HubSpot Import Integrationについて詳しく知る。
Treasure DataからHubSpot Marketing Cloudへ直接データをエクスポートできます。HubSpotは、マーケティング、営業、カスタマーサービスを連携するために必要なソフトウェア、インテグレーション、リソースを備えたAI搭載のカスタマープラットフォームです。
- toolbeltを含むTreasure Dataの基本的な知識。
- Treasure Dataに権限を付与できるHubSpotアカウント。
null の company_id を繰り返し送信すると、会社レコードの重複が発生します。データのスキップを許可する代わりにレコードの作成を指定した場合、NULL の company_id またはHubSpot上に存在しない company_id により、HubSpot上で新しい company_id を持つ会社レコードが作成されます。同じ結果セットに対して同じクエリを再実行すると、重複したレコードが表示されます。
この制限を解決するには、次回の実行前に company_id の値を取り込み、Treasure Data内の既存レコードを重複排除して、これらの重複を減らしてください。
セキュリティポリシーで IP ホワイトリストが必要な場合は、接続を成功させるために Treasure Data の IP アドレスを許可リストに追加する必要があります。
リージョンごとに整理された静的 IP アドレスの完全なリストは、次のリンクにあります: https://api-docs.treasuredata.com/en/overview/ip-addresses-integrations-result-workers/
HubSpotポータルで Automatically create and associate companies with contacts の設定を有効にして、コンタクトが会社に自動的に関連付けられるようにする必要があります。
一括挿入/更新機能を無効にする場合は、まずターゲットのContactsを使用してコンタクトを作成する必要があります。各会社のデータは、HubSpotポータルの Automatically create and associate companies with contacts 設定がオンかオフかに関わらず、自動的に作成されます。
詳細については、Create or update a group of the contacts pageを参照してください。
Treasure Dataでは、クエリを実行する前に、エクスポート時に使用するデータコネクションを作成および設定する必要があります。データコネクションの一部として、インテグレーションにアクセスするための認証を提供します。
TD Consoleを開きます。
Integrations Hub > Catalog に移動します。
Hubspotを検索して選択します。

次のダイアログが開きます。
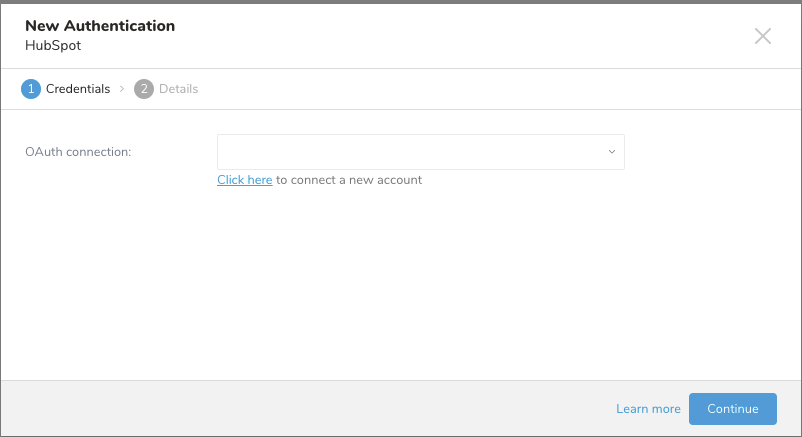
- Click here to connect to a new account. を選択します。
まだログインしていない場合はHubspotにログインするためのページへ、またはTreasure Dataへのアクセス許可を付与する同意ページにリダイレクトされます。
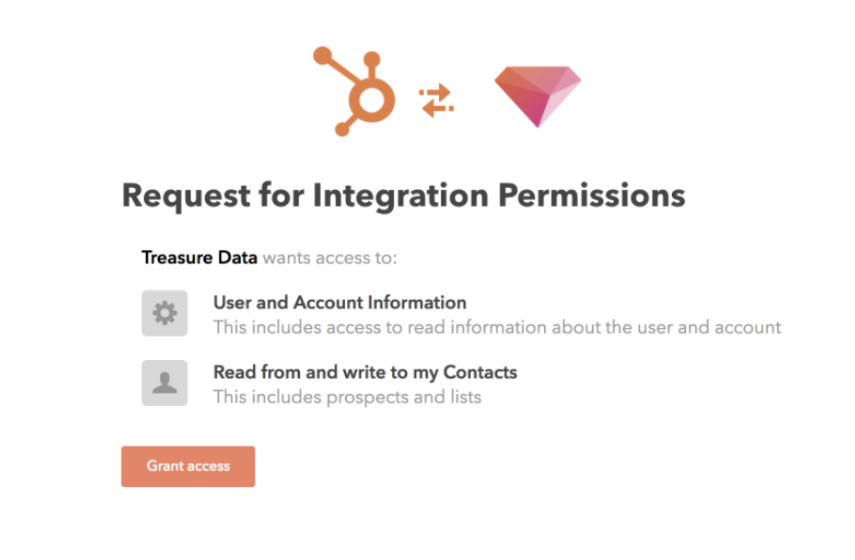
Treasure Dataへのアクセスを許可すると、TD Consoleにリダイレクトされます。
