このデータコネクタを使用して、FTPサーバーからTreasure Dataに直接データをインポートできます。
FTPサーバーからデータをインポートするサンプルワークフローについては、Treasure Boxesをご覧ください。
- Treasure Dataの基本知識
- FTPの基本知識
- 有効なプロトコルを使用していることを確認してください。FTPまたはFTPSを使用する場合は、このFTP用データコネクタを使用できます。SFTPの場合は、SFTPインテグレーションを使用してください。
- ファイアウォールを使用している場合は、許可されているIPレンジ/ポートを確認してください。サーバー管理者は、セキュリティ上の理由からデフォルトのポート番号を変更することがあります。
- FTPは、デフォルトの制御ポートとしてTCP/21を使用しますが、パッシブモードを使用している場合は、データ転送ポートとして任意のTCPポートも使用します。このポート範囲は、サーバーの設定によって異なります。
- パッシブモードで接続していることを確認してください。アクティブモードは、FTPサーバー側から接続を確立するため、通常は機能しません。
- FTPSを使用している場合、ExplicitとImplicitの2つのモードがあります。通常はExplicitモードが使用されます。
インクリメンタル読み込みについてを参照してください。
- 一部のインテグレーションでは、インクリメンタル読み込みを選択する場合、フルテーブルスキャンを回避するために、カラムにインデックスがあることを確認する必要がある場合があります。
- Timestamp、Datetime、および数値カラムのみがincremental_columnsとしてサポートされています。
- 複雑なクエリのプライマリキーを検出できないため、rawクエリにはincremental_columnsが必要です。
Treasure Dataでは、クエリを実行する前にデータ接続を作成して設定する必要があります。データ接続の一部として、インテグレーションにアクセスするための認証情報を提供します。
