Treasure DataからCriteo Marketing APIにジョブ結果を直接書き込むことができます。
Criteoは、クリエイティブな広告コントロール、ターゲティングオプション、メディアバイイングを1つのプラットフォームで提供します。
- TD Toolbeltを含むTreasure Dataの基本知識
- Criteo Marketing APIアカウント
- CriteoへのTreasure Dataアカウントアクセス権限
クエリを実行する前に、Treasure Dataでデータ接続を作成して設定する必要があります。データ接続の一部として、統合にアクセスするための認証情報を提供します。
- TD Consoleを開きます
- Integrations Hub > Catalogに移動します
- カタログ画面の右端にある検索アイコンをクリックし、Criteoと入力します。
- Criteo統合にマウスカーソルを合わせ、Create Authenticationを選択します。
- Continueを選択します
- 接続に名前を付けます。
- Doneを選択します。
- サポートに連絡して同意URL(例: https://consent.criteo.com/request?nonce=xxxxxxxxxx&hmac=xxxxxxxxxx)を提供してもらいます。
- このリンクをブラウザで開く必要があります。
- 次のように広告主へのアクセスを許可します。
- 変更を承認します。
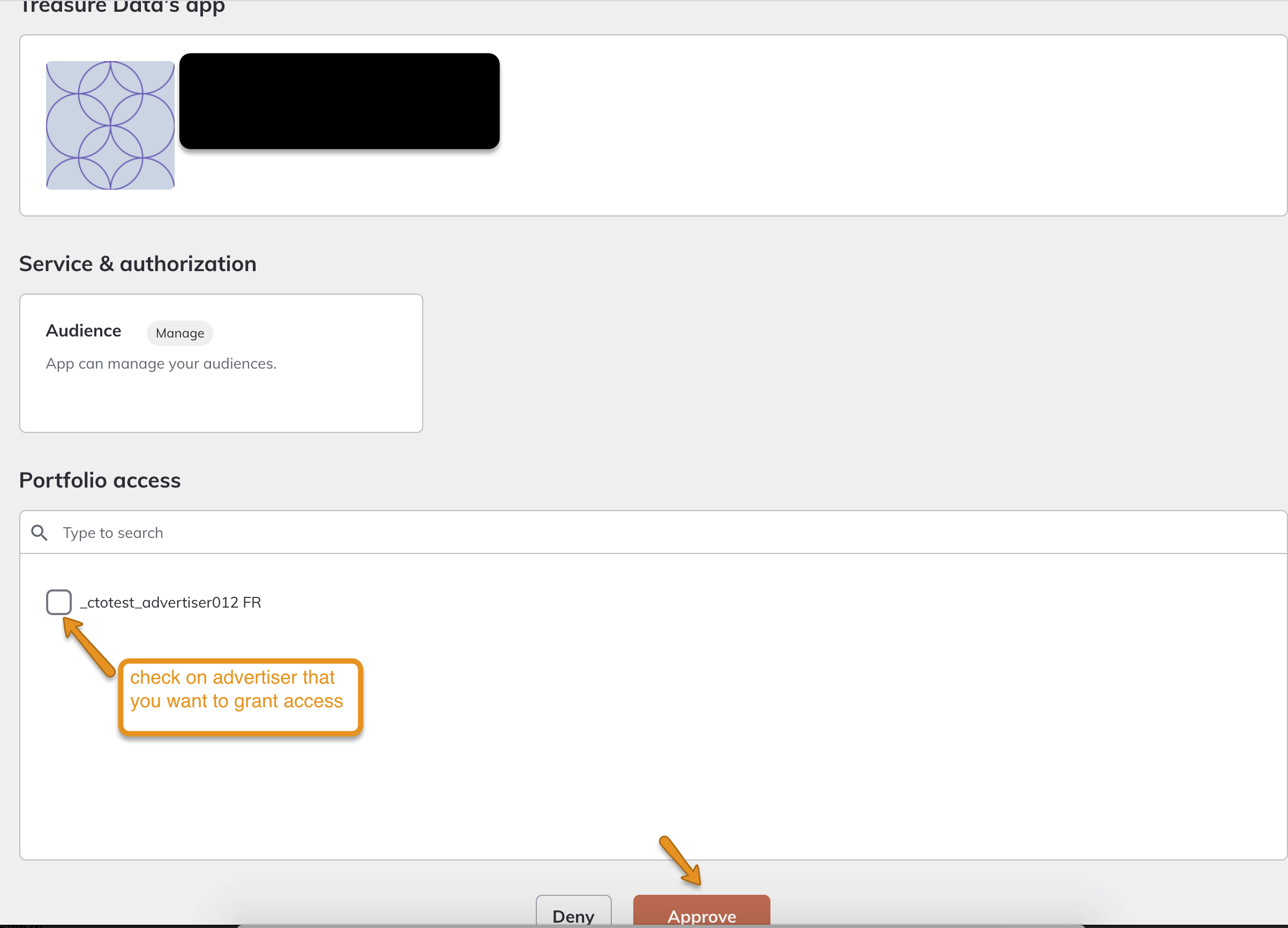
このIDは、データをCriteoにエクスポートするために必要です。
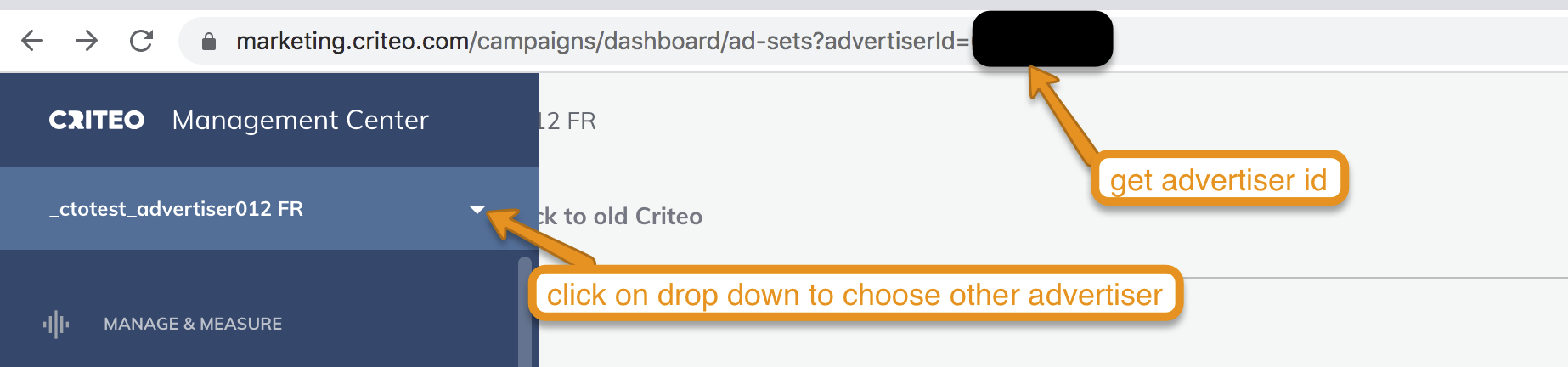
- https://account.criteo.com/auth/XUI/criteo-login/にログインします
- Management Centerを選択します。
- URLから広告主IDを取得します。例:
クエリで列マッピングを定義する必要がある場合があります。
Creating a Destination Integrationの手順を完了します。
Data Workbench > Queriesに移動します。
データをエクスポートするクエリを選択します。