Integrations Hub > Catalog に移動します。
再度Hubspotを選択します。
New Authenticationダイアログが開きます。
ドロップダウンリストからアカウント名を含むOAuth接続を選択します。
Continue を選択します。
接続に名前を付けます。
Done を選択します。
- Creating a Destination Integrationの手順を完了します。
- Data Workbench > Queries に移動します。
- データをエクスポートしたいクエリを選択します。
- クエリを実行して結果セットを検証します。
- Export Results を選択します。
- 既存のインテグレーション認証を選択します。
- 追加のExport Resultsの詳細を定義します。エクスポートインテグレーションの内容で、インテグレーションパラメータを確認してください。 例えば、Export Results画面が異なる場合や、追加で入力する詳細がない場合があります:
- Done を選択します。
- クエリを実行します。
- 指定した宛先にデータが移動したことを検証します。
宛先の選択内容によって、パラメータは異なります。次の表は、すべての可能なパラメータを示しています。
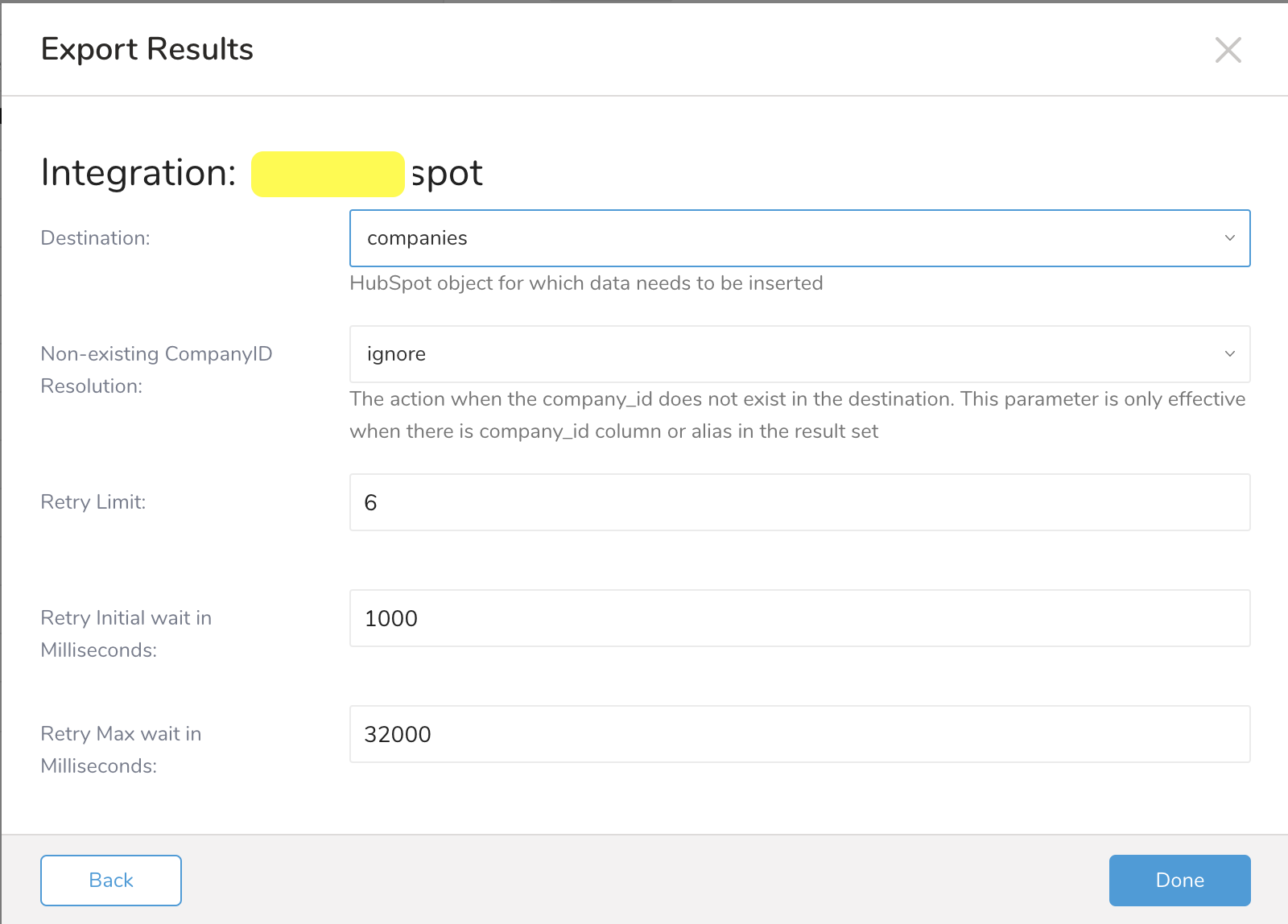
以下のパラメータを編集し、Doneを選択します。
次の表は、HubSpotエクスポートの統合パラメータを説明しています:
| CLIパラメータ | パラメータタイプ | サンプル値 | UI説明 | 説明 | 必須カラム |
|---|---|---|---|---|---|
| Enum ( |
| Destination | 作成または更新するHubSpotオブジェクトを選択します:
|
|
resolution_mode | Enum (ignore, create) | ignore | Non-existing CompanyID Resolution | HubSpotにcompany_idが存在しない行の処理方法を指定します。 | |
enable_batch | Boolean | false | Enable batch insert | コンタクトプロパティをエクスポートする際に、レコードをバッチで挿入または更新する場合に切り替えます。行レベルのエラーが発生すると、バッチ全体が停止します。 | |
skip_creating_company | Boolean | false | Skip creating companies by email domain | コンタクトのメールドメインからの企業の自動作成を防止します。 | |
list_name | String | hubspot_list | List Name | targetがcontact_listの場合に必須。HubSpotリスト名を指定します。 | |
contact_list_action | Enum (add, remove) | add | Action | targetがcontact_listの場合に必須。コンタクトをリストに追加するか、リストから削除するかを選択します。 | |
retry_limit | Integer | 3 | Retry Limit (optional) | エクスポートが停止するまでの最大再試行回数。 | |
retry_initial_wait_msec- Integer | 10000 | 初回リトライ待機時間(ミリ秒)(オプション) | 最初の試行と2回目の試行の間の遅延時間。 | ||