TD Consoleを開きます。
Integrations Hub > Catalogに移動します。
FTPを検索して選択します。

- Create Authenticationを選択します。
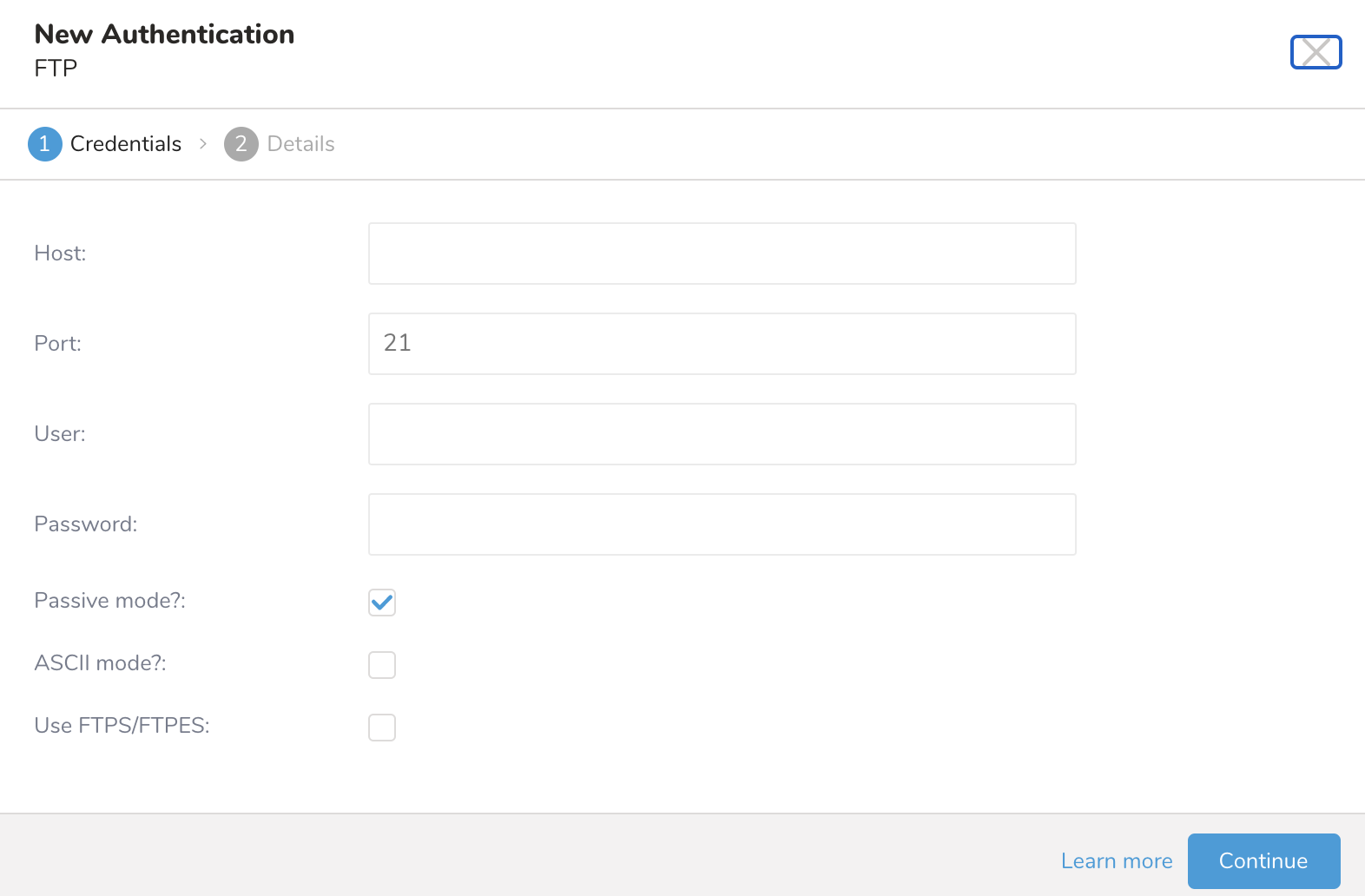
- リモートFTPインスタンスに必要な認証情報を入力します。選択内容によって、表示されるフィールドが異なる場合があります:
| フィールド | 説明 |
|---|---|
| Host | リモートFTPインスタンスのホスト情報(例:IPアドレス)。 |
| Port | リモートFTPインスタンスの接続ポート。デフォルトは21です。 |
| User | リモートFTPインスタンスへの接続に使用するユーザー名。 |
| Password | リモートFTPインスタンスへの接続に使用するパスワード。 |
| Passive mode | パッシブモードを使用する(デフォルト:チェック済み) |
| ASCII mode | バイナリモードの代わりにASCIIモードを使用する(ブール値、デフォルト:未チェック) |
| Use FTPS/FTPES | FTPS(SSL暗号化)を使用する。(ブール値、デフォルト:未チェック) |
| Verify cert | サーバーによって提供される証明書を検証します。デフォルトでは、サーバー証明書がJVMのデフォルトの信頼できるCAリストのいずれかのCAによって署名されていない場合、接続は失敗します。 |
| Verify hostname | サーバーのホスト名が提供された証明書と一致することを検証します。 |
| Enable FTPES | FTPESはFTPSのセキュリティ拡張です。 |
| SSL CA Cert Content | 証明書ファイルの内容を貼り付けます。 |
Continueを選択します。
接続の名前を入力します。
Continueを選択します。