クエリを実行して結果セットを検証します。
Export Resultsを選択します。
既存の統合認証を選択します。

追加のExport Resultsの詳細を定義します。エクスポート統合コンテンツで統合パラメータを確認します。
Doneを選択します。
指定した宛先にデータが移動したことを検証します。
Criteoにエクスポートされるデータは、Criteoスキーマに従う必要があります。サポートされている列名は次のとおりです:
- id: オーディエンスセグメントID
- name: オーディエンスセグメント名
- operation: オーディエンスセグメントに対して実行する操作(addまたはremove)
- schema: データの行で表される識別子のタイプ。サポートされている識別子の値には、gum、email、madid、identityLinkが含まれます
- userid: オーディエンスセグメントに追加または削除する識別子
- gumid: GUM caller ID、gumスキーマに必要なデータ。この場合、呼び出し元がTreasureDataであるため、
359を指定する必要があります。
例:
SELECT
audience_segment_id_column AS id,
audience_segment_name_column AS name,
'add' AS OPERATION,
'gum' AS SCHEMA,
{criteo_id} AS userid,
359 AS gumid
FROM
your_table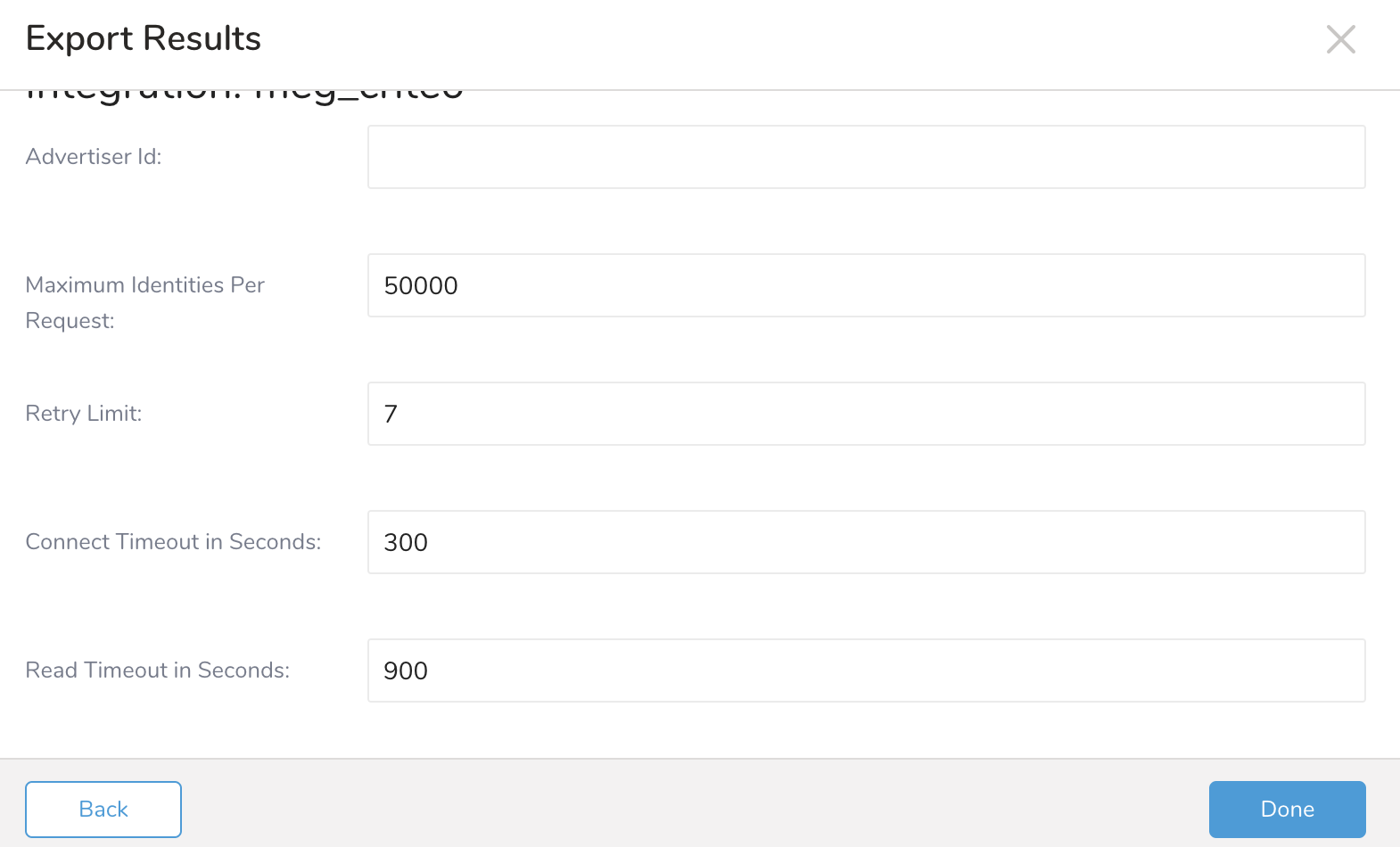
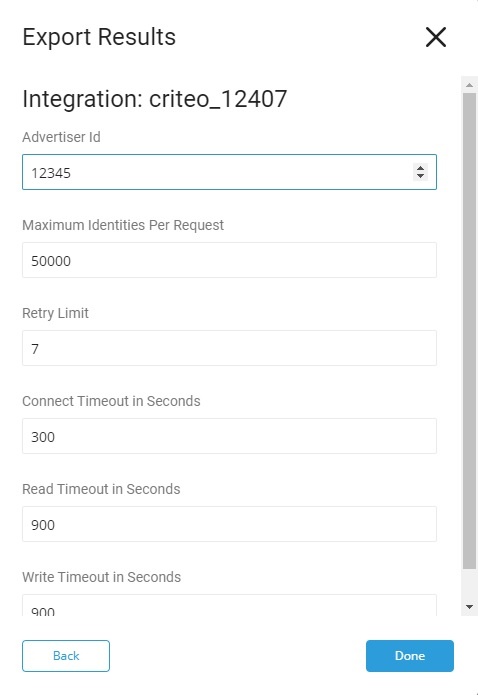
| パラメータ | 説明 | |
|---|---|---|
| Advertiser ID | 必須 | オーディエンスをグループ化するために使用されるID。 |
| Maximum Identities Per Request | オプション デフォルト: 50000 | リクエストごとに含めるIDの最大数。Criteoインターフェースの最大数は50000です。 |
| Retry Limit | オプション デフォルト: 7 | ネットワーク操作を試行する回数。 |