max_retry_wait_msec | Integer | 300000 | 最大リトライ待機時間(ミリ秒)(オプション) | 2回目以降の試行の間の遅延時間。 |
この機能には追加のHubSpot APIスコープが必要です。2024年10月2日以前に作成された認証の場合は、認証を再作成してください。
contact_list_actionがaddに設定されている場合、コネクタはリストが存在しない場合に自動的にリストを作成します。removeはリストからコンタクトを削除するだけで、コンタクト自体は削除されません。
このコネクタはHubSpotのupsert APIを使用します。コンタクトが存在し、提供されたプロパティ値が現在の値と異なる場合、HubSpotはプロパティを更新します。更新する予定のプロパティのみをクエリに含めてください。そうしないと、新しいコンタクトが作成される可能性があります。
select 'test@edm.com' as EMAIL, 'tester' as firstname, 'll' as lastname, '650-000-1234' as phone, 'test' as address,
'a' as city, 'CA' as state, '60599' as zip-- firstnameの値を更新
select 'firstname' as name, 'test1@samplecom.com' as email, 'newContactName' as valueselect '1234567890' as company_id, 'www.testwebsite.com' as website-- nameの値を更新
select '1234567890' as company_id, 'name' as name, 'www.google.com' as website, 'NewCompanyName' as valueselect 'test@edm.com' as EMAIL, 'Jonh' as firstname, 'Doe' as lastname, '650-000-1234' as phone, 'test' as address, 'a' as city, 'CA' as state, '60599' as zipクエリの列名またはエイリアスとして使用するプロパティ名(例:firstname、lastname)は、HubSpotで定義された有効なコンタクトのプロパティと一致している必要があります。詳細についてはコンタクトのデフォルトプロパティを参照してください。プロパティの「内部名」を列名またはエイリアスとして渡す必要があることに注意してください。それを取得するには、プロパティ管理を参照してください。たとえば、「First name」フィールドの内部名は「firstname」であり、これをクエリ結果の列名またはエイリアスとして使用する必要があります。
Audience Studio で activation を作成することで、segment データをターゲットプラットフォームに送信することもできます。
- Audience Studio に移動します。
- parent segment を選択します。
- ターゲット segment を開き、右クリックして、Create Activation を選択します。