認証された接続を作成すると、自動的にAuthenticationsに移動します。
- 作成した接続を検索します。
- New Sourceを選択します。
- Data TransferフィールドにSourceの名前を入力します。
- Nextを選択します。
Source Tableダイアログが開きます。
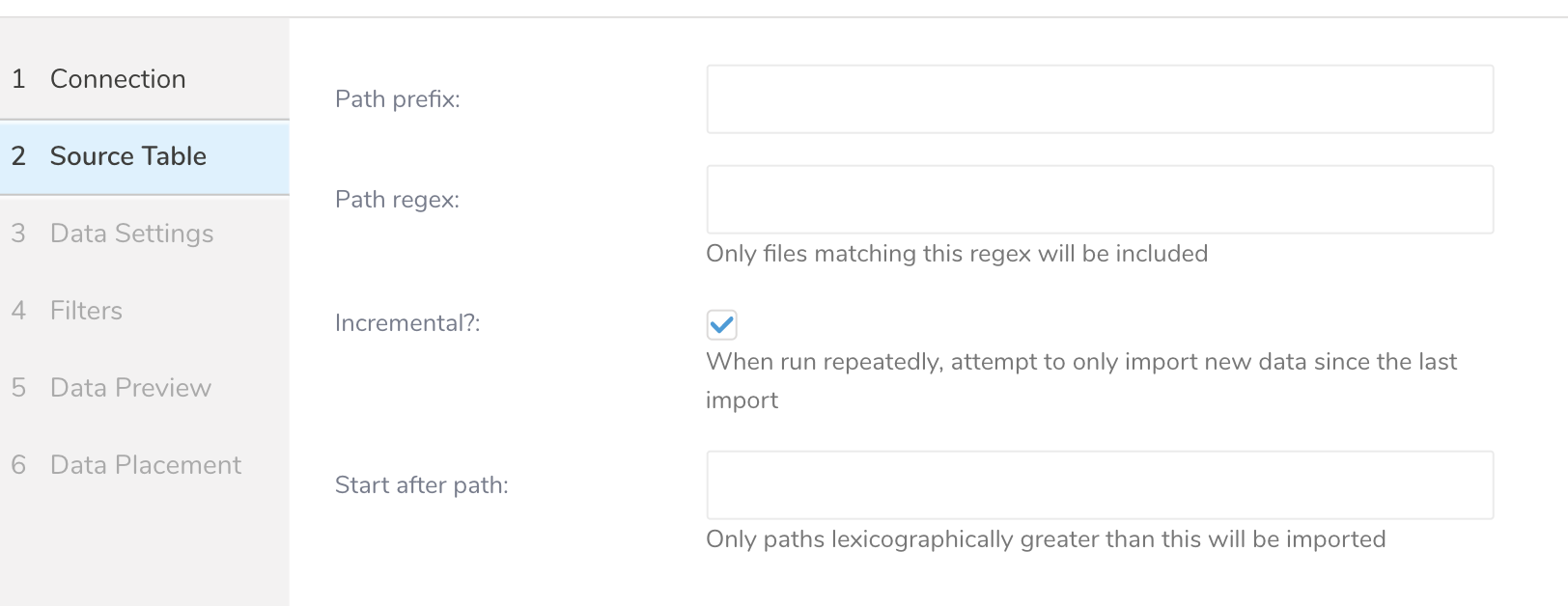
- 以下のパラメータを編集します:
| パラメータ | 説明 |
|---|---|
| Path prefix | ターゲットファイルのプレフィックス(文字列、必須)。例:resultoutputtest。 |
| Path regex | ファイルパスをクエリするための正規表現を入力します。ファイルパスが指定されたパターンと一致しない場合、そのファイルはスキップされます。例えば、パターン.csv$#を指定した場合、ファイルのパスがパターンと一致しない場合、そのファイルはスキップされます。 |
| Incremental | インクリメンタル読み込みを有効にします(ブール値)、オプション。デフォルト:true。インクリメンタル読み込みが有効な場合、次回実行のconfig diffにはlast_pathパラメータが含まれるため、次回実行ではそのパスより前のファイルがスキップされます。それ以外の場合、last_pathは含まれません。 |
| Start after path | これより辞書順で大きいパスのみがインポートされます。 |
- Nextを選択します。
Data Settingsページは、必要に応じて変更できます。または、このページをスキップすることもできます。
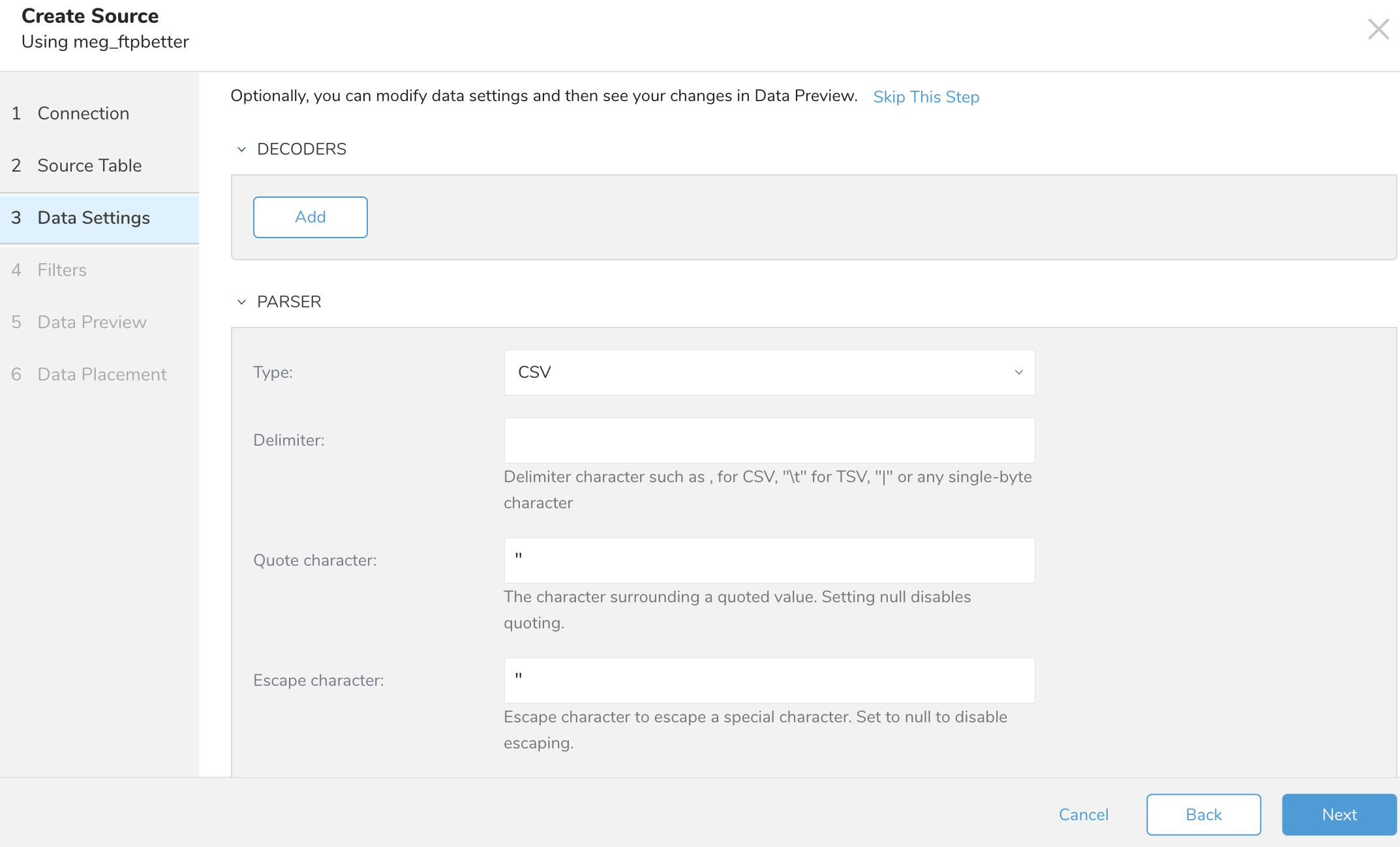
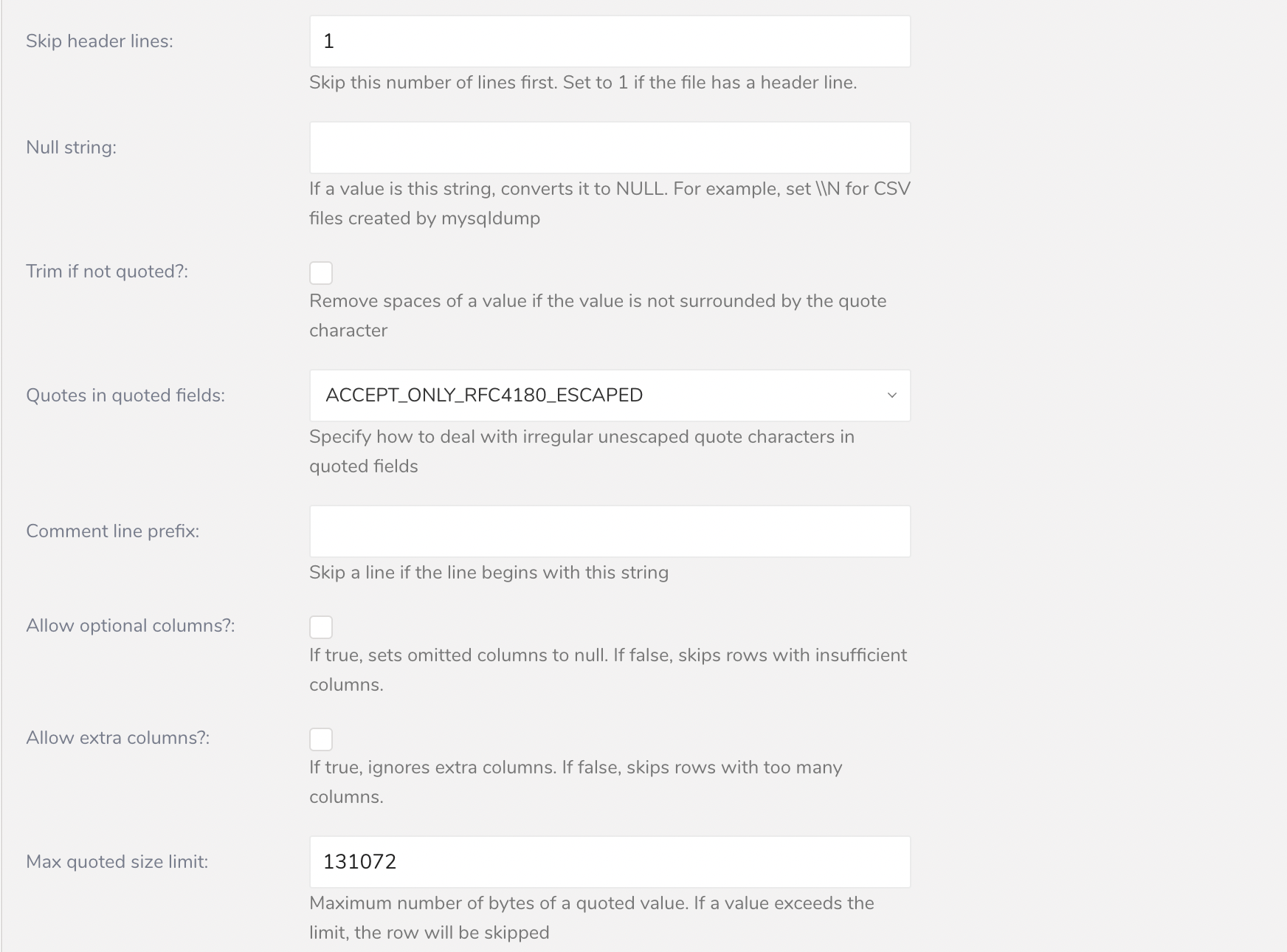
必要に応じて、パラメータを編集します。
Nextを選択します。