| Connect Timeout in Seconds | オプション デフォルト: 300 | 接続操作を中止するまで待機する時間(秒)。デフォルト: 300、これは5分に相当します。 |
| Read Timeout in Seconds | オプション デフォルト: 900 | 読み取り操作を中止するまで待機する時間(秒)。デフォルト: 900、これは15分に相当します。 |
| Write Timeout in Seconds | オプション デフォルト: 900 | 書き込み操作を中止するまで待機する時間(秒)。デフォルト: 900、これは15分に相当します。 |
SELECT
audience_id_column AS id,
audience_name_column AS name,
operation_column AS operation,
schema_column AS schema,
userid_column AS userid,
gumid_column AS gumid
FROM
your_table
;次はサンプル設定です:
Audience Studio で activation を作成することで、segment データをターゲットプラットフォームに送信することもできます。
- Audience Studio に移動します。
- parent segment を選択します。
- ターゲット segment を開き、右クリックして、Create Activation を選択します。
- Details パネルで、Activation 名を入力し、前述の Configuration Parameters のセクションに従って activation を設定します。
- Output Mapping パネルで activation 出力をカスタマイズします。

- Attribute Columns
- Export All Columns を選択すると、変更を加えずにすべての列をエクスポートできます。
- + Add Columns を選択して、エクスポート用の特定の列を追加します。Output Column Name には、Source 列名と同じ名前があらかじめ入力されます。Output Column Name を更新できます。+ Add Columns を選択し続けて、activation 出力用の新しい列を追加します。