- Details パネルで、Activation 名を入力し、前述の Configuration Parameters のセクションに従って activation を設定します。
- Output Mapping パネルで activation 出力をカスタマイズします。

- Attribute Columns
- Export All Columns を選択すると、変更を加えずにすべての列をエクスポートできます。
- + Add Columns を選択して、エクスポート用の特定の列を追加します。Output Column Name には、Source 列名と同じ名前があらかじめ入力されます。Output Column Name を更新できます。+ Add Columns を選択し続けて、activation 出力用の新しい列を追加します。
- String Builder
- + Add string を選択して、エクスポート用の文字列を作成します。次の値から選択します:
- String: 任意の値を選択します。テキストを使用してカスタム値を作成します。
- Timestamp: エクスポートの日時。
- Segment Id: segment ID 番号。
- Segment Name: segment 名。
- Audience Id: parent segment 番号。
- + Add string を選択して、エクスポート用の文字列を作成します。次の値から選択します:
- Schedule を設定します。

- スケジュールを定義する値を選択し、オプションでメール通知を含めます。
- Create を選択します。
batch journey の activation を作成する必要がある場合は、Creating a Batch Journey Activation を参照してください。
Scheduled Jobs と Result Export を使用して、指定したターゲット宛先に出力結果を定期的に書き込むことができます。
Treasure Data のスケジューラー機能は、高可用性を実現するために定期的なクエリ実行をサポートしています。
2 つの仕様が競合するスケジュール仕様を提供する場合、より頻繁に実行するよう要求する仕様が優先され、もう一方のスケジュール仕様は無視されます。
例えば、cron スケジュールが '0 0 1 * 1' の場合、「月の日」の仕様と「週の曜日」が矛盾します。前者の仕様は毎月 1 日の午前 0 時 (00:00) に実行することを要求し、後者の仕様は毎週月曜日の午前 0 時 (00:00) に実行することを要求するためです。後者の仕様が優先されます。
Data Workbench > Queries に移動します
新しいクエリを作成するか、既存のクエリを選択します。
Schedule の横にある None を選択します。

ドロップダウンで、次のスケジュールオプションのいずれかを選択します:
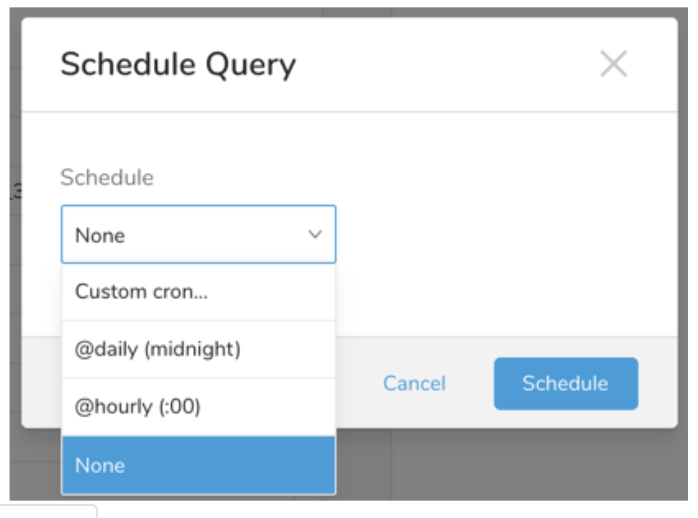
ドロップダウン値 説明 Custom cron... Custom cron... の詳細を参照してください。 @daily (midnight) 指定されたタイムゾーンで 1 日 1 回午前 0 時 (00:00 am) に実行します。 @hourly (:00) 毎時 00 分に実行します。 None スケジュールなし。
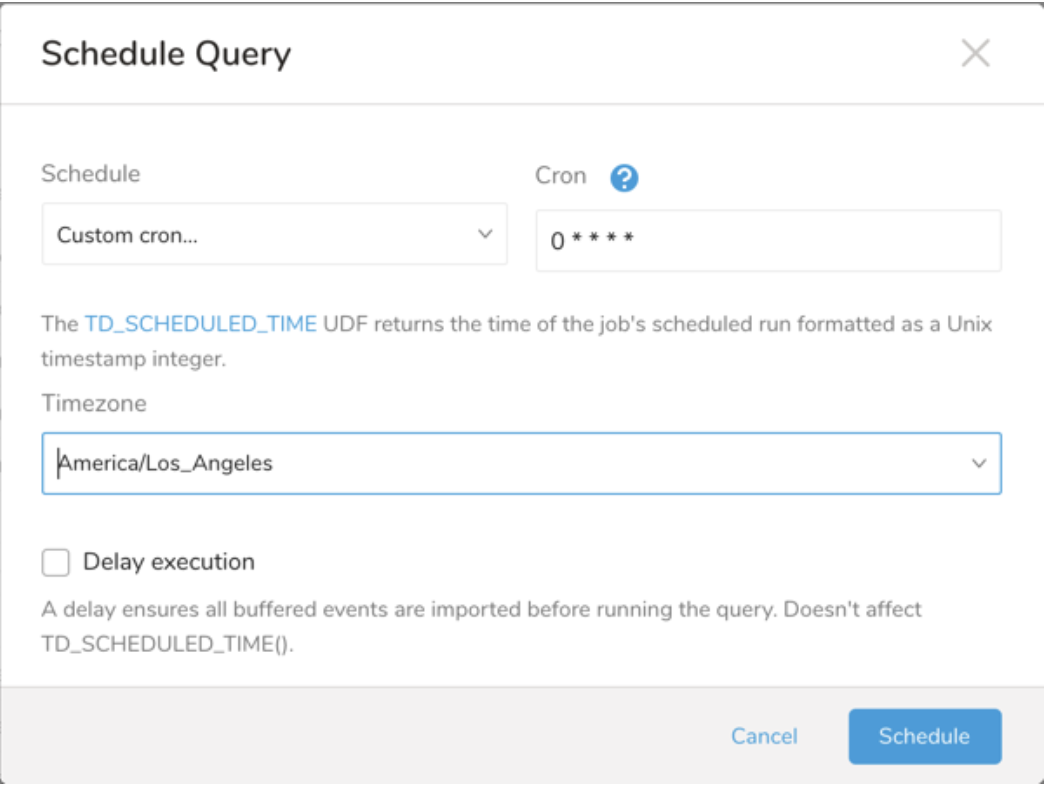
| Cron 値 | 説明 |
|---|---|
0 * * * * | 1 時間に 1 回実行します。 |