Filters は、S3、FTP、または SFTP コネクターの Create Source または Edit Source インポート設定で使用できます。
Import Integration Filters を使用すると、インポート用のデータ設定の編集を完了した後、インポートされたデータを変更できます。
import integration filters を適用するには:
- Data Settings で Next を選択します。Filters ダイアログが開きます。
- 追加したいフィルターオプションを選択します。
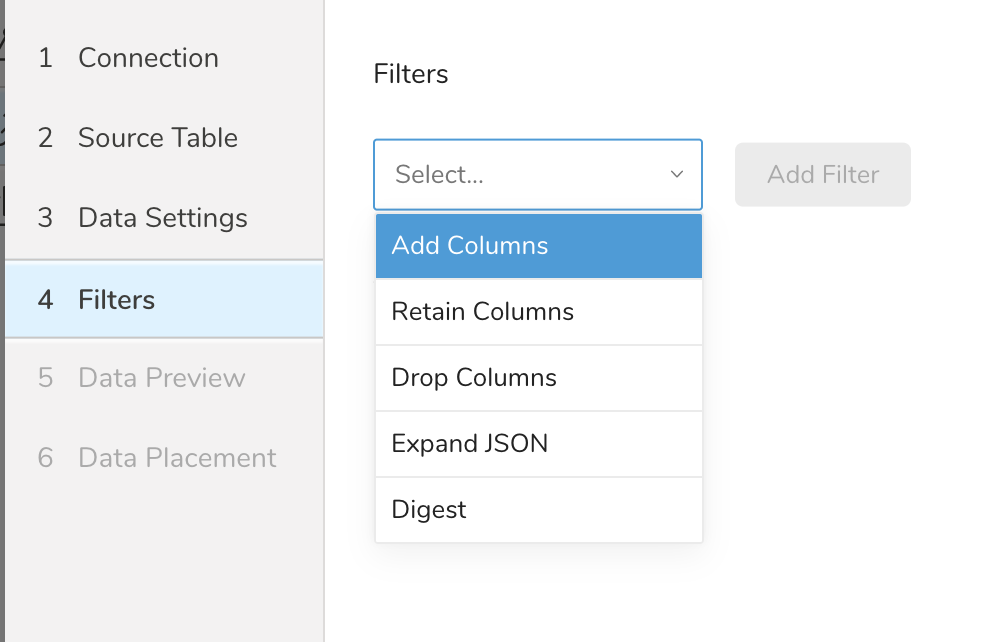
- Add Filter を選択します。そのフィルターのパラメーターダイアログが開きます。
- パラメーターを編集します。各フィルタータイプの情報については、次のいずれかを参照してください:
- Retaining Columns Filter
- Adding Columns Filter
- Dropping Columns Filter
- Expanding JSON Filter
- Digesting Filter
- オプションで、同じタイプの別のフィルターを追加するには、特定の列フィルターダイアログ内で Add を選択します。
- オプションで、別のタイプの別のフィルターを追加するには、リストからフィルターオプションを選択して、同じ手順を繰り返します。
- 追加したいフィルターを追加した後、Next を選択します。Data Preview ダイアログが開きます。
インポートを実行する前に、Generate Preview を選択してデータのプレビューを表示できます。Data preview はオプションであり、選択した場合はダイアログの次のページに安全にスキップできます。
- Next を選択します。Data Preview ページが開きます。
- データをプレビューする場合は、Generate Preview を選択します。
- データを確認します。
