Gigya(SAP Customer Data Cloud)から Accounts、Profile Management、Data Store、Audit Log のデータを Treasure Data に取り込むことができます。
- TD toolbelt を含む Treasure Data の基礎知識
- Gigya アカウント
- Accounts オブジェクトからデータを取得するための Query Syntax Specification に関する基礎知識
- 増分ロードについて を確認してください
増分ロードは、指定された増分列の最大値(max value)を使用して、最初の実行時には最大値までのすべてのレコードをロードし、以降の実行では前回の実行の(最大値 +1)から、ジョブが実行される現在の時刻までのレコードをインポートします。これが新しい最大値となります。
- Select 句
- From 句
- Where 句
- Group By 句
- START、CONTAINS、WITH キーワードはサポートされていません
- COUNTERS はサポートされていません
- クエリ内の LIMIT 句は自動的に削除されます(SELECT * FROM ACCOUNTS LIMIT 100)は制限を無視してすべてのレコードを返します
- 集計関数(sum, min, max, avg, sum_of_squares, variance, std)と Group By 句を含むクエリは、最初のページのみ取り込むことができます
- FROM 句に無効なオブジェクトを入力した場合(例:SELECT * FROM unexisted)、クエリは自動的に accounts オブジェクトにフォールバックします
- カラム名は大文字と小文字を区別し、オブジェクト名は大文字と小文字を区別しません
Treasure Data は、Gigya 向けに以下の SQL クエリ構文をサポートしています:
- Select 句
- From 句
- Where 句
- Group By 句
- START、CONTAINS、WITH キーワードはサポートされていません。
- COUNTERS はサポートされていません。
- クエリ内の LIMIT 句は自動的に削除されます。 SELECT * FROM ACCOUNTS LIMIT 100 はすべてのレコードを返し、制限を無視します。
- 集計関数(sum, min, max, avg, sum_of_squares, variance, std)と Group By 句を含むクエリは、最初のページのみ取り込むことができます。
- カラム名は大文字と小文字を区別します。
- オブジェクト名は大文字と小文字を区別しません。
- 増分列は数値型またはタイムスタンプ型である必要があります。
- データクエリは、accounts と email accounts の 2 つのオブジェクトに制限されます。