- String Builder
- + Add string を選択して、エクスポート用の文字列を作成します。次の値から選択します:
- String: 任意の値を選択します。テキストを使用してカスタム値を作成します。
- Timestamp: エクスポートの日時。
- Segment Id: segment ID 番号。
- Segment Name: segment 名。
- Audience Id: parent segment 番号。
- + Add string を選択して、エクスポート用の文字列を作成します。次の値から選択します:
- Schedule を設定します。

- スケジュールを定義する値を選択し、オプションでメール通知を含めます。
- Create を選択します。
batch journey の activation を作成する必要がある場合は、Creating a Batch Journey Activation を参照してください。
Scheduled Jobs と Result Export を使用して、指定したターゲット宛先に出力結果を定期的に書き込むことができます。
Treasure Data のスケジューラー機能は、高可用性を実現するために定期的なクエリ実行をサポートしています。
2 つの仕様が競合するスケジュール仕様を提供する場合、より頻繁に実行するよう要求する仕様が優先され、もう一方のスケジュール仕様は無視されます。
例えば、cron スケジュールが '0 0 1 * 1' の場合、「月の日」の仕様と「週の曜日」が矛盾します。前者の仕様は毎月 1 日の午前 0 時 (00:00) に実行することを要求し、後者の仕様は毎週月曜日の午前 0 時 (00:00) に実行することを要求するためです。後者の仕様が優先されます。
Data Workbench > Queries に移動します
新しいクエリを作成するか、既存のクエリを選択します。
Schedule の横にある None を選択します。

ドロップダウンで、次のスケジュールオプションのいずれかを選択します:
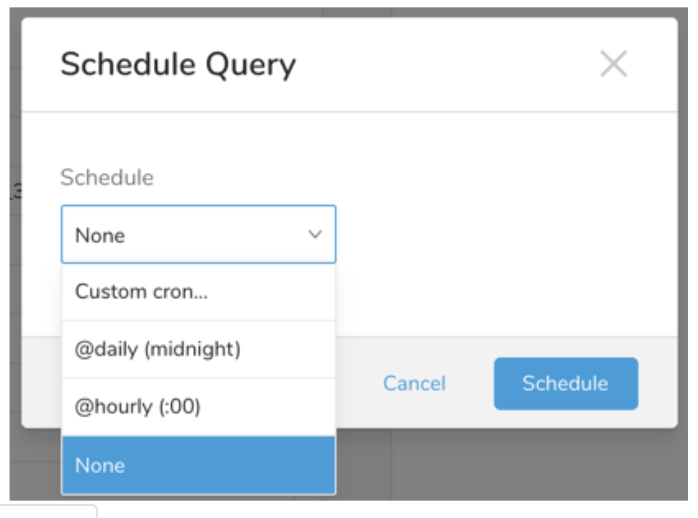