0 0 * * * | 1 日 1 回午前 0 時に実行します。 |
0 0 1 * * | 毎月 1 日の午前 0 時に 1 回実行します。 |
| "" | スケジュールされた実行時刻のないジョブを作成します。 |
* * * * *
- - - - -
| | | | |
| | | | +----- day of week (0 - 6) (Sunday=0)
| | | +---------- month (1 - 12)
| | +--------------- day of month (1 - 31)
| +-------------------- hour (0 - 23)
+------------------------- min (0 - 59)次の名前付きエントリを使用できます:
- Day of Week: sun, mon, tue, wed, thu, fri, sat.
- Month: jan, feb, mar, apr, may, jun, jul, aug, sep, oct, nov, dec.
各フィールド間には単一のスペースが必要です。各フィールドの値は、次のもので構成できます:
| フィールド値 | 例 | 例の説明 |
|---|---|---|
| 各フィールドに対して上記で表示された制限内の単一の値。 | ||
フィールドに基づく制限がないことを示すワイルドカード '*'。 | '0 0 1 * *' | 毎月 1 日の午前 0 時 (00:00) に実行するようにスケジュールを設定します。 |
範囲 '2-5' フィールドの許可される値の範囲を示します。 | '0 0 1-10 * *' | 毎月 1 日から 10 日までの午前 0 時 (00:00) に実行するようにスケジュールを設定します。 |
カンマ区切りの値のリスト '2,3,4,5' フィールドの許可される値のリストを示します。 | 0 0 1,11,21 * *' | 毎月 1 日、11 日、21 日の午前 0 時 (00:00) に実行するようにスケジュールを設定します。 |
周期性インジケータ '*/5' フィールドの有効な値の範囲に基づいて、 スケジュールが実行を許可される頻度を表現します。 | '30 */2 1 * *' | 毎月 1 日、00:30 から 2 時間ごとに実行するようにスケジュールを設定します。 '0 0 */5 * *' は、毎月 5 日から 5 日ごとに午前 0 時 (00:00) に実行するようにスケジュールを設定します。 |
'*' ワイルドカードを除く上記の いずれかのカンマ区切りリストもサポートされています '2,*/5,8-10' | '0 0 5,*/10,25 * *' | 毎月 5 日、10 日、20 日、25 日の午前 0 時 (00:00) に実行するようにスケジュールを設定します。 |
- (オプション) Delay execution を有効にすることで、クエリの開始時刻を遅延させることができます。
クエリに名前を付けて保存して実行するか、そのままクエリを実行します。クエリが正常に完了すると、クエリ結果は指定されたコンテナの送信先に自動的にインポートされます。
設定エラーにより継続的に失敗するスケジュールされたジョブは、複数回の通知後にシステム側で無効化される場合があります。
Treasure Workflow内で、このデータコネクタを使用してデータをエクスポートするよう指定できます。
詳細については、TD Toolbeltを使用したWorkflowでのデータエクスポートを参照してください。