- FROM 句に無効なオブジェクトを入力すると、クエリは自動的に accounts オブジェクトにフォールバックします。 例:
SELECT * FROM does_not_existは、does_not_existを accounts に置き換えます。 - accounts オブジェクトでサポートされる増分列:[lastLogin, registered, oldestDataUpdatedTimestamp, lastUpdated, verifiedTimestamp, oldestDataUpdated, lastUpdatedTimestamp, created, createdTimestamp, verified, registeredTimestamp, lastLoginTimestamp, lockedUntil]
- emailAccounts でサポートされる増分列:[lastUpdated, lastUpdatedTimestamp, created, createdTimestamp]
- 参考リンク:accounts.search REST
- データクエリは、accounts と email accounts の 2 つのオブジェクトに制限されます。
- FROM 句に無効なオブジェクトを入力すると、クエリは自動的に accounts オブジェクトにフォールバックします。 例:
SELECT * FROM does_not_existは、does_not_existを accounts に置き換えます。 - accounts オブジェクトでサポートされる増分列:[lastLogin, registered, oldestDataUpdatedTimestamp, lastUpdated, verifiedTimestamp, oldestDataUpdated, lastUpdatedTimestamp, created, createdTimestamp, verified, registeredTimestamp, lastLoginTimestamp, lockedUntil]
- emailAccounts でサポートされる増分列:[lastUpdatedTimestamp, created, createdTimestamp, lastUpdated]
- 参考リンク:ids.search REST
- FROM 句に無効なオブジェクトを入力すると、エラー [400006] Invalid parameter value: Invalid argument: accounts type not allowed が返されます
- ターゲット Data Store のスキーマに応じて、増分列は異なります。ただし、無効なカラム名を入力すると、TD Console からのエラーで許容されるカラム名を確認できます。
- 参考リンク:ds.search REST
- サポートされる増分列:[@timestamp]