データの配置について、データを配置したいターゲット database と table を選択し、インポートを実行する頻度を指定します。
Next を選択します。Storage の下で、インポートされたデータを配置する新しい database を作成するか、既存の database を選択し、新しい table を作成するか、既存の table を選択します。
Database を選択 > Select an existing または Create New Database を選択します。
オプションで、database 名を入力します。
Table を選択 > Select an existing または Create New Table を選択します。
オプションで、table 名を入力します。
データをインポートする方法を選択します。
- Append (デフォルト) - データインポートの結果は table に追加されます。 table が存在しない場合は作成されます。
- Always Replace - 既存の table の全体の内容をクエリの結果出力で置き換えます。table が存在しない場合は、新しい table が作成されます。
- Replace on New Data - 新しいデータがある場合のみ、既存の table の全体の内容をクエリの結果出力で置き換えます。
Timestamp-based Partition Key 列を選択します。 デフォルトキーとは異なるパーティションキーシードを設定したい場合は、long または timestamp 列をパーティショニング時刻として指定できます。デフォルトの時刻列として、add_time フィルターで upload_time を使用します。
データストレージの Timezone を選択します。
Schedule の下で、このクエリを実行するタイミングと頻度を選択できます。
- Off を選択します。
- Scheduling Timezone を選択します。
- Create & Run Now を選択します。
