Adobe Analytics Import Integration v2を使用すると、Adobe Analyticsによって生成されたdata feedをネイティブconnectorを通じてTreasure dataに直接取り込むことができます。Adobe Analyticsユーザーが利用するクラウドストレージサービスとの柔軟性が向上しています。
Adobe Analyticsは、組織がデジタル顧客インタラクションからデータを収集し、実用的なインサイトを得ることを可能にします。詳細については、Adobe experience league docsを参照してください。
- TD Toolbeltを含むTreasure Dataの基本知識。
- Adobe Analyticsの基本知識
セキュリティポリシーで IP ホワイトリストが必要な場合は、接続を成功させるために Treasure Data の IP アドレスを許可リストに追加する必要があります。
リージョンごとに整理された静的 IP アドレスの完全なリストは、次のリンクにあります: https://api-docs.treasuredata.com/en/overview/ip-addresses-integrations-result-workers/
connectorはdata sourceとしてクラウドストレージサービスをサポートしています。data sourceにアクセスするには、authenticationを設定する必要があります。
- Integrations Hubを選択します。
- Catalogを選択します。
- 名前"Adobe Analytics V2"でCatalog内のIntegrationを検索するか、カテゴリ"Web/Mobile analytics services"および/または"Business Intelligence"でフィルタリングします。
- アイコンにマウスを合わせ、Create Authenticationを選択します。
- Adobe Analyticsからdata feedを受信するクラウドサービスに対応するStorage Typeを選択します。
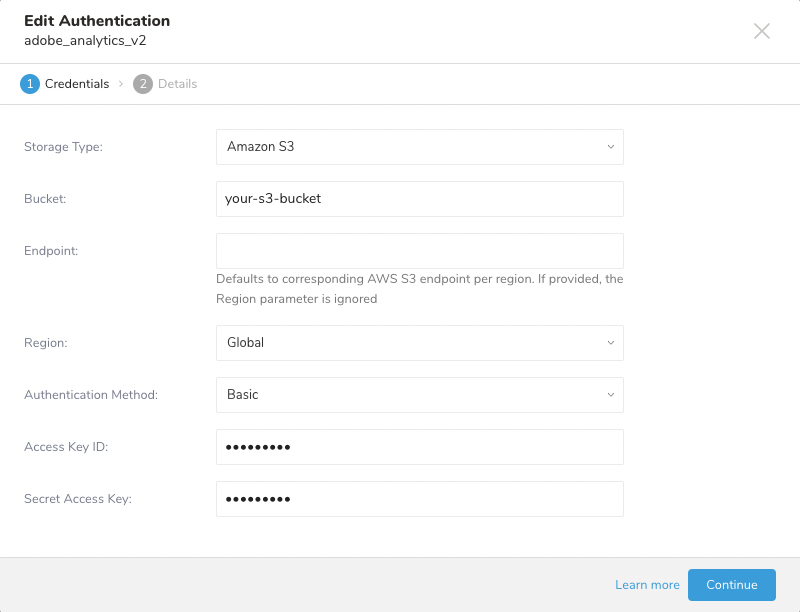
- Bucket情報を入力します。
- Endpointを入力します。または、そのリージョンのデフォルトendpointを使用する場合はRegionを選択します。
- Authentication Methodを選択します。選択したStorage Typeに応じて、さまざまな方法がサポートされています。例えば、Amazon S3の場合、connectorは以下をサポートしています:
- Basic
- Session Token
- Assume Role
- 選択したAuthentication Methodに応じて必要な認証情報を入力します。
Storage Type: 現在、選択可能なのはAmazon S3のみです。他のサービスのサポートは将来の実装を予定しており、ロードマップに記載されています。
file loaderはbucketルート直下に保存されているファイルをサポートしていません。
file loaderによるパフォーマンスと認識を向上させるために、異なるreport suiteのdata feedは別々のディレクトリに保存することをお勧めします。file loaderによる認識を向上させるために、ディレクトリ名には正規化された英数字を使用することをお勧めします。

connectorはdata feed内のhitファイルとlook upファイルの両方の取り込みをサポートしています。
file loaderはReport Suite IDとPath Prefixを使用してdata feedファイルを検索します。複数のdata feedが見つかった場合、最も古いfeedが選択され、job実行ごとに1つのfeedのみが処理されます。
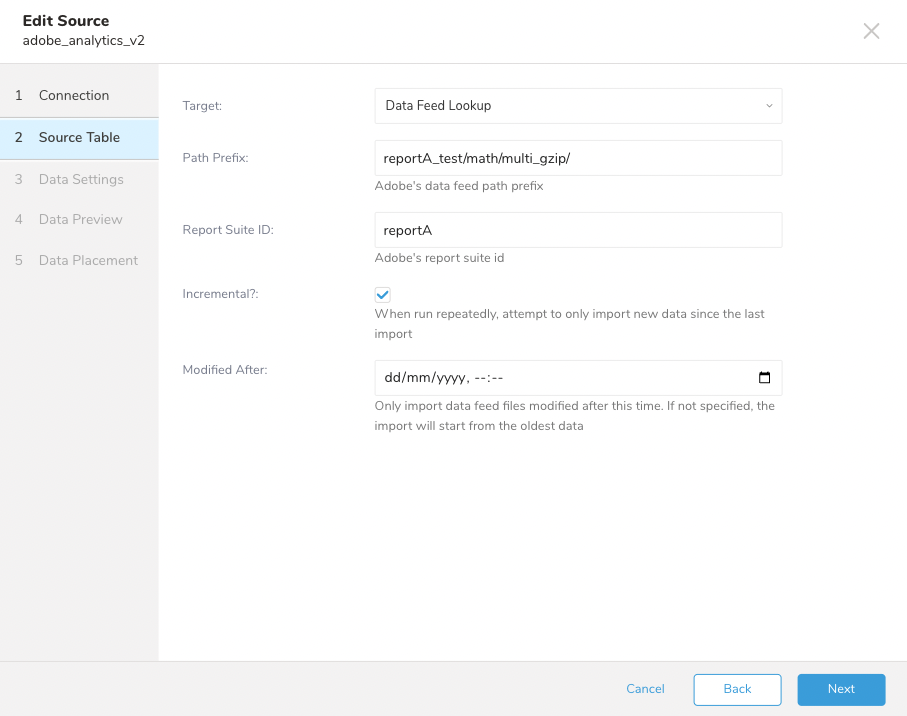
- Targetはインポートするデータのタイプです。
- Data Feed: hitファイルをインポートします。
- Look Up Data: look upファイルをインポートします。
- TargetとしてData Feed Dataを選択します。
- bucket内の目的のディレクトリへのPath Prefixを入力します。
- Report Suite IDを入力します。
- Incrementalを選択します。このオプションを有効にすると、import jobは前回の実行タイムスタンプ以降にbucketにアップロードされたファイルのみを検索します。
- Modified After。このオプションは古いdata feedをフィルタリングするために使用します
Incrementalと適切なjobスケジュールを使用して、次のjob実行時にAdobe Analyticsによって配信される正しいdata feedが選択されるようにすることをお勧めします。
Look-upファイルをdatabaseにインポートして、後続のqueryと分析を容易にできます。
- Source Tableで、TargetをLook Up Dataに設定します。