- 参考リンク:audit.search
増分ロードは、指定された増分列の最大値(max value)を使用して、最初の実行時には最大値までのすべてのレコードをロードし、以降の実行では前回の実行の(最大値 +1)から、ジョブが実行される現在の時刻(これが新しい最大値になります)までのレコードをインポートします。
サポート対象:
- 数値型またはタイムスタンプ型の増分列
- Accounts オブジェクトの増分列:[lastUpdated, lastUpdatedTimestamp, created, createdTimestamp]
- EmailAccounts の増分列: [lastLogin, registered, oldestDataUpdatedTimestamp, lastUpdated, verifiedTimestamp, oldestDataUpdated, lastUpdatedTimestamp, created, createdTimestamp, verified, registeredTimestamp, lastLoginTimestamp, lockedUntil]
- auditLog でサポートされる増分列:[@timestamp]
- Creating and Managing Applications の手順に従って、アプリケーションを作成し、App User Key と Secret Key を取得します。
- API Key and Site Setup の手順に従って、API Key を取得します。
- 手順に従って Data Center を確認します。
データ接続を設定する際には、連携にアクセスするための認証情報を提供します。Treasure Data では、まず認証を設定してから、ソース情報を指定します。
TD Console を開きます。
Integrations Hub -> Catalog に移動します。
Gigya(SAP Customer Data Cloud)を検索して選択します。

以下のダイアログが開きます。
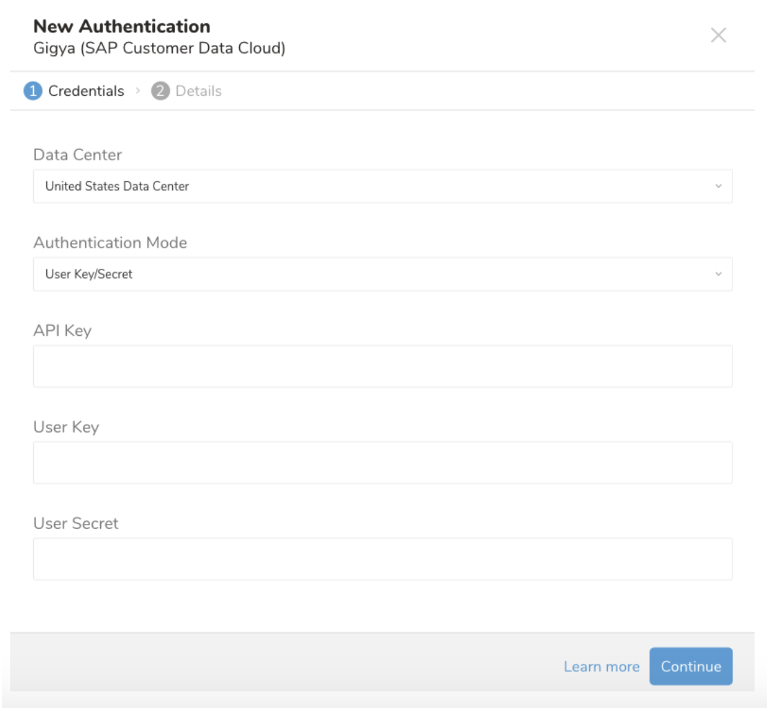
アカウントの Data Center を選択します。
以下の値を入力します:
- API Key
- User Key
- User Secret
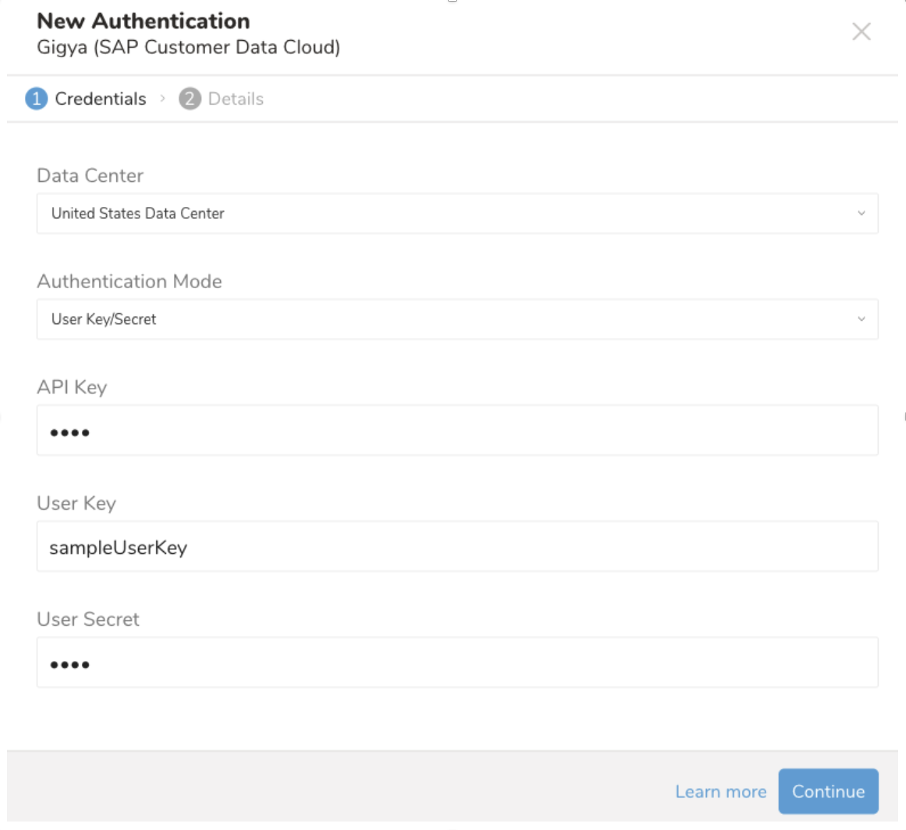
Continue を選択します。
接続の名前を入力し、Done を選択します。
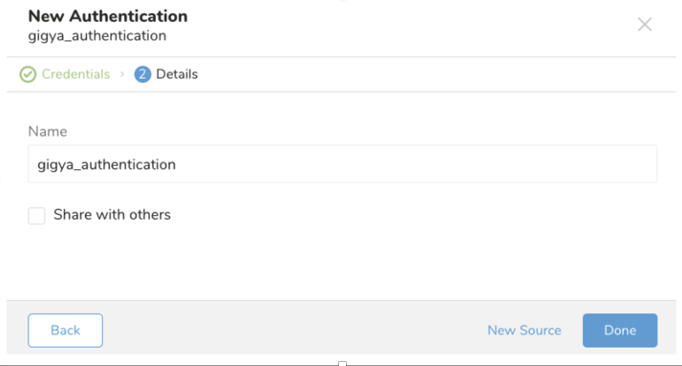
認証された接続を作成すると、自動的に Authentications タブに移動します。
- 作成した接続を検索し、New Source を選択します。

Source に名前を付けます。
Next を選択します。
Source Table でパラメータを編集します。
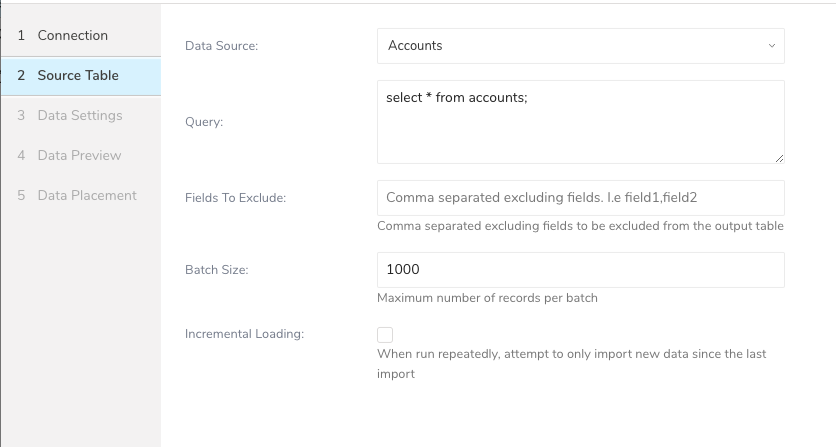
