の結果を調査するには、td job jobid を使用します。
td connector:history daily_importtd connector:delete は、スケジュールを削除します。
td connector:delete daily_importseed.yml の out セクションでファイルインポートモードを指定できます。
これはデフォルトモードで、レコードは対象テーブルに追加されます。
in:
...
out:
mode: appendこのモードは、対象テーブルのデータを置き換えます。このモードでは、対象テーブルに対して行われた手動のスキーマ変更はそのまま残ります。
in:
...
out:
mode: replaceSTFP サーバーからファイルをインポートするサンプルワークフローについては、Treasure Boxes を参照してください。