ドロップダウン値 説明 Custom cron... Custom cron... の詳細を参照してください。 @daily (midnight) 指定されたタイムゾーンで 1 日 1 回午前 0 時 (00:00 am) に実行します。 @hourly (:00) 毎時 00 分に実行します。 None スケジュールなし。
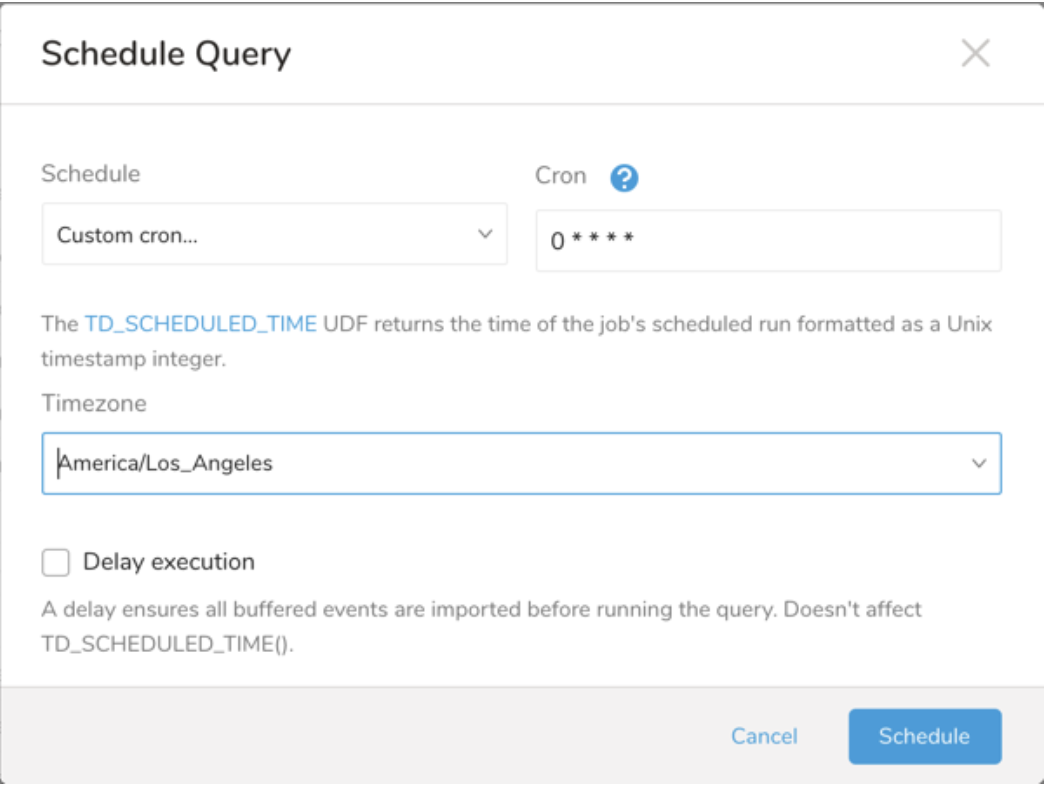
| Cron 値 | 説明 |
|---|---|
0 * * * * | 1 時間に 1 回実行します。 |
0 0 * * * | 1 日 1 回午前 0 時に実行します。 |
0 0 1 * * | 毎月 1 日の午前 0 時に 1 回実行します。 |
| "" | スケジュールされた実行時刻のないジョブを作成します。 |
* * * * *
- - - - -
| | | | |
| | | | +----- day of week (0 - 6) (Sunday=0)
| | | +---------- month (1 - 12)
| | +--------------- day of month (1 - 31)
| +-------------------- hour (0 - 23)
+------------------------- min (0 - 59)次の名前付きエントリを使用できます:
- Day of Week: sun, mon, tue, wed, thu, fri, sat.
- Month: jan, feb, mar, apr, may, jun, jul, aug, sep, oct, nov, dec.
各フィールド間には単一のスペースが必要です。各フィールドの値は、次のもので構成できます:
| フィールド値 | 例 | 例の説明 |
|---|---|---|
| 各フィールドに対して上記で表示された制限内の単一の値。 | ||
フィールドに基づく制限がないことを示すワイルドカード '*'。 | '0 0 1 * *' | 毎月 1 日の午前 0 時 (00:00) に実行するようにスケジュールを設定します。 |
範囲 '2-5' フィールドの許可される値の範囲を示します。 | '0 0 1-10 * *' | 毎月 1 日から 10 日までの午前 0 時 (00:00) に実行するようにスケジュールを設定します。 |