| パラメータ | 説明 |
|---|---|
| Data Source | ターゲットデータソース。現在サポート対象:Accounts、Profile Management、Data Store、Audit Log |
| Query | データを取り込むための Gigya のクエリ。ターゲットオブジェクトによって、クエリは異なります。 Account と Profile Management データソースの場合、accounts と emailAccounts オブジェクトのみサポート(サンプルクエリ:Select * From accounts) Data Store の場合、オブジェクトは任意(サンプルクエリ:Select * From my_data) Audit Log の場合、auditLog オブジェクトのみサポート(サンプルクエリ:Select * From auditLog) |
| Fields To Exclude | Gigya の API 仕様により、SELECT ステートメントに含めるカラムを指定することはできません。このパラメータを使用して、不要なカラムを削除できます。 |
| Batch Size | 1 回の API 呼び出しで取得するレコードの最大数。最大値は 10000、最小値は 10 です。バッチサイズをカスタマイズする際は、以下を考慮してください:小さい値にすると API の応答は速くなりますが、API 呼び出しの回数が増えます。 |
| Incremental | スケジュールで実行する場合、次回のインポートでは、Incremental Column の値に基づいて、前回の実行後に更新されたデータのみを取り込みます。 |
| Incremental Column | 増分転送を実行するデータオブジェクトのカラム。 Account と Profile Management データソースの場合、推奨値:created、createdTimestamp、updated、updatedTimestamp。 Data Store データソースの場合、推奨値:数値型または日時型のカラム Audit Log データソースの場合、推奨値:@timestamp |
- Data Settings ダイアログで、データ設定を編集するか、このステップをスキップできます。
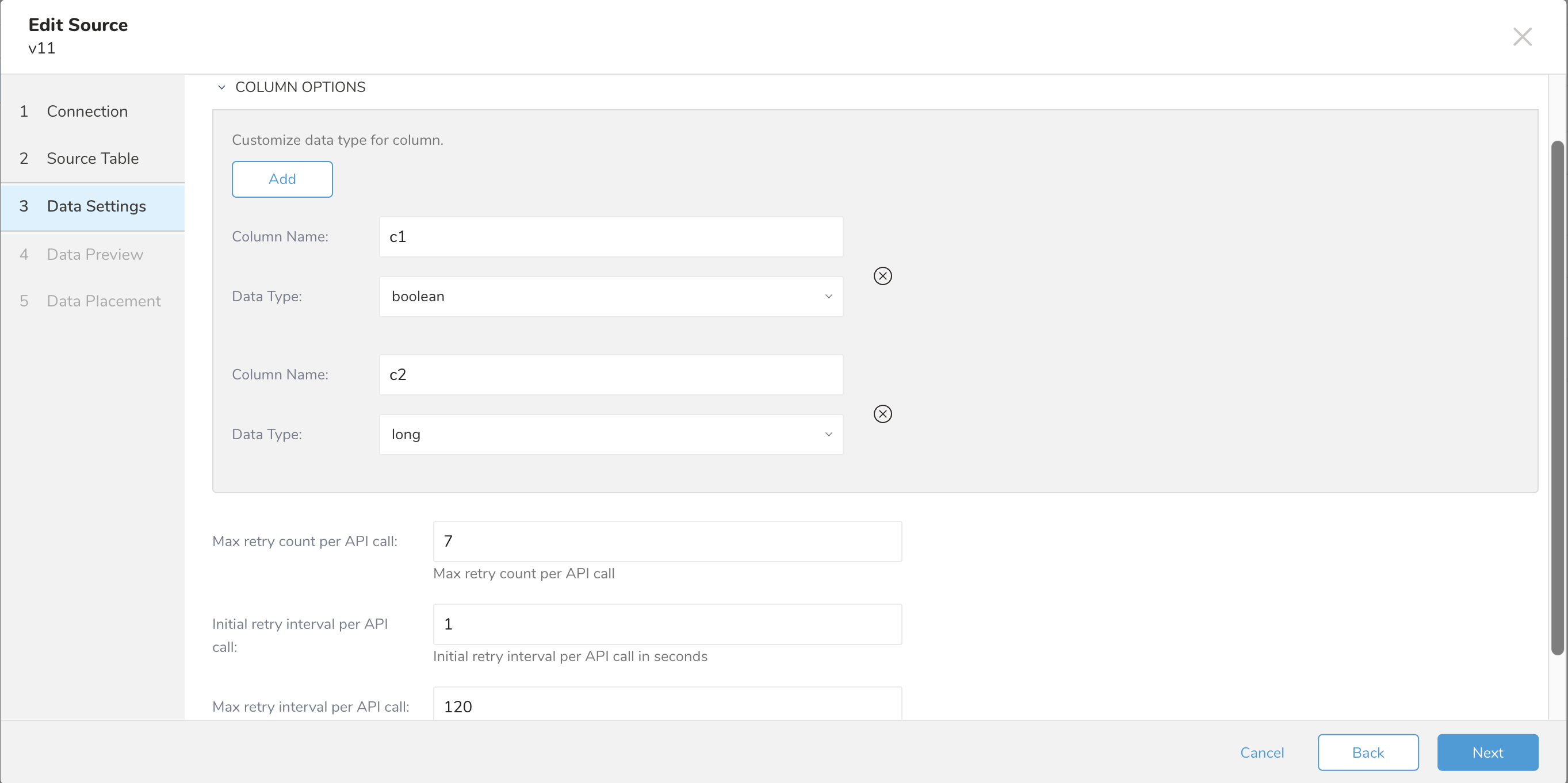
デフォルトでは、コネクタはデータ型を自動的に検出できます。ただし、ユーザーは column_options パラメータを使用して、インポート属性フィールドのデータ型をカスタマイズできます。サポートされるデータ型のマッピング:
- boolean
- long
- double
- string
- timestamp
- json
インポートを実行する前に、Generate Preview を選択してデータのプレビューを表示できます。Data preview はオプションであり、選択した場合はダイアログの次のページに安全にスキップできます。