lookup_type (filename without extenstion); key (1st column) ; value (2nd column) ; source (datafeed name)
browser ; 1 ; chrome ; treasuredata_20240101-120000
browser ; 2 ; IE ; treasuredata_20240101-120000
country ; 1 ; Afghanistan ; treasuredata_20240101-120000
country ; 2 ; Albania ; treasuredata_2024-01-01
country ; 3 ; Algeria ; treasuredata_2024-01-01
resolution ; 1 ; 320 x 200 ; ...
resolution ; 2 ; 640 x 240 ; ...
.........以下の手順に従って、詳細設定、data placement、jobのスケジュールを設定してください。
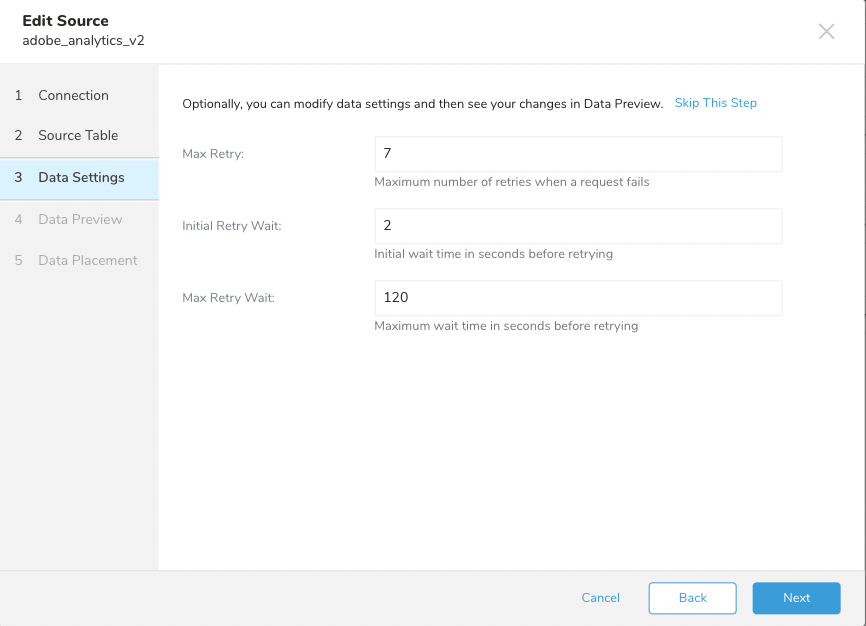
connectorは、初回リクエストが失敗した場合の再試行をサポートしています。再試行は、hitファイルは見つかったがlook upファイルが見つからない場合にのみ行われます。次の再試行時間はExponential Backoffルールに従って決定されます。ユーザーは以下を設定できます:
- Max Retry: 最大再試行回数。デフォルトは7です。
- Initial Retry Wait: 初回の待機時間(秒単位)。デフォルトは2です。
- Max Retry Wait: 次の再試行前の最大許容待機時間。
hitデータはクリックの生データであるため、connectorはこの画面でダミー値のみを表示します。 
ユーザーは、データをインポートするdatabaseとtableを設定できます。 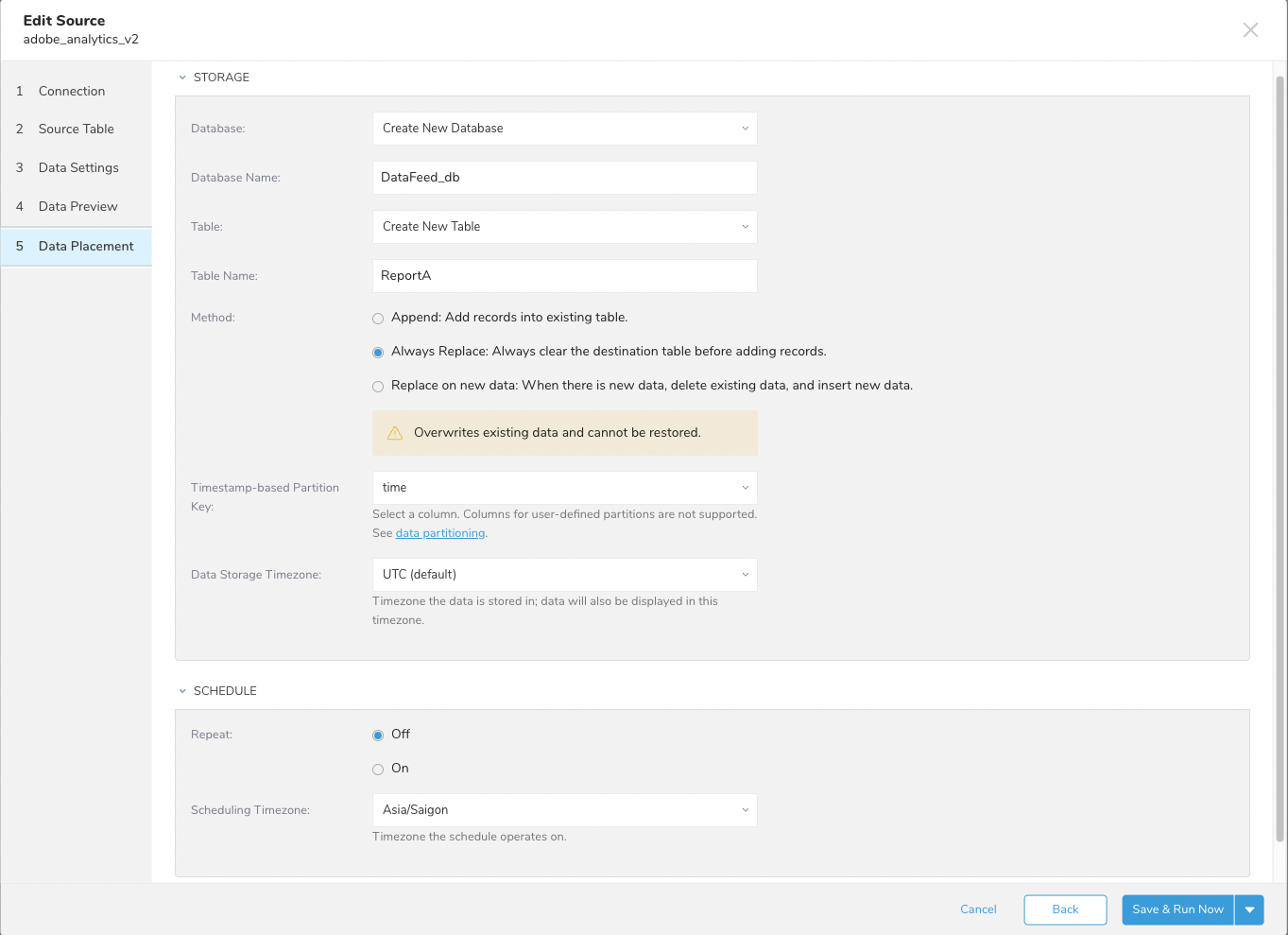
- Database****and Table: 宛先を選択するか、新しいものを作成します。
- Database情報を入力します。
- Table情報を入力します。
- 保存Methodを選択します。
- Append
- Always replace
- Replace on new data.
- Timestamp-based Partition Keyを選択します。
Schedule:
- Repeatを設定します
- On: スケジュールを設定します。
- Off
- Schedule Timezoneを設定します。スケジュールタイムスタンプのタイムゾーン参照を選択します。