カンマ区切りの値のリスト '2,3,4,5' フィールドの許可される値のリストを示します。 | 0 0 1,11,21 * *' | 毎月 1 日、11 日、21 日の午前 0 時 (00:00) に実行するようにスケジュールを設定します。 |
周期性インジケータ '*/5' フィールドの有効な値の範囲に基づいて、 スケジュールが実行を許可される頻度を表現します。 | '30 */2 1 * *' | 毎月 1 日、00:30 から 2 時間ごとに実行するようにスケジュールを設定します。 '0 0 */5 * *' は、毎月 5 日から 5 日ごとに午前 0 時 (00:00) に実行するようにスケジュールを設定します。 |
'*' ワイルドカードを除く上記の いずれかのカンマ区切りリストもサポートされています '2,*/5,8-10' | '0 0 5,*/10,25 * *' | 毎月 5 日、10 日、20 日、25 日の午前 0 時 (00:00) に実行するようにスケジュールを設定します。 |
- (オプション) Delay execution を有効にすることで、クエリの開始時刻を遅延させることができます。
Treasure Workflow内で、このデータコネクタを使用してデータをエクスポートするように指定できます。
Using Workflows to Export Data with the TD Toolbeltで詳細をご確認ください。
Treasure Workflow内で、データコネクタを使用してデータを出力するように指定できます。
timezone: UTC
_export:
td:
database: sample_datasets
+td-result-into-criteo:
td>: queries/sample.sql
result_connection: your_connections_name
result_settings:
advertiser_id: 12345
request_threshold: 50000
request_retries: 7
request_connect_timeout: 300
request_read_timeout: 900
request_write_timeout: 900Q: オーディエンスセグメントIDはどこで確認できますか?