- Next を選択します。Data Preview ページが開きます。
- データをプレビューする場合は、Generate Preview を選択します。
- データを確認します。
データの配置について、データを配置したいターゲット database と table を選択し、インポートを実行する頻度を指定します。
Next を選択します。Storage の下で、インポートされたデータを配置する新しい database を作成するか、既存の database を選択し、新しい table を作成するか、既存の table を選択します。
Database を選択 > Select an existing または Create New Database を選択します。
オプションで、database 名を入力します。
Table を選択 > Select an existing または Create New Table を選択します。
オプションで、table 名を入力します。
データをインポートする方法を選択します。
- Append (デフォルト) - データインポートの結果は table に追加されます。 table が存在しない場合は作成されます。
- Always Replace - 既存の table の全体の内容をクエリの結果出力で置き換えます。table が存在しない場合は、新しい table が作成されます。
- Replace on New Data - 新しいデータがある場合のみ、既存の table の全体の内容をクエリの結果出力で置き換えます。
Timestamp-based Partition Key 列を選択します。 デフォルトキーとは異なるパーティションキーシードを設定したい場合は、long または timestamp 列をパーティショニング時刻として指定できます。デフォルトの時刻列として、add_time フィルターで upload_time を使用します。
データストレージの Timezone を選択します。
Schedule の下で、このクエリを実行するタイミングと頻度を選択できます。
- Off を選択します。
- Scheduling Timezone を選択します。
- Create & Run Now を選択します。
- On を選択します。
- Schedule を選択します。UI では、@hourly、@daily、@monthly、またはカスタム cron の 4 つのオプションが提供されます。
- Delay Transfer を選択して、実行時間の遅延を追加することもできます。
- Scheduling Timezone を選択します。
- Create & Run Now を選択します。
転送が実行された後、Data Workbench > Databases で転送の結果を確認できます。