- On を選択します。
- Schedule を選択します。UI では、@hourly、@daily、@monthly、またはカスタム cron の 4 つのオプションが提供されます。
- Delay Transfer を選択して、実行時間の遅延を追加することもできます。
- Scheduling Timezone を選択します。
- Create & Run Now を選択します。
転送が実行された後、Data Workbench > Databases で転送の結果を確認できます。
ジョブログを確認してください。警告とエラーは、インポートの成功に関する情報を提供します。例えば、インポートエラーに関連するソースファイル名を特定することができます。
Treasure Workflow内では、このデータコネクタを使用してデータをエクスポートするように指定できます。
詳細については、TD Toolbeltを使用してワークフローでデータをエクスポートするをご覧ください。
timezone: UTC
schedule:
daily>: 02:00:00
sla:
time: 08:00
+notice:
mail>: {data: Treasure Workflow Notification}
subject: This workflow is taking long time to finish
to: [meg@example.com]
_export:
td:
dest_db: dest_db
dest_table: dest_table
ftp:
ssl: true
ssl_verify: false
+prepare_table:
td_ddl>:
database: ${td.dest_db}
create_tables: ["${td.dest_table}"]
+load_step:
td_load>: config/daily_load.yml
database: ${td.dest_db}
table: ${td.dest_table}