- オーディエンスセグメントIDを確認するには、Criteoが提供するツールを確認してください。https://marketing.criteo.com/audiences?advertiserId={advertiserId}
Q: オーディエンスセグメントIDとオーディエンスセグメント名の両方がNULLでないことが必要ですか?
- いいえ。オーディエンスセグメントIDまたはオーディエンスセグメント名のいずれかが非NULLである必要があり、両方である必要はありません。オーディエンスセグメントIDとオーディエンスセグメント名の両方が提供されている場合、値は同じオーディエンスセグメント内に存在する必要があります。
Q: オーディエンスセグメントIDまたはオーディエンスセグメント名がオーディエンスセグメントのリストに存在しない場合、作成されますか?
- オーディエンスセグメント名が提供され、オーディエンスセグメントIDがNULLの場合、オーディエンスセグメント名がオーディエンスセグメントのリストに見つからない場合、オーディエンスセグメントが作成されます。
- オーディエンスセグメントIDが提供されている場合、オーディエンスセグメントIDがオーディエンスセグメントのリストに見つからない場合、オーディエンスセグメントは作成できません。Criteo APIでは、オーディエンスセグメントを作成するときにオーディエンスセグメントIDを指定することはできません。
Q: ユーザーを追加または削除する際に、オーディエンスセグメントが更新されるまでどのくらいの時間がかかりますか?
- Criteoがデータを処理して表示できるようにするには、最大24時間かかる場合があります。データはCriteoのシステムに保存されますが、処理には時間がかかります。
Q: アップロード結果はどのように確認できますか?
- Criteoが提供するツール(https://marketing.criteo.com/audiences?advertiserId={advertiserId})で確認してください。
Q: ログ: Columns [<name(s)>] were not found.
- メッセージに記載されている列名がクエリに見つかりませんでした。
- 列名が欠落していないか、スペルミスがないかクエリを確認してください。
Q: ログ: Created audience id 'id' for audience name 'name'
- 提供された広告主IDのオーディエンスセグメントのリスト内にオーディエンスセグメント名が見つかりませんでした。オーディエンスセグメントは、名前が存在せず、クエリによって提供されたID値がNULLの場合にのみ作成されます。
Q: ログ: Audience id 'id' is not found in the list of audiences for advertiser 'id'. Cannot create a new audience for non-existent id
- クエリによって提供されたオーディエンスセグメントID値がNULLでなく、提供された広告主IDのオーディエンスセグメントのリスト内にオーディエンスセグメントIDが存在しない場合、コネクタはオーディエンスセグメントを作成できません。提供されたオーディエンスセグメントIDはCriteo APIによって生成されたオーディエンスセグメントIDと一致せず、データの不一致が発生します。
- オーディエンスセグメントを作成し、不明なオーディエンスセグメントIDのデータエントリを新しく作成されたオーディエンスセグメントIDで更新してください。
Q: ログ: Audience name 'name' is not found in the list of audiences for advertiser 'id' but audience id 'id' is found. Cannot create a new audience due to name mismatch
- オーディエンスセグメントIDと名前の両方がクエリによって提供されましたが、提供された広告主IDのオーディエンスセグメントのリスト内にオーディエンスセグメント名が見つかりませんでした。Criteo API操作の一部として名前を提供することは無効です。
- データベース内の名前をNULLにするか、オーディエンスセグメント名をクエリによって提供された名前と一致するように更新してください。
Q: ログ: Audience id 'id' and audience name 'name' do not represent the same audience for advertiser 'id'
- IDに関連付けられたオーディエンスセグメント名が、クエリによって提供されたオーディエンスセグメント名と一致しません。
- オーディエンスセグメントIDと名前の両方がクエリによって提供され、NULLでない場合、両方の値は同じオーディエンスセグメントに関連付けられている必要があります。IDに関連付けられたオーディエンスセグメント名をクエリによって提供された名前と一致するように更新するか、データの行を変更して名前をオーディエンスセグメント内の名前の値と一致するように